

-
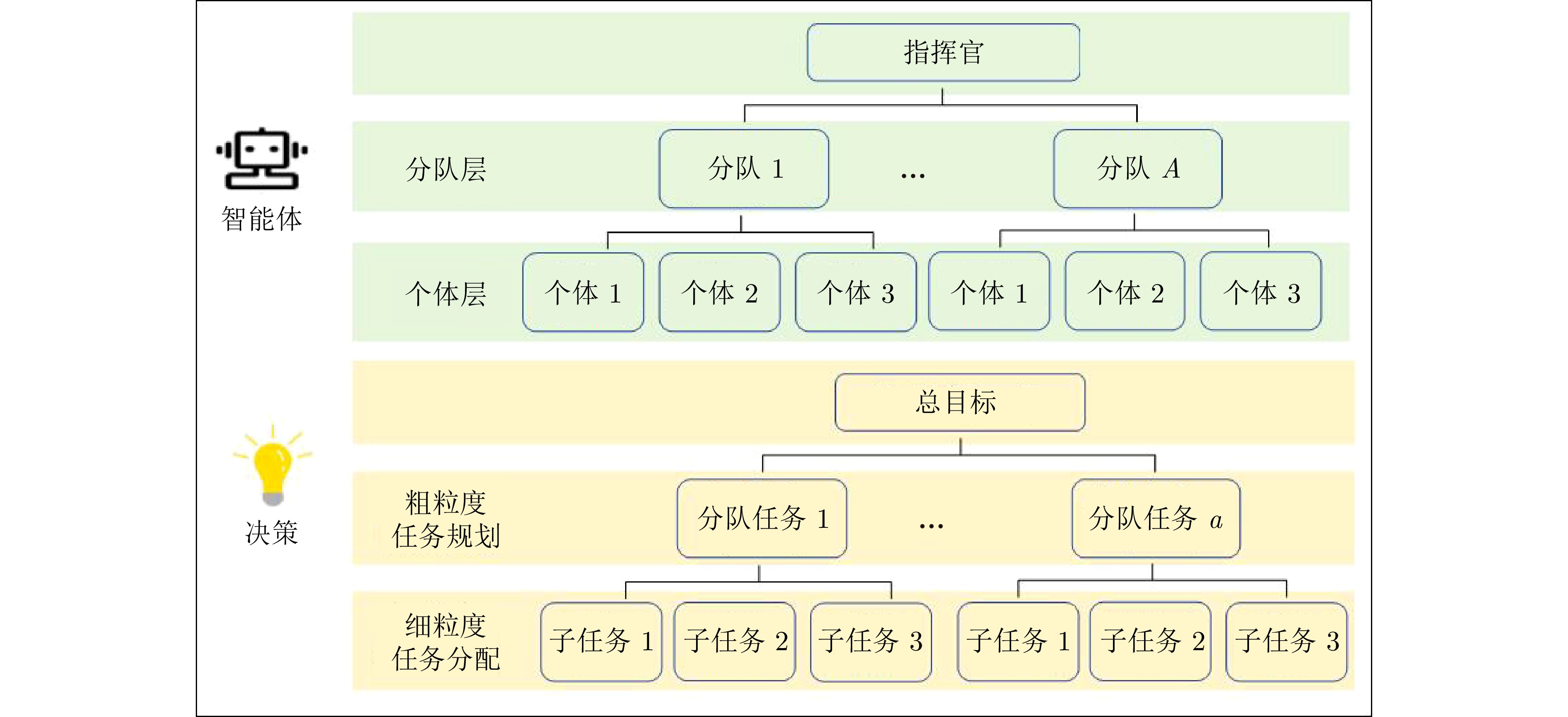
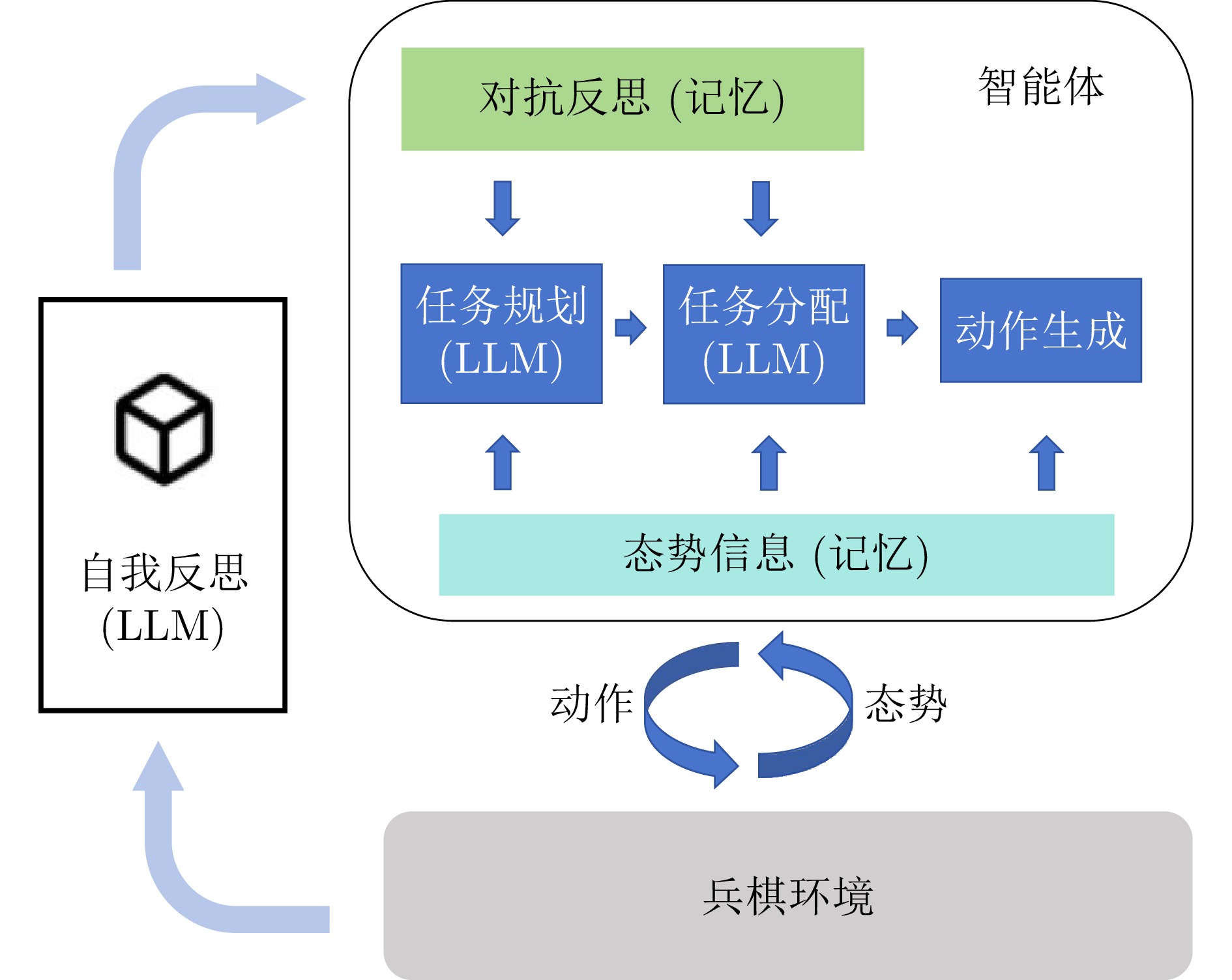
摘要: 兵棋推演通过控制棋子的行为来模拟真实的对抗场景, 在智能决策领域具有重大研究意义. 已有的研究大多聚焦于知识驱动的规则型智能体或数据驱动的学习型智能体. 尽管这些方法在小规模兵棋推演上取得一定的进展, 但是由于知识规则的高获取代价、弱泛化性, 以及学习算法的低稳定性、学习过程的高算力需求, 导致已有方法难以在更加贴近真实场景的大规模兵棋推演环境中灵活应用. 为缓解上述问题, 提出基于大语言模型的大规模多智能体分层任务规划框架, 该框架利用大语言模型分别进行组队层次的粗粒度任务规划和个体层次的细粒度任务分解, 围绕“规划−交流−记忆−反思”实现策略生成. 相较于之前的工作, 该方法能有效缓解泛化性的难题, 同时在维持智能体一定的自我增强能力的情况下避免对智能体参数的高成本训练. 实验表明, 该模型能以较高胜率击败高水平AI, 且具备自我增强能力、泛化能力以及可解释能力, 在大规模对抗环境中具有显著优势.Abstract: Wargame simulates real confrontations by controlling the behavior of agents, which has important research significance in the field of intelligent decision-making. Most existing research has focused on knowledge-driven rule-based agents or data-driven learning agents. Although these methods have made some progress in small-scale wargame, the high acquisition cost and weak generalization of knowledge rules, as well as the low stability of learning algorithms and the high computational requirements of the learning process, make it difficult to be flexibly applied in large-scale wargame that are closer to real scenarios. In order to alleviate the above problems, a large-scale multi-agent hierarchical task planning framework based on large language model is proposed, which uses large language model to perfom coarse-grained task planning at the team level and fine-grained task decomposition at the individual level, which focuses on strategy generation through planning, communication, memory, and reflection. Compared to previous works, the proposed method alleviates the problem of generalization effectively and can maintain a certain degree of self-improvement ability while avoiding high cost training of agent parameters. Experiment shows that our model can defeat elite AI with a high winning rate. Furthermore, our model also has self-improve ability, generalization ability, and interpretability ability, which has significant advantages in large-scale adversarial environment.
-
Key words:
- Wargame /
- policy generation /
- large language model /
- hierarchical task planning
-
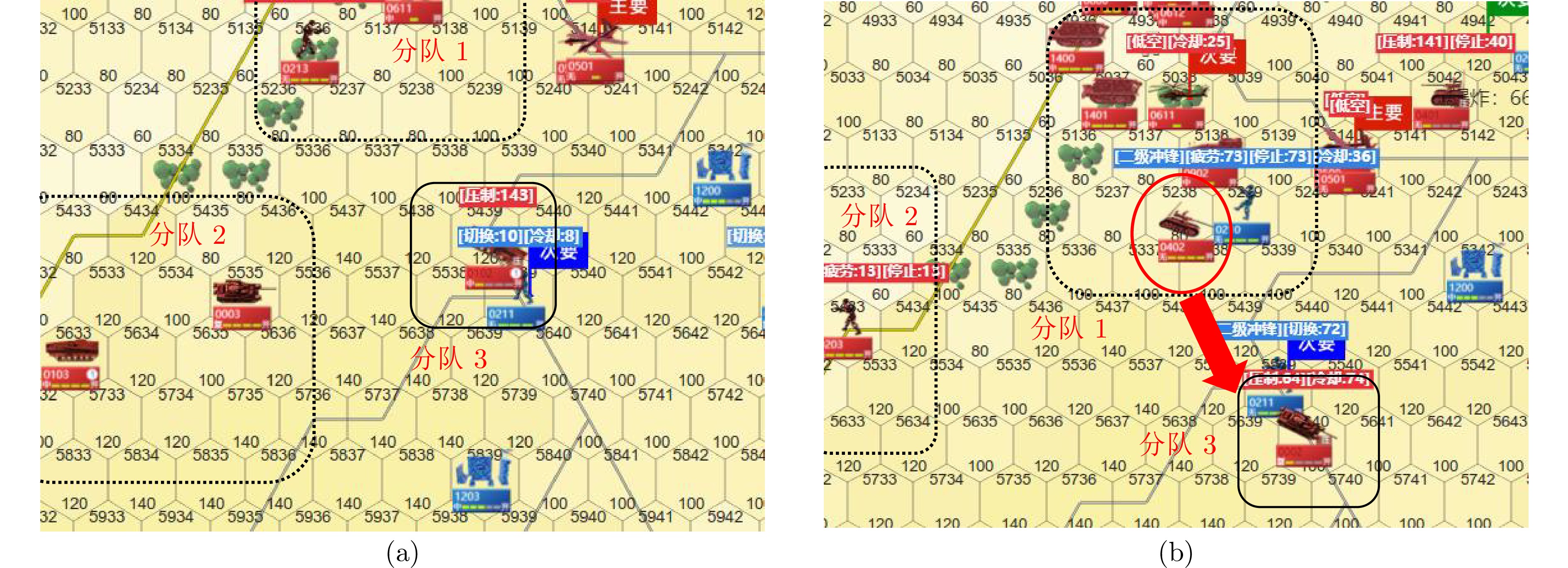
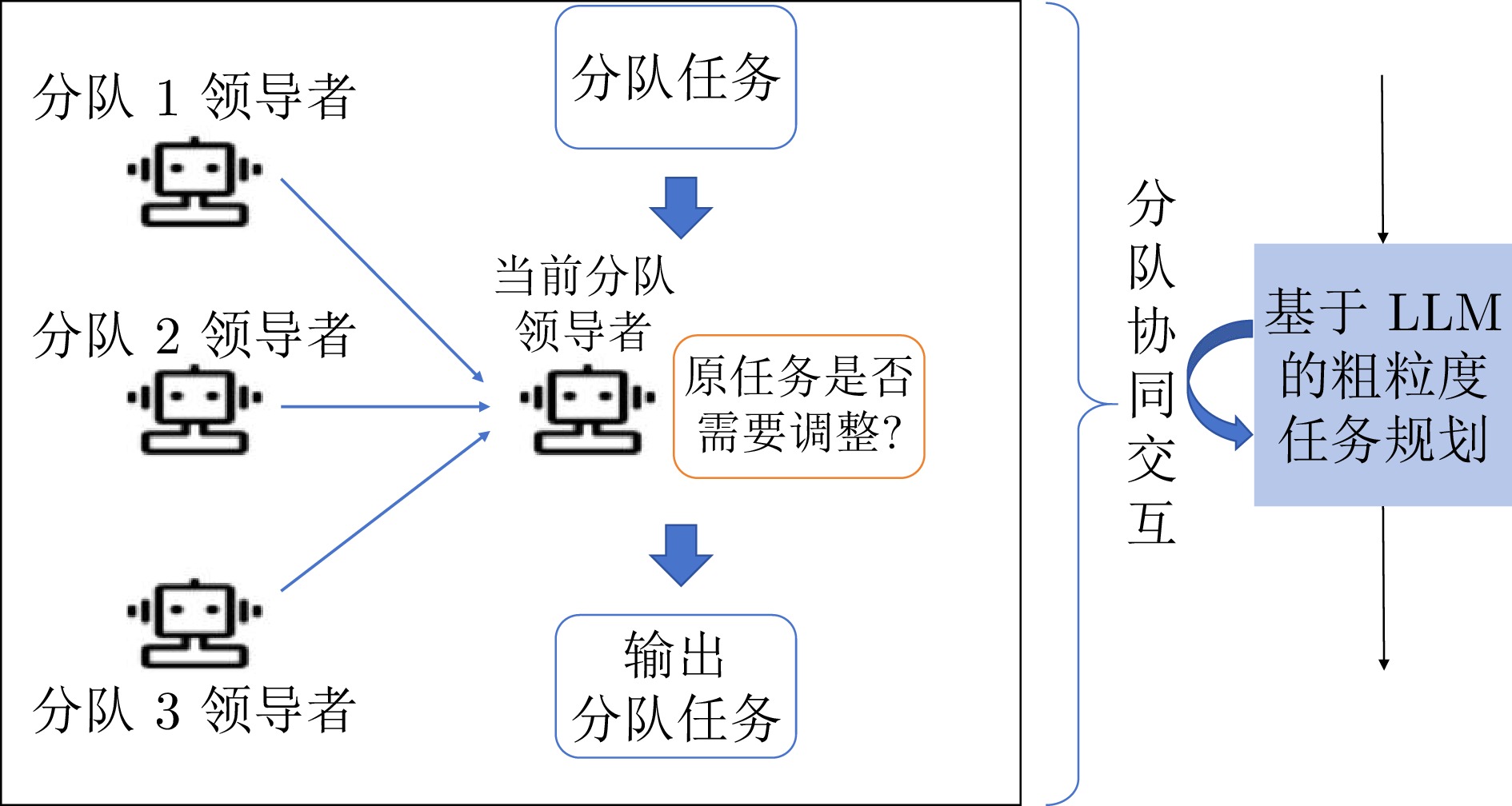
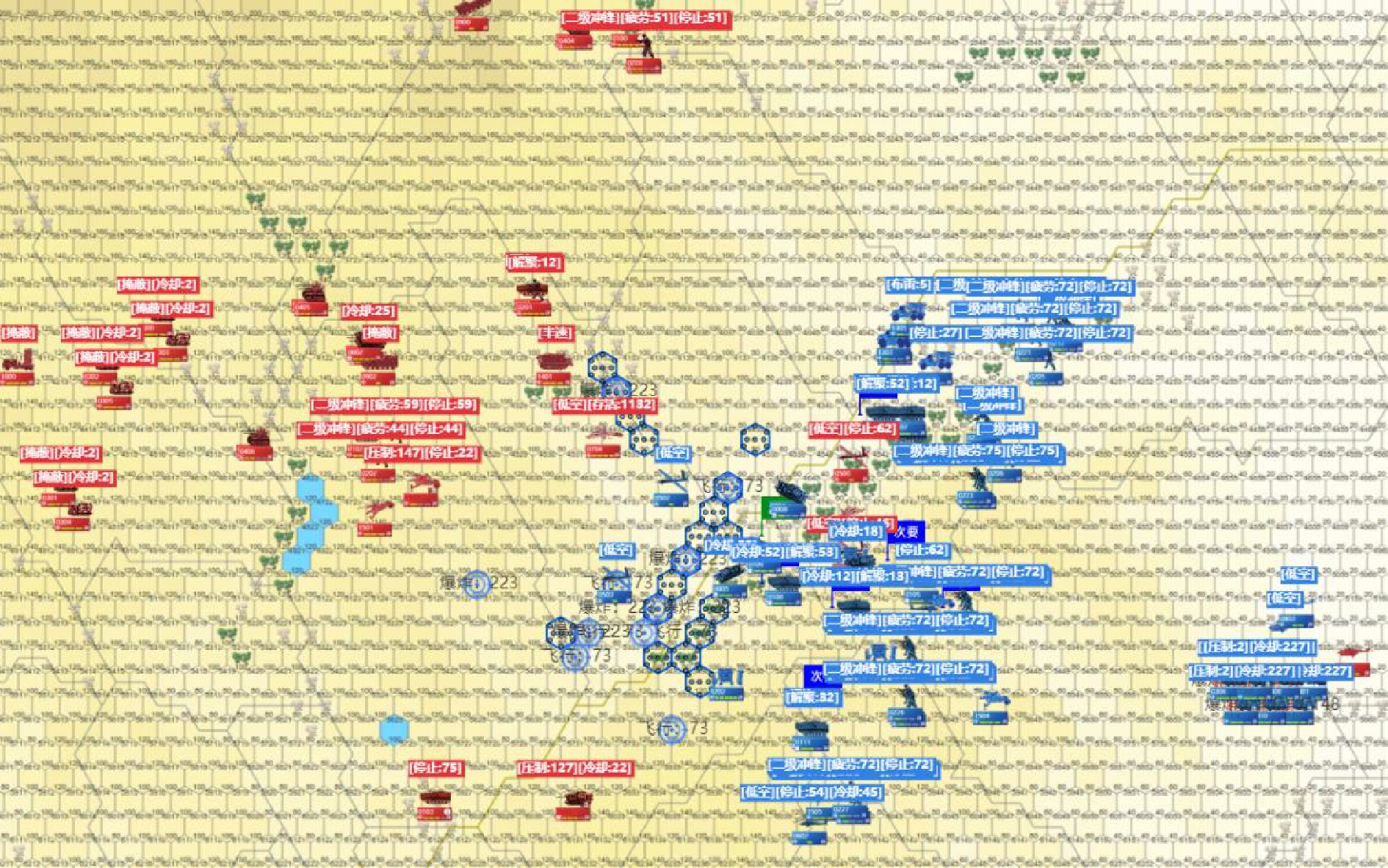
图 6 有无分队协同交互模块的复盘截图 ((a)无分队协同交互模块: 分队3仅剩战车夺点, 附近的分队1与分队2未进行支援; (b)有分队协同交互模块: 分队3仅剩坦克夺点, 附近的分队1进行支援)
Fig. 6 Screenshots of replays with and without the team coordination module ((a) Without team collaboration module:Team 3 only has one chariot capturing the point, and nearby Teams 1 and 2 do not provide support; (b) With team collaboration module: Team 3 only has one tank capturing the point, and nearby Teams 1 provides support)
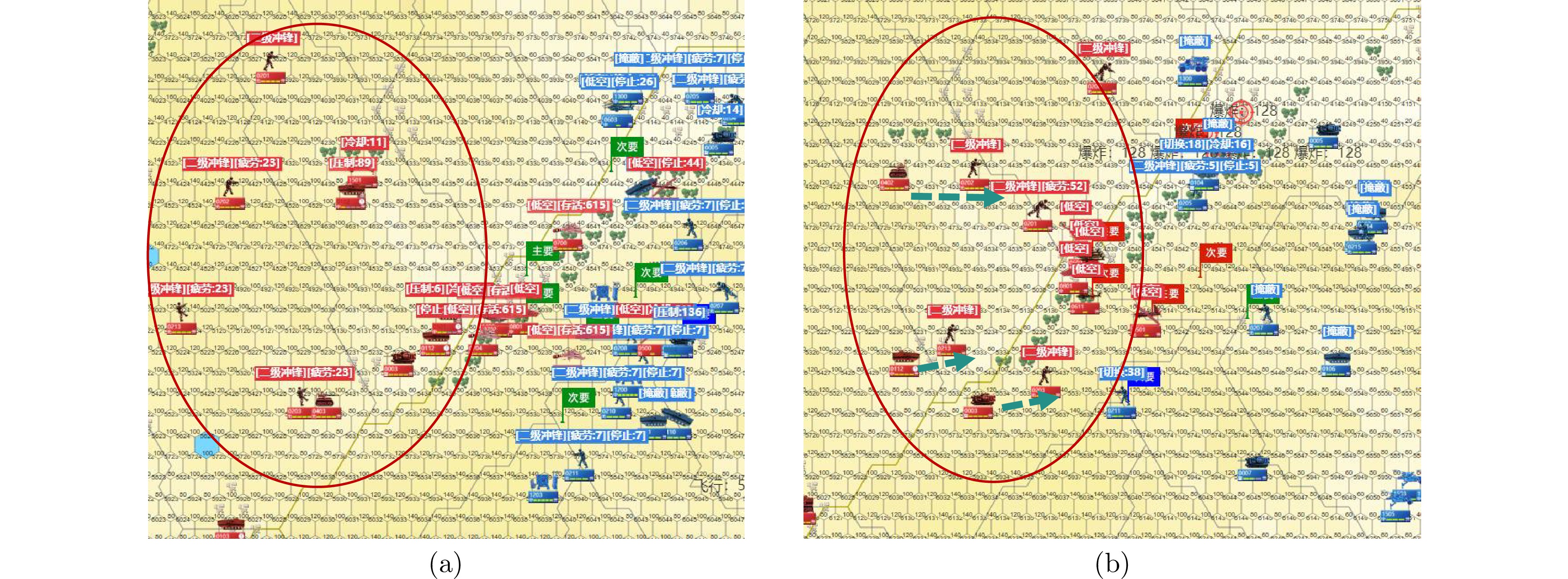
图 8 不同赛局推演的复盘截图 ((a)失败赛局推演复盘: 红方车辆单位比较激进, 冲在步兵前面, 容易被敌方埋伏攻击; (b)迭代多轮赛局推演复盘: 红方车辆单位更加保守, 跟随步兵进行夺控, 减少损耗)
Fig. 8 Screenshots of replays of different games ((a) Failed game: Red vehicle units are more aggressive and ahead of infantry, ambushed by enemies easily; (b) Iteration multi-rounds of game: Red vehicle units adopt a more cautiousapproach and follow infantry to seize control, reducing losses)
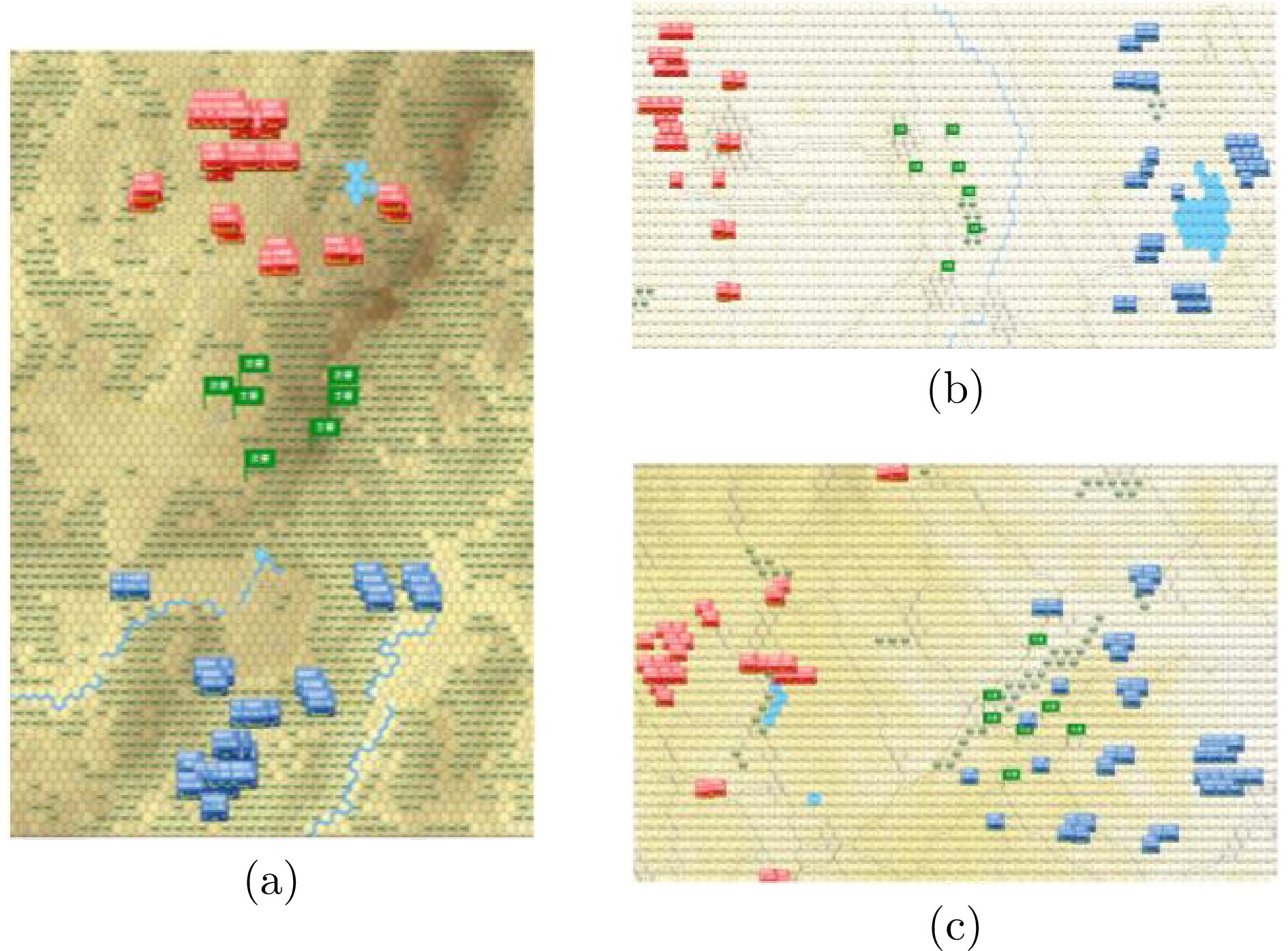
图 10 不同地图想定示意图 ((a)地图1; (b)地图2; (c)地图3)
Fig. 10 Different map scenarios ((a) Map 1; (b) Map 2; (c) Map 3)

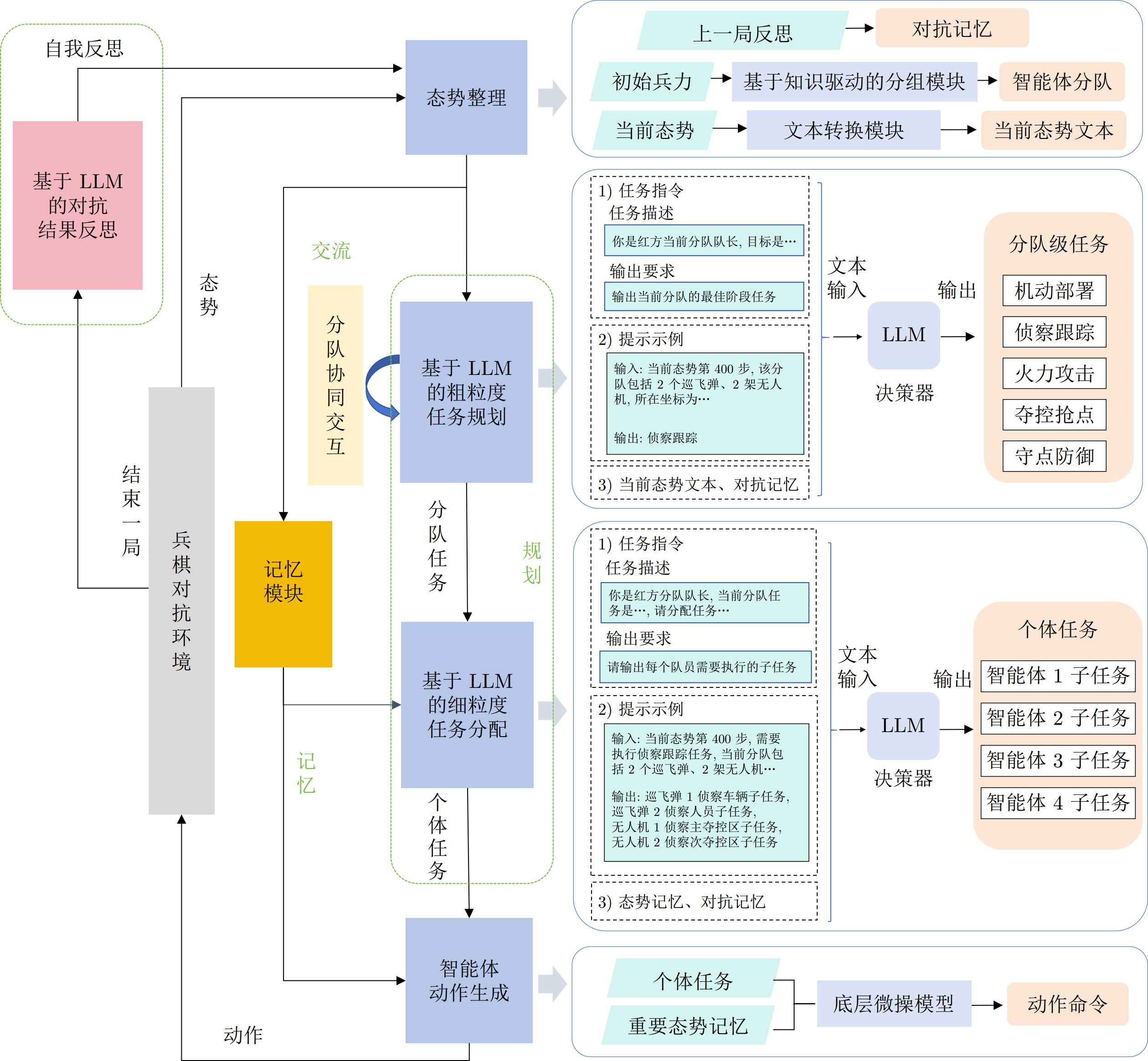
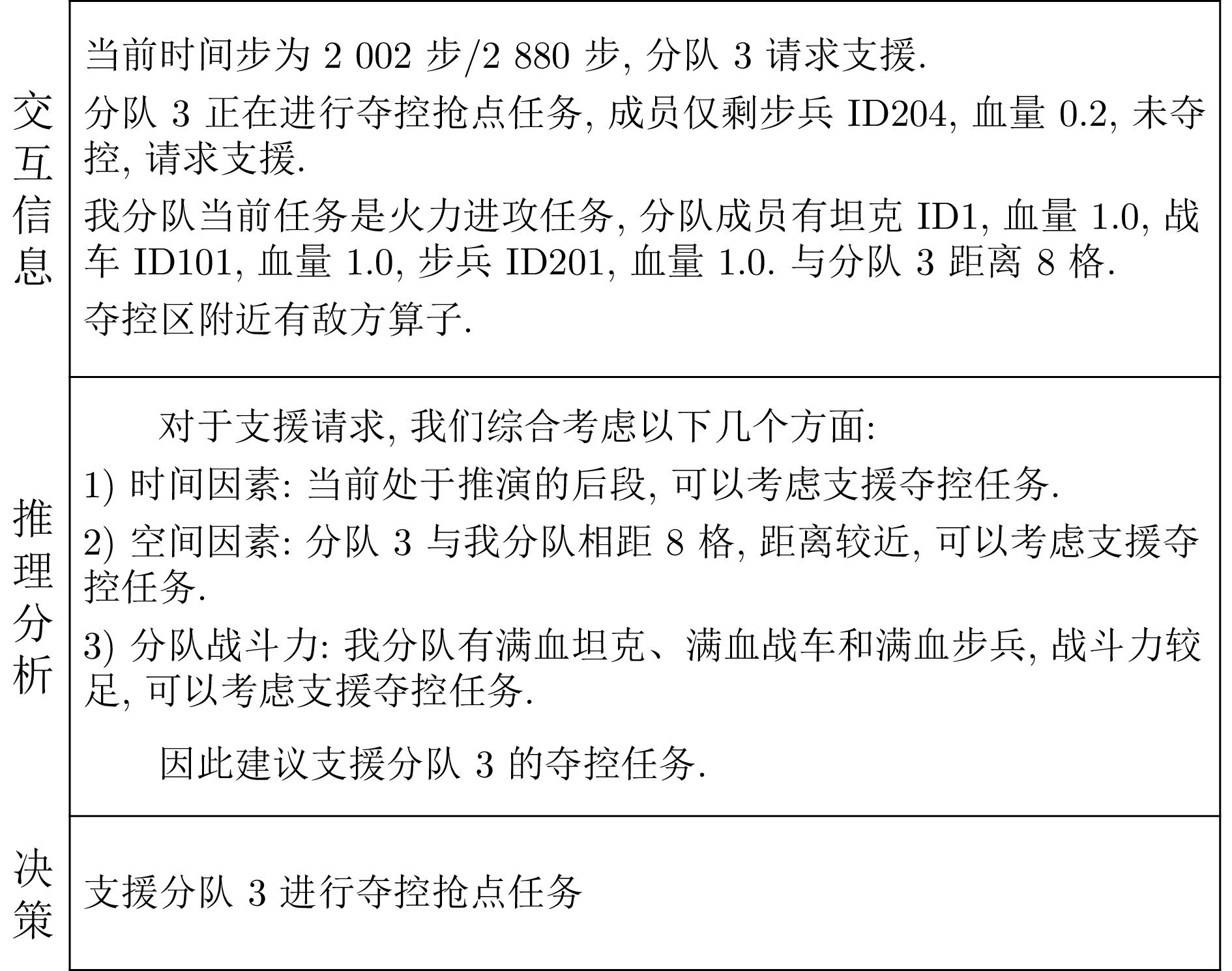
图 11 基于LLM任务规划的推理解释过程
Fig. 11 The inferential interpretive process of task planning based on LLM

图 13 基于LLM任务分配的推理解释过程
Fig. 13 The inferential interpretive process of task allocation based on LLM
表 1 LLM超参数设置
Table 1 LLM hyper-parameters settings
超参数 取值 范围 Top-p 0.8 (0, 1] Temperature 0.95 (0, 1] Max-length 1 024 > 0  下载: 导出CSV
下载: 导出CSV
表 2 固定地图想定下不同智能体的对抗胜率(%)
Table 2 Winning rate of different agents in a fixed map scenario (%)
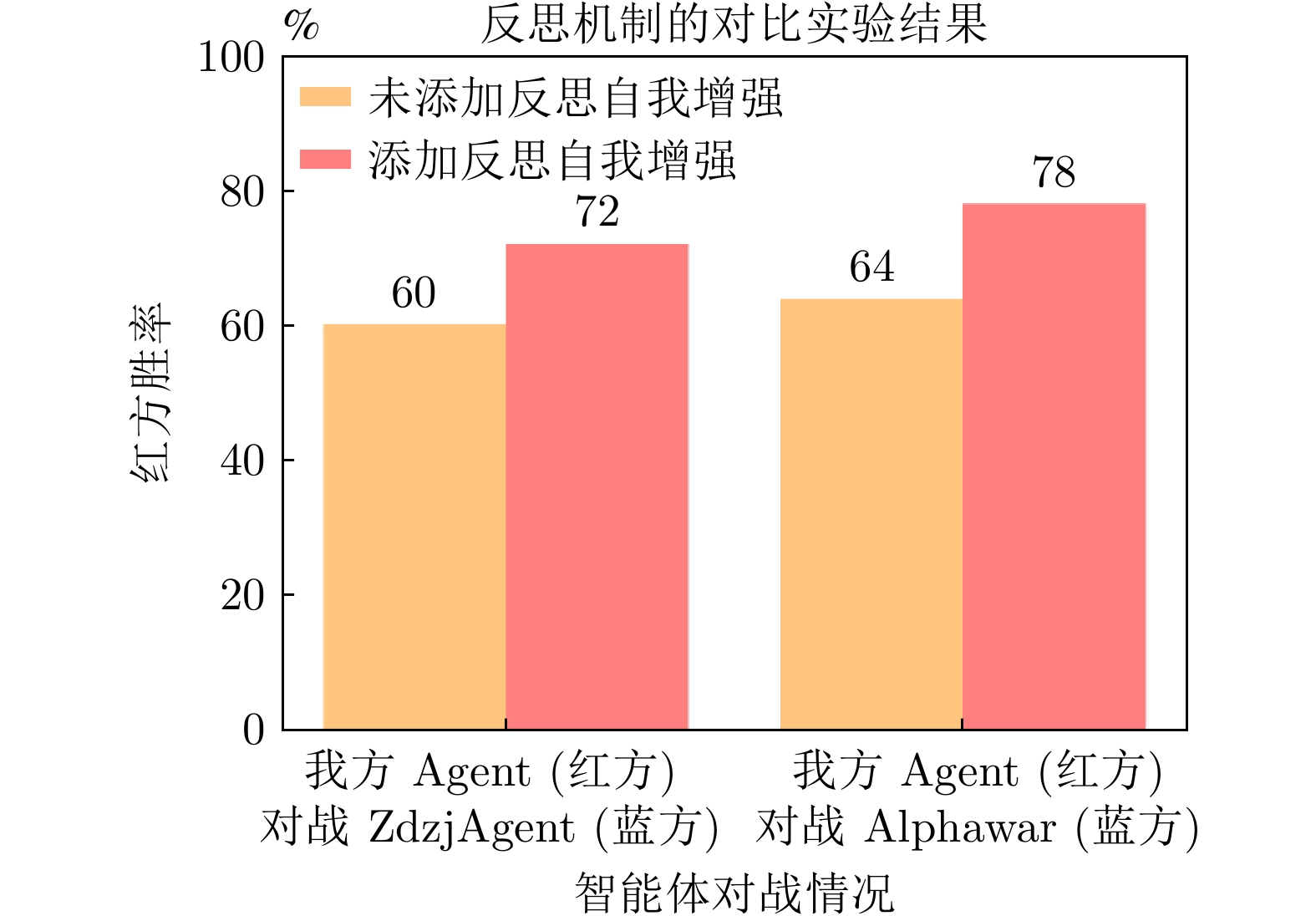
胜率 对手(执蓝) 执红平均胜率 对手(执红) 执蓝平均胜率 总胜率 DemoAgent ZdzjAgent Alphawar DemoAgent ZdzjAgent Alphawar RDAgent 80.0 44.0 44.0 56.0 88.0 62.0 60.0 70.0 63.0 本文方法(无分队协同交互模块) 84.0 52.0 56.0 64.0 90.0 84.0 80.0 84.7 74.4 本文方法(无记忆模块) 88.0 56.0 60.0 68.0 96.0 84.0 84.0 88.0 78.0 本文方法 90.0 60.0 64.0 71.3 98.0 88.0 86.0 90.7 81.0
下载: 导出CSV
表 3 不同地图想定下智能体的对抗胜率(%)
Table 3 Winning rate of agents in different map scenario (%)
地图1 胜率 地图2 胜率 地图3 胜率 执红胜率 执蓝胜率 执红胜率 执蓝胜率 执红胜率 执蓝胜率 DemoAgent 13.3 17.3 15.3 9.3 13.3 11.3 2.7 4.0 3.3 ZdzjAgent 46.7 48.0 47.4 49.3 52.0 50.7 60.0 62.7 61.4 Alphawar 62.7 60.0 61.4 57.3 60.0 58.7 53.3 57.3 55.3 本文方法 73.3 78.7 76.0 78.7 80.0 79.3 77.3 82.7 80.0
下载: 导出CSV
-
[1] 胡晓峰, 齐大伟. 智能决策问题探讨——从游戏博弈到作战指挥, 距离还有多远. 指挥与控制学报, 2020, 6(4): 356−363Hu Xiao-Feng, Qi Da-Wei. On problems of intelligent decision-making——How far is it from game-playing to operational command. Journal of Command and Control, 2020, 6(4): 356−363 [2] 黄凯奇, 兴军亮, 张俊格, 倪晚成, 徐博. 人机对抗智能技术. 中国科学: 信息科学, 2020, 50(4): 540−550 doi: 10.1360/N112019-00048Huang Kai-Qi, Xing Jun-Liang, Zhang Jun-Ge, Ni Wan-Cheng, Xu Bo. Intelligent technologies of human-computer gaming. SCIENTIA SINICA: Informations, 2020, 50(4): 540−550 doi: 10.1360/N112019-00048 [3] 周志杰, 曹友, 胡昌华, 唐帅文, 张春潮, 王杰. 基于规则的建模方法的可解释性及其发展. 自动化学报, 2021, 47(6): 1201−1216Zhou Zhi-Jie, Cao You, Hu Chang-Hua, Tang Shuai-Wen, Zhang Chun-Chao, Wang Jie. The interpretability of rule-based modeling approach and its development. Acta Automatica Sinica, 2021, 47(6): 1201−1216 [4] Xu X, Yang M, Li G. Adaptive CGF commander behavior modeling through HTN guided Monte Carlo tree search. Journal of Systems Science and Systems Engineering, 2018, 27: 231−249 doi: 10.1007/s11518-018-5366-8 [5] 刘满, 张宏军, 徐有为, 冯欣亮, 冯玉芳. 群队级兵棋实体智能行为决策方法研究. 系统工程与电子技术, 2022, 44(8): 2562−2569 doi: 10.12305/j.issn.1001-506X.2022.08.21Liu Man, Zhang Hong-Jun, Xu You-Wei, Feng Xin-Liang, Feng Yu-Fang. Research on behavior decision-making of multi entities in group-level wargame. Systems Engineering and Electronics, 2022, 44(8): 2562−2569 doi: 10.12305/j.issn.1001-506X.2022.08.21 [6] Wu K Y, Liu M Y, Cui P, Zhang Y. A training model of wargaming based on imitation learning and deep reinforcement learning. In: Proceedings of the Chinese Intelligent Systems Conference. Singapore: Springer, 2022. 786−795 [7] Zhang J F, Xue Q. Actor-critic-based decision-making method for the artificial intelligence commander in tactical wargames. The Journal of Defense Modeling and Simulation, 2022, 19(3): 467−480 doi: 10.1177/1548512920954542 [8] Wang X Z, Wang M, Luo W. Intelligent decision technology in combat deduction based on soft actor-critic algorithm. Chinese Journal of Ship Research, 2021, 16(6): 99−108 [9] Xu P, Zhang J G, Huang K Q. Population-based diverse exploration for sparse-reward multi-agent tasks. In: Proceedings of the 33rd International Joint Conference on Artificial Intelligence. Jeju, South Korea: 2024. 283−291 [10] Xu P, Zhang J G, Yin Q Y, Yu C, Yang Y D, Huang K Q. Subspace-aware exploration for sparse-reward multi-agent tasks. In: Proceedings of the AAAI Conference on Artificial Intelligence. Washington, USA: 2023. 11717−11725 [11] Lowe R, Wu Y I, Tamar A, Harb J, Pieter A, Mordatch I. Multi-agent actor-critic for mixed cooperative-competitive environments. arXiv preprint arXiv: 1706.02275, 2017. [12] Chang Y P, Wang X, Wang J D, Wu Y, Yang L Y, Zhu K J, et al. A survey on evaluation of large language models. ACM Transactions on Intelligent Systems and Technology, 2024, 15(3): 1−45 [13] Singh C, Askari A, Caruana R, Gao J F. Augmenting interpretable models with large language models during training. Nature Communications, 2023, 14(1): 7913−7914 doi: 10.1038/s41467-023-43713-1 [14] Hager P, Jungmann F, Holland R, Bhagat K, Hubrecht I, Knauer M, et al. Evaluation and mitigation of the limitations of large language models in clinical decision-making. Nature Medicine, 2024, 30: 2613−2622 doi: 10.1038/s41591-024-03097-1 [15] Lorè N, Babak H. Strategic behavior of large language models and the role of game structure versus contextual framing. Scientific Reports, 2024, 14(1): Article No. 18490 doi: 10.1038/s41598-024-69032-z [16] Palantir. Get AI into operations [Online], available: https://www.palantir.com/platforms/, August 10, 2024 [17] Webb T, Holyoak K J, Lu H J. Emergent analogical reasoning in large language models. Nature Human Behaviour, 2023, 7(9): 1526−1541 doi: 10.1038/s41562-023-01659-w [18] XAgent Team. XAgent [Online], available: https://github.com/OpenBMB/XAgent, August 12, 2024 [19] Wang G Z, Xie Y Q, Jiang Y F, Mandlekar A, Xiao C W, Zhu Y K, et al. Voyager: An open-ended embodied agent with large language models. arXiv preprint arXiv: 2305.16291, 2023. [20] Zelikman E, Huang Q, Poesia G, Goodman N, Haber N. Parsel: Algorithmic reasoning with language models by composing decompositions. Advances in Neural Information Processing Systems, 2023, 36: 31466−31523 [21] Zheng H S, Mishra S, Chen X Y, Cheng H T, Chi E H, Le Q V, et al. Take a step back: Evoking reasoning via abstraction in large language models. arXiv preprint arXiv: 2305.16291, 2023. [22] Chen Y C, Arkin J, Hao Y L, Zhang Y, Roy N, Fan C C. PRompt optimization in multi-step tasks (PROMST): Integrating human feedback and heuristic-based sampling. In: Proceedings of the Conference on Empirical Methods in Natural Language Processing. Florida, USA: 2024. 3859−3920 [23] Aghzal M, Plaku E, Yao Z Y. Can large language models be good path planners? A benchmark and investigation on spatial-temporal reasoning. arXiv preprint arXiv: 2310.03249, 2023. [24] Deng H R, Zhang H J, Ou J, Feng C S. Can LLM be a good path planner based on prompt engineering? Mitigating the hallucination for path planning. arXiv preprint arXiv: 2408.13184, 2024. [25] Du Z X, Qian Y J, Liu X, Ding M, Qiu J Z, Yang Z L, et al. GLM: General language model pretraining with autoregressive blank infilling. arXiv preprint arXiv: 2103.10360, 2021. [26] 刘满, 张宏军, 郝文宁, 程恺, 王佳胤. 战术级兵棋实体作战行动智能决策方法. 控制与决策, 2020, 35(12): 2977−2985Liu Man, Zhang Hong-Jun, Hao Wen-Ning, Cheng Kai, Wang Jia-Yin. Intelligent decision method for tactical level wargame entity operations. Control and Decision, 2020, 35(12): 2977−2985 [27] 尹奇跃, 赵美静, 倪晚成, 张俊格, 黄凯奇. 兵棋推演的智能决策技术与挑战. 自动化学报, 2023, 49(5): 913−928Yin Qi-Yue, Zhao Mei-Jing, Ni Wan-Cheng, Zhang Jun-Ge, Huang Kai-Qi. Intelligent decision making technology and challenge of wargame. Acta Automatica Sinica, 2023, 49(5): 913−928 [28] Fu Y H, Liang X X, Ma Y, Huang K H, Li Y. Coordinating multi-agent deep reinforcement learning in wargame. In: Proceedings of the 2020 3rd International Conference on Algorithms, Computing and Artificial Intelligence. Sanya, China: 2020. 1−5 [29] 李卓远, 张德平. 基于BN-DDPG轻量级强化学习算法的智能兵棋推演. 计算机系统应用, 2023, 32(4): 293−299Li Zhuo-Yuan, Zhang De-Ping. Intelligent wargame deduction based on BN-DDPG lightweight reinforcement learning algorithm. Computer Systems and Applications, 2023, 32(4): 293−299 [30] Wang H C, Tang H Y, Hao J Y, Hao X T, Fu Y, Ma Y. Large scale deep reinforcement learning in war-games. In: Proceedings of 2020 IEEE International Conference on Bioinformatics and Biomedicine. South Korea: 2000. 1693−1699 [31] Sun Y X, Yuan B, Zhang T, Tang B J, Zheng W W, Zhou X Z. Research and implementation of intelligent decision based on a priori knowledge and DQN algorithms in wargame environment. Electronics, 2020, 9(10): 1668−1669 doi: 10.3390/electronics9101668 [32] Park J S, OBrien J, Cai C J, Morris M R, Liang P, Bernstein M S. Generative agents: Interactive simulacra of human behavior. In: Proceedings of the 36th Annual Acm Symposium on User Interface Software and Technology. San Francisco, USA: 2023. 1−22 [33] Duan J H, Wang S Q, Diffenderfer J, Sun L C, Chen T L, Kailkhura B, et al. ReTA: Recursively thinking ahead to improve the strategic reasoning of large language models. In: Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Mexico: 2024. 2232−2246 [34] Hao S B, Gu Y, Ma H D, Hong J J, Wang Z, Wang D Z, et al. Reasoning with language model is planning with world model. arXiv preprint arXiv: 2305.14992, 2023. [35] Holler D, Behnke G, Bercher P, Biundo S, Fiorino H, Pellier D, et al. HDDL: An extension to PDDL for expressing hierarchical planning problems. In: Proceedings of the AAAI conference on artificial intelligence. New York, USA: 2020. 9883−9891 [36] Iovino M, Scukins E, Styrud J, Ogren P, Smith C. A survey of behavior trees in robotics and AI. Robotics and Autonomous Systems, 2022, 154(104): Article No. 096 [37] Chien S, Smith B, Rabideau G, Muscettola N, Rajan K. Automated planning and scheduling for goal-based autonomous spacecraft. IEEE Intelligent Systems and Their Applications, 1998, 13(5): 50−55 doi: 10.1109/5254.722362 [38] Hu X X, Ma H W, Ye Q S, Luo H. Hierarchical method of task assignment for multiple cooperating UAV teams. Journal of Systems Engineering and Electronics, 2015, 26(5): 1000−1005 doi: 10.1109/JSEE.2015.00109 [39] Ghallab M, Nau D, Traverso P. Automated Planning: Theory and Practice. Elsevier, 2004. 229−259 [40] Georgievski I, Aiello M. HTN planning: Overview, comparison, and beyond. Artificial Intelligence, 2015, 222: 124−156 doi: 10.1016/j.artint.2015.02.002 [41] Wies N, Levine Y, Shashua A. Sub-task decomposition enables learning in sequence to sequence tasks. arXiv preprint arXiv: 2204.02892, 2022. [42] Liu Z Y, Lai Z Q, Gao Z W, Cui E F, Li Z H, Zhu X Z, et al. ControlLLM: Augment language models with tools by searching on graphs. arXiv preprint arXiv: 2310.17796, 2023. [43] Wei J, Wang X Z, Schuurmans D, Bosma M, Xia F, Chi E, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems, 2022, 35: 24824−24827 [44] Shinn N, Cassano F, Gopinath A, Narasimhan K, Yao S Y. Reflexion: Language agents with verbal reinforcement learning. Advances in Neural Information Processing Systems, 2024, 36: 8634−8652 [45] Madaan A, Tandon N, Gupta P, Hallinan S, Gao L Y, Wiegreffe S, et al. Self-refine: Iterative refinement with self-feedback. Advances in Neural Information Processing Systems, 2024, 36: 46534−46594 [46] Zhu X Z, Chen Y T, Tian H, Tao C X, Su W J, Yang C Y, et al. Ghost in the minecraft: Generally capable agents for open-world environments via large language models with text-based knowledge and memory. arXiv preprint arXiv: 2305.17144, 2023. [47] Wang Z H, Cai S F, Liu A J, Jin Y G, Hou J B, Zhang B W, et al. Jarvis-1: Open-world multi-task agents with memory-augmented multimodal language models. arXiv preprint arXiv: 2311.05997, 2023. [48] 中国科学院自动化研究所. 即时策略人机对抗平台 [Online], available: http://wargame.ia.ac.cn, 2024-8-12Institute of Automation, Chinese Academy of Sciences. Real-time strategy man-machine confrontation platform [Online], available: http://wargame.ia.ac.cn, August 12, 2024 [49] Lewis P, Perez E, Piktus A, Petroni F, Karpukhin V, Goyal N, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in Neural Information Processing Systems, 2022, 33: 9459−9474 -

计量
- 文章访问数: 393
- HTML全文浏览量: 301
- PDF下载量: 82
- 被引次数: 0
