

-
摘要: 近年来, 以人机对抗为途径的智能决策技术取得了飞速发展, 人工智能(Artificial intelligence, AI)技术AlphaGo、AlphaStar等分别在围棋、星际争霸等游戏环境中战胜了顶尖人类选手. 兵棋推演作为一种人机对抗策略验证环境, 由于其非对称环境决策、更接近真实环境的随机性与高风险决策等特点, 受到智能决策技术研究者的广泛关注. 通过梳理兵棋推演与目前主流人机对抗环境(如围棋、德州扑克、星际争霸等)的区别, 阐述了兵棋推演智能决策技术的发展现状, 分析了当前主流技术的局限与瓶颈, 对兵棋推演中的智能决策技术研究进行了思考, 期望能对兵棋推演相关问题中的智能决策技术研究带来启发.Abstract: In recent years, decision-making intelligence based on human-machine confrontation has achieved rapid development. For example, artificial intelligence (AI) technology such as AlphaGo and AlphaStar have defeated top human players in games Go and StarCraft, respectively. Nowadays, wargame, as a new verification environment for human-machine confrontation, attracts more and more researchers due to new challenges being raised, i.e., asymmetric environmental decision-making and randomness with high-risk decision-making. In this paper, we will sort out the differences between wargame and the current mainstream human-machine confrontation environments such as Go, Poker and StarCraft. Then, we explain the development status of wargame intelligent technology, and analyze the limitations of current mainstream technologies. Finally, we present our thoughts about future development of technologies for wargame, hoping to inspire researchers for through study on wargame.1) 1
http://turingai.ia.ac.cn 2) 2http://turingai.ia.ac.cn/ranks/wargame_list 3) 3http://turingai.ia.ac.cn/notices/detail/116 4) 4http://turingai.ia.ac.cn/bbs/detail/14/1/29 5) 5http://www.cas.cn/syky/202107/t20210712_4798152.shtml 6) 6http://gym.openai.com -
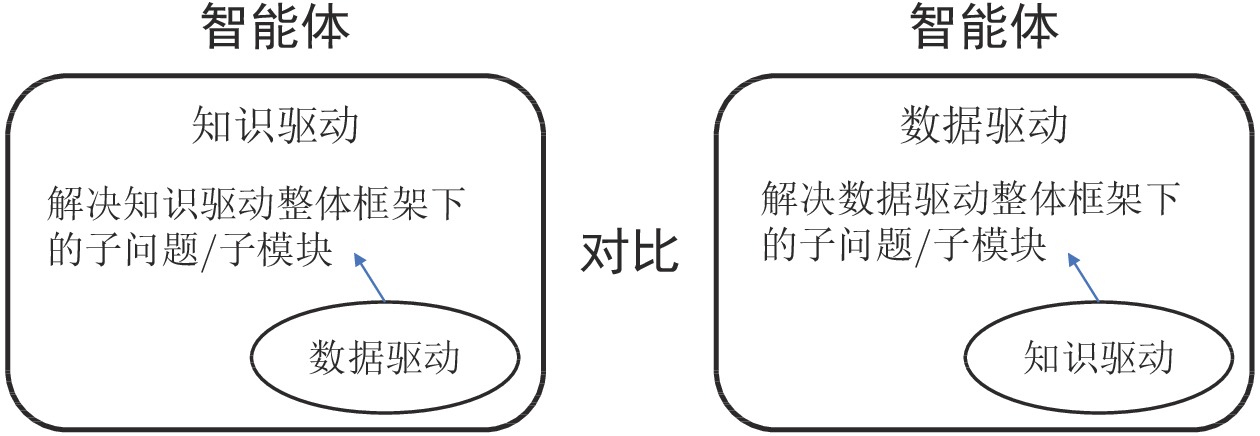
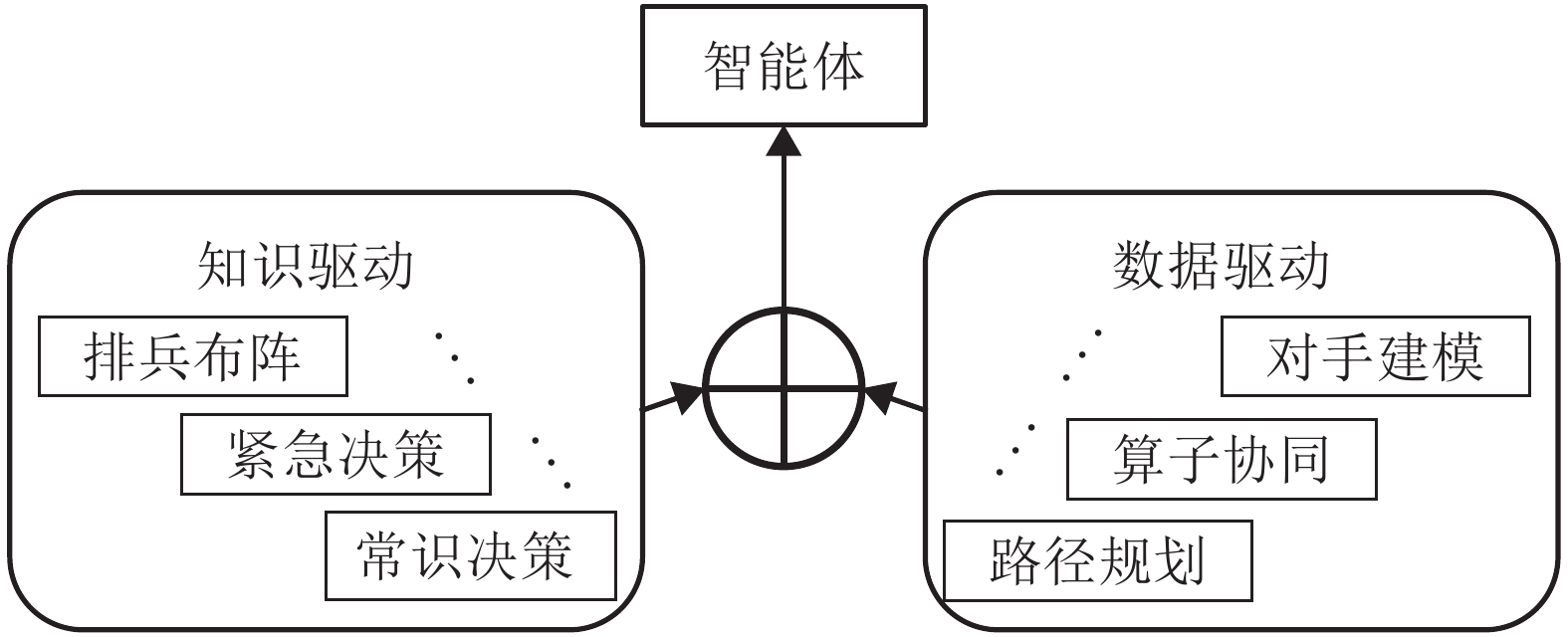
图 6 知识与数据驱动“主从融合”框架
Fig. 6 Principal and subordinate fusion framework of knowledge and data driven
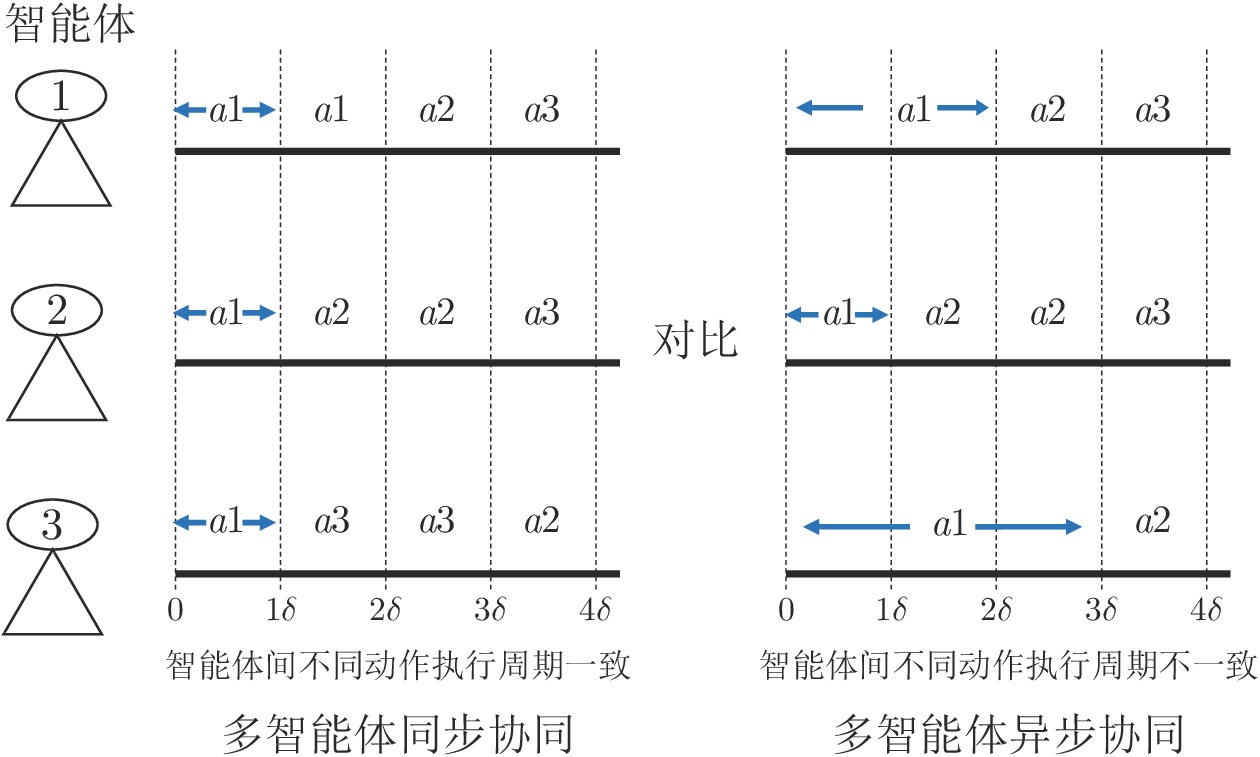
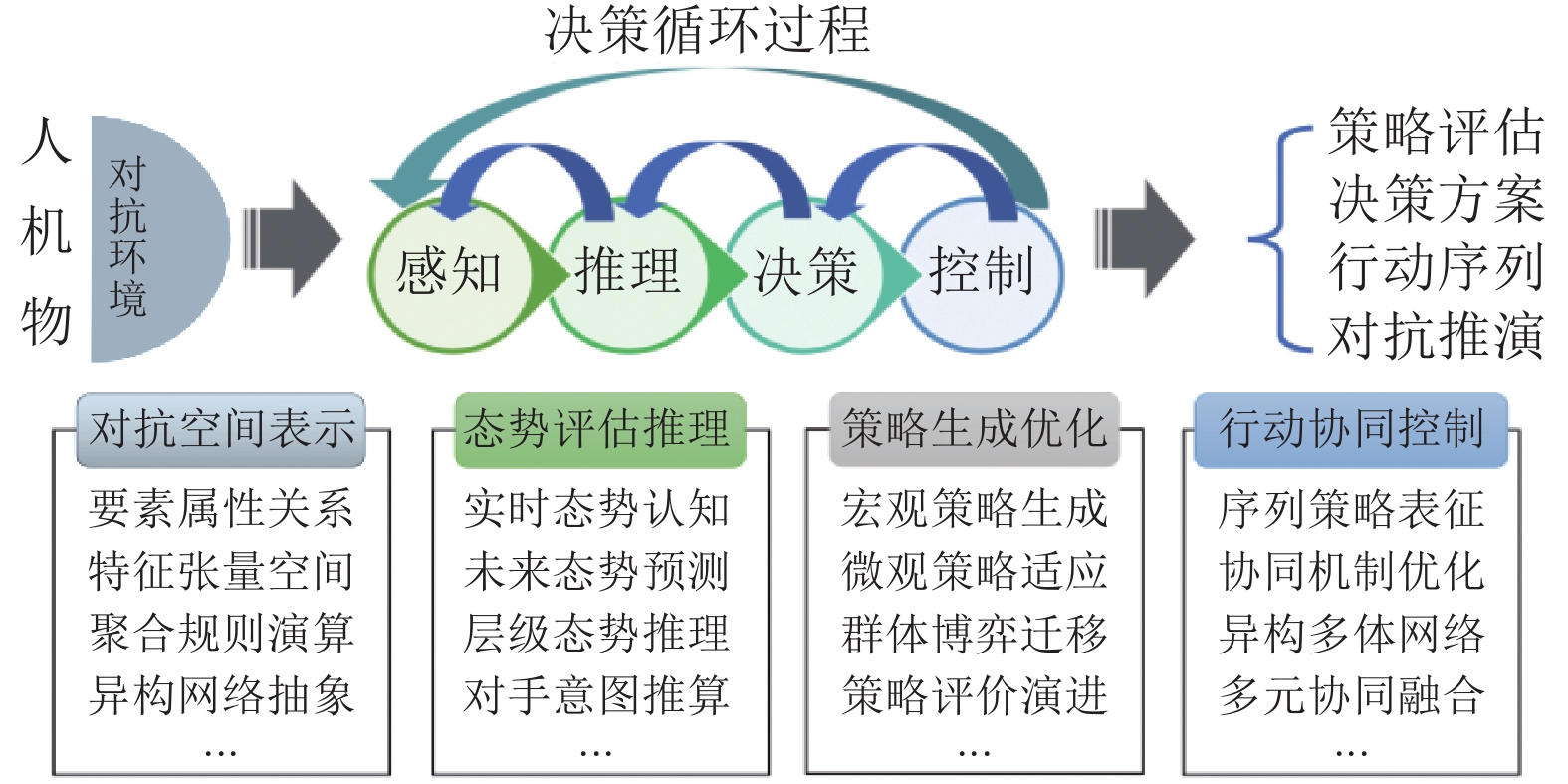
图 10 兵棋推演中的异步协同与同步协同对比
Fig. 10 Comparison between asynchronous cooperation and synchronous cooperation in wargame
表 1 对决策带来挑战的代表性因素
Table 1 Representative factors of challenge decision-making
游戏 雅达利 围棋 德州扑克 星际争霸 兵棋推演 不完美信息博弈 √ × √ √ √ 长时决策 √ √ × √ √ 策略非传递性 × √ √ √ √ 智能体协作 × × × √ √ 非对称环境 × × × × √ 随机性与高风险 × × × × √  下载: 导出CSV
下载: 导出CSV
-
[1] Campbell M, Hoane A J Jr, Hsu F H. Deep blue. Artificial Intelligence, 2002, 134(1-2): 57-83 doi: 10.1016/S0004-3702(01)00129-1 [2] Silver D, Huang A, Maddison C J, Guez A, Sifre L, van den Driessche G, et al. Mastering the game of Go with deep neural networks and tree search. Nature, 2016, 529(7587): 484-489 doi: 10.1038/nature16961 [3] Brown N, Sandholm T. Superhuman AI for heads-up no-limit poker: Libratus beats top professionals. Science, 2018, 359(6374): 418-424 doi: 10.1126/science.aao1733 [4] Vinyals O, Babuschkin I, Czarnecki W M, Mathieu M, Dudzik A, Chung J, et al. Grandmaster level in StarCraft II using multi-agent reinforcement learning. Nature, 2019, 575(7782): 350-354 doi: 10.1038/s41586-019-1724-z [5] Ye D H, Chen G B, Zhang W, Chen S, Yuan B, Liu B, et al. Towards playing full MOBA games with deep reinforcement learning. In: Proceedings of the Advances in Neural Information Processing Systems 33. Virtual Event: MIT Press, 2020. [6] 胡晓峰, 贺筱媛, 陶九阳. AlphaGo的突破与兵棋推演的挑战. 科技导报, 2017, 35(21): 49-60Hu Xiao-Feng, He Xiao-Yuan, Tao Jiu-Yang. AlphaGo's breakthrough and challenges of wargaming. Science & Technology Review, 2017, 35(21): 49-60 [7] 胡晓峰, 齐大伟. 智能化兵棋系统: 下一代需要改变的是什么. 系统仿真学报, 2021, 33(9): 1997-2009Hu Xiao-Feng, Qi Da-Wei. Intelligent wargaming system: Change needed by next generation need to be changed. Journal of System Simulation, 2021, 33(9): 1997-2009 [8] 吴琳, 胡晓峰, 陶九阳, 贺筱媛. 面向智能成长的兵棋推演生态系统. 系统仿真学报, 2021, 33(9): 2048-2058Wu Lin, Hu Xiao-Feng, Tao Jiu-Yang, He Xiao-Yuan. Wargaming eco-system for intelligence growing. Journal of System Simulation, 2021, 33(9): 2048-2058 [9] (徐佳乐, 张海东, 赵东海, 倪晚成. 基于卷积神经网络的陆战兵棋战术机动策略学习. 系统仿真学报, 2022, 34(10): 2181-2193.)Xu Jia-Le, Zhang Hai-Dong, Zhao Dong-Hai, Ni Wan-Cheng. Tactical maneuver strategy learning from land wargame replay based on convolutional neural network. Journal of System Simulation, 2022, 34(10): 2181-2193. [10] Moy G, Shekh S. The application of AlphaZero to wargaming. In: Proceedings of the 32nd Australasian Joint Conference on Artificial Intelligence. Adelaide, Australia: 2019. 3−14 [11] Wu K, Liu M, Cui P, Zhang Y. A training model of wargaming based on imitation learning and deep reinforcement learning. In: Proceedings of the Chinese Intelligent Systems Conference. Beijing, China: 2022. 786−795 [12] 胡艮胜, 张倩倩, 马朝忠. 兵棋推演系统中的异常数据挖掘方法. 信息工程大学学报, 2020, 21(3): 373-377 doi: 10.3969/j.issn.1671-0673.2020.03.019Hu Gen-Sheng, Zhang Qian-Qian, Ma Chao-Zhong. Outlier data mining of the war game system. Journal of Information Engineering University, 2020, 21(3): 373-377 doi: 10.3969/j.issn.1671-0673.2020.03.019 [13] (张锦明. 运用栅格矩阵建立兵棋地图的地形属性. 系统仿真学报, 2016, 28(8): 1748-1756.) doi: 10.3969/j.issn.1673-3819.2018.05.016Zhang Jin-Ming. Using raster lattices to build terrain attribute of wargame map. Journal of System Simulation, 2016, 28(8): 1748-1756. doi: 10.3969/j.issn.1673-3819.2018.05.016 [14] Chen L, Liang X, Feng Y, Zhang L, Yang J, Liu Z. Online intention recognition with incomplete information based on a weighted contrastive predictive coding model in wargame. IEEE Transaction on Neural Networks and Learning Systems. 2022, DOI: 10.1109/TNNLS.2022.3144171 [15] 王桂起, 刘辉, 朱宁. 兵棋技术综述. 兵工自动化, 2012, 31(8): 38-41, 45 doi: 10.3969/j.issn.1006-1576.2012.08.012Wang Gui-Qi, Liu Hui, Zhu Ning. A survey of war games technology. Ordnance Industry Automation, 2012, 31(8): 38-41, 45 doi: 10.3969/j.issn.1006-1576.2012.08.012 [16] 彭春光, 赵鑫业, 刘宝宏, 黄柯棣. 兵棋推演技术综述. 第 14 届系统仿真技术及其应用学术会议. 合肥, 中国: 2009. 366−370Peng Chun-Guang, Zhao Xin-Ye, Liu Bao-Hong, Huang Ke-Di. The technology of wargaming: An overview. In: Proceedings of the 14th Chinese Conference on System Simulation Technology & Application. Hefei, China: 2009. 366−370 [17] 曹占广, 陶帅, 胡晓峰, 何吕龙. 国外兵棋推演及系统研究进展. 系统仿真学报, 2021, 33(9): 2059-2065Cao Zhan-Guang, Tao Shuai, Hu Xiao-Feng, He Lü-Long. Abroad wargaming deduction and system research. Journal of System Simulation, 2021, 33(9): 2059-2065 [18] 司光亚, 王艳正. 新一代大型计算机兵棋系统面临的挑战与思考. 系统仿真学报, 2021, 33(9): 2010-2016Si Guang-Ya, Wang Yan-Zheng. Challenges and reflection on next-generation large-scale computer wargame system. Journal of System Simulation, 2021, 33(9): 2010-2016 [19] Ganzfried S, Sandholm T. Game theory-based opponent modeling in large imperfect-information games. In: Proceedings of the 10th International Conference on Autonomous Agents and Multi-agent Systems. Taipei, China: 2011. 533−540 [20] Littman M L. Algorithms for Sequential Decision Making [Ph.D. dissertation], Brown University, USA, 1996 [21] Nieves N P, Yang Y D, Slumbers O, Mguni D H, Wen Y, Wang J. Modelling behavioural diversity for learning in open-ended games. In: Proceedings of the 38th International Conference on Machine Learning. Vienna, Austria: 2021. 8514−8524 [22] Jaderberg M, Czarnecki W M, Dunning I, Marris L, Lever G, Castañeda A G, et al. Human-level performance in 3D multiplayer games with population-based reinforcement learning. Science, 2019, 364(6443): 859-865 doi: 10.1109/TVT.2021.3096928 [23] Baker B, Kanitscheider I, Markov T M, Wu Y, Powell G, McGrew B, et al. Emergent tool use from multi-agent autocurricula. In: Proceedings of the 8th International Conference on Learning Representations. Addis Ababa, Ethiopia: 2020. [24] Liu I J, Jain U, Yeh R A, Schwing A G. Cooperative exploration for multi-agent deep reinforcement learning. In: Proceedings of the 38th International Conference on Machine Learning. Vienna, Austria: 2021. 6826−6836 [25] 周志杰, 曹友, 胡昌华, 唐帅文, 张春潮, 王杰. 基于规则的建模方法的可解释性及其发展. 自动化学报, 2021, 47(6): 1201-1216Zhou Zhi-Jie, Cao You, Hu Chang-Hua, Tang Shuai-Wen, Zhang Chun-Chao, Wang Jie. The interpretability of rule-based modeling approach and its development. Acta Automatica Sinica, 2021, 47(6): 1201-1216 [26] Révay M, Líška M. OODA loop in command & control systems. In: Proceedings of the Communication and Information Technologies. Vysoke Tatry, Slovakia: 2017. [27] IEEE Transactions on Computational Intelligence and AI in Games, 2017, 9(3): 227-238 doi: 10.1109/TCIAIG.2016.2543661 [28] Najam-ul-lslam M, Zahra F T, Jafri A R, Shah R, Hassan M u, Rashid M. Auto implementation of parallel hardware architecture for Aho-Corasick algorithm. Design Automation for Embedded System, 2022, 26: 29-53 [29] 崔文华, 李东, 唐宇波, 柳少军. 基于深度强化学习的兵棋推演决策方法框架. 国防科技, 2020, 41(2): 113-121Cui Wen-Hua, Li Dong, Tang Yu-Bo, Liu Shao-Jun. Framework of wargaming decision-making methods based on deep reinforcement learning. National Defense Technology, 2020, 41(2): 113-121 [30] 李琛, 黄炎焱, 张永亮, 陈天德. Actor-Critic框架下的多智能体决策方法及其在兵棋上的应用. 系统工程与电子技术, 2021, 43(3): 755-762 doi: 10.12305/j.issn.1001-506X.2021.03.20Li Chen, Huang Yan-Yan, Zhang Yong-Liang, Chen Tian-De. Multi-agent decision-making method based on actor-critic framework and its application in wargame. Systems Engineering and Electronics, 2021, 43(3): 755-762 doi: 10.12305/j.issn.1001-506X.2021.03.20 [31] 张振, 黄炎焱, 张永亮, 陈天德. 基于近端策略优化的作战实体博弈对抗算法. 南京理工大学学报, 2021, 45(1): 77-83Zhang Zhen, Huang Yan-Yan, Zhang Yong-Liang, Chen Tian-De. Battle entity confrontation algorithm based on proximal policy optimization. Journal of Nanjing University of Science and Technology, 2021, 45(1): 77-83 [32] 秦超, 高晓光, 万开方. 深度卷积记忆网络时空数据模型. 自动化学报, 2020, 46(3): 451-462Qin Chao, Gao Xiao-Guang, Wan Kai-Fang. Deep spatio-temporal convolutional long-short memory network. Acta Automatica Sinica, 2020, 46(3): 451-462 [33] 陈伟宏, 安吉尧, 李仁发, 李万里. 深度学习认知计算综述. 自动化学报, 2017, 43(11): 1886-1897Chen Wei-Hong, An Ji-Yao, Li Ren-Fa, Li Wan-Li. Review on deep-learning-based cognitive computing. Acta Automatica Sinica, 2017, 43(11): 1886-1897 [34] Burda Y, Edwards H, Storkey A J, Klimov O. Exploration by random network distillation. In: Proceedings of the 7th International Conference on Learning Representations. New Orleans, USA: 2019. [35] Mnih V, Badia A P, Mirza M, Graves A, Harley T, Lillicrap T P, et al. Asynchronous methods for deep reinforcement learning. In: Proceedings of the 33rd International Conference on Machine Learning. New York, USA: 2016. 1928−1937 [36] Horgan D, Quan J, Budden D, Barth-Maron G, Hessel M, Van Hasselt H, et al. Distributed prioritized experience replay. In: Proceedings of the 6th International Conference on Learning Representations. Vancouver, Canada: 2018. [37] Espeholt L, Soyer H, Munos R, Simonyan K, Mnih V, Ward T, et al. IMPALA: Scalable distributed deep-RL with importance weighted actor-learner architectures. In: Proceedings of the 35th International Conference on Machine Learning. Stockholm, Sweden: 2018. 1407−1416 [38] Jaderberg M, Czarnecki W M, Dunning I, Marris L, Lever G, Castañeda A G, et al. Human-level performance in 3D multiplayer games with population-based reinforcement learning. Science, 2019, 364(6443): 859-865 doi: 10.1126/science.aau6249 [39] Espeholt L, Marinier R, Stanczyk P, Wang K, Michalski M. SEED RL: Scalable and efficient deep-RL with accelerated central inference. In: Proceedings of the 8th International Conference on Learning Representations. Addis Ababa, Ethiopia: 2020. [40] Moritz P, Nishihara R, Wang S, Tumanov A, Liaw R, Liang E, et al. Ray: A distributed framework for emerging AI applications. In: Proceedings of the 13th USENIX Conference on Operating Systems Design and Implementation. Carlsbad, USA: 2018. 561−577 [41] 蒲志强, 易建强, 刘振, 丘腾海, 孙金林, 李非墨. 知识和数据协同驱动的群体智能决策方法研究综述. 自动化学报, 2022, 48(3): 627−643 doi: 10.16383/j.aas.c210118Pu Zhi-Qiang, Yi Jian-Qiang, Liu Zhen, Qiu Teng-Hai, Sun Jin-Lin, Li Fei-Mo. Knowledge-based and data-driven integrating methodologies for collective intelligence decision making: A survey. Acta Automatica Sinica, 2022, 48(3): 627−643 doi: 10.16383/j.aas.c210118 [42] Rueden L V, Mayer S, Beckh K, Georgiev B, Giesselbach S, Heese R, et al. Informed machine learning – a taxonomy and survey of integrating prior knowledge into learning systems. IEEE Transactions on Knowledge and Data Engineering, DOI: 10.1109/TKDE.2021.3079836, 2021, 5: 1−19 [43] Hartmann G, Shiller Z, Azaria A. Deep reinforcement learning for time optimal velocity control using prior knowledge. In: Proceedings of the 31st International Conference on Tools With Artificial Intelligence. Portland, USA: 2019. 186−193 [44] Zhang P, Hao J Y, Wang W X, Tang H Y, Ma Y, Duan Y H, et al. KoGuN: Accelerating deep reinforcement learning via integrating human suboptimal knowledge. In: Proceedings of the 29th International Joint Conference on Artificial Intelligence. Virtual Event: 2020. 2291−2297 [45] 黄凯奇, 兴军亮, 张俊格, 倪晚成, 徐博. 人机对抗智能技术. 中国科学: 信息科学, 2020, 50(4): 540-550 doi: 10.1360/N112019-00048Huang Kai-Qi, Xing Jun-Liang, Zhang Jun-Ge, Ni Wan-Cheng, Xu Bo. Intelligent technologies of human-computer gaming. Scientia Sinica Informations, 2020, 50(4): 540-550 doi: 10.1360/N112019-00048 [46] Elo A E. The Rating of Chess Players, Past and Present. London: Batsford, 1978. [47] Herbrich R, Minka T, Graepel T. TrueSkill (TM): A Bayesian skill rating system. In: Proceedings of the 19th International Conference on Neural Information Processing Systems. Vancou-ver, Canada: 2006. 569−576 [48] Balduzzi D, Tuyls K, Perolat J, Graepel T. Re-evaluating evaluation. In: Proceedings of the 32nd International Conference on Neural Information Processing Systems. Montréal, Canada: 2018. 3272−3283 [49] Omidshafiei S, Papadimitriou C, Piliouras G, Tuyls K, Rowland M, Lespiau J B, et al. α-rank: Multi-agent evaluation by evolution. Scientific Reports, 2019, 9(1): Article No. 9937 doi: 10.1038/s41598-019-45619-9 [50] 唐宇波, 沈弼龙, 师磊, 易星. 下一代兵棋系统模型引擎设计问题研究. 系统仿真学报, 2021, 33(9): 2025-2036Tang Yu-Bo, Shen Bi-Long, Shi Lei, Yi Xing. Research on the issues of next generation wargame system model engine. Journal of System Simulation, 2021, 33(9): 2025-2036 [51] Ji S, Pan S, Cambria E, Marttinen P, Yu P. A survey on knowledge graphs: Representation, acquisition, and applications. IEEE Transactions on Neural Networks and Learning Systems, 2022, 33(2): 494-514 doi: 10.1145/154421.154422 [52] Wang Z, Zhang J W, Feng J L, Chen Z. Knowledge graph embedding by translating on hyperplanes. In: Proceedings of the 28th AAAI Conference on Artificial Intelligence. Québec, Can-ada: 2014. 1112−1119 [53] 王保魁, 吴琳, 胡晓峰, 贺筱媛, 郭圣明. 基于时序图的作战指挥行为知识表示学习方法. 系统工程与电子技术, 2020, 42(11): 2520-2528 doi: 10.3969/j.issn.1001-506X.2020.11.14Wang Bao-Kui, Wu Lin, Hu Xiao-Feng, He Xiao-Yuan, Guo Sheng-Ming. Operations command behavior knowledge representation learning method based on sequential graph. Systems Engineering and Electronics, 2020, 42(11): 2520-2528 doi: 10.3969/j.issn.1001-506X.2020.11.14 [54] 刘嵩, 武志强, 游雄, 张欣, 王雪峰. 基于兵棋推演的综合战场态势多尺度表达. 测绘科学技术学报, 2012, 29(5): 382-385, 390 doi: 10.3969/j.issn.1673-6338.2012.05.015Liu Song, Wu Zhi-Qiang, You Xiong, Zhang Xin, Wang Xue-Feng. Multi-scale expression of integrated battlefield situation based on wargaming. Journal of Geomatics Science and Technology, 2012, 29(5): 382-385, 390 doi: 10.3969/j.issn.1673-6338.2012.05.015 [55] 贺筱媛, 郭圣明, 吴琳, 李东, 许霄, 李丽. 面向智能化兵棋的认知行为建模方法研究. 系统仿真学报, 2021, 33(9): 2037-2047He Xiao-Yuan, Guo Sheng-Ming, Wu Lin, Li Dong, Xu Xiao, Li Li. Modeling research of cognition behavior for intelligent wargaming. Journal of System Simulation, 2021, 33(9): 2037-2047 [56] 朱丰, 胡晓峰, 吴琳, 贺筱媛, 吕学志, 廖鹰. 从态势认知走向态势智能认知. 系统仿真学报, 2018, 30(3): 761-771Zhu Feng, Hu Xiao-Feng, Wu Lin, He Xiao-Yuan, Lü Xue-Zhi, Liao Ying. From situation cognition stepped into situation intelligent cognition. Journal of System Simulation, 2018, 30(3): 761-771 [57] Heinrich J, Lanctot M, Silver D. Fictitious self-play in extensive-form games. In: Proceedings of the 32nd International Conference on Machine Learning. Lille, France: 2015. 805−813 [58] Adam L, Horcík R, Kasl T, Kroupa T. Double oracle algorithm for computing equilibria in continuous games. In: Proceedings of the 35th AAAI Conference on Artificial Intelligence. Virtual Event: 2021. 5070−5077 [59] Nguyen T T, Nguyen N D, Nahavandi S. Deep reinforcement learning for multiagent systems: A review of challenges, solutions, and applications. IEEE Transactions on Cybernetics, 2020, 50(9): 3826-3839 doi: 10.1109/TCYB.2020.2977374 [60] Zhang K Q, Yang Z R, Başar T. Multi-agent reinforcement learning: A selective overview of theories and algorithms. Hand-book of Reinforcement Learning and Control, 2021: 321−384 [61] 施伟, 冯旸赫, 程光权, 黄红蓝, 黄金才, 刘忠, 贺威. 基于深度强化学习的多机协同空战方法研究. 自动化学报, 2021, 47(7): 1610-1623Shi Wei, Feng Yang-He, Cheng Guang-Quan, Huang Hong-Lan, Huang Jin-Cai, Liu Zhong, He Wei. Research on multi-aircraft cooperative air combat method based on deep reinforcement learning. Acta Automatica Sinica, 2021, 47(7): 1610-1623 [62] 梁星星, 冯旸赫, 马扬, 程光权, 黄金才, 王琦, 周玉珍, 刘忠. 多Agent深度强化学习综述. 自动化学报, 2020, 46(12): 2537-2557Liang Xing-Xing, Feng Yang-He, Ma Yang, Cheng Guang-Quan, Huang Jin-Cai, Wang Qi, Zhou Yu-Zhen, Liu Zhong. Deep multi-agent reinforcement learning: A survey. Acta Automatica Sinica, 2020, 46(12): 2537-2557 [63] Yan D, Weng J, Huang S, Li C, Zhou Y, Su H, Zhu J. Deep reinforcement learning with credit assignment for combinatorial optimization. Pattern Recognition, 2022, 124: Artice No. 108466 [64] Lansdell B J, Prakash P R, Körding K P. Learning to solve the credit assignment problem. In: Proceedings of the 8th International Conference on Learning Representations. Addis Ababa, Ethiopia: 2020. [65] 孙长银, 穆朝絮. 多智能体深度强化学习的若干关键科学问题. 自动化学报, 2020, 46(7): 1301-1312Sun Chang-Yin, Mu Chao-Xu. Important scientific problems of multi-agent deep reinforcement learning. Acta Automatica Sinica, 2020, 46(7): 1301-1312 [66] Sunehag P, Lever G, Gruslys A, Czarnecki W M, Zambaldi V, Jaderberg M, et al. Value-decomposition networks for cooperative multi-agent learning based on team reward. In: Proceedings of the 17th International Conference on Autonomous Agents and Multi-agent Systems. Stockholm, Sweden: 2018. 2085−2087 [67] Rashid T, Samvelyan M, De Witt C S, Farquhar G, Foerster J N, Whiteson S. QMIX: Monotonic value function factorisation for deep multi-agent reinforcement learning. In: Proceedings of the 35th International Conference on Machine Learning. Stock-holm, Sweden: 2018. 4292−4301 [68] Son K, Kim D, Kang W J, Hostallero D, Yi Y. QTRAN: Learning to factorize with transformation for cooperative multi-agent reinforcement learning. In: Proceedings of the 36th International Conference on Machine Learning. Long Beach, USA: 2019. 5887−5896 [69] Foerster J N, Farquhar G, Afouras T, Nardelli N, Whiteson S. Counterfactual multi-agent policy gradients. In: Proceedings of the 32nd AAAI Conference on Artificial Intelligence. New Orleans, USA: 2018. 2974−2982 [70] Nguyen D T, Kumar A, Lau H C. Credit assignment for collective multi-agent RL with global rewards. In: Proceedings of the 32nd International Conference on Neural Information Processing Systems. Montréal, Canada: 2018. 8113−8124 [71] Silver D, Hubert T, Schrittwieser J, Antonoglou I, Lai M, Guez A, et al. A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play. Science, 2018, 362(6419): 1140-1144 doi: 10.1126/science.aar6404 [72] Yu Y. Towards sample efficient reinforcement learning. In: Proceedings of the 27th International Joint Conference on Artificial Intelligence. Stockholm, Sweden: 2018. 5739−5743 [73] Ecoffet A, Huizinga J, Lehman J, Stanley K O, Clune J. First return, then explore. Nature, 2021, 590(7847): 580-586 doi: 10.1038/s41586-020-03157-9 [74] Jin C, Krishnamurthy A, Simchowitz M, Yu T C. Reward-free exploration for reinforcement learning. In: Proceedings of the 37th International Conference on Machine Learning. Virtual Event: 2020. 4870−4879 [75] Mahajan A, Rashid T, Samvelyan M, Whiteson S. MAVEN: Multi-agent variational exploration. In: Proceedings of the 33rd International Conference on Neural Information Processing Systems. Vancouver, Canada: 2019. Article No. 684 [76] Yang Y D, Wen Y, Chen L H, Wang J, Shao K, Mguni D, et al. Multi-agent determinantal Q-learning. In: Proce-edings of the 37th International Conference on Machine Learning. Virtual Event: 2020. 10757−10766 [77] Wang T H, Dong H, Lesser V, Zhang C J. ROMA: Role-oriented multi-agent reinforcement learning. In: Proceedings of the 37th International Conference on Machine Learning. Virtual Event: 2020. 9876−9886 [78] 张钹, 朱军, 苏航. 迈向第三代人工智能. 中国科学: 信息科学, 2020, 50(9): 1281-1302 doi: 10.1360/SSI-2020-0204Zhang Bo, Zhu Jun, Su Hang. Toward the third generation of artificial intelligence. Scientia Sinca Informationis, 2020, 50(9): 1281-1302 doi: 10.1360/SSI-2020-0204 [79] 王保剑, 胡大裟, 蒋玉明. 改进A*算法在路径规划中的应用. 计算机工程与应用, 2021, 57(12): 243-247 doi: 10.3778/j.issn.1002-8331.2008-0099Wand Bao-Jian, Hu Da-Sha, Jiang Yu-Ming. Application of improved A* algorithm in path planning. Computer Engineering and Applications, 2021, 57(12): 243-247 doi: 10.3778/j.issn.1002-8331.2008-0099 [80] 张可, 郝文宁, 史路荣, 余晓晗, 邵天浩. 基于级联模糊系统的兵棋进攻关键点推理. 控制工程, 2021, 28(7): 1366-1374Zhang Ke, Hao Wen-Ning, Shi Lu-Rong, Yu Xiao-Han, Shao Tian-Hao. Inference of key points of attack in wargame based on cascaded fuzzy system. Control Engineering of China, 2021, 28(7): 1366-1374 [81] 邢思远, 倪晚成, 张海东, 闫科. 基于兵棋复盘数据的武器效用挖掘. 指挥与控制学报, 2020, 6(2): 132-140 doi: 10.3969/j.issn.2096-0204.2020.02.0132Xing Si-Yuan, Ni Wan-Cheng, Zhang Hai-Dong, Yan Ke. Mining of weapon utility based on the replay data of wargame. Journal of Command and Control, 2020, 6(2): 132-140 doi: 10.3969/j.issn.2096-0204.2020.02.0132 [82] 金哲豪, 刘安东, 俞立. 基于GPR和深度强化学习的分层人机协作控制. 自动化学报, 2020, 46: 1-11Jin Zhe-Hao, Liu An-Dong, Yu Li. Hierarchical human-robot cooperative control based on GPR and DRL. Acta Automatica Sinica, 2020, 46: 1-11 [83] 徐磊, 杨勇. 基于兵棋推演的分队战斗行动方案评估. 火力与指挥控制, 2021, 46(4): 88-92, 98 doi: 10.3969/j.issn.1002-0640.2021.04.016Xu Lei, Yang Yong. Research on evaluation of unit combat action plan based on wargaming. Fire Control & Command Control, 2021, 46(4): 88-92, 98 doi: 10.3969/j.issn.1002-0640.2021.04.016 [84] 李云龙, 张艳伟, 王增臣. 联合作战方案推演评估技术框架. 指挥信息系统与技术, 2020, 11(4): 78-83Li Yun-Long, Zhang Yan-Wei, Wang Zeng-Chen. Technical framework of joint operation scheme deduction and evaluation. Command Information System and Technology, 2020, 11(4): 78-83 [85] Myerson R B. Game Theory. Cambridge: Harvard University Press, 2013. [86] Weibull J W. Evolutionary Game Theory. Cambridge: MIT Press, 1997. [87] Roughgarden T. Algorithmic game theory. Communications of the ACM, 2010, 53(7): 78-86 doi: 10.1145/1785414.1785439 [88] Chalkiadakis G, Elkind E, Wooldridge M. Cooperative game theory: Basic concepts and computational challenges. IEEE Intelligent Systems, 2012, 27(3): 86-90 doi: 10.1109/MIS.2012.47 [89] 周雷, 尹奇跃, 黄凯奇. 人机对抗中的博弈学习方法. 计算机学报, DOI: 10.11897/SP.J.1016.2022.01859Zhou Lei, Yin Qi-Yue, Huang Kai-Qi. Game-theoretic learning in human-computer gaming. Chinese Journal of Computers, DOI: 10.11897/SP.J.1016.2022.01859 [90] Lanctot M, Zambaldi V, Gruslys A, Lazaridou A, Tuyls K, Pérolat J, et al. A unified game-theoretic approach to multi-agent reinforcement learning. In: Proceedings of the 31st Conference on Neural Information Processing Systems. Long Beach, USA: 2017. 4190−4203 [91] Brown N, Lerer A, Gross S, Sandholm T. Deep counterfactual regret minimization. In: Proceedings of the 36th International Conference on Machine Learning. Long Beach, USA: 2019. 793−802 [92] Qiu X P, Sun T X, Xu Y G, Shao Y F, Dai N, Huang X J. Pre-trained models for natural language processing: A survey. Science China Technological Sciences, 2020, 63(10): 1872-1897 doi: 10.1007/s11431-020-1647-3 [93] Zhang Z Y, Han X, Zhou H, Ke P, Gu Y X, Ye D M, et al. CPM: A large-scale generative Chinese Pre-trained language model. AI Open, 2021, 2: 93-99 doi: 10.1016/j.aiopen.2021.07.001 [94] Brown T B, Mann B, Ryder N, Subbiah M, Kaplan J, Dhariwal P, et al. Language models are few-shot learners. In: Proceedings of the 34th Conference on Neural Information Processing Systems. Vancouver, Canada: MIT Press, 2020. [95] Meng D Y, Zhao Q, Jiang L. A theoretical understanding of self-paced learning. Information Sciences, 2017, 414: 319-328 doi: 10.1016/j.ins.2017.05.043 [96] Singh P, Verma V K, Mazumder P, Carin L, Rai P. Calibrating CNNs for lifelong learning. In: Proceedings of the 34th Conference on Neural Information Processing Systems. Vancouver, Canada: 2020. [97] Cheng W, Yin Q Y, Zhang J G. Opponent strategy recognition in real time strategy game using deep feature fusion neural network. In: Proceedings of the 5th International Conference on Computer and Communication Systems. Shanghai, China: 2020. 134−137 [98] Samvelyan M, Rashid T, De Witt C S, Farquhar G, Nardelli N, Rudner T G J, et al. The StarCraft multi-agent challenge. In: Proceedings of the 18th International Conference on Auto-nomous Agents and Multi-agent Systems. Montreal, Canada: 2019. 2186−2188 [99] Tang Z T, Shao K, Zhu Y H, Li D, Zhao D B, Huang T W. A review of computational intelligence for StarCraft AI. In: Proceedings of the IEEE Symposium Series on Computational Intelligence. Bangalore, India: 2018. 1167−1173 [100] Christianos F, Schäfer L, Albrecht S V. Shared experience actor-critic for multi-agent reinforcement learning. In: Proceedings of the Advances in Neural Information Processing Systems 33. Virtual Event: 2020. [101] Jaques N, Lazaridou A, Hughes E, Gulcehre C, Ortega P A, Strouse D J, et al. Social influence as intrinsic motivation for multi-agent deep reinforcement learning. In: Proceedings of the 36th International Conference on Machine Learning. Long Beach, USA: 2019. 3040−3049 -

 下载:
下载:

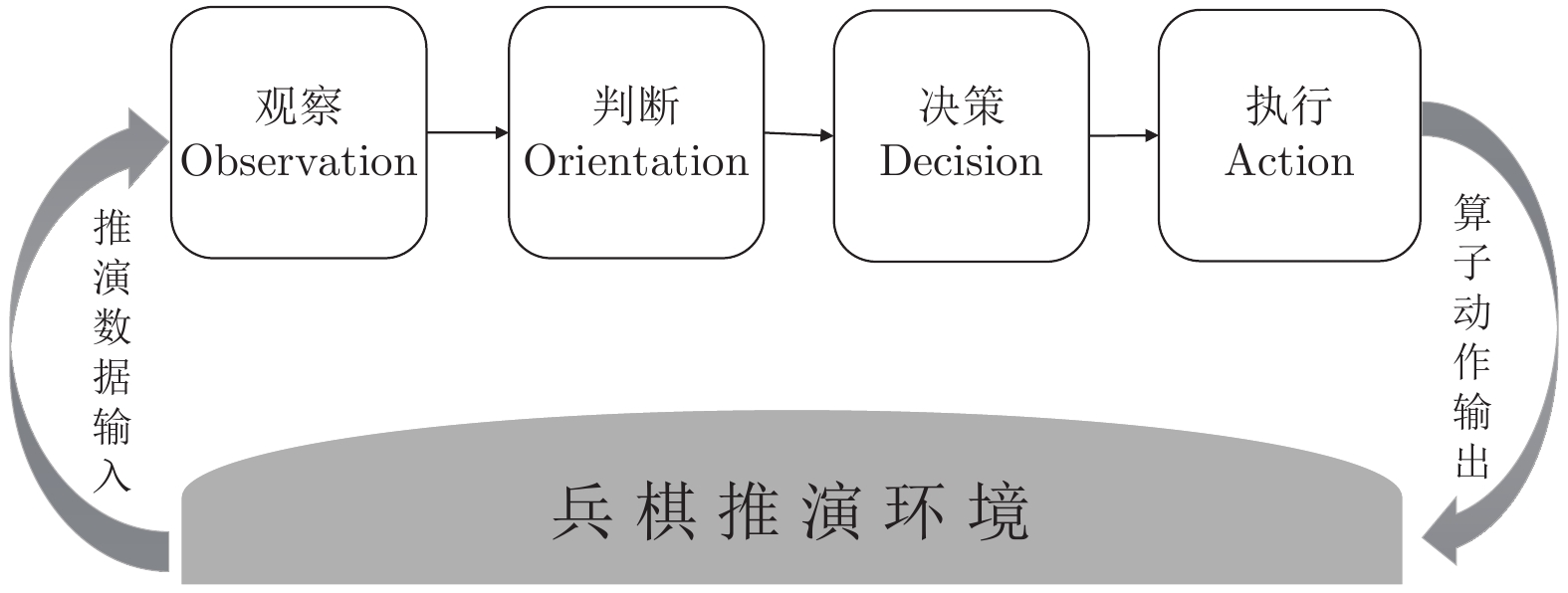
图(13) / 表(1)
计量
- 文章访问数: 8036
- HTML全文浏览量: 5066
- PDF下载量: 1680
- 被引次数: 0
