

Feature Selection Method Based on Maximum Information Coefficient and Approximate Markov Blanket
-
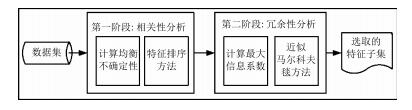
摘要: 最大信息系数(Maximum information coefficient,MIC)可以对变量间的线性和非线性关系,以及非函数依赖关系进行有效度量.本文首先根据最大信息系数理论,提出了一种评价各维特征间以及每维特征与类别间相关性的度量标准,然后提出了基于新度量标准的近似马尔科夫毯特征选择方法,删除冗余特征.在此基础上提出了基于特征排序和近似马尔科夫毯的两阶段特征选择方法,分别对特征的相关性和冗余性进行分析,选择有效的特征子集.在UCI和ASU上的多个公开数据集上的对比实验表明,本文提出的方法总体优于快速相关滤波(Fast correlation-based filter,FCBF)方法,与ReliefF,FAST,Lasso和RFS方法相比也具有优势.Abstract: Maximum information coefficient(MIC) is utilized to capture a wide range of associations between variables, including linear, non-linear and non-functional relationships. In this paper, firstly a measurement based on MIC is presented to measure relationships of features and classes in feature selection. Then the approximate Markov blanket with the proposed measurement is used to remove redundant features. A two-stage method based on feature ranking and approximate Markov blanket is further applied to select the feature subset by analyzing relevance and redundancy respectively. Experimental results on UCI and ASU open datasets show that the proposed method outperforms the fast correlation-based filter (FCBF) and gives better performance than ReliefF, FAST, Lasso and RFS.
-
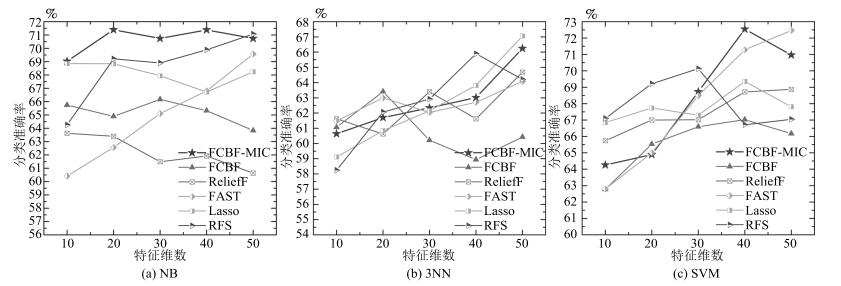
图 2 六种特征选择方法在SMK-CAN数据集上的比较
Fig. 2 The comparison of six feature selection methods on the SMK-CAN dataset
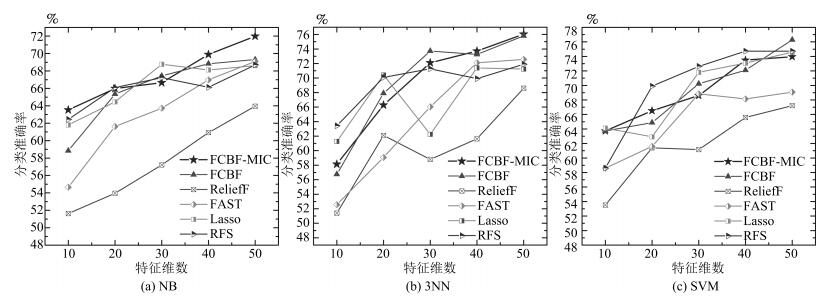
图 3 六种特征选择方法在TOX-171数据集上的比较
Fig. 3 The comparison of six feature selection methods on the TOX-171 dataset
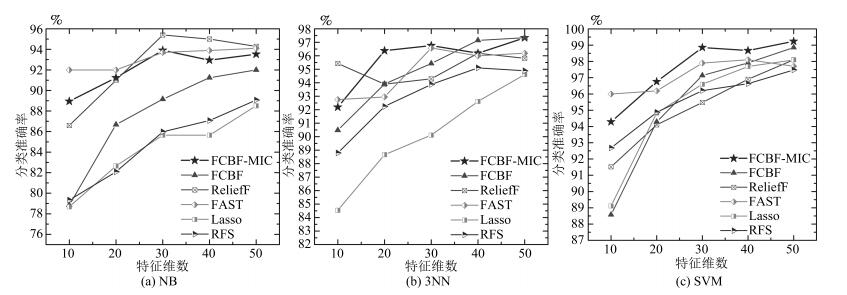
图 4 六种特征选择方法在PIE10P数据集上的比较
Fig. 4 The comparison of six feature selection methods on the PIE10P dataset
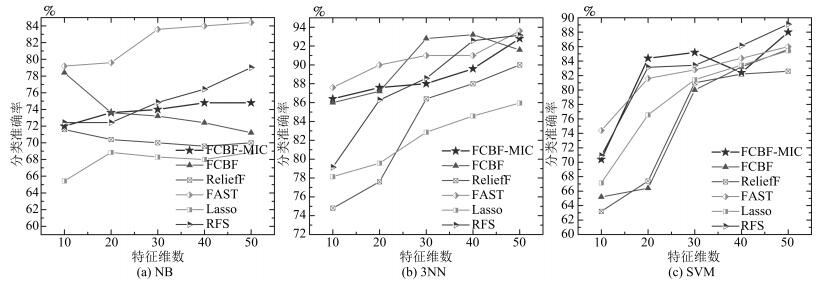
图 5 六种特征选择方法在ORL10P数据集上的比较
Fig. 5 The comparison of six feature selection methods on the ORL10P dataset
表 1 UCI数据集
Table 1 UCI datasets
数据集 特征总数 样本数 类别数 Spambase 57 4 601 2 Arrhythmia 452 279 16 Dermatology 34 366 6 Colon 2 000 62 2  下载: 导出CSV
下载: 导出CSV
表 2 两种特征选择方法选择的特征数
Table 2 The number of selected features in FCBF-MIC and FCBF
数据集 特征总数 FBCF-MIC FCBF Spambase 57 7.2 16.8 Arrhythmia 279 7.2 12.2 Dermatology 34 18.2 12.6 Colon 2 000 12.8 21
下载: 导出CSV
表 3 两种特征选择方法在UCI数据集上的实验结果(均值 $\pm$ 标准差%)
Table 3 The comparison of two feature selection methods on UCI datasets (Mean $\pm$ Std%)
数据集 NB 3NN SVM Full set NB FCBF-MIC FCBF Full set 3NN FCBF-MIC FCBF Full set SVM FCBF-MIC FCBF Spambase 79.93±0.30 86.93±2.15 78.60±2.34 87.55±1.47 89.43±0.51 87.8±2.05 90.11±0.62 90.15±0.98 90.24±0.88 Arrhythmia 61.17±3.81 62.66±3.91 65.84±3.83 57.5±3.72 65.04±4.62 62.13±3.96 61.87±3.98 65.49±3.64 64.07±3.33 Dermatology 96.06±1.00 97.16±1.27 96.27±0.91 95.08±1.51 95.63±0.84 95.52±0.64 96.61±1.27 96.83±0.40 95.85±0.74 Colon 80.00±3.76 83.02±2.89 83.06±3.29 78.07±4.56 77.42±5.67 76.87±3.08 78.71±3.29 83.87±2.04 83.23±3.76 Average 79.29 82.44 80.94 79.55 81.69 80.94 81.83 83.91 82.74
下载: 导出CSV
表 4 ASU数据集
Table 4 ASU datasets
数据集 特征总数 样本数 类别数 SMK-CAN 19 993 187 2 TOX-171 5 748 171 4 PIE10P 2 420 210 10 ORL10P 10 304 100 10
下载: 导出CSV
表 5 六种特征选择方法在NB上的比较(均值 $\pm$ 标准差%)
Table 5 The comparison of six feature selection methods on NB classification (Mean $\pm$ Std%)
数据集 FCBF-MIC FCBF ReliefF FAST Lasso RFS SMK-CAN 70.66±1.56 65.19±3.53 62.21±3.49 64.9±3.74 68.12±1.88 68.67±2.36 TOX-171 67.61±3.48 65.95 5.37 57.53±4.00 63.21±2.50 66.34±3.09 66.11±3.13 PIE10P 92.11±2.33 87.58±3.92 92.46±3.12 93.14±3.01 84.22±1.42 84.71±3.11 ORL10P 73.84±3.48 73.76±3.78 70.32±3.12 82.61±2.89 67.89±3.72 75.03±3.61 Average 76.06 73.12 70.63 75.97 71.64 73.63
下载: 导出CSV
表 6 六种特征选择方法在3NN上的比较(均值 $\pm$ 标准差%)
Table 6 The comparison of six feature selection methods on 3NN classification (Mean $\pm$ Std%)
数据集 FCBF-MIC FCBF ReliefF FAST Lasso RFS SMK-CAN 62.79±2.36 61.14±1.91 62.39±1.13 62.77±2.01 62.60±3.03 62.66±2.63 TOX-171 69.25±2.02 69.49±2.82 60.51±3.11 64.55±3.17 67.31±3.09 69.32±3.19 PIE10P 95.77±1.19 94.86±1.15 95.12±1.71 94.89±1.21 90.11±2.78 92.97±1.61 ORL10P 88.88±3.06 90.16±1.78 83.76±3.49 90.34±2.65 82.22±3.95 87.94±3.07 Average 79.17 78.91 78.14 75.45 75.56 78.22
下载: 导出CSV
表 7 六种特征选择方法在SVM上的比较(均值 $\pm$ 标准差%)
Table 7 The comparison of six feature selection methods on SVM classification (Mean $\pm$ Std%)
数据集 FCBF-MIC FCBF ReliefF FAST Lasso RFS SMK-CAN 68.28±1.60 65.26±2.31 67.27±1.33 68.04±1.47 67.81±1.54 68.04±1.78 TOX-171 69.26±2.13 69.44±5.35 61.76±1.19 65.16±3.33 69.30±2.12 70.12±3.31 PIE10P 97.56±1.24 95.35±0.51 95.21±0.97 96.38 1.56 95.27±1.17 95.58±1.21 ORL10P 82.08±5.32 76.08±2.66 75.24±2.46 81.84±3.01 78.80±5.55 82.56±4.60 Average 79.30 76.62 74.87 77.86 77.79 79.08
下载: 导出CSV
-
[1] Koller D, Sahami M. Toward optimal feature selection. In: Proceedings of the 13th International Conference on Machine Learning. Bari, Italy: Morgan Kaufmann, 1996. 284-292 [2] Liu H, Motoda H. Feature Selection for Knowledge Discovery and Data Mining. Berlin: Springer Science and Business Media, 2012. 1-5 [3] Bolón-Canedo V, Sánchez-Maroňo N, Alonso-Betanzos A. A review of feature selection methods on synthetic data. Knowledge and Information Systems, 2013, 34(3): 483-519 doi: 10.1007/s10115-012-0487-8 [4] 崔潇潇, 王贵锦, 林行刚.基于Adaboost权值更新以及K-L距离的特征选择算法.自动化学报, 2009, 35(5): 462-468 http://www.aas.net.cn/CN/abstract/abstract13753.shtmlCui Xiao-Xiao, Wang Gui-Jin, Lin Xing-Gang. Feature selection based on weight updating and K-L distance. Acta Automatica Sinica, 2009, 35(5): 462-468 http://www.aas.net.cn/CN/abstract/abstract13753.shtml [5] Yu L, Liu H. Feature selection for high-dimensional data: a fast correlation-based filter solution. In: Proceedings of the 20th International Conferences on Machine Learning. Washington DC, USA: AAAI Press, 2003. 856-863 [6] Lazar C, Taminau J, Meganck S, Steenhoff D, Coletta A, Molter C, de Schaetzen V, Duque R, Bersini H, Nowe A. A survey on filter techniques for feature selection in gene expression microarray analysis. IEEE/ACM Transactions on Computational Biology and Bioinformatics, 2012, 9(4): 1106-1119 doi: 10.1109/TCBB.2012.33 [7] 刘建伟, 李双成, 罗雄麟. p范数正则化支持向量机分类算法.自动化学报, 2012, 38(1): 76-87 http://www.aas.net.cn/CN/abstract/abstract17657.shtmlLiu Jian-Wei, Li Shuang-Cheng, Luo Xiong-Lin. Classification algorithm of support vector machine via p-norm regularization. Acta Automatica Sinica, 2012, 38(1): 76-87 http://www.aas.net.cn/CN/abstract/abstract17657.shtml [8] Li Z C, Liu J, Yang Y, Zhou X F, Lu H Q. Clustering-guided sparse structural learning for unsupervised feature selection. IEEE Transactions on Knowledge and Data Engineering, 2014, 26(9): 2138-2150 doi: 10.1109/TKDE.2013.65 [9] 刘峤, 秦志光, 陈伟, 张凤荔.基于零范数特征选择的支持向量机模型.自动化学报, 2011, 37(2): 252-256 http://www.aas.net.cn/CN/abstract/abstract17388.shtmlLiu Qiao, Qin Zhi-Guang, Chen Wei, Zhang Feng-Li. Zero-norm penalized feature selection support vector machine. Acta Automatica Sinica, 2011, 37(2): 252-256 http://www.aas.net.cn/CN/abstract/abstract17388.shtml [10] Gheyas I A, Smith L S. Feature subset selection in large dimensionality domains. Pattern Recognition, 2010, 43(1): 5-13 doi: 10.1016/j.patcog.2009.06.009 [11] Feng D C, Chen F, Xu W L. Detecting local manifold structure for unsupervised feature selection. Acta Automatica Sinica, 2014, 40(10): 2253-2261 doi: 10.1016/S1874-1029(14)60362-1 [12] Livni R, Lehavi D, Schein S, Nachlieli H. Vanishing component analysis. In: Proceedings of the 30th International Conference on Machine Learning. Atlanta, USA: Microtome Publishing, 2013. 597-605 [13] Liu H W, Sun J G, Liu L, Zhang H J. Feature selection with dynamic mutual information. Pattern Recognition, 2009, 42(7): 1330-1339 doi: 10.1016/j.patcog.2008.10.028 [14] Estévez P, Tesmer M, Perez C A, Zurada J M. Normalized mutual information feature selection. IEEE Transactions on Neural Networks, 2009, 20(2): 189-201 doi: 10.1109/TNN.2008.2005601 [15] Dash M, Liu H. Feature selection for classification. Intelligent Data Analysis, 1997, 1(1-4): 131-156 doi: 10.1016/S1088-467X(97)00008-5 [16] Kononenko I. Estimating attributes: analysis and extensions of RELIEF. In: Proceedings of the 1994 European Conference on Machine Learning. Berlin, Germany: Springer, 1994. 171-182 [17] Mitra P, Murthy C A, Pal S K. Unsupervised feature selection using feature similarity. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2002, 24(3): 301-312 doi: 10.1109/34.990133 [18] Yang Y M, Pedersen J O. A comparative study on feature selection in text categorization. In: Proceedings of the 14th International Conference on Machine Learning. Nashville, Tennessee, USA: Morgan Kaufmann, 1997. 412-420 [19] Xing E P, Jordan M I, Karp R M. Feature selection for high-dimensional genomic microarray data. In: Proceedings of the 18th International Conference on Machine Learning. Williams College, Williamstown, MA, USA: Morgan Kaufmann, 2001. 601-608 [20] Yu L, Liu H. Efficient feature selection via analysis of relevance and redundancy. The Journal of Machine Learning Research, 2004, 5: 1205-1224 http://citeseer.ist.psu.edu/viewdoc/summary?doi=10.1.1.71.5055 [21] Reshef D N, Reshef Y A, Finucane H K, Grossman S R, McVean G, Turnbaugh P J, Lander E S, Mitzenmacher M, Sabeti P C. Detecting novel associations in large data sets. Science, 2011, 334(6062): 1518-1524 doi: 10.1126/science.1205438 [22] Kira K, Rendell L A. The feature selection problem: traditional methods and a new algorithm. In: Proceedings of the 10th National Conference on Artificial Intelligence. Massachusetts, USA: AAAI Press, 1992. 129-134 [23] Forman G. An extensive empirical study of feature selection metrics for text classification. The Journal of Machine Learning Research, 2003, 3: 1289-1305 http://www.citeulike.org/user/markymaypo/article/1915886 [24] Fleuret F. Fast binary feature selection with conditional mutual information. The Journal of Machine Learning Research, 2004, 5: 1531-1555 https://www.researchgate.net/publication/220320537_Fast_Binary_Feature_Selection_with_Conditional_Mutual_Information [25] Yu L, Liu H. Redundancy based feature selection for microarray data. In: Proceedings of the 10th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York, USA: ACM, 2004. 737-742 [26] Hall M A. Correlation-based feature selection for discrete and numeric class machine learning. In: Proceedings of the 17th International Conference on Machine Learning. Stanford, USA: Morgan Kaufmann, 2000. 359-366 [27] Ding C, Peng H C. Minimum redundancy feature selection from microarray gene expression data. Journal of Bioinformatics and Computational Biology, 2005, 3(2): 185-205 doi: 10.1142/S0219720005001004 [28] Peng H C, Long F H, Ding C. Feature selection based on mutual information criteria of max-dependency, max-relevance, and min-redundancy. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2005, 27(8): 1226-1238 doi: 10.1109/TPAMI.2005.159 [29] Seth S, Principe J C. Variable selection: a statistical dependence perspective. In: Proceedings of the 9th International Conference on Machine Learning and Applications. Washington DC, USA: IEEE, 2010. 931-936 [30] Vergara J R, Estévez P A. A review of feature selection methods based on mutual information. Neural Computing and Applications, 2014, 24(1): 175-186 doi: 10.1007/s00521-013-1368-0 [31] 崔自峰, 徐宝文, 张卫丰, 徐峻岭.一种近似Markov Blanket最优特征选择算法.计算机学报, 2007, 30(12): 2074-2081 doi: 10.3321/j.issn:0254-4164.2007.12.002Cui Zi-Feng, Xu Bao-Wen, Zhang Wei-Feng, Xu Jun-Ling. An approximate Markov blanket feature selection algorithm. Chinese Journal of Computers, 2007, 30(12): 2074-2081 doi: 10.3321/j.issn:0254-4164.2007.12.002 [32] Saeed M. Bernoulli mixture models for Markov blanket filtering and classification. In: Proceedings of the 2008 IEEE World Congress on Computational Intelligence. Hong Kong, China: IEEE, 2008. 77-91 [33] Zhang Y, Ding C, Li T. A two-stage gene selection algorithm by combining ReliefF and mRMR. In: Proceedings of the 7th IEEE International Conference on Bioinformatics and Bioengineering. Massachusetts, USA: IEEE, 2007. 164-171 [34] Javed K, Babri H A, Saeed M. Feature selection based on class-dependent densities for high-dimensional binary data. IEEE Transactions on Knowledge and Data Engineering, 2012, 24(3): 465-477 doi: 10.1109/TKDE.2010.263 [35] Song Q B, Ni J J, Wang G T. A fast clustering-based feature subset selection algorithm for high-dimensional data. IEEE Transactions on Knowledge and Data Engineering, 2013, 25(1): 1-14 doi: 10.1109/TKDE.2011.181 [36] Ruiz R, Riquelme J C, Aguilar-Ruiz J S. Incremental wrapper-based gene selection from microarray data for cancer classification. Pattern Recognition, 2006, 39(12): 2383-2392 doi: 10.1016/j.patcog.2005.11.001 [37] de Souza R S, Maio U, Biffi V, Ciardi B. Robust PCA and MIC statistics of baryons in early minihaloes. Monthly Notices of the Royal Astronomical Society, 2013, 440(1): 240-248 http://adsabs.harvard.edu/abs/2014MNRAS.440..240D [38] Liu H M, Rao N, Yang D, Yang L, Li Y, Ou F. A novel method for identifying SNP disease association based on maximal information coefficient. Genetics and Molecular Research, 2014, 13(4): 10863-10877 doi: 10.4238/2014.December.19.7 [39] Mani-Varnosfaderani A, Ghaemmaghami M. Assessment of the orthogonality in two-dimensional separation systems using criteria defined by the maximal information coefficient. Journal of Chromatography A, 2015, 1415: 108-114 doi: 10.1016/j.chroma.2015.08.049 [40] Fayyad U M, Irani K B. Multi-interval discretization of continuous-valued attributes for classification learning. In: Proceedings of the 13th International Joint Conference on Artificial Intelligence. Chambéry, France: Springer, 1993. 1022-1027 [41] Lichman M. UCI machine learning repository [Online], available: http://archive.ics.uci.edu/ml, November 10, 2015 [42] Zhao Z, Morstatter F, Sharma S, Alelyani S, Anand A, Liu H. Advancing feature selection research. ASU Feature Selection Repository, 2010. 1-28 [43] Tibshirani R. Regression shrinkage and selection via the lasso. Journal of the Royal Statistical Society. Series B (Methodological), 1996, 58(1): 267-288 http://www.ams.org/mathscinet-getitem?mr=1379242 [44] Nie F P, Huang H, Cai X, Ding C. Efficient and robust feature selection via joint l2, 1-norms minimization. In: Advances in Neural Information Processing Systems 23: 24th Annual Conference on Neural Information Processing Systems. Vancouver, British Columbia, Canada: NIPS, 2010. 1813-1821 [45] 段洁, 胡清华, 张灵均, 钱宇华, 李德玉.基于邻域粗糙集的多标记分类特征选择算法.计算机研究与发展, 2015, 52(1): 56-65 doi: 10.7544/issn1000-1239.2015.20140544Duan Jie, Hu Qing-Hua, Zhang Ling-Jun, Qian Yu-Hua, Li De-Yu. Feature selection for multi-label classification based on neighborhood rough sets. Journal of Computer Research and Development, 2015, 52(1): 56-65 doi: 10.7544/issn1000-1239.2015.20140544 [46] Hall M, Frank E, Holmes G. The WEKA data mining software: an update. ACM SIGKDD Explorations Newsletter, 2009, 11(1): 10-18 doi: 10.1145/1656274 -

 下载:
下载:

计量
- 文章访问数: 3401
- HTML全文浏览量: 606
- PDF下载量: 1104
- 被引次数: 0
