

-
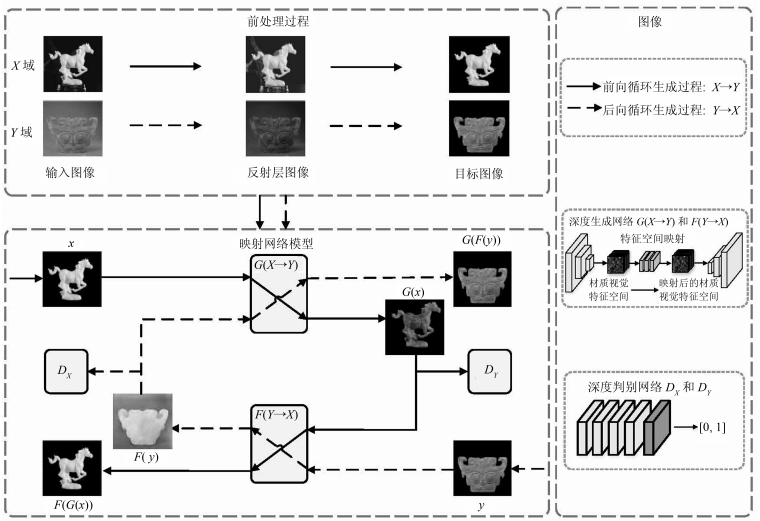
摘要: 针对自然场景图像目标材质视觉特征映射中,尚存在特征提取困难、图像无对应标签等问题,本文提出了一种自然场景图像的目标材质视觉特征映射算法.首先,从图像中获取能表征材质视觉重要特征的反射层图像;然后,对获取的反射层图像进行前景、背景分割,得到目标图像;最后,利用循环生成对抗网络对材质视觉特征进行无监督学习,获得对图像目标材质视觉特征空间的高阶表达,实现了目标材质视觉特征的映射.实验结果表明,所提算法能够有效地获取自然场景图像目标的材质视觉特征,并进行材质视觉特征映射;与同类算法相比,具有更好的主、客观效果.Abstract: The natural scene image object material visual feature mapping is still a challenging task, such as the difficulties of feature extraction and images without corresponding labels. A material visual features mapping algorithm with natural scene image object is proposed in this paper. First, the proposed algorithm extracts the reflection layer image that can represent the essential features of the material vision, then it divides the acquired reflection layer image into the segmentation of foreground and background to obtain the object image. Finally, the cycle-GAN (Generative adversarial network) is used for the unsupervised learning of the material visual features, and the visual features of image object is obtained. The high level expression of material visual feature space can achieve the mapping of visual characteristics of object material. The experiment results show that the algorithm can obtain the visual features of the natural scene image object and carry on the material visual feature mapping much better. Compared with the existing methods for material visual feature mapping, the proposed algorithm achieves better subjective and objective effects.
-
Key words:
- Natural scene image /
- material visual feature /
- feature mapping /
- cycle-GAN
1) 本文责任编委 张军平 -
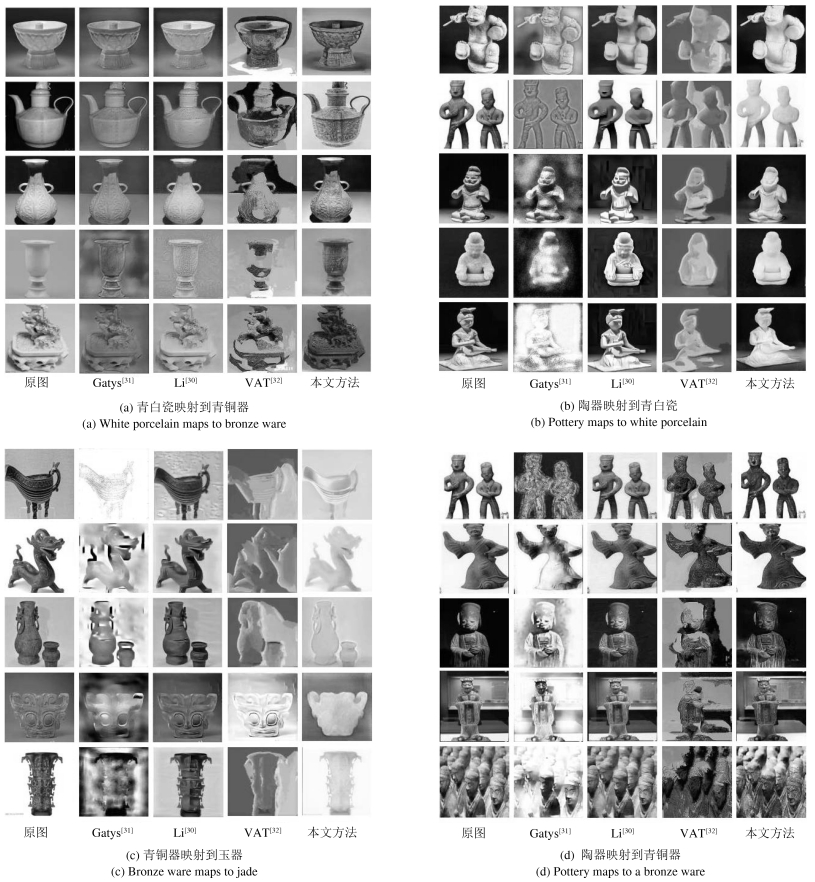
表 1 平均梯度与局部信息熵对比结果
Table 1 Comparison in terms of both the average gradient and the local information entropy
对比方法 青白瓷映射到青铜器 陶器映射到青白瓷 青铜器映射到玉器 陶器映射到青铜器 mAP 平均梯度 局部信息熵 平均梯度 局部信息熵 平均梯度 局部信息熵 平均梯度 局部信息熵 平均梯度 局部信息熵 Gatys[31] 0.020 3.470 0.030 3.884 0.024 3.457 0.022 3.937 0.024 3.687 Li[30] 0.017 4.425 0.030 4.134 0.023 3.906 0.042 4.956 0.028 4.356 VAT[32] 0.025 4.279 0.043 4.391 0.031 4.368 0.101 4.639 0.050 4.419 Ours 0.042 4.796 0.056 4.554 0.029 4.652 0.117 4.462 0.061 4.616  下载: 导出CSV
下载: 导出CSV
表 2 IL-QINE与MEON对比结果
Table 2 Comparison in terms of both the IL-QINE and the MEON
对比方法 青白瓷映射到青铜器 陶器映射到青白瓷 青铜器映射到玉器 陶器映射到青铜器 mAP IL-QINE MEON IL-QINE MEON IL-QINE MEON IL-QINE MEON IL-QINE MEON Gatys[31] 61.946 50.513 69.141 25.403 54.519 22.457 49.441 38.496 58.762 34.217 Li[30] 57.231 42.357 52.973 40.510 48.956 55.490 43.268 42.449 50.607 45.201 VAT[32] 52.932 16.013 50.618 51.271 50.280 45.226 45.257 29.625 49.771 35.534 Ours 46.689 17.309 49.372 6.709 47.817 12.917 43.021 14.955 46.725 12.973
下载: 导出CSV
-
[1] Fleming R W. Material perception. Annual Review of Vision Science, 2017, 3(1):365-388 doi: 10.1146/annurev-vision-102016-061429 [2] 仲训杲, 徐敏, 仲训昱, 彭侠夫.基于多模特征深度学习的机器人抓取判别方法.自动化学报, 2016, 42(7):1022-1029 http://www.aas.net.cn/CN/abstract/abstract18893.shtmlZhong Xun-Gao, Xu Min, Zhong Xun-Yu, Peng Xia-Fu. Multimodal features deep learning for robotic potential grasp recognition. Acta Automatica Sinica, 2016, 42(7):1022-1029 http://www.aas.net.cn/CN/abstract/abstract18893.shtml [3] 贾丙西, 刘山, 张凯祥, 陈剑.机器人视觉伺服研究进展:视觉系统与控制策略.自动化学报, 2015, 41(5):861-873 http://www.aas.net.cn/CN/abstract/abstract18661.shtmlJia Bing-Xi, Liu Shan, Zhang Kai-Xiang, Chen Jian. Survey on robot visual servo control:Vision system and control strategies. Acta Automatica Sinica, 2015, 41(5):861-873 http://www.aas.net.cn/CN/abstract/abstract18661.shtml [4] Khan E A, Reinhard E, Fleming R W, Bülthofff H H. Image-based material editing. ACM Transactions on Graphics, 2006, 25(3):654-663 doi: 10.1145/1141911 [5] Boyadzhiev I, Bala K, Paris S, Adelson E. Band-sifting decomposition for image-based material editing. ACM Transactions on Graphics, 2015, 34(5):163-179 http://cn.bing.com/academic/profile?id=29645f175afc7d4b468abb4ee5677e55&encoded=0&v=paper_preview&mkt=zh-cn [6] 刘昊, 李哲, 石晶, 辛敏思, 蔡红星, 高雪, 谭勇.基于卷积神经网络的材质分类识别研究.激光与红外, 2017, 47(8):1024-1028 doi: 10.3969/j.issn.1001-5078.2017.08.019Liu Hao, Li Zhe, Shi Jing, Xin Min-Si, Cai Hong-Xing, Gao Xue, Tan Yong. Study on classification and recognition of materials based on convolutional neural network. Laser & Infrared, 2017, 47(8):1024-1028 doi: 10.3969/j.issn.1001-5078.2017.08.019 [7] 李婉婉.基于卷积神经网络和集成学习的材质识别和分割方法研究[硕士学位论文], 北京交通大学, 中国, 2018Li Wan-Wan. Ensemble Learning for Material Recognition and Segmentation with Convolutional Neural Networks[Master thesis], Beijing Jiaotong University, China, 2018 [8] 郑军庭, 李建, 李建勋.径向基函数神经网络在超宽带探地雷达目标材质识别中的应用.上海交通大学学报, 2006, 40(1):98-102 doi: 10.3321/j.issn:1006-2467.2006.01.023Zheng Jun-Ting, Li Jian, Li Jian-Xun. The application of RBF neural network in material recognition ultra wideband ground penetrating radar. Journal of Shanghai Jiaotong University, 2006, 40(1):98-102 doi: 10.3321/j.issn:1006-2467.2006.01.023 [9] Tang Y C, Salakhutdinov R, Hinton G. Deep lambertian networks. In: Proceedings of the 2012 International Conference on Machine Learning. Edinburgh, Scotland: ACM, 2012. 1623-1630 [10] Richter S R, Roth S. Discriminative shape from shading in uncalibrated illumination. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, MA, USA: IEEE, 2015. 1128-1136 [11] Zhou T H, Krahenbuhl P, Efros A A. Learning data-driven reflectance priors for intrinsic image decomposition. In: Proceedings of the 2015 IEEE International Conference on Computer Vision. Santiago, Chile: IEEE, 2015. 3469-3477 [12] Narihira T, Maire M, Yu S X. Direct intrinsics: learning albedo-shading decomposition by convolutional regression. In: Proceedings of the 2015 IEEE International Conference on Computer Vision. Santiago, Chile: IEEE, 2015. 2992-3001 [13] Kulkarni T D, Whitney W F, Kohli P, Tenenbaum J. Deep convolutional inverse graphics network. In: Proceedings of the 2015 Annual Conference on Neural Information Processing Systems. Montreal, Canada: MIT Press, 2015. 2539-2547 [14] Rematas K, Ritschel T, Fritz M, Gavves E, Tuytelaars T. Deep reflectance maps. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, NV, USA: IEEE, 2016. 4508-4516 [15] Liu G, Ceylan D, Yumer E, Yang J M, Lien J M. Material editing using a physically based rendering network. In: Proceedings of the 2017 IEEE International Conference on Computer Vision. Venice, Italy: IEEE, 2017. 2261-2269 [16] Zhu J Y, Park T, Isola P, Efros A A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In: Proceedings of the 2017 IEEE International Conference on Computer Vision. Venice, Italy: IEEE, 2017. 2223-2232 [17] Goodfellow I J, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, Ozair S, et al. Generative adversarial nets. In: Proceedings of the 2014 Annual Conference on Neural Information Processing Systems. Montreal, Canada: MIT Press, 2014. 2672-2680 [18] 王坤峰, 苟超, 段艳杰, 林懿伦, 郑心湖, 王飞跃.基于多模特征深度学习的机器人抓取判别方法.自动化学报, 2017, 43(3):321-332 http://www.aas.net.cn/CN/abstract/abstract18893.shtmlWang Kun-Feng, Gou Chao, Duan Yan-Jie, Lin Yi-Lun, Zheng Xin-Hu, Wang Fei-Yue. Generative adversarial networks:the state of the art and beyond. Acta Automatica Sinica, 2017, 43(3):321-332 http://www.aas.net.cn/CN/abstract/abstract18893.shtml [19] 姚乃明, 郭清沛, 乔逢春, 陈辉, 王宏安.基于生成式对抗网络的鲁棒人脸表情识别.自动化学报, 2018, 44(5):865-877 http://www.aas.net.cn/CN/abstract/abstract19278.shtmlYao Nai-Ming, Guo Qing-Pei, Qiao Feng-Chun, Chen Hui, Wang Hong-An. Robust facial expression recognition with generative adversarial networks. Acta Automatica Sinica, 2018, 44(5):865-877 http://www.aas.net.cn/CN/abstract/abstract19278.shtml [20] 唐贤伦, 杜一铭, 刘雨微, 李佳歆, 马艺玮.基于条件深度卷积生成对抗网络的图像识别方法.自动化学报, 2018, 44(5):855-864 http://www.aas.net.cn/CN/abstract/abstract19277.shtmlTang Xian-Lun, Du Yi-Ming, Liu Yu-Wei, Li Jia-Xin, Ma Yi-Wei. Image recognition with conditional deep convolutional generative adversarial networks. Acta Automatica Sinica, 2018, 44(5):855-864 http://www.aas.net.cn/CN/abstract/abstract19277.shtml [21] Zhu Y, Zhang Z Y. Research on users' product material perception. In: Proceedings of the 2010 IEEE International Conference on Computer-aided Industrial Design & Conceptual Design. Wenzhou, China: IEEE, 2010. 1277-1280 [22] Land E H, McCann J J. Lightness and retinex theory. Journal of the Optical Society of America, 1971, 61(1):1-11 doi: 10.1364/JOSA.61.000001 [23] Fleming R W. Visual perception of materials and their properties. Vision Research, 2014, 94(1):62-75 http://cn.bing.com/academic/profile?id=47715d8615dc46b4bba0631eb9a4f529&encoded=0&v=paper_preview&mkt=zh-cn [24] Zhang H, Dana K, Nishino K. Reflectance hashing for material recognition. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, MA, USA: IEEE, 2015. 3071-3080 [25] Tomasi C, Manduchi R. Bilateral filtering for gray and color images. In: Proceedings of the 1998 IEEE International Conference on Computer Vision. Bombay, India: IEEE, 1998. 839-846 [26] Ben S M, Mitiche A, Ben A I. Multiregion image segmentation by parametric kernel graph cuts. IEEE Transactions on Image Processing, 2011, 20(2):545-557 doi: 10.1109/TIP.2010.2066982 [27] Ioffe S, Szegedy C. Batch normalization: Accelerating deepnetwork training by reducing internal covariate shift. In: Proceedings of the 2015 International Conference on Machine Learning. Lille, France: ACM, 2015. 448-456 [28] He K M, Zhang X Y, Ren S Q, Sun J. Deep residual learning for image recognition. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, NV, USA: IEEE, 2016. 770-778 [29] Springenberg J T, Dosovitskiy A, Brox T, Riedmiller M. Striving for simplicity: The all convolutional net. In: Proceedings of the 2015 International Conference on Learning Representations. San Diego, CA, USA: IEEE, 2015. 1-14 [30] Johnson J, Alahi A, Li F F. Perceptual losses for real-time style transfer and super-resolution. In: Proceedings of the 2016 European Conference on Computer Vision. Amsterdam, The Netherlands: Springer, 2016. 694-711 [31] Gatys L A, Ecker A S, Bethge M. Image style transfer using convolutional neural networks. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, NV, USA: IEEE, 2016. 2414-2423 [32] Liao J, Yao Y, Yuan L, Hua G, Kang S B. Visual attribute transfer through deep image analogy. ACM Transactions on Graphics, 2017, 36(4):1-15 http://cn.bing.com/academic/profile?id=59eb0d68a1f11e6453c924a44f0fcd94&encoded=0&v=paper_preview&mkt=zh-cn [33] Zhang L, Zhang L, Bovik A C. A feature-enriched completely blind image quality evaluator. IEEE Transactions on Image Processing, 2015, 24(8):2579-2591 doi: 10.1109/TIP.2015.2426416 [34] Ma K D, Liu W T, Zhang K, Duanmu Z F, Wang Z, Zuo W M. End-to-end blind image quality assessment using deep neural networks. IEEE Transactions on Image Processing, 2018, 27(3):1202-1213 doi: 10.1109/TIP.2017.2774045 -

 下载:
下载:


图(7) / 表(2)
计量
- 文章访问数: 2132
- HTML全文浏览量: 391
- PDF下载量: 420
- 被引次数: 0
