

-
摘要:
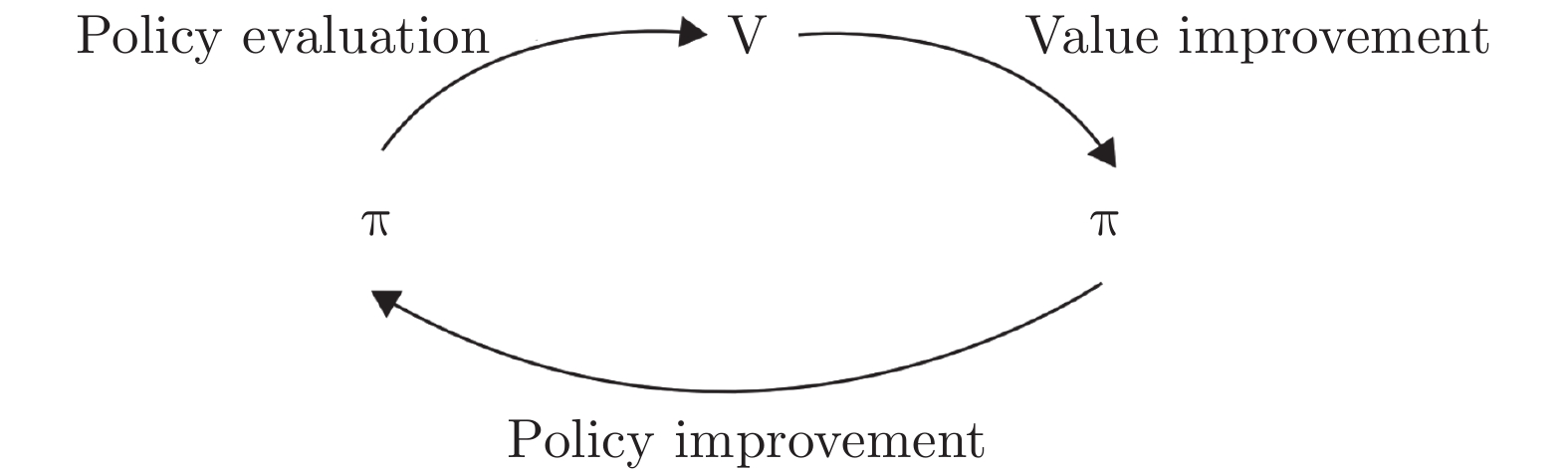
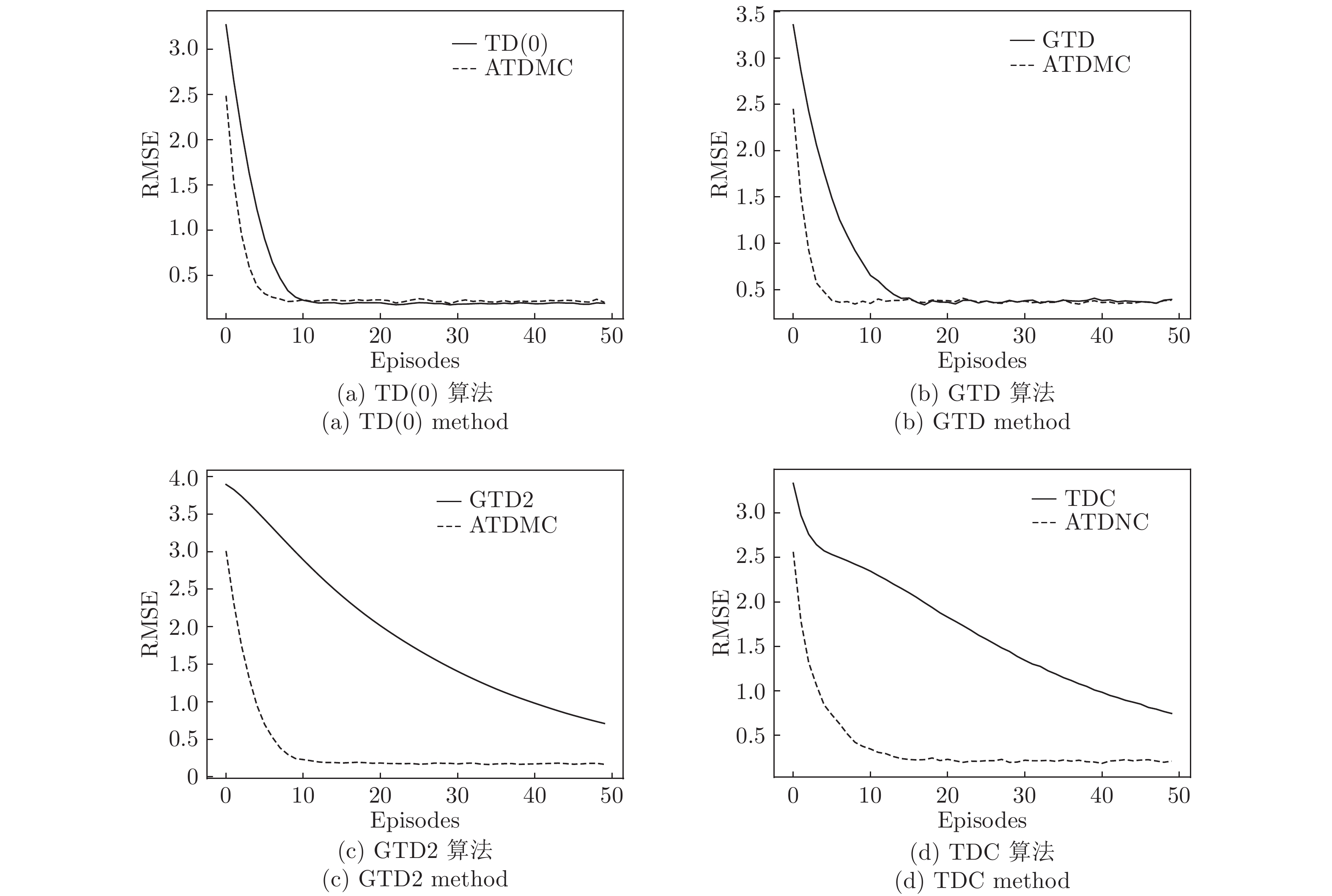
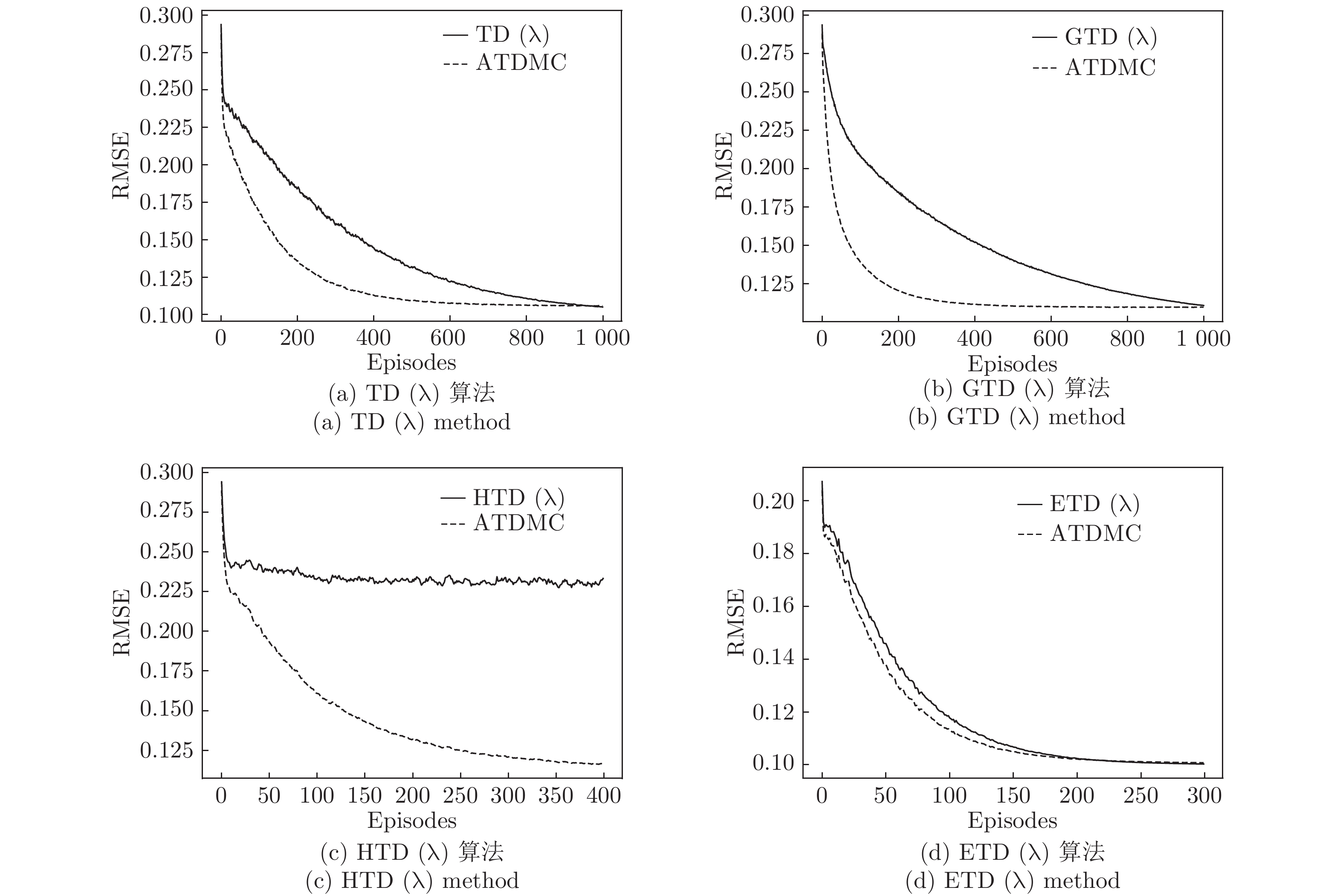
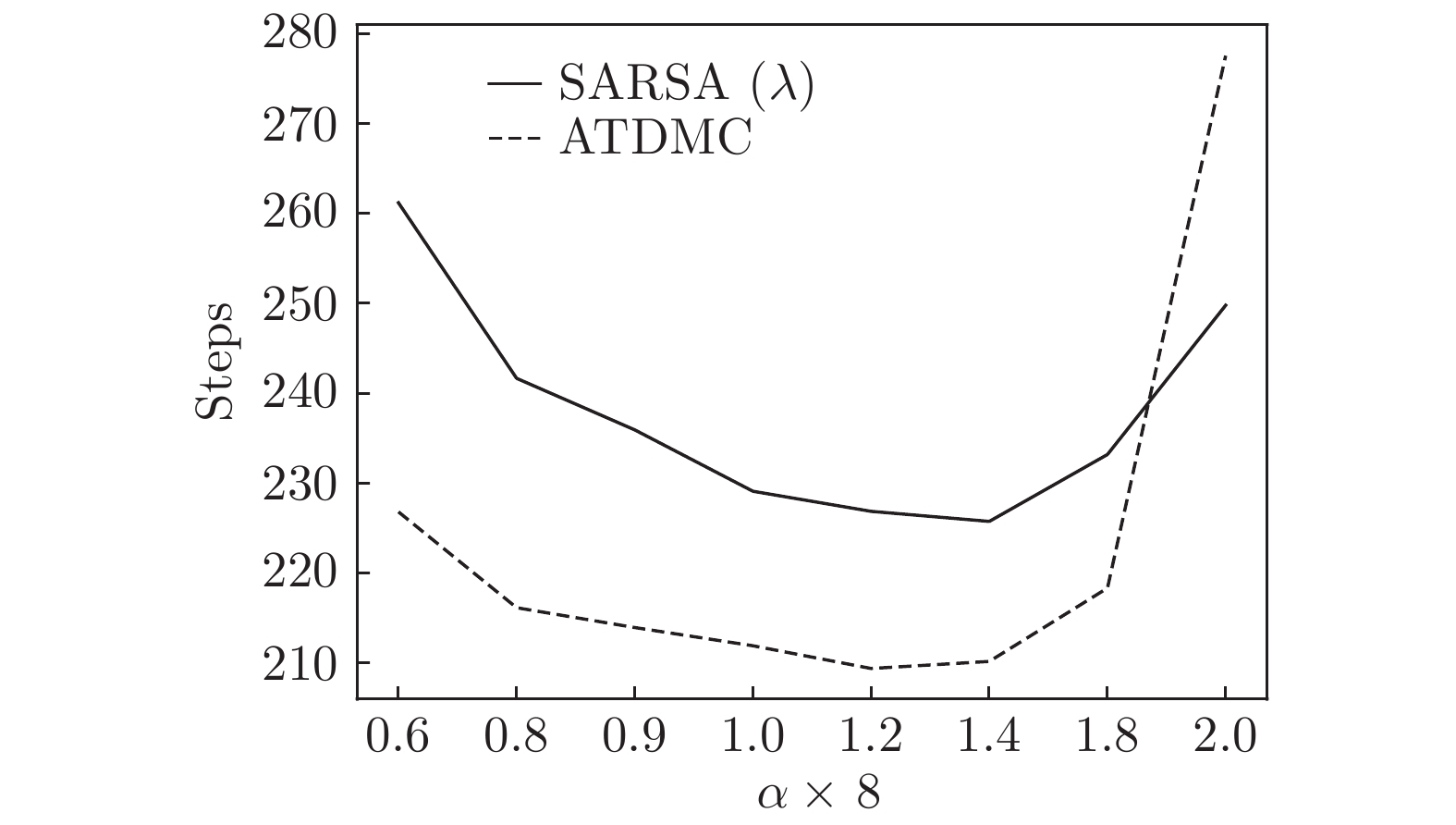
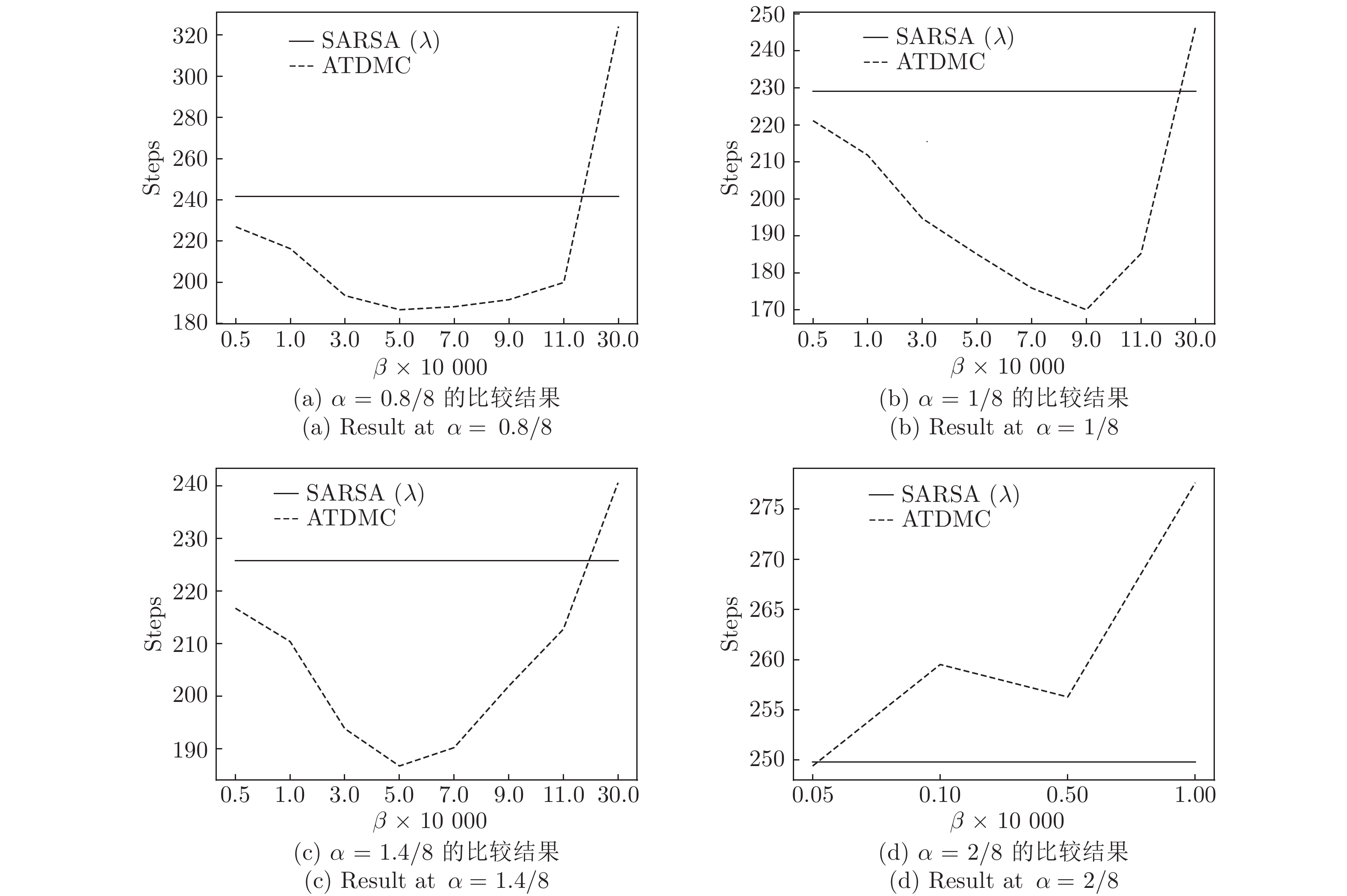
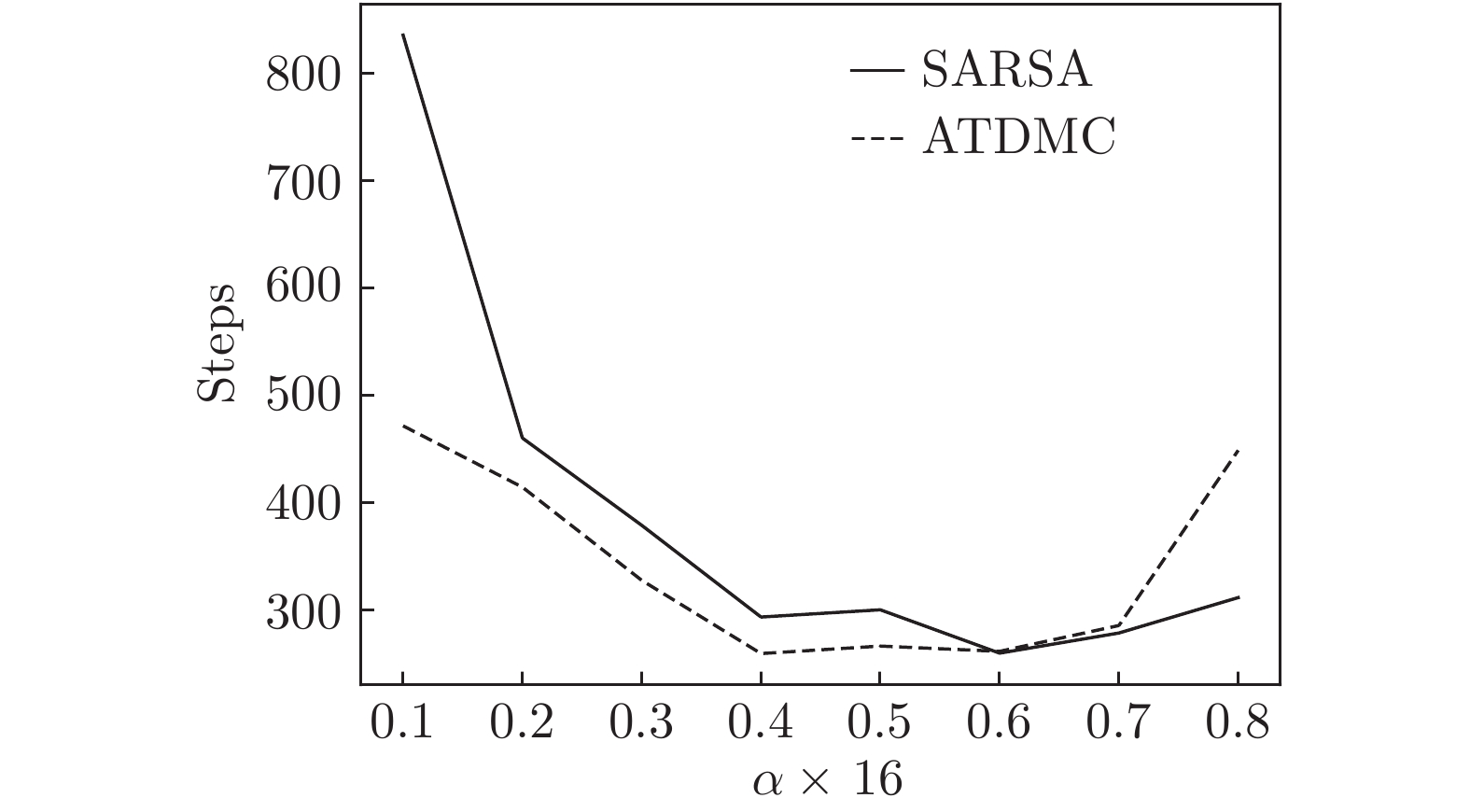
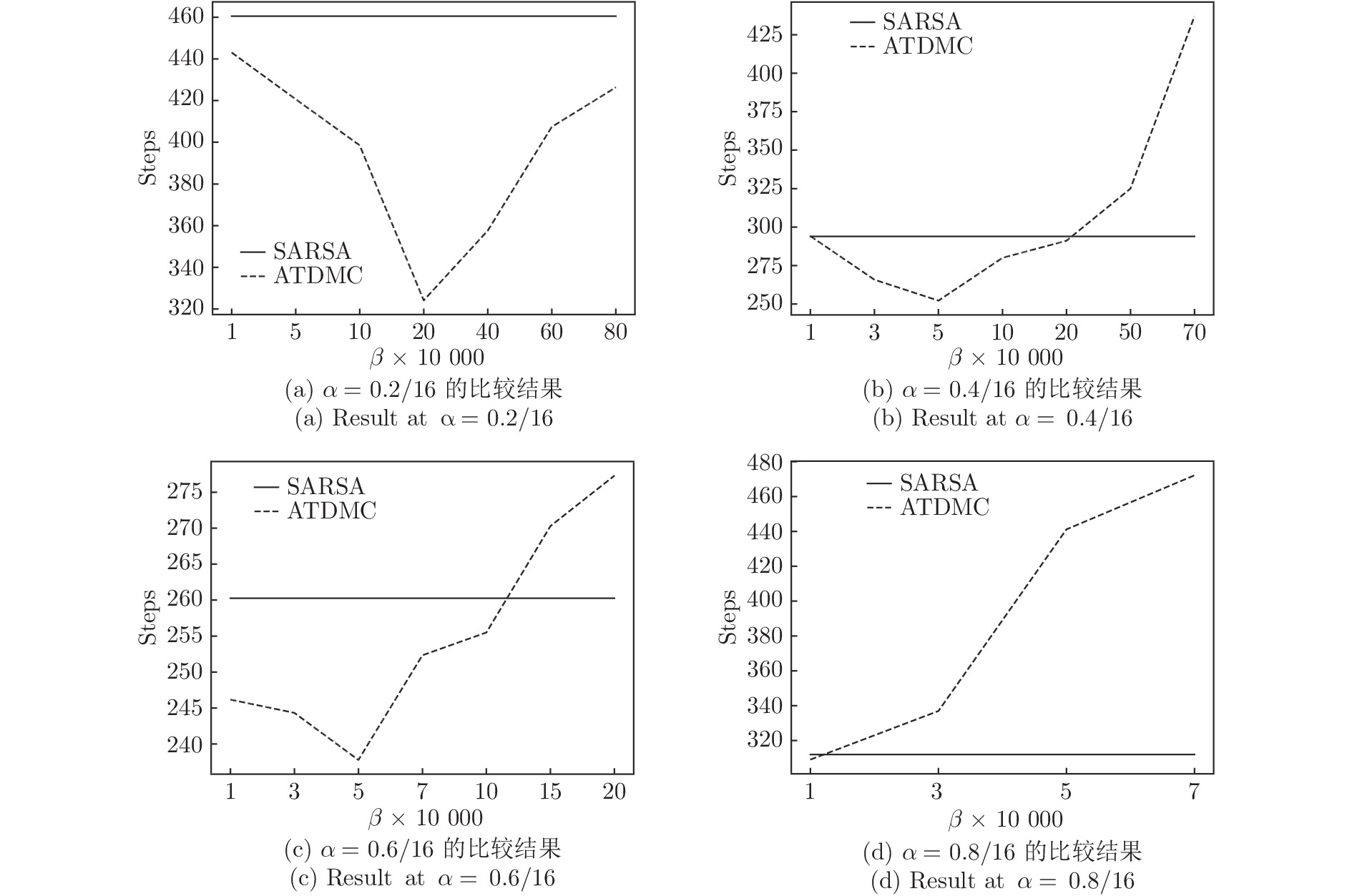
时间差分算法(Temporal difference methods, TD)是一类模型无关的强化学习算法. 该算法拥有较低的方差和可以在线(On-line)学习的优点, 得到了广泛的应用. 但对于一种给定的TD算法, 往往只能通过调整步长参数或其他超参数来加速收敛, 这也就造成了加速TD算法收敛的方法匮乏. 针对此问题提出了一种利用蒙特卡洛算法(Monte Carlo methods, MC)来加速TD算法收敛的方法(Accelerate TD by MC, ATDMC). 该方法不仅可以适用于绝大部分的TD算法, 而且不需要改变在线学习的方式. 为了证明方法的有效性, 分别在同策略(On-policy)评估、异策略(Off-policy)评估和控制(Control)三个方面进行了实验. 实验结果表明ATDMC方法可以有效地加速各类TD算法.
Abstract:Temporal difference methods (TD) methods are a class of model-free reinforcement learning methods. TD methods have been widely used, which have a low variance and can learn on-line. But for a given TD method, there is only one approach that adjusts the step size or other parameters to accelerate the convergence, which leads to a lack of methods to make it. To solve this problem, we introduce a method for accelerating TD methods based on Monte Carlo (MC) methods, which not only can be applied to most of the TD methods, but also do not need to change the way of on-line learning. In order to demonstrate the effectiveness of the method, experiments were carried out in the three aspects: the on-policy evaluation, off-policy evaluation and control. The experimental results show that the accelerate TD by MC (ATDMC) method can effectively accelerate TD methods.
1) 收稿日期 2019-03-07 录用日期 2019-08-22 Manuscript received March 7, 2019; accepted August 22, 2019 国家自然科学基金项目 (61772355, 61702055, 61502323, 61502329), 江苏省高等学校自然科学研究重大项目 (18KJA520011, 17KJA520004),吉林大学符号计算与知识工程教育部重点实验室资助项目 (93K172014K04, 93K172017K18),苏州市应用基础研究计划工业部分 (SYG201422) 资助 Supported by National Natural Science Foundation of China (61772355, 61702055, 61502323, 61502329), Jiangsu Province Natural Science Research University Major Projects (18KJA520011, 17KJA520004), Key Laboratory of Symbolic Computation and Knowledge Engineering of Ministry of Education, Jilin University (93K172014K04, 93K172017K18), Suzhou Industrial Application of Basic Research Program (SYG201422) 本文责任编委 魏庆来 Recommended by Associate Editor WEI Qing-Lai 1. 苏州大学计算机科学与技术学院 苏州 215006 2. 苏州大学江苏省计算机信息处理技术重点实验室 苏州 215006 3. 吉林大学符号计算与知识工程教育部重点实验室 长春 130012 4. 软件新技术与产业化协同创新中心 南京 210000 1. School of Computer Science and Technology, Soochow University, Suzhou 215006 2. Provincial Key Laboratory for Computer Information Processing Technology, Soochow University, Suzhou 215006 3. Key Laboratory of Symbolic Computation and Knowledge Engineering of Ministry of Education, Jilin University, Changchun 130012 4. Collaborative Innovation Center of Novel Software Technology and Industrialization, Nanjing 210000 -
[1] Sutton R S, Barto A G. Reinforcement Learning: An Introduction. Cambridge, MA: MIT Press, 2018. [2] 刘乃军, 鲁涛, 蔡莹皓, 王硕. 机器人操作技能学习方法综述. 自动化学报, 2019, 45(3): 458−470Liu Nai-Jun, Lu Tao, Cai Ying-Hao, Wang Shuo. A review of robot manipulation skills learning methods. Acta Automatica Sinica, 2019, 45(3): 458−470 [3] Polydoros A S, Nalpantidis L. Survey of model-based reinforcement learning: applications on robotics. Journal of Intelligent & Robotic Systems, 2017, 86(2): 153−173 [4] 王鼎. 基于学习的鲁棒自适应评判控制研究进展. 自动化学报, 2019, 45(6): 1031−1043Wang Ding. Research progress on learning-based robust adaptive critic control. Acta Automatica Sinica, 2019, 45(6): 1031−1043 [5] Wang Fei-Yue, Zheng Nan-Ning, Cao Dong-Pu, Clara M M, Li Li, Liu Teng. Parallel driving in CPSS: A unified approach for transport automation and vehicle intelligence. IEEE/CAA Journal of Automatica Sinica, 2017, 4(4): 577−587 doi: 10.1109/JAS.2017.7510598 [6] Du S S, Chen Jian-Shu, Li Li-Hong, Xiao Lin, Zhou Deng-Yong. Stochastic variance reduction methods for policy evaluation. In: Proceedings of the 34th International Conference on Machine Learning-Volume 70. Sydney, NSW, Australia: PMLR, 2017. 1049–1058 [7] Lyu Dao-Ming, Liu Bo, Geist M, Dong Wen, Biaz S, Wang Qi. Stable and efficient policy evaluation. IEEE Transactions on Neural Networks and Learning Systems, 2019, 30(6): 1831−1840 doi: 10.1109/TNNLS.2018.2871361 [8] Dabney W C. Adaptive step-sizes for reinforcement learning [Ph. D. dissertation], University of Massachusetts Amherst, 2014 [9] Young K, Wang Bao-Xiang, Taylor M E. Metatrace actor-critic: Online step-size tuning by meta-gradient descent for reinforcement learning control. In: Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence. Macau, China: ijcai.org, 2019. 4185–4191 [10] Szepesvári C. Algorithms for reinforcement learning. Synthesis Lectures on Artificial Intelligence and Machine Learning, 2010, 4(1): 1−103 [11] Busoniu L, Babuska R, De Schutter B, Ernst D. Reinforcement Learning and Dynamic Programming Using Function Approximators. Florida: CRC Press, 2017. [12] Boyan J A. Least-squares temporal difference learning. In: Proceedings of the 16th International Conference on Machine Learning. Bled, Slovenia: Morgan Kaufmann, 1999. 49–56 [13] Sutton R S, Szepesvári C, Maei H R. A convergent O(n) algorithm for off-policy temporal-difference learning with linear function approximation. Advances in Neural Information Processing Systems, 2008, 21(21): 1609−1616 [14] Sutton R S, Maei H R, Precup D, Bhatnagar S, Silver D, Szepesvári C, et al. Fast gradient-descent methods for temporal-difference learning with linear function approximation. In: Proceedings of the 26th International Conference on Machine Learning. Montreal, Quebec, Canada: ACM, 2009. 993–1000 [15] Dann C, Neumann G, Peters J. Policy evaluation with temporal differences: A survey and comparison. The Journal of Machine Learning Research, 2014, 15(1): 809−883 [16] Van Seijen H, Sutton R S. True online TD (lambda). In: Proceedings of the 31st International Conference on Machine Learning. Beijing, China: JMLR.org, 2014. 692–700 [17] Precup D, Sutton R S, Dasgupta S. Off-policy temporal-difference learning with function approximation. In: Proceedings of the 18th International Conference on Machine Learning. Williams College, Williamstown, MA, USA: Morgan Kaufmann, 2001. 417–424 [18] Maei H R, Sutton R S. GQ(λ): A general gradient algorithm for temporal-difference prediction learning with eligibility traces. In: Proceedings of the 3rd Conference on Artficial General Intelligence. Lugano, Switzerland: Atlantis Press, 2010. 91–96 [19] Precup D, Sutton R S, Singh S. Eligibility traces for off-policy policy evaluation. In: Proceedings of the Seventeenth International Conference on Machine Learning. Stanford, CA, USA: Morgan Kaufmann, 2000. 759–766 [20] Sutton R S. Learning to predict by the method of temporal differences. Machine Learning, 1988, 3(1): 9−44 [21] Van Seijen H, Mahmood A R, Pilarski P M, Machado M C, Sutton R S. True online temporal-difference learning. The Journal of Machine Learning Research, 2016, 17(1): 5057−5096 [22] Maei H R. Gradient temporal-difference learning algorithms [Ph. D. dissertation], University of Alberta, 2014 [23] White A, White M. Investigating practical linear temporal difference learning. In: Proceedings of the 2016 International Conference on Autonomous Agents & Multiagent Systems. Singapore, Singapore: ACM, 2016. 494–502 [24] Sutton R S, Mahmood A R, White M. An emphatic approach to the problem of off-policy temporal-difference learning. The Journal of Machine Learning Research, 2016, 17(1): 2603−2631 [25] Yu H. Weak convergence properties of constrained emphatic temporal-difference learning with constant and slowly diminishing stepsize. The Journal of Machine Learning Research, 2016, 17(1): 7745−7802 [26] Rummery G A. Problem solving with reinforcement learning [Ph. D. dissertation], University of Cambridge, 1995 -


 下载:
下载:











计量
- 文章访问数: 1102
- HTML全文浏览量: 752
- PDF下载量: 174
- 被引次数: 0
