

-
摘要: 以德州扑克游戏为代表的大规模不完美信息博弈是现实世界中常见的一种博弈类型. 现有以求解纳什均衡策略为目标的主流德州扑克求解算法存在依赖博弈树模型、算力消耗大、策略过于保守等问题, 导致智能体在面对不同对手时无法最大化自身收益. 为解决上述问题, 提出一种轻量高效且能快速适应对手策略变化进而剥削对手的不完美信息博弈求解框架. 本框架分为智能体离线训练和在线博弈两个阶段. 第1阶段基于演化学习思想训练智能体, 得到能够剥削不同博弈风格对手的策略神经网络. 在第2博弈阶段中, 智能体在线建模并适应未知风格对手, 利用种群策略集成的方法最大化剥削对手. 在两人无限注德州扑克环境中的实验结果表明, 本框架在面对动态对手策略时, 相比已有方法能够大幅提升博弈性能.Abstract: Texas Hold'em is a typical large-scale imperfect information game in the real world. Existing algorithms computing Nash equilibriums in the Texas Hold'em have severe problems, including the heavy dependency on the game's abstract model, the considerable resource consumption, and the learned strategy's conservatism prevents it from maximizing the payoffs when facing different opponents. To alleviate these problems, we propose a light-weight and efficient framework for imperfect information that can quickly adapt to new opponents/strategies. It consists of two stages: The offline training stage and the online game stage. Based on the evolutionary theory, we train policy networks to exploit opponents with distinct styles in the training stage. While during the game stage, the agent first models the unknown opponent and then weighs the trained policies to integrate an adaptive strategy, which maximizes the exploitation of the opponent. Experimental results in heads-up no-limit Texas Hold'em show the superiority of the proposed framework. Strategy obtained by this framework significantly outperforms the existing methods when facing dynamic opponents.1) 1
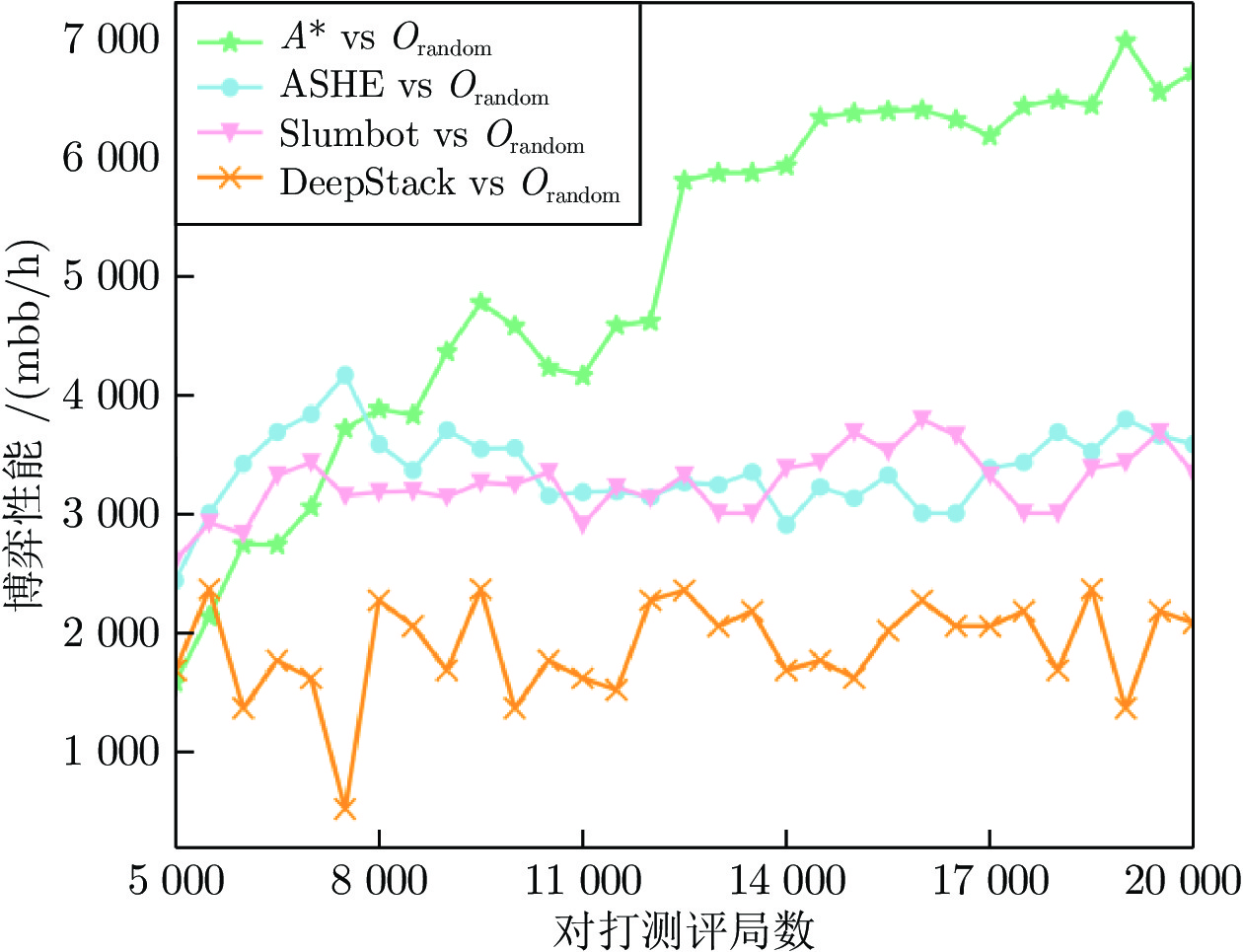
http://www.slumbot.com/ -
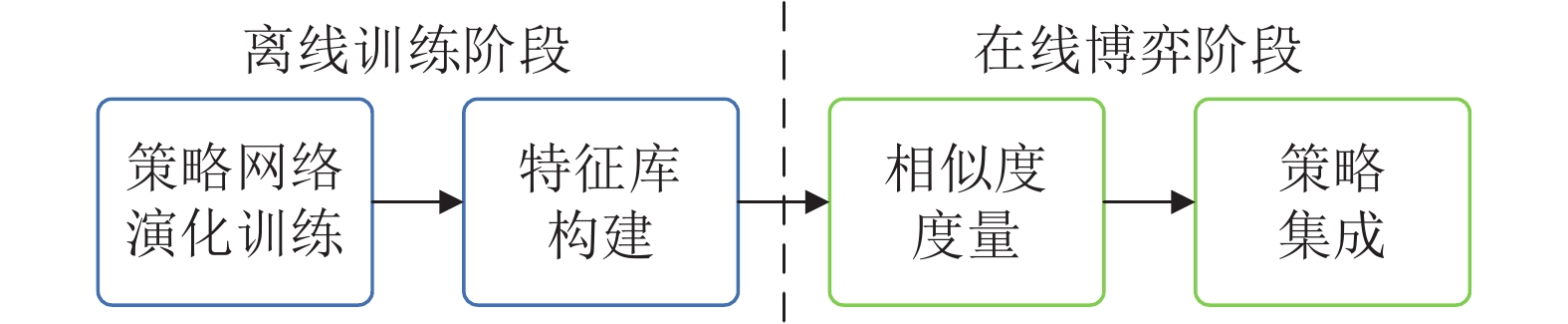
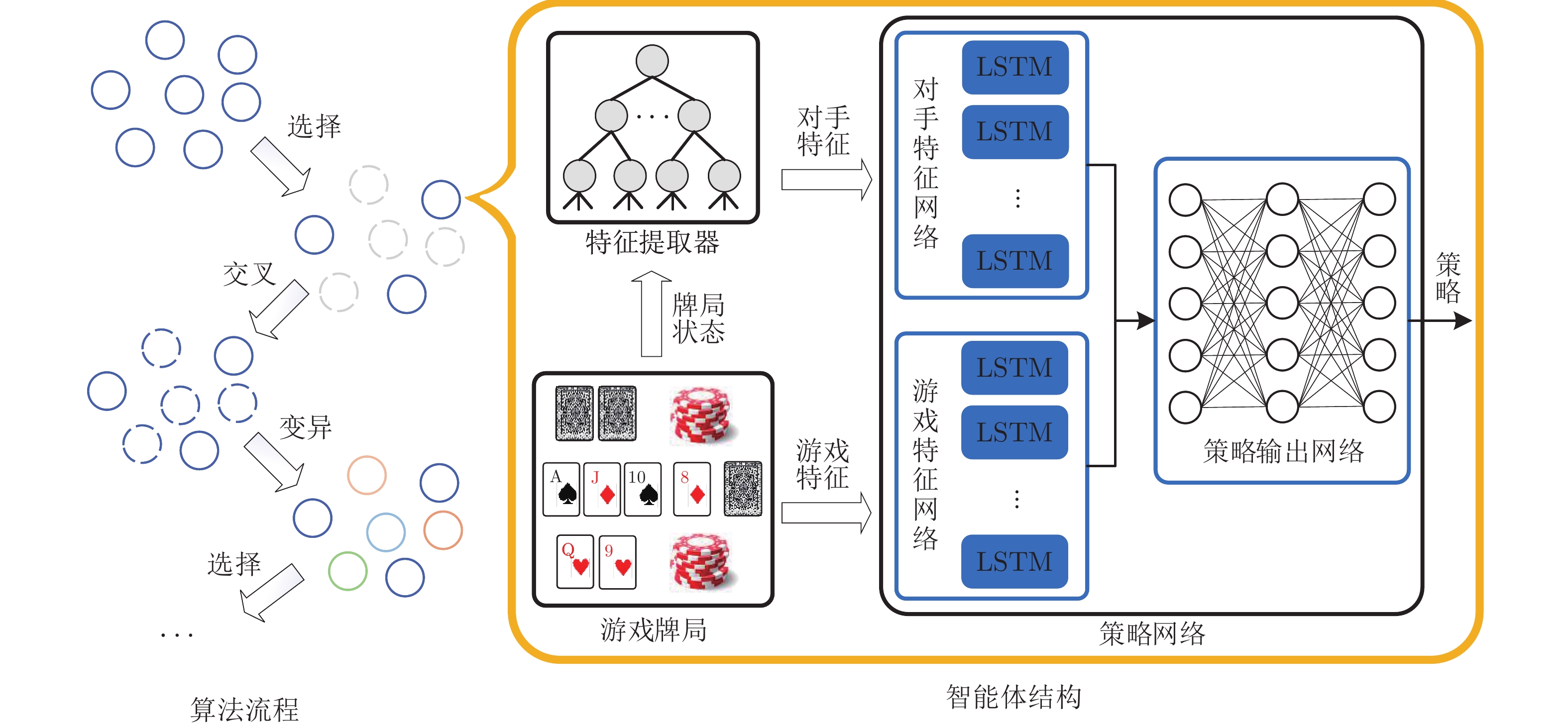
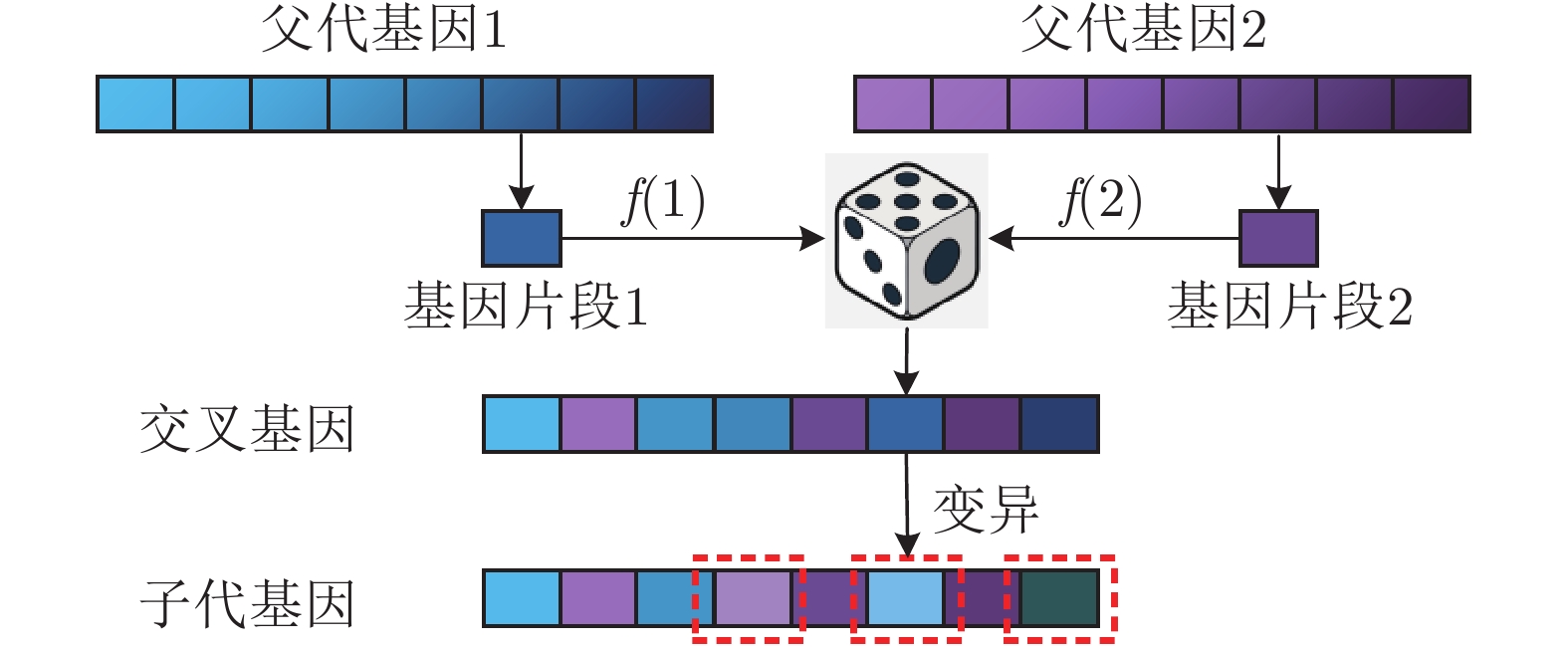
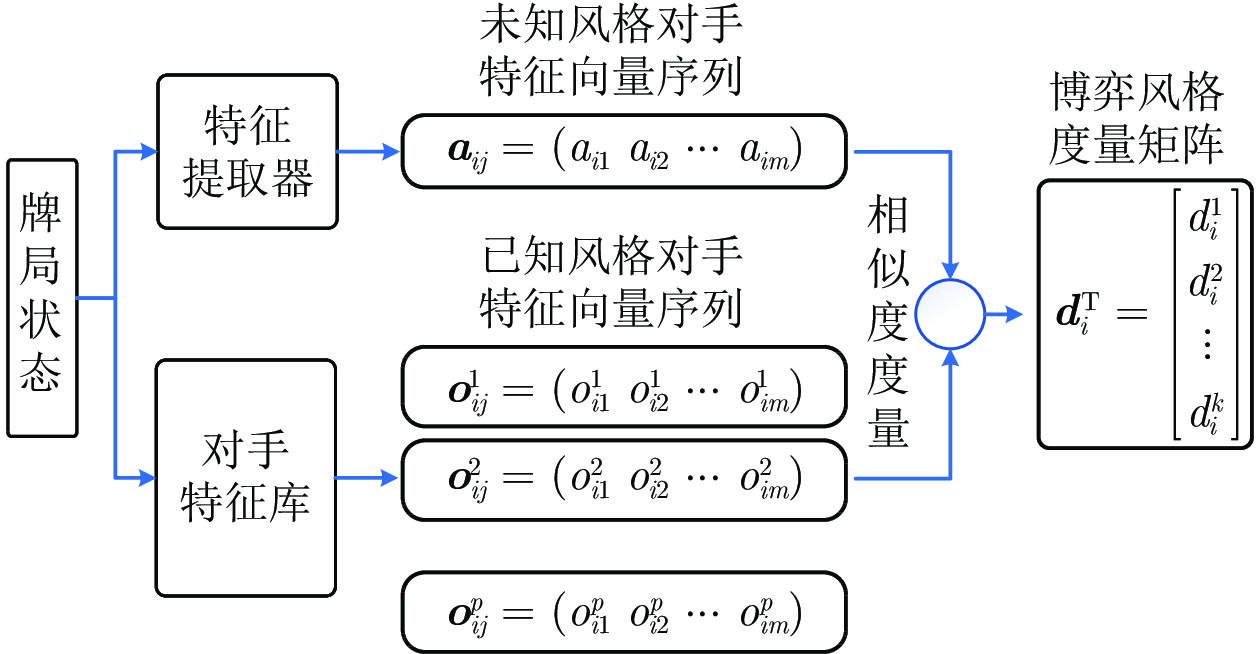
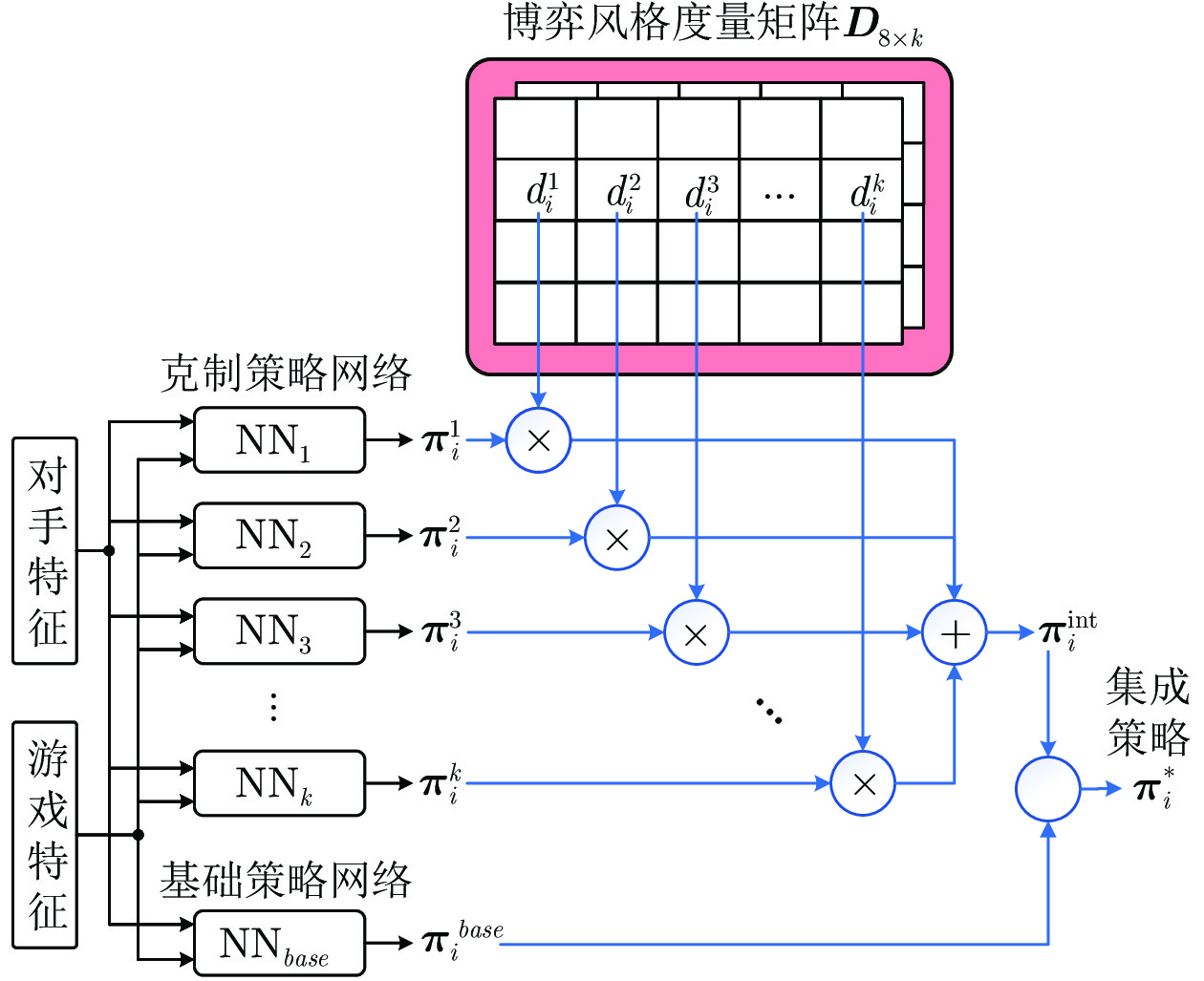
图 2 不完美信息博弈求解框架整体流程
Fig. 2 Overall process of the imperfect information game solving framework
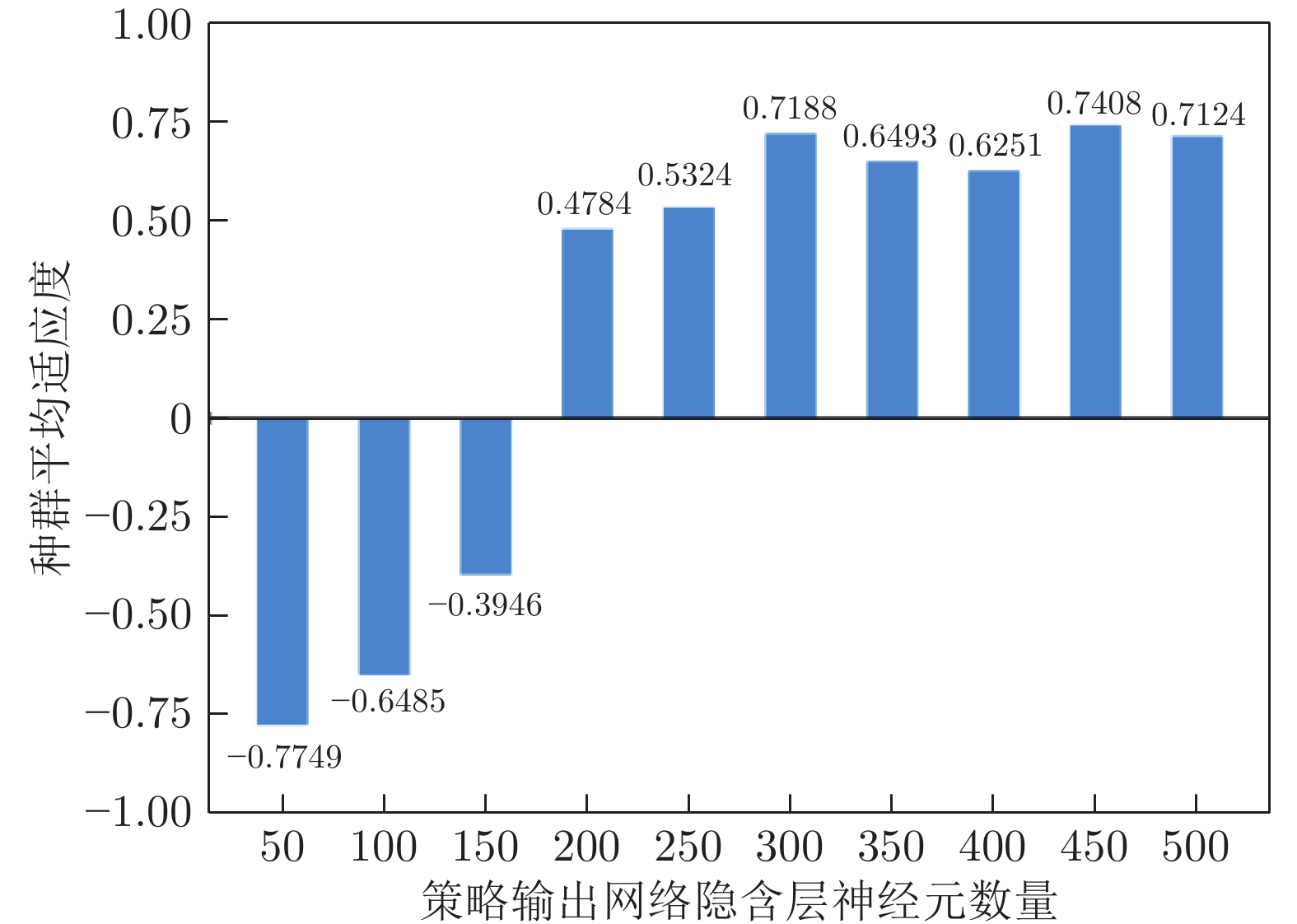
图 8 策略输出网络隐含层神经元数量对种群平均适应度的影响
Fig. 8 The influence of the hidden neurons in policy output network on population fitness
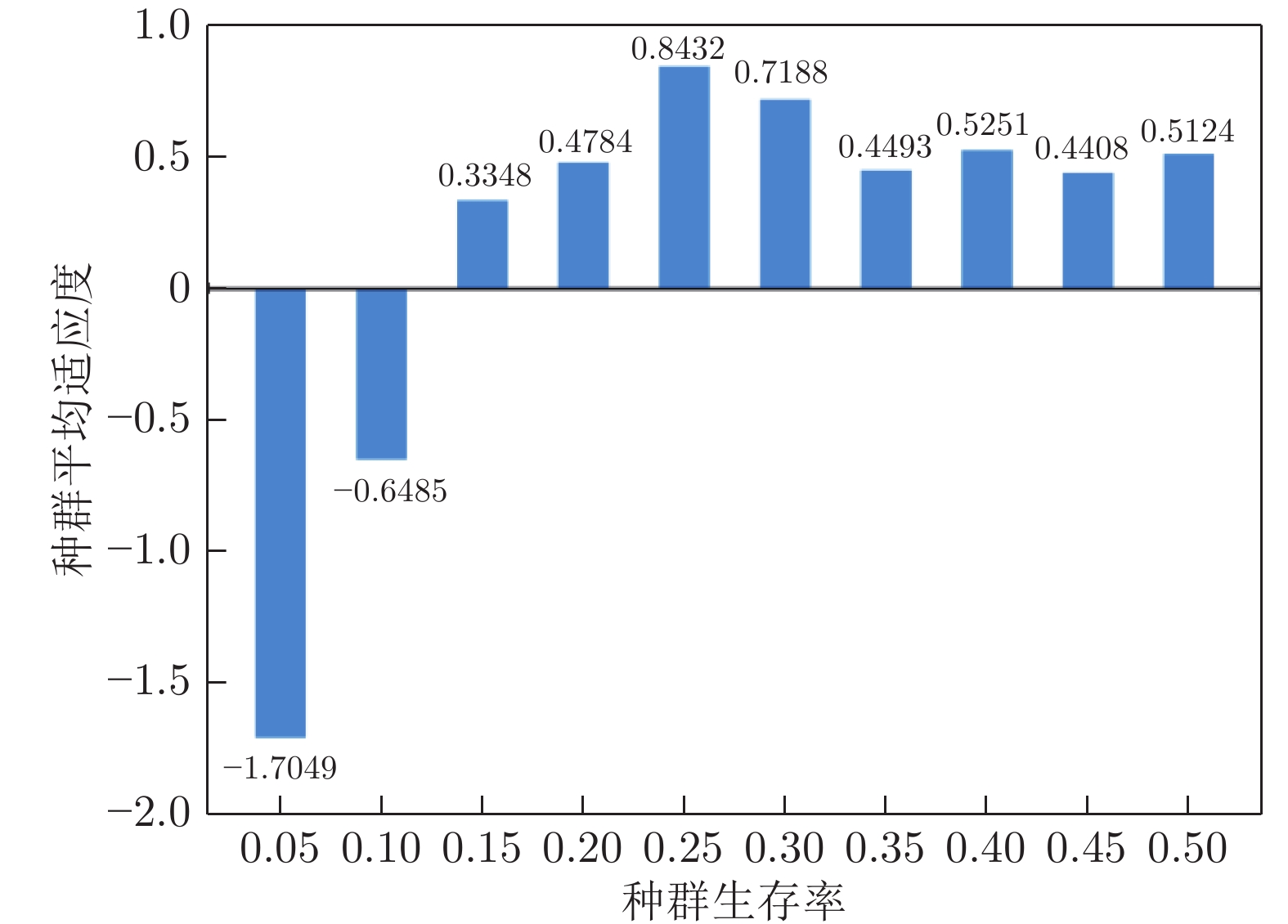
图 9 种群生存率对种群平均适应度的影响
Fig. 9 The influence of population survival rates on population average fitness
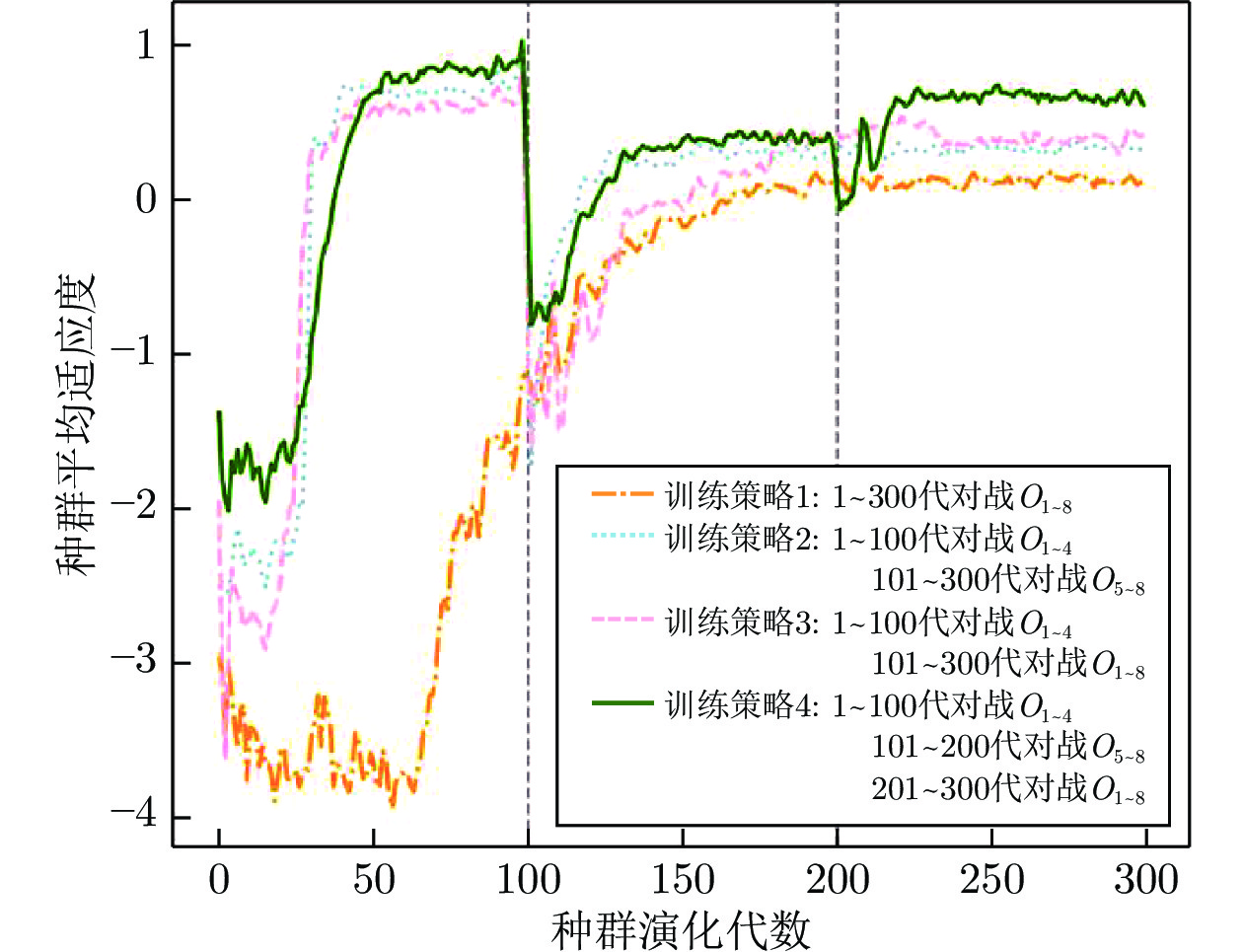
图 10 不同训练策略对种群平均适应度的影响
Fig. 10 The influence of different training strategies on population average fitness
表 1 对手智能体博弈风格及定义
Table 1 The opponents'play styles and definitions
名称 类型 手牌松紧度 策略激进度 ${O_{\rm{1}}}$ 松−弱 70 % 极度保守 ${O_2}$ 松−凶 70 % 极度激进 ${O_3}$ 紧−弱 10 % 极度保守 ${O_4}$ 紧−凶 10 % 极度激进 ${O_5}$ 松−弱 50 % 相对保守 ${O_6}$ 松−凶 50 % 相对激进 ${O_7}$ 紧−弱 30 % 相对保守 ${O_8}$ 紧−凶 30 % 相对激进  下载: 导出CSV
下载: 导出CSV
表 2 策略网络结构与训练参数
Table 2 Policy network structure and the training hyper-parameters
参数含义 参数值 对手特征网络LSTM区块数 5 对手特征网络LSTM时间序列步数 5 对手特征网络输出维度 200 游戏特征网络LSTM区块数 5 游戏特征网络LSTM时间序列步数 5 游戏特征网络输出维度 300 策略输出网络输入层神经元数量 500 策略输出网络隐含层数量 2 策略输出网络隐含层神经元数量 300 策略输出网络输出层神经元数量 10 种群演化代数 300 种群个体规模 100 种群生存率 0.25 基因变异率(初始/最终) 0.25/0.05 基因变异强度(初始/最终) 0.5/0.1 单个对手对打训练牌局数量 10000 对手特征库收集游戏对打局数 100000
下载: 导出CSV
表 3 消融实验结果(mbb/h)
Table 3 Ablation study results (mbb/h)
智能体\对手 ${O_{\rm{1}}}$ ${O_2}$ ${O_3}$ ${O_4}$ ${O_5}$ ${O_6}$ ${O_7}$ ${O_8}$ ${O_{random}}$ Slumbot 702.53 12761 4942.58 14983 652.73 2623.14 484.29 2449.08 3387.13 ${A_{tar}}$ 999.92 29232 1494.92 27474 1391.04 12746 1371.10 34546 — ${A_{base}}$ 1000.00 22611 1205.05 20380 1109.84 9892.43 793.42 14568 5105.38 ${A_{ave}}$ 999.91 78.46 34.06 −5537.19 927.84 92.36 −631.55 −4461.82 −1068.44 ${A_{\rm{int} }}$ 999.92 29964 1305.04 27314 1316.21 12874 1380.88 18330 2738.98 ${A^*}$ 1000.00 24888 1310.34 27526 1286.08 11253 1020.38 16514 6359.36
下载: 导出CSV
表 4 博弈性能对比结果(mbb/h)
Table 4 Performance comparison results (mbb/h)
智能体 ${A^*}$ ASHE Slumbot Deepstack NFSP 知识AI ${O_{random}}$ ${A^*}$ — 675.68 −48.49 −896.76 32255 229.64 6359.36 ASHE −675.68 — −153.35 −1552.64 11904 −13.00 3177.68 Slumbot 48.49 153.35 — −103.44 8623.18 52.43 3387.13 DeepStack 896.76 1552.64 103.44 — 4084.27 139.41 1791.27 NFSP −32255 −11904 −8623.18 −4084.27 — −3257.75 −18819 知识AI −229.64 13.00 −52.43 −139.41 3257.75 — −91.92 ${O_{random}}$ −6859.36 −3177.68 −3387.13 −1791.27 18819 91.92 —
下载: 导出CSV
表 5 算法轻量性对比
Table 5 Light-weight comparison
智能体 训练阶段资源需求 测评阶段资源需求 存储资源(GB) 计算资源(h) 存储资源(GB) 计算资源(h) 响应时间(s) ${A^*}$ ~30 ~2×103 CPU <0.5 <0.1 CPU <0.1 ASHE ~30 ~103 CPU ~30 <0.1 CPU <0.1 Slumbot >500 >105 CPU >500 >10 CPU ~1 DeepStack >500 >106 CPU
>103 GPU>10 ~103 CPU
~103 GPU~30 NFSP >50 ~104 CPU
~102 GPU~1 <1 CPU
<1 GPU<1 人类玩家 — — — — ~15
下载: 导出CSV
-
[1] Pomerol J C. Artificial intelligence and human decision making. European Journal of Operational Research, 1997, 99(1): 3−25 doi: 10.1016/S0377-2217(96)00378-5 [2] LeCun Y, Bengio Y, Hinton G. Deep learning. Nature, 2015, 521(7553): 436−444 doi: 10.1038/nature14539 [3] 罗浩, 姜伟, 范星, 张思朋. 基于深度学习的行人重识别研究进展. 自动化学报, 2019, 45(11): 2032−2049LUO Hao, JIANG Wei, FAN Xing, ZHANG Si-Peng. A survey on deep learning based person re-identification. Acta Automatica Sinica, 2019, 45(11): 2032−2049 [4] Xiong W, Droppo J, Huang X, Seide F, Seltzer M, Stolcke A, et al. Achieving human parity in conversational speech recognition. arXiv preprint, arXiv: 1610.05256, 2016 [5] He K, Zhang X, Ren S, Sun J. Deep residual learning for image recognition. In: Proceedings of the 29th IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA: IEEE Press, 2016. 770−778 [6] Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez A N, et al. Attention is all you need. In: Proceedings of the 31st Annual Conference on Neural Information Processing Systems. Long Beach, USA: MIT Press, 2017. 5998−6008 [7] 奚雪峰, 周国栋. 面向自然语言处理的深度学习研究. 自动化学报, 2016, 42(10): 1445−1465XI Xue-Feng, ZHOU Guo-Dong. A survey on deep learning for natural language processing. Acta Automatica Sinica, 2016, 42(10): 1445−1465 [8] Mnih V, Kavukcuoglu K, Silver D, Rusu A A, Veness J, Bellemare M G, et al. Human-level control through deep reinforcement learning. Nature, 2015, 518(7540): 529−533 doi: 10.1038/nature14236 [9] 赵冬斌, 邵坤, 朱圆恒, 李栋, 陈亚冉, 王海涛, 等. 深度强化学习综述: 兼论计算机围棋的发展. 控制理论与应用, 2016, 33(6): 701−717 doi: 10.7641/CTA.2016.60173Zhao Dong-Bin, Shao Kun, Zhu Yuan-Heng, Li Dong, Chen Ya-Ran, Wang Hai-Tao, et al. Review of deep reinforcement learning and discussions on the development of computer go. Control Theory and Applications, 2016, 33(6): 701−717 doi: 10.7641/CTA.2016.60173 [10] 梁星星, 冯旸赫, 马扬, 程光权, 黄金才, 王琦, 等. 多Agent深度强化学习综述. 自动化学报, 2020, 46(12): 2537−2557Liang Xing-Xing, Feng Yang-He, Ma Yang, Cheng Guang-Quan, Huang Jin-Cai, Wang Qi, et al. Deep multi-agent reinforcement learning: a survey. Acta Automatica Sinica, 2020, 46(12): 2537−2557 [11] Silver D, Huang A, Maddison C J, Guez A, Sifre L, Van Den Driessche G, et al. Mastering the game of go with deep neural networks and tree search. Nature, 2016, 51(7587): 484−489 [12] Silver D, Schrittwieser J, Simonyan K, Antonoglou I, Huang A, Guez A, et al. Mastering the game of go without human knowledge. Nature, 2017, 550(7676): 354−359 doi: 10.1038/nature24270 [13] Silver D, Hubert T, Schrittwieser J, Antonoglou I, Lai M, Guez A, et al. A general reinforcement learning algorithm that Masters chess, shogi, and go through self-play. Science, 2018, 362(6419): 1140−1144 doi: 10.1126/science.aar6404 [14] Schrittwieser J, Antonoglou I, Hubert T, Simonyan K, Sifre L, Schmitt S, et al. Mastering atari, go, chess and shogi by planning with a learned model. Nature, 2020, 588(7839): 604−609 doi: 10.1038/s41586-020-03051-4 [15] 周志华. AlphaGo专题介绍. 自动化学报, 2016, 42(5): 670−670Zhou Zhi-Hua. AlphaGo special session: an introduction. Acta Automatica Sinica, 2016, 42(5): 670−670 [16] Rhalibi A, Wong K W. Artificial intelligence for computer games: an Introduction. International Journal of Computer Games Technology. 2009, 12(3): 351−369 [17] 沈宇, 韩金朋, 李灵犀, 王飞跃. 游戏智能中的AI——从多角色博弈到平行博弈. 智能科学与技术学报, 2020, 2(3): 205−213SHEN Yu, HAN Jin-Peng, LI Ling-Xi, Wang Fei-Yue. AI in game intelligence—from multi-role game to parallel game. Chinese Journal of Intelligent Science and Technology, 2020, 2(3): 205−213 [18] Myerson R B. Game Theory. London: Harvard university press, 2013. 74−82 [19] Brown N, Sandholm T. Superhuman AI for heads-up no-limit poker: libratus beats top professionals. Science, 2018, 359(6374): 418−424 doi: 10.1126/science.aao1733 [20] Brown N, Sandholm T. Superhuman AI for multiplayer poker. Science, 2019, 365(6456): 885−890 doi: 10.1126/science.aay2400 [21] Li J, Koyamada S, Ye Q, Liu G, Wang C, Yang R, et al. Suphx: mastering mahjong with deep reinforcement learning. arXiv preprint, arXiv: 2003.13590, 2020 [22] Jiang Q, Li K, Du B, Chen H, Fang H. DeltaDou: expert-level doudizhu AI through self-play. In: Proceedings of the 28th International Joint Conference on Artificial Intelligence, Macao, China: Morgan Kaufmann, 2019. 1265−1271 [23] Zhou Z H, Yu Y, Qian C. Evolutionary Learning: Advances In Theories and Algorithms. Singapore: Springer-Verlag, 2019. 4−6 [24] Darse B, Aaron D, Jonathan S, Szafron D. The challenge of poker. Artificial Intelligence, 2002, 134(1-2): 201−240 doi: 10.1016/S0004-3702(01)00130-8 [25] Jackson E G. Slumbot N L. Solving large games with counterfactual regret minimization using sampling and distributed processing. In: Proceedings of Workshops at the 27th AAAI Conference on Artificial Intelligence, Bellevue, Washington, USA: AAAI, 2013. 35−38 [26] Zinkevich M, Johanson M, Bowling M, Piccione C. Regret minimization in games with incomplete information. In: Proceedings of the 21st Annual Conference on Neural Information Processing Systems. British Columbia, Canada: MIT Press, 2007. 1729−1736 [27] Waugh K, Schnizlein D, Bowling M H, Szafron D. Abstraction pathologies in extensive games. In: Proceedings of the 8th International Conference on Autonomous Agents and Multiagent Systems, Budapest, Hungary: Springer-Verlag, 2009. 781−788 [28] Lanctot M, Waugh K, Zinkevich M, Bowling M H. Monte Carlo sampling for regret minimization in extensive games. In: Proceedings of the 23rd Annual Conference on Neural Information Processing Systems. Whistler, Canada: MIT Press, 2009. 1078−1086 [29] Moravčík M, Schmid M, Burch N, Lisý V, Morrill D, Bard N, et al. Deepstack: expert-level artificial intelligence in heads-up no-limit poker. Science, 2017, 356(6337): 508−513 doi: 10.1126/science.aam6960 [30] Bowling M, Burch N, Johanson M, Tammelin O. Heads-up limit hold’em poker is solved. Science, 2015, 347(6218): 145−149 doi: 10.1126/science.1259433 [31] Heinrich J, Silver D. Deep reinforcement learning from self-play in imperfect-information games. arXiv preprint, arXiv: 1603.01121, 2016. [32] 孙长银, 穆朝絮. 多智能体深度强化学习的若干关键科学问题. 自动化学报, 2020, 46(7): 1301−1312Sun Chang-Yin, Mu Chao-Xu. Important scientific problems of multi-agent deep reinforcement learning. Acta Automatica Sinica, 2020, 46(7): 1301−1312 [33] 郭潇逍, 李程, 梅俏竹. 深度学习在游戏中的应用. 自动化学报, 2016, 42(5): 676−684GUO Xiao-Xiao, LI Cheng, MEI Qiao-Zhu. Deep Learning Applied to Games. Acta Automatica Sinica, 2016, 42(5): 676−684 [34] Li X, Miikkulainen R. Opponent modeling and exploitation in poker using evolved recurrent neural networks. In: Proceedings of the 27th Genetic and Evolutionary Computation Conference, Kyoto, Japan: ACM Press, 2018. 189−196 -

 下载:
下载:


计量
- 文章访问数: 5652
- HTML全文浏览量: 2986
- PDF下载量: 483
- 被引次数: 0
