

基于MARL-MHSA架构的水下仿生机器人协同围捕策略: 数据驱动建模与分布式策略优化
doi: 10.16383/j.aas.c250086 cstr: 32138.14.j.aas.c250086
Cooperative Pursuit Policy for Bionic Underwater Robot Based on MARL-MHSA Architecture: Data-driven Modeling and Distributed Strategy Optimization
-
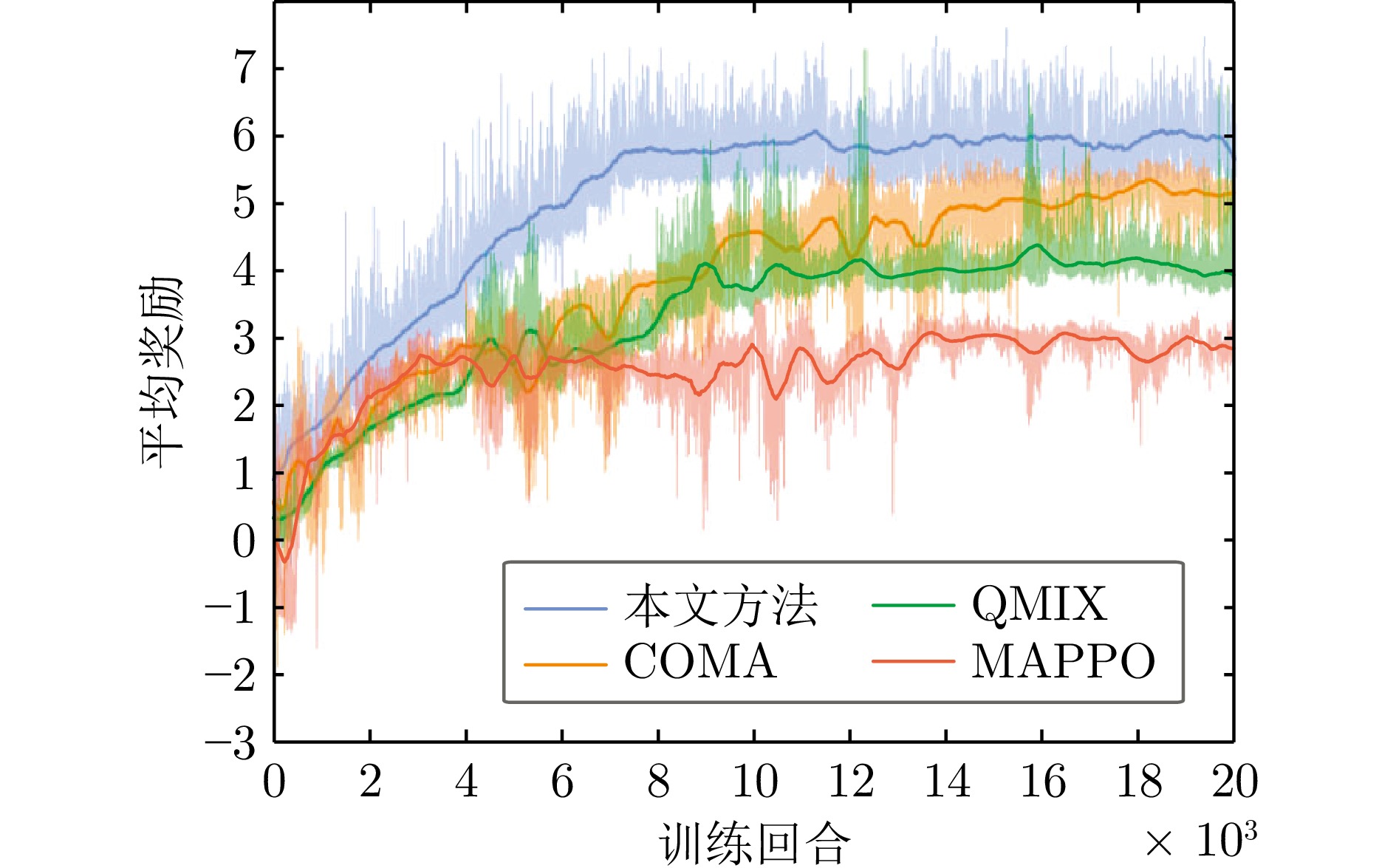
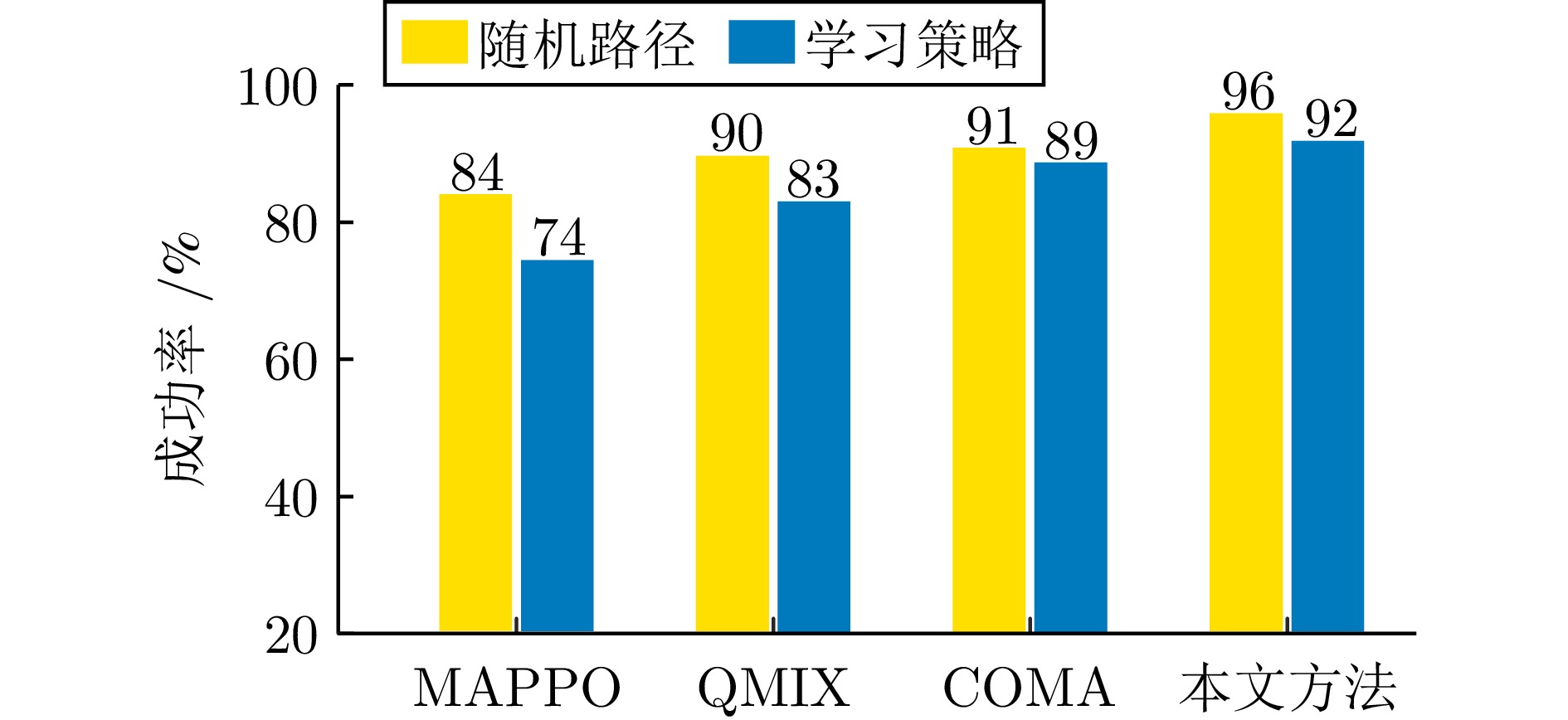
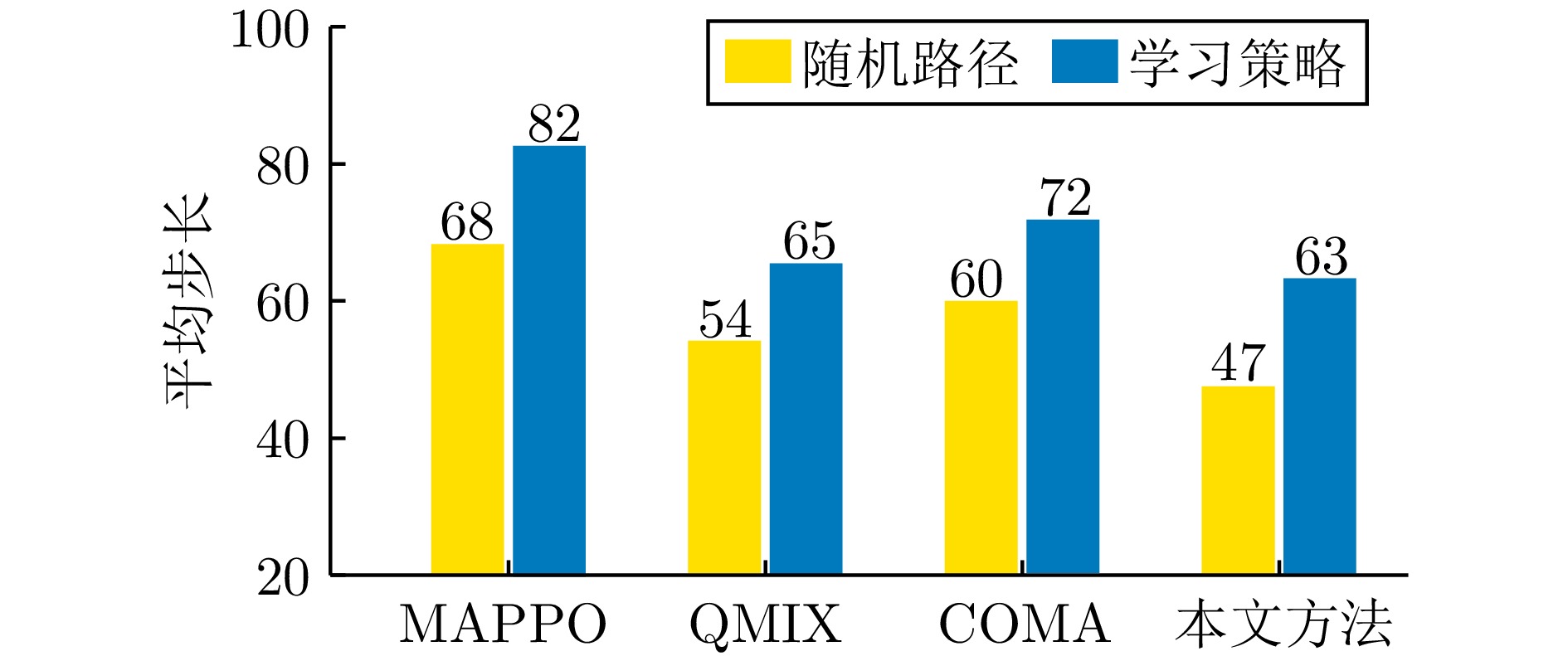
摘要: 针对水下仿生机器人集群的围捕—逃逸问题, 提出一种融合多头自注意力机制的多智能体强化学习策略训练框架. 该框架构建一种基于多头自注意力机制的中心化决策网络, 在提升策略训练效率的同时, 保留了分布式决策架构, 有效增强了个体的自主决策能力与群体间的协同性能. 此外, 针对策略由仿真环境向真实场景迁移过程中动力学建模不精确、感知—动作存在偏差等挑战, 构建一种由真实场景机器鱼运动数据驱动的仿真环境, 有效提升了策略的可迁移性与部署的可靠性. 通过仿真与真实场景实验验证了所提方法在水下仿生机器人协同围捕任务中的有效性. 相较于多智能体近端策略优化算法, 该方法可使平均围捕成功率提升24.3%、平均围捕步长减少30.9%, 显著提升了水下仿生机器人集群的协同围捕效率. 该研究为多智能体强化学习在水下仿生机器人集群任务中的应用提供了新的思路和技术支持.Abstract: This paper addresses the pursuit-evasion problem in bionic underwater robot swarms and proposes a policy training framework based on multi-agent reinforcement learning with multi-head self-attention mechanism. The framework constructs a centralized decision-making network enhanced by a multi-head self-attention mechanism, which improves strategy training efficiency while preserving a distributed decision-making architecture, effectively enhancing individual autonomy and group cooperation. In addition, to address the challenges of dynamics mismatch and perception-action discrepancy during policy transfers from simulation environments to real-world scenarios, a data-driven simulation environment is constructed by using real motion data collected from robotic fish. This approach effectively enhancing the transferability and reliability of the trained policy for real-world deployment. Extensive simulations and real-world experiments validate the effectiveness of the proposed method in bionic underwater robot cooperative pursuit tasks. Compared with multi-agent proximal policy optimization algorithm, the proposed method increases the average pursuit success rate by 24.3% and reduces the average pursuit step by 30.9%, demonstrating a substantial improvement in the cooperative pursuit efficiency of bionic underwater robot swarms. This study offers novel insights and technical support for the application of multi-agent reinforcement learning in bionic underwater robot swarm tasks.
-
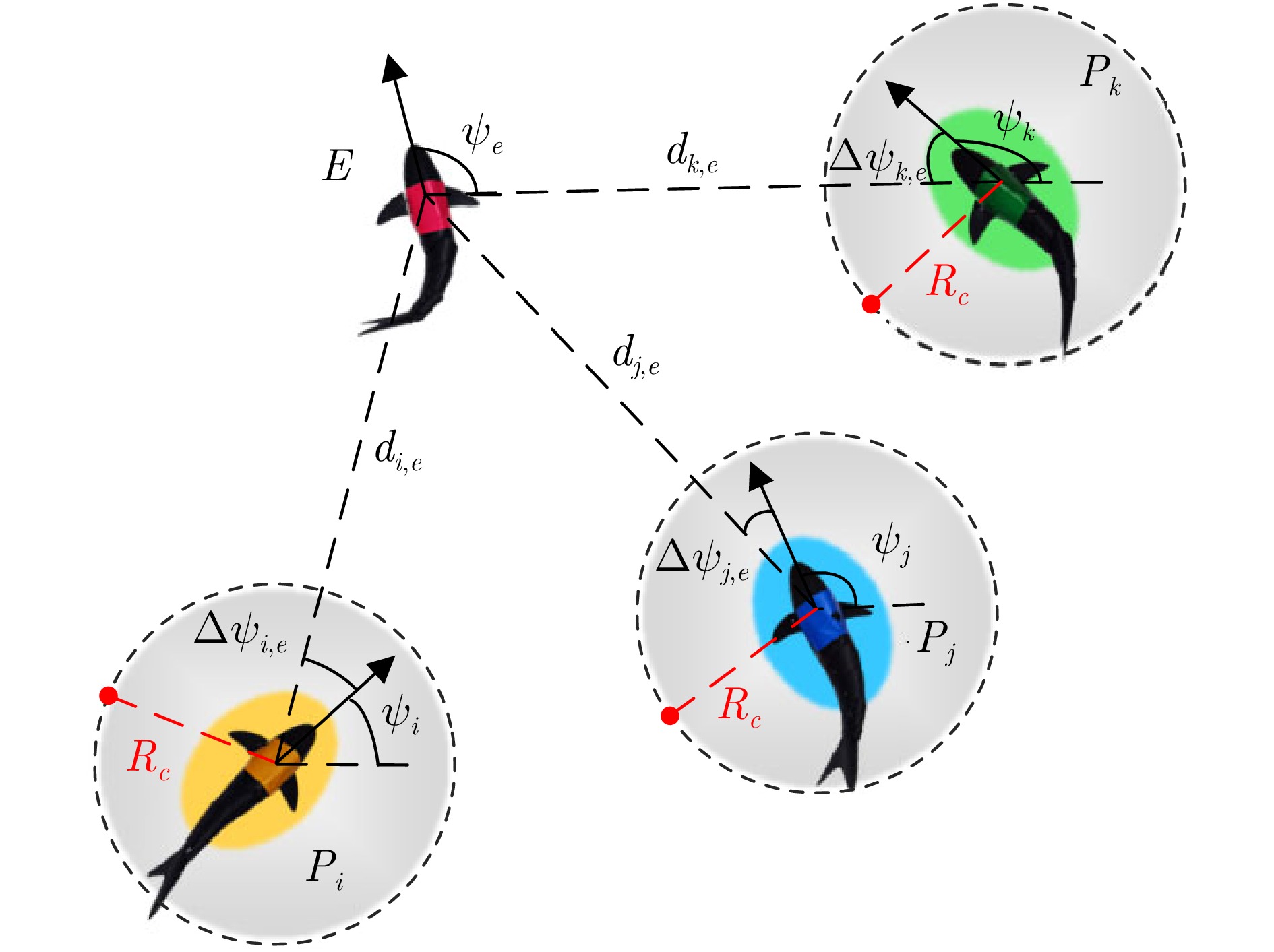
图 1 水下仿生机器鲨鱼协同围捕任务示意图
Fig. 1 Diagram of the cooperative pursuit task for bionic underwater robotic shark
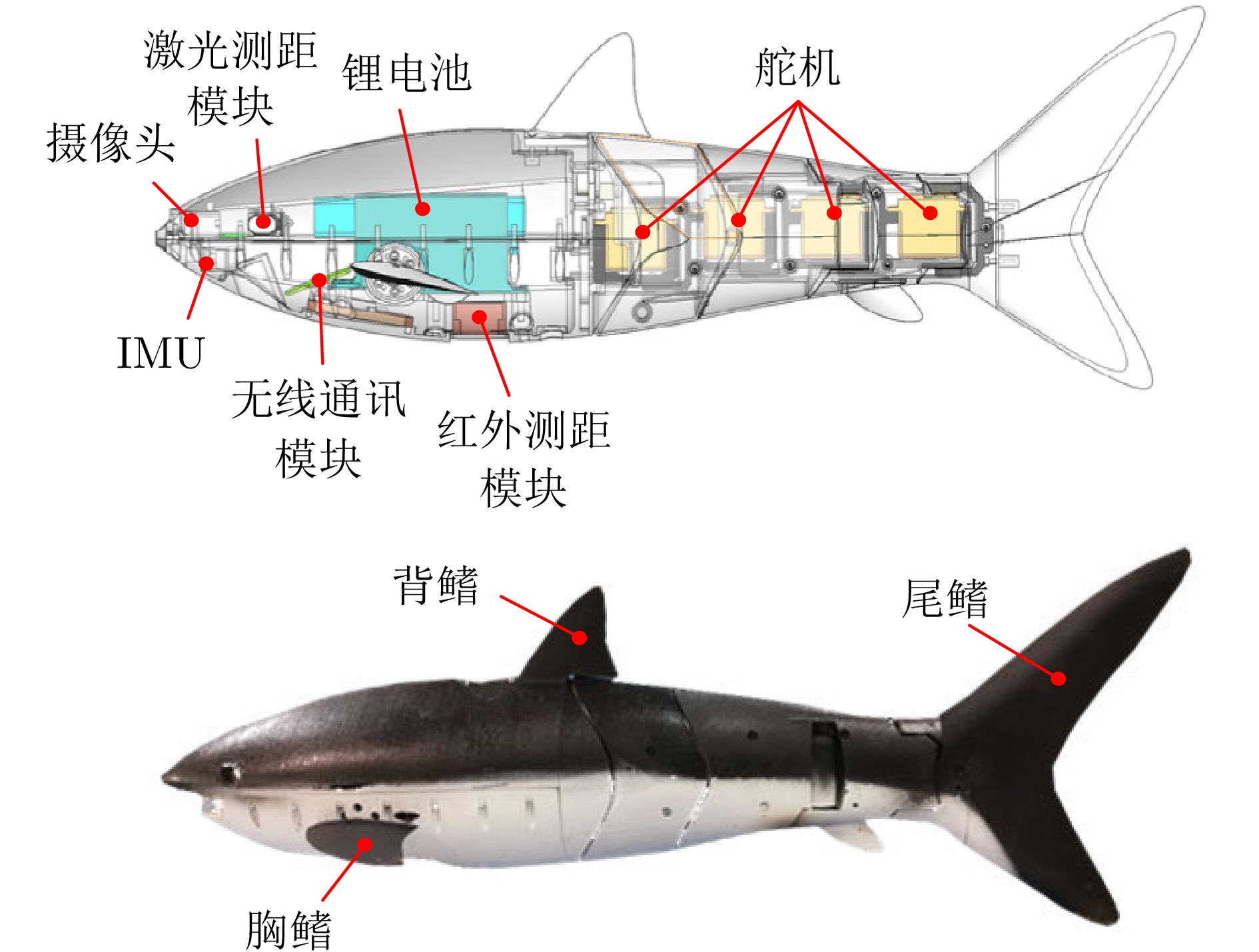
图 2 仿生机器鲨鱼设计概念图与原型样机
Fig. 2 Design concept diagram and physical prototype of the bionic robotic shark
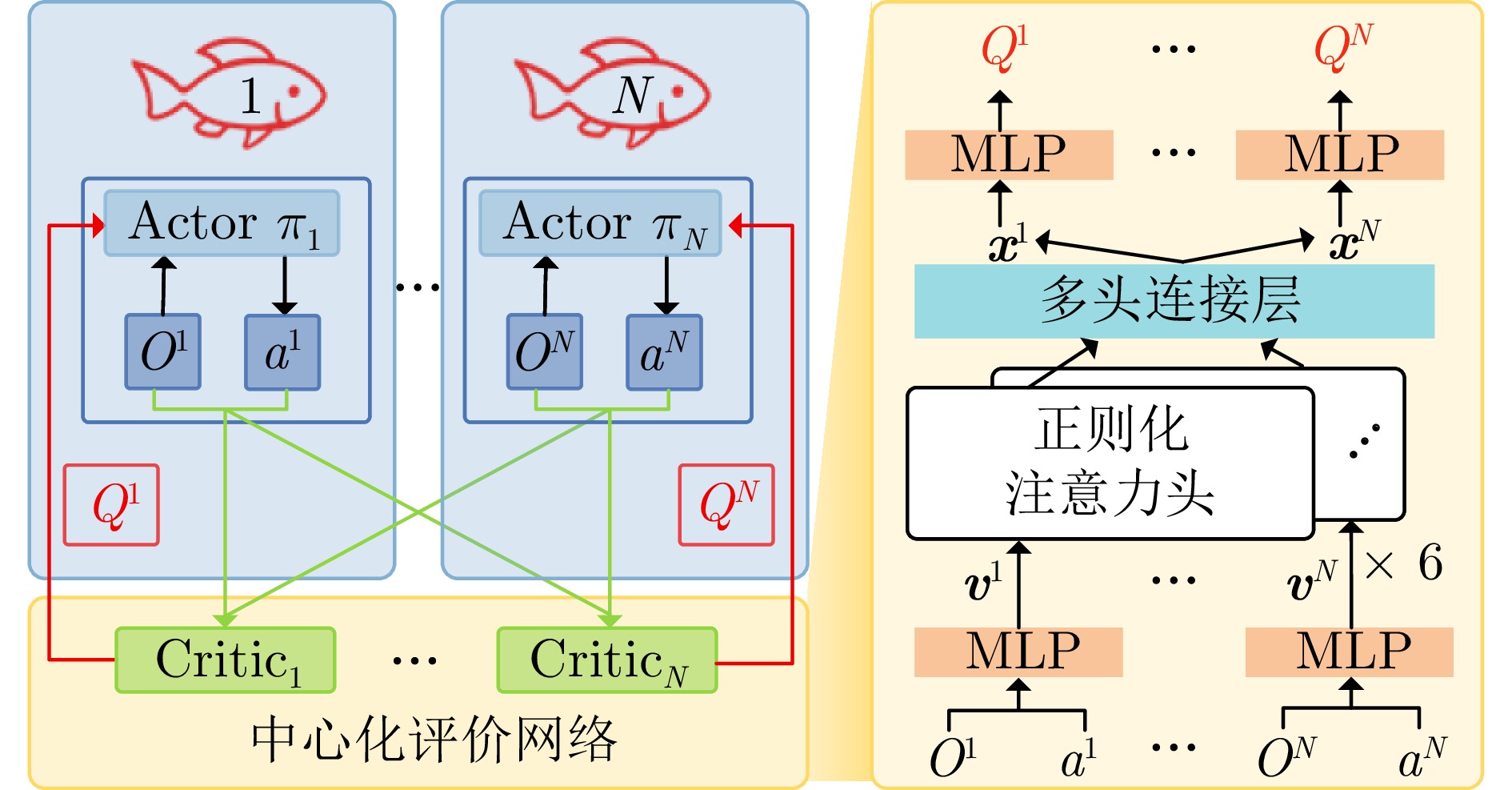
图 3 基于多头自注意力机制的多智能体策略训练框架
Fig. 3 Multi-agent policy training framework based on multi-head self-attention mechanism
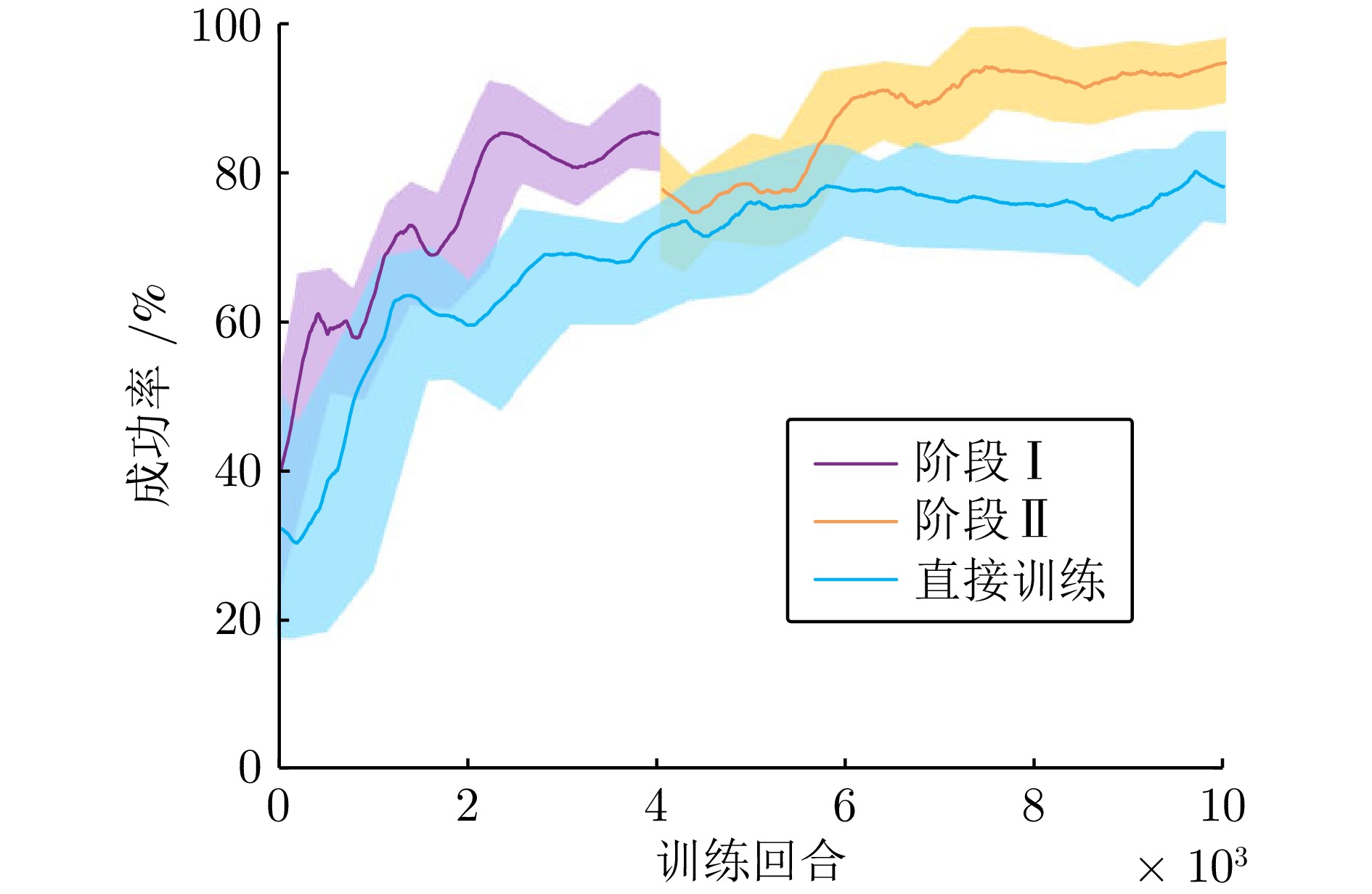
图 4 阶段化训练与直接训练效果对比
Fig. 4 Comparison of the effects of phased training and direct training
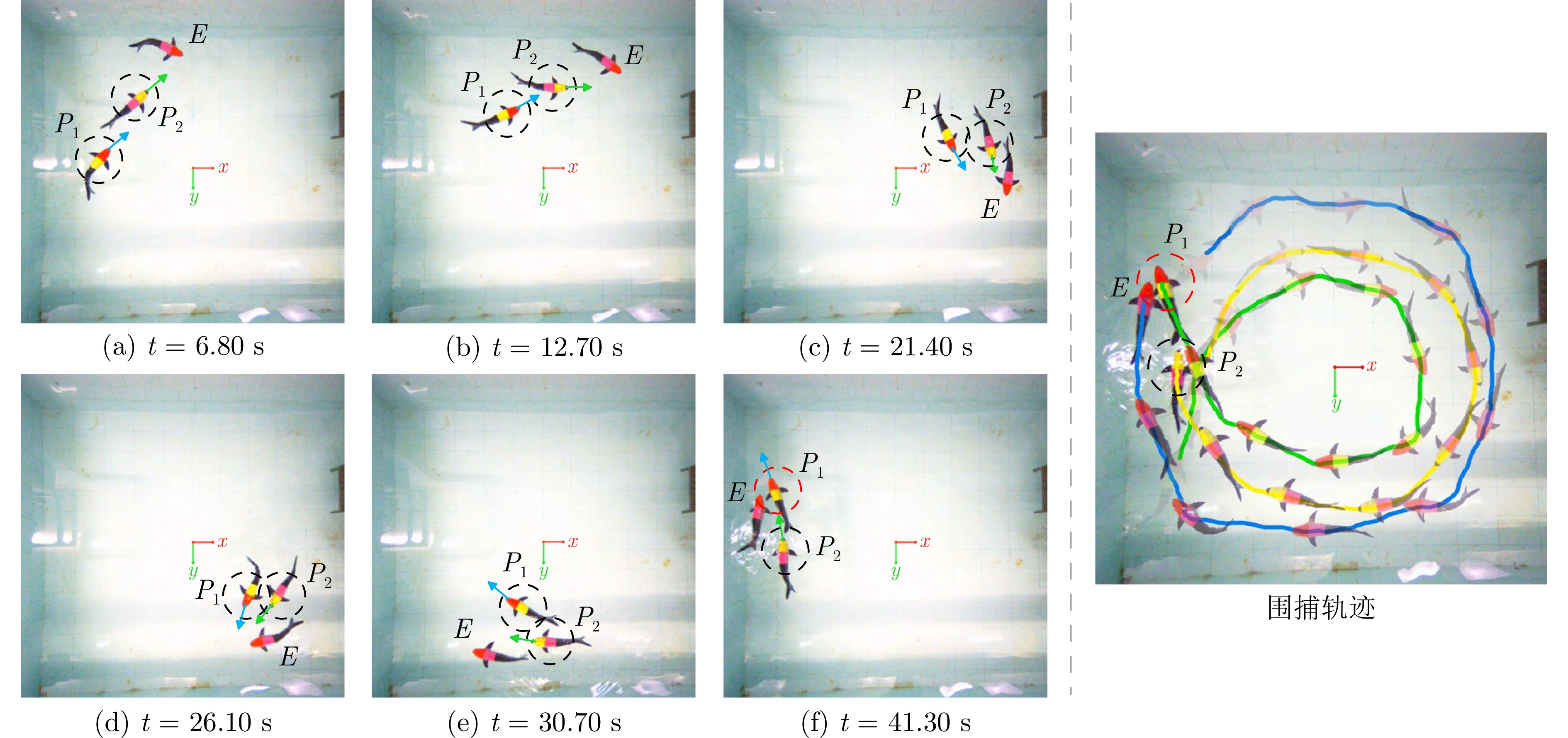
图 10 水下仿生机器人协同围捕实验截图
Fig. 10 Snapshots of the cooperative pursuit experiment for bionic underwater robots
表 1 基于数据驱动的控制输入与状态输出对应表
Table 1 Mapping between control inputs and state outputs based on data-driven approach
$ v/w $ $ b $ ($ ^\circ $) $ f $ (Hz) −30 −20 −10 0 10 20 30 0.5 0.040/−0.763 0.089/−0.619 0.180/−0.419 0.155/0 0.190/0.311 0.093/0.501 0.045/0.611 0.6 0.034/−0.602 0.086/−0.546 0.207/−0.439 0.161/0 0.199/0.342 0.087/0.418 0.032/0.469 0.7 0.036/−0.693 0.098/−0.728 0.175/−0.344 0.179/0 0.165/0.251 0.105/0.512 0.040/0.576 0.8 0.046/−0.912 0.104/−0.771 0.189/−0.409 0.217/0 0.184/0.301 0.106/0.580 0.045/0.699 0.9 0.065/−1.079 0.108/−0.822 0.261/−0.472 0.299/0 0.245/0.543 0.124/0.761 0.065/1.121 1.0 0.072/−1.177 0.141/−0.996 0.279/−0.574 0.336/0 0.267/0.553 0.143/1.056 0.070/1.168 1.1 0.056/−0.931 0.126/−0.950 0.232/−0.463 0.319/0 0.225/0.475 0.138/0.904 0.050/0.859 1.2 0.061/−1.028 0.116/−0.863 0.243/−0.519 0.269/0 0.229/0.451 0.128/0.873 0.059/1.000  下载: 导出CSV
下载: 导出CSV
表 2 多头注意力机制消融实验与对比方法性能分析
Table 2 Ablation and comparative performance analysis of the multi-head attention mechanism
对比方法 成功率(%) 成功步长 训练回合 AC 82 73 ~ 9500 AC+MHSA (1H, 64D) 86 67 ~ 8600 AC+MHSA (4H, 64D) 90 61 ~ 7800 AC+MHSA (6H, 64D) 92 63 ~ 7500 AC+MHSA (8H, 64D) 91 65 ~ 7700 AC+MHSA (6H, 32D) 89 66 ~ 8000 AC+MHSA (6H, 128D) 92 61 ~ 7300 AC+MHSA (6H, 256D) 93 60 ~ 7200 MAPPO 74 82 ~ 4800 COMA 89 72 ~ 9700 QMIX 83 65 ~ 8300
下载: 导出CSV
-
[1] 刘金存, 任崟杰, 徐战, 安冬, 位耀光. 从自然灵感角度出发的群体智能集群机器人系统研究综述. 信息与控制, 2024, 53(2): 154−181Liu Jin-Cun, Ren Yin-Jie, Xu Zhan, An Dong, Wei Yao-Guang. Review of swarm intelligence research in swarm robotic systems: Approaching from the perspective of nature inspiration. Information and Control, 2024, 53(2): 154−181 [2] 刘小峰, 陈果, 刘宇, 王希. 动物集群行为的机制和应用. 科学通报, 2023, 68(23): 3063−3076 doi: 10.1360/TB-2023-0165Liu Xiao-Feng, Chen Guo, Liu Yu, Wang Xi. Animal collective behavior: Mechanisms and applications. Chinese Science Bulletin, 2023, 68(23): 3063−3076 doi: 10.1360/TB-2023-0165 [3] Maxeiner M, Hocke M, Moenck H J, Gebhardt G H W, Weimar N, Musiolek L, et al. Social competence improves the performance of biomimetic robots leading live fish. Bioinspiration & Biomimetics, 2003, 18(4): 045001 [4] 段海滨, 邵山, 苏丙未, 张雷. 基于仿生智能的无人作战飞机控制技术发展新思路. 中国科学: 技术科学, 2010, 40(8): 853−860Duan Hai-Bin, Shao Shan, Su Bing-Wei, Zhang Lei. New development thoughts on the bio-inspired intelligence based control for unmanned combat aerial vehicle. Science China Technological Sciences, 2010, 40(8): 853−860 [5] Nguyen L V. Swarm intelligence-based multi-robotics: A comprehensive review. AppliedMath, 2024, 4(4): 1192−1210 doi: 10.3390/appliedmath4040064 [6] Sani M, Robu B, Hably A. Pursuit-evasion game for nonholonomic mobile robots with obstacle avoidance using NMPC. In: Proceedings of the 28th Mediterranean Conference on Control and Automation (MED). Saint-Raphaël, France: IEEE, 2020. 978−983 [7] Vidal R, Shakernia O, Kim H J, Shim D H, Sastry S. Probabilistic pursuit-evasion games: Theory, implementation, and experimental evaluation. IEEE Transactions on Robotics and Automation, 2002, 18(5): 662−669 doi: 10.1109/TRA.2002.804040 [8] Feng Y K, Wu Z X, Wang J, Gu J W, Yu F Y, Yu J Z, et al. Decentralized multirobotic fish pursuit control with attraction-enhanced reinforcement learning. IEEE Transactions on Industrial Electronics, 2025, 72(7): 8290−8300 [9] Vieira M A M, Govindan R, Sukhatme G S. Scalable and practical pursuit-evasion with networked robots. Intelligent Service Robotics, 2009, 2(4): 247−263 doi: 10.1007/s11370-009-0050-y [10] 张红强, 吴亮红, 周游, 章兢, 周少武, 刘朝华. 复杂环境下群机器人自组织协同多目标围捕. 控制理论与应用, 2020, 37(5): 1054−1062 doi: 10.7641/CTA.2019.90015Zhang Hong-Qiang, Wu Liang-Hong, Zhou You, Zhang Jing, Zhou Shao-Wu, Liu Zhao-Hua. Self-organizing cooperative multi-target hunting by swarm robots in complex environments. Control Theory & Applications, 2020, 37(5): 1054−1062 doi: 10.7641/CTA.2019.90015 [11] Kothari M, Manathara J G, Postlethwaite I. Cooperative multiple pursuers against a single evader. Journal of Intelligent & Robotic Systems, 2017, 86(3): 551−567 [12] 周萌, 李建宇, 王昶, 王晶, 王力. 多机器人协同围捕方法综述. 自动化学报, 2024, 50(12): 2325−2358Zhou Meng, Li Jian-Yu, Wang Chang, Wang Jing, Wang Li. Multi-robot cooperative hunting: A survey. Acta Automatica Sinica, 2024, 50(12): 2325−2358 [13] 苏牧青, 王寅, 濮锐敏, 余萌. 基于强化学习的多无人车协同围捕方法. 工程科学学报, 2024, 46(7): 1237−1250Su Mu-Qing, Wang Yin, Pu Rui-Min, Yu Meng. Cooperative encirclement method for multiple unmanned ground vehicles based on reinforcement learning. Chinese Journal of Engineering, 2024, 46(7): 1237−1250 [14] Oyler D W, Kabamba P T, Girard A R. Pursuit-evasion games in the presence of obstacles. Automatica, 2016, 65: 1−11 doi: 10.1016/j.automatica.2015.11.018 [15] Liu W H, Hu J W, Zhang H, Wang M Y, Xiong Z H. A novel graph-based motion planner of multi-mobile robot systems with formation and obstacle constraints. IEEE Transactions on Robotics, 2024, 40: 714−728 doi: 10.1109/TRO.2023.3339989 [16] Umar B M, Rilwan J, Aphane M, Muangchoo K. Pursuit and evasion linear differential game problems with generalized integral constraints. Symmetry, 2024, 16(5): Article No. 513 doi: 10.3390/sym16050513 [17] Weintraub I E, Pachter M, Garcia E. An introduction to pursuit-evasion differential games. In: Proceedings of the American Control Conference (ACC). Denver, USA: IEEE, 2020. 1049−1066 [18] Engin S, Jiang Q Y, Isler V. Learning to play pursuit-evasion with visibility constraints. In: Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). Prague, Czech Republic: IEEE, 2021. 3858−3863 [19] Isaacs R. Differential Games: A Mathematical Theory with Applications to Warfare and Pursuit, Control and Optimization. New York: Dover Publications, 1999. [20] Xu Y H, Yang H, Jiang B, Polycarpou M M. Multiplayer pursuit-evasion differential games with malicious pursuers. IEEE Transactions on Automatic Control, 2022, 67(9): 4939−4946 doi: 10.1109/TAC.2022.3168430 [21] Geng N G, Chen Z T, Nguyen Q A, Gong D W. Particle swarm optimization algorithm for the optimization of rescue task allocation with uncertain time constraints. Complex & Intelligent Systems, 2021, 7(2): 873−890 [22] Zeng X, Yang L P, Zhu Y W, Yang F Y X. Comparison of two optimal guidance methods for the long-distance orbital pursuit-evasion game. IEEE Transactions on Aerospace and Electronic Systems, 2021, 57(1): 521−539 doi: 10.1109/TAES.2020.3024423 [23] Wang L X, Wang M L, Yue T. A fuzzy deterministic policy gradient algorithm for pursuit-evasion differential games. Neurocomputing, 2019, 362: 106−117 doi: 10.1016/j.neucom.2019.07.038 [24] De Souza C, Newbury R, Cosgun A, Castillo P, Vidolov B, Kulić D. Decentralized multi-agent pursuit using deep reinforcement learning. IEEE Robotics and Automation Letters, 2021, 6(3): 4552−4559 doi: 10.1109/LRA.2021.3068952 [25] Zhang Z, Wang X H, Zhang Q R, Hu T J. Multi-robot cooperative pursuit via potential field-enhanced reinforcement learning. In: Proceedings of the International Conference on Robotics and Automation (ICRA). Philadelphia, USA: IEEE, 2022. 8808−8814 [26] Kouzeghar M, Song Y B, Meghjani M, Bouffanais R. Multi-target pursuit by a decentralized heterogeneous UAV swarm using deep multi-agent reinforcement learning. In: Proceedings of the IEEE International Conference on Robotics and Automation (ICRA). London, UK: IEEE, 2023. 3289−3295 [27] Arndt K, Hazara M, Ghadirzadeh A, Kyrki V. Meta reinforcement learning for sim-to-real domain adaptation. In: Proceedings of the IEEE international conference on robotics and automation (ICRA). Paris, France: IEEE, 2020. 2725−2731 [28] Yu J Z, Wang C, Xie G M. Coordination of multiple robotic fish with applications to underwater robot competition. IEEE Transactions on Industrial Electronics, 2016, 63(2): 1280−1288 doi: 10.1109/TIE.2015.2425359 [29] Yan S Z, Wu Z X, Wang J, Tan M, Yu J Z. Efficient cooperative structured control for a multijoint biomimetic robotic fish. IEEE/ASME Transactions on Mechatronics, 2021, 26(5): 2506−2516 doi: 10.1109/TMECH.2020.3041506 [30] Qiu C L, Wu Z X, Wang J, Tan M, Yu J Z. Multiagent-reinforcement-learning-based stable path tracking control for a bionic robotic fish with reaction wheel. IEEE Transactions on Industrial Electronics, 2023, 70(12): 12670−12679 doi: 10.1109/TIE.2023.3239937 [31] Yan L, Chang X H, Wang N H, Tian R Y, Zhang L P, Liu W. Learning how to avoid obstacles: A numerical investigation for maneuvering of self-propelled fish based on deep reinforcement learning. International Journal for Numerical Methods in Fluids, 2021, 93(10): 3073−3091 doi: 10.1002/fld.5025 [32] Zhang T H, Tian R Y, Yang H Q, Wang C, Sun J N, Zhang S K, et al. From simulation to reality: A learning framework for fish-like robots to perform control tasks. IEEE Transactions on Robotics, 2022, 38(6): 3861−3878 (查阅网上资料, 未能确认作者Sun J N为Sun J N还是Sun J A, 请确认)Zhang T H, Tian R Y, Yang H Q, Wang C, Sun J N, Zhang S K, et al. From simulation to reality: A learning framework for fish-like robots to perform control tasks. IEEE Transactions on Robotics, 2022, 38(6): 3861−3878 (查阅网上资料, 未能确认作者Sun J N为Sun J N还是Sun J A, 请确认) [33] Zhang T H, Yue L, Wang C, Sun J N, Zhang S K, Wei A R, et al. Leveraging imitation learning on pose regulation problem of a robotic fish. IEEE Transactions on Neural Networks and Learning Systems, 2024, 35(3): 4232−4245 doi: 10.1109/TNNLS.2022.3202075 [34] Yan S Z, Wu Z X, Wang J, Huang Y P, Tan M, Yu J Z. Real-world learning control for autonomous exploration of a biomimetic robotic shark. IEEE Transactions on Industrial Electronics, 2022, 70(4): 3966−3974 [35] Ijspeert A J. Central pattern generators for locomotion control in animals and robots: A review. Neural Networks, 2008, 21(4): 642−653 doi: 10.1016/j.neunet.2008.03.014 [36] 吴正兴, 喻俊志, 苏宗帅, 谭民. 仿生机器鱼S形起动的控制与实现. 自动化学报, 2013, 39(11): 1914−1922 doi: 10.3724/SP.J.1004.2013.01914Wu Zheng-Xing, Yu Jun-Zhi, Su Zong-Shuai, Tan Min. Control and implementation of S-start for a multijoint biomimetic robotic fish. Acta Automatica Sinica, 2013, 39(11): 1914−1922 doi: 10.3724/SP.J.1004.2013.01914 [37] Yu J Z, Wu Z X, Wang M, Tan M. CPG network optimization for a biomimetic robotic fish via PSO. IEEE Transactions on Neural Networks and Learning Systems, 2016, 27(9): 1962−1968 doi: 10.1109/TNNLS.2015.2459913 [38] Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez A N, et al. Attention is all you need. In: Proceedings of the 31st International Conference on Neural Information Processing Systems. Long Beach, USA: Curran Associates Inc., 2017. 6000−6010 [39] Hüttenrauch M, Šošić A, Neumann G. Deep reinforcement learning for swarm systems. The Journal of Machine Learning Research, 2019, 20(1): 1966−1996 [40] Yu C, Velu A, Vinitsky E, Gao J X, Wang Y, Bayen A, et al. The surprising effectiveness of PPO in cooperative multi-agent games. In: Proceedings of the 36th Conference on Neural Information Processing Systems. New Orleans, USA: NeurIPS, 2022. 24611−24624 [41] Rashid T, Samvelyan M, De Witt C S, Farquhar G, Foerster J, Whiteson S. Monotonic value function factorisation for deep multi-agent reinforcement learning. The Journal of Machine Learning Research, 2020, 21(1): Article No. 178 [42] Foerster J, Farquhar G, Afouras T, Nardelli N, Whiteson S. Counterfactual multi-agent policy gradients. In: Proceedings of the 32nd AAAI Conference on Artificial Intelligence. New Orleans, USA: AAAI, 2018. 2974−2982 -
计量
- 文章访问数: 13
- HTML全文浏览量: 8
- 被引次数: 0
