

-
摘要: 近年来, 大语言模型研究取得了突破性进展. 本文针对大模型分布式训练中通信开销高、算力利用率低的问题, 提出了一种基于Adam-mini优化器的单比特通信压缩算法——单比特Adam-mini. 该算法通过减少二阶动量参数, 使得能够以较小的通信代价精确计算全局二阶动量, 从而简化了通信误差补偿机制的设计. 单比特Adam-mini不仅避免了现有单比特Adam算法中通信开销较大的预热阶段, 还具备可证明的线性加速性质, 确保了分布式训练的高效性. 实验结果表明, 该算法在多种任务上表现优异, 并且可以兼容稀疏压缩器, 为大模型训练提供了更高效的解决方案.Abstract: Recent advancements in large language models (LLMs) research have achieved remarkable breakthroughs. This paper tackles the challenges of high communication costs and low computational efficiency in distributed training for large models by introducing a one-bit communication compression algorithm based on the Adam-mini optimizer, named 1-bit Adam-mini. By significantly reducing the number of second-order momentum parameters through aggregation strategies, our algorithm achieves full-precision global synchronization of second-order momentum with minimal communication overhead. Additionally, by incorporating an error feedback mechanism, 1-bit Adam-mini not only eliminates the communication-intensive warm-up phase required by existing 1-bit Adam algorithms but also provides provable linear speedup properties. Experimental results demonstrate that the algorithm exhibits exceptional performance across a variety of tasks and can be seamlessly extended to sparse compressors, presenting a more efficient solution for large-scale model training.1)
1 1 本文中的算力利用率是指集群的实际每秒浮点运算次数与理论峰值每秒浮点运算次数的比值.2)2 2 线性加速性质是指, 当算法收敛至指定精度时, 所需的迭代次数随着计算节点数量的增加而线性减少.3)3 3https://rajpurkar.github.io/SQuAD-explorer/ 4https://huggingface.co/datasets/allenai/c4 5https://www.cs.toronto.edu/kriz/cifar.html -
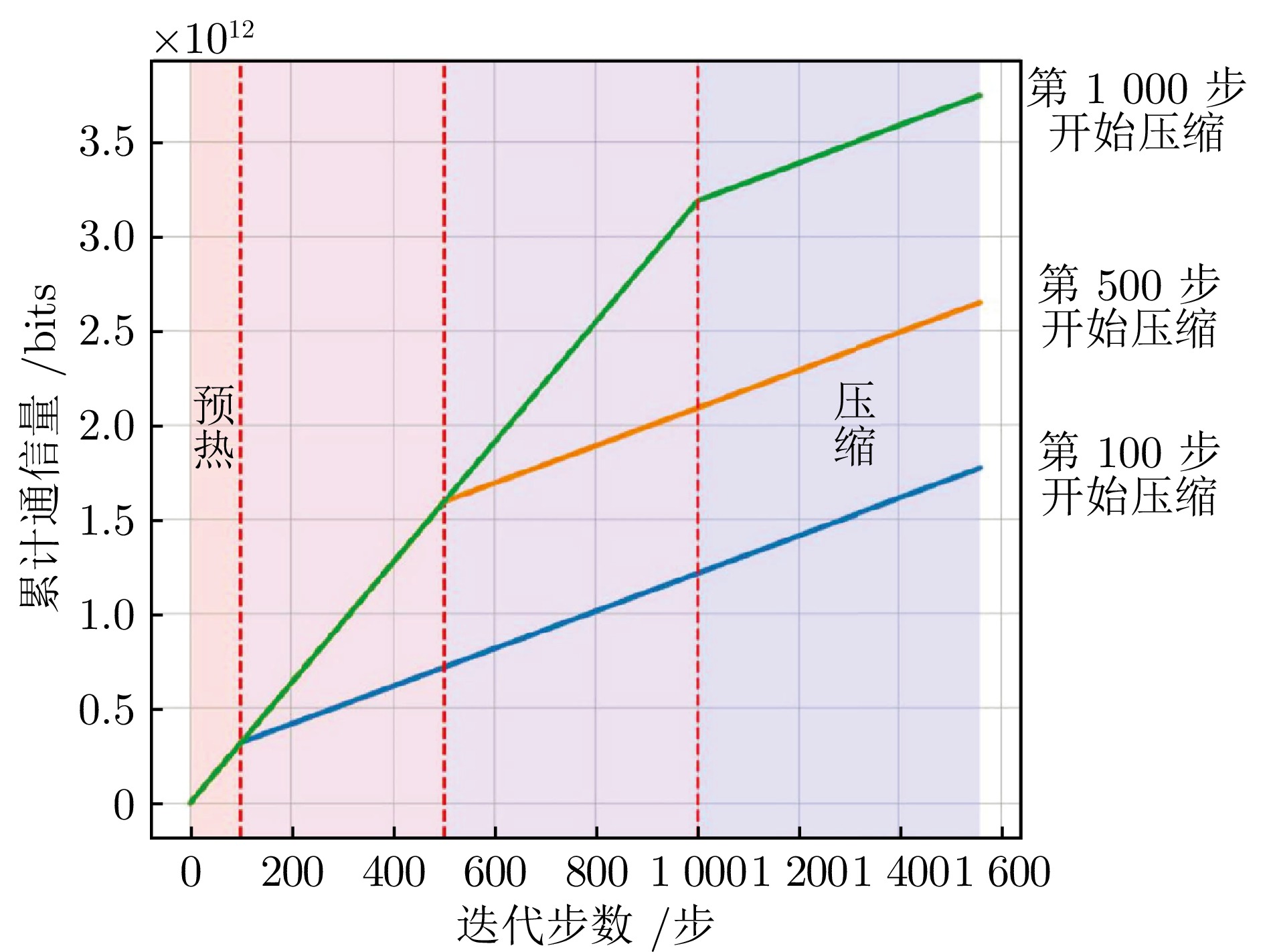
图 1 单比特Adam算法累积通信量与迭代步数的关系图
Fig. 1 Relationship between accumulated communication and optimization steps for 1-bit Adam
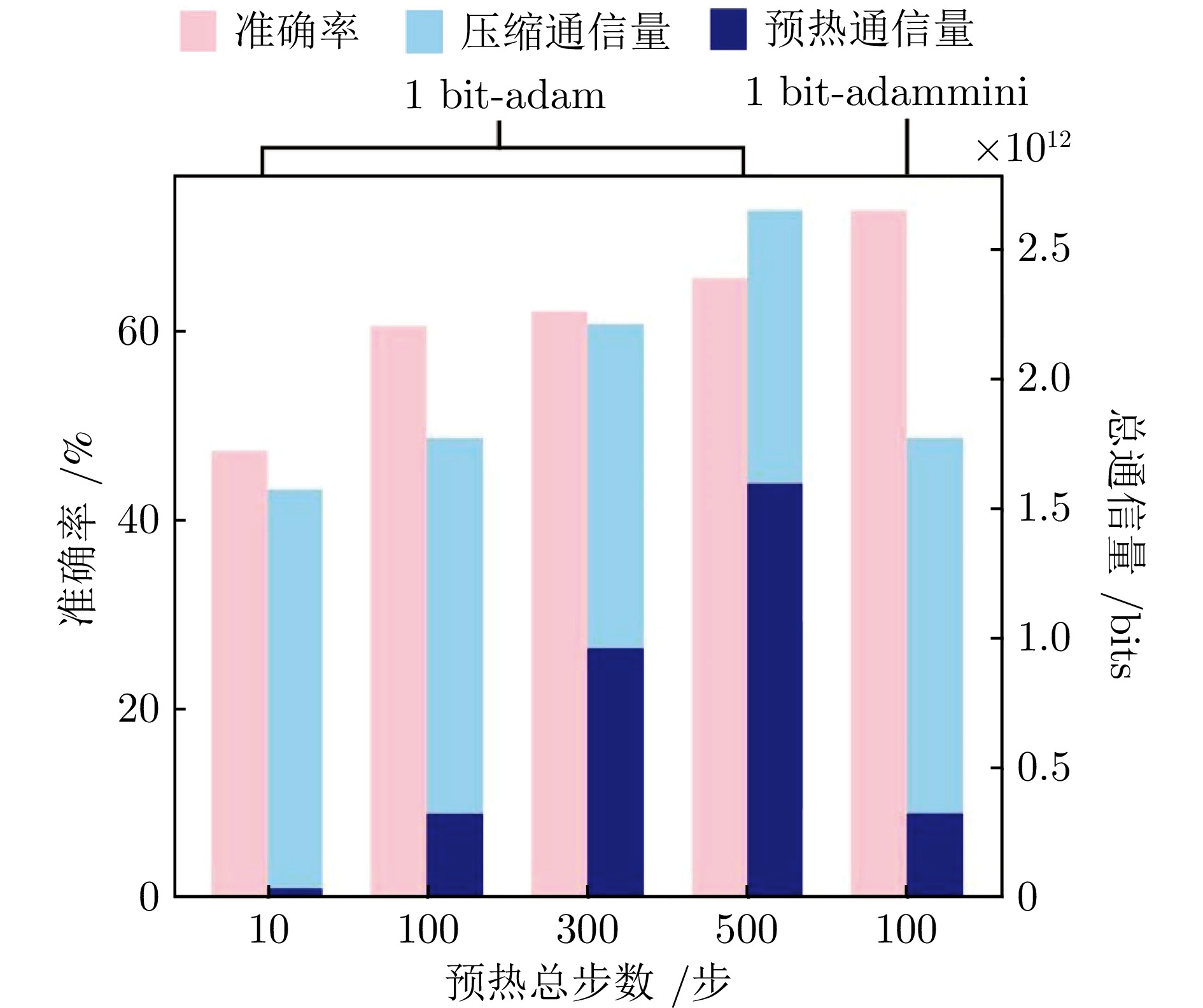
图 2 单比特 Adam 和单比特 Adam-mini 在不同预热步数下的总通信量开销比例与准确率对比图
Fig. 2 Accuracy and proportion of total communication overhead comparison between the 1-bit Adam algorithm and the 1-bit Adam-mini algorithm
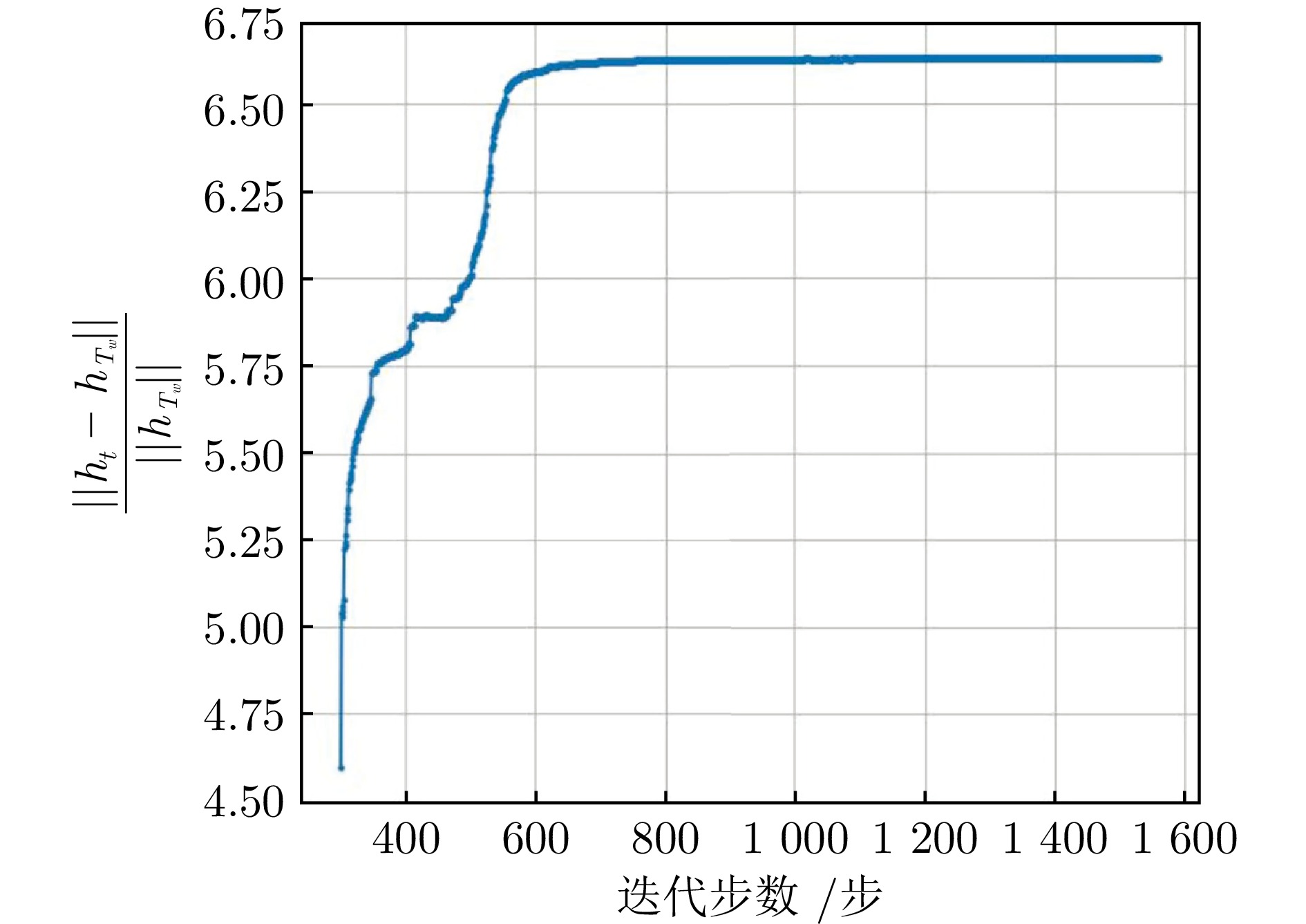
图 3 $\|{\boldsymbol{h}}_t - {\boldsymbol{h}}_{T_w}\| / \|{\boldsymbol{h}}_{T_w}\|$与迭代步数关系图
Fig. 3 Relationship between $\|{\boldsymbol{h}}_t - {\boldsymbol{h}}_{T_w}\| / \|{\boldsymbol{h}}_{T_w}\|$ and optimization steps
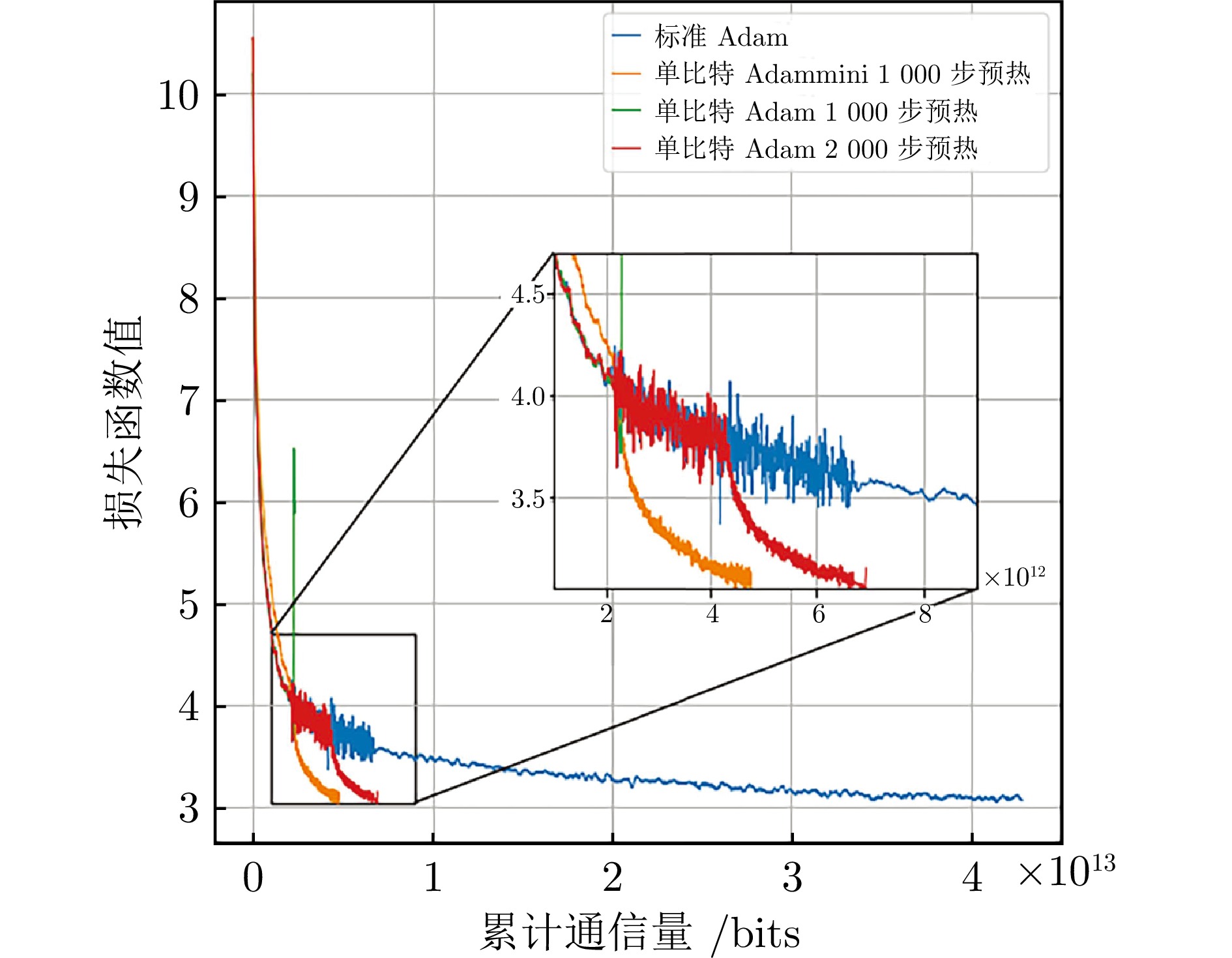
图 4 LLaMA预训练任务中训练损失与通信量关系曲线
Fig. 4 Curve between training loss and communication bits in LLaMA pre-training tasks
表 1 非凸光滑假设下单比特Adam-mini与其他通信压缩算法对比
Table 1 Comparison between 1-bit Adam-mini and other communication-compression algorithms under the non-convex smoothness assumption
算法 Adam兼容性 无需预热 压缩种类 单机收敛速率 多机收敛速率 Parallel SGD/Adam √ √ 无压缩 $ \dfrac{\sigma}{\sqrt{T}} + \dfrac{1}{T} $ $ \dfrac{\sigma}{\sqrt{nT}} + \dfrac{1}{T} $ DoubleSqueeze[30] × √ 双向压缩 $ \dfrac{\sigma}{\sqrt{T}} + \dfrac{\epsilon^{2/3}}{T^{2/3}} + \dfrac{1}{T} $ $ \dfrac{\sigma}{\sqrt{nT}} + \dfrac{\epsilon^{2/3}}{T^{2/3}} + \dfrac{1}{T} $ 1-bit Adam[25] √ × 双向压缩 $ \dfrac{\sigma}{\sqrt{T}} + \dfrac{\epsilon^{2/3}}{T^{2/3}} + \dfrac{1}{T} $ $ \dfrac{\sigma}{\sqrt{nT}} + \dfrac{\epsilon^{2/3}}{T^{2/3}} + \dfrac{1}{T} $ QAdam[23] √ √ 单向压缩+权重压缩 $ \dfrac{1}{\sqrt{T}} $ $ \dfrac{1}{\sqrt{T}} $ Comp-AMS[31] √ √ 单向压缩 $ \dfrac{\sigma^2 +1}{\sqrt{T}} + \dfrac{1}{T} $ $ \dfrac{\sigma^2 +1}{\sqrt{nT}} + \dfrac{1}{T} $ Efficient Adam[24] √ √ 双向压缩 $ \dfrac{1}{\sqrt{T}} $ × 1-bit Adam-mini (本文) √ √ 双向压缩 $ \dfrac{\sigma}{\sqrt{T}} + \dfrac{1}{T} $ $ \dfrac{\sigma}{\sqrt{nT}} + \dfrac{1}{T} $  下载: 导出CSV
下载: 导出CSV
表 2 在CIFAR数据集上预训练ResNet18模型的结果
Table 2 Results of pretraining ResNet18 model on CIFAR dataset
算法 损失 准确率(%) 时间(秒/步) Adam 0.0118 92.06 0.0724 Adam-mini 0.0141 91.55 0.0728 1-bit Adam 0.0136 91.02 0.0557 Efficient Adam 0.0048 91.68 0.0530 Comp-AMS 0.0171 92.02 0.0538 1-bit Adam-mini 0.0235 92.08 0.0598 注: 加粗字体表示最优结果.
下载: 导出CSV
表 3 CIFAR数据集微调ViT-L/16模型的结果
Table 3 Results of finetuning ViT-L/16 on CIFAR
算法 准确率 损失 预热步数 学习率 训练循环数 Adam 97.79 0.0003 — $ 1\times10^{-5} $ 10 1-bit Adam 13.19 2.229 10 $ 1\times10^{-5} $ 10 1-bit Adam-mini 97.51 0.0006 10 $ 1\times10^{-5} $ 10 Adam 97.63 0.0002 — $ 5\times10^{-5} $ 10 1-bit Adam 11.76 2.296 10 $ 5\times10^{-5} $ 10 1-bit Adam-mini 96.7 0.0003 10 $ 5\times10^{-5} $ 10 注: 加粗字体表示最优结果.
下载: 导出CSV
表 4 GLUE数据集微调RoBERTa-base模型的测试准确率(SST2, QNLI, RTE)和皮尔森系数(STS-B)
Table 4 Test accuracy (SST2, QNLI, RTE) and pearson coefficient (STS-B) of finetuning RoBERTa-base on GLUE
算法 SST2 QNLI RTE STS-B (P) 时间 (秒/步) Adam 94.84 92.57 73.65 0.90 0.2757 Adam-mini 93.69 89.07 48.74 0.72 0.2800 vanilla 1-bit Adam 90.60 87.79 55.96 0.66 0.1405 1-bit Adam 93.58 91.47 60.65 −0.03 0.1412 Comp-AMS 92.43 88.83 70.40 0.89 0.1401 Efficient Adam 92.78 88.80 68.23 0.89 0.1563 1-bit Adam-mini 94.15 92.09 72.92 0.90 0.1482 注: 加粗字体表示最优结果.
下载: 导出CSV
表 5 GLUE数据集微调DeBERTa-v2-xxlarge模型的测试准确率与F1值(MRPC)
Table 5 Test accuracy and F1 score of finetuned DeBERTa-v2-xxlarge models on GLUE dataset (MRPC)
优化算法 MRPC (Acc) MRPC (F1) 运行时间(秒/步) Adam 91.18 93.68 2.2085 1-bit Adam 89.95 92.79 0.9488 Comp-AMS 83.09 88.56 0.9421 Efficient Adam 84.07 89.15 1.1588 1-bit Adam-mini 90.44 93.07 1.0039 注: 加粗字体表示最优结果.
下载: 导出CSV
表 6 Math-10k数学数据集微调LLaMA-7B模型的测试准确率(GSM8K, SVAMP, AQuA, MultiArith)
Table 6 Test accuracy (GSM8K, SVAMP, AQuA, MultiArith) of finetuned LLaMA-7B on Math-10K dataset
算法 GSM8K SVAMP AQuA MultiArith Adam 32.6 43.1 17.71 92.33 1-bit Adam 27.14 36.5 13.38 88.17 1-bit Adam-mini 31.16 40.4 14.56 91.5 注: 加粗字体表示最优结果.
下载: 导出CSV
表 7 SQuAD数据集微调BERT-large模型的测试准确率
Table 7 Test accuracy of finetuned BERT-large models on SQuAD dataset
优化算法 Adam Adam-mini 压缩器 1-bit top 5% 1-bit top 5% 预热步数$ =20 $ 78.32 — 86.51 85.74 预热步数$ =100 $ 86.28 85.67 86.71 86.17 预热步数$ =+\infty $ 86.93 86.93 86.49 86.49 注: 加粗字体表示最优结果.
下载: 导出CSV
表 8 SQuAD数据集微调BERT-large模型的测试准确率
Table 8 Test accuracy of finetuned BERT-large models on SQuAD dataset
优化算法 1-bit Adam-mini 是否使用AMS技巧 w/AMS wo/AMS 预热步数$ =20 $ 85.76 86.51 预热步数$ =100 $ 86.32 86.71 预热步数$ =+\infty $ 86.49 86.45 注: 加粗字体表示最优结果.
下载: 导出CSV
-
[1] Grattafiori A, Dubey A, Jauhri A, Pandey A, Kadian A, Al-Dahle A, et al. The llama 3 herd of models. arXiv preprint arXiv: 2407.21783, 2024 [2] Mesnard T, Hardin C, Dadashi R, Bhupatiraju S, Pathak S, Sifre L, et al. Gemma: Open models based on gemini research and technology. arXiv preprint arXiv: 2403.08295, 2024 [3] Liu H, Li C, Wu Q, Lee Y J. Visual instruction tuning. In: Proceedings of the 37th International Conference on Neural Information Processing Systems. New Orleans, USA: 2023. 34892−34916 [4] Achiam J, Adler S, Agarwal S, Ahmad L, Akkaya I, Aleman F L, et al. GPT-4 technical report. arXiv preprint arXiv: 2303.08774, 2023 [5] Liu A Feng B, Xue B, Wang B, Wu B, Lu C, et al. DeepSeek-V3 technical report. arXiv preprint arXiv: 2412.19437, 2024 [6] Anil R, Borgeaud S, Alayrac J B, Yu J, Soricut R, Schalkwyk J, et al. Gemini: A family of highly capable multimodal models. arXiv preprint arXiv: 2312.11805, 2023 [7] Shoeybi M, Patwary M, Puri R, LeGresley P, Casper J, Catanzaro B. Megatron-LM: Training multi-billion parameter language models using model parallelism. arXiv preprint arXiv: 1909.08053, 2019 [8] Narayanan D, et al. Efficient large-scale language model training on GPU clusters using Megatron-LM. In: Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis. Saint Louis, USA: 2021. 1−15 [9] Brown T, Mann B, Ryder N, Subbiah M, Kaplan J D, Dhariwal P, et al. Language models are few-shot learners. In: Proceedings of the 34th International Conference on Neural Information Processing Systems. Vancouver, Canada: 2020. 1877−1901 [10] Zhang S, Roller S, Goyal N, Artetxe M, Chen M, Chen S, et al. OPT: Open pre-trained transformer language models. arXiv preprint arXiv: 2205.01068, 2022 [11] Dan A, Grubic D, Li J Z, Tomioka R, Vojnovic M. QSGD: Communication-efficient SGD via gradient quantization and encoding. In: Proceedings of the 31st International Conference on Neural Information Processing Systems. Long Beach, USA: 2017. 1707−1718 [12] Bernstein J, Wang Y X, Azizzadenesheli K, Anandkumar A. SignSGD: Compressed optimisation for non-convex problems. In: Proceedings of the 35th International Conference on Machine Learning. Stockholm, Sweden: PMLR, 2018. 560−569 [13] Stich S U, Cordonnier J B, Jaggi M. Sparsified SGD with memory. In: Proceedings of the 32nd International Conference on Neural Information Processing Systems. Montréal, Canada: 2018. 4452−4463 [14] Richtárik P, Sokolov I, Fatkhullin I. EF21: A new, simpler, theoretically better, and practically faster error feedback. In: Proceedings of the 35th International Conference on Neural Information Processing Systems. Virtual Event: 2021. 4384−4396 [15] Huang X, Chen Y, Yin W, Yuan K. Lower bounds and nearly optimal algorithms in distributed learning with communication compression. In: Proceedings of the 36th International Conference on Neural Information Processing Systems. New Orleans, USA: 2022. 18955−18969 [16] Ramasinghe S, Ajanthan T, Avraham G, Zuo Y, Long A. Protocal models: Scaling decentralized training with communication-efficient model parallelism. arXiv preprint arXiv: 2506.01260, 2025 [17] Horvóth S, Ho C Y, Horvath L, Sahu A N, Canini M, Richtárik P. Natural compression for distributed deep learning. Mathematical and Scientific Machine Learning. Beijing, China: PMLR, 2022. 129−141 [18] Seide F, Fu H, Droppo J, Li G, Yu D. 1-bit stochastic gradient descent and its application to data-parallel distributed training of speech DNNs. In: Proceedings of Interspeech. Singapore: 2014. 1058−1062 [19] Li S, Xu W, Wang H, Tang X, Qi Y, Xu S, et al. FedBAT: communication-efficient federated learning via learnable binarization. In: Proceedings of the 41st International Conference on Machine Learning. Vienna, Austria: PMLR, 2024. 29074−29095 [20] Wangni J, Wang J, Liu J, Zhang T. Gradient sparsification for communication-efficient distributed optimization. In: Proceedings of the 32nd International Conference on Neural Information Processing Systems. Montréal, Canada: 2018. 1306−1316 [21] Kingma D P, Ba J. Adam: A method for stochastic optimization. arXiv preprint arXiv: 1412.6980, 2014 [22] Fatkhullin I, Tyurin A, Richtárik P. Momentum provably improves error feedback! In: Proceedings of the 38th International Conference on Neural Information Processing Systems. Vancouver, Canada: 2024. 76444−76495 [23] Chen C, Shen L, Huang H, Liu W. Quantized adam with error feedback. ACM Transactions on Intelligent Systems and Technology (TIST), 2021, 12(5): 1−26 [24] Chen C, Shen L, Liu W, Luo Z Q. Efficient-Adam: Communication-Efficient Distributed Adam. IEEE Transactions on Signal Processing, 2023, 71: 3257−3266 doi: 10.1109/TSP.2023.3309461 [25] Tang H, Gan S, Awan A A, Rajbhandari S, Li C, Lian X, et al. 1-bit adam: Communication efficient large-scale training with adam’s convergence speed. In: Proceedings of the 38th International Conference on Machine Learning. Virtual Event: PMLR, 2021. 10118−10129 [26] Zhang Y, Chen C, Li Z, Ding T, Wu C, Kingma D P, et al. Adam-mini: Use fewer learning rates to gain more. arXiv preprint arXiv: 2406.16793, 2024 [27] Dean J, Corrado G, Monga R, Chen K, Devin M, Mao M, et al. Large scale distributed deep networks. In: Proceedings of the 26th International Conference on Neural Information Processing Systems. Nevada, USA: 2012. 1223−1231 [28] Huang Y, Cheng Y, Bapna A, Firat O, Chen D, Chen M, et al. Gpipe: Efficient training of giant neural networks using pipeline parallelism. In: Proceedings of the 33rd International Conference on Neural Information Processing Systems. Vancouver, Canada: 2019. 103−112 [29] Narayanan D, Harlap A, Phanishayee A, Seshadri V, Devanur N R, Ganger G R, et al. PipeDream: Generalized pipeline parallelism for DNN training. In: Proceedings of the 27th ACM Symposium on Operating Systems Principles. Huntsville, Canada: 2019. 1−15 [30] Tang H, Yu C, Lian X, Zhang T, Liu J. Doublesqueeze: Parallel stochastic gradient descent with double-pass error-compensated compression. In: Proceedings of the 36th International Conference on Machine Learning. Long Beach, USA: PMLR, 2019. 6155−6165 [31] Li X, Karimi B, Li P. On distributed adaptive optimization with gradient compression. arXiv preprint arXiv: 2205.05632, 2022 [32] Nedic A, Ozdaglar A. Distributed subgradient methods for multi-agent optimization. IEEE Transactions on Automatic Control, 2009, 54(1): 48−61 doi: 10.1109/TAC.2008.2009515 [33] Lopes C G, Sayed A H. Diffusion least-mean squares over adaptive networks: Formulation and performance analysis. IEEE Transactions on Signal Processing, 2008, 56(7): 3122−3136 doi: 10.1109/TSP.2008.917383 [34] Xu J, Zhu S, Soh Y C, Xie L. Augmented distributed gradient methods for multi-agent optimization under uncoordinated constant stepsizes. IEEE Conference on Decision and Control (CDC), 20152055−2060 [35] Nedic A, Olshevsky A, Shi W. Achieving geometric convergence for distributed optimization over time-varying graphs. SIAM Journal on Optimization, 2017, 27(4): 2597−2633 doi: 10.1137/16M1084316 [36] Shi W, Ling Q, Wu G, Yin W. Extra: An exact first-order algorithm for decentralized consensus optimization. SIAM Journal on Optimization, 2015, 25(2): 944−966 doi: 10.1137/14096668X [37] Yuan K, Ying B, Zhao X, Sayed A H. Exact diffusion for distributed optimization and learning–part i: Algorithm development. IEEE Transactions on Signal Processing, 2018, 67(3): 708−723 [38] Kong B, Zhu S, Lu S, Huang X, Yuan K. Decentralized bilevel optimization over graphs: Loopless algorithmic update and transient iteration complexity. arXiv preprint arXiv: 2402.03167, 2024 [39] Zhu S, Kong B, Lu S, Huang X, Yuan K. SPARKLE: a unified single-loop primal-dual framework for decentralized bilevel optimization. In: Proceedings of the 38th International Conference on Neural Information Processing Systems. Vancouver, Canada: 2024. 62912−62987 [40] He Y, Shang Q, Huang X, Liu J, Yuan K. A mathematics-inspired learning-to-optimize framework for decentralized optimization. arXiv preprint arXiv: 2410.01700, 2024 [41] McMahan B, Moore E, Ramage D, Hampson S, y Arcas B A. Communication-efficient learning of deep networks from decentralized data. In: Proceedings of the 20th International Conference on Artificial Intelligence and Statistics. Fort Lauderdale, USA: PMLR, 2017. 1273−1282 [42] Karimireddy S P, Kale S, Mohri M, Reddi S, Stich S, Suresh A T. Scaffold: Stochastic controlled averaging for federated learning. In: Proceedings of the 37th International conference on machine learning. Virtual Event: PMLR, 2020. 5132−5143 [43] Mishchenko K, Malinovsky G, Stich S, Richtárik P. Proxskip: Yes! local gradient steps provably lead to communication acceleration! finally! In: Proceedings of the 39th International Conference on Machine Learning. Baltimore, USA: PMLR, 2022. 15750−15769 [44] Condat L, Maranjyan A, Richtárik P. Locodl: Communication-efficient distributed learning with local training and compression. arXiv preprint arXiv: 2403.04348, 2024 [45] Douillard A, Feng Q, Rusu A A, Chhaparia R, Donchev Y, Kuncoro A, et al. Diloco: Distributed low-communication training of language models. arXiv preprint arXiv: 2311.08105, 2023 [46] Wang H, Sievert S, Liu S, Charles Z, Papailiopoulos, Wright S. Atomo: Communication-efficient learning via atomic sparsification. In: Proceedings of the 32nd International Conference on Neural Information Processing Systems. Montréal, Canada: 2018. 9872−9883 [47] Mishchenko K, Wang B, Kovalev D, Richtárik P. IntSGD: Adaptive floatless compression of stochastic gradients. arXiv preprint arXiv: 2102.08374, 2021 [48] Mayekar P, Tyagi H. RATQ: A universal fixed-length quantizer for stochastic optimization. In: Proceedings of the 23rd International Conference on Artificial Intelligence and Statistics. Virtual Event: PMLR, 2020. 1399−1409 [49] Wen W, Xu C, Yan F, Wu C, Wang Y, Chen Y, et al. Terngrad: Ternary gradients to reduce communication in distributed deep learning. In: Proceedings of the 31st International Conference on Neural Information Processing Systems. Long Beach, USA: 2017. 1508−1518 [50] Gandikota V, Kane D, Maity R K, Mazumdar A. vqSGD: Vector quantized stochastic gradient descent. In: Proceedings of the 24th International Conference on Artificial Intelligence and Statistics. Virtual Evenvt: PMLR, 2021. 2197−2205 [51] He Y, Hu J, Huang X, Lu S, Wang B, Yuan K. Distributed bilevel optimization with communication compression. In: Proceedings of the 41st International Conference on Machine Learning. Vienna, Austria: PMLR, 2024. 17877−17920 [52] Modoranu I V, Safaryan M, Malinovsky G, Kurtić E, Robert T, Richtárik P, et al. Microadam: Accurate adaptive optimization with low space overhead and provable convergence. In: Proceedings of the 38th International Conference on Neural Information Processing Systems. Vancouver, Canada: 2024. 1−43 [53] Gorbunov E, Burlachenko K P, Li Z, Richtárik P. MARINA: Faster non-convex distributed learning with compression. In: Proceedings of the 38th International Conference on Machine Learning. Virtual Event: PMLR, 2021: 3788−3798 [54] Li Z, Richtárik P. CANITA: Faster rates for distributed convex optimization with communication compression. In: Proceedings of the 35th International Conference on Neural Information Processing Systems. Virtual Event: 2021. 13770−13781 [55] Li Z, Kovalev D, Qian X, Richtárik P. Acceleration for compressed gradient descent in distributed and federated optimization. arXiv preprint arXiv: 2002.11364, 2020 [56] He Y, Huang X, Yuan K. Unbiased compression saves communication in distributed optimization: when and how much? In: Proceedings of the 37th International Conference on Neural Information Processing Systems. New Orleans, USA: 2023. 47991−48020 [57] He Y, Huang X, Chen Y, Yin W, Yuan K. Lower bounds and accelerated algorithms in distributed stochastic optimization with communication compression. arXiv preprint arXiv: 2305.07612, 2023 [58] Zhao H, Xie X, Fang C, Lin Z. SEPARATE: A simple low-rank projection for gradient compression in modern large-scale model training process. In: Proceedings of the 13th International Conference on Learning Representations. Singapore: 2025 [59] Mishchenko K, Gorbunov E, Takáč M, Richtárik P. Distributed learning with compressed gradient differences. Optimization Methods and Software, 20241−16 [60] Duchi J, Hazan E, Singer Y. Adaptive subgradient methods for online learning and stochastic optimization. Journal of machine learning research, 2011, 12(7): 2121−2159 [61] Zeiler M D. Adadelta: an adaptive learning rate method. arXiv preprint arXiv: 1212.5701, 2012 [62] Loshchilov I, Hutter F. Decoupled weight decay regularization. arXiv preprint arXiv: 1711.05101, 2017 [63] Reddi S J, Kale S, Kumar S, On the convergence of adam and beyond. arXiv preprint arXiv: 1904.09237, 2019 [64] He K, Zhang X, Ren S, Sun J. Deep residual learning for image recognition. In: Proceedings of the 29th IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA: IEEE, 2016. 770−778 [65] Dosovitskiy A, Beyer L, Kolesnikov A, Weissenborn D, Zhai X, Unterthiner T, et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv: 2010.11929, 2020 [66] Wang A, Singh A, Michael J, Hill F, Levy O, Bowman S R. GLUE: A multi-task benchmark and analysis platform for natural language understanding. arXiv preprint arXiv: 1804.07461, 2018 [67] Liu Y, Ott M, Goyal N, Du J, Joshi M, Chen D, et al. RoBERTa: A robustly optimized bert pretraining approach. arXiv preprint arXiv: 1907.11692, 2019 [68] He P, Liu X, Gao J, Chen W. Deberta: Decoding-enhanced bert with disentangled attention. arXiv preprint arXiv: 2006.03654, 2020 [69] Touvron H, Lavril T, Izacard G, Martinet X, Lachaux M A, Lacroix T, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv: 2302.13971, 2023 [70] Robert T, Safaryan M, Modoranu I V, Alistarh D. Ldadam: Adaptive optimization from low-dimensional gradient statistics. arXiv preprint arXiv: 2410.16103, 2024 [71] Hu Z, Wang L, Lan Y, Xu W, Lim E P, Bing L, et al. LLM-Adapters: An Adapter Family for Parameter-Efficient Fine-Tuning of Large Language Models. arXiv preprint arXiv: 2304.01933, 2023 [72] Cobbe K, Kosaraju V, Bavarian M, Chen M, Jun H, Kaiser L, et al. Training verifiers to solve math word problems. arXiv preprint arXiv: 2110.14168, 2021 [73] Patel A, Bhattamishra S, Goyal N. Are NLP models really able to solve simple math word problems? In: Proceedings of the 2021 Annual Conference of the North American Chapter of the Association for Computational Linguistics. Virtual Event: 2021. 2080−2094 [74] Ling W, Yogatama D, Dyer C, Blunsom P. Program induction by rationale generation: Learning to solve and explain algebraic word problems. In: Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics. Vancouver, Canada: 2017. 158−167 [75] Roy S, Roth D. Solving general arithmetic word problems. arXiv preprint arXiv: 1608.01413, 2016 -
计量
- 文章访问数: 5
- HTML全文浏览量: 1
- 被引次数: 0
