

A Video Co-segmentation Algorithm by Means of Maximizing Submodular Function and RRWM
-
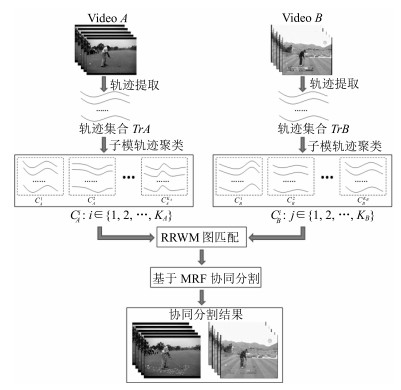
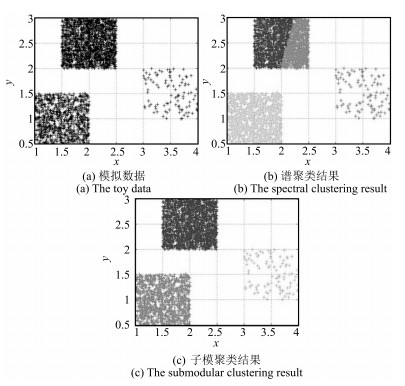
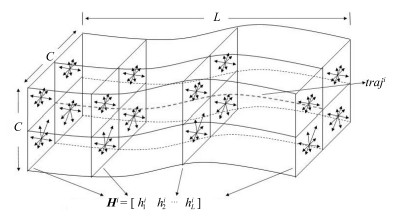
摘要: 成对视频共同运动模式的协同分割指的是同时检测出两个相关视频中共有的行为模式,是计算机视觉研究的一个热点.本文提出了一种新的成对视频协同分割方法.首先,利用稠密轨迹方法对视频运动部分进行检测,并对运动轨迹进行特征表示;然后,引入子模优化方法对单视频内的运动轨迹进行聚类分析;接着采用基于重加权随机游走的图匹配方法对成对视频运动轨迹进行匹配,该方法对出格点、变形和噪声都具有很强的鲁棒性;同时根据图匹配结果实现运动轨迹的共显著性度量;最后,将所有轨迹分类成共同运动轨迹和异常运动轨迹的问题转化为基于图割的马尔科夫随机场的二值化标签问题.通过典型运动视频数据集的比较实验,其结果验证了本文方法的有效性.Abstract: Co-segmentation of common motion pattern in a pair of videos aims to detect and segment common motion pattern of the two videos simultaneously, which has become a new hotspot in computer vision. We propose a novel method to address the problem. Firstly, we detect the movement part of the video using dense trajectories and represent the movement trajectory characteristic. Then we introduce submodular function is to group these dense trajectories in the single video. Furthermore, reweighted random walks for graph matching (RRWM) is used to match the obtained trajectory clusters in different videos, which is the robust to noise, outlier, and deformation. And the trajectory co-saliency is measured according to the matching results of RRWM. Finally, classify the trajectories into common motion trajectories and outlier motion trajectories; we formulate the problem as a binary labeling of a Markov random field (MRF) based on graph cut. Experimental results on the benchmark datasets show the effectiveness of the proposed approach.
-
Key words:
- Dense trajectories /
- submodular function /
- graph matching /
- co-saliency /
- Markov random field
-

图 4 Bench press类中视频轨迹聚类与匹配结果
Fig. 4 The clustering and matching results of video trajectories

图 5 Bench press类中视频轨迹聚类与匹配结果
Fig. 5 The clustering and matching results of video trajectories
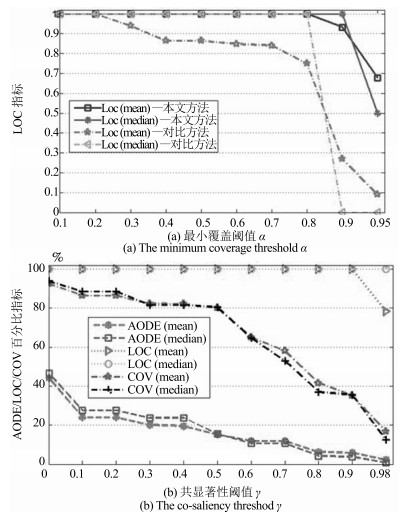
图 6 Bench press类中视频轨迹聚类与匹配结果
Fig. 6 The clustering and matching results of video trajectories
表 1 运动标签与其对应的视频对的数量
Table 1 Action tags and the corresponding number of pairs of sequences
运动类型 数量 Basketball shooting 6 Bench press 8 Clean and jerk 5 Jumping rope 8 Lunges 6 Rope climbing 5 Pommel horse 4 Golf 6 Pullup 4 Pushup 3 Ride bike 7  下载: 导出CSV
下载: 导出CSV
表 2 本文方法与SC + GM方法的实验结果对比
Table 2 The experimental results of the proposed method and SC + GM
类名 AODE (%, mean) AODE (%, median) LOC (%, mean) LOC (%, median) COV (%, mean) COV (%, median) Basketball 36.76 34.38 96.35 100 86.05 87.81 47.66 47.84 64.42 50 73.90 81.03 Bench press 24.10 27.47 100 100 86.57 88.49 27.34 26.56 84.09 100 75.52 81.86 Clean and jerk 31.05 30.94 100 100 73.81 82.22 30.79 33.34 94.50 100 70.40 76.31 Jumping rope 5.45 38.60 100 100 84.23 83.58 20.18 23.69 65.89 100 77.30 86.15 Lunges 28.28 31.91 89.62 100 52.78 57.58 29.31 28.48 37.65 50 65.05 83.76 Kayaking 51.62 53.68 41.50 50 64.96 69.39 42.51 43.67 42.13 50 65.48 62.60 Rope climbing 20.60 22.00 74.17 100 63.08 82.16 33.81 19.41 64.75 72.14 56.43 71.33
下载: 导出CSV
表 3 本文方法与其他方法的实验结果对比
Table 3 The experimental results of the proposed method and other methods
类名 方法 MR (%, mean) COV (%, mean) 本文方法 51.37 60.12 Golf SC + GM 50.64 58.90 VCS 48.82 54.17 本文方法 82.20 80.35 Pullup SC + GM 79.58 78.78 VCS 70.22 72.41 本文方法 47.54 52.81 Pushup SC + GM 45.61 52.97 VCS 55.34 60.15 本文方法 35.30 35.78 Ride bike SC + GM 34.62 36.35 VCS 38.45 34.56
下载: 导出CSV
-
[1] Rother C, Minka T, Blake A, Kolmogorov V. Cosegmentation of image pairs by histogram matching-incorporating a global constraint into MRFs. In:Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. New York, USA:IEEE, 2006. 993-1000 [2] Vicente S, Rother C, Kolmogorov V. Object cosegmentation. In:Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition. Providence, RI:IEEE, 2011. 2217-2224 [3] Cao X C, Tao Z Q, Zhang B, Fu H Z, Feng W. Self-adaptively weighted co-saliency detection via rank constraint. IEEE Transactions on Image Processing, 2014, 23(9):4175-4186 https://www.ncbi.nlm.nih.gov/pubmed/24968170 [4] Zhang D W, Han J W, Li C, Wang J D. Co-saliency detection via looking deep and wide. In:Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, Massachusetts, USA:IEEE, 2015. 2994-3002 [5] Galasso F, Iwasaki M, Nobori K, Cipolla R. Spatio-temporal clustering of probabilistic region trajectories. In:Proceedings of the 2011 International Conference on Computer Vision. Barcelona, Spain:IEEE, 2011. 1738-1745 [6] 王蒙, 戴亚平, 王庆林.单目视觉下目标三维行为的时间尺度不变建模及识别.自动化学报, 2014, 40(8):1644-1653 http://www.aas.net.cn/CN/article/downloadArticleFile.do?attachType=PDF&id=18432Wang Meng, Dai Ya-Ping, Wang Qing-Lin. Time-scale invariant modeling and classifying for object behaviors in 3D space based on monocular vision. Acta Automatica Sinica, 2014, 40(8):1644-1653 http://www.aas.net.cn/CN/article/downloadArticleFile.do?attachType=PDF&id=18432 [7] 褚一平, 张引, 叶修梓, 张三元.基于隐条件随机场的自适应视频分割算法.自动化学报, 2007, 33(12):1252-1258 http://www.aas.net.cn/CN/article/searchArticle.do#Chu Yi-Ping, Zhang Yin, Ye Xiu-Zi, Zhang San-Yuan. Adaptive video segmentation algorithm using hidden conditional random fields. Acta Automatica Sinica, 2007, 33(12):1252-1258 http://www.aas.net.cn/CN/article/searchArticle.do# [8] Joulin A, Tang K, Li F F. Efficient image and video co-localization with frank-wolfe algorithm. In:Proceedings of the 13th European Conference on Computer Vision. Zurich, Switzerland:Springer, 2014. 253-268 doi: 10.1007%2F978-3-319-10599-4_17 [9] Prest A, Leistner C, Civera J, Schmid C, Ferrari V. Learning object class detectors from weakly annotated video. In:Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition. Providence, Rhode Island, USA:IEEE, 2012. 3282-3289 [10] Chen D J, Chen H T, Chang L W. Video object cosegmentation. In:Proceedings of the 20th ACM International Conference on Multimedia. Nara, Japan:ACM, 2012. 805-808 [11] Rubio J C, Serrat J, López A. Video co-segmentation. In:Proceedings of the 11th Asian Conference on Computer Vision. Daejeon, Korea:Springer, 2013. 13-24 doi: 10.1007%2F978-3-642-37444-9_2 [12] Chiu W C, Fritz M. Multi-class video co-segmentation with a generative multi-video model. In:Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition. Portland, OR:IEEE, 2013. 321-328 [13] Zhang D, Javed O, Shah M. Video object co-segmentation by regulated maximum weight cliques. In:Proceedings of the 13th European Conference on Computer Vision. Zurich, Switzerland:Springer, 2014. 551-566 doi: 10.1007%2F978-3-319-10584-0_36 [14] Fu H Z, Xu D, Zhang B, Lin S. Object-based multiple foreground video co-segmentation. In:Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus, Ohio, USA:IEEE, 2014. 3166-3173 [15] Wang W G, Shen J B, Li X L, Porikli F. Robust video object cosegmentation. IEEE Transactions on Image Processing, 2015, 24(10):3137-3148 doi: 10.1109/TIP.2015.2438550 [16] Guo J M, Li Z W, Cheong L F, Zhou S Z. Video co-segmentation for meaningful action extraction. In:Proceedings of the 2013 IEEE International Conference on Computer Vision. Sydney, Australia:IEEE, 2013. 2232-2239 [17] Wang H, Kläser A, Schmid C, Liu C L. Action recognition by dense trajectories. In:Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition. Providence, RI:IEEE, 2011. 3169-3176 [18] Tang J, Shao L, Li X L. Efficient dictionary learning for visual categorization. Computer Vision and Image Understanding, 2014, 124:91-98 doi: 10.1016/j.cviu.2014.02.007 [19] Yang F, Jiang Z L, Davis L S. Submodular reranking with multiple feature modalities for image retrieval. In:Proceedings of the 12th Asian Conference on Computer Vision. Singapore:Springer, 2015. 19-34 http://www.umiacs.umd.edu/~fyang/papers/accv14.pdf [20] Xu J, Mukherjee L, Li Y, Warner J, Rehg J M, Singht V. Gaze-enabled egocentric video summarization via constrained submodular maximization. In:Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, Massachusetts, USA:IEEE, 2015. 2235-2244 [21] Gygli M, Grabner H, van Gool L. Video summarization by learning submodular mixtures of objectives. In:Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, Massachusetts, USA:IEEE, 2015. 3090-3098 [22] Leordeanu M, Hebert M. A spectral technique for correspondence problems using pairwise constraints. In:Proceedings of the 10th IEEE International Conference on Computer Vision. Beijing, China:IEEE, 2005. 1482-1489 [23] Cho M, Lee J, Lee K M. Reweighted random walks for graph matching. In:Proceedings of the 11th European Conference on Computer Vision. Crete, Greece:Springer, 2010. 492-505 doi: 10.1007%2F978-3-642-15555-0_36 [24] Dalal N, Triggs B, Schmid C. Human detection using oriented histograms of flow and appearance. In:Proceedings of the 9th European Conference on Computer Vision. Graz, Austria:Springer, 2006. 428-441 http://www.oalib.com/references/17185810 [25] Lovász L. Submodular functions and convexity. Mathematical Programming the State of the Art. Berlin Heidelberg:Springer, 1983. 235-257 doi: 10.1007%2F978-3-642-68874-4_10 [26] Jiang Z L, Davis L S. Submodular salient region detection. In:Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition. Portland, OR:IEEE, 2013. 2043-2050 [27] Boykov Y, Veksler O, Zabih R. Fast approximate energy minimization via graph cuts. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2001, 23(11):1222-1239 doi: 10.1109/34.969114 -

 下载:
下载:

计量
- 文章访问数: 2797
- HTML全文浏览量: 506
- PDF下载量: 540
- 被引次数: 0
