

Weakly Supervised Real-time Object Detection Based on Saliency Map
-
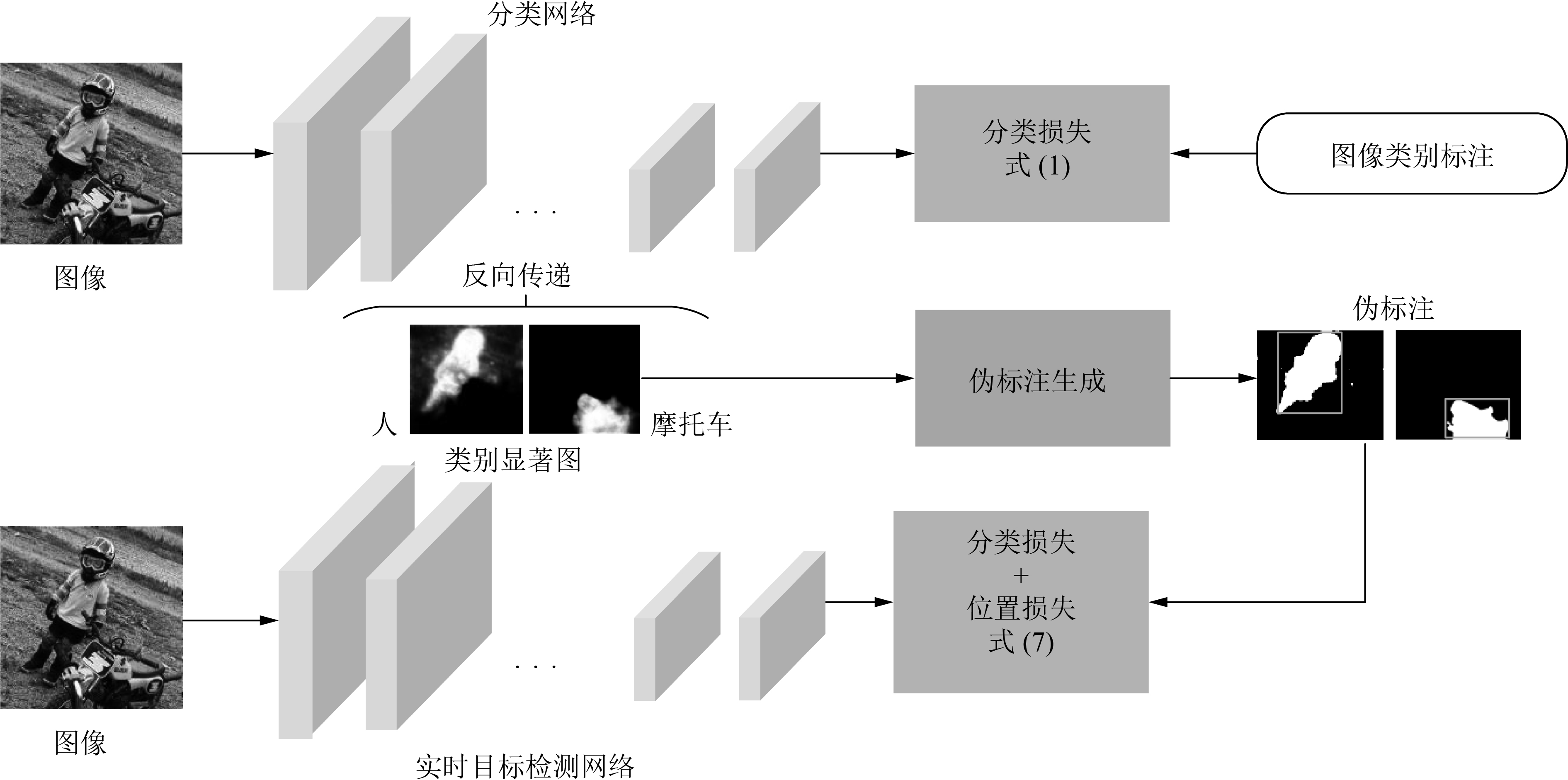
摘要: 深度卷积神经网络(Deep convolutional neural network, DCNN)在目标检测任务上使用目标的全标注来训练网络参数, 其检测准确率也得到了大幅度的提升. 然而, 获取目标的边界框(Bounding-box)标注是一项耗时且代价高的工作. 此外, 目标检测的实时性是制约其实用性的另一个重要问题. 为了克服这两个问题, 本文提出一种基于图像级标注的弱监督实时目标检测方法. 该方法分为三个子模块: 1)首先应用分类网络和反向传递过程生成类别显著图, 该显著图提供了目标在图像中的位置信息; 2)根据类别显著图生成目标的伪标注(Pseudo-bounding-box); 3)最后将伪标注看作真实标注并优化实时目标检测网络的参数. 不同于其他弱监督目标检测方法, 本文方法无需目标候选集合获取过程, 并且对于测试图像仅通过网络的前向传递过程就可以获取检测结果, 因此极大地加快了检测的速率(实时性). 此外, 该方法简单易用; 针对未知类别的目标检测, 只需要训练目标类别的分类网络和检测网络. 因此本框架具有较强的泛化能力, 为解决弱监督实时检测问题提供了新的研究思路. 在PASCAL VOC 2007数据集上的实验表明: 1)本文方法在检测的准确率上取得了较好的提升; 2)实现了弱监督条件下的实时检测.Abstract: Deep convolutional neural network (DCNN) trains model parameters by using object bounding-box annotations in object detection task, and its detection accuracy has been greatly improved. However, bounding-box annotations are very expensive and time-consuming. In addition, the real-time performance of object detection is another important problem that restricts its practicality. To solve these two problems, this paper proposes a new weakly supervised real-time object detector with image-level labels. The proposed method includes three sub-modules: 1) firstly, producing class-specific saliency maps based on a classification network and the back-propagation process, which provides object localization clues; 2) then, generating pseudo-annotations (pseudo-bounding-box) based on class-specific saliency maps; 3) finally, treating the pseudo annotations as ground-truth and optimizing the parameters of our real-time object detection network. Different from other weakly supervised object detection methods, our method avoids the computing process for obtaining object candidates. And we obtain object detection results of test images by feed-forward process, thus our method greatly speeds up the detection process (real-time). In addition, our method is simple and easy to use; for unknown class objects, we only need to train the classification and detection networks. So our method has a strong generalization ability and provides a new idea for weakly supervision real-time detection problem. Extensive experiments on PASCAL VOC 2007 benchmark show that: 1) the proposed method achieves a good improvement on detection accuracy; 2) it realizes real-time detection under weakly supervised condition.
-

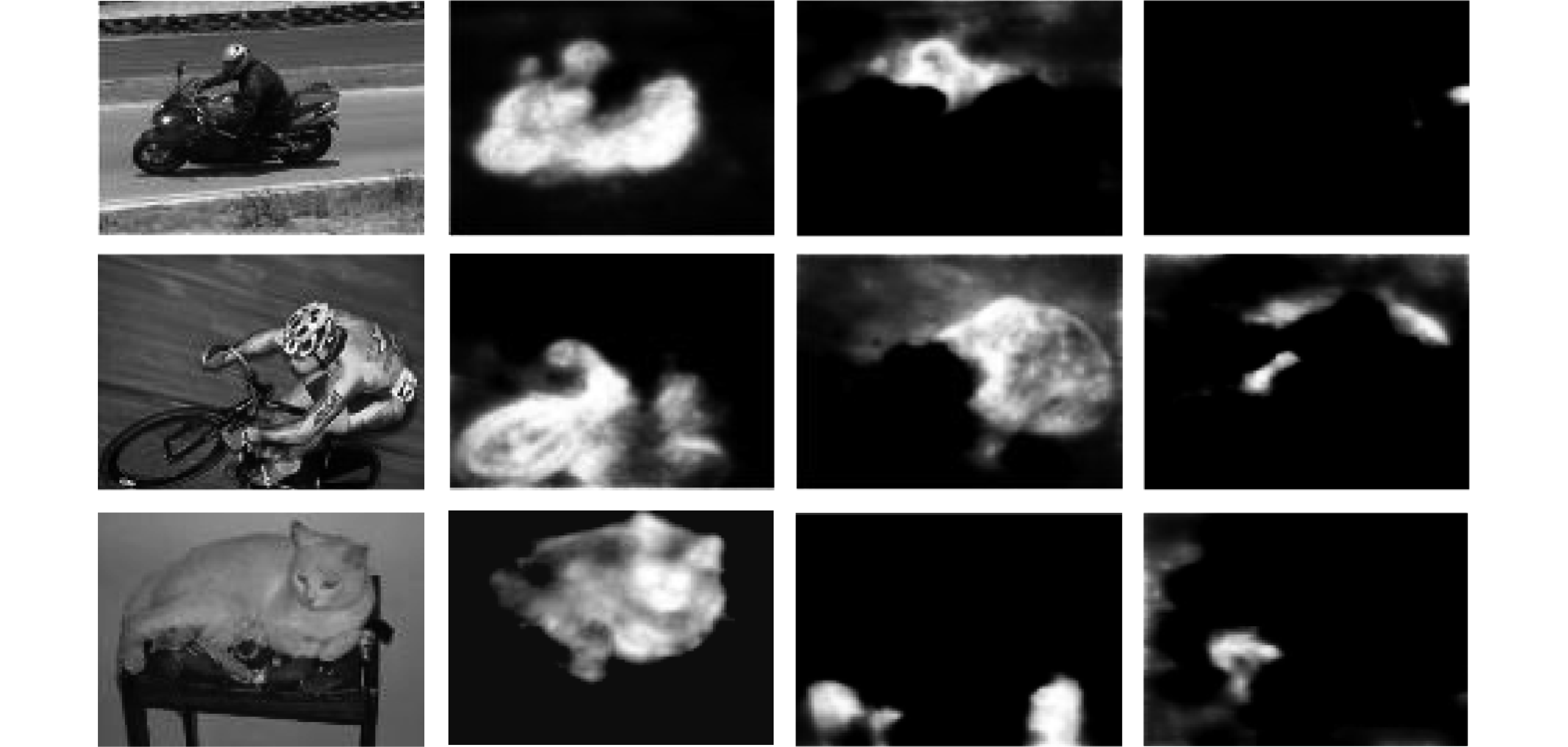
图 3 二值化类别显著图以及相应的伪标注
Fig. 3 Binarization class-specific saliency maps and the corresponding pseudo-bounding-boxes

图 4
$4\times 4$ 及$8\times 8$ 的特征单元和相对应的目标基检测框Fig. 4 Feature map cells for
$4\times 4$ and$8\times 8$ and its corresponding object default bounding-boxes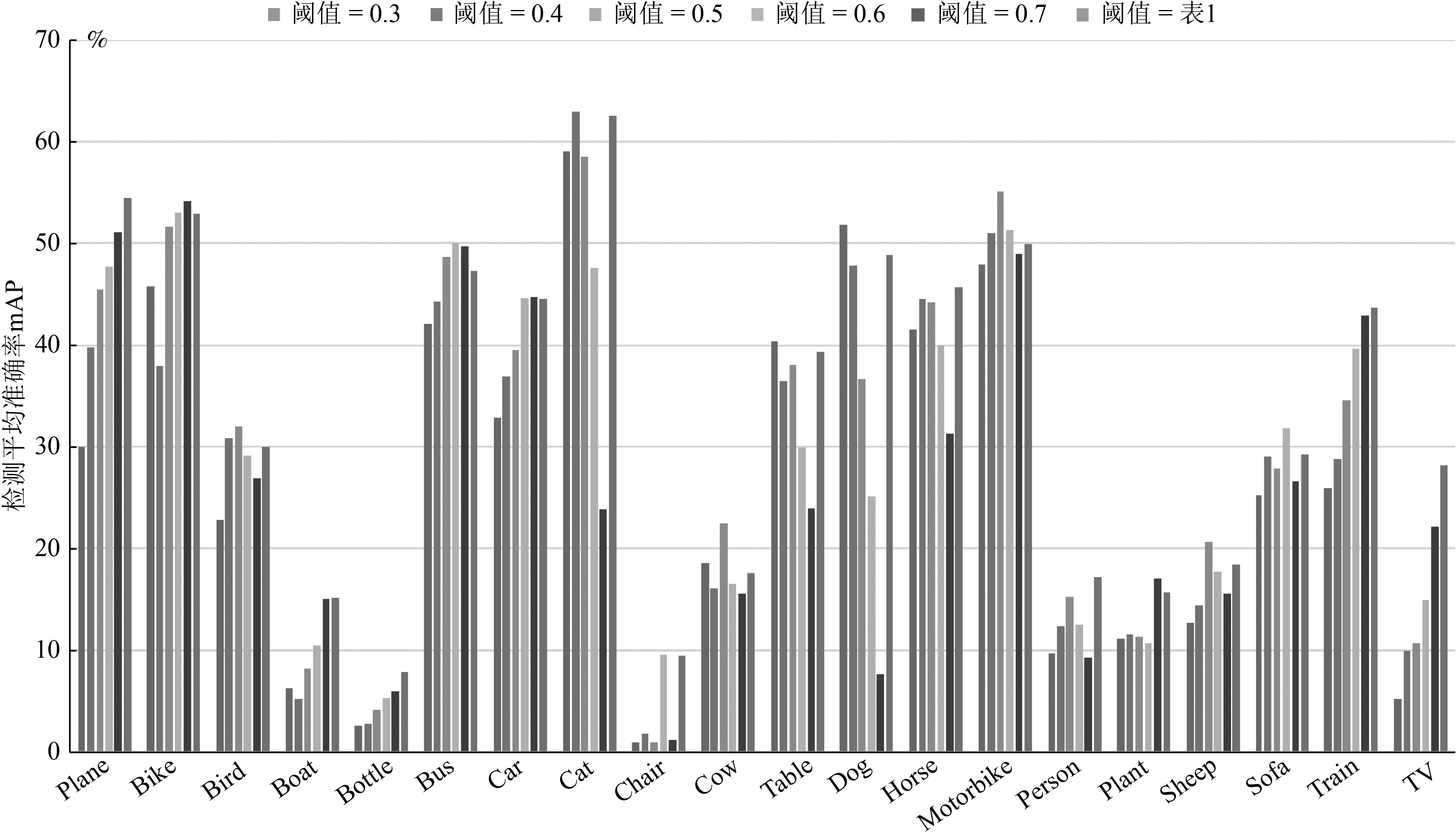
图 5 不同阈值设定下20个类别的目标检测准确率
Fig. 5 Object detection precision for 20 categories under different thresholds

图 6 PASCAL VOC 2007测试集上的成功检测样例
Fig. 6 Successful detection examples on PASCAL VOC 2007 test set

图 7 PASCAL VOC 2007 测试集上的失败检测样例
Fig. 7 Unsuccessful detection examples on PASCAL VOC 2007 test set
表 1 二值化类别显著图的阈值设置(PASCAL VOC数据集20个类别)
Table 1 Thresholds of the binarization class-specific saliency maps (20 categories for PASCAL VOC dataset)
类别 阈值 类别 阈值 类别 阈值 Plane 0.7 Cat 0.4 Person 0.5 Bike 0.7 Chair 0.6 Plant 0.7 Bird 0.5 Cow 0.5 Sheep 0.5 Boat 0.8 Diningtable 0.3 Sofa 0.5 Bottle 0.8 Dog 0.3 Train 0.7 Bus 0.6 Horse 0.3 TV 0.8 Car 0.6 Motorbike 0.5  下载: 导出CSV
下载: 导出CSV
表 2 PASCAL VOC 2007测试数据集的目标检测准确率(%)
Table 2 Object detection precision (%) on PASCAL VOC 2007 test set
方法 Bilen[11] Cinbis[7] Wang[32] Teh[17] WSDDN[10] WSDDN_Ens[10] WCCN[9] MELM[12, 14] PCL[13] 本文 (07数据集) 本文 (07+12数据集) mAP 27.7 30.2 31.6 34.5 34.8 39.3 42.8 47.3 48.8 33.9 39.3 Plane 46.2 39.3 48.9 48.8 39.4 46.4 49.5 55.6 63.2 54.5 54.2 Bike 46.9 43.0 42.3 45.9 50.1 58.3 60.6 66.9 69.9 52.9 60.0 Bird 24.1 28.8 26.1 37.4 31.5 35.5 38.6 34.2 47.9 30.0 41.9 Boat 16.4 20.4 11.3 26.9 16.3 25.9 29.2 29.1 22.6 15.2 20.7 Bottle 12.2 8.0 11.9 9.2 12.6 14.0 16.2 16.4 27.3 7.8 11.4 Bus 42.2 45.5 41.3 50.7 64.5 66.7 70.8 68.8 71.0 47.3 55.9 Car 47.1 47.9 40.9 43.4 42.8 53.0 56.9 68.1 69.1 44.5 49.2 Cat 35.2 22.1 34.7 43.6 42.6 39.2 42.5 43.0 49.6 62.5 71.3 Chair 7.8 8.4 10.8 10.6 10.1 8.9 10.9 25.0 12.0 9.4 10.5 Cow 28.3 33.5 34.7 35.9 35.7 41.8 44.1 65.6 60.1 17.6 23.2 Table 12.7 23.6 18.8 27.0 24.9 26.6 29.9 45.3 51.5 39.3 48.5 Dog 21.5 29.2 34.4 38.6 38.2 38.6 42.2 53.2 37.3 48.9 54.5 Horse 30.1 38.5 35.4 48.5 34.4 44.7 47.9 49.6 63.3 45.7 52.1 Motorbike 42.4 47.9 52.7 43.8 55.6 59.0 64.1 68.6 63.9 49.9 56.4 Person 7.8 20.3 19.1 24.7 9.4 10.8 13.8 2.0 15.8 17.2 15.0 Plant 20.0 20.0 17.4 12.1 14.7 17.3 23.5 25.4 23.6 15.7 17.6 Sheep 26.6 35.8 35.9 29.0 30.2 40.7 45.9 52.5 48.8 18.4 23.3 Sofa 20.6 30.8 33.3 23.2 40.7 49.6 54.1 56.8 55.3 29.3 42.5 Train 35.9 41.0 34.8 48.8 54.7 56.9 60.8 62.1 61.2 43.7 47.6 TV 29.6 20.1 46.5 41.9 46.9 50.8 54.5 57.1 62.1 28.2 30.4
下载: 导出CSV
表 3 PASCAL VOC 2007测试数据集上的目标检测速度(FPS)及检测平均准确率
Table 3 Object detection speed (FPS) and detection mean average precision on PASCAL VOC 2007 test set
下载: 导出CSV
表 4 不同二值化阈值对于检测准确率(%)的影响
Table 4 The influence of different binarization thresholds on the detection precision (%)
阈值 0.3 0.4 0.5 0.6 0.7 表1 mAP 26.6 28.7 30.3 29.4 26.7 33.9 Plane 30 39.8 45.5 47.7 51.1 54.5 Bike 45.8 37.9 51.6 53 54.2 52.9 Bird 22.8 30.8 32 29.2 26.9 30.0 Boat 6.3 5.2 8.2 10.5 15.1 15.2 Bottle 2.5 2.8 4.1 5.3 5.9 7.8 Bus 42.1 44.3 48.6 50 49.7 47.3 Car 32.9 36.9 39.5 44.6 44.7 44.5 Cat 59 63 58.5 47.6. 23.8 62.5 Chair 1 1.8 1 9.5 1.2 9.4 Cow 18.6 16.1 22.5 16.5 15.6 17.6 Table 40.4 36.5 38.1 29.9 24 39.3 Dog 51.8 47.8 36.7 25.1 7.6 48.9 Horse 41.6 44.5 44.2 40 31.3 45.7 Motorbike 47.9 51 55.1 51.3 49 49.9 Person 9.6 12.4 15.3 12.5 9.2 17.2 Plant 11.1 11.6 11.3 10.7 17.1 15.7 Sheep 12.7 14.4 20.7 17.7 15.6 18.4 Sofa 25.2 29 27.9 31.8 26.6 29.3 Train 26 28.8 34.6 39.6 42.9 43.7 TV 5.2 10 10.7 15 22.2 28.2
下载: 导出CSV
-
[1] Girshick R. Fast R-CNN. In: Proceedings of the 2015 IEEE International Conference on Computer Vision. Boston, USA: IEEE, 2015. 1440−1448 [2] Girshick R, Donahue J, Darrell T, Malik J. Rich feature hierarchies for accurate object detection and semantic segmentation. In: Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus, USA: IEEE, 2014. 580−587 [3] Liu W, Anguelov D, Erhan D, Szegedy C, Reed S, Fu C Y, Berg A C. SSD: single shot multibox detector. In: Proceedings of the 14th European Conference on Computer Vision. Amsterdam, The Netherlands: Springer, 2016. 21−37 [4] Ren S Q, He K M, Girshick R, Sun J. Faster R-CNN: towards real-time object detection with region proposal networks. In: Procoeedings of the 2015 Advances in neural Information Processing Systems. Montréal, Canada: MIT Press, 2015. 91−99 [5] Song H O, Girshick R, Jegelka S, Mairal J, Harchaoui Z, Darrell T. On learning to localize objects with minimal supervision. arXiv preprint.arXiv: 1403.1024, 2014. [6] 李勇, 林小竹, 蒋梦莹. 基于跨连接LeNet-5网络的面部表情识别. 自动化学报, 2018, 44(1): 176−1826 Li Yong, Lin Xiao-Zhu, Jiang Meng-Ying. Facial expression recognition with cross-connect LeNet-5 network. Acta Automatica Sinica, 2018, 44(1): 176−182 [7] 7 Cinbis R G, Verbeek J, Schmid C. Weakly supervised object localization with multi-fold multiple instance learning. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(1): 189−203 doi: 10.1109/TPAMI.2016.2535231 [8] Shi M J, Ferrari V. Weakly supervised object localization using size estimates. In: Proceedings of the 14th European Conference on Computer Vision. Amsterdam, the Netherlands: Springer, 2016. 105−121 [9] Diba A, Sharma V, Pazandeh A, Pirsiavash H, Gool L V. Weakly supervised cascaded convolutional networks. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, USA: IEEE, 2017. 914−922 [10] Bilen H, Vedaldi A. Weakly supervised deep detection networks. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA: IEEE, 2016. 2846−2854 [11] Bilen H, Pedersoli M, Tuytelaars T. Weakly supervised object detection with convex clustering. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, USA: IEEE, 2015. 1081−1089 [12] Wan F, Wei P X, Jiao J B, Han Z J, Ye Q X. Min-entropy latent model for weakly supervised object detection. In: Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 1297−1306 [13] Tang P, Wang X G, Bai S, Shen W, Bai X, Liu W Y, Yuille A L. PCL: proposal cluster learning for weakly supervised object detection. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018. DOI: 10.1109/TPAMI.2018.2876304 [14] Wan F, Wei P X, Jiao J B, Han Z J, Ye Q X. Min-entropy latent model for weakly supervised object detection. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018. DOI: 10.1109/CVPR.2018.00141 [15] 奚雪峰, 周国栋. 面向自然语言处理的深度学习研究. 自动化学报, 2016, 42(10): 1445−146515 Xi Xue-Feng, Zhou Guo-Dong. A survey on deep learning for natural language processing. Acta Automatica Sinica, 2016, 42(10): 1445−1465 [16] 常亮, 邓小明, 周明全, 武仲科, 袁野, 杨硕, 王宏安. 图像理解中的卷积神经网络. 自动化学报, 2016, 42(9): 1300−131216 Chang Liang, Deng Xiao-Ming, Zhou Ming-Quan, Wu Zhong-Ke, Yuan Ye, Yang Shuo, Wang Hong-An. Convolutional neural networks in image understanding. Acta Automatica Sinica, 2016, 42(9): 1300−1312 [17] Teh E W, Rochan M, Wang Y. Attention networks for weakly supervised object localization. In: Proceedings of the 2016 British Mahcine Vision Conference. York, UK: British Machine Vision Association, 2016. [18] Kantorov V, Oquab M, Cho M, Laptev I. Contextlocnet: context-aware deep network models for weakly supervised localization. In: Proceedings of the 14th European Conference on Computer Vision. Amsterdam, the Netherlands: Springer, 2016. 350−365 [19] Zhou B L, Khosla A, Lapedriza A, Oliva A, Torralba A. Learning deep features for discriminative localization. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA: IEEE, 2016. 2921−2929 [20] Simonyan K, Vedaldi A, Zisserman A. Deep inside convolutional networks: visualising image classiflcation models and saliency maps. arXiv Preprint. arXiv: 1312.6034, 2013. [21] Wei Y C, Feng J S, Liang X D, Cheng M M, Zhao Y, Yan S C. Object region mining with adversarial erasing: a simple classiflcation to semantic segmentation approach. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, USA: IEEE, 2017. 1568−1576 [22] Kolesnikov A, Lampert C H. Seed, expand and constrain: three principles for weakly-supervised image segmentation. In: Proceedings of the 14th European Conference on Computer Vision. Amsterdam, the Netherlands: Springer, 2016. 695−711 [23] Shimoda W, Yanai K. Distinct class-specific saliency maps for weakly supervised semantic segmentation. In: Proceedings of the 14th European Conference on Computer Vision. Amsterdam, the Netherlands: Springer, 2016. 218−234 [24] Sadeghi M A, Forsyth D. 30 Hz object detection with DPM V5. In: Proceedings of the 13th European Conference on Computer Vision. Zurich, Switzerland: Springer, 2014. 65−79 [25] Dean T, Ruzon M A, Segal M, Shlens J, Vijayanarasimhan S, Yagnik J. Fast, accurate detection of 100, 000 object classes on a single machine. In: Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition. Portland, USA: IEEE, 2013. 1814−1821 [26] Van de Sande K E A, Uijlings J R R, Gevers T, Smeulders A W M. Segmentation as selective search for object recognition. In: Proceedings of the 2011 IEEE International Conference on Computer Vision. Colorado Springs, USA: IEEE, 2011. 1879−1886 [27] Zitnick C L, Dollár P. Edge boxes: locating object proposals from edges. In: Proceedings of the 13th European Conference on Computer Vision. Zurich, Switzerland: Springer, 2014. 391−405 [28] 28 Dietterich T G, Lathrop R H, Lozano-Pérez T. Solving the multiple instance problem with axis-parallel rectangles. Artiflcial Intelligence, 1997, 89(1−2): 31−71 doi: 10.1016/S0004-3702(96)00034-3 [29] Zhang D, Liu Y, Si L, Zhang J, Lawrence R D. Multiple instance learning on structured data. In: Proceedings of the 2011 Advances in Neural Information Processing Systems. Cranada, Spain: MIT Press, 2011. 145−153 [30] Long J, Shelhamer E, Darrell T. Fully convolutional networks for semantic segmentation. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, USA: IEEE, 2015. 3431−3440 [31] 31 Russakovsky O, Deng J, Su H, Krause J, Satheesh S, Ma S, Huang Z H, Karpathy A, Khosla A, Bernstein M, et al. Imagenet large scale visual recognition challenge. International Journal of Computer Vision, 2015, 115(3): 211−252 doi: 10.1007/s11263-015-0816-y [32] Wang C, Ren W Q, Huang K Q, Tan T N. Weakly supervised object localization with latent category learning. In: Proceedings of the 13th European Conference on Computer Vision. Zurich, Switzerland: Springer, 2014. 431−445 [33] George P, Kokkinos I, Savalle P A. Untangling local and global deformations in deep convolutional networks for image classiflcation and sliding window detection. arXiv Preprint arXiv: 1412.0296, 2014. [34] Tang P, Wang X G, Bai X, Liu W Y. Multiple instance detection network with online instance classifier refinement. arXiv Preprint arXiv: 1701.00138, 2017. [35] Wu J J, Yu Y N, Huang C, Yu K. Deep multiple instance learning for image classiflcation and auto-annotation. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, USA: IEEE, 2015. 3460−3469 [36] Oquab M, Bottou L, Laptev I, Sivic J. Learning and transferring mid-level image representations using convolutional neural networks. In: Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus, USA: IEEE, 2014. 1717−1724 [37] Zhu W J, Liang S, Wei Y C, Sun J. Saliency optimization from robust background detection. In: Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Rognition. Columbus, USA: IEEE, 2014. 2814−2821 [38] Zhu L, Chen Y H, Yuille A, Freeman W. Latent hierarchical structural learning for object detection. In: Proceedings of the 2010 IEEE Conference on Computer Vision and Pattern Rognition. San Francisco, USA, 2010. 1062−1069 [39] Redmon J, Divvala S, Girshick R, Farhadi A. You only look once: unifled, real-time object detection. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA: IEEE, 2016. 779−788 [40] Springenberg J T, Dosovitskiy A, Brox T, Riedmiller M. Striving for simplicity: the all convolutional net. arXiv Preprint arXiv: 1412.6806, 2014. [41] Cheng M M, Liu Y, Lin W Y, Zhang Z M, Posin P L, Torr P H S. BING: binarized normed gradients for objectness estimation at 300 fps. In: Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus, USA: IEEE, 2014. 3286−3293 [42] Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition. arXiv Preprint. arXiv: 1409.1556, 2014. [43] Yan J J, Lei Z, Wen L Y, Li S Z. The fastest deformable part model for object detection. In: Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus, USA: IEEE, 2014. 2497−2504 -

 下载:
下载:






计量
- 文章访问数: 5794
- HTML全文浏览量: 1945
- PDF下载量: 693
- 被引次数: 0
