2020年 第46卷 第4期
2020, 46(4): 613-630.
doi: 10.16383/j.aas.2018.c170561
摘要:
图实现(Graph realization)问题研究基于节点间全部或部分距离关系测量, 在\begin{document}$d$\end{document}
图实现(Graph realization)问题研究基于节点间全部或部分距离关系测量, 在












2020, 46(4): 631-652.
doi: 10.16383/j.aas.2017.c170502
摘要:
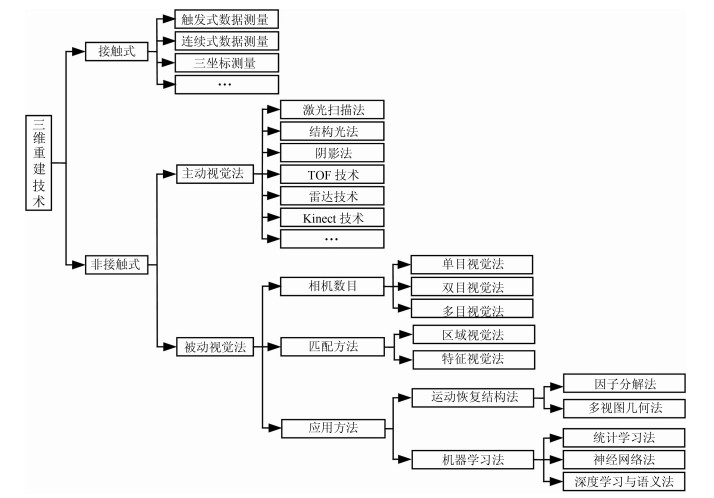
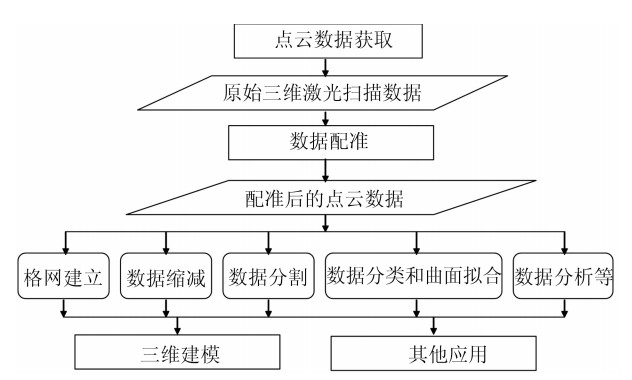
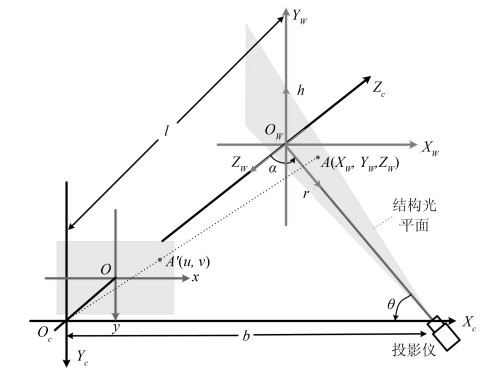
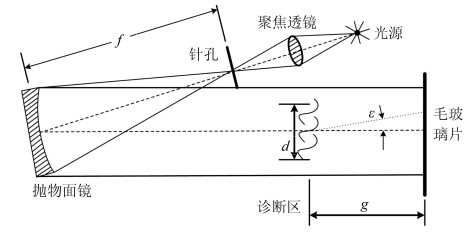
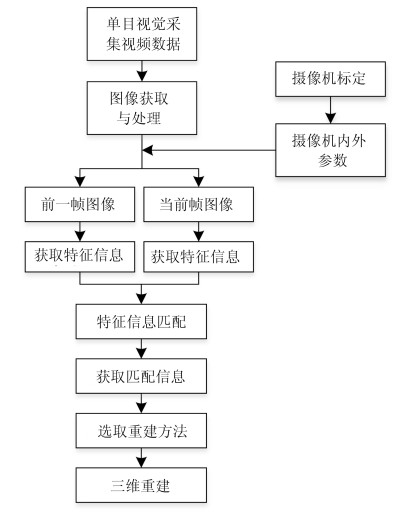
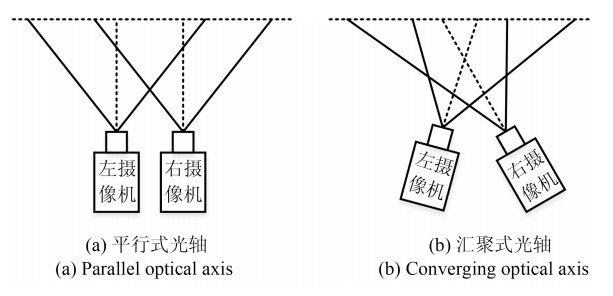
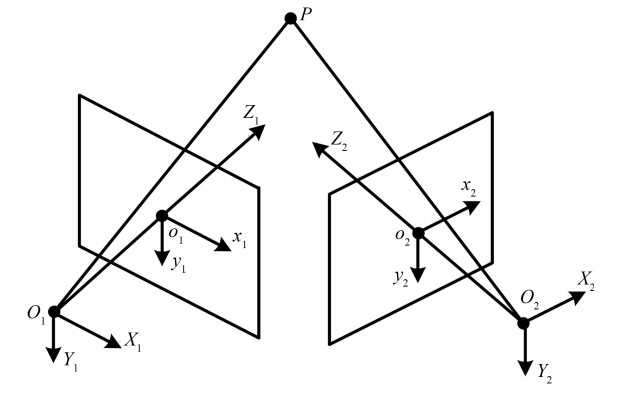
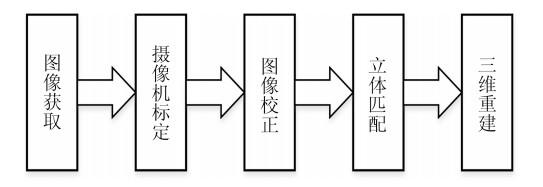
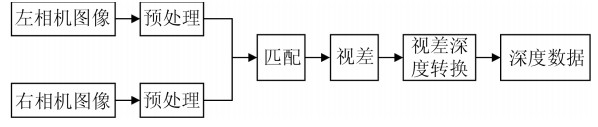
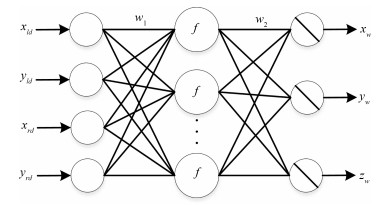
三维重建在视觉方面具有很高的研究价值, 在机器人视觉导航、智能车环境感知系统以及虚拟现实中被广泛应用.本文对近年来国内外基于视觉的三维重建方法的研究工作进行了总结和分析, 主要介绍了基于主动视觉下的激光扫描法、结构光法、阴影法以及TOF (Time of flight)技术、雷达技术、Kinect技术和被动视觉下的单目视觉、双目视觉、多目视觉以及其他被动视觉法的三维重建技术, 并比较和分析这些方法的优点和不足.最后对三维重建的未来发展作了几点展望.
三维重建在视觉方面具有很高的研究价值, 在机器人视觉导航、智能车环境感知系统以及虚拟现实中被广泛应用.本文对近年来国内外基于视觉的三维重建方法的研究工作进行了总结和分析, 主要介绍了基于主动视觉下的激光扫描法、结构光法、阴影法以及TOF (Time of flight)技术、雷达技术、Kinect技术和被动视觉下的单目视觉、双目视觉、多目视觉以及其他被动视觉法的三维重建技术, 并比较和分析这些方法的优点和不足.最后对三维重建的未来发展作了几点展望.

2020, 46(4): 653-669.
doi: 10.16383/j.aas.c190641
摘要:
由互联网促成的社会运动组织一经出现, 就受到了广大社会学者以及计算机领域专家的广泛关注. 一方面, 互联网特别是移动互联网在整合信息、引发共振、实时分享及高度互动等方面的特性, 为网民行为的大规模快速聚集提供了直通渠道, 使得多角度超视距观察并研究在线人群复杂行为及其组织特性成为可能; 另一方面, 这一研究在社会化媒体营销、共享经济、非军事组织行动中的应用意义愈加显著. 本文引入群体行为动力学和社会运动组织理论的研究, 提出基于ACP的动态网民群体运动组织(Cyber movement organizations, CMOs)研究方法. 本文工作首先使用多智能体建模方法构造双层结构的人工社区模型, 以此为基础对动态网民的个体以及群体动态组织行为展开计算实验探讨, 重点阐释了社区用户的交互行为机制及群体组织活动的建模机制, 为揭示微观个体简单行为对于宏观群体复杂涌现现象的影响奠定基础.
由互联网促成的社会运动组织一经出现, 就受到了广大社会学者以及计算机领域专家的广泛关注. 一方面, 互联网特别是移动互联网在整合信息、引发共振、实时分享及高度互动等方面的特性, 为网民行为的大规模快速聚集提供了直通渠道, 使得多角度超视距观察并研究在线人群复杂行为及其组织特性成为可能; 另一方面, 这一研究在社会化媒体营销、共享经济、非军事组织行动中的应用意义愈加显著. 本文引入群体行为动力学和社会运动组织理论的研究, 提出基于ACP的动态网民群体运动组织(Cyber movement organizations, CMOs)研究方法. 本文工作首先使用多智能体建模方法构造双层结构的人工社区模型, 以此为基础对动态网民的个体以及群体动态组织行为展开计算实验探讨, 重点阐释了社区用户的交互行为机制及群体组织活动的建模机制, 为揭示微观个体简单行为对于宏观群体复杂涌现现象的影响奠定基础.









2020, 46(4): 670-680.
doi: 10.16383/j.aas.c170363
摘要:
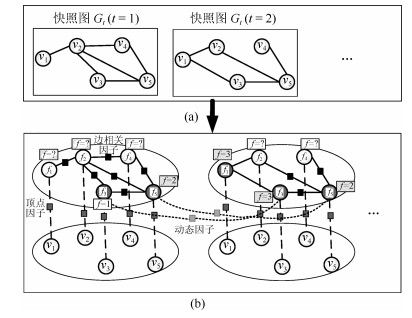
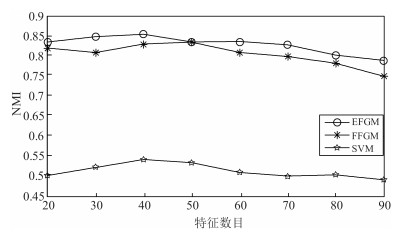
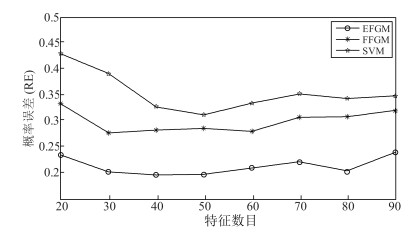
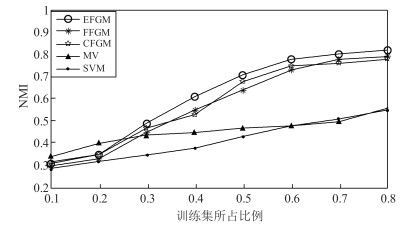
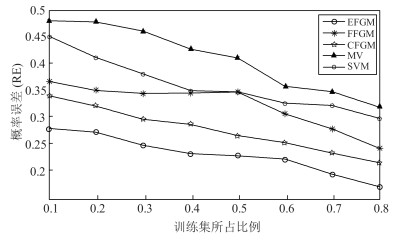
针对动态图的聚类主要存在着两点不足:首先, 现有的经典聚类算法大多从静态图分析的角度出发, 无法对真实网络图持续演化的特性进行有效建模, 亟待对动态图的聚类算法展开研究, 通过对不同时刻图快照的聚类结构进行分析进而掌握图的动态演化情况.其次, 真实网络中可以预先获取图中部分节点的聚类标签, 如何将这些先验信息融入到动态图的聚类结构划分中, 从而向图中的未标记节点分配聚类标签也是本文需要解决的问题.为此, 本文提出进化因子图模型(Evolution factor graph model, EFGM)用于解决动态图节点的半监督聚类问题, 所提EFGM不仅可以捕获动态图的节点属性和边邻接属性, 还可以捕获节点的时间快照信息.本文对真实数据集进行实验验证, 实验结果表明EFGM算法将动态图与先验信息融合到一个统一的进化因子图框架中, 既使得聚类结果满足先验知识, 又契合动态图的整体演化规律, 有效验证了本文方法的有效性.
针对动态图的聚类主要存在着两点不足:首先, 现有的经典聚类算法大多从静态图分析的角度出发, 无法对真实网络图持续演化的特性进行有效建模, 亟待对动态图的聚类算法展开研究, 通过对不同时刻图快照的聚类结构进行分析进而掌握图的动态演化情况.其次, 真实网络中可以预先获取图中部分节点的聚类标签, 如何将这些先验信息融入到动态图的聚类结构划分中, 从而向图中的未标记节点分配聚类标签也是本文需要解决的问题.为此, 本文提出进化因子图模型(Evolution factor graph model, EFGM)用于解决动态图节点的半监督聚类问题, 所提EFGM不仅可以捕获动态图的节点属性和边邻接属性, 还可以捕获节点的时间快照信息.本文对真实数据集进行实验验证, 实验结果表明EFGM算法将动态图与先验信息融合到一个统一的进化因子图框架中, 既使得聚类结果满足先验知识, 又契合动态图的整体演化规律, 有效验证了本文方法的有效性.
2020, 46(4): 681-694.
doi: 10.16383/j.aas.c170416
摘要:
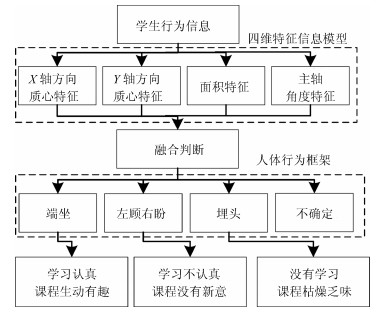
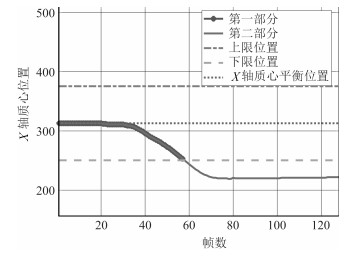
为了解决在线课程(Massive open online course, MOOC)授课过程中, 缺乏对于学生学习情况的跟踪与教学效果评估问题, 本文依据视频信息对学生行为进行建模, 提出了一种评判学生听课专心程度的行为自动分析算法.该算法能够有效跟踪学生的学习状态, 提取学生的行为特征参数, 并对这些参数进行D-S融合判决, 以获得学生的听课专注度.经过多次实验的结果表明, 本文采用的方法能够有效评判学生在授课期间的专心程度, 在数据融合上, 与贝叶斯推理方法相比, 采用D-S融合方法能有效提高实验结果的准确性和可靠性.
为了解决在线课程(Massive open online course, MOOC)授课过程中, 缺乏对于学生学习情况的跟踪与教学效果评估问题, 本文依据视频信息对学生行为进行建模, 提出了一种评判学生听课专心程度的行为自动分析算法.该算法能够有效跟踪学生的学习状态, 提取学生的行为特征参数, 并对这些参数进行D-S融合判决, 以获得学生的听课专注度.经过多次实验的结果表明, 本文采用的方法能够有效评判学生在授课期间的专心程度, 在数据融合上, 与贝叶斯推理方法相比, 采用D-S融合方法能有效提高实验结果的准确性和可靠性.








2020, 46(4): 695-720.
doi: 10.16383/j.aas.2018.c170232
摘要:
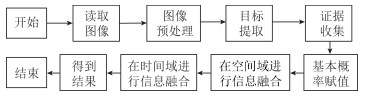
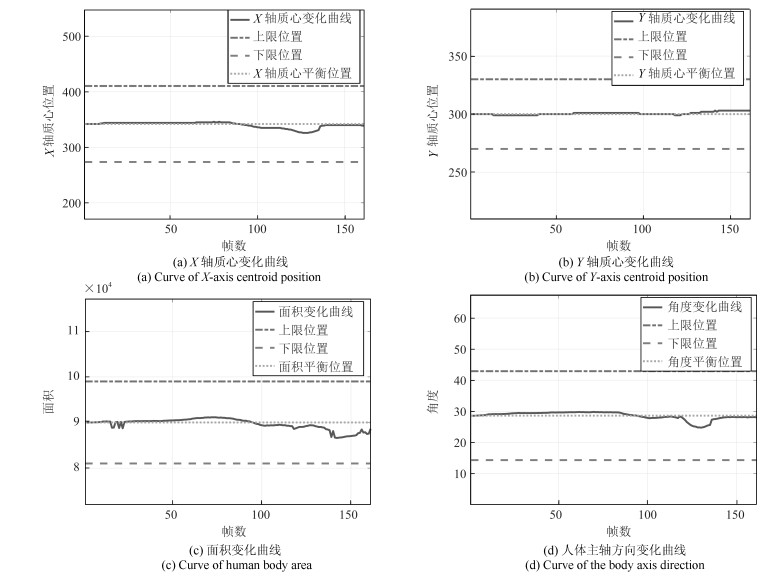
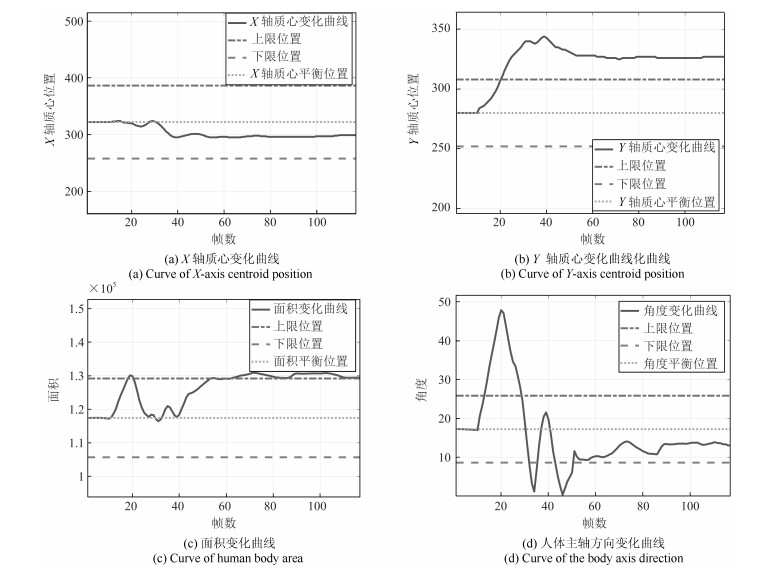
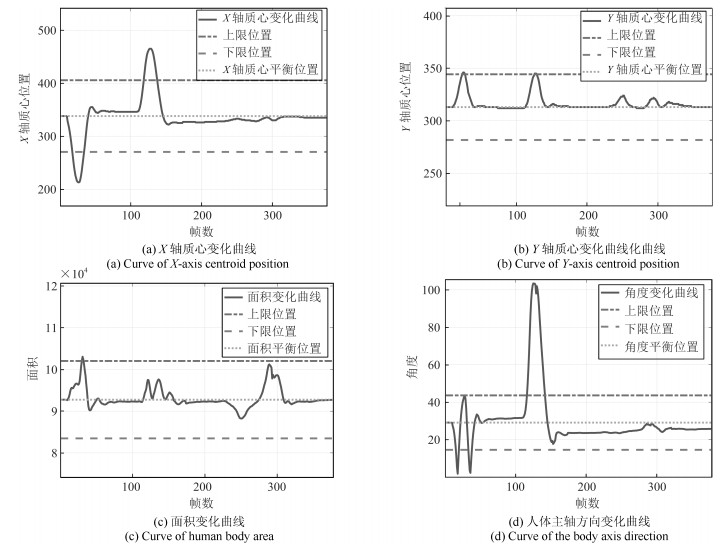
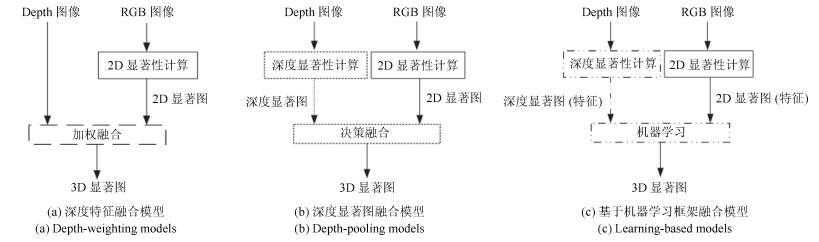
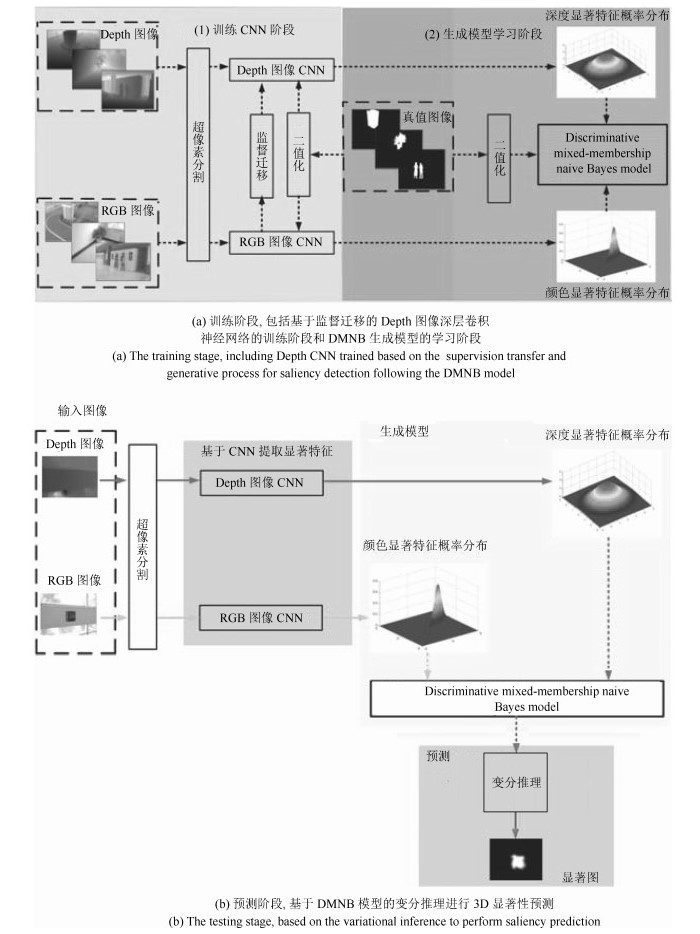
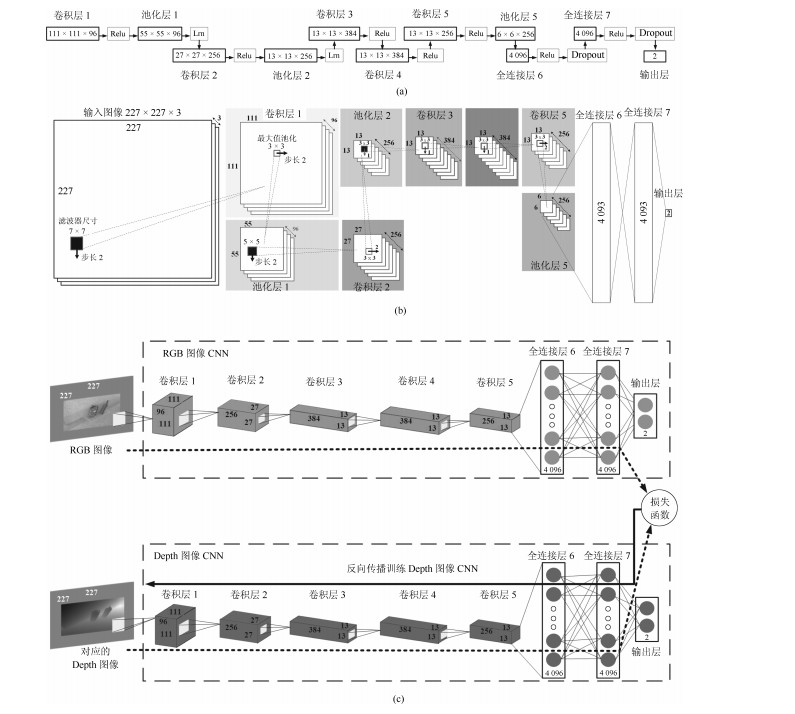
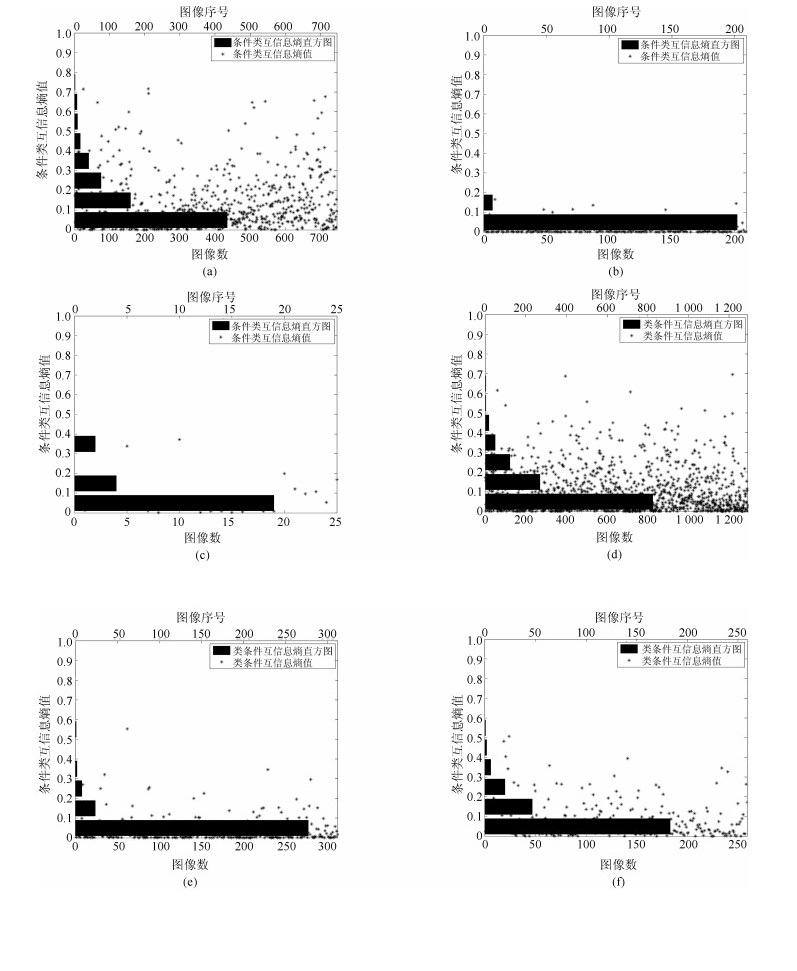
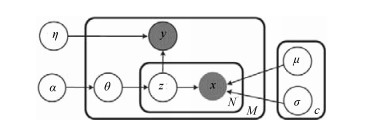
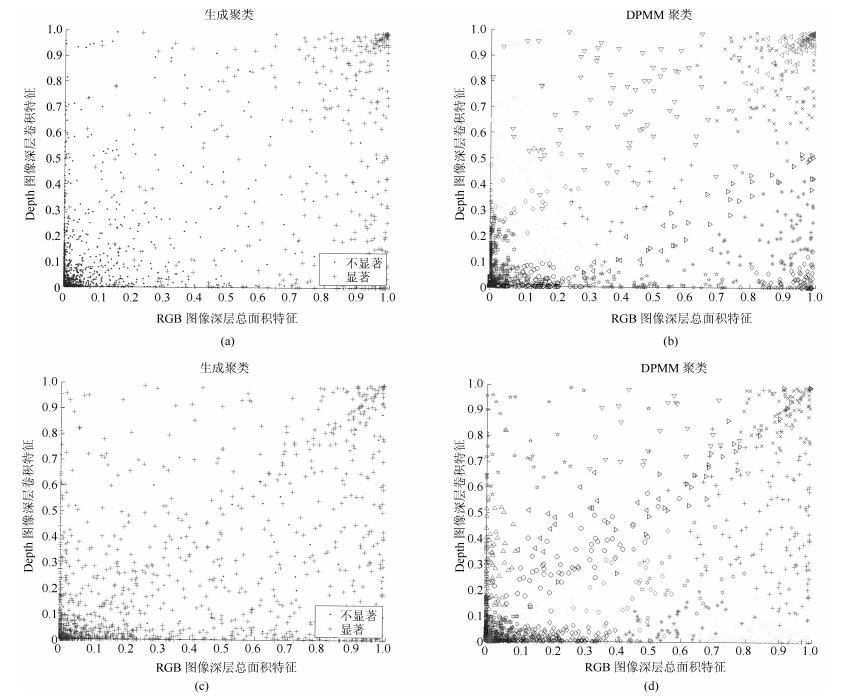
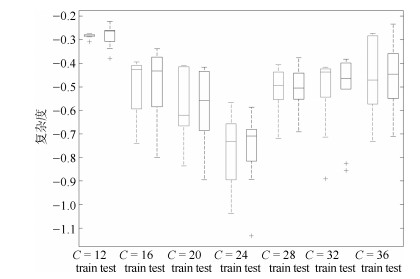
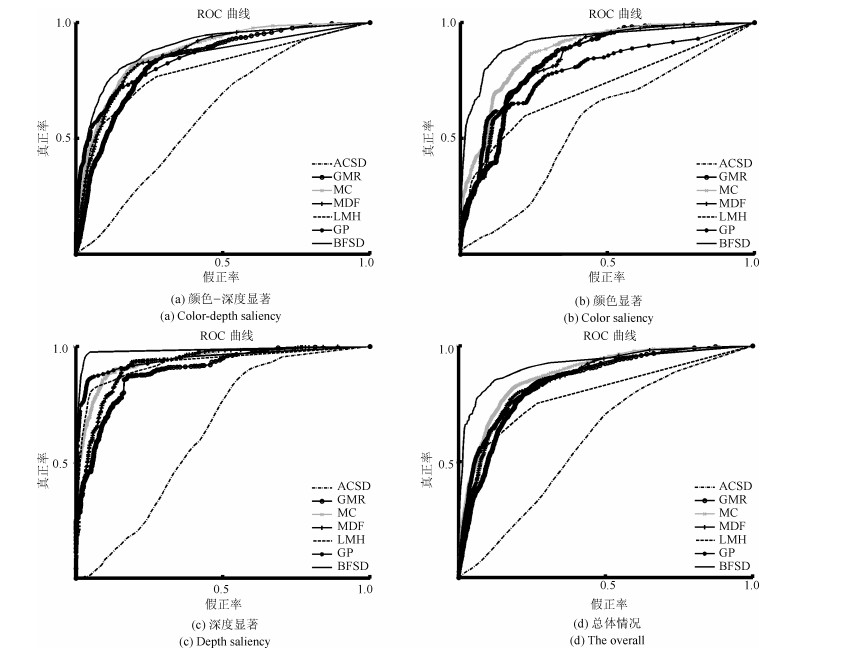
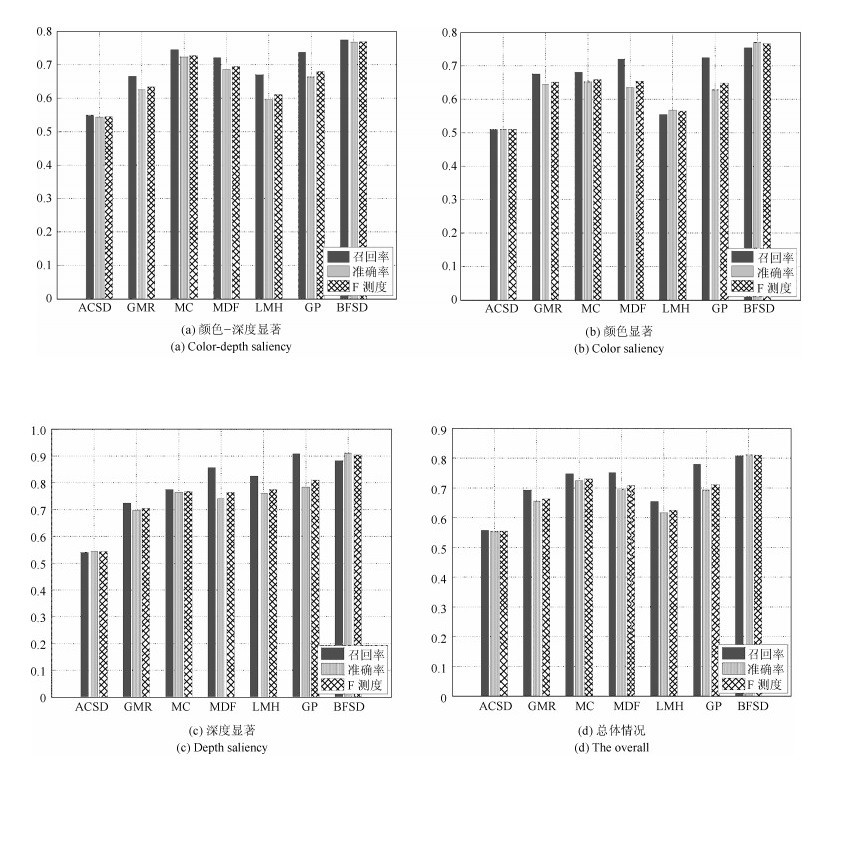
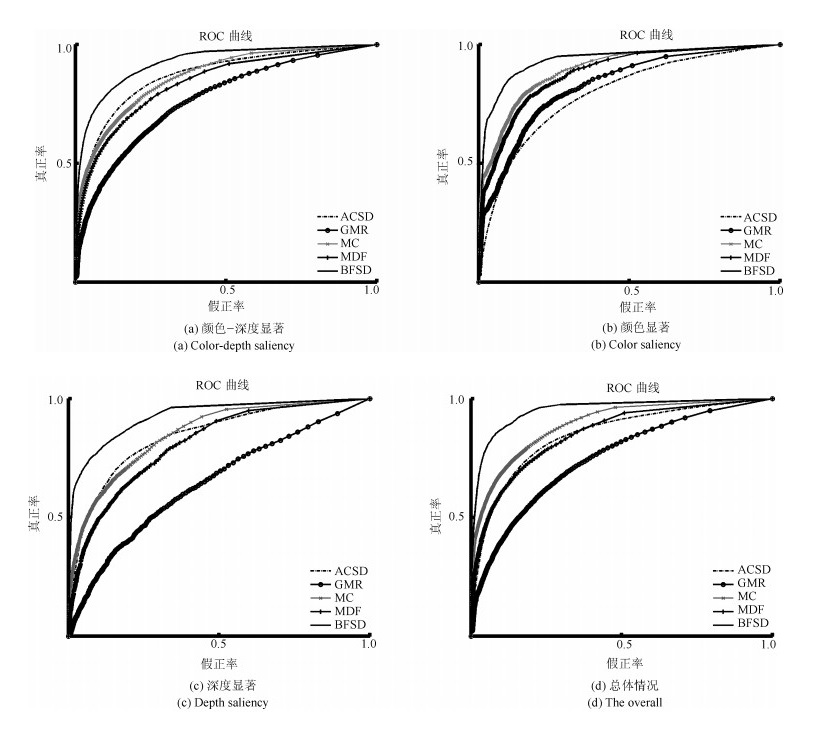
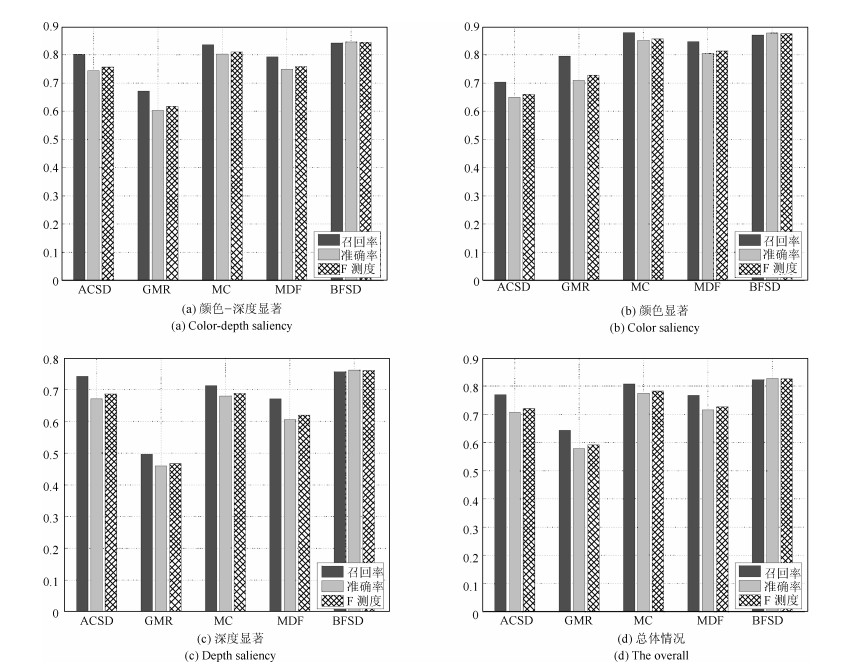
为了有效融合RGB图像颜色信息和Depth图像深度信息, 提出一种基于贝叶斯框架融合的RGB-D图像显著性检测方法.通过分析3D显著性在RGB图像和Depth图像分布的情况, 采用类条件互信息熵(Class-conditional mutual information, CMI)度量由深层卷积神经网络提取的颜色特征和深度特征的相关性, 依据贝叶斯定理得到RGB-D图像显著性后验概率.假设颜色特征和深度特征符合高斯分布, 基于DMNB (Discriminative mixed-membership naive Bayes)生成模型进行显著性检测建模, 其模型参数由变分最大期望算法进行估计.在RGB-D图像显著性检测公开数据集NLPR和NJU-DS2000上测试, 实验结果表明提出的方法具有更高的准确率和召回率.
为了有效融合RGB图像颜色信息和Depth图像深度信息, 提出一种基于贝叶斯框架融合的RGB-D图像显著性检测方法.通过分析3D显著性在RGB图像和Depth图像分布的情况, 采用类条件互信息熵(Class-conditional mutual information, CMI)度量由深层卷积神经网络提取的颜色特征和深度特征的相关性, 依据贝叶斯定理得到RGB-D图像显著性后验概率.假设颜色特征和深度特征符合高斯分布, 基于DMNB (Discriminative mixed-membership naive Bayes)生成模型进行显著性检测建模, 其模型参数由变分最大期望算法进行估计.在RGB-D图像显著性检测公开数据集NLPR和NJU-DS2000上测试, 实验结果表明提出的方法具有更高的准确率和召回率.









2020, 46(4): 721-733.
doi: 10.16383/j.aas.2018.c170670
摘要:
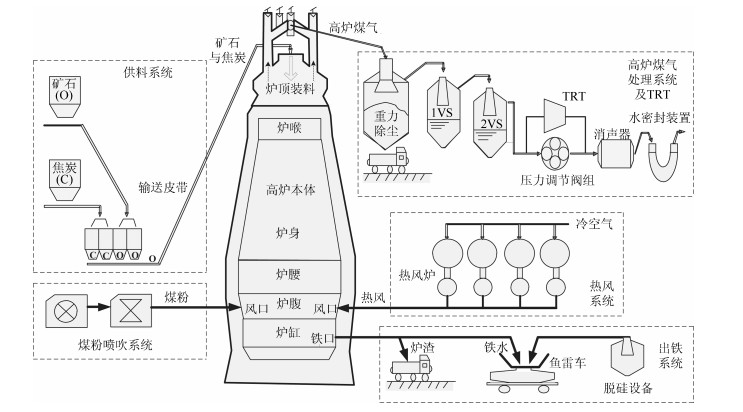
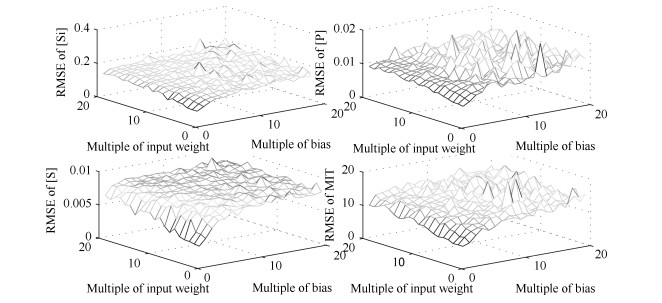
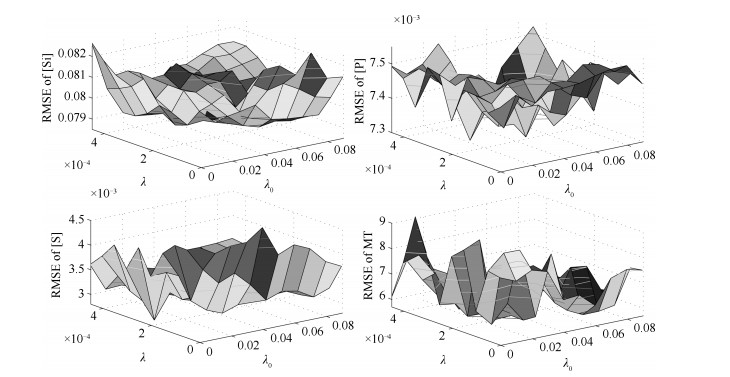
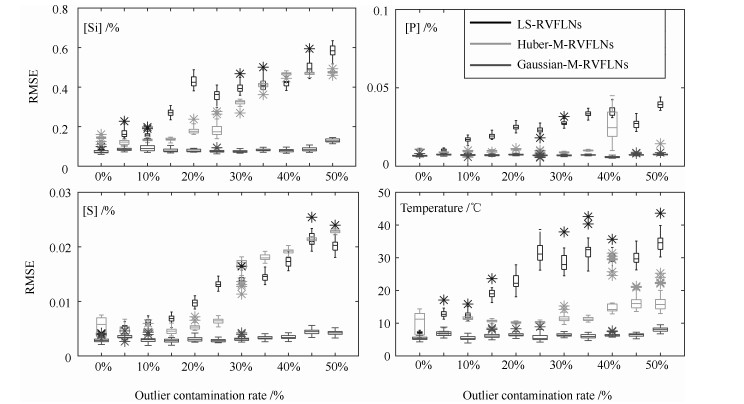
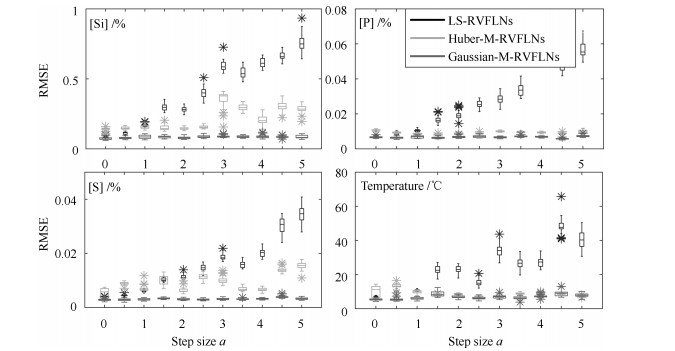
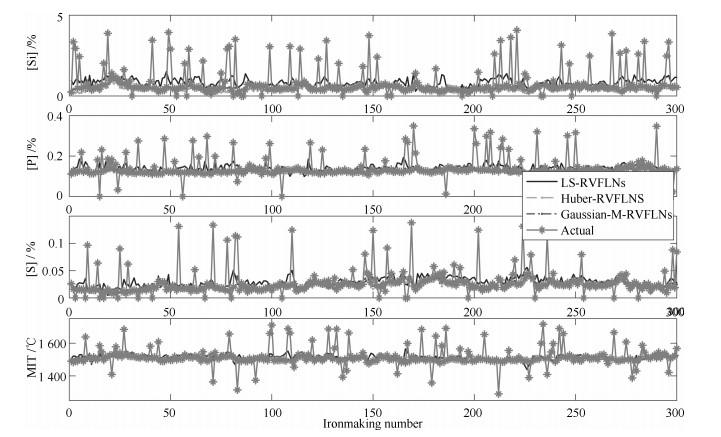
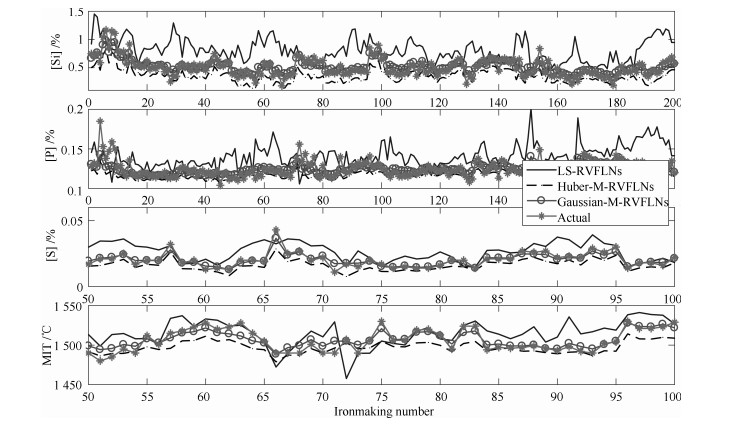
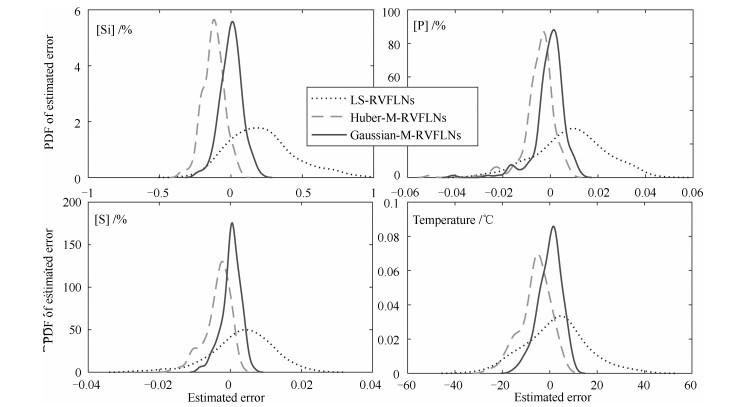
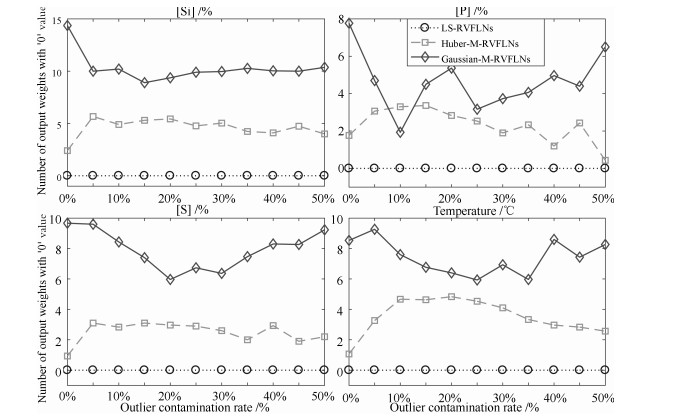
高炉炼铁过程运行优化与控制依赖于可靠、稳定的难测铁水质量(Molten iron quality, MIQ)指标模型.针对现有MIQ建模方法的不足, 本文提出一种新型的数据驱动鲁棒正则化随机权神经网络(Random vector functional-link networks, RVFLNs)算法, 用于实现MIQ指标在线估计的鲁棒建模.首先, 为了提高建模效率和降低计算复杂度, 采用数据驱动典型相关性分析方法从众多变量中提取与MIQ相关性最强的变量作为建模输入变量; 其次, 由于传统RVFLNs网络的输出权值由最小二乘估计获得, 易受离群数据影响而鲁棒性差, 引入基于Gaussian分布加权的M估计技术, 提出新型鲁棒RVFLNs算法建立多元MIQ指标的鲁棒模型; 同时, 在鲁棒加权后的最小二乘损失函数基础上, 进一步引入\begin{document}${L_1}$\end{document} \begin{document}${L_2}$\end{document}
高炉炼铁过程运行优化与控制依赖于可靠、稳定的难测铁水质量(Molten iron quality, MIQ)指标模型.针对现有MIQ建模方法的不足, 本文提出一种新型的数据驱动鲁棒正则化随机权神经网络(Random vector functional-link networks, RVFLNs)算法, 用于实现MIQ指标在线估计的鲁棒建模.首先, 为了提高建模效率和降低计算复杂度, 采用数据驱动典型相关性分析方法从众多变量中提取与MIQ相关性最强的变量作为建模输入变量; 其次, 由于传统RVFLNs网络的输出权值由最小二乘估计获得, 易受离群数据影响而鲁棒性差, 引入基于Gaussian分布加权的M估计技术, 提出新型鲁棒RVFLNs算法建立多元MIQ指标的鲁棒模型; 同时, 在鲁棒加权后的最小二乘损失函数基础上, 进一步引入
2020, 46(4): 734-743.
doi: 10.16383/j.aas.2018.c170387
摘要:
针对超空泡航行体姿轨控制普遍存在的模型不确定性问题进行相关研究.为此, 首先对其动力学特性进行分析, 并建立了超空泡航行体的动力学名义模型, 随后将其改写为不确定反馈系统, 然后利用反演控制方法设计超空泡航行体姿轨控制器, 针对模型中的未知函数利用径向基函数(Radial basis function, RBF)神经网络进行逼近并补偿, 由基于Lyapunov稳定理论设计的自适应方法计算神经网络的权重, 并给出稳定性证明.仿真研究验证了控制器设计的有效性.
针对超空泡航行体姿轨控制普遍存在的模型不确定性问题进行相关研究.为此, 首先对其动力学特性进行分析, 并建立了超空泡航行体的动力学名义模型, 随后将其改写为不确定反馈系统, 然后利用反演控制方法设计超空泡航行体姿轨控制器, 针对模型中的未知函数利用径向基函数(Radial basis function, RBF)神经网络进行逼近并补偿, 由基于Lyapunov稳定理论设计的自适应方法计算神经网络的权重, 并给出稳定性证明.仿真研究验证了控制器设计的有效性.














2020, 46(4): 744-751.
doi: 10.16383/j.aas.c180002
摘要:
张量指数函数已经广泛应用于工程领域.本文得到了一种有效的张量广义逆, 并以此为基础构造了广义逆张量Padé逼近的一种\begin{document}$\varepsilon$\end{document} \begin{document}$\varepsilon$\end{document}
张量指数函数已经广泛应用于工程领域.本文得到了一种有效的张量广义逆, 并以此为基础构造了广义逆张量Padé逼近的一种

2020, 46(4): 752-766.
doi: 10.16383/j.aas.2018.c170338
摘要:
借鉴闭环控制思想, 提出基于状态估计反馈的策略自适应差分进化(Differential evolution, DE)算法, 通过设计状态评价因子自适应判定种群个体所处于的阶段, 实现变异策略的反馈调节, 达到平衡算法全局探测和局部搜索的目的.首先, 基于抽象凸理论对种群个体建立进化状态估计模型, 提取下界估计信息并结合进化知识设计状态评价因子, 以判定当前种群的进化状态; 其次, 利用状态评价因子的反馈信息, 实现不同进化状态下策略的自适应调整以指导种群进化, 达到提高算法搜索效率的目的.另外, 20个典型测试函数与CEC2013测试集的实验结果表明, 所提算法在计算代价、收敛速度和解的质量方面优于主流改进差分进化算法和非差分进化算法.
借鉴闭环控制思想, 提出基于状态估计反馈的策略自适应差分进化(Differential evolution, DE)算法, 通过设计状态评价因子自适应判定种群个体所处于的阶段, 实现变异策略的反馈调节, 达到平衡算法全局探测和局部搜索的目的.首先, 基于抽象凸理论对种群个体建立进化状态估计模型, 提取下界估计信息并结合进化知识设计状态评价因子, 以判定当前种群的进化状态; 其次, 利用状态评价因子的反馈信息, 实现不同进化状态下策略的自适应调整以指导种群进化, 达到提高算法搜索效率的目的.另外, 20个典型测试函数与CEC2013测试集的实验结果表明, 所提算法在计算代价、收敛速度和解的质量方面优于主流改进差分进化算法和非差分进化算法.








2020, 46(4): 767-781.
doi: 10.16383/j.aas.c180523
摘要:
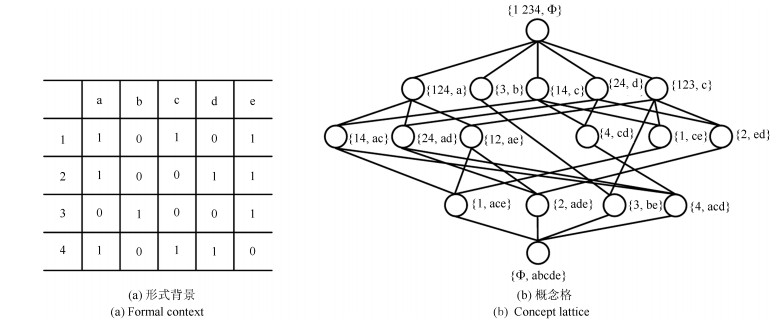
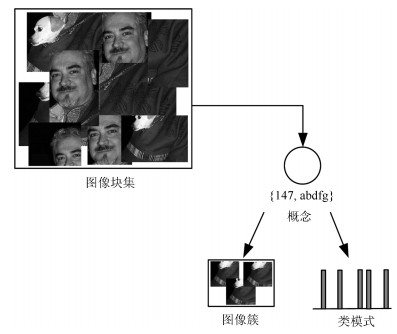
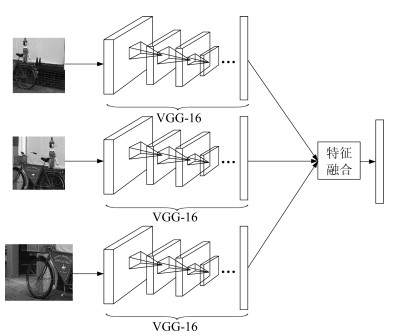
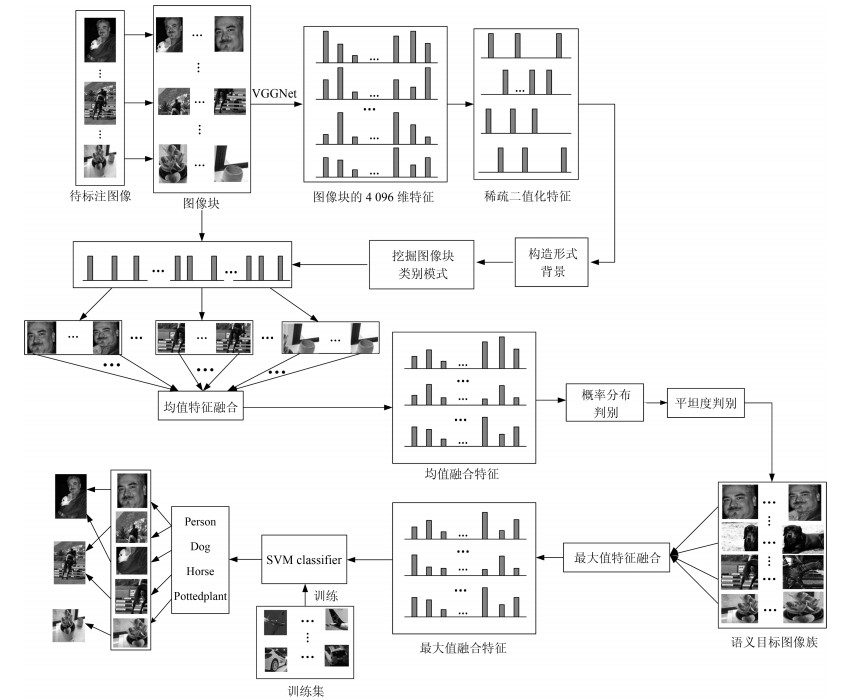
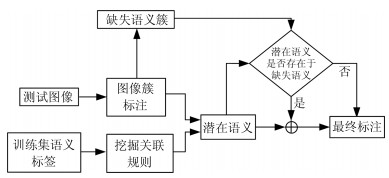
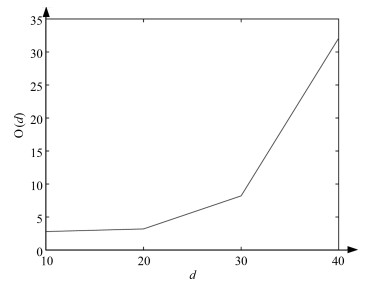
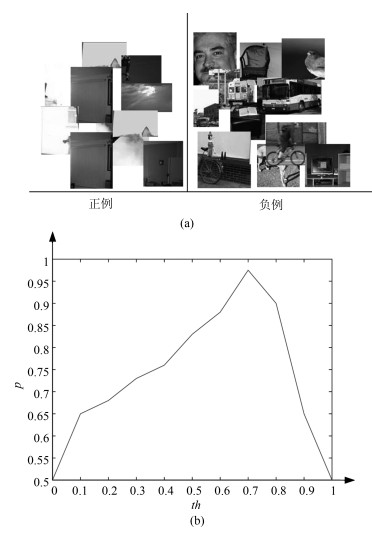
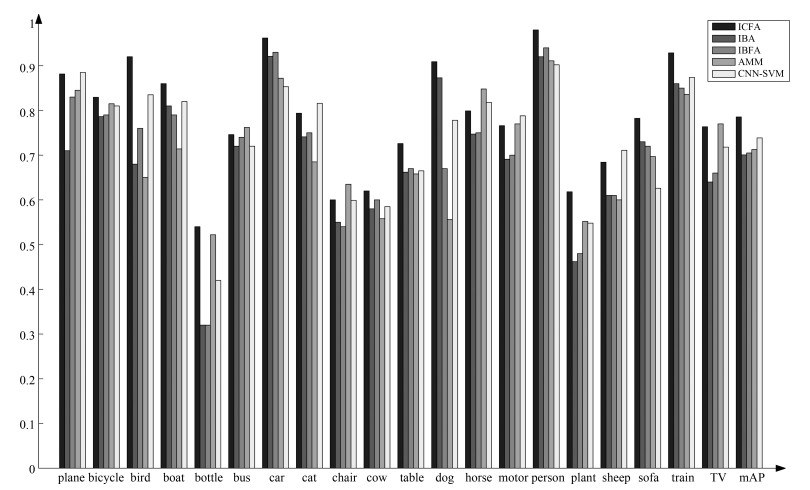
基于目标的图像标注一直是图像处理和计算机视觉领域中一个重要的研究问题.图像目标的多尺度性、多形变性使得图像标注十分困难.目标分割和目标识别是目标图像标注任务中两大关键问题.本文提出一种基于形式概念分析(Formal concept analysis, FCA)和语义关联规则的目标图像标注方法, 针对目标建议算法生成图像块中存在的高度重叠问题, 借鉴形式概念分析中概念格的思想, 按照图像块的共性将其归成几个图像簇挖掘图像类别模式, 利用类别概率分布判决和平坦度判决分别去除目标噪声块和背景噪声块, 最终得到目标语义簇; 针对语义目标判别问题, 首先对有效图像簇进行特征融合形成共性特征描述, 通过分类器进行类别判决, 生成初始目标图像标注, 然后利用图像语义标注词挖掘语义关联规则, 进行图像标注的语义补充, 以避免挖掘类别模式时丢失较小的语义目标.实验表明, 本文提出的图像标注算法既能保证语义标注的准确性, 又能保证语义标注的完整性, 具有较好的图像标注性能.
基于目标的图像标注一直是图像处理和计算机视觉领域中一个重要的研究问题.图像目标的多尺度性、多形变性使得图像标注十分困难.目标分割和目标识别是目标图像标注任务中两大关键问题.本文提出一种基于形式概念分析(Formal concept analysis, FCA)和语义关联规则的目标图像标注方法, 针对目标建议算法生成图像块中存在的高度重叠问题, 借鉴形式概念分析中概念格的思想, 按照图像块的共性将其归成几个图像簇挖掘图像类别模式, 利用类别概率分布判决和平坦度判决分别去除目标噪声块和背景噪声块, 最终得到目标语义簇; 针对语义目标判别问题, 首先对有效图像簇进行特征融合形成共性特征描述, 通过分类器进行类别判决, 生成初始目标图像标注, 然后利用图像语义标注词挖掘语义关联规则, 进行图像标注的语义补充, 以避免挖掘类别模式时丢失较小的语义目标.实验表明, 本文提出的图像标注算法既能保证语义标注的准确性, 又能保证语义标注的完整性, 具有较好的图像标注性能.


2020, 46(4): 782-795.
doi: 10.16383/j.aas.c180155
摘要:
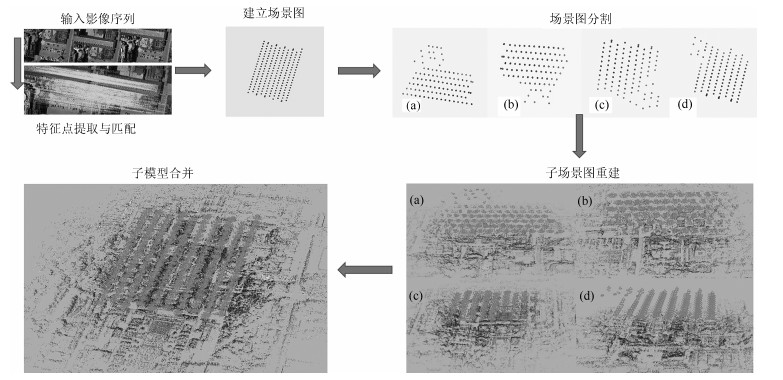
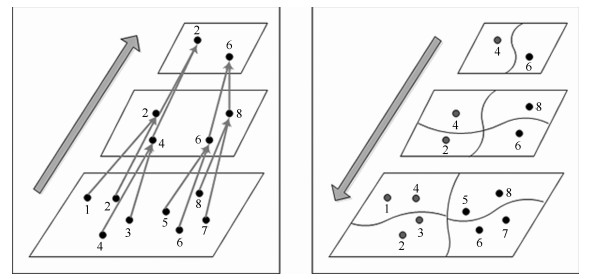
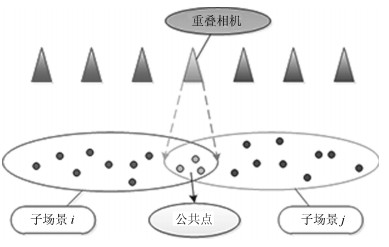
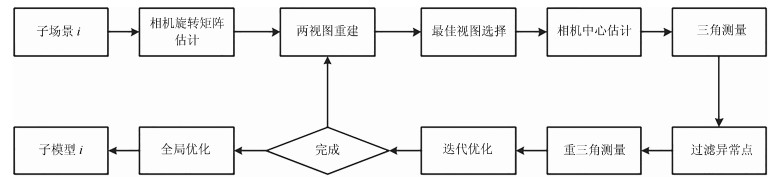
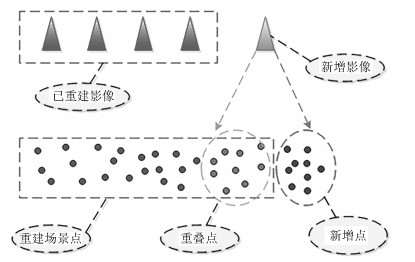
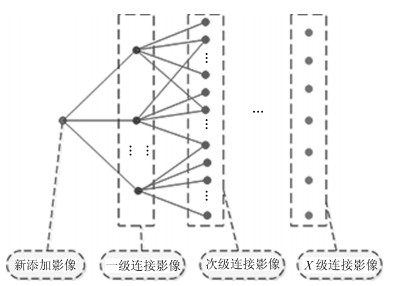
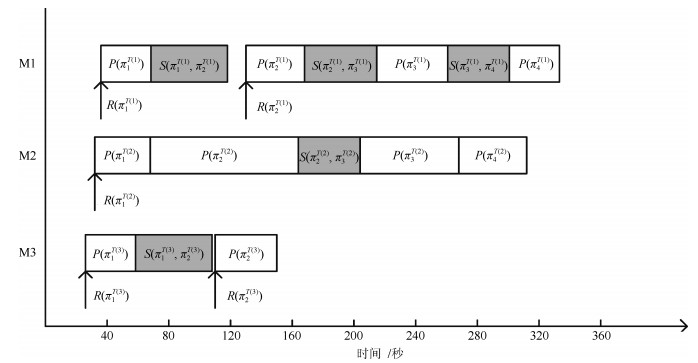
针对大范围三维重建, 重建效率较低和重建稳定性、精度差等问题, 提出了一种基于场景图分割的大范围混合式多视图三维重建方法.该方法首先使用多层次加权核K均值算法进行场景图分割; 然后,分别对每个子场景图进行混合式重建, 生成对应的子模型, 通过场景图分割、混合式重建和局部优化等方法提高重建效率、降低计算资源消耗, 并综合采用强化的最佳影像选择标准、稳健的三角测量方法和迭代优化等策略, 提高重建精度和稳健性; 最后, 对所有子模型进行合并, 完成大范围三维重建.分别使用互联网收集数据和无人机航拍数据进行了验证, 并与1DSFM、HSFM算法在计算精度和计算效率等方面进行了比较.实验结果表明, 本文算法大大提高了计算效率、计算精度, 能充分保证重建模型的完整性, 并具备单机大范围场景三维重建能力.
针对大范围三维重建, 重建效率较低和重建稳定性、精度差等问题, 提出了一种基于场景图分割的大范围混合式多视图三维重建方法.该方法首先使用多层次加权核K均值算法进行场景图分割; 然后,分别对每个子场景图进行混合式重建, 生成对应的子模型, 通过场景图分割、混合式重建和局部优化等方法提高重建效率、降低计算资源消耗, 并综合采用强化的最佳影像选择标准、稳健的三角测量方法和迭代优化等策略, 提高重建精度和稳健性; 最后, 对所有子模型进行合并, 完成大范围三维重建.分别使用互联网收集数据和无人机航拍数据进行了验证, 并与1DSFM、HSFM算法在计算精度和计算效率等方面进行了比较.实验结果表明, 本文算法大大提高了计算效率、计算精度, 能充分保证重建模型的完整性, 并具备单机大范围场景三维重建能力.






2020, 46(4): 796-804.
doi: 10.16383/j.aas.2018.c180188
摘要:
针对传统红外与可见光图像融合算法中存在的细节信息不够丰富, 边缘信息保留不够充分等问题, 文中提出了一种基于四阶偏微分方程(Fourth-order partial differential equation, FPDE)的改进的图像融合算法.算法首先采用FPDE将已配准的红外与可见光图像进行分解, 得到高频分量和低频分量; 然后, 对高频分量采用基于主成分分析(Principal component analysis, PCA)的融合规则来得到细节图像, 对低频分量采用基于期望值最大(Expectation maximization, EM)的融合规则来得到近似图像; 最后, 通过组合最终的高频分量和低频分量来重构得到最终的融合结果.实验是建立在标准的融合数据集上进行的, 并与传统的和最近的融合方法进行比较, 结果证明所提方法得到的融合图像比现有的融合方法能有效地综合红外与可见光图像中的重要信息, 有更好的视觉效果.
针对传统红外与可见光图像融合算法中存在的细节信息不够丰富, 边缘信息保留不够充分等问题, 文中提出了一种基于四阶偏微分方程(Fourth-order partial differential equation, FPDE)的改进的图像融合算法.算法首先采用FPDE将已配准的红外与可见光图像进行分解, 得到高频分量和低频分量; 然后, 对高频分量采用基于主成分分析(Principal component analysis, PCA)的融合规则来得到细节图像, 对低频分量采用基于期望值最大(Expectation maximization, EM)的融合规则来得到近似图像; 最后, 通过组合最终的高频分量和低频分量来重构得到最终的融合结果.实验是建立在标准的融合数据集上进行的, 并与传统的和最近的融合方法进行比较, 结果证明所提方法得到的融合图像比现有的融合方法能有效地综合红外与可见光图像中的重要信息, 有更好的视觉效果.






2020, 46(4): 805-819.
doi: 10.16383/j.aas.c180321
摘要:
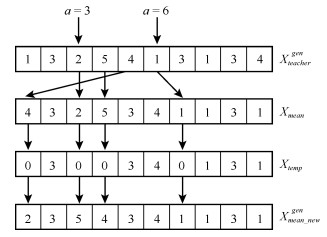
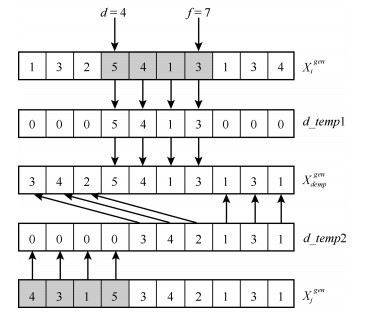
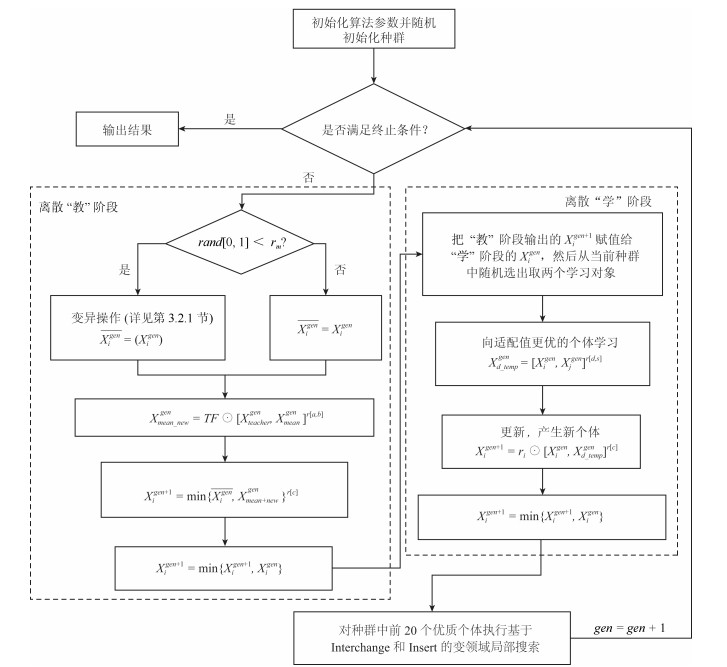
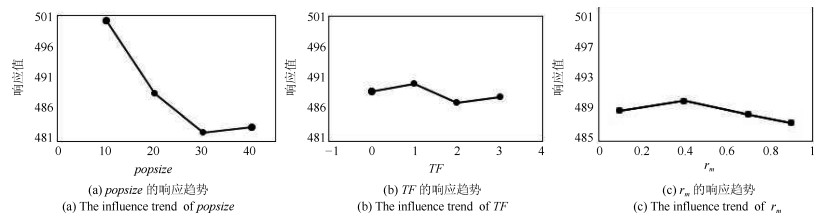
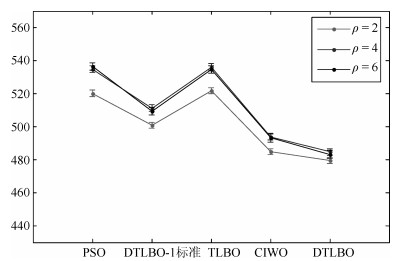
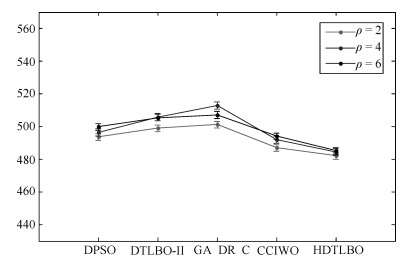
针对制造行业中广泛存在的一类复杂并行机调度问题, 即带到达时间、多工序、加工约束和序相关设置时间的并行机调度问题(Parallel machine scheduling problem with arrival time, multiple operations, process restraints and sequence-dependent setup times, PMSP_AMPS), 建立问题的排序模型并提出一种混合离散教与学优化算法进行求解, 优化目标为最小化最大完工时间.首先, 根据标准教与学算法(Teaching-learning-based optimization, TLBO)中两阶段个体更新公式的特点, 在保留每一阶段个体更新公式框架不变的前提下, 对公式中具体改变实数个体或向量的每个核心操作均用所设计的排列操作进行替换, 使其可直接在离散问题解空间中执行基于标准教与学算法机理的全局搜索, 从而明显提高了原算法的全局搜索效率.其次, 采用交换操作和插入操作构造了一种简洁有效地变邻域局部搜索, 对全局搜索发现的优质解区域进行细致搜索, 从而进一步增强了算法的性能.通过对不同测试问题的仿真实验和算法比较, 验证了所提算法可有效求解PMSP_AMPS.
针对制造行业中广泛存在的一类复杂并行机调度问题, 即带到达时间、多工序、加工约束和序相关设置时间的并行机调度问题(Parallel machine scheduling problem with arrival time, multiple operations, process restraints and sequence-dependent setup times, PMSP_AMPS), 建立问题的排序模型并提出一种混合离散教与学优化算法进行求解, 优化目标为最小化最大完工时间.首先, 根据标准教与学算法(Teaching-learning-based optimization, TLBO)中两阶段个体更新公式的特点, 在保留每一阶段个体更新公式框架不变的前提下, 对公式中具体改变实数个体或向量的每个核心操作均用所设计的排列操作进行替换, 使其可直接在离散问题解空间中执行基于标准教与学算法机理的全局搜索, 从而明显提高了原算法的全局搜索效率.其次, 采用交换操作和插入操作构造了一种简洁有效地变邻域局部搜索, 对全局搜索发现的优质解区域进行细致搜索, 从而进一步增强了算法的性能.通过对不同测试问题的仿真实验和算法比较, 验证了所提算法可有效求解PMSP_AMPS.
2020, 46(4): 820-830.
doi: 10.16383/j.aas.2018.c170352
摘要:
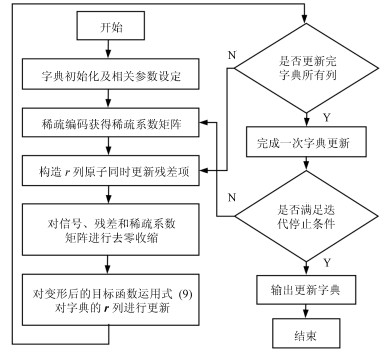
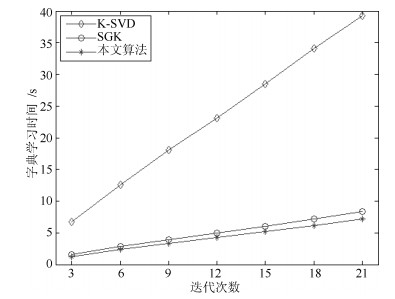
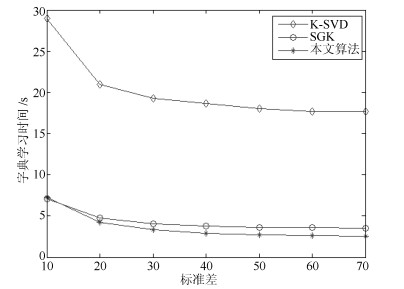
针对机器人图像压缩感知(Compressed sensing, CS)过程中稀疏字典训练时间过长的问题, 本文提出了一种更加高效的字典学习方法.通过对MOD、K-SVD、SGK等字典学习算法研究, 从参与更新的字典原子列数入手, 将残差项变形为多列原子同时更新, 进而利用最小二乘法连续地更新字典中的多个原子.本文算法是对SGK算法字典学习效率的进一步提高, 减少了单次迭代的计算量, 加快了字典学习速度.实验表明, 本文算法与K-SVD和SGK算法相比, 在字典稀疏性和重构图像质量变化很小的情况下, 字典训练时间得到较明显缩短.
针对机器人图像压缩感知(Compressed sensing, CS)过程中稀疏字典训练时间过长的问题, 本文提出了一种更加高效的字典学习方法.通过对MOD、K-SVD、SGK等字典学习算法研究, 从参与更新的字典原子列数入手, 将残差项变形为多列原子同时更新, 进而利用最小二乘法连续地更新字典中的多个原子.本文算法是对SGK算法字典学习效率的进一步提高, 减少了单次迭代的计算量, 加快了字典学习速度.实验表明, 本文算法与K-SVD和SGK算法相比, 在字典稀疏性和重构图像质量变化很小的情况下, 字典训练时间得到较明显缩短.