

-
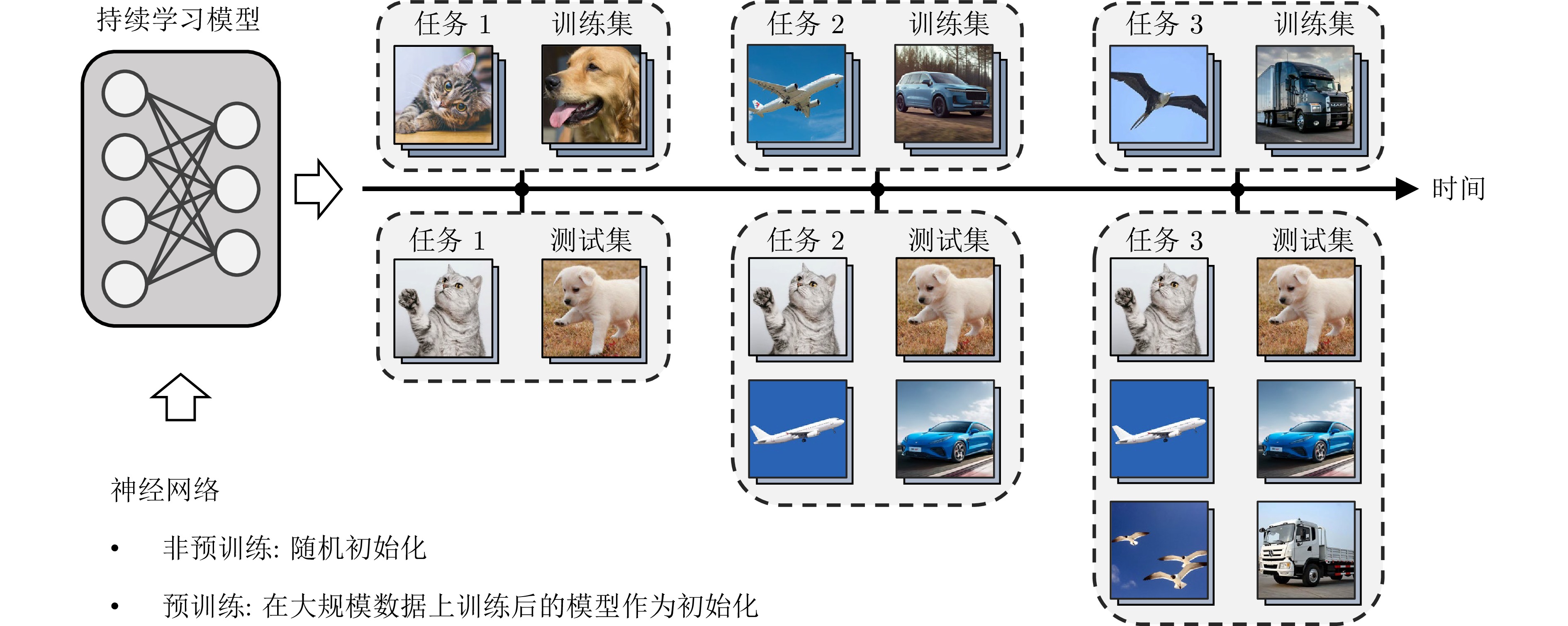
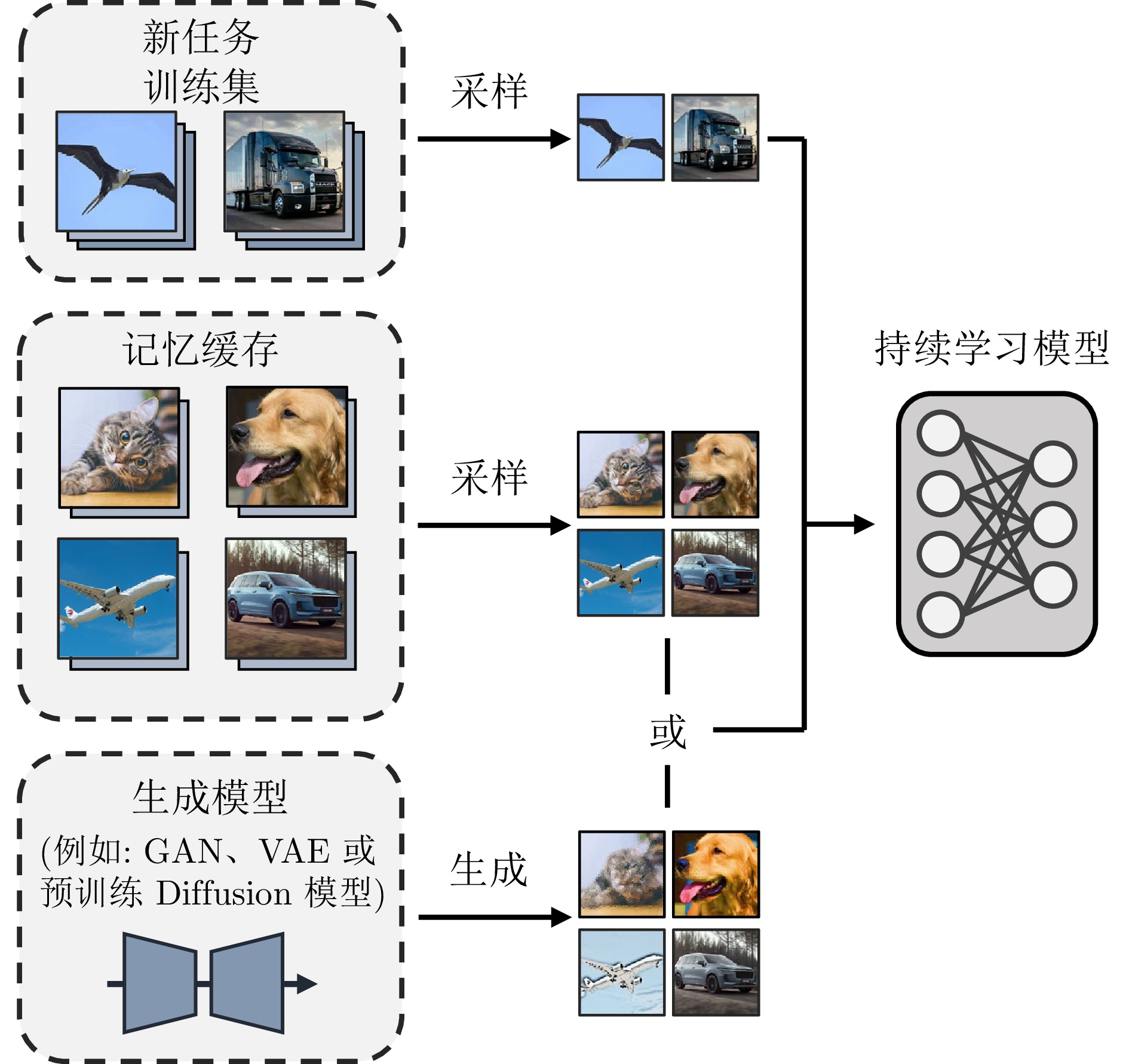
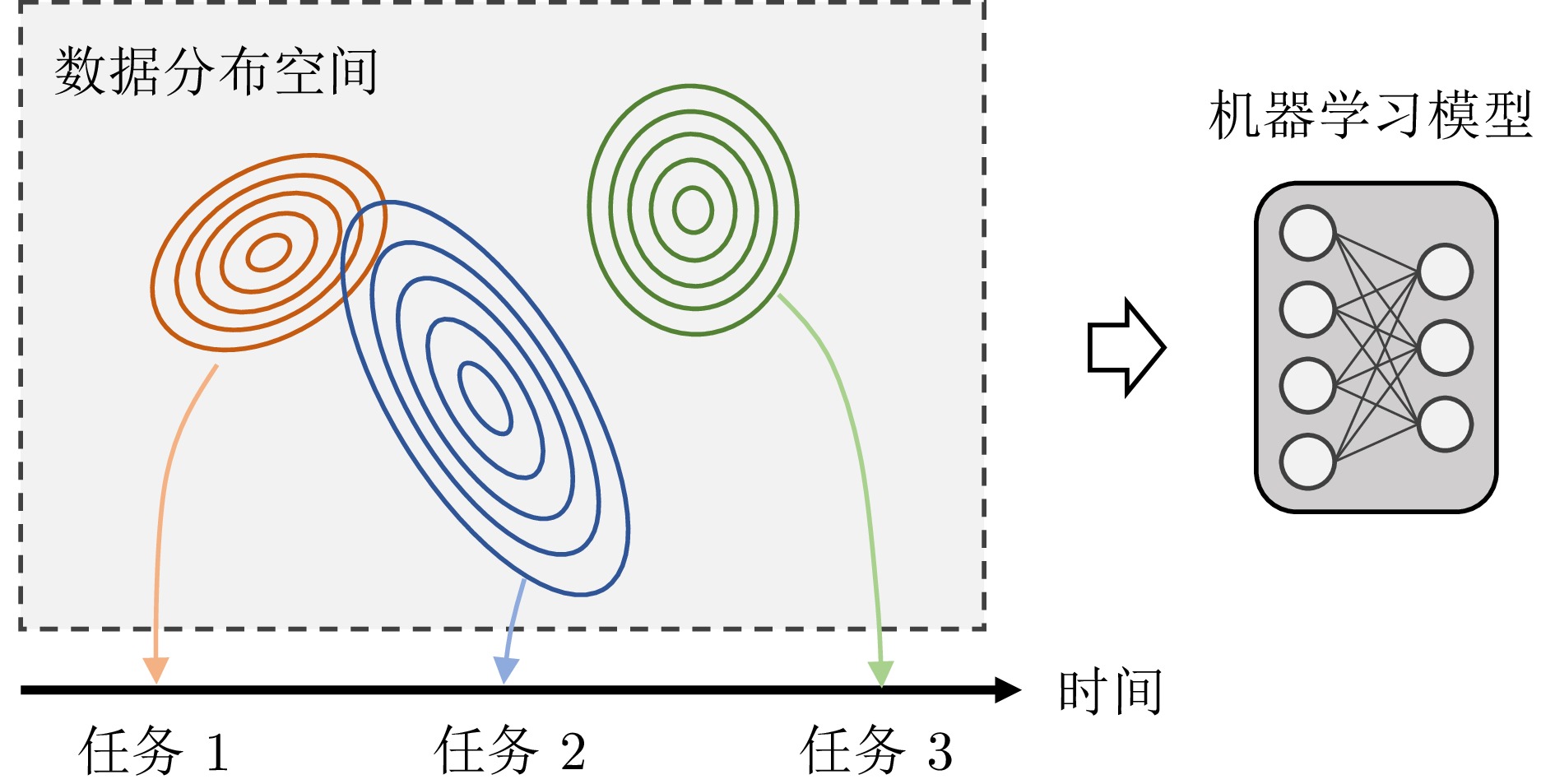
摘要: 以深度学习为代表的机器学习方法已经在多个领域取得显著进展, 然而大多方法局限于静态场景, 难以像人类一样在开放世界的动态场景中不断学习新知识, 同时保持已经学过的知识. 为解决该挑战, 持续学习受到越来越多的关注. 现有的持续学习方法大致可以分为两类, 即传统的非预训练模型持续学习方法以及大模型时代下逐步演进的预训练模型持续学习方法. 本文旨在对这两类方法的研究进展进行详细的综述, 主要从四个层面对比非预训练模型和预训练模型方法的异同点, 即数据层面、模型层面、损失/优化层面以及理论层面. 着重分析从应用非预训练模型的方法发展到应用预训练模型的方法的技术变化, 并分析出现此类差异的内在本质. 最后, 总结并展望未来持续学习发展的趋势.Abstract: Machine learning methods, especially deep learning, have achieved remarkable progress across various fields. However, most approaches are limited to static scenarios and struggle to continually learn new knowledge in dynamic, open-world scenarios while retaining previously acquired knowledge, unlike humans. To address this challenge, continual learning (CL) has attracted increasing attention. Existing CL methods can be broadly categorized into two types: Traditional CL methods based on non-pretrained models, and CL methods based on pretrained models that have emerged with the advent of large models. This paper aims to provide a detailed review of the research progress in these two categories of methods, mainly comparing the similarities and differences between non-pretrained and pretrained model approaches from four perspectives: Data level, model level, loss/optimization level and theoretical level. We focus on analyzing the technical changes from methods employing non-pretrained models to those employing pretrained models, and analyze the underlying reasons for these differences. Finally, we summarize and envision the future trends in continual learning development.
-
Key words:
- Continual learning /
- catastrophic forgetting /
- pretrained model /
- machine learning /
- deep learning
-
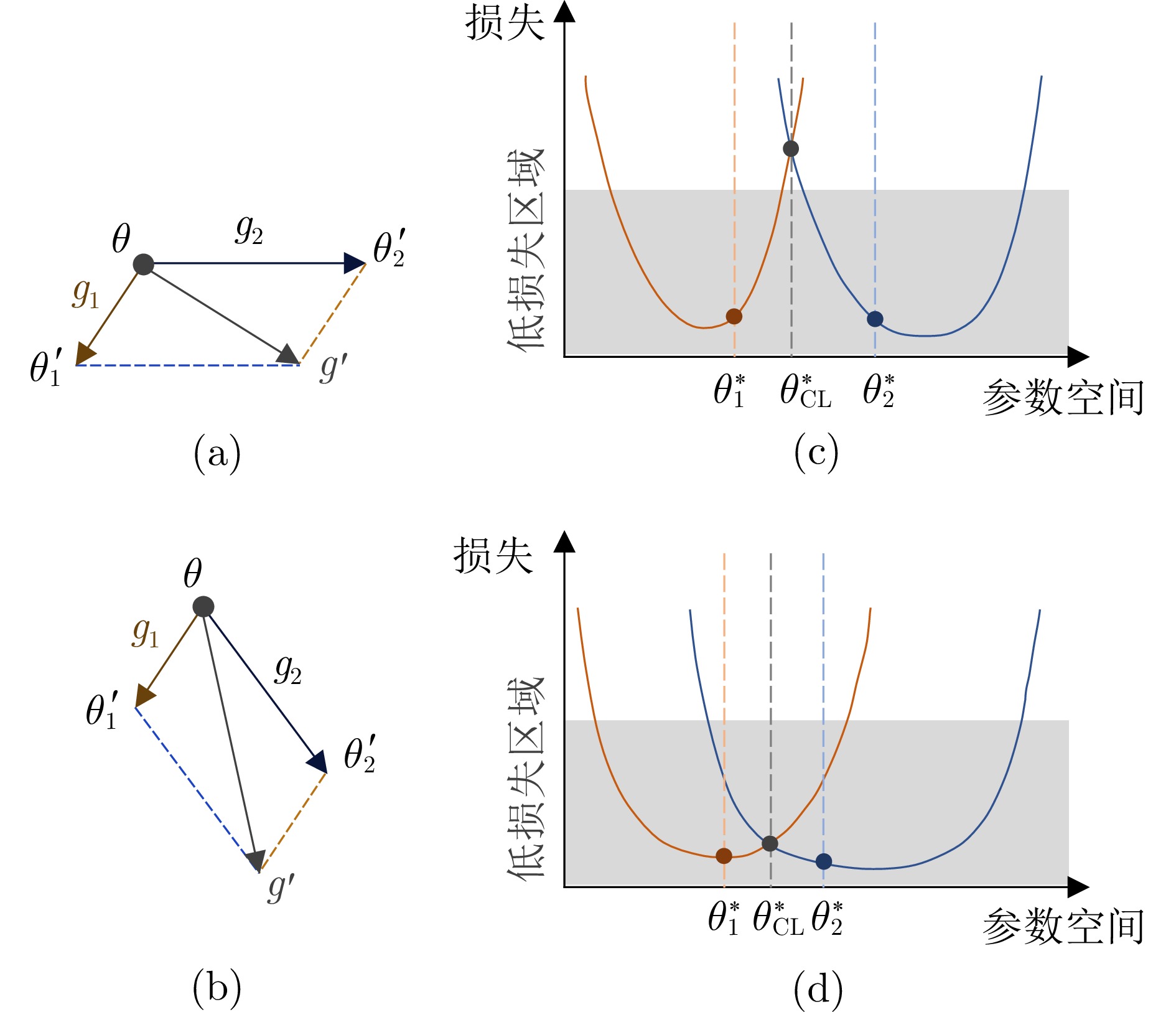
图 5 损失/优化层面梯度的对齐和损失平滑图示
Fig. 5 Illustration of gradient alignment and loss flatness on the perspective of loss and optimizaiton
表 1 持续学习方法总结
Table 1 Summary of continual learning methods
方法分类 非预训练持续学习方法 预训练持续学习方法 数据层面 基于重放 数据增广: [47, 52−53] [96−98] 数据表征: [47−48, 54] 数据选择: [37−38, 46, 56−59, 61−64] 基于伪重放 生成模型: [66−73] 生成预训练模型: [85−90, 93, 99−101] 合成数据集: [76−80] 合成数据集: [95] 特征重放: [82−83] 特征重放: [94] 模型层面 模型表征 [105−108, 110−114, 116−118] [146−150] 模型偏差 [83, 119−131] [148, 151−153] 模型结构 扩展模型: [132−139] 提示微调: [154−168] 路径模型: [140−145] 适配器及专家模型: [169−190] 损失/优化层面 正则化 [194−199] [170, 219] 梯度对齐 [200−204] [220−221] 损失平滑 [205−211] 元持续学习 [121, 131, 199, 214−218] [222−223] 理论层面 PAC-Bayesian 理论 [138, 224−226] — 概率模型 [195, 197−198, 227−228] 线性模型 [229−233] 其他 [234−235, 237−240]  下载: 导出CSV
下载: 导出CSV
-
[1] Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition. In: Proceedings of the 3rd International Conference on Learning Representations. San Diego, USA: ICLR, 2015. 1−14 [2] He K M, Zhang X Y, Ren S Q, Sun J. Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA: IEEE, 2016. 770−778 [3] Dosovitskiy A, Beyer L, Kolesnikov A, Weissenborn D, Zhai X, Unterthiner T, et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv preprint arXiv: 2010.11929, 2020. [4] Liu Z, Lin Y T, Cao Y, Hu H, Wei Y X, Zhang Z Z, et al. Swin transformer: Hierarchical vision transformer using shifted windows. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. Montreal, Canada: IEEE, 2021. 9992−10002 [5] Zhao H S, Shi J P, Qi X J, Wang X G, Jia J Y. Pyramid scene parsing network. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, USA: IEEE, 2017. 6230−6239 [6] Zheng S X, Lu J C, Zhao H S, Zhu X T, Luo Z K, Wang Y B, et al. Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Nashville, USA: IEEE, 2021. 6877−6886 [7] He K M, Chen X L, Xie S N, Li Y H, Dollár P, Girshick R. Masked autoencoders are scalable vision learners. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans, USA: IEEE, 2022. 15979−15988 [8] Goodfellow I, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, Ozair S, et al. Generative adversarial networks. Communications of the ACM, 2020, 63(11): 139−144 doi: 10.1145/3422622 [9] Kingma D P, Welling M. Auto-encoding variational Bayes. In: Proceedings of the 2nd International Conference on Learning Representations. Banff, Canada: ICLR, 2014. 1−14 [10] Ho J, Jain A, Abbeel P. Denoising diffusion probabilistic models. In: Proceedings of the 34th International Conference on Neural Information Processing Systems. Vancouver, Canada: Curran Associates Inc., 2020. Article No. 574 [11] de Lange M, Aljundi R, Masana M, Parisot S, Jia X, Leonardis G, et al. A continual learning survey: Defying forgetting in classification tasks. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(7): 3366−3385 [12] Wang L Y, Zhang X X, Su H, Zhu J. A comprehensive survey of continual learning: Theory, method and application. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024, 46(8): 5362−5383 doi: 10.1109/TPAMI.2024.3367329 [13] Zhou D W, Wang Q W, Qi Z H, Ye H J, Zhan D C, Liu Z W. Classincremental learning: A survey. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024, 46(12): 9851−9873 doi: 10.1109/TPAMI.2024.3429383 [14] McCloskey M, Cohen N J. Catastrophic interference in connectionist networks: The sequential learning problem. Psychology of Learning and Motivation, 1989, 24: 109−165 [15] Zhang Y, Yang Q. A survey on multi-task learning. IEEE Transactions on Knowledge and Data Engineering, 2022, 34(12): 5586−5609 doi: 10.1109/TKDE.2021.3070203 [16] Sener O, Koltun V. Multi-task learning as multi-objective optimization. In: Proceedings of the 32nd Neural Information Processing Systems. Montréal, Canada: Curran Associates Inc. 2018. 525−536 [17] Hoi S C H, Sahoo D, Lu J, Zhao P L. Online learning: A comprehensive survey. Neurocomputing, 2021, 459: 249−289 doi: 10.1016/j.neucom.2021.04.112 [18] Glorot X, Bengio Y. Understanding the difficulty of training deep feedforward neural networks. In: Proceedings of the 13th International Conference on Artificial Intelligence and Statistics. Sardinia, Italy: PMLR, 2010. 249−256 [19] He K M, Zhang X Y, Ren S Q, Sun J. Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification. In: Proceedings of the IEEE International Conference on Computer Vision. Santiago, Chile: IEEE, 2015. 1026−1034 [20] Bommasani R, Hudson D A, Adeli E, Altman R, Arora S, von Arx S, et al. On the opportunities and risks of foundation models. arXiv preprint arXiv: 2108.07258, 2021. [21] Radford A, Kim J W, Hallacy C, Ramesh A, Goh G, Agarwal S, et al. Learning transferable visual models from natural language supervision. In: Proceedings of the 38th International Conference on Machine Learning. Virtual Event: PMLR, 2021. 8748−8763 [22] Zhao W X, Zhou K, Li J Y, Tang T Y, Wang X L, Hou Y P, et al. A survey of large language models. arXiv preprint arXiv: 2303.18223, 2023. [23] Han Z Y, Gao C, Liu J Y, Zhang J, Zhang S Q. Parameter-efficient fine-tuning for large models: A comprehensive survey. arXiv preprint arXiv: 2403.14608, 2024. [24] Xin Y, Yang J J, Luo S Q, Zhou H D, Du J L, Liu X H, et al. Parameter-efficient fine-tuning for pre-trained vision models: A survey. arXiv preprint arXiv: 2402.02242, 2024. [25] Lester B, Al-Rfou R, Constant N. The power of scale for parameter-efficient prompt tuning. In: Proceedings of the Conference on Empirical Methods in Natural Language Processing. Punta Cana, Dominican Republic: Association for Computational Linguistics, 2021. 3045−3059 [26] Jia M L, Tang L M, Chen B C, Cardie C, Belongie S, Hariharan B, et al. Visual prompt tuning. In: Proceedings of the 17th European Conference on Computer Vision. Tel Aviv, Israel: Springer, 2022. 709−727 [27] Hu E J, Shen Y L, Wallis P, Allen-Zhu Z, Li Y Z, Wang S A, et al. LoRA: Low-rank adaptation of large language models. In: Proceedings of the 10th International Conference on Learning Representations. Virtual Event: ICLR, 2022. 1−13 [28] Zhou D W, Sun H L, Ning J Y, Ye H J, Zhan D C. Continual learning with pre-trained models: A survey. In: Proceedings of the 33rd International Joint Conference on Artificial Intelligence. Jeju, South Korea: IJCAI, 2024. 8363−8371 [29] Wu T T, Luo L H, Li Y F, Pan S R, Vu T T, Haffari G. Continual learning for large language models: A survey. arXiv preprint arXiv: 2402.01364, 2024. [30] Shi H Z, Xu Z H, Wang H Y, Qin W Y, Wang W Y, Wang Y B, et al. Continual learning of large language models: A comprehensive survey. arXiv preprint arXiv: 2404.16789, 2024. [31] Zhang J H, Liu L, Silvén O, Pietikäinen M, Hu D W. Few-shot class-incremental learning for classification and object detection: A survey. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025, 47(4): 2924−2945 doi: 10.1109/TPAMI.2025.3529038 [32] Tian S S, Li L S, Li W J, Ran H, Ning X, Tiwari P. A survey on few-shot class-incremental learning. Neural Networks, 2024, 169: 307−324 doi: 10.1016/j.neunet.2023.10.039 [33] Yu D Z, Zhang X N, Chen Y K, Liu A W, Zhang Y F, Yu P S, et al. Recent advances of multimodal continual learning: A comprehensive survey. arXiv preprint arXiv: 2410.0535, 2024. [34] van de Ven G M, Tolias A S. Three scenarios for continual learning. arXiv preprint arXiv: 1904.07734, 2019. [35] Aljundi R, Kelchtermans K, Tuytelaars T. Task-free continual learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach, USA: IEEE, 2019. 11246−11255 [36] Lee S, Ha J, Zhang D S, Kim G. A neural dirichlet process mixture model for task-free continual learning. In: Proceedings of the 8th International Conference on Learning Representations. Addis Ababa, Ethiopia: ICLR, 2020. 1−22 [37] Aljundi R, Lin M, Goujaud B, Bengio Y. Gradient based sample selection for online continual learning. In: Proceedings of the 33rd International Conference on Neural Information Processing Systems. Vancouver, Canada: Curran Associates Inc., 2019. Article No. 1058 [38] Bang J, Kim H, Yoo Y J, Ha J W, Choi J. Rainbow memory: Continual learning with a memory of diverse samples. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Nashville, USA: IEEE, 2021. 8214−8223 [39] Kim C D, Jeong J, Moon S, Kim G. Continual learning on noisy data streams via self-purified replay. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. Montreal, Canada: IEEE, 2021. 517−527 [40] Karim N, Khalid U, Esmaeili A, Rahnavard N. CNLL: A semi-supervised approach for continual noisy label learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans, USA: 2022. 3877−3887 [41] Chrysakis A, Moens M F. Online continual learning from imbalanced data. In: Proceedings of the 37th International Conference on Machine Learning. Virtual Event: PMLR, 2020. 1952−1961 [42] Kim C D, Jeong J, Kim G. Imbalanced continual learning with partitioning reservoir sampling. In: Proceedings of the 16th European Conference on Computer Vision. Glasgow, UK: Springer, 2020. 411−428 [43] Koh H, Kim D, Ha J W, Choi J. Online continual learning on class incremental blurry task configuration with anytime inference. In: Proceedings of the 10th International Conference on Learning Representations. Virtual Event: ICLR, 2022. 1−21 [44] Ratcliff R. Connectionist models of recognition memory: Constraints imposed by learning and forgetting functions. Psychological Review, 1990, 97(2): 285−308 doi: 10.1037/0033-295X.97.2.285 [45] Robins A. Catastrophic forgetting, rehearsal and pseudorehearsal. Connection Science, 1995, 7(2): 123−146 doi: 10.1080/09540099550039318 [46] Rebuffi S A, Kolesnikov A, Sperl G, Lampert C H. iCaRL: Incremental classifier and representation learning. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, USA: IEEE, 2017. 5533−5542 [47] Buzzega P, Boschini M, Porrello A, Abati D, Calderara S. Dark experience for general continual learning: A strong, simple baseline. In: Proceedings of the 34th International Conference on Neural Information Processing Systems. Vancouver, Canada: Curran Associates Inc., 2020. Article No. 1335 [48] Bellitto G, Salanitri F P, Pennisi M, Bonicelli L, Porrello A, Calderara S, et al. Saliency-driven experience replay for continual learning. In: Proceedings of the 38th International Conference on Neural Information Processing Systems. Vancouver, Canada: NeurIPS, 2024. 1−28 [49] LeCun Y, Bottou L, Bengio Y, Haffner P. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 1998, 86(11): 2278−2324 doi: 10.1109/5.726791 [50] Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks. In: Proceedings of the 26th International Conference on Neural Information Processing Systems. Lake Tahoe, USA: Curran Associates Inc., 2012. 1097−1105 [51] Zhang H Y, Cisse M, Dauphin Y N, Lopez-Paz D. Mixup: Beyond empirical risk minimization. In: Proceedings of the 6th International Conference on Learning Representations. Vancouver, Canada: ICLR, 2018. 1−13 [52] Buzzega P, Boschini M, Porrello A, Calderara S. Rethinking experience replay: A bag of tricks for continual learning. In: Proceedings of the 25th International Conference on Pattern Recognition (ICPR). Milan, Italy: IEEE, 2021. 2180−2187 [53] Zhang Y Q, Pfahringer B, Frank E, Bifet A, Lim N J S, Jia Y Z. A simple but strong baseline for online continual learning: Repeated augmented rehearsal. In: Proceedings of the 36th Neural Information Processing Systems. New Orleans, USA: NeurIPS, 2022. 1−13 [54] Wang L Y, Zhang X X, Yang K, Yu L H, Li C X, Hong L Q, et al. Memory replay with data compression for continual learning. In: Proceedings of the 10th International Conference on Learning Representations. Virtual Event: ICLR, 2022. 1−25 [55] Wallace G K. The JPEG still picture compression standard. Communications of the ACM, 1991, 34(4): 30−44 doi: 10.1145/103085.103089 [56] Isele D, Cosgun A. Selective experience replay for lifelong learning. In: Proceedings of the 32nd AAAI Conference on Artificial Intelligence. New Orleans, USA: AAAI Press, 2018. 3302−3309 [57] Killamsetty K, Sivasubramanian D, Ramakrishnan G, Iyer R. GLISTER: Generalization based data subset selection for efficient and robust learning. In: Proceedings of the 35th AAAI Conference on Artificial Intelligence. Virtual Event: AAAI Press, 2021. 8110−8118 [58] Yoon J, Madaan D, Yang E, Hwang S J. Online coreset selection for rehearsal-based continual learning. In: Proceedings of the 10th International Conference on Learning Representations. Virtual Event: ICLR, 2022. 1−16 [59] Sun S Y, Calandriello D, Hu H Y, Li A, Titsias M K. Information-theoretic online memory selection for continual learning. In: Proceedings of the 10th International Conference on Learning Representations. Virtual Event: ICLR, 2022. 1−25 [60] Welling M. Herding dynamical weights to learn. In: Proceedings of the 26th Annual International Conference on Machine Learning. Montreal, Canada: ACM, 2009. 1121−1128 [61] Borsos Z, Mutný M, Krause A. Coresets via bilevel optimization for continual learning and Streaming. In: Proceedings of the 34th International Conference on Neural Information Processing Systems. Vancouver, Canada: Curran Associates Inc., 2020. Article No. 1247 [62] Zhou X, Pi R J, Zhang W Z, Lin Y, Chen Z H, Zhang T. Probabilistic bilevel coreset selection. In: Proceedings of the 39th International Conference on Machine Learning. Baltimore, USA: PMLR, 2022. 27287−27302 [63] Hao J, Ji K Y, Liu M R. Bilevel coreset selection in continual learning: A new formulation and algorithm. In: Proceedings of the 37th International Conference on Neural Information Processing Systems. New Orleans, USA: Curran Associates Inc., 2023. Article No. 2220 [64] Tong R L, Liu Y H, Shi J Q, Gong D. Coreset selection via reducible loss in continual learning. In: Proceedings of the 13th International Conference on Learning Representations. Singapore, Singapore: ICLR, 2025. 1−36 [65] Verma T, Jin L Y, Zhou J, Huang J, Tan M R, Choong B C M, et al. Privacy-preserving continual learning methods for medical image classification: A comparative analysis. Frontiers in Medicine, 2023, 10: Article No. 1227515 doi: 10.3389/fmed.2023.1227515 [66] Mellado D, Saavedra C, Chabert S, Salas R. Pseudorehearsal approach for incremental learning of deep convolutional neural networks. In: Computational Neuroscience: First Latin American Workshop, LAWCN. Porto Alegre, Brazil: Springer International Publishing, 2017. 118−126 [67] Shin H, Lee J K, Kim J, Kim J. Continual learning with deep generative replay. In: Proceedings of the 31st International Conference on Neural Information Processing Systems. Long Beach, USA: Curran Associates Inc., 2017. 2994−3003 [68] Wu C S, Herranz L, Liu X L, Wang W X, van de Weijer J, Raducanu B. Memory replay GANs: Learning to generate new categories without forgetting. In: Proceedings of the 32nd International Conference on Neural Information Processing Systems. Montréal, Canada: Curran Associates Inc., 2018. 5966−5976 [69] Rios A, Itti L. Closed-loop memory GAN for continual learning. In: Proceedings of the 28th International Joint Conference on Artificial Intelligence. Macao, China: AAAI Press, 2019. 3332−3338 [70] Xiang Y, Fu Y, Ji P, Huang H. Incremental learning using conditional adversarial networks. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. Seoul, Korea (South): IEEE, 2019. 6618−6627 [71] Wang Z, Liu L, Duan Y Q, Tao D C. Continual learning through retrieval and imagination. In: Proceedings of the 36th AAAI Conference on Artificial Intelligence. Virtual Event: AAAI Press, 2022. 8594−8602 [72] Ayub A, Wagner A R. EEC: Learning to encode and regenerate images for continual learning. In: Proceedings of the 9th International Conference on Learning Representations. Virtual Event: ICLR, 2021. 1−16 [73] Chen P H, Wei W, Hsieh C J, Dai B. Overcoming catastrophic forgetting by Bayesian generative regularization. In: Proceedings of the 38th International Conference on Machine Learning. Virtual Event: PMLR, 2021. 1760−1770 [74] Wang T Z, Zhu J Y, Torralba A, Efros A A. Dataset distillation. arXiv preprint arXiv: 1811.10959, 2018. [75] Lei S Y, Tao D C. A comprehensive survey of dataset distillation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024, 46(1): 17−32 doi: 10.1109/TPAMI.2023.3322540 [76] Wiewel F, Yang B. Condensed composite memory continual learning. In: Proceedings of the International Joint Conference on Neural Networks (IJCNN). Shenzhen, China: IEEE, 2021. 1−8 [77] Sangermano M, Carta A, Cossu A, Bacciu D. Sample condensation in online continual learning. In: Proceedings of the International Joint Conference on Neural Networks (IJCNN). Padua, Italy: IEEE, 2022. 1−8 [78] Gu J Y, Wang K, Jiang W, You Y. Summarizing stream data for memory-constrained online continual learning. In: Proceedings of the 38th AAAI Conference on Artificial Intelligence. Vancouver, Canada: AAAI Press, 2024. 12217−12225 [79] Yin H X, Molchanov P, Alvarez J M, Li Z Z, Mallya A, Hoiem D, et al. Dreaming to distill: Data-free knowledge transfer via deepinversion. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle, USA: IEEE, 2020. 8712−8721 [80] Yin H X, Mallya A, Vahdat A, Alvarez J M, Kautz J, Molchanov P. See through gradients: Image batch recovery via gradinversion. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Nashville, TN, USA: IEEE, 2021. 16332−16341 [81] Smith J, Hsu Y C, Balloch J, Shen Y L, Jin H X, Kira Z. Always be dreaming: A new approach for data-free class-incremental learning. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. Montreal, Canada: IEEE, 2021. 9354−9364 [82] Liu X L, Wu C S, Menta M, Herranz L, Raducanu B, Bagdanov A D, et al. Generative feature replay for class-incremental learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Seattle, USA: IEEE, 2020. 915−924 [83] Iscen A, Zhang J, Lazebnik S, Schmid C. Memory-efficient incremental learning through feature adaptation. In: Proceedings of the 16th European Conference on Computer Vision. Glasgow, UK: Springer, 2020. 699−715 [84] Smith J S, Tian J J, Halbe S, Hsu Y C, Kira Z. A closer look at rehearsal-free continual learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Vancouver, Canada: IEEE, 2023. 2410−2420 [85] Gao R, Liu W W. DDGR: Continual learning with deep diffusion-based generative replay. In: Proceedings of the 40th International Conference on Machine Learning. Honolulu, USA: PMLR, 2023. 10744−10763 [86] Smith J S, Hsu Y C, Zhang L Y, Hua T, Kira Z, Shen Y L, et al. Continual diffusion: Continual customization of text-to-image diffusion with C-LoRA. Transactions on Machine Learning Research, 2024, 2024: 1−13 [87] Jodelet Q, Liu X, Phua Y J, Murata T. Class-incremental learning using diffusion model for distillation and replay. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023. Paris, France: IEEE, 3417−3425 [88] Zajac M, Deja K, Kuzina A, Tomczak J M, Trzcinski T, Shkurti F, et al. Exploring continual learning of diffusion models. arXiv preprint arXiv: 2303.15342, 2023. [89] Masip S, Rodriguez P, Tuytelaars T, van de Ven G M. Continual learning of diffusion models with generative distillation. In: Proceedings of the 3rd Conference on Lifelong Learning Agents. Pisa, Italy: PMLR, 2025. 431−456 [90] Cywinski B, Deja K, Trzcinski T, Twardowski B, Kucinski L. GUIDE: Guidance-based incremental learning with diffusion models. arXiv preprint arXiv: 2403.03938, 2024. [91] Hataya R, Bao H, Arai H. Will large-scale generative models corrupt future datasets? In: Proceedings of the IEEE/CVF International Conference on Computer Vision. Paris, France: IEEE, 2023. 20498−20508 [92] Martínez G, Watson L, Reviriego P, Hernández J A, Juarez M, Sarkar R. Towards understanding the interplay of generative artificial intelligence and the internet. In: Proceedings of the 1st International Workshop on Epistemic Uncertainty in Artificial Intelligence. Pittsburgh, USA: Springer, 2023. 59−73 [93] Wang M R, Michel N, Mao J F, Yamasaki T. Dealing with synthetic data contamination in online continual learning. In: Proceedings of the 38th Annual Conference on Neural Information Processing Systems. Vancouver, Vancouver: NeurIPS, 2024. 1−28 [94] Zuo Y K, Yao H T, Yu L, Zhuang L S, Xu C S. Hierarchical prompts for rehearsal-free continual learning. arXiv preprint arXiv: 2401.11544, 2024. [95] Hatamizadeh A, Yin H X, Roth H, Li W Q, Kautz J, Xu D G, et al. GradViT: Gradient inversion of vision transformers. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans, USA: IEEE, 2022. 10011−10020 [96] Cai Y L, Thomason J, Rostami M. Task-attentive transformer architecture for continual learning of vision-and-language tasks using knowledge distillation. In: Proceedings of the Findings of the Association for Computational Linguistics (EMNLP). Singapore, Singapore: Association for Computational Linguistics, 2023. 6986−7000 [97] Zhang X, Zhang F F, Xu C S. VQACL: A novel visual question answering continual learning setting. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Vancouver, Canada: IEEE, 2023. 19102−19112 [98] Yang R, Wang S, Zhang H, Xu S Y, Guo Y H, Ye X T, et al. Knowledge decomposition and replay: A novel cross-modal image-text retrieval continual learning method. In: Proceedings of the 31st ACM International Conference on Multimedia. Ottawa, Canada: Association for Computing Machinery, 2023. 6510−6519 [99] Yan S P, Hong L Q, Xu H, Han J H, Tuytelaars T, Li Z F, et al. Generative negative text replay for continual vision-language pretraining. In: Proceedings of the 17th European Conference on Computer Vision. Tel Aviv, Israel: Springer, 2022. 22−38 [100] Lei S W, Gao D F, Wu J Z, Wang Y X, Liu W, Zhang M M, et al. Symbolic replay: Scene graph as prompt for continual learning on VQA task. In: Proceedings of the 37th AAAI Conference on Artificial Intelligence. Washington, USA: AAAI Press, 2023. 1250−1259 [101] Cheng S X, He C Y, Chen K L, Xu L F, Li H L, Meng F M, et al. Vision-sensor attention based continual multimodal egocentric activity recognition. In: Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). Seoul, Korea: IEEE, 2024. 6300−6304 [102] Geirhos R, Jacobsen J H, Michaelis C, Zemel R, Brendel W, Bethge M, et al. Shortcut learning in deep neural networks. Nature Machine Intelligence, 2020, 2(11): 665−673 doi: 10.1038/s42256-020-00257-z [103] Wei Y J, Ye J X, Huang Z Z, Zhang J P, Shan H M. Online prototype learning for online continual learning. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. Paris, France: IEEE, 2023. 18718−18728 [104] Kim D, Park D, Shin Y, Bang J, Song H, Lee J G. Adaptive shortcut debiasing for online continual learning. In: Proceedings of the 38th AAAI Conference on Artificial Intelligence. Vancouver, Canada: AAAI Press, 2024. 13122−13131 [105] Jing L L, Tian Y L. Self-supervised visual feature learning with deep neural networks: A survey. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021, 43(11): 4037−4058 doi: 10.1109/TPAMI.2020.2992393 [106] Cha H, Lee J, Shin J. Co.2L: Contrastive continual learning. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. Montreal, Canada: IEEE, 2021. 9496−9505 [107] Gomez-Villa A, Twardowski B, Yu L, Bagdanov A D, van de Weijer J. Continually learning self-supervised representations with projected functional regularization. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans, USA: IEEE, 2022. 3866−3876 [108] Purushwalkam S, Morgado P, Gupta A. The challenges of continuous self-supervised learning. In: Proceedings of the 17th European Conference on Computer Vision. Tel Aviv, Israel: Springer, 2022, 702−721 [109] Yao L Y, Chu Z X, Li S Y, Li Y L, Gao J, Zhang A D. A survey on causal inference. ACM Transactions on Knowledge Discovery from Data, 2021, 15(5): Article No. 74 [110] Hu X T, Tang K H, Miao C Y, Hua X S, Zhang H W. Distilling causal effect of data in class-incremental learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Nashville, USA: IEEE, 2021. 3956−3965 [111] Chu Z X, Li R P, Rathbun S, Li S. Continual causal inference with incremental observational data. In: Proceedings of the 39th International Conference on Data Engineering (ICDE). Anaheim, USA: IEEE, 2023. 3430−3439 [112] Wang L Y, Yang K, Li C X, Hong L Q, Li Z G, Zhu J. ORDisCo: Effective and efficient usage of incremental unlabeled data for semi-supervised continual learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Nashville, USA: IEEE, 2021. 5379−5388 [113] Smith J, Balloch J, Hsu Y C, Kira Z. Memory-efficient semi-supervised continual learning: The world is its own replay buffer. In: Proceedings of the International Joint Conference on Neural Networks (IJCNN). Shenzhen, China: IEEE, 2021. 1−8 [114] Luo Y, Wong Y K, Kankanhalli M, Zhao Q. Learning to predict gradients for semi-supervised continual learning. IEEE Transactions on Neural Networks and Learning Systems, 2025, 36(2): 2593−2607 doi: 10.1109/TNNLS.2024.3361375 [115] O'Reilly R C, Bhattacharyya R, Howard M D, Ketz N. Complementary learning systems. Cognitive Science, 2014, 38(6): 1229−1248 doi: 10.1111/j.1551-6709.2011.01214.x [116] Pham Q, Liu C H, Hoi S C H. DualNet: Continual learning, fast and slow. In: Proceedings of the 35th International Conference on Neural Information Processing Systems. Virtual Event: Curran Associates Inc., 2021. Article No. 1234 [117] Arani E, Sarfraz F, Zonooz B. Learning fast, learning slow: A general continual learning method based on complementary learning system. In: Proceedings of the 10th International Conference on Learning Representations. Virtual Event: ICLR, 2022. 1−22 [118] Ren X Y, Qin Y, Wang B, Cheng X Q, Jia L M. A complementary continual learning framework using incremental samples for remaining useful life prediction of machinery. IEEE Transactions on Industrial Informatics, 2024, 20(12): 14330−14340 doi: 10.1109/TII.2024.3450077 [119] Mai Z D, Li R W, Kim H, Sanner S. Supervised contrastive replay: Revisiting the nearest class mean classifier in online class-incremental continual learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPR). Nashville, USA: IEEE, 2021. 3584−3594 [120] Rypeść G, Cygert S, Trzciński T, Twardowski B. Task-recency bias strikes back: Adapting covariances in exemplar-free class incremental learning. In: Proceedings of the 38th Annual Conference on Neural Information Processing Systems, Vancouver, Canada: NeurIPS, 2024. 63268−63289 [121] Wang Q Z A, Wang R Z, Wu Y C, Jia X X, Meng D Y. CBA: Improving online continual learning via continual bias adaptor. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. Paris, France: IEEE, 2023. 19036−19046 [122] Hou S H, Pan X Y, Loy C C, Wang Z L, Lin D H. Learning a unified classifier incrementally via rebalancing. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach, USA: IEEE, 2019. 831−839 [123] Ahn H, Kwak J, Lim S, Bang H, Kim H, Moon T. SS-IL: Separated softmax for incremental learning. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. Montreal, Canada: IEEE, 2021. 824−833 [124] Wu Y, Chen Y P, Wang L J, Ye Y C, Liu Z X, Guo Y D, et al. Large scale incremental learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach, USA: IEEE, 2019. 374−382 [125] Caccia L, Aljundi R, Asadi N, Tuytelaars T, Pineau J, Belilovsky E. New insights on reducing abrupt representation change in online continual learning. In: Proceedings of the 10th International Conference on Learning Representations. Virtual Event: ICLR, 2022. 1−27 [126] Yu L, Twardowski B, Liu X L, Herranz L, Wang K, Cheng Y M, et al. Semantic drift compensation for class-incremental learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle, USA: IEEE, 2020. 6980−6989 [127] Zhu K, Zhai W, Cao Y, Luo J B, Zha Z J. Self-sustaining representation expansion for non-exemplar class-incremental learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022. New Orleans, USA: IEEE, 9286−9295 [128] Pham Q, Liu C H, Hoi S C H. Continual normalization: Rethinking batch normalization for online continual learning. In: Proceedings of the 10th International Conference on Learning Representations. Virtual Event: ICLR, 2022. 1−20 [129] Cha S M, Cho S, Hwang D, Hong S, Lee M, Moon T. Rebalancing batch normalization for exemplar-based class-incremental learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Vancouver, BC, Canada: IEEE, 2023. 20127−20136 [130] Lyu Y L, Wang L Y, Zhang X X, Sun Z C, Su H, Zhu J, et al. Overcoming recency bias of normalization statistics in continual learning: Balance and adaptation. In: Proceedings of the 37th International Conference on Neural Information Processing Systems. New Orleans, USA: Curran Associates Inc., 2023. Article No. 1108 [131] Wang Q Z, Wang R Z, Wu Y C, Jia X X, Zhou M H, Meng D Y. Dual-CBA: Improving online continual learning via dual continual bias adaptors from a bi-level optimization perspective. arXiv preprint arXiv: 2408.13991, 2024. [132] Rusu A A, Rabinowitz N C, Desjardins G, Soyer H, Kirkpatrick J, Kavukcuoglu K, et al. Progressive neural networks. arXiv preprint arXiv: 1606.04671, 2016. [133] Yan S P, Xie J W, He X M. DER: Dynamically expandable representation for class incremental learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Nashville, USA: IEEE, 2021. 3013−3022 [134] Mallya A, Lazebnik S. PackNet: Adding multiple tasks to a single network by iterative pruning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 7765−7773 [135] Golkar S, Kagan M, Cho K. Continual learning via neural pruning. arXiv preprint arXiv: 1903.04476, 2019. [136] Yoon J, Kim S, Yang E, Hwang S J. Scalable and order-robust continual learning with additive parameter decomposition. In: Proceedings of the 8th International Conference on Learning Representations. Addis Ababa, Ethiopia: ICLR, 2020. 1−15 [137] Hihn H, Braun D A. Mixture-of-variational-experts for continual learning. arXiv preprint arXiv: 2110.12667, 2021. [138] Wang L Y, Zhang X X, Li Q, Zhu J, Zhong Y. CoSCL: Cooperation of small continual learners is stronger than a big one. In: Proceedings of the 17th European Conference on Computer Vision. Tel Aviv, Israel: Springer, 2022, 254−271 [139] Zhou Y Q, Lei T, Liu H X, Du N, Huang Y P, Zhao V T, et al. Mixture-of-experts with expert choice routing. In: Proceedings of the 36th International Conference on Neural Information Processing Systems. New Orleans, USA: Curran Associates Inc., 2022. Article No. 515 [140] Abati D, Tomczak J, Blankevoort T, Calderara S, Cucchiara R, Bejnordi B E. Conditional channel gated networks for task-aware continual learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle, USA: IEEE, 2020. 3930−3939 [141] Mallya A, Davis D, Lazebnik S. Piggyback: Adapting a single network to multiple tasks by learning to mask weights. In: Proceedings of the 15th European Conference on Computer Vision. Munich, Germany: Springer, 2018. 67−82 [142] Wortsman M, Ramanujan V, Liu R, Kembhavi A, Rastegari M, Yosinski J, et al. Supermasks in superposition. In: Proceedings of the 34th Annual Conference on Neural Information Processing Systems. Virtual Event: Curran Associates Inc., 2020. 15173−15184 [143] Kang H, Mina R J L, Madjid S R H, Yoon J, Hasegawa-Johnson M, Hwang S J, et al. Forget-free continual learning with winning subnetworks. In: Proceedings of the 39th International Conference on Machine Learning. Baltimore, USA: PMLR, 2022. 10734−10750 [144] Kang H, Yoon J, Madjid S R H, Hwang S J, Yoo C D. On the soft-subnetwork for few-shot class incremental learning. In: Proceedings of the 11th International Conference on Learning Representations. Kigali, Rwanda: ICLR, 2023. 1−23 [145] Gao Q, Shan X J, Zhang Y C, Zhou F. Enhancing knowledge transfer for task incremental learning with data-free subnetwork. In: Proceedings of the 37th International Conference on Neural Information Processing Systems. New Orleans, USA: Curran Associates Inc., 2023. Article No. 2994 [146] Fini E, da Costa V G T, Alameda-Pineda X, Ricci E, Alahari K, Mairal J. Self-supervised models are continual learners. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans, USA: IEEE, 2022. 9611−9620 [147] Ye Y W, Xie Y T, Zhang J P, Chen Z Y, Wu Q, Xia Y. Continual self-supervised learning: Towards universal multi-modal medical data representation learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle, USA: IEEE, 2024. 11114−11124 [148] McDonnell M D, Gong D, Parveneh A, Abbasnejad E, van den Hengel A. RanPAC: Random projections and pre-trained models for continual learning. In: Proceedings of the 37th International Conference on Neural Information Processing Systems. New Orleans, USA: Curran Associates Inc., 2024. Article No. 526 [149] Zhang G W, Wang L Y, Kang G L, Cheng L, Wei Y C. SLCA: Slow learner with classifier alignment for continual learning on a pre-trained model. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. Paris, France: IEEE, 2023. 19091−19101 [150] Zhang G W, Wang L Y, Kang G L, Cheng L, Wei Y C. SLCA++: Unleash the power of sequential fine-tuning for continual learning with pre-training. arXiv preprint arXiv: 2408.08295, 2024. [151] He J P, Zhu F Q. Exemplar-free online continual learning. In: Proceedings of the IEEE International Conference on Image Processing (ICIP). Bordeaux, France: IEEE, 2022. 541−545 [152] Zhuang H P, Weng Z Y, Wei H Z, Xie R C Z, Toh K A, Lin Z P. ACIL: Analytic class-incremental learning with absolute memorization and privacy protection. In: Proceedings of the 36th International Conference on Neural Information Processing Systems, New Orleans, USA: Curran Associates Inc., 2022. Article No. 843 [153] Zhuang H P, He R, Tong K, Zeng Z Q, Chen C, Lin Z P. DS-AL: A dual-stream analytic learning for exemplar-free class-incremental learning. In: Proceedings of the 38th AAAI Conference on Artificial Intelligence. Vancouver, Canada: AAAI Press, 2024. 17237−17244 [154] Wang Z F, Zhang Z Z, Lee C Y, Zhang H, Sun R X, Ren X Q, et al. Learning to prompt for continual learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans, USA: IEEE, 2022. 139−149 [155] Wang Z F, Zhang Z Z, Ebrahimi S, Sun R X, Zhang H, Lee C Y, et al. DualPrompt: Complementary prompting for rehearsal-free continual learning. In: Proceedings of the 17th European Conference on Computer Vision. Tel Aviv, Israel: Springer, 2022. 631−648 [156] Smith J S, Karlinsky L, Gutta V, Cascante-Bonilla P, Kim D, Arbelle A, et al. Coda-prompt: Continual decomposed attention-based prompting for rehearsal-free continual learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Vancouver, Canada: IEEE, 2023. 11909−11919 [157] Wang L Y, Xie J Y, Zhang X X, Huang M Y, Zhu J. Hierarchical decomposition of prompt-based continual learning: Rethinking obscured sub-optimality. In: Proceedings of the 37th International Conference on Neural Information Processing Systems. New Orleans, USA: Curran Associates Inc., 2024. Article No. 3022 [158] Chen H R, Wu Z X, Han X T, Jia M L, Jiang Y G. PromptFusion: Decoupling stability and plasticity for continual learning. In: Proceedings of the 18th European Conference on Computer Vision. Milan, Italy: Springer, 2023. 196−212 [159] Wang Y B, Huang Z W, Hong X P. S-prompts learning with pre-trained transformers: An Occam's razor for domain incremental learning. In: Proceedings of the 36th International Conference on Neural Information Processing Systems. New Orleans, USA: Curran Associates Inc., 2022. Article No. 411 [160] Kang Z Q, Wang L Y, Zhang X X, Alahari K. Advancing prompt-based methods for replay-independent general continual learning. In: Proceedings of the 13th International Conference on Learning Representations. Singapore, Singapore: ICLR, 2025. 1−19 [161] Gao Z, Cen J, Chang X. Consistent prompting for rehearsal-free continual learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle, USA: 2024: 28463−28473 [162] Huang W C, Chen C F, Hsu H. OVOR: OnePrompt with virtual outlier regularization for rehearsal-free class-incremental learning. In: Proceedings of the 12th International Conference on Learning Representations. Vienna, Austria: ICLR, 2024. 1−20 [163] Jung D, Han D, Bang J, Song H. Generating instance-level prompts for rehearsal-free continual learning. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. Paris, France: IEEE, 2023. 11813−11823 [164] Tang Y M, Peng Y X, Zheng W S. When prompt-based incremental learning does not meet strong pretraining. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023. 1706−1716 [165] Yang C Y, Liu W T, Chen S S, Qi J Y, Zhou A M. Generating prompts in latent space for rehearsal-free continual learning. In: Proceedings of the 32nd ACM International Conference on Multimedia. Melbourne, Australia: Association for Computing Machinery, 2024. 8913−8922 [166] Zheng J H, Ma Q L, Liu Z, Wu B Q, Feng H W. Beyond anti-forgetting: Multimodal continual instruction tuning with positive forward transfer. arXiv preprint arXiv: 2401.09181, 2024. [167] D'Alessandro M, Alonso A, Calabrés E, Galar M. Multimodal parameter-efficient few-shot class incremental learning. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. Paris, France: IEEE, 2023. 3385−3395 [168] Qian Z, Wang X, Duan X G, Qin P D, Li Y H, Zhu W W. Decouple before interact: Multi-modal prompt learning for continual visual question answering. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. Paris, France: IEEE, 2023. 2941−2950 [169] Li J S, Wang S K, Qian B, He Y H, Wei X, Gong Y H. Dynamic integration of task-specific adapters for class incremental learning. arXiv preprint arXiv: 2409.14983, 2024. [170] Liang Y S, Li W J. InfLoRA: Interference-free low-rank adaptation for continual learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle, USA: IEEE, 2024. 23638−23647 [171] Zhao L L, Zhang X R, Yan K, Ding S H, Huang W R. SAFE: Slow and fast parameter-efficient tuning for continual learning with pre-trained models. In: Proceedings of the 38th Annual Conference on Neural Information Processing Systems. Vancouver, Canada: NeurIPS, 2024. 1−25 [172] Zhang X, Bai L, Yang X, Liang J Y. C-LoRA: Continual low-rank adaptation for pre-trained models. arXiv preprint arXiv: 2502.17920, 2025. [173] Wu Y C, Piao H M, Huang L K, Wang R Z, Li W H, Pfister H, et al. SD-LoRA: Scalable decoupled low-rank adaptation for class incremental learning. In: Proceedings of the 13th International Conference on Learning Representations. Singapore, Singapore: ICLR, 2025. 1−17 [174] Wei X W, Li G H, Marculescu R. Online-LoRA: Task-free online continual learning via low rank adaptation. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV). Tucson, USA: IEEE, 2025, 6634−6645 [175] He J P, Duan Z H, Zhu F Q. CL-LoRA: Continual low-rank adaptation for rehearsal-free class-incremental learning. arXiv preprint arXiv: 2505.24816, 2025 [176] Jin Y, Liu J, Chen S. Multi-LoRA continual learning based instruction tuning framework for universal information extraction. Knowledge-Based Systems, 2025, 308: Article No. 112750 [177] Liu X, Chang X B. LoRA subtraction for drift-resistant space in exemplar-free continual learning. arXiv preprint arXiv: 2503.18985, 2025. [178] Lu Y, Zhang S, Cheng D, Liang G, Xing Y, Wang N, et al. Training consistent mixture-of-experts-based prompt generator for continual learning. In: Proceedings of the AAAI Conference on Artificial Intelligence. Philadelphia, USA: AAAI Press, 2025. 19152−19160 [179] Le M, Nguyen A, Nguyen H, Nguyen T, Pham T, Van Ngo L, et al. Mixture of experts meets prompt-based continual learning. In: Proceedings of the 38th Annual Conference on Neural Information Processing Systems. Vancouver, Canada: NeurIPS, 2024. 1−38 [180] Jung M J, Kim J. PMoE: Progressive mixture of experts with asymmetric transformer for continual learning. arXiv preprint arXiv: 2407.21571, 2024. [181] Yang S, Ali M A, Wang C L, Hu L J, Wang D. MoRAL: MoE augmented LoRA for LLMs'lifelong learning. arXiv preprint arXiv: 2402.11260, 2024. [182] Marouf I E, Roy S, Tartaglione E, Lathuilière S. Weighted ensemble models are strong continual learners. In: Proceedings of the 18th European Conference on Computer Vision. Milan, Italy: Springer, 2024. 306−324 [183] Wang H Y, Lu H D, Yao L N, Gong D. Self-expansion of pre-trained models with mixture of adapters for continual learning. In: Proceedings of the 38th Conference on Neural Information Processing Systems. Vancouver, Canada: NeurIPS, 2024. 1−20 [184] Zhao H, Wang Z, Sun Q, Song K, Li Y, Hu X, et al. LLaVA-CMoE: Towards continual mixture of experts for large vision-language models. arXiv preprint arXiv: 2503.21227, 2025. [185] Song G, Tan X Y. Real-world cross-modal retrieval via sequential learning. IEEE Transactions on Multimedia, 2021, 23: 1708−1721 doi: 10.1109/TMM.2020.3002177 [186] Sun F C, Liu H P, Yang C, Fang B. Multimodal continual learning using online dictionary updating. IEEE Transactions on Cognitive and Developmental Systems, 2021, 13(1): 171−178 doi: 10.1109/TCDS.2020.2973280 [187] Peng Y X, Qi J W, Ye Z D, Zhuo Y K. Hierarchical visual-textual knowledge distillation for life-long correlation learning. International Journal of Computer Vision, 2021, 129(4): 921−941 doi: 10.1007/s11263-020-01392-1 [188] Yu J Z, Zhuge Y Z, Zhang L, Hu P, Wang D, Lu H C, et al. Boosting continual learning of vision-language models via mixture-of-experts adapters. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle, USA: IEEE, 2024. 23219−23230 [189] Jha S, Gong D, Yao L N. CLAP4CLIP: Continual learning with probabilistic finetuning for vision-language models. In: Proceedings of the 38th Annual Conference on Neural Information Processing Systems. Vancouver, Canada: NeurIPS, 2024. 1−41 [190] Gao Z J, Zhang X X, Xu K L, Mao X J, Wang H M. Stabilizing zero-shot prediction: A novel antidote to forgetting in continual vision-language tasks. In: Proceedings of the 38th Annual Conference on Neural Information Processing Systems. Vancouver, Canada: NeurIPS, 2024. 1−27 [191] Zheng J H, Cai X D, Qiu S J, Ma Q L. Spurious forgetting in continual learning of language models. In: Proceedings of the 13th International Conference on Learning Representations. Singapore, Singapore: ICLR, 2025. 1−66 [192] Hinton G E, Vinyals O, Dean J. Distilling the knowledge in a neural network. arXiv preprint arXiv: 1503.02531, 2015. [193] Gou J P, Yu B S, Maybank S J, Tao D C. Knowledge distillation: A survey. International Journal of Computer Vision, 2021, 129(6): 1789−1819 doi: 10.1007/s11263-021-01453-z [194] Li Z Z, Hoiem D. Learning without forgetting. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(12): 2935−2947 doi: 10.1109/TPAMI.2017.2773081 [195] Kirkpatrick J, Pascanu R, Rabinowitz N, Veness J, Desjardins G, Rusu A A, et al. Overcoming catastrophic forgetting in neural networks. Proceedings of the National Academy of Sciences of the United States of America, 2017, 114(13): 3521−3526 [196] Huszár F. On quadratic penalties in elastic weight consolidation. arXiv preprint arXiv: 1712.03847, 2017. [197] Ritter H, Botev A, Barber D. Online structured Laplace approximations for overcoming catastrophic forgetting. In: Proceedings of the 32nd International Conference on Neural Information Processing Systems. Montréal, Canada: Curran Associates Inc., 2018. 3742−3752 [198] Zenke F, Poole B, Ganguli S. Continual learning through synaptic intelligence. In: Proceedings of the 34th International Conference on Machine Learning. Sydney, Australia: PMLR, 2017. 3987−3995 [199] Wu Y C, Huang L K, Wang R Z, Meng D Y, Wei Y. Meta continual learning revisited: Implicitly enhancing online hessian approximation via variance reduction. In: Proceedings of the 12th International Conference on Learning Representations. Vienna, Austria: ICLR, 2024. 1−30 [200] Lopez-Paz D, Ranzato M A. Gradient episodic memory for continual learning. In: Proceedings of the 31st International Conference on Neural Information Processing Systems. Long Beach, USA: Curran Associates Inc., 2017. 6470−6479 [201] Chaudhry A, Ranzato M A, Rohrbach M, Elhoseiny M. Efficient lifelong learning with A-GEM. In: Proceedings of the 7th International Conference on Learning Representations. New Orleans, USA: ICLR, 2018. 1−20 [202] Tang S X, Chen D P, Zhu J G, Yu S J, Ouyang W L. Layerwise optimization by gradient decomposition for continual learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Nashville, USA: IEEE, 2021. 9629−9638 [203] Wang S P, Li X R, Sun J, Xu Z B. Training networks in null space of feature covariance for continual learning. In: Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition. Nashville, USA: IEEE, 2021. 184−193 [204] Kong Y J, Liu L, Wang Z, Tao D C. Balancing stability and plasticity through advanced null space in continual learning. In: Proceedings of the 17th European Conference on Computer Vision. Tel Aviv, Israel: Springer, 2022. 219−236 [205] Dinh L, Pascanu R, Bengio S, Bengio Y. Sharp minima can generalize for deep nets. In: Proceedings of the 34th International Conference on Machine Learning. Sydney, Australia: PMLR, 2017. 1019−1028 [206] Foret P, Kleiner A, Mobahi H, Neyshabur B. Sharpness-aware minimization for efficiently improving generalization. In: Proceedings of the 9th International Conference on Learning Representations. Virtual Event: ICLR, 2021. 1−19 [207] Liu Y, Mai S Q, Chen X N, Hsieh C H, You Y. Towards efficient and scalable sharpness-aware minimization. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans, USA: IEEE, 2022. 12350−12360 [208] Yang E N, Shen L, Wang Z Y, Liu S W, Guo G B, Wang X W. Data augmented flatness-aware gradient projection for continual learning. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. Paris, France: IEEE, 2023. 5607−5616 [209] Chen R H, Jing X Y, Wu F, Chen H W. Sharpness-aware gradient guidance for few-shot class-incremental learning. Knowledge-Based Systems, 2024, 299: Article No. 112030 doi: 10.1016/j.knosys.2024.112030 [210] Yang E N, Shen L, Wang Z Y, Liu S W, Guo G B, Wang X W, et al. Revisiting flatness-aware optimization in continual learning with orthogonal gradient projection. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025, 47(5): 3895−3907 doi: 10.1109/TPAMI.2025.3539019 [211] Bian A, Li W, Yuan H J, Yu C R, Wang M, Zhao Z X, et al. Make continual learning stronger via C-flat. In: Proceedings of the 38th Annual Conference on Neural Information Processing Systems. Vancouver, Canada: NeurIPS, 2024. 7608−7630 [212] Finn C, Abbeel P, Levine S. Model-agnostic meta-learning for fast adaptation of deep networks. In: Proceedings of the 34th International Conference on Machine Learning. Sydney, Australia: PMLR, 2017. 1126−1135 [213] Hospedales T, Antoniou A, Micaelli P, Storkey A. Meta-learning in neural networks: A survey. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(9): 5149−5169 [214] Riemer M, Cases I, Ajemian R, Liu M, Rish I, Tu Y, et al. Learning to learn without forgetting by maximizing transfer and minimizing interference. In: Proceedings of the 7th International Conference on Learning Representations. New Orleans, USA: ICLR, 2019. 1−31 [215] Gupta G, Yadav K, Paull L. Look-ahead meta learning for continual learning. In: Proceedings of the 34th Annual Conference on Neural Information Processing Systems. Virtual Event: Curran Associates Inc., 2020. 11588−11598 [216] Javed K, White M. Meta-learning representations for continual learning. In: Proceedings of the 33rd International Conference on Neural Information Processing Systems, Vancouver, Canada: Curran Associates Inc., 2019. Article No. 163 [217] He X, Sygnowski J, Galashov A, Rusu A A, Teh Y W, Pascanu R. Task agnostic continual learning via meta learning. In: Proceedings of the 37th International Conference on Machine Learning. Virtual Event: PMLR, 2020. [218] Beaulieu S, Frati L, Miconi T, Lehman J, Stanley K O, Clune J, et al. Learning to continually learn. In: Proceedings of the 24th European Conference on Artificial Intelligence. Santiago de Compostela, Spain: IOS Press, 2020. 992−1001 [219] He J H, Guo H Y, Tang M, Wang J Q. Continual instruction tuning for large multimodal models. arXiv preprint arXiv: 2311.16206, 2023. [220] Qiao J Y, Zhang Z Z, Tan X, Chen C W, Qu Y Y, Peng Y, et al. Prompt gradient projection for continual learning. In: Proceedings of the 12th International Conference on Learning Representations. Vienna, Austria: ICLR, 2023. 1−22 [221] Lu Y, Zhang S Z, Cheng D, Xing Y H, Wang N N, Wang P, et al. Visual prompt tuning in null space for continual learning. In: Proceedings of the 38th Annual Conference on Neural Information Processing Systems. Vancouver, Canada: NeurIPS, 2024. 1−24 [222] Liu R H, Zhang J Y, Song Y Q, Zhang Y, Yang B L. Discarding the crutches: Adaptive parameter-efficient expert meta-learning for continual semantic parsing. In: Proceedings of the 31st International Conference on Computational Linguistics. Abu Dhabi, UAE: Association for Computational Linguistics, 2025. 3560−3578 [223] Seo Y, Lee D, Yeo J. Train-attention: Meta-learning where to focus in continual knowledge learning. In: Proceedings of the 38th Annual Conference on Neural Information Processing Systems. Vancouver, Canada: NeurIPS, 2025. 58284−58308 [224] Pentina A, Lampert C H. A PAC-Bayesian bound for lifelong learning. In: Proceedings of the 31st International Conference on Machine Learning. Beijing, China: PMLR, 2014. 991−999 [225] Pentina A, Lampert C H. Lifelong learning with non-i.i.d. tasks. In: Proceedings of the 29th International Conference on Neural Information Processing Systems. Montreal, Canada: MIT Press, 2015. 1540−1548 [226] Ramesh R, Chaudhari P. Model zoo: A growing brain that learns continually. In: Proceedings of the 10th International Conference on Learning Representations. Virtual Event: ICLR, 2022. 1−27 [227] Nguyen C V, Li Y Z, Bui T D, Turner R E. Variational continual learning. In: Proceedings of the 6th International Conference on Learning Representations. Vancouver, Canada: ICLR, 2018. 1−18 [228] Andle J, Yasaei Sekeh S. Theoretical understanding of the information flow on continual learning performance. In: Proceedings of the 17th European Conference on Computer Vision. Tel Aviv, Israel: Springer, 2022. 86−101 [229] Peng B H, Risteski A. Continual learning: A feature extraction formalization, an efficient algorithm, and barriers. In: Proceedings of the 36th International Conference on Neural Information Processing Systems. New Orleans, USA: Curran Associates Inc., 2022. Article No. 2060 [230] Lin S, Ju P Z, Liang Y B, Shroff N. Theory on forgetting and generalization of continual learning. In: Proceedings of the 40th International Conference on Machine Learning. Honolulu, USA: PMLR, 2023. 21078−21100 [231] Goldfarb D, Hand P. Analysis of catastrophic forgetting for random orthogonal transformation tasks in the overparameterized regime. In: Proceedings of the 26th International Conference on Artificial Intelligence and Statistics. Valencia, Spain: PMLR, 2023. 2975−2993 [232] Ding M, Ji K Y, Wang D, Xu J H. Understanding forgetting in continual learning with linear regression. In: Proceedings of the 41st International Conference on Machine Learning. Vienna, Austria: PMLR, 2024. 10978−11001 [233] Li H B, Lin S, Duan L J, Liang Y B, Shroff N B. Theory on mixture-of-experts in continual learning. In: Proceedings of the 13th International Conference on Learning Representations. Singapore, Singapore: ICLR, 2025. 1−38 [234] Alquier P, Mai T T, Pontil M. Regret bounds for lifelong learning. In: Proceedings of the 20th International Conference on Artificial Intelligence and Statistics. Fort Lauderdale, USA: PMLR, 2017. 261−269 [235] Wu Y S, Wang P A, Lu C J. Lifelong optimization with low regret. In: Proceedings of the 22nd International Conference on Artificial Intelligence and Statistics. Naha, Japan: PMLR, 2019. 448−456 [236] Jacot A, Gabriel F, Hongler C. Neural tangent kernel: Convergence and generalization in neural networks. In: Proceedings of the 53rd Annual ACM SIGACT Symposium on Theory of Computing. Virtual Event: Association for Computing Machinery, 2018. Article No. 6 [237] Doan T, Bennani M A, Mazoure B, Rabusseau G, Alquier P. A theoretical analysis of catastrophic forgetting through the NTK overlap matrix. In: Proceedings of the 24th International Conference on Artificial Intelligence and Statistics. Virtual Event: PMLR, 2021. 1072−1080 [238] Krishnan R, Balaprakash P. Formalizing the generalization-forgetting trade-off in continual learning. In: Proceedings of the 35th International Conference on Neural Information Processing Systems. Virtual Event: Curran Associates Inc., 2021. Article No. 1322 [239] Kim G, Xiao C N, Konishi T, Ke Z X, Liu B. A theoretical study on solving continual learning. In: Proceedings of the 36th International Conference on Neural Information Processing Systems. New Orleans, USA: Curran Associates Inc., 2022. Article No. 366 [240] Sun S Y, Calandriello D, Hu H Y, Li A, Titsias M. Information-theoretic online memory selection for continual learning. In: Proceedings of the 10th International Conference on Learning Representations. Virtual Event: ICLR, 2022. 1−25 [241] Peng L Z, Elenter J, Agterberg J, Ribeiro A, Vidal R. TSVD: Bridging theory and practice in continual learning with pre-trained models. In: Proceedings of the 13th International Conference on Learning Representations. Singapore, Singapore: ICLR, 2025. 1−47 [242] Wang D Q, Shelhamer E, Liu S T, Olshausen B A, Darrell T. Tent: Fully test-time adaptation by entropy minimization. In: Proceedings of the 9th International Conference on Learning Representations. Virtual Event: ICLR, 2021. 1−15 [243] Wang Z Y, Yang E N, Shen L, Huang H. A comprehensive survey of forgetting in deep learning beyond continual learning. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025, 47(3): 1464−1483 doi: 10.1109/TPAMI.2024.3498346 [244] Liang J, He R, Tan T N. A comprehensive survey on test-time adaptation under distribution shifts. International Journal of Computer Vision, 2025, 133(1): 31−64 doi: 10.1007/s11263-024-02181-w [245] Gong T, Jeong J, Kim T, Shin J, Lee S J. NOTE: Robust continual test-time adaptation against temporal correlation. In: Proceedings of the 36th International Conference on Neural Information Processing Systems. New Orleans, USA: Curran Associates Inc., 2022. Article No. 1976 [246] Wang Q, Fink O, van Gool L, Dai D X. Continual test-time domain adaptation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans, USA: IEEE, 2022. 7191−7201 [247] Chen H R, Goldblum M, Wu Z X, Jiang Y G. Adaptive retention & correction: Test-time training for continual learning. In: Proceedings of the 13th International Conference on Learning Representations. Singapore, Singapore: ICLR, 2025. 1−13 [248] Niu S C, Wu J X, Zhang Y F, Chen Y F, Zheng S J, Zhao P L, et al. Efficient test-time model adaptation without forgetting. In: Proceedings of the 39th International Conference on Machine Learning. Baltimore, USA: PMLR, 2022. 16888−16905 [249] Döbler M, Marsden R A, Yang B. Robust mean teacher for continual and gradual test-time adaptation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, Canada: IEEE, 2023. 7704−7714 [250] Yang P N, Liang J, Cao J, He R. Auto: Adaptive outlier optimization for online test-time OOD detection. arXiv preprint arXiv: 2303.12267, 2023. [251] Cao Y Z, Yang J F. Towards making systems forget with machine unlearning. In: Proceedings of the IEEE Symposium on Security and Privacy. San Jose, USA: IEEE, 2015. 463−480 [252] Bourtoule L, Chandrasekaran V, Choquette-Choo C A, Jia H R, Travers A, Zhang B W, et al. Machine unlearning. In: Proceedings of the IEEE Symposium on Security and Privacy. San Francisco, USA: IEEE, 2021. 141−159 [253] Nguyen T T, Huynh T T, Ren Z, Nguyen P L, Liew A W C, Yin H Z, et al. A survey of machine unlearning. arXiv preprint arXiv: 2209.02299, 2022. [254] Wang W Q, Tian Z Y, Zhang C H, Yu S. Machine unlearning: A comprehensive survey. arXiv preprint arXiv: 2405.07406, 2024. [255] Wu Y J, Dobriban E, Davidson S. DeltaGrad: Rapid retraining of machine learning models. In: Proceedings of the 37th International Conference on Machine Learning. Virtual Event: PMLR, 2020. 10355−10366 [256] Sekhari A, Acharya J, Kamath G, Suresh A T. Remember what you want to forget: Algorithms for machine unlearning. In: Proceedings of the 35th International Conference on Neural Information Processing Systems. Virtual Event: Curran Associates Inc., 2021. Article No. 1383 [257] Guo C, Goldstein T, Hannun A, van der Maaten L. Certified data removal from machine learning models. In: Proceedings of the 37th International Conference on Machine Learning. Virtual Event: PMLR, 2020. 3832−3842 [258] Golatkar A, Achille A, Soatto S. Eternal sunshine of the spotless net: Selective forgetting in deep networks. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle, USA: IEEE, 2020. 9301−9309 [259] Nguyen Q P, Kian B, Low H, Jaillet P. Variational Bayesian unlearning. In: Proceedings of the 34th International Conference on Neural Information Processing Systems. Vancouver, Canada: Curran Associates Inc., 2020. Article No. 1344 [260] Du M, Chen Z, Liu C, Oak R, Song D. Lifelong anomaly detection through unlearning. In: Proceedings of the ACM SIGSAC Conference on Computer and Communications Security. London, UK: Association for Computing Machinery, 2019. 1283−1297 [261] Ma Z, Liu Y, Liu X M, Liu J, Ma J F, Ren K. Learn to forget: Machine unlearning via neuron masking. IEEE Transactions on Dependable and Secure Computing, 2023, 20(4): 3194−3207 doi: 10.1109/TDSC.2022.3194884 [262] Gao C Y, Wang L X, Ding K Z, Weng C K, Wang X, Zhu Q. On large language model continual unlearning. In: Proceedings of the 13th International Conference on Learning Representations. Singapore, Singapore: ICLR, 2025. 1−30 [263] Lin L J. Self-improving reactive agents based on reinforcement learning, planning and teaching. Machine Learning, 1992, 8(3): 293−321 [264] Mnih V, Kavukcuoglu K, Silver D, Rusu A A, Veness J, Bellemare M G, et al. Human-level control through deep reinforcement learning. Nature, 2015, 518(7540): 529−533 doi: 10.1038/nature14236 [265] Schaul T, Quan J, Antonoglou I, Silver D. Prioritized experience replay. In: Proceedings of the 4th International Conference on Learning Representations. San Juan, Puerto Rico: ICLR, 2016. 1−21 [266] Lyle C, Rowland M, Dabney W, Kwiatkowska M, Gal Y. Learning dynamics and generalization in deep reinforcement learning. In: Proceedings of the 39th International Conference on Machine Learning. Baltimore, USA: PMLR, 2022. 14560−14581 [267] Dohare S, Hernandez-Garcia J F, Lan Q F, Rahman P, Mahmood A R, Sutton R S. Loss of plasticity in deep continual learning. Nature, 2024, 632(8026): 768−774 doi: 10.1038/s41586-024-07711-7 [268] Kumar S, Marklund H, Rao A, Zhu Y F, Jeon H J, Liu Y Y, et al. Continual learning as computationally constrained reinforcement learning. arXiv preprint arXiv: 2307.04345, 2023. [269] Abel D, Barreto A, Van Roy B, Precup D, van Hasselt H, Singh S. A definition of continual reinforcement learning. In: Proceedings of the 37th International Conference on Neural Information Processing Systems. New Orleans, USA: Curran Associates Inc., 2023. Article No. 2192 [270] Daniels Z A, Raghavan A, Hostetler J, Rahman A, Sur I, Piacentino M, et al. Model-free generative replay for lifelong reinforcement learning: Application to StarCraft-2. In: Proceedings of the 1st Conference on Lifelong Learning Agents. Montréal, Canada: PMLR, 2022. 1120−1145 [271] Igl M, Farquhar G, Luketina J, Boehmer W, Whiteson S. Transient non-stationarity and generalisation in deep reinforcement learning. In: Proceedings of the 9th International Conference on Learning Representations. Virtual Event: ICLR, 2021. 1−16 [272] Gaya J B, Doan T, Caccia L, Soulier L, Denoyer L, Raileanu R. Building a subspace of policies for scalable continual learning. In: Proceedings of the 11th International Conference of Learning Representations. Kigali, Rwanda: ICLR, 2023. 1−28 [273] Achiam J, Adler S, Agarwal S, Ahmad L, Akkaya I, Aleman F L, et al. GPT-4 technical report. arXiv preprint arXiv: 2303.08774, 2023. [274] Touvron H, Lavril T, Izacard G, Martinet X, Lachaux M A, Lacroix T, et al. LLaMA: Open and efficient foundation language models. arXiv preprint arXiv: 2302.13971, 2023. [275] Bai J Z, Bai S, Chu Y F, Cui Z Y, Dang K, Deng X D, et al. Qwen technical report. arXiv preprint arXiv: 2309.16609, 2023. [276] Liu A X, Feng B, Xue B, Wang B X, Wu B C, Lu C D, et al. Deepseek-V3 technical report. arXiv preprint arXiv: 2412.19437, 2024 [277] Sun Y, Wang S H, Li Y K, Feng S K, Tian H, Wu H F, et al. ERNIE 2.0: A continual pre-training framework for language understanding. In: Proceedings of the 34th AAAI Conference on Artificial Intelligence. New York, USA: AAAI Press, 2020. 8968−8975 [278] Jang J, Ye S, Yang S, Shin J, Han J, Kim G, et al. Towards continual knowledge learning of language models. In: Proceedings of the 10th International Conference on Learning Representations. Virtual Event: ICLR, 2022. 1−27 [279] Ke Z X, Shao Y J, Lin H W, Konishi T, Kim G, Liu B. Continual pre-training of language models. In: Proceedings of the 11th International Conference on Learning Representations. Kigali, Rwanda: ICLR, 2023. 1−16 [280] Yang X J, Gao J F, Xue W X, Alexandersson E. PLLaMa: An open-source large language model for plant science. arXiv preprint arXiv: 2401.01600, 2024. [281] Gogoulou E, Lesort T, Boman M, Nivre J. A study of continual learning under language shift. In: Proceedings of the 27th International Conference on Text, Speech, and Dialogue. Brno, Czech Republic: Springer, 2023. 71−84 [282] Razdaibiedina A, Mao Y B, Hou R, Khabsa M, Lewis M, Almahairi A. Progressive prompts: Continual learning for language models. In: Proceedings of the 11th International Conference on Learning Representations. Kigali, Rwanda: ICLR, 2023. 1−23 [283] Peng B H, Tian Z T, Liu S, Yang M C, Jia J Y. Scalable language model with generalized continual learning. In: Proceedings of the 12th International Conference on Learning Representations. Vienna, Austria: ICLR, 2024. 1−23 [284] Wang X, Zhang Y S, Chen T Z, Gao S Y, Jin S J, Yang X J, et al. TRACE: A comprehensive benchmark for continual learning in large language models. arXiv preprint arXiv: 2310.06762, 2023. [285] Song C Y, Han X, Zeng Z N, Li K, Chen C, Liu Z Y, et al. ConPET: Continual parameter-efficient tuning for large language models. arXiv preprint arXiv: 2309.14763, 2023. [286] Hao S B, Liu T Y, Wang Z, Hu Z T. ToolkenGPT: Augmenting frozen language models with massive tools via tool embeddings. In: Proceedings of the 37th Neural Information Processing Systems. New Orleans, USA: NeurIPS, 2024. 1−25 [287] Zhang H, Gui L, Zhai Y Z, Wang H, Lei Y, Xu R F. COPF: Continual learning human preference through optimal policy fitting. arXiv preprint arXiv: 2310.15694, 2023. [288] Zhang H, Lei Y, Gui L, Yang M, He Y L, Wang H, et al. CPPO: Continual learning for reinforcement learning with human feedback. In: Proceedings of the 12th International Conference on Learning Representations. Vienna, Austria: ICLR, 2024. 1−24 [289] Suhr A, Artzi Y. Continual learning for instruction following from realtime feedback. In: Proceedings of the 37th Neural Information Processing Systems. New Orleans, USA: NeurIPS, 2024. 1−20 [290] Wang X, Chen T Z, Ge Q M, Xia H, Bao R, Zheng R, et al. Orthogonal subspace learning for language model continual learning. In: Proceedings of the Findings of the Association for Computational Linguistics (EMNLP). Singapore, Singapore: Association for Computational Linguistics, 2023. 10658−10671 [291] Jang J, Kim S, Ye S, Kim D, Logeswaran L, Lee M, et al. Exploring the benefits of training expert language models over instruction tuning. In: Proceedings of the 40th International Conference on Machine Learning. Honolulu, USA: PMLR, 2023. 14702−14729 [292] Qiao F L, Mahdavi M. Learn more, but bother less: Parameter efficient continual learning. In: Proceedings of the 38th Annual Conference on Neural Information Processing Systems. Vancouver, Canada: NeurIPS, 2024. 1−23 -
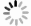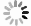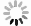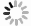
图(5) / 表(1)
计量
- 文章访问数: 595
- HTML全文浏览量: 242
- PDF下载量: 67
- 被引次数: 0
