

English Lexical Simplification Based on Pretrained Language Representation Modeling
-
摘要: 词语简化是将给定句子中的复杂词替换成意义相等的简单替代词,从而达到简化句子的目的. 已有的词语简化方法只依靠复杂词本身而不考虑其上下文信息来生成候选替换词, 这将不可避免地产生大量的虚假候选词. 为此, 提出了一种基于预语言训练表示模型的词语简化方法, 利用预训练语言表示模进行候选替换词的生成和排序. 基于预语言训练表示模型的词语简化方法在候选词生成过程中, 不仅不需要任何语义词典和平行语料, 而且能够充分考虑复杂词本身和上下文信息产生候选替代词. 在候选替代词排序过程中, 基于预语言训练表示模型的词语简化方法采用了5个高效的特征, 除了常用的词频和词语之间相似度特征之外, 还利用了预训练语言表示模的预测排名、基于基于预语言训练表示模型的上、下文产生概率和复述数据库PPDB三个新特征. 通过3个基准数据集进行验证, 基于预语言训练表示模型的词语简化方法取得了明显的进步, 整体性能平均比最先进的方法准确率高出29.8%.Abstract: Lexical simplification (LS) aims to replace complex words in a given sentence with their simpler alternatives of equivalent meaning, so as to simplify the sentence. Recently unsupervised lexical simplification approaches only rely on the complex word itself regardless of the given sentence to generate candidate substitutions, which will inevitably produce a large number of spurious candidates. Therefore, we present a lexical simplification approach BERT-LS based on pretrained representation model BERT, which exploits BERT to generate substitute candidates and rank candidates. In the step of substitute generation, BERT-LS not only does not rely on any linguistic database and parallel corpus, but also fully considers both the given sentence and the complex word during generating candidate substitutions. In the step of substitute ranking, BERT-LS employs five efficient features, including BERT's prediction ranking, BERT-based language model and the paraphrase database PPDB, in addition to the word frequency and word similarity commonly used in other LS methods. Experimental results show that our approach obtains obvious improvement compared with these baselines, outperforming the state-of-the-art by 29.8 Accuracy points on three well-known benchmarks.
-

图 2 BERT-LS使用BERT模型生成候选词, 其中输入为“the cat perched on the mat”
Fig. 2 BERT-LS uses the BERT model to generate candidate words, and the input is “the cat perched on the mat”
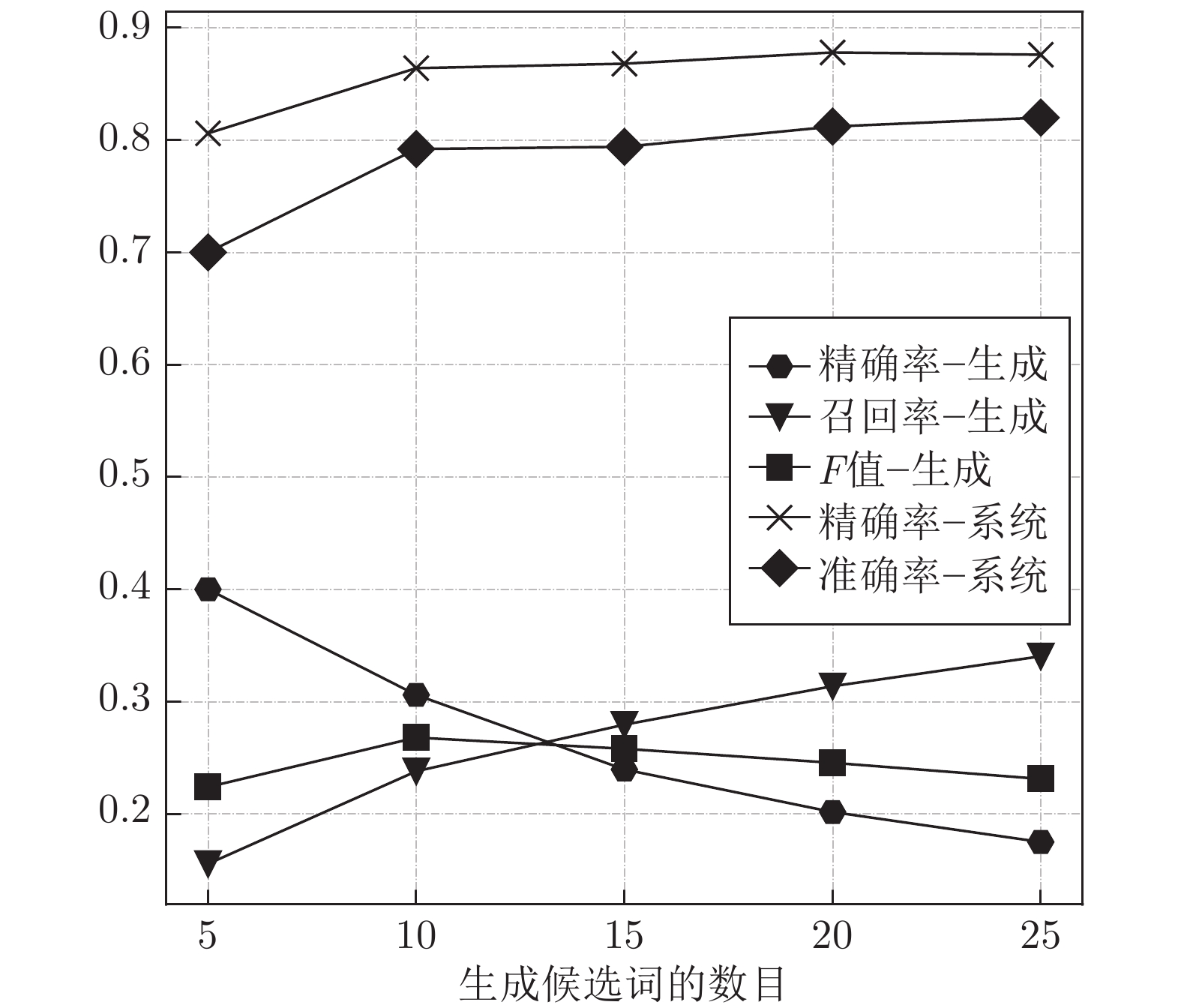
图 5 不同生成候选词数量的评估结果
Fig. 5 Evaluation results of different number of candidate words generated
表 1 候选词生成过程评估结果
Table 1 Evaluation results of candidate word generation process
方法 LexMTurk BenchLS NNSeval 精确率 召回率 F值 精确率 召回率 F值 精确率 召回率 F值 Yamamoto 0.056 0.079 0.065 0.032 0.087 0.047 0.026 0.061 0.037 Biran 0.153 0.098 0.119 0.130 0.144 0.136 0.084 0.079 0.081 Devlin 0.164 0.092 0.118 0.133 0.153 0.143 0.092 0.093 0.092 Horn 0.153 0.134 0.143 0.235 0.131 0.168 0.134 0.088 0.106 Glavaš 0.151 0.122 0.135 0.142 0.191 0.163 0.105 0.141 0.121 PaetzoldCA 0.177 0.140 0.156 0.180 0.252 0.210 0.118 0.161 0.136 PaetzoldNE 0.310 0.142 0.195 0.270 0.209 0.236 0.186 0.136 0.157 Rec-LS 0.151 0.154 0.152 0.129 0.246 0.170 0.103 0.155 0.124 BERT-Single 0.253 0.197 0.221 0.176 0.239 0.203 0.138 0.185 0.158 BERT-LS 0.306 0.238 0.268 0.244 0.331 0.281 0.194 0.260 0.222  下载: 导出CSV
下载: 导出CSV
表 2 整个简化系统评估结果
Table 2 Evaluation results of the whole simplified system
方法 LexMTurk BenchLS NNSeval 精确率 准确率 精确率 准确率 精确率 准确率 Yamamoto 0.066 0.066 0.044 0.041 0.444 0.025 Biran 0.714 0.034 0.124 0.123 0.121 0.121 Devlin 0.368 0.366 0.309 0.307 0.335 0.117 PaetzoldCA 0.578 0.396 0.423 0.423 0.297 0.297 Horn 0.761 0.663 0.546 0.341 0.364 0.172 Glavaš 0.710 0.682 0.480 0.252 0.456 0.197 PaetzoldNE 0.676 0.676 0.642 0.434 0.544 0.335 Rec-LS 0.784 0.256 0.734 0.335 0.665 0.218 BERT-Single 0.694 0.652 0.495 0.461 0.314 0.285 BERT-LS 0.864 0.792 0.697 0.616 0.526 0.436
下载: 导出CSV
表 3 不同特征对候选词排序的影响
Table 3 The influence of different features on the ranking of candidates
方法 LexMTurk BenchLS NNSeval 平均值 精确率 准确率 精确率 准确率 精确率 准确率 精确率 准确率 BERT-LS 0.864 0.792 0.697 0.616 0.526 0.436 0.696 0.615 仅用 BERT 预测排名 0.772 0.608 0.695 0.502 0.531 0.343 0.666 0.484 去除 BERT 预测排名 0.834 0.778 0.678 0.623 0.473 0.423 0.662 0.608 去除上下文产生概率 0.838 0.760 0.706 0.614 0.515 0.406 0.686 0.593 去除相似度 0.818 0.766 0.651 0.604 0.473 0.418 0.647 0.596 去除词频 0.806 0.670 0.709 0.550 0.556 0.397 0.691 0.539 去除 PPDB 0.840 0.774 0.682 0.612 0.515 0.431 0.679 0.606
下载: 导出CSV
表 4 使用不同的BERT模型的评估结果
Table 4 Evaluation results using different BERT models
数据集 模型 候选词生成评估 完整系统评估 精确率 召回率 F值 精确率 准确率 LexMTurk Base 0.317 0.246 0.277 0.746 0.700 Large 0.334 0.259 0.292 0.786 0.742 全词掩码 0.306 0.238 0.268 0.864 0.792 BenchLS Base 0.233 0.317 0.269 0.586 0.537 Large 0.252 0.342 0.290 0.636 0.589 全词掩码 0.244 0.331 0.281 0.697 0.616 NNSeval Base 0.172 0.230 0.197 0.393 0.347 Large 0.185 0.247 0.211 0.402 0.360 全词掩码 0.194 0.260 0.222 0.526 0.436
下载: 导出CSV
表 5 LexMTurk数据集中的简化句例
Table 5 Simplified sentences in LexMTurk
句子 原句; 标签; 生成词; 最终 句 1 Much of the water carried by these streams is diverted; Changed, turned, moved, rerouted, separated, split, altered, veered, …; transferred, directed, discarded, converted, derived; transferred 句 2 Following the death of Schidlof from a heart attack in 1987, the Amadeus Quartet disbanded; dissolved, scattered, quit, separated, died, ended, stopped, split; formed, retired, ceased, folded, reformed, resigned, collapsed, closed, terminated; formed 句 3 …, apart from the efficacious or prevenient grace of God, is utterly unable to…; ever, present, showy, useful, effective, capable, strong, valuable, powerful, active, efficient, …; irresistible, inspired, inspiring, extraordinary, energetic, inspirational; irresistible 句 4 …, resembles the mid-19th century Crystal Palace in London; mimics, represents, matches, shows, mirrors, echos, favors, match; suggests, appears, follows, echoes, references, features, reflects, approaches; suggests 句 5 …who first demonstrated the practical application of electromagnetic waves,…; showed, shown, performed, displayed; suggested, realized, discovered, observed, proved, witnessed, sustained; suggested 句 6 …a well-defined low and strong wind gusts in squalls as the system tracked into…; followed, traveled, looked, moved, entered, steered, went, directed, trailed, traced…; rolled, ran, continued, fed, raced, stalked, slid, approached, slowed; rolled 句 7 …is one in which part of the kinetic energy is changed to some other form of energy…; active, moving, movement, motion, static, motive, innate, kinetic, real, strong, driving…; mechanical, total, dynamic, physical, the, momentum, velocity, ballistic; mechanical 句 8 None of your watched items were edited in the time period displayed; changed, refined, revise, finished, fixed, revised, revised, scanned, shortened; altered, modified, organized, incorporated, appropriate; altered
下载: 导出CSV
表 6 LexMTurk数据集中的简化句例
Table 6 Simplified sentences in LexMTurk
句子 原句; 标签; 生成词; 最终 句 1 Triangles can also be classified according to their internal angles, measured here in degrees; grouped, categorized, arranged, labeled, divided, organized, separated, defined, described …; divided, described, separated, designated; classified 句 2 …; he retained the conductorship of the Vienna Philharmonic until 1927; kept, held, had, got maintained, held, kept, remained, continued, shared; maintained 句 3 …, and a Venetian in Paris in 1528 also reported that she was said to be beautiful; said, told, stated, wrote, declared, indicated, noted, claimed, announced, mentioned; noted, confirmed, described, claimed, recorded, said; reported 句 4 …, the king will rarely play an active role in the development of an offensive or ….; infrequently, hardly, uncommonly, barely, seldom, unlikely, sometimes, not, seldomly…; never, usually, seldom, not, barely, hardly; never
下载: 导出CSV
-
[1] Hirsh D, Nation P. What vocabulary size is needed to read unsimplified texts for pleasure? Reading in a Foreign Language, 1992, 8(2): 689-696 [2] Nation I S P. Learning Vocabulary in Another Language. Cambridge: Cambridge University Press, 2001. [3] De Belder J, Moens M F. Text simplification for children. In: Proceedings of the SIGIR Workshop on Accessible Search Systems. Geneva, Switzerland: ACM, 2010. 19−26 [4] Paetzold G H, Specia L. Unsupervised lexical simplification for non-native speakers. In: Proceedings of the 30th AAAI Conference on Artificial Intelligence. Phoenix, USA: AAAI, 2016. 3761−3767 [5] Feng L J. Automatic readability assessment for people with intellectual disabilities. ACM SIGACCESS Accessibility and Computing, 2009(93): 84-91 doi: 10.1145/1531930.1531940 [6] Saggion H. Automatic text simplification. Synthesis Lectures on Human Language Technologies, 2017, 10(1): 1-137 [7] Devlin S. The use of a psycholinguistic database in the simplification of text for aphasic readers. Linguistic Databases, 1998 [8] Lesk M. Automatic sense disambiguation using machine readable dictionaries: How to tell a pine cone from an ice cream cone. In: Proceedings of the 5th Annual International Conference on Systems Documentation. New York, USA: ACM, 1986. 24−26 [9] Sinha R. UNT-SimpRank: Systems for lexical simplification ranking. In: Proceedings of the 1st Joint Conference on Lexical and Computational Semantics. Montreal, Canada: ACL, 2012. 493−496 [10] Leroy G, Endicott J E, Kauchak D, Mouradi O, Just M. User evaluation of the effects of a text simplification algorithm using term familiarity on perception, understanding, learning, and information retention. Journal of Medical Internet Research, 2013, 15(7): Article No. e144 doi: 10.2196/jmir.2569 [11] Biran O, Brody S, Elhadad N. Putting it simply: A context-aware approach to lexical simplification. In: Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies. Portland, USA: ACL, 2011. 496−501 [12] Yatskar M, Pang B, Danescu-Niculescu-Mizil C, Lee L. For the sake of simplicity: Unsupervised extraction of lexical simplifications from Wikipedia. In: Proceedings of the 2010 Annual Conference of the North American Chapter of the ACL. Los Angeles, USA: ACL, 2010. 365−368 [13] Horn C, Manduca C, Kauchak D. Learning a lexical simplifier using Wikipedia. In: Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics. Baltimore, USA: ACL, 2014. 458−463 [14] Glavaš G, Štajner S. Simplifying lexical simplification: Do we need simplified corpora. In: Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing. Beijing, China: ACL, 2015. 63−68 [15] Paetzold G. Reliable lexical simplification for non-native speakers. In: Proceedings of the 2015 Conference of the North American Chapter of the Association for Computational Linguistics, Student Research Workshop. Denver, UAS: ACL, 2015. 9−16 [16] Paetzold G, Specia L. Lexical simplification with neural ranking. In: Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics. Valencia, Spain: ACL, 2017. 34−40 [17] Devlin J, Chang M W, Lee K, Toutanova K. BERT: Pre-training of deep bidirectional transformers for language understanding. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Minneapolis, USA: ACL, 2019. 4171−4186 [18] Gooding S, Kochmar E. Recursive context-aware lexical simplification. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). Hong Kong, China: ACL, 2019. 4853−4863 [19] Coster W, Kauchak D. Simple English Wikipedia: A new text simplification task. In: Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies. Portland, USA: ACL, 2011. 665−669 [20] Xu W, Napoles C, Pavlick E, Chen Q Z, Callison-Burch C. Optimizing statistical machine translation for text simplification. Transactions of the Association for Computational Linguistics, 2016, 4: 401-415 doi: 10.1162/tacl_a_00107 [21] Nisioi S, Štajner S, Ponzetto S P, Dinu L P. Exploring neural text simplification models. In: Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics. Vancouver, Canada: ACL, 2017. 85−91 [22] Dong Y, Li Z C, Rezagholizadeh M, Cheung J C K. EditNTS: An neural programmer-interpreter model for sentence simplification through explicit editing. In: Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Florence, Italy: ACL, 2019. 3393−3402 [23] Xu W, Callison-Burch C, Napoles C. Problems in current text simplification research: New data can help. Transactions of the Association for Computational Linguistics, 2015, 3: 283-297 doi: 10.1162/tacl_a_00139 [24] Shardlow M. A survey of automated text simplification. International Journal of Advanced Computer Science and Applications, 2014, 4(1): 58−70 [25] Paetzold G H, Specia L. A survey on lexical simplification. Journal of Artificial Intelligence Research, 2017, 60(1): 549-593 [26] Pavlick E, Callison-Burch C. Simple PPDB: A paraphrase database for simplification. In: Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics. Berlin, Germany: ACL, 2016. 143−148 [27] Maddela M, Xu W. A word-complexity lexicon and a neural readability ranking model for lexical simplification. In: Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Brussels, Belgium: ACM, 2018. 3749−3760 [28] Bautista S, León C, Hervás R, Gervás P. Empirical identification of text simplification strategies for reading-impaired people. In: Proceedings of the European Conference for the Advancement of Assistive Technology. Maastricht, Netherland, 2011. 567−574 [29] Lee J, Yoon W, Kim S, Kim D, Kim S, So C H, et al. BioBERT: A pre-trained biomedical language representation model for biomedical text mining. Bioinformatics, 2020, 36(4): 1234-1240 [30] Conneau A, Lample G. Cross-lingual language model pretraining. In: Proceedings of the 33rd Conference on Neural Information Processing Systems (NeurIPS 2019). Vancouver, Canada: NIPC, 2019. [31] Mikolov T, Grave E, Bojanowski P, Puhrsch C, Joulin A. Advances in pre-training distributed word representations. In: Proceedings of the 11th International Conference on Language Resources and Evaluation (LREC 2018). Miyazaki, Japan: LREC, 2018. [32] Brysbaert M, New B. Moving beyond Kučera and Francis: A critical evaluation of current word frequency norms and the introduction of a new and improved word frequency measure for American English. Behavior Research Methods, 2009, 41(4): 977-990 doi: 10.3758/BRM.41.4.977 [33] Ganitkevitch J, Van Durme B, Callison-Burch C. PPDB: The paraphrase database. In: Proceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics. Atlanta, USA: ACL, 2013. 758−764 [34] Little D. The Common european framework of reference for languages: Content, purpose, origin, reception and impact. Language Teaching, 2006, 39(3): 167−90 [35] Gooding S, Kochmar E. Complex word identification as a sequence labelling task. In: Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Florence, Italy: ACL, 2019. 1148−1153 [36] Kajiwara T, Matsumoto H, Yamamoto K. Selecting proper lexical paraphrase for children. In: Proceedings of the 25th Conference on Computational Linguistics and Speech Processing (ROCLING 2013). Kaohsiung, China, 2013. 59−73 -

 下载:
下载:

计量
- 文章访问数: 1016
- HTML全文浏览量: 917
- PDF下载量: 139
- 被引次数: 0
