

-
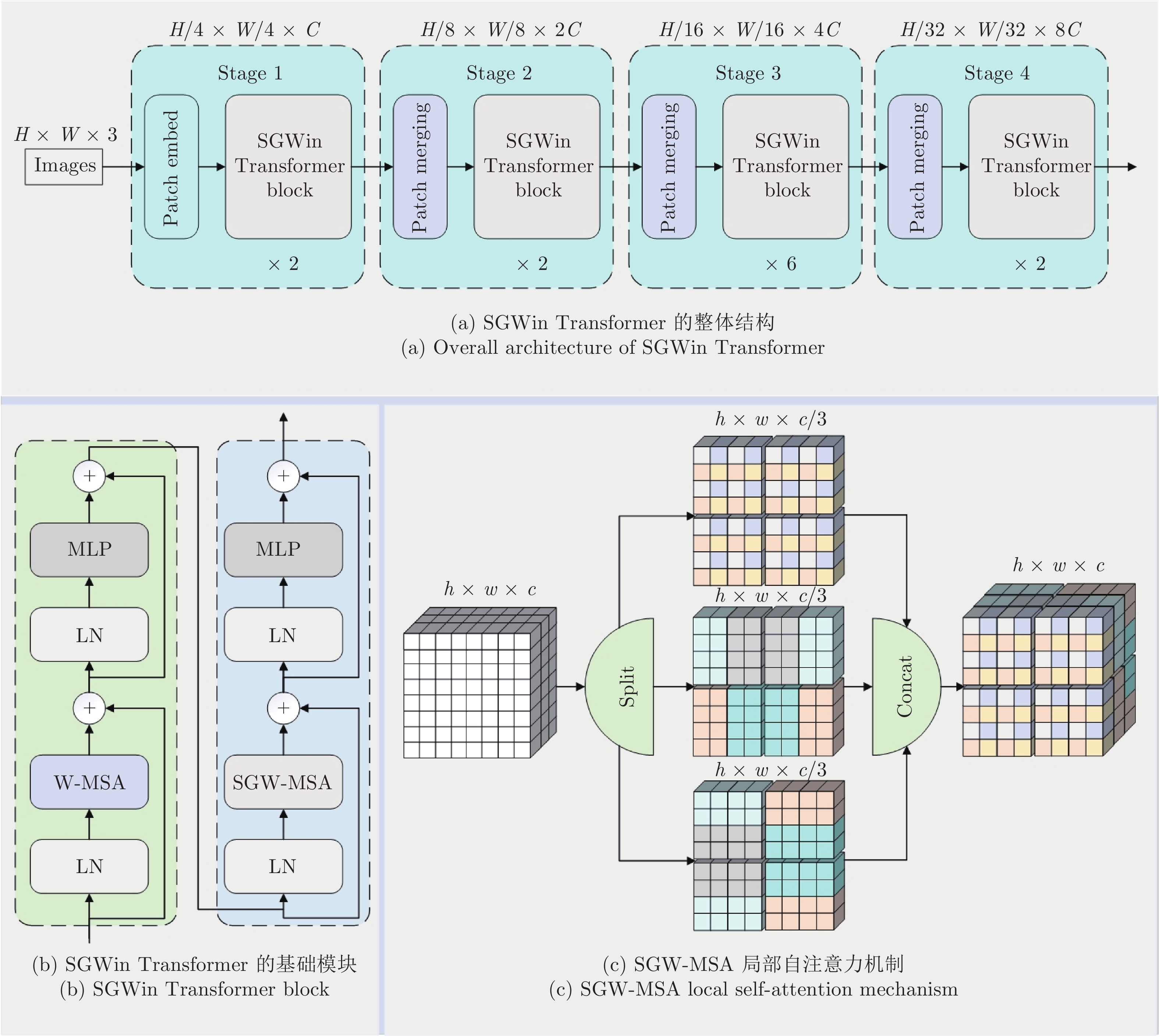
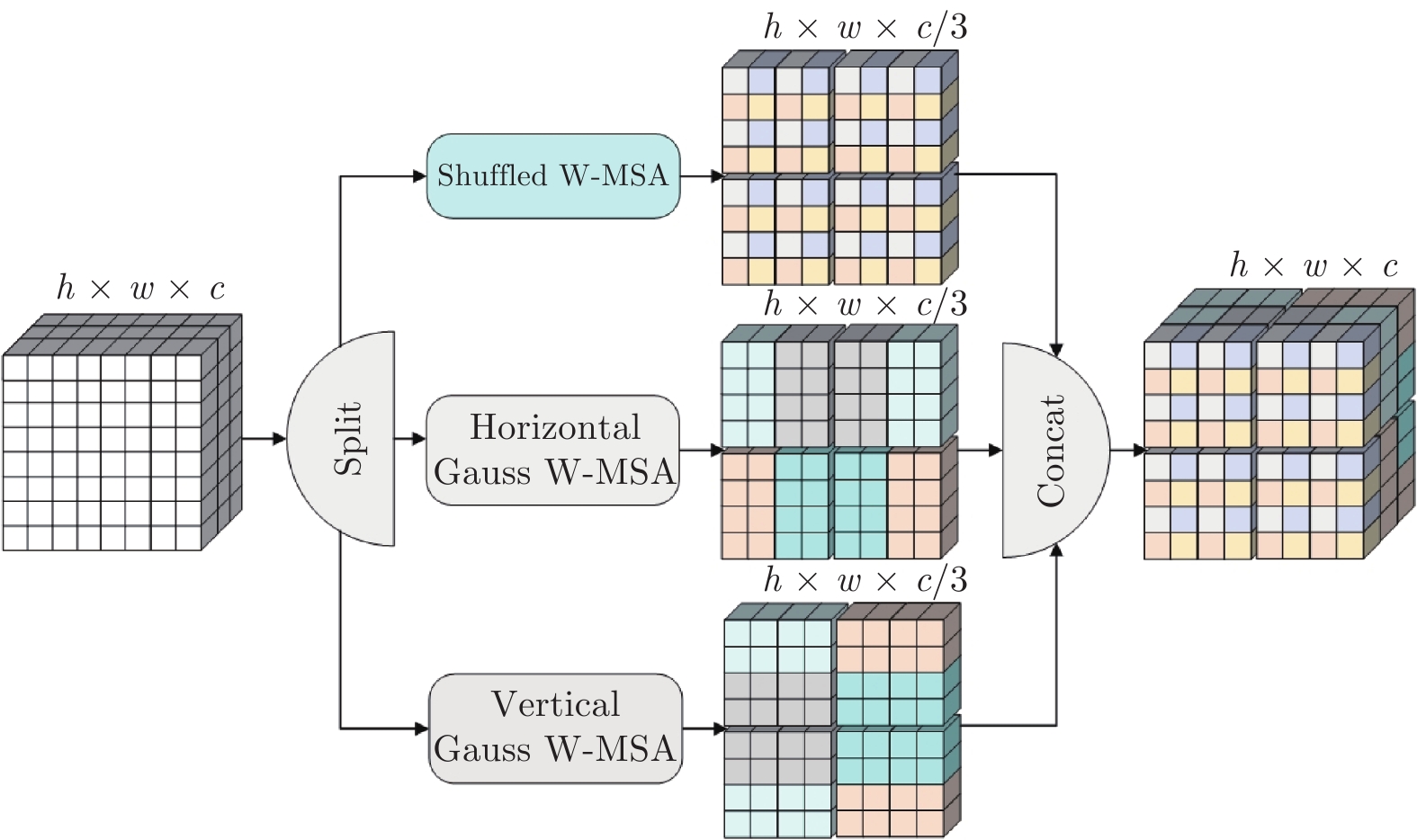
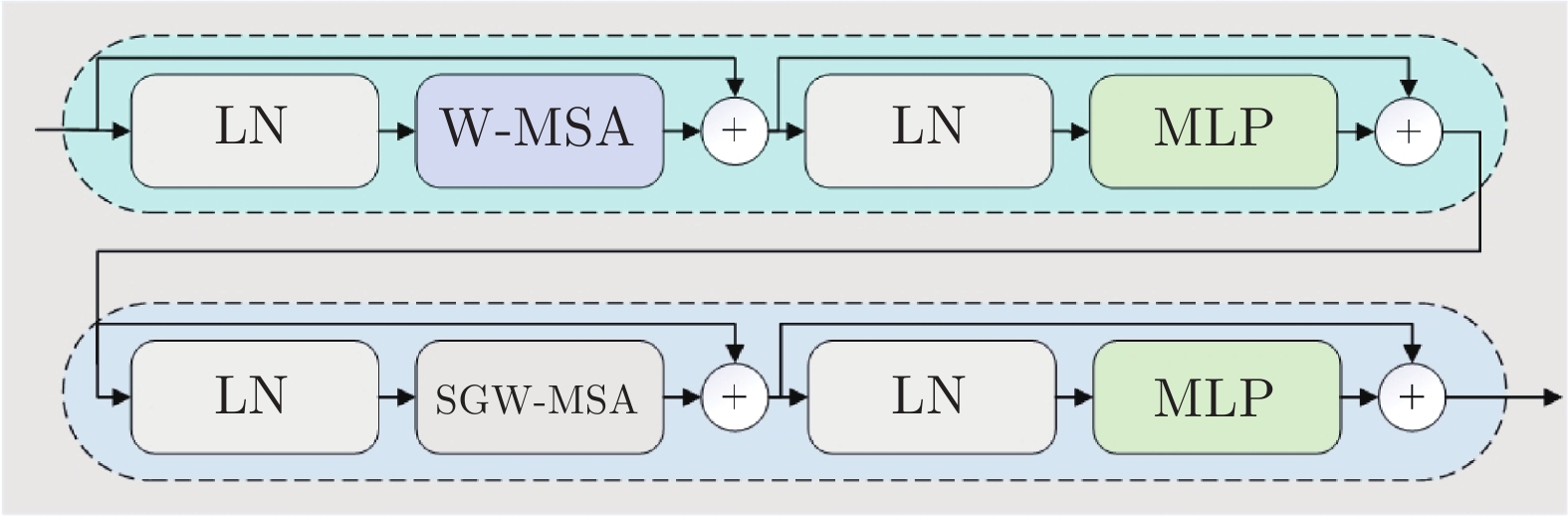
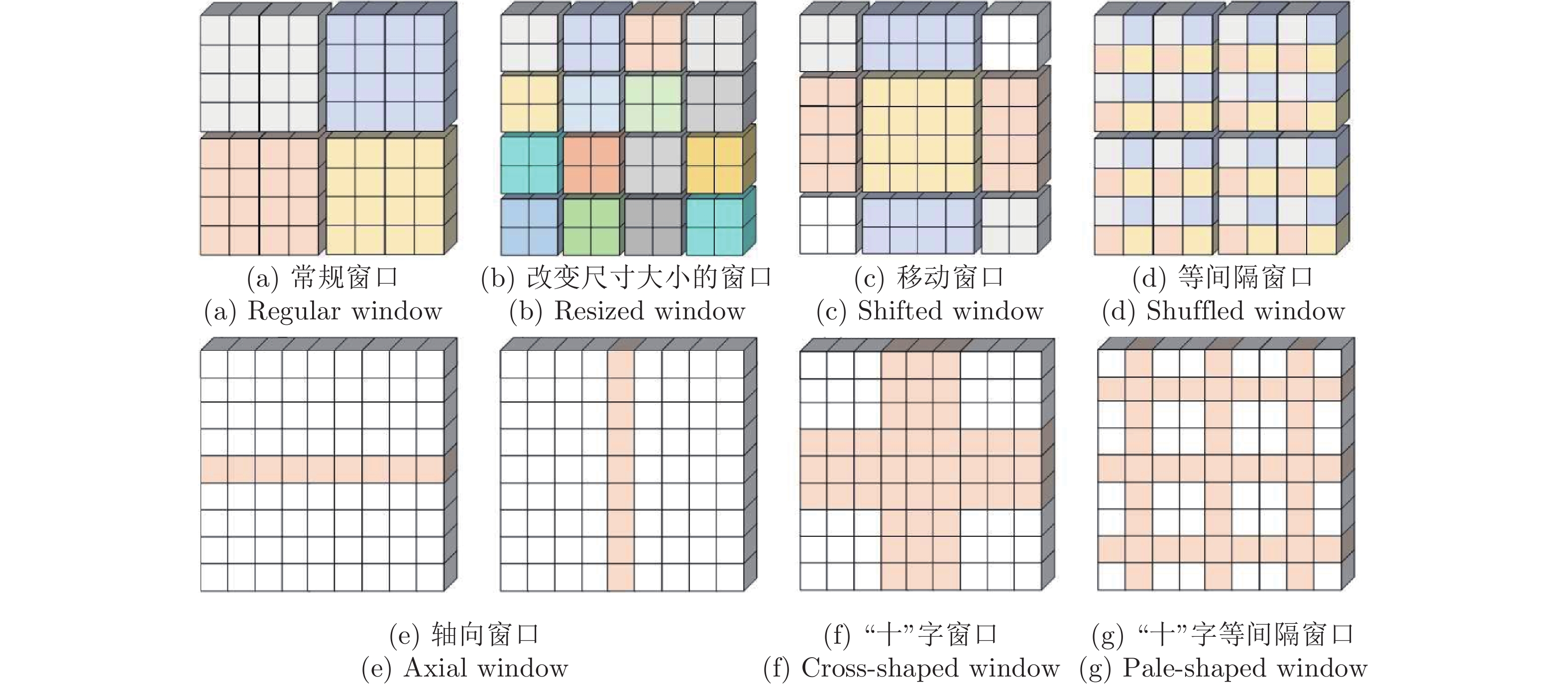
摘要: 在目前视觉Transformer的局部自注意力中, 现有的策略无法建立所有窗口之间的信息流动, 导致上下文语境建模能力不足. 针对这个问题, 基于混合高斯权重重组(Gaussian weight recombination, GWR)的策略, 提出一种新的局部自注意力机制SGW-MSA (Shuffled and Gaussian window-multi-head self-attention), 它融合了3种不同的局部自注意力, 并通过GWR策略对特征图进行重建, 在重建的特征图上提取图像特征, 建立了所有窗口的交互以捕获更加丰富的上下文信息. 基于SGW-MSA设计了SGWin Transformer整体架构. 实验结果表明, 该算法在mini-imagenet图像分类数据集上的准确率比Swin Transformer提升了5.1%, 在CIFAR10图像分类实验中的准确率比Swin Transformer提升了5.2%, 在MS COCO数据集上分别使用Mask R-CNN和Cascade R-CNN目标检测框架的mAP比Swin Transformer分别提升了5.5%和5.1%, 相比于其他基于局部自注意力的模型在参数量相似的情况下具有较强的竞争力.
-
关键词:
- Transformer /
- 局部自注意力 /
- 混合高斯权重重组 /
- 图像分类 /
- 目标检测
Abstract: In the current vision Transformer's local self-attention, the existing strategy cannot establish the information flow between all windows, resulting in the lack of context modeling ability. To solve this problem, this paper proposes a new local self-attention mechanism shuffled and Gaussian window-multi-head self-attention (SGW-MSA) based on the strategy of Gaussian weight recombination (GWR), which combines three different local self-attention forces, and reconstructs the feature map through GWR strategy, and extracts image features from the reconstructed feature map. The interaction of all windows is established to capture richer context information. This paper designs the overall architecture of SGWin Transformer based on SGW-MSA. The experimental results show that the accuracy of this algorithm in the mini-imagenet image classification dataset is 5.1% higher than that in the Swin Transformer, the accuracy in the CIFAR10 image classification experiment is 5.2% higher than that in the Swin Transformer, and the mAP using the Mask R-CNN and Cascade R-CNN object detection frameworks on the MS COCO dataset are 5.5% and 5.1% higher than that in the Swin Transformer, respectively. Compared with other models based on local self-attention, it has stronger competitiveness in the case of similar parameters. -
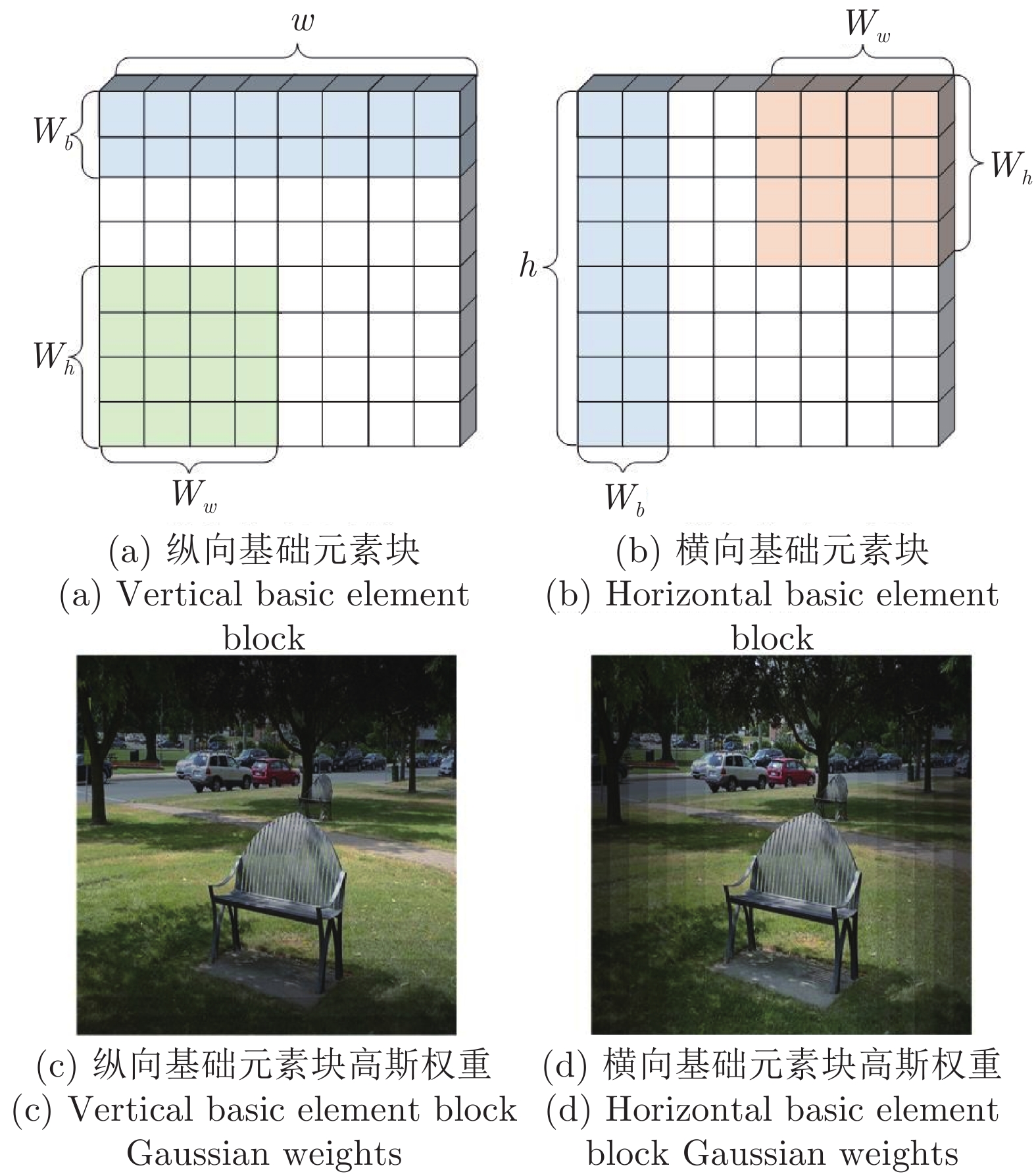
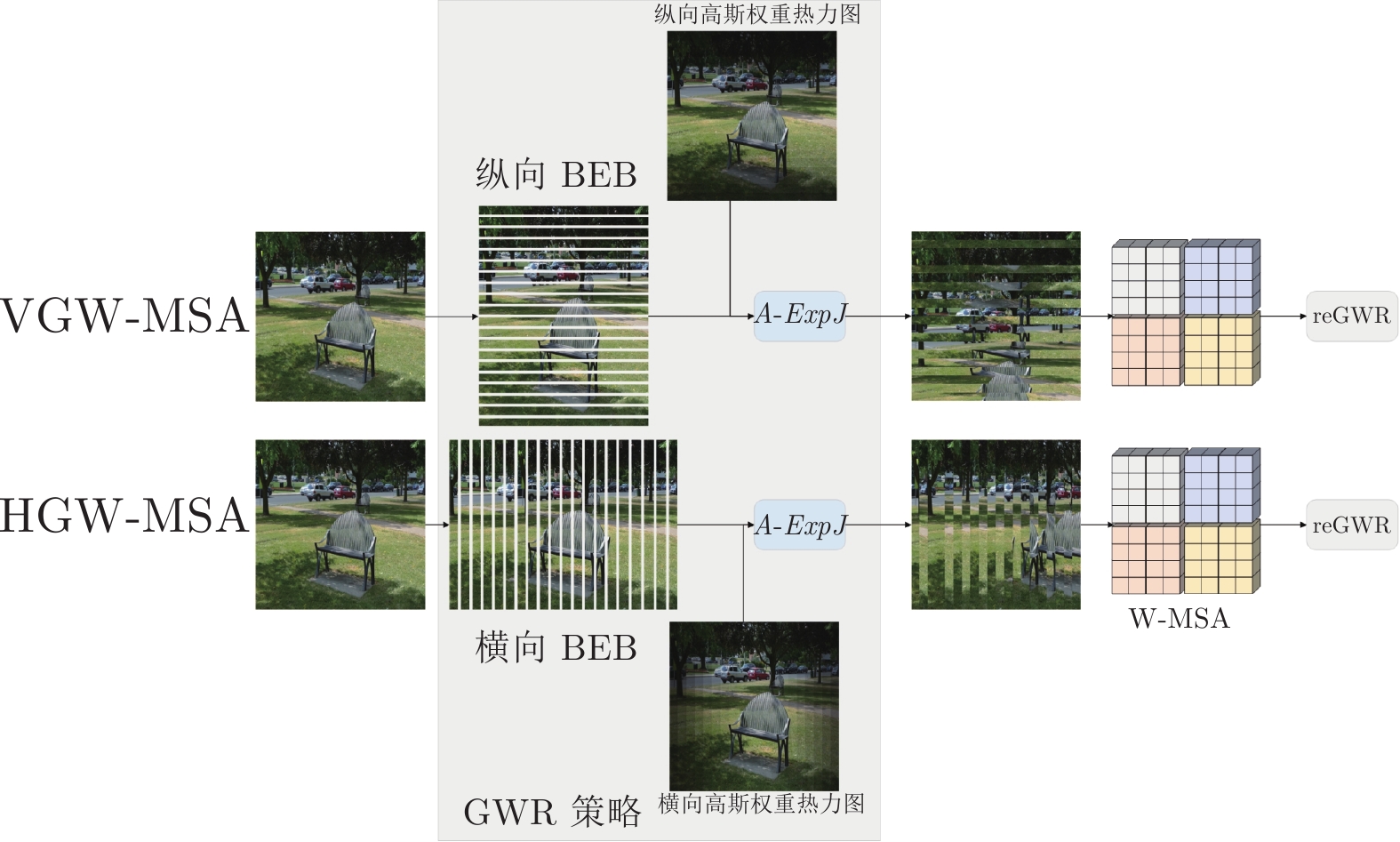
图 6 纵横向基础元素块示意图
Fig. 6 Schematic diagram of vertical and horizontal basic element block

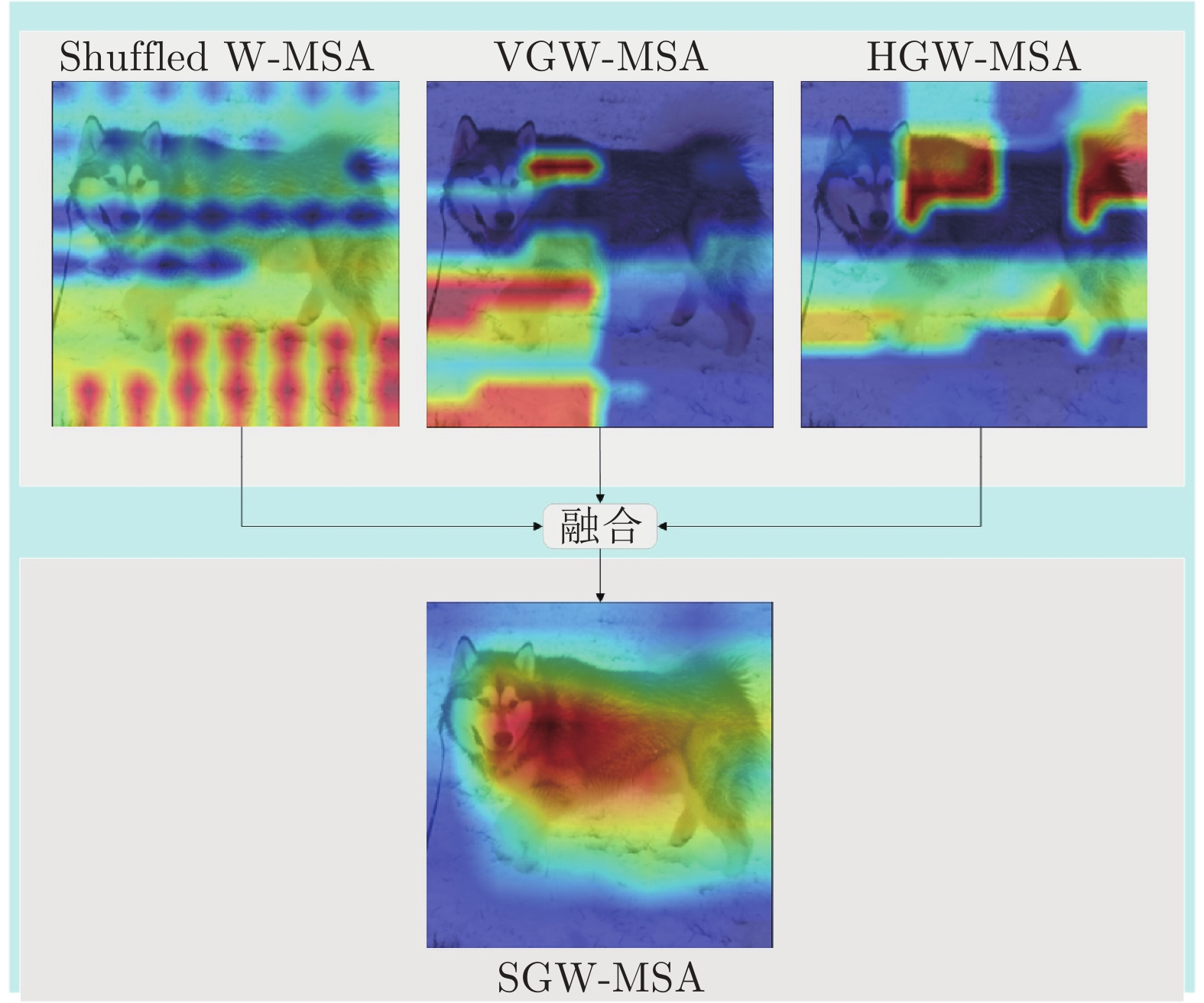
图 8 本文算法与Swin Transformer的热力图对比
Fig. 8 Comparison between the algorithm in this paper and the thermal diagram of Swin Transformer
表 1 SGWin Transformer的超参数配置表
Table 1 Super parameter configuration table of SGWin Transformer
Stage Stride Layer Parameter 1 4 Patch embed $\begin{aligned} P_1 = 4\;\;\\ C_1 = 96\end{aligned}$ Transformer block ${\left[\begin{aligned} S_1 = 7\\H_1 = 3\\R_1 = 4\end{aligned}\right ]}\times{2}$ 2 8 Patch merging $\begin{aligned} P_2 = 2\;\;\;\\C_2 = 192\end{aligned}$ Transformer block ${\left[\begin{aligned} S_2 = 7\\H_2 = 6\\R_2 = 4\end{aligned}\right ]}\times{2}$ 3 16 Patch merging $\begin{aligned} P_3 = 2\;\;\;\\C_3 = 384\end{aligned}$ Transformer block ${\left[\begin{aligned} S_3 = 7\;\;\\H_3 = 12\\R_3 = 4\;\;\end{aligned}\right ]}\times{2}$ 4 32 Patch merging $\begin{aligned} p_4 = 2\;\;\;\\C_4 = 768\end{aligned}$ Transformer block ${\left[\begin{aligned} S_4 = 7\;\;\\H_4 = 24\\R_4 = 4\;\;\end{aligned}\right ]}\times{2}$  下载: 导出CSV
下载: 导出CSV
表 2 基础元素块宽度消融实验对比
Table 2 Comparison of ablation experiments of basic element block width
$W_b$ $AP^b\;(\%)$ $AP^m\;(\%)$ 1 34.2 31.9 2 34.9 32.5 3 35.8 33.2 4 36.3 33.7 5 35.5 32.4 6 34.7 32.0
下载: 导出CSV
表 3 SGW-MSA消融实验结果
Table 3 SGW-MSA ablation experimental results
序号 方法 $AP^b\;(\%)$ $AP^m\;(\%)$ A SW-MSA (baseline) 30.8 29.5 B Shuffled W-MSA 33.6 (+2.8) 31.6 (+2.1) C B+VGW-MSA 34.9 (+1.3) 32.7 (+1.1) D C+HGW-MSA 36.3 (+1.4) 33.7 (+1.0)
下载: 导出CSV
表 4 CIFAR10数据集上的Top1精度对比
Table 4 Top1 accuracy comparison on CIFAR10 dataset
算法 Top1准确率 (%) Parameter (MB) Swin Transformer 85.44 7.1 CSWin Transformer 90.20 7.0 CrossFormer 88.64 7.0 GG Transformer 87.75 7.1 Shuffle Transformer 89.32 7.1 Pale Transformer 90.23 7.0 SGWin Transformer 90.64 7.1
下载: 导出CSV
表 5 mini-imagenet数据集上的Top1精度对比
Table 5 Top1 accuracy comparison on mini-imagenet dataset
算法 Top1准确率(%) Parameter (MB) Swin Transformer 67.51 28 CSWin Transformer 71.68 23 CrossFormer 70.43 28 GG Transformer 69.85 28 Shuffle Transformer 71.26 28 Pale Transformer 71.96 23 SGWin Transformer 72.63 28
下载: 导出CSV
表 6 以Mask R-CNN为目标检测框架在MS COCO数据集上的实验结果
Table 6 Experimental results on MS COCO dataset based on Mask R-CNN
Backbone Params (M) FLOPs (G) $AP^b\;(\%)$ $AP^b_{50}\;(\%)$ $AP^b_{75}\;(\%)$ $AP^m\;(\%)$ $AP^m_{50}\;(\%)$ $AP^m_{75}\;(\%)$ Swin 48 264 39.6 61.3 43.2 36.6 58.2 39.3 CSWin 42 279 42.6 63.3 46.9 39.0 60.5 42.0 Cross 50 301 41.3 62.7 45.3 38.2 59.7 41.2 GG 48 265 40.0 61.4 43.9 36.7 58.2 39.0 Shuffle 48 268 42.7 63.6 47.1 39.1 60.9 42.2 Focal 49 291 40.7 62.4 44.8 37.8 59.6 40.8 Pale 41 306 43.3 64.1 47.9 39.5 61.2 42.8 SGWin 48 265 45.1 66.0 49.9 40.8 63.5 44.2
下载: 导出CSV
表 7 以Cascade R-CNN为目标检测框架在MS COCO数据集上的实验结果
Table 7 Experimental results on MS COCO dataset based on Cascade R-CNN
Backbone Params(M) FLOPs(G) $AP^b\;(\%)$ $AP^b_{50}\;(\%)$ $AP^b_{75}\;(\%)$ $AP^m\;(\%)$ $AP^m_{50}\;(\%)$ $AP^m_{75}\;(\%)$ Swin 86 754 47.8 55.5 40.9 33.4 52.8 35.8 CSWin 80 757 40.7 57.1 44.5 35.5 55.0 38.3 Cross 88 770 39.5 56.9 43.0 34.7 53.7 37.2 GG 86 756 38.1 55.4 41.5 33.2 51.9 35.1 Shuffle 86 758 40.7 57.0 44.4 35.8 55.1 38.0 Focal 87 770 38.6 55.6 42.2 34.5 53.7 39.0 Pale 79 770 41.5 57.8 45.3 36.1 55.2 39.0 SGWin 86 756 42.9 60.9 46.3 37.8 57.2 40.5
下载: 导出CSV
表 8 KITTI和PASCAL VOC数据集上的实验结果
Table 8 Experimental results on KITTI and PASCAL VOC dataset
Backbone KITTI mAP@0.5:0.95 VOC mAP@0.5 Params (M) FPS Swin 57.3 59.6 14.4 50 CSWin 58.7 64.1 14.2 48 Cross 58.1 62.8 13.8 20 Shuffle 58.7 64.6 14.4 53 GG 57.8 62.4 14.4 46 Pale 58.9 64.5 14.2 48 SGWin 59.2 65.1 14.4 56
下载: 导出CSV
-
[1] 蒋弘毅, 王永娟, 康锦煜. 目标检测模型及其优化方法综述. 自动化学报, 2021, 47(6): 1232-1255 doi: 10.16383/j.aas.c190756Jiang Hong-Yi, Wang Yong-Juan, Kang Jin-Yu. A survey of object detection models and its optimiza-tion methods. Acta Automatica Sinica, 2021, 47(6): 1232-1255 doi: 10.16383/j.aas.c190756 [2] 尹宏鹏, 陈波, 柴毅, 刘兆栋. 基于视觉的目标检测与跟踪综述. 自动化学报, 2016, 42(10): 1466-1489 doi: 10.16383/j.aas.2016.c150823Yin Hong-Peng, Chen Bo, Chai Yi, Liu Zhao-Dong. Vision-based object detection and tracking: a review.Acta Automatica Sinica, 2016, 42(10): 1466-1489 doi: 10.16383/j.aas.2016.c150823 [3] 徐鹏斌, 翟安国, 王坤峰, 李大字. 全景分割研究综述. 自动化学报, 2021, 47(3): 549-568 doi: 10.16383/j.aas.c200657Xu Peng-Bin, Q An-Guo, Wang Kun-Feng, Li Da-Zi. A survey of panoptic segmentation methods. Acta Automatica Sinica, 2021, 47(3): 549-568 doi: 10.16383/j.aas.c200657 [4] Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks. Communications of the ACM, 2017, 60(6): 84-90 doi: 10.1145/3065386 [5] Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv: 1409.1556, 2014. [6] Huang G, Liu Z, Laurens V D M. Densely connected convolutional networks. In: Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, USA: IEEE, 2017. 4700−4708 [7] He K, Zhang X, Ren S. Deep residual tearning for image recognition. In: Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, USA: IEEE, 2016. 770−778 [8] Xie S, Girshick R, Dollár P. Aggregated residual transformations for deep neural networks. In: Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, USA: IEEE, 2017. 1492−1500 [9] Szegedy C, Liu W, Jia Y. Going deeper with convolutions. In: Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR). Boston, USA: IEEE, 2015. 1−9 [10] Tan M, Le Q V. EfficientNet: Rethinking model scaling for convolutional neural networks. In: Proceedings of the 36th International Conference on Machine Learning. New York, USA: JMLR, 2019. 6105−6114 [11] Tomar G S, Duque T, Tckstrm O. Neural paraphrase identification of questions with noisy pretraining. In: Proceedings of the First Workshop on Subword and Character Level Models in NLP. Copenhagen, Denmark: Association for Computational Linguistics, 2017. 142−147 [12] Wang C, Bai X, Zhou L. Hyperspectral image classification based on non-local neural networks. In: Proceedings of the International Geoscience and Remote Sensing Symposium. Yokohama, Japan: IEEE, 2019. 584−587 [13] Zhao H, Jia J, Koltun V. Exploring self-attention for image recognition. In: Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, USA: IEEE, 2020. 10073−10082 [14] Ramachandran P, Parmar N, Vaswani A. Stand-alone self-attention in vision models. In: Proceedings of the Advances in Neural Information Processing Systems. Vancouver, Canada: NeurIPS, 2019. [15] Carion N, Massa F, Synnaeve G. End-to-end object detection with transformers. In: Proceedings of the 16th European Conference. Glasgow, UK: ECCV, 2020. 213−229 [16] Dosovitskiy A, Beyer L, Kolesnikov A. An image is worth 16×16 words: Transformers for image recognition at scale. In: Proceedings of the International Conference on Learning Representations. Virtual Event: ICLR, 2021. [17] Chu X, Tian Z, Zhang B. Conditional positional encodings for vision transformers. In: Proceedings of the International Conference on Learning Representations. Virtual Event: ICLR, 2021. [18] Han K, Xiao A, Wu E. Transformer in transformer. Advances in Neural Information Processing Systems. 2021, 34: 15908-15919 [19] Touvron H, Cord M, Douze M. Training data-efficient image transformers distillation through attention. In: Proceedings of the International Conference on Machine Learning. Jeju Island, South Korea: PMLR, 2021. 10347−10357 [20] Yuan L, Chen Y, Wang T. Tokens-to-Token ViT: Training vision transformers from scratch on ImageNet. In: Proceedings of the International Conference on Computer Vision. Montreal, Canada: IEEE, 2021. 558−567 [21] Henaff O. Data-efficient image recognition with contrastive predictive coding. In: Proceedings of International Conference on Machine Learning. Berlin, Germany: PMLR, 2020. 4182−4192 [22] Liu Z, Lin Y, Cao Y. Swin Transformer: Hierarchical vision transformer using shifted windows. In: Proceedings of the International Conference on Computer Vision. Montreal, Canada: IEEE, 2021. 10012−10022 [23] Rao Y, Zhao W, Liu B. Dynamicvit: Efficient vision transformers with dynamic token sparsification. Advances in Neural Information Processing Systems. 2021, 34: 13937-13949 [24] Lin H, Cheng X, Wu X. CAT: Cross attention in visiontransformer. In: Proceedings of the International Conference on Multimedia and Expo. Taipei, China: IEEE, 2022. 1−6 [25] Vaswani A, Ramachandran P, Srinivas A. Scaling local self-attention for parameter efficient visual backbones. In: Proceedings of Conference on Computer Vision and Pattern Recognition (CVPR). Nashville, USA: IEEE, 2021. 12894−12904 [26] Wang W, Chen W, Qiu Q. Crossformer++: A versatile vision transformer hinging on cross-scale attention. arXiv preprint arXiv: 2303.06908, 2023. [27] Huang Z, Ben Y, Luo G. Shuffle transformer: Rethinking spatial shuffle for vision transformer. arXiv preprint arXiv: 2106.03650, 2021. [28] Yu Q, Xia Y, Bai Y. Glance-and-gaze Vision Transformer. Advances in Neural Information Processing Systems.2021, 34: 12992-13003 [29] Wang H, Zhu Y, Green B. Axial-deeplab: Stand-alone axial-attention for panoptic segmentation. In: Proceedings of the 16th European Conference. Glasgow, UK: ECCV, 2020. 108−126 [30] Dong X, Bao J, Chen D. Cswin transformer: A general vision transformer backbone with cross-shaped windows. In: Proceedings of the Conference on Computer Vision and Pattern Recognition. New York, USA: IEEE, 2022. 12124−12134 [31] Wu S, Wu T, Tan H. Pale transformer: A general vision transformer backbone with pale-shaped attention. In: Proceedings of the AAAI Conference on Artificial Intelligence. Washington, USA: 2022. 2731−2739 [32] Wang W, Xie E, Li X. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In: Proceedings of the International Conference on Computer Vision. Montreal, Canada: IEEE, 2021. 568−578 [33] Ren S, He K, Girshick R. Faster r-cnn: Towards real-time object detection with region proposal networks. Advances in Neural Information Processing Systems. 2015, 28 [34] Efraimidis P S, Spirakis P G. Weighted random samplingwith a reservoir. Information Processing Letters, 2006, 97(5): 181-185 doi: 10.1016/j.ipl.2005.11.003 [35] Krizhevsky A, Hinton G. Convolutional beep belief networks on Cifar-10[J]. Unpublished manuscript, 2010, 40(7): 1-9 [36] Geiger A, Lenz P, Stiller C. Vision meets robotics: The kitti dataset. International Journal of Robotics Research (IJRR), 2013 [37] Everingham M, Eslami S M A, Van Gool L. The pascal visual object classes challenge: A retrospective. International Journal of Computer Vision, 2015, 111: 98-136 doi: 10.1007/s11263-014-0733-5 [38] Veit A, Matera T, Neumann L. Coco-text: Dataset and benchmark for text detection and recognition in natural images. arXiv preprint arXiv: 1601.07140, 2016. [39] Selvaraju R R, Cogswell M, Das A. Grad-cam: Visual explanations from deep networks via gradient-based localization. In: Proceedings of the International Conference on Computer Vision. Venice, Italy: IEEE, 2017. 618−626 [40] Chen K, Wang J, Pang J. MMDetection: Open MMLab detection toolbox and benchmark. arXiv preprint arXiv: 1906.07155, 2019. [41] He K, Gkioxari G, Dollár P. Mask R-CNN. In: Proceedings of the International Conference on Computer Vision. Venice, Italy: IEEE, 2017. 2961−2969 [42] Loshchilov I, Hutter F. Decoupled weight decay regularization. arXiv preprint arXiv: 1711.05101, 2017. [43] You Y, Li J, Reddi S. Large batch optimization for deep learning: Training bert in 76 minutes. arXiv preprint arXiv: 1904.00962, 2019. [44] Cai Z, Vasconcelos N. Cascade R-CNN: Delving into high quality object detection. In: Proceedings of the Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 6154−6162 [45] Wu W, Liu H, Li L. Application of local fully Convolutional Neural Network combined with YOLO v5 algorithm in small target detection of remote sensing image. PloS one, 2021, 16(10): 1-10 [46] Bottou, L. Stochastic Gradient descent tricks. Journal of Machine Learning Research. 2017, 18: 1−15 [47] Bochkovskiy A, Wang C Y, Liao H Y M. Yolov4: Optimal speed and accuracy of object detection. arXiv preprint arXiv: 2004.10934, 2020. -

 下载:
下载:


计量
- 文章访问数: 1411
- HTML全文浏览量: 837
- PDF下载量: 260
- 被引次数: 0
