

Adapted Expectation Maximization Algorithm for Gaussian Mixture Clustering With Censored Data
-
摘要: 针对聚类问题中的非随机性缺失数据, 本文基于高斯混合聚类模型, 分析了删失型数据期望最大化算法的有效性, 并揭示了删失数据似然函数对模型算法的作用机制. 从赤池弘次信息准则、信息散度等指标, 比较了所提出方法与标准的期望最大化算法的优劣性. 通过删失数据划分及指示变量, 推导了聚类模型参数后验概率及似然函数, 调整了参数截尾正态函数的一阶和二阶估计量. 并根据估计算法的有效性理论, 通过关于得分向量期望的方程得出算法估计的最优参数. 对于同一删失数据集, 所提出的聚类算法对数据聚类中心估计更精准. 实验结果证实了所提出算法在高斯混合聚类的性能上优于标准的随机性缺失数据期望最大化算法.Abstract: To provide a solution for clustering with data of missing not at random, this paper provided the efficiency analysis on the adapted expectation-maximization (EM) algorithm for Gaussian mixture clustering model with censored data. We also revealed the impact mechanism of the likelihood function of censored data on the clustering model and its estimation algorithm. With Akaike´s information criterion and Kullback-Leibler divergence, the performance of the proposed algorithm was compared with the standard EM algorithm. Based on data partition and the indicating variables of the censored data set, the paper proposed derived the posterior and likelihood function of the parameters, and adjusted its first and second moments of the truncated normal functions. According to the principles of efficient influence function, the optimal parameters of the algorithm are obtained by the equation of the expectation of the score vector. For the censored data, the proposed clustering algorithm is more accurate in estimating its centroids. The experimental results demonstrated that the proposed algorithm in Gaussian mixture clustering outperformed the standard EM algorithm, which was designed for the data of missing at random.
-
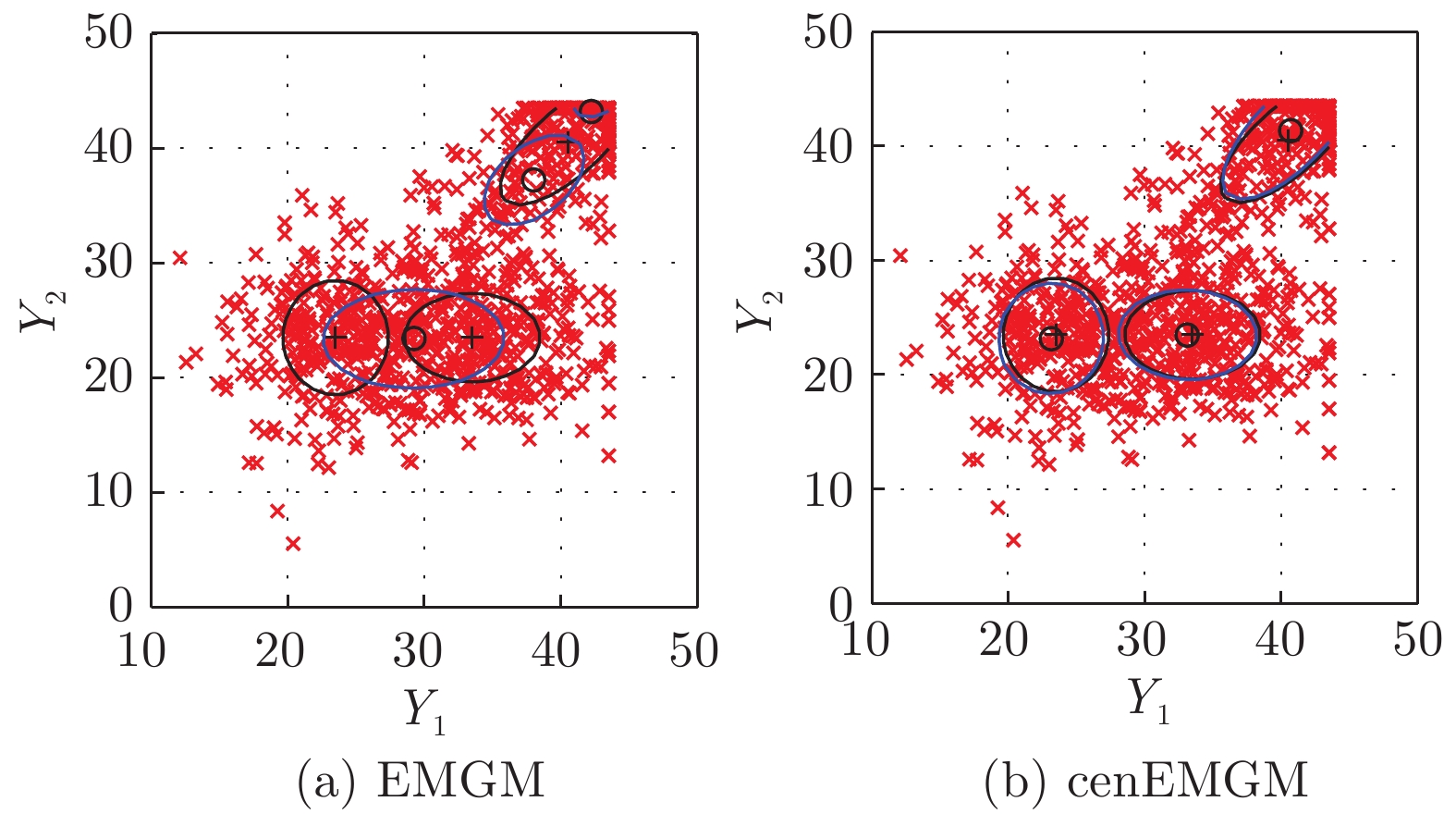
图 1 在数据集DS-a右删失上的两种算法比较
Fig. 1 Comparison of the two algorithms on the dataset DS-a with right censoring
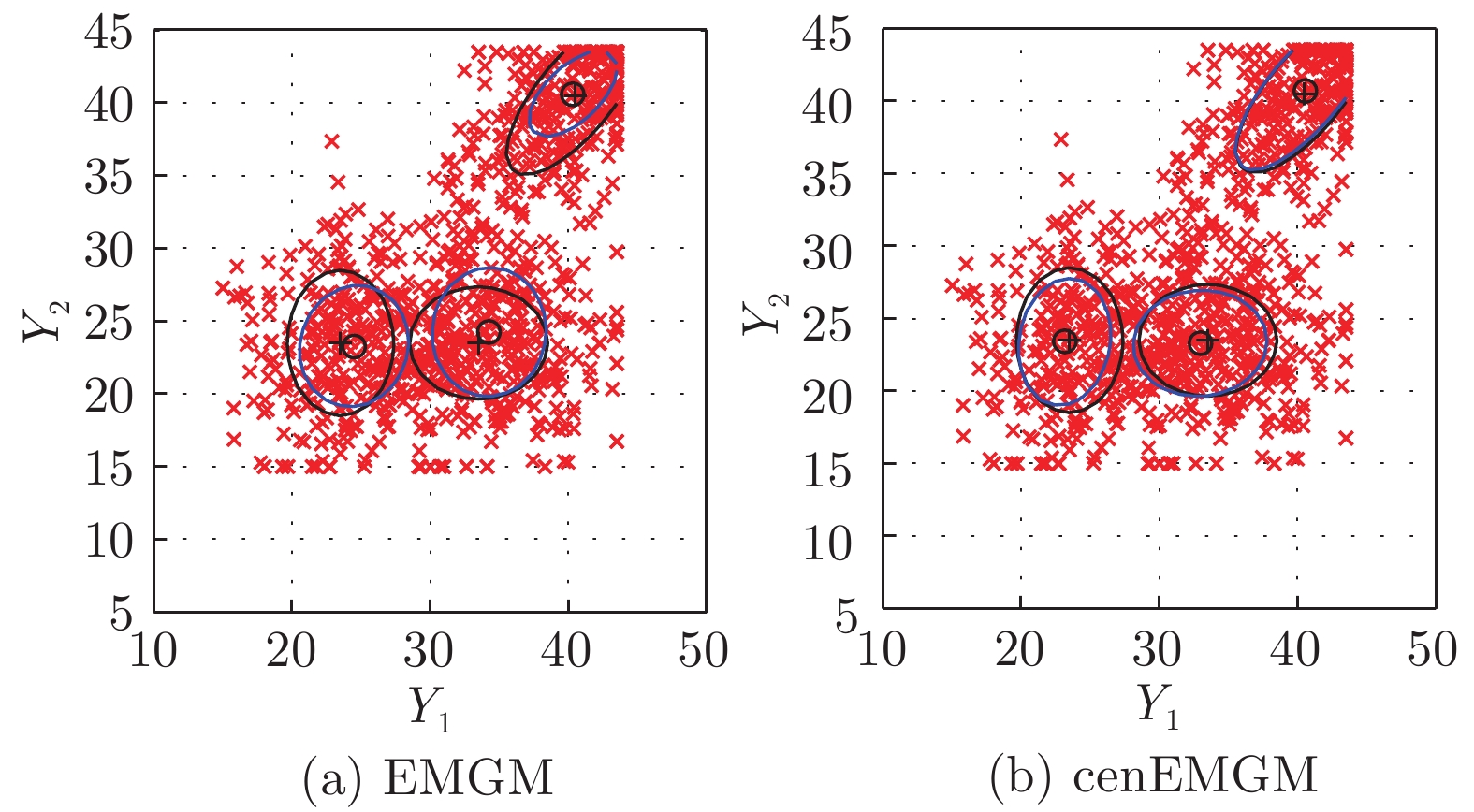
图 2 在数据集DS-a双边删失上的两种算法比较
Fig. 2 Comparison of the two algorithms on the dataset DS-a with double-side censoring
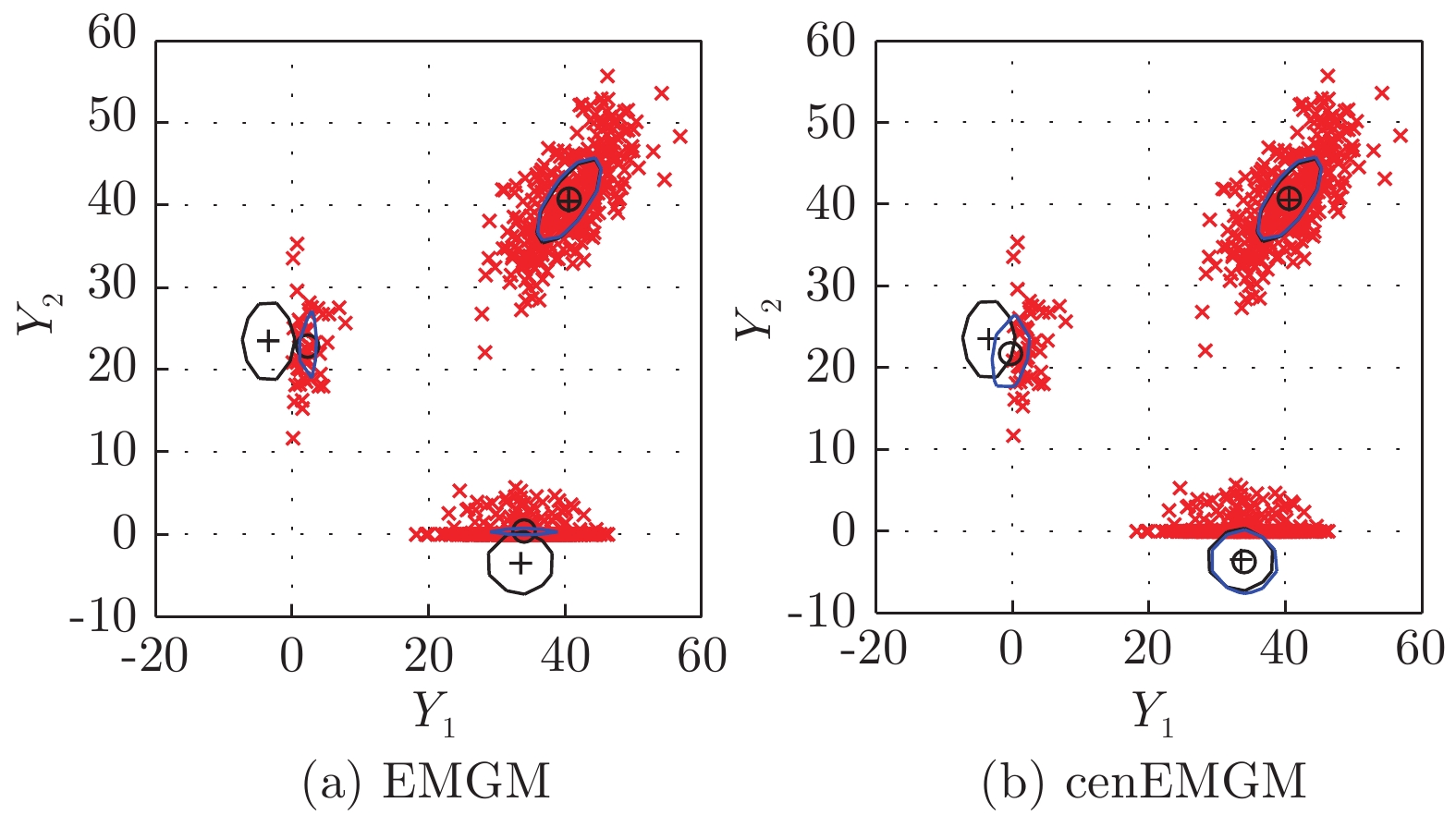
图 3 在数据集DS-b左删失上的两种算法比较
Fig. 3 Comparison of the two algorithms on the dataset DS-b with left censoring
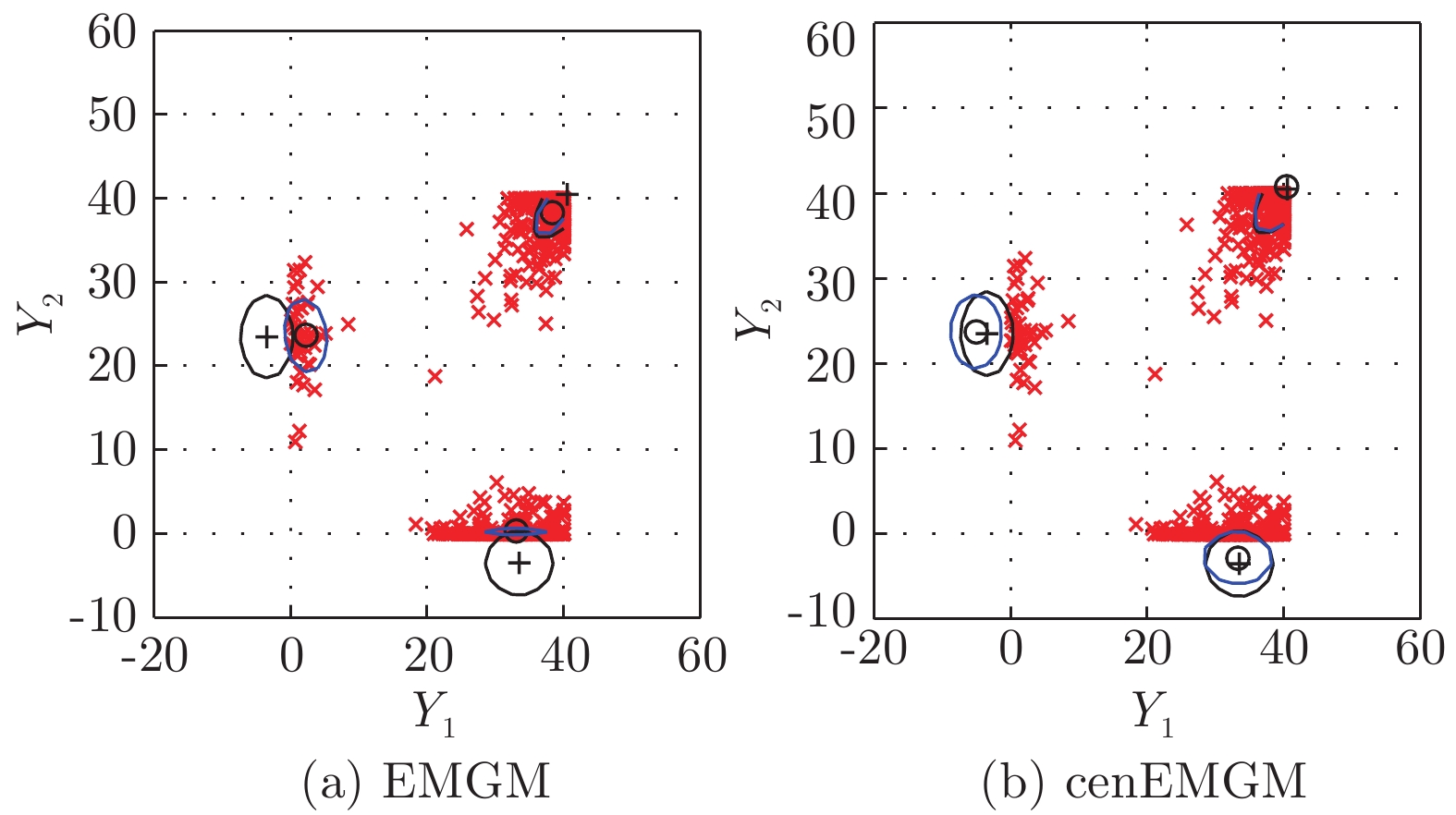
图 4 在数据集DS-b双边删失上的两种算法比较
Fig. 4 Comparison of the two algorithms on the dataset DS-b with double-side censoring
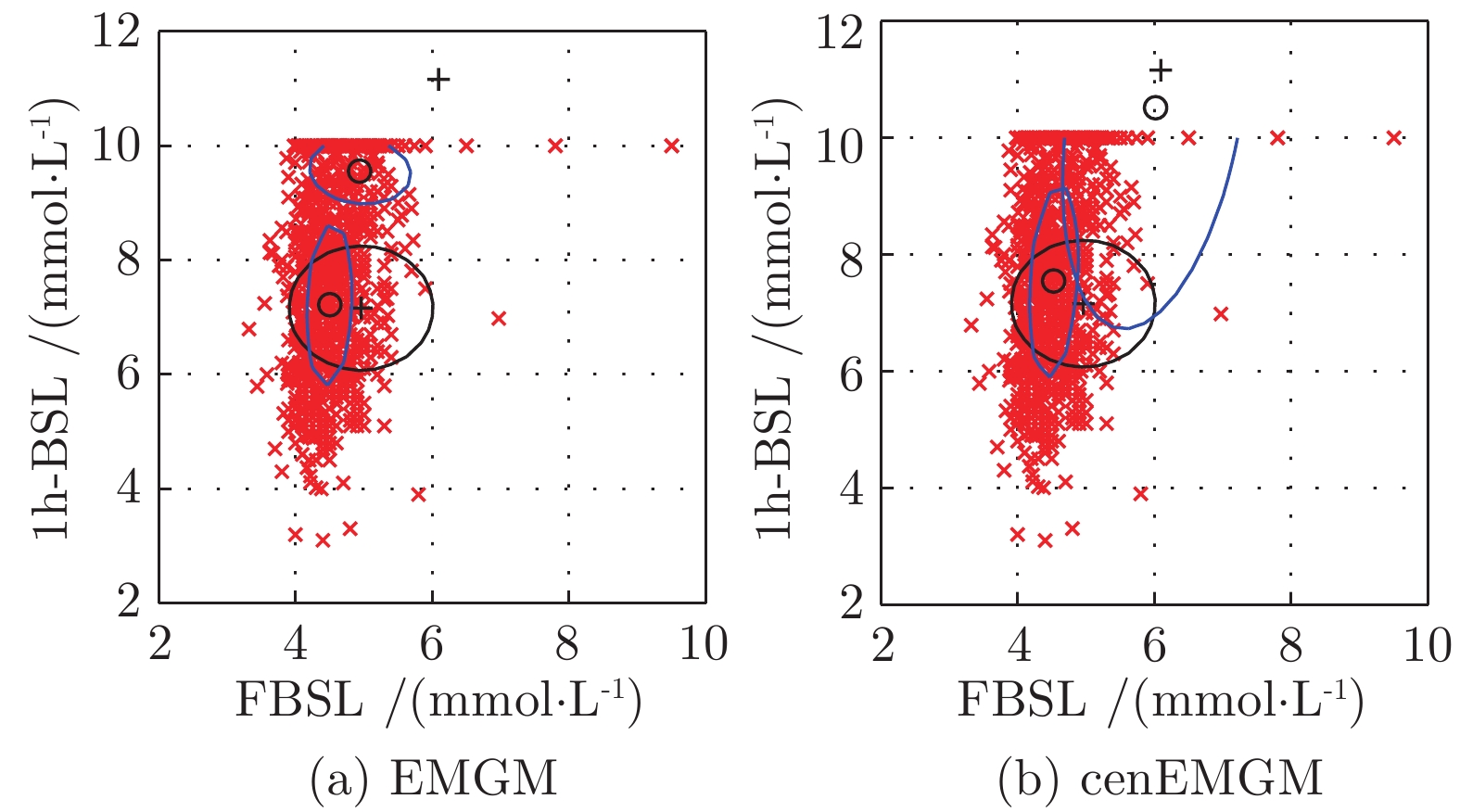
图 5 在血糖测试数据右删失上两种算法比较
Fig. 5 Comparison of the two algorithms on the dataset of blood sugar tests with right-side censoring
表 1 实验合成数据集真实分布和估计分布之间的KLD值
Table 1 Kullback-Leibler divergence (KLD) between the true densities and the estimated densities of the synthetic data set
数据集 观测值 (删失) EMGM cenEMGM DS-a 右删失 0.072 ± 0.011 0.261 ± 0.016 0.051 ± 0.003 DS-a 双边删失 0.226 ± 0.017 10.602 ± 1.966 0.028 ± 0.009 DS-b 左删失 4.362 ± 0.393 32.263 ± 4.193 22.583 ± 3.392 DS-b 双边删失 4.219 ± 0.381 30.321 ± 4.128 29.655 ± 3.938  下载: 导出CSV
下载: 导出CSV
表 2 实验合成数据集参数估计的两种算法AIC比较
Table 2 AIC comparison of the two estimation algorithms on the synthetic data set
数据集 EMGM cenEMGM DS-a 右删失 12852 ± 594 12349 ± 481 DS-a 双边删失 12782 ± 436 12323 ± 417 DS-b 左删失 9435 ± 317 8815 ± 305 DS-b 双边删失 8759 ± 293 7152 ± 264
下载: 导出CSV
表 3 真实数据及其拓展数据的两种算法比较
Table 3 Comparison of the two algorithms with the real data and its extended data
EMGM 算法 cenEMGM 算法 右边删失率 8.51 % 聚类中心 (4.50, 7.22) (4.53, 7.54) (4.94, 9.55) (6.01, 10.51) KLD 12.7 9.1 AIC 4366 4263 右边删失率 11.67 % 聚类中心 (4.50, 7.20) (4.53, 7.54) (4.81, 9.70) (6.08, 9.85) KLD 11.35 9.08 AIC 4 290 4 209 双边删失率 15.05 %: 右边删失 8.51 %,
左边删失 6.54 %聚类中心 (5.10, 7.43) (5.10, 7.48) (5.48, 8.56) (5.48, 8.94) KLD 173.7 158.6 AIC 2226 −24327
下载: 导出CSV
-
[1] Scrucca L, Raftery A E. Clustvarsel: A package implementing variable selection for Gaussian model-based clustering in R. Journal of Statistical Software, 2018: 84 [2] O´Hagan A, Murphy TB, Gormley IC, McNicholas PD, Karlis D. Clustering with the multivariate normal inverse Gaussian distribution. Computational Statistics & Data Analysis, 2016, 93: 18−30 [3] Xu M, Yu H Y, and Shen J. New approach to eliminate structural redundancy in case resource pools usingαmutual information. Journal of Systems Engineering and Electronics, 2013, 24(4): 625−633 doi: 10.1109/JSEE.2013.00073 [4] Qiu H, Yu H Y, Wang L Y, Yao Q, Wu S N, Yin C, Deng J. Electronic health record driven prediction for gestational diabetes mellitus in early pregnancy. Scientific Reports, 2017, 7(1): 16417 doi: 10.1038/s41598-017-16665-y [5] 李晓庆, 唐昊, 司加胜, 苗刚中. 面向混合属性数据集的改进半监督FCM聚类方法. 自动化学报, 2018, 44(12): 2259−2268Li Xiao-Qing, Tang Hao, Si Jia-Sheng, Miao Gang-Zhong. An improved semi-supervised FCM clustering method for mixed attribute datasets. Acta Automatica Sinica, 2018, 44(12): 2259−2268 [6] Xu M, Yu H Y, and Shen J. New algorithm for CBR-RBR fusion with robust thresholds. Chinese Journal of Mechanical Engineering, 2012, 25: 1255−1263 doi: 10.3901/CJME.2012.06.1255 [7] 沈江, 余海燕, 徐曼. 实体异构性下证据链融合推理的多属性群决策. 自动化学报, 2015, 41: 832−842Shen Jiang, Yu Hai-Yan, Xu Man. Heterogeneous evidence chains based fusion reasoning for multi-attribute group decision making. Acta Automatica Sinica, 2015, 41: 832−842 [8] 余海燕, 沈江, 徐曼. 类别误标下证据链推理的群决策分类方法. 系统工程与电子技术, 2015, (11): 2546−2553 doi: 10.3969/j.issn.1001-506X.2015.11.19Yu Hai-Yan, Shen Jiang, Xu Man. ECs-based reasoning for group decision analysis in the mislabeled classification context. Systems Engineering and Electronic Technology, 2015, (11): 2546−2553 doi: 10.3969/j.issn.1001-506X.2015.11.19 [9] Yu H Y, Shen J, Xu M. Temporal case matching with information value maximization for predicting physiological states. Information Sciences, 2016, 367: 766−782 [10] Yu H Y, Shen J, Xu M. Resilient parallel similarity-based reasoning for classifying heterogeneous medical cases in mapreduce. Digital Communications & Networks, 2016, 2(3): 145−150 [11] Lee G, Scott C. EM algorithms for multivariate Gaussian mixture models with truncated and censored data. Computational Statistics & Data Analysis, 2012, 56(9): 2816−2829 [12] Little R J, and Donald B R. Statistical Analysis with Missing Data. John Wiley & Sons, 2019. [13] Linero A R, Daniels M J. Bayesian approaches for missing not at random outcome data: The role of identifying restrictions. Statistical Science, 2018, 33: 198−213 doi: 10.1214/17-STS630 [14] Fang F, Shao J. Model selection with nonignorable nonresponse. Biometrika, 2016, 103(4): asw039 [15] Wu Y J, Fang W Q, Cheng L H, et al. A flexible Bayesian non-parametric approach for fitting the odds to case II interval-censored data. Journal of Statistical Computation and Simulation, 2018, 88(16): 3132−3150 doi: 10.1080/00949655.2018.1504944 [16] Leão J, Leiva V, Saulo H, et al. A survival model with Birnbaum – Saunders frailty for uncensored and censored cancer data. Brazilian Journal of Probability and Statistics, 2018, 32(4): 707−729 doi: 10.1214/17-BJPS360 [17] Goldberg Y, Kosorok M R. Support vector regression for right censored data. Electronic Journal of Statistics, 2017, 11(1): 532−69 doi: 10.1214/17-EJS1231 [18] 荀立, 周勇. 左截断右删失数据分位差估计及其渐近性质. 数学学报, 2017, 60(3): 451−464Xun Li, Zhou Yong. Estimators and their asymptotic properties for quantile difference with left truncated and right censored data. Acta Mathematica Sinica (Chinese Series), 2017, 60(3): 451−464 [19] Ma Y, Wang Y. Estimating disease onset distribution functions in mutation carriers with censored mixture data. Journal of the Royal Statistical Society: Series C (Applied Statistics), 2014, 63(1): 1−23 [20] 周志华. 机器学习. 北京: 清华大学出版社, 2016.Zhou Zhi-Hua. Machine Learning, Beijing: Tsinghua University Press, 2016. [21] Cai T T, Ma J, Zhang L. CHIME: Clustering of highdimensional Gaussian mixtures with EM algorithm and its optimality. The Annals of Statistics, 2019, 47: 1234−1267 doi: 10.1214/18-AOS1711 [22] Chauveau D. A stochastic EM algorithm for mixtures with censored data. Journal of Statistical Planning & Inference, 1995, 46(1): 1−25 [23] Dempster A P, Laird N M, Rubin D B. Maximum likelihood from incomplete data via the EM algorithm. Series B (Methodological), 1977: 1−38 [24] Tsiatis A. Semiparametric Theory and Missing Data. Springer Science & Business Media, 2007. [25] Wang Yong, et al. A hybrid user similarity model for collaborative filtering. Information Sciences, 2017, 418: 102−118 [26] Yu H, Chen J, Wang J N, Chiu Y L, Qiu H, Wang L Y. Identification of the differential effect of city-level on the Gini coefficient of healthcare service delivery in online health community. International Journal of Environmental Research and Public Health, 2019, 16: 2314 doi: 10.3390/ijerph16132314 [27] Luers B, Klasnja P, Murphy S. Standardized effect sizes for preventive mobile health interventions in micro-randomized trials. Prevention Science, 2019, 20: 100−109 doi: 10.1007/s11121-017-0862-5 [28] McIntyre H D, Catalano P, Zhang C, Desoye G, Mathiesen E R, Damm P. Gestational diabetes mellitus. Nature Reviews Disease Primers, 2019, 5: 47 doi: 10.1038/s41572-019-0098-8 -

 下载:
下载:

计量
- 文章访问数: 1562
- HTML全文浏览量: 502
- PDF下载量: 172
- 被引次数: 0
