

-
摘要: 在真实场景中, 图像往往同时遭受低分辨率、压缩失真及噪声等多种退化因素影响. 现有方法通常聚焦于单一退化类型, 难以应对复杂的复合退化情况. 为解决真实场景中普遍存在的低分辨率与JPEG压缩伪影复合退化问题, 提出一种梯度引导的联合JPEG压缩伪影去除和超分辨率重建网络. 该网络以超分辨率分支为主导, 融合JPEG压缩伪影去除分支与梯度引导分支的非对称特征, 实现了高质量图像重建. JPEG压缩伪影去除分支专注于压缩伪影抑制, 缓解了主导分支的重建负担. 梯度引导分支则精准估计图像梯度, 引导主导分支恢复更多细节与纹理. 实验结果表明, 该方法提升了低分辨率JPEG压缩图像的重建质量.Abstract: In real-world scenarios, images are often affected by multiple degradation factors simultaneously, such as low resolution, compression distortions, and noise. Existing methods typically focus on addressing a single type of degradation, making them less effective when dealing with complex compound degradations. To tackle the commonly encountered compound degradation issue of low resolution and JPEG compression artifacts in real-world scenarios, we propose a gradient-guided joint JPEG compression artifact removal and super-resolution reconstruction network. The proposed network adopts the super-resolution branch as the leading branch, which asymmetrically integrates features from the JPEG compression artifact removal and gradient-guided branches to achieve high-quality image reconstruction. The JPEG compression artifact removal branch focuses on suppressing compression artifacts, thereby alleviating the reconstruction burden on the leading branch. The gradient-guided branch accurately estimates image gradients to guide the leading branch in restoring fine details and textures. Experimental results demonstrate that the proposed method improves the reconstruction quality of low-resolution JPEG-compressed images.
-
Key words:
- JPEG compression /
- super-resolution /
- image reconstruction /
- gradient prior
-
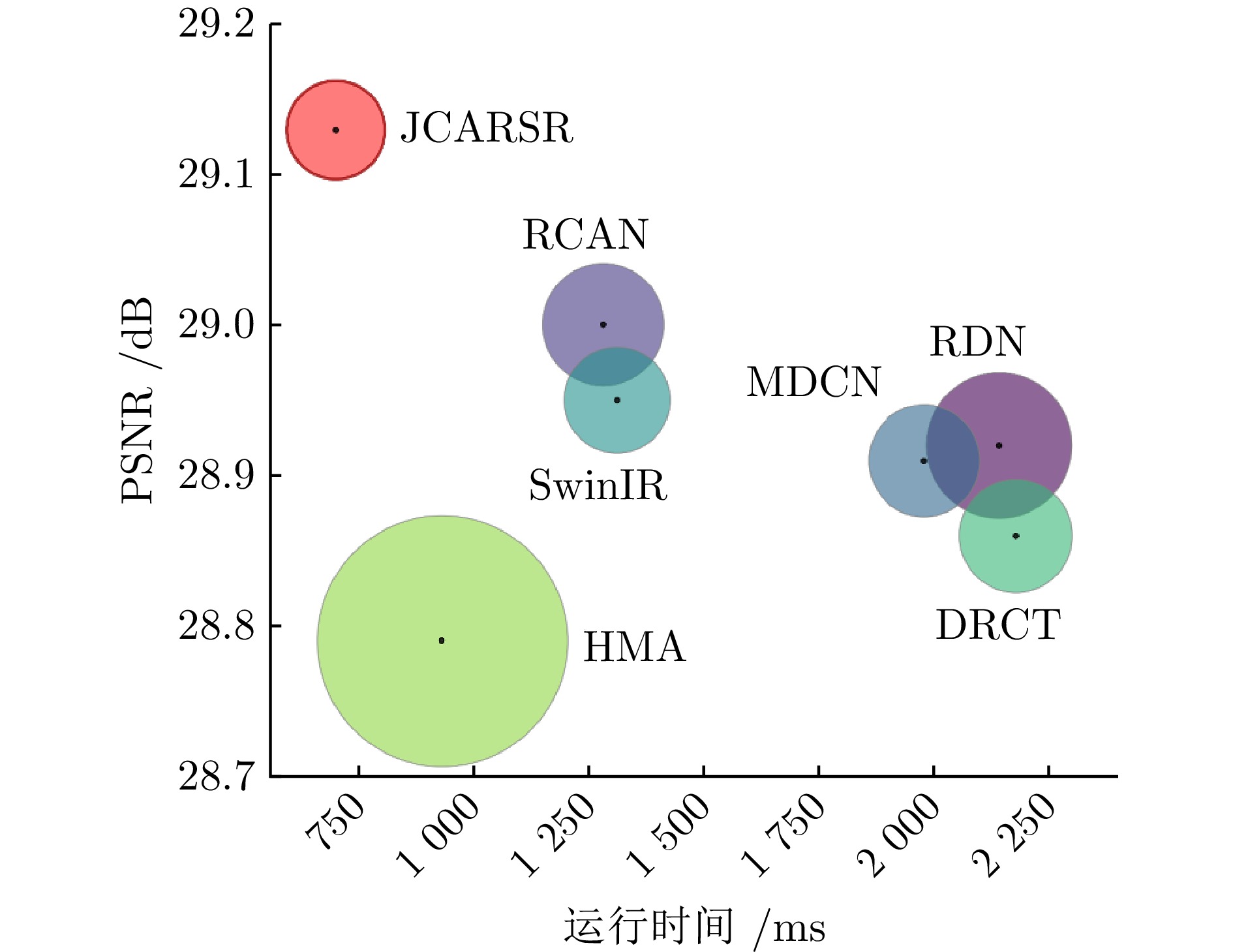
图 6 不同模型的性能与运行时间对比
Fig. 6 Comparison of performance and runtime across different models

图 7 JPEG压缩图像超分辨率视觉对比
Fig. 7 Visual comparison of JPEG-compressed image super-resolution

图 8 两阶段JPEG压缩图像超分辨率视觉对比
Fig. 8 Visual comparison of two-stage JPEG-compressed image super-resolution

图 9 在真实数据集上的超分辨率视觉对比
Fig. 9 Visual comparison of super-resolution on real-world datasets
表 1 JCARSR与经典图像超分辨率方法的定量比较
Table 1 Quantitative comparison of JCARSR with classical image super-resolution methods
对比方法 尺度因子 模型参数(M) Set5 Set14 Urban100 B100 Manga109 PSNR (dB)/SSIM PSNR (dB)/SSIM PSNR (dB)/SSIM PSNR (dB)/SSIM PSNR (dB)/SSIM EDSR[27] 2 40.73 28.97/ 0.8235 26.85/ 0.7136 25.07/ 0.7368 26.14/ 0.6623 28.04/ 0.8560 RDN[28] 2 22.12 28.92/ 0.8227 26.82/ 0.7126 24.97/ 0.7335 26.11/ 0.6613 27.98/ 0.8548 RCAN[29] 2 15.44 29.00/0.823 6 26.83/ 0.7125 25.08/ 0.7355 26.13/ 0.6610 28.02/ 0.8550 MDCN[30] 2 13.12 28.91/ 0.8220 26.80/ 0.7120 24.92/ 0.7311 26.11/ 0.6607 27.91/ 0.8530 SwinIR[46] 2 11.75 28.95/ 0.8231 26.87/0.714 1 25.11/0.737 7 26.13/ 0.6622 28.03/0.856 5 DRCT [55] 2 13.34 28.86/ 0.8207 26.76/ 0.7103 24.87/ 0.7275 26.08/ 0.6597 27.78/ 0.8510 HMA[56] 2 66.49 28.79/ 0.8183 26.71/ 0.7077 24.73/ 0.7214 26.04/ 0.6575 27.64/ 0.8471 JCARSR 2 10.10 29.13/ 0.8269 26.96/ 0.7158 25.28/ 0.7423 26.19/ 0.6637 28.37/ 0.8609 EDSR[27] 4 43.09 25.03/ 0.7118 23.91/ 0.6005 21.87/ 0.5891 23.86/ 0.5588 23.26/ 0.7270 RDN[28] 4 22.27 25.04/ 0.7128 23.89/ 0.6012 21.84/ 0.5881 23.84/ 0.5593 23.25/ 0.7276 RCAN[29] 4 15.59 25.07/0.715 5 23.90/ 0.6010 21.93/ 0.5910 23.85/ 0.5592 23.26/ 0.7276 MDCN[30] 4 13.71 25.02/ 0.7128 23.84/ 0.5995 21.80/ 0.5885 23.82/ 0.5585 23.20/ 0.7251 SwinIR[46] 4 11.90 25.03/ 0.7145 23.93/0.602 2 21.94/0.592 8 23.86/0.560 0 23.29/0.730 7 DRCT [55] 4 13.48 24.95/ 0.7111 23.86/ 0.5988 21.79/ 0.5842 23.82/ 0.5580 23.16/ 0.7244 HMA[56] 4 66.63 24.99/ 0.7120 23.87/ 0.5984 21.89/ 0.5881 23.83/ 0.5581 23.18/ 0.7254 JCARSR 4 10.40 25.14/ 0.7174 24.03/ 0.6039 22.11/ 0.5967 23.92/ 0.5607 23.50/ 0.7338  下载: 导出CSV
下载: 导出CSV
表 2 JCARSR与JCAR-SR方法的定量比较
Table 2 Quantitative comparison of JCARSR with JCAR-SR methods
对比方法 尺度因子 Set5 Set14 Urban100 B100 Manga109 PSNR (dB)/SSIM PSNR (dB)/SSIM PSNR (dB)/SSIM PSNR (dB)/SSIM PSNR (dB)/SSIM ARCNN[40] + SwinIR[46] 2 28.24/ 0.7988 26.34/ 0.6936 24.16/ 0.6947 25.84/ 0.6480 26.68/ 0.8184 DnCNN3[41] + SwinIR[46] 2 28.54/ 0.8103 26.50/ 0.7017 24.40/ 0.7070 25.96/ 0.6542 27.01/ 0.8304 QGCN[43] + SwinIR[46] 2 28.93/0.822 7 26.80/0.712 5 25.04/0.735 3 26.13/0.661 8 27.88/0.852 8 FBCNN[44] + SwinIR[46] 2 28.87/ 0.8209 26.80/0.712 0 24.95/ 0.7311 26.13/ 0.6614 27.83/ 0.8527 JDEC[12] + SwinIR[46] 2 27.76/ 0.7920 25.70/ 0.6678 23.63/ 0.6724 25.39/ 0.6236 25.61/ 0.8024 JCARSR 2 29.13/ 0.8269 26.96/ 0.7158 25.28/ 0.7423 26.19/ 0.6637 28.37/ 0.8609 ARCNN[40] + SwinIR[46] 4 24.60/ 0.6806 23.57/ 0.5826 21.41/ 0.5563 23.68/ 0.5485 22.55/ 0.6881 DnCNN3[41] + SwinIR[46] 4 24.77/ 0.6911 23.70/ 0.5883 21.55/ 0.5640 23.74/ 0.5518 22.71/ 0.6965 QGCN[43] + SwinIR[46] 4 25.04/0.708 5 23.93/ 0.5995 21.93/0.587 5 23.86/ 0.5577 23.17/ 0.7200 FBCNN[44] + SwinIR[46] 4 25.02/ 0.7080 23.94/0.599 9 21.88/ 0.5851 23.87/0.557 8 23.20/0.723 6 JDEC[12] + SwinIR[46] 4 24.58/ 0.6966 23.38/ 0.5786 21.10/ 0.5454 23.54/ 0.5437 21.82/ 0.6771 JCARSR 4 25.14/ 0.7174 24.03/ 0.6039 22.11/ 0.5967 23.92/ 0.5607 23.50/ 0.7338
下载: 导出CSV
表 3 JCARSR与SR-JCAR方法的定量比较
Table 3 Quantitative comparison of JCARSR with SR-JCAR methods
对比方法 尺度因子 Set5 Set14 Urban100 B100 Manga109 PSNR (dB)/SSIM PSNR (dB)/SSIM PSNR (dB)/SSIM PSNR (dB)/SSIM PSNR (dB)/SSIM ARCNN[40] + SwinIR[46] 2 27.23/0.759 2 25.59/0.671 7 23.38/ 0.6634 25.36/0.634 4 25.47/0.778 3 DnCNN3[41] + SwinIR[46] 2 26.75/ 0.7355 25.23/ 0.6573 23.01/ 0.6442 25.13/ 0.6253 24.88/ 0.7507 QGCN[43] + SwinIR[46] 2 26.97/ 0.7495 25.43/ 0.6661 23.25/ 0.6571 25.22/ 0.6293 25.30/ 0.7721 FBCNN[44] + SwinIR[46] 2 27.14/ 0.7577 25.55/ 0.6717 23.38/0.664 2 25.30/ 0.6333 25.43/ 0.7781 JDEC[12] + SwinIR[46] 2 27.25/ 0.7601 25.62/ 0.6701 23.46/ 0.6619 25.34/ 0.6315 25.71/ 0.7880 JCARSR 2 29.13/ 0.8269 26.96/ 0.7158 25.28/ 0.7423 26.19/ 0.6637 28.37/ 0.8609 ARCNN[40] + SwinIR[46] 4 23.46/ 0.6134 22.56/0.536 8 20.56/0.508 9 23.02/0.518 1 21.48/0.627 8 DnCNN3[41] + SwinIR[46] 4 23.23/ 0.5936 22.40/ 0.5223 20.44/ 0.4956 22.86/ 0.5066 21.35/ 0.6079 QGCN[43] + SwinIR[46] 4 23.45/ 0.6124 22.56/ 0.5350 20.57/ 0.5068 23.00/ 0.5172 21.50/ 0.6246 FBCNN[44] + SwinIR[46] 4 23.46/0.613 8 22.58/ 0.5361 20.58/ 0.5079 23.01/0.518 1 21.51/ 0.6253 JDEC[12] + SwinIR[46] 4 23.60/ 0.6170 22.71/ 0.5381 20.70/ 0.5102 23.09/ 0.5196 21.68/ 0.6286 JCARSR 4 25.14/ 0.7174 24.03/ 0.6039 22.11/ 0.5967 23.92/ 0.5607 23.50/ 0.7338
下载: 导出CSV
表 4 不同JPEG压缩因子下的定量比较
Table 4 Quantitative comparison under different JPEG compress factors
对比方法 压缩因子 尺度因子 Set5 Set14 Urban100 B100 Manga109 PSNR (dB)/SSIM PSNR (dB)/SSIM PSNR (dB)/SSIM PSNR (dB)/SSIM PSNR (dB)/SSIM SwinIR[46] 10 2 28.95/ 0.8231 26.87/ 0.7141 25.11/ 0.7377 26.13/ 0.6622 28.03/ 0.8565 20 2 30.91/ 0.8638 28.31/ 0.7657 26.53/ 0.7911 27.33/ 0.7167 30.23/ 0.8943 30 2 31.92/ 0.8822 29.11/ 0.7929 27.40/ 0.8205 27.98/ 0.7464 31.48/ 0.9120 40 2 32.53/ 0.8926 29.63/ 0.8092 28.05/ 0.8385 28.40/ 0.7651 32.19/ 0.9214 80 2 34.65/ 0.9230 31.48/ 0.8653 30.09/ 0.8881 30.19/ 0.8341 35.26/ 0.9497 JCARSR 10 2 29.13/ 0.8269 26.96/ 0.7158 25.28/ 0.7423 26.19/ 0.6637 28.37/ 0.8609 20 2 31.01/ 0.8660 28.41/ 0.7669 26.69/ 0.7943 27.38/ 0.7175 30.55/ 0.8972 30 2 32.01/ 0.8836 29.18/ 0.7934 27.53/ 0.8215 28.02/ 0.7469 31.80/ 0.9137 40 2 32.63/ 0.8939 29.69/ 0.8098 28.12/ 0.8386 28.47/ 0.7659 32.66/ 0.9235 80 2 34.74/ 0.9233 31.50/ 0.8653 30.13/ 0.8883 30.20/ 0.8345 35.51/ 0.9502 SwinIR[46] 10 4 25.03/ 0.7145 23.93/ 0.6022 21.94/ 0.5928 23.86/ 0.5600 23.29/ 0.7307 20 4 26.50/ 0.7577 24.95/ 0.6369 22.88/ 0.6377 24.70/ 0.5917 24.77/ 0.7754 30 4 27.48/ 0.7825 25.56/ 0.6572 23.42/ 0.6631 25.13/ 0.6095 25.59/ 0.7986 40 4 28.04/ 0.7954 25.89/ 0.6695 23.78/ 0.6806 25.42/ 0.6216 26.14/ 0.8141 80 4 29.89/ 0.8409 27.24/ 0.7229 25.02/ 0.7360 26.45/ 0.6733 28.33/ 0.8626 JCARSR 10 4 25.14/ 0.7174 24.03/ 0.6039 22.11/ 0.5967 23.92/ 0.5607 23.50/ 0.7338 20 4 26.66/ 0.7608 25.07/ 0.6387 22.99/ 0.6386 24.76/ 0.5925 24.94/ 0.7767 30 4 27.54/ 0.7826 25.60/ 0.6578 23.51/ 0.6637 25.18/ 0.6104 25.78/ 0.8006 40 4 28.07/ 0.7957 25.97/ 0.6715 23.87/ 0.6813 25.47/ 0.6234 26.39/ 0.8171 80 4 29.94/ 0.8424 27.31/ 0.7246 25.06/ 0.7362 26.50/ 0.6745 28.41/ 0.8637
下载: 导出CSV
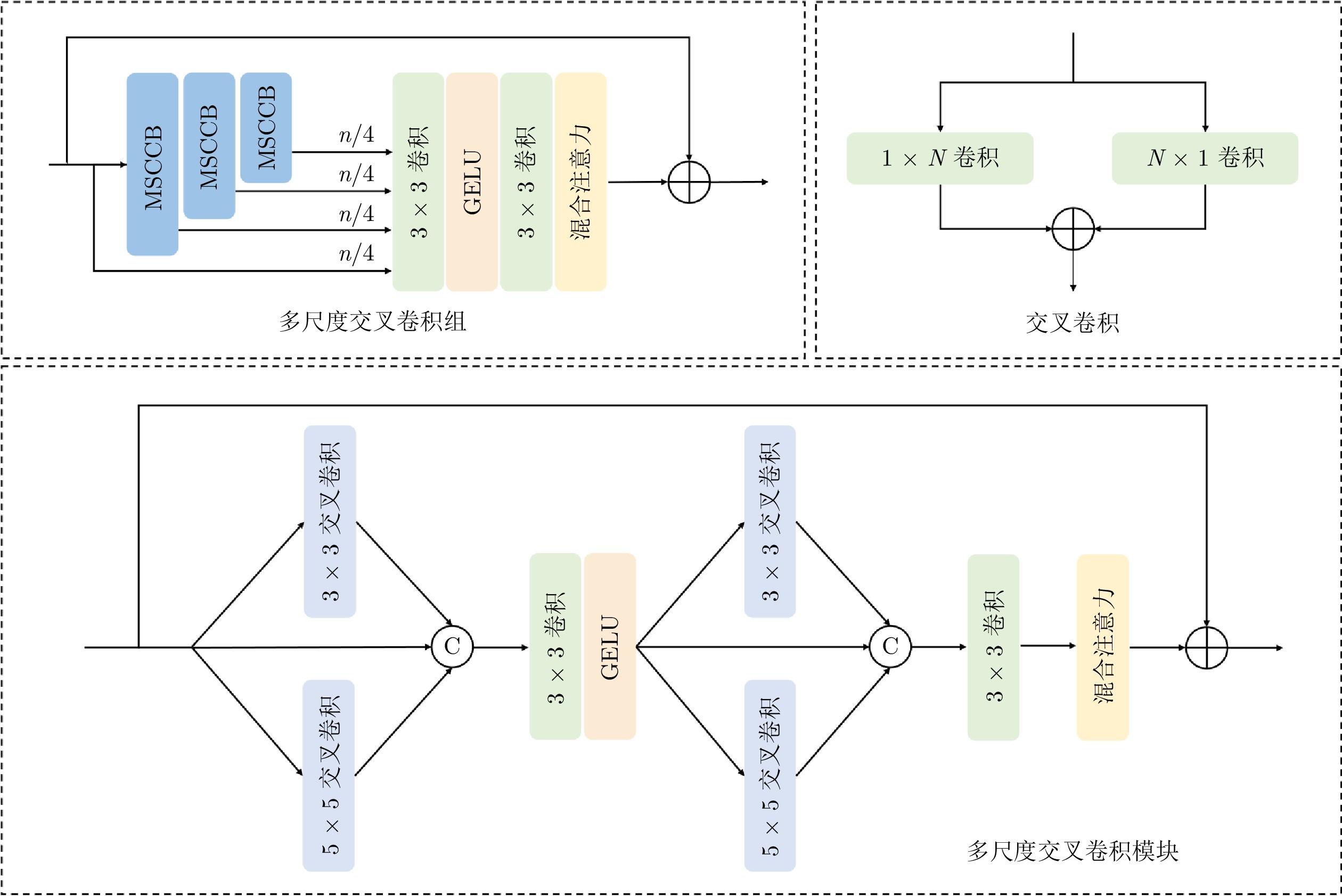
表 5 网络模块消融研究
Table 5 Ablation study on the network block
对比方法 Set5 Set14 Urban100 B100 Manga109 PSNR (dB)/SSIM PSNR (dB)/SSIM PSNR (dB)/SSIM PSNR (dB)/SSIM PSNR (dB)/SSIM w/o MSNAFB 29.00/ 0.8232 26.84/ 0.7122 25.00/ 0.7311 26.12/ 0.6608 28.06/ 0.8545 w/o MA 29.01/ 0.8237 26.85/ 0.7124 25.02/ 0.7316 26.13/ 0.6610 28.08/ 0.8545 w/o MSCCB 29.02/ 0.8240 26.90/ 0.7136 25.11/ 0.7359 26.15/ 0.6618 28.19/0.8570 JCARSR 29.13/ 0.8269 26.96/ 0.7158 25.28/ 0.7423 26.19/ 0.6637 28.37/ 0.8609
下载: 导出CSV
表 6 网络分支结构消融研究
Table 6 Ablation study on the network branch structure
对比方法 Set5 Set14 Urban100 B100 Manga109 PSNR (dB)/SSIM PSNR (dB)/SSIM PSNR (dB)/SSIM PSNR (dB)/SSIM PSNR (dB)/SSIM ISRB 29.02/ 0.8242 26.89/ 0.7137 25.11/ 0.7366 26.15/ 0.6619 28.20/ 0.8575 ISRB$ + $GGB 29.05/ 0.8242 26.90/ 0.7139 25.14/ 0.7373 26.15/ 0.6621 28.24/ 0.8578 ISRB$ + $GGB$ + $CARB 29.13/ 0.8269 26.96/ 0.7158 25.28/ 0.7423 26.19/ 0.6637 28.37/ 0.8609
下载: 导出CSV
表 7 多分支融合方式消融研究
Table 7 Ablation study on multi-branch fusion methods
信息融合方式 Set5 Set14 Urban100 B100 Manga109 PSNR (dB)/SSIM PSNR (dB)/SSIM PSNR (dB)/SSIM PSNR (dB)/SSIM PSNR (dB)/SSIM 双向 29.04/ 0.8242 26.89/ 0.7136 25.10/ 0.7356 26.15/ 0.6618 28.19/ 0.8572 单向 29.13/ 0.8269 26.96/ 0.7158 25.28/ 0.7423 26.19/ 0.6637 28.37/ 0.8609
下载: 导出CSV
表 8 梯度引导策略消融研究
Table 8 Ablation study on gradient-guided strategy
GL-ISRB GL-GGB Set5 Set14 Urban100 B100 Manga109 PSNR (dB)/SSIM PSNR (dB)/SSIM PSNR (dB)/SSIM PSNR (dB)/SSIM PSNR (dB)/SSIM √ × 29.06/ 0.8258 26.91/ 0.7160 25.20/ 0.7406 26.17/ 0.6645 28.27/ 0.8591 × √ 29.13/ 0.8269 26.96/ 0.7158 25.28/ 0.7423 26.19/ 0.6637 28.37/ 0.8609 √ √ 29.11/ 0.8268 26.94/ 0.7161 25.25/ 0.7412 26.18/ 0.6642 28.31/ 0.8595
下载: 导出CSV
-
[1] Zhang C J, Zheng X L. Decomposing visual and semantic correlations for both fully supervised and few-shot image classification. IEEE Transactions on Artificial Intelligence, 2024, 5(4): 1658−1668 doi: 10.1109/TAI.2023.3329457 [2] Tang Y P, Wang W N, Zhang C J, Liu J, Zhao Y. Temporal action proposal generation with action frequency adaptive network. IEEE Transactions on Multimedia, 2024, 26: 2340−2353 doi: 10.1109/TMM.2023.3295090 [3] 周登文, 刘子涵, 刘玉铠. 基于像素对比学习的图像超分辨率算法. 自动化学报, 2024, 50(1): 181−193Zhou Deng-Wen, Liu Zi-Han, Liu Yu-Kai. Pixel-wise contrastive learning for single image super-resolution. Acta Automatica Sinica, 2024, 50(1): 181−193 [4] Yue Z S, Wang J Y, Loy C C. ResShift: Efficient diffusion model for image super-resolution by residual shifting. In: Proceedings of the 37th International Conference on Neural Information Processing System. New Orleans, USA: Curran Associates Inc., 2023. 13294−13307 [5] 王云涛, 赵蔺, 刘李漫, 陶文兵. 基于组−信息蒸馏残差网络的轻量 级图像超分辨率重建. 自动化学报, 2024, 50(10): 2063−2078Wang Yun-Tao, Zhao Lin, Liu Li-Man, Tao Wen-Bing. G-IDRN: A group-information distillation residual network for lightweight image super-resolution. Acta Automatica Sinica, 2024, 50(10): 2063−2078 [6] Wang X Y, Hu Q, Cheng Y S, Ma J Y. Hyperspectral image super-resolution meets deep learning: A survey and perspective. IEEE/CAA Journal of Automatica Sinica, 2023, 10(8): 1668−1691 doi: 10.1109/JAS.2023.123681 [7] Dong C, Loy C C, He K M, Tang X O. Image super-resolution using deep convolutional networks. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2016, 38(2): 295−307 doi: 10.1109/TPAMI.2015.2439281 [8] Hu Q, Ma J Y, Gao Y, Jiang J J, Yuan Y X. Maun: MEMORY-augmented deep unfolding network for hyperspectral image reconstruction. IEEE/CAA Journal of Automatica Sinica, 2024, 11(5): 1139−1150 doi: 10.1109/JAS.2024.124362 [9] Ma C, Rao Y M, Cheng Y, Chen C, Lu J W, Zhou J. Structure-preserving super resolution with gradient guidance. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, USA: IEEE, 2020. 7769−7778 [10] Fang F M, Li J C, Zeng T Y. Soft-edge assisted network for single image super-resolution. IEEE Transactions on Image Processing, 2020, 29: 4656−4668 doi: 10.1109/TIP.2020.2973769 [11] Ma C, Rao Y M, Lu J W, Zhou J. Structure-preserving image super-resolution. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(11): 7898−7911 doi: 10.1109/TPAMI.2021.3114428 [12] Han W K, Im S, Kim J, Jin K H. JDEC: JPEG decoding via enhanced continuous cosine coefficients. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, USA: IEEE, 2024. 2784−2793 [13] Zuo Y F, Xie J C, Wang H, Fang Y M, Liu D Y, Wen W Y. Gradient-guided single image super-resolution based on joint trilateral feature filtering. IEEE Transactions on Circuits and Systems for Video Technology, 2023, 33(2): 505−520Zuo Y F, Xie J C, Wang H, Fang Y M, Liu D Y, Wen W Y. Gradient-guided single image super-resolution based on joint trilateral feature filtering. IEEE Transactions on Circuits and Systems for Video Technology, 2023, 33(2): 505−520 [14] Zhu Y, Zhang Y N, Bonev B, Yuille A L. Modeling deformable gradient compositions for single-image super-resolution. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Boston, USA: IEEE, 2015. 5417−5425 [15] 周圆, 王明非, 杜晓婷, 陈艳芳. 基于层次特征复用的视频超分辨率重建. 自动化学报, 2024, 50(9): 1736−1746Zhou Yuan, Wang Ming-Fei, Du Xiao-Ting, Chen Yan-Fang. Video super-resolution via hierarchical feature reuse. Acta Automatica Sinica, 2024, 50(9): 1736−1746 [16] Yang W H, Feng J S, Yang J C, Zhao F, Liu J Y, Guo Z M, et al. Deep edge guided recurrent residual learning for image super-resolution. IEEE Transactions on Image Processing, 2017, 26(12): 5895−5907 doi: 10.1109/TIP.2017.2750403 [17] Luo Z W, Gustafsson F K, Zhao Z, Sjölund J, Schön T B. Photo-realistic image restoration in the wild with controlled vision-language models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). Seattle, USA: IEEE, 2024. 6641−6651 [18] Özdenizci O, Legenstein R. Restoring vision in adverse weather conditions with patch-based denoising diffusion models. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(8): 10346−10357 doi: 10.1109/TPAMI.2023.3238179 [19] Chen X Y, Liu Y H, Pu Y D, Zhang W L, Zhou J T, Qiao Y, et al. Learning a low-level vision generalist via visual task prompt. In: Proceedings of the 32nd ACM International Conference on Multimedia. Melbourne, Australia: ACM, 2024. 2671−2680 [20] Wu R Y, Yang T, Sun L C, Zhang Z Q, Li S, Zhang L, et al. SeeSR: Towards semantics-aware real-world image super-resolution. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, USA: IEEE, 2024. 25456−25467 [21] Zhang C J, Bai H H, Zhao Y. Fine-grained image classification by class and image-specific decomposition with multiple views. IEEE Transactions on Multimedia, 2023, 25: 6756−6766 doi: 10.1109/TMM.2022.3214431 [22] Zhang C J, Cheng J, Tian Q. Multi-view image classification with visual, semantic and view consistency. IEEE Transactions on Image Processing, 2020, 29: 617−627 doi: 10.1109/TIP.2019.2934576 [23] 李金新, 黄志勇, 李文斌, 周登文. 基于多层次特征融合的图像超分辨率重建. 自动化学报, 2023, 49(1): 161−171Li Jin-Xin, Huang Zhi-Yong, Li Wen-Bin, Zhou Deng-Wen. Image super-resolution based on multi-hierarchical features fusion network. Acta Automatica Sinica, 2023, 49(1): 161−171 [24] Dong C, Loy C C, Tang X O. Accelerating the super-resolution convolutional neural network. In: Proceedings of the 14th European Conference on Computer Vision. Amsterdam, Netherlands: Springer, 2016. 391−407 [25] Shi W Z, Caballero J, Huszár F, Totz J, Aitken A P, Bishop R, et al. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, USA: IEEE, 2016. 1874−1883 [26] Liu Y Q, Jia Q, Fan X, Wang S S, Ma S W, Gao W. Cross-SRN: Structure-preserving super-resolution network with cross convolution. IEEE Transactions on Circuits and Systems for Video Technology, 2022, 32(8): 4927−4939 doi: 10.1109/TCSVT.2021.3138431 [27] Lim B, Son S, Kim H, Nah S, Mu Lee K. Enhanced deep residual networks for single image super-resolution. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops. Honolulu, USA: IEEE, 2017. 136−144 [28] Zhang Y L, Tian Y P, Kong Y, Zhong B N, Fu Y. Residual dense network for image super-resolution. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 2472−2481 [29] Zhang Y L, Li K P, Li K, Wang L C, Zhong B N, Fu Y. Image super-resolution using very deep residual channel attention networks. In: Proceedings of the 15th European Conference on Computer Vision. Munich, Germany: Springer, 2018. 286−301 [30] Li J C, Fang F M, Li J Q, Mei K F, Zhang G X. MDCN: Multi-scale dense cross network for image super-resolution. IEEE Transactions on Circuits and Systems for Video Technology, 2021, 31(7): 2547−2561 doi: 10.1109/TCSVT.2020.3027732 [31] Lai W S, Huang J B, Ahuja N, Yang M H. Deep laplacian pyramid networks for fast and accurate super-resolution. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, USA: IEEE, 2017. 624−632 [32] Haris M, Shakhnarovich G, Ukita N. Deep back-projection networks for super-resolution. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 1664−1673 [33] Zakhor A. Iterative procedures for reduction of blocking effects in transform image coding. IEEE Transactions on Circuits and Systems for Video Technology, 1992, 2(1): 91−95 doi: 10.1109/76.134377 [34] Zhang X F, Xiong R Q, Fan X P, Ma S W, Gao W. Compression artifact reduction by overlapped-block transform coefficient estimation with block similarity. IEEE Transactions on Image Processing, 2013, 22(12): 4613−4626 doi: 10.1109/TIP.2013.2274386 [35] Zhang J, Xiong R Q, Zhao C, Zhang Y B, Ma S W, Gao W. CONCOLOR: Constrained non-convex low-rank model for image deblocking. IEEE Transactions on Image Processing, 2016, 25(3): 1246−1259 doi: 10.1109/TIP.2016.2515985 [36] Foi A, Katkovnik V, Egiazarian K. Pointwise shape-adaptive DCT for high-quality denoising and deblocking of grayscale and color images. IEEE Transactions on Image Processing, 2007, 16(5): 1395−1411 doi: 10.1109/TIP.2007.891788 [37] Liu X M, Cheung G, Wu X L, Zhao D B. Random walk graph laplacian-based smoothness prior for soft decoding of JPEG images. IEEE Transactions on Image Processing, 2017, 26(2): 509−524 doi: 10.1109/TIP.2016.2627807 [38] Zhang C J, Liang C, Zhao Y. Exemplar-based, semantic guided zero-shot visual recognition. IEEE Transactions on Image Processing, 2022, 31: 3056−3065 doi: 10.1109/TIP.2021.3120319 [39] Chen L Y, Chu X J, Zhang X Y, Sun J. Simple baselines for image restoration. In: Proceedings of the 17th European Conference on Computer Vision. Tel Aviv, Israel: Springer, 2022. 17−33 [40] Dong C, Deng Y B, Loy C C, Tang X O. Compression artifacts reduction by a deep convolutional network. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV). Santiago, Chile: IEEE, 2015. 576−584 [41] Zhang K, Zuo W M, Chen Y J, Meng D Y, Zhang L. Beyond a Gaussian denoiser: Residual learning of deep CNN for image denoising. IEEE Transactions on Image Processing, 2017, 26(7): 3142−3155 doi: 10.1109/TIP.2017.2662206 [42] Fu X Y, Zha Z J, Wu F, Ding X H, Paisley J. JPEG artifacts reduction via deep convolutional sparse coding. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). Seoul, Korea (South): IEEE, 2019. 2501−2510 [43] Li J W, Wang Y T, Xie H H, Ma K K. Learning a single model with a wide range of quality factors for JPEG image artifacts removal. IEEE Transactions on Image Processing, 2020, 29: 8842−8854 doi: 10.1109/TIP.2020.3020389 [44] Jiang J X, Zhang K, Timofte R. Towards flexible blind JPEG artifacts removal. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). Montreal, Canada: IEEE, 2021. 4997−5006 [45] Liu Z, Lin Y T, Cao Y, Hu H, Wei Y X, Zhang Z, et al. Swin transformer: Hierarchical vision transformer using shifted windows. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). Montreal, Canada: IEEE, 2021. 10012−10022 [46] Liang J Y, Cao J Z, Sun G L, Zhang K, van Gool L, Timofte R. SwinIR: Image restoration using swin transformer. In: Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops (ICCVW). Montreal, Canada: IEEE, 2021. 1833−1844 [47] Zamir S W, Arora A, Khan S, Hayat M, Khan F S, Yang M H, et al. Learning enriched features for fast image restoration and enhancement. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(2): 1934−1948 doi: 10.1109/TPAMI.2022.3167175 [48] Hendrycks D, Gimpel K. Gaussian error linear units (GELUs). arXiv preprint arXiv: 1606.08415, 2016. [49] Agustsson E, Timofte R. NTIRE 2017 challenge on single image super-resolution: Dataset and study. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). Honolulu, USA: IEEE, 2017. 126−135 [50] Bevilacqua M, Roumy A, Guillemot C, Alberi-Morel M L. Low-complexity single-image super-resolution based on nonnegative neighbor embedding. In: Proceedings of the British Machine Vision Conference. Surrey, UK: BMVC, 2012. 1−10 [51] Zeyde R, Elad M, Protter M. On single image scale-up using sparse-representations. In: Proceedings of the 7th International Conference on Curves and Surfaces. Avignon, France: Springer, 2012. 711−730 [52] Huang J B, Singh A, Ahuja N. Single image super-resolution from transformed self-exemplars. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Boston, USA: IEEE, 2015. 5197−5206 [53] Martin D, Fowlkes C, Tal D, Malik J. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. In: Proceedings of the 8th IEEE International Conference on Computer Vision. Vancouver, Canada: IEEE, 2001. 416−423 [54] Matsui Y, Ito K, Aramaki Y, Fujimoto A, Ogawa T, Yamasaki T, et al. Sketch-based manga retrieval using manga109 dataset. Multimedia Tools and Applications, 2017, 76(20): 21811−21838 doi: 10.1007/s11042-016-4020-z [55] Hsu C C, Lee C M, Chou Y S. DRCT: Saving image super-resolution away from information bottleneck. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). Seattle, USA: IEEE, 2024. 6133−6142 [56] Chu S C, Dou Z C, Pan J S, Weng S W, Li J B. HMANet: Hybrid multi-axis aggregation network for image super-resolution. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). Seattle, USA: IEEE, 2024. 6257−6266 [57] Ji X Z, Cao Y, Tai Y, Wang C J, Li J L, Huang F Y. Real-world super-resolution via kernel estimation and noise injection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). Seattle, USA: IEEE, 2020. 466−467Ji X Z, Cao Y, Tai Y, Wang C J, Li J L, Huang F Y. Real-world super-resolution via kernel estimation and noise injection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). Seattle, USA: IEEE, 2020. 466−467 [58] Wang X T, Xie L B, Dong C, Shan Y. Real-ESRGAN: Training real-world blind super-resolution with pure synthetic data. In: Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops (ICCVW). Montreal, Canada: IEEE, 2021. 1905−1914 [59] Luo Z X, Huang Y, Li S, Wang L, Tan T N. End-to-end alternating optimization for real-world blind super resolution. International Journal of Computer Vision, 2023, 131(12): 3152−3169 doi: 10.1007/s11263-023-01833-7 -

 下载:
下载:



计量
- 文章访问数: 348
- HTML全文浏览量: 320
- PDF下载量: 68
- 被引次数: 0
