

-
摘要: 感兴趣区域(Region of interest, ROI) 提取在生物特征识别中, 常用于减少后续处理的计算消耗, 提高识别模型的准确性, 是生物识别系统中预处理的关键步骤. 针对生物识别数据, 提出了一种鲁棒的ROI提取方法. 方法使用语义分割模型作为基础, 通过增加全局感知模块, 与分割模型形成对抗结构, 为模型提供先验知识, 补充全局视觉模式信息, 解决了语义分割模型的末端收敛困难问题, 提高了模型的鲁棒性和泛化能力. 在传统二维(2D)指纹、人脸、三维(3D)指纹和指纹汗孔数据集中验证了方法的有效性. 实验结果表明, 相比于现有方法, 所提出的ROI提取方法更具鲁棒性和泛化能力, 精度最高.Abstract: Region of interest (ROI) extraction is an initial and key step in biometrics since it can not only facilitate more accurate feature extraction but also can reduce the computational cost. This paper proposes a more robust ROI extraction method for biometric image. The method uses semantic segmentation network as the basis. By adding the global perceptual loss module (i.e., adversarial structure) into the loss function of the learning model, prior knowledge is provided to try to make the model know the global pattern information. Furthermore, global perceptual loss module solves the problem of terminal convergence and improve the robustness of the ROI extraction. The effectiveness of the proposed method is validated on the 2D fingerprint, face, 3D fingerprint and sweat pore datasets, respectively. Comparisons with other ROI extraction methods also shows the outstanding performance of the proposed method.
-

图 1 基于PASCAL VOC 2011验证集的分割结果(第1行是以马作为提取目标的案例; 第2行是以飞行器作为提取目标的案例)
Fig. 1 Sample segmentation results on the PASCAL VOC 2011 validation set (The first row shows the ROI extraction result for horse and the second row shows the result for aircraft extraction)
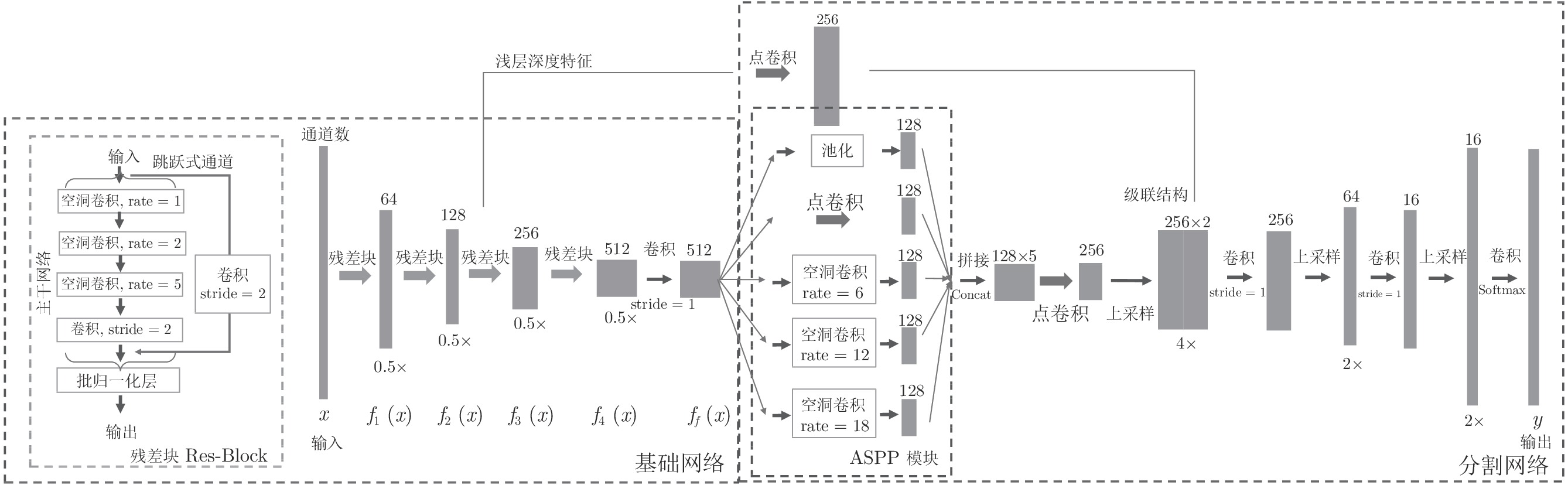
图 3 基于语义分割的ROI提取模型, 模型分为两部分: 基础网络和分割网络
Fig. 3 The flowchart of ROI extraction network based on semantic segmentation

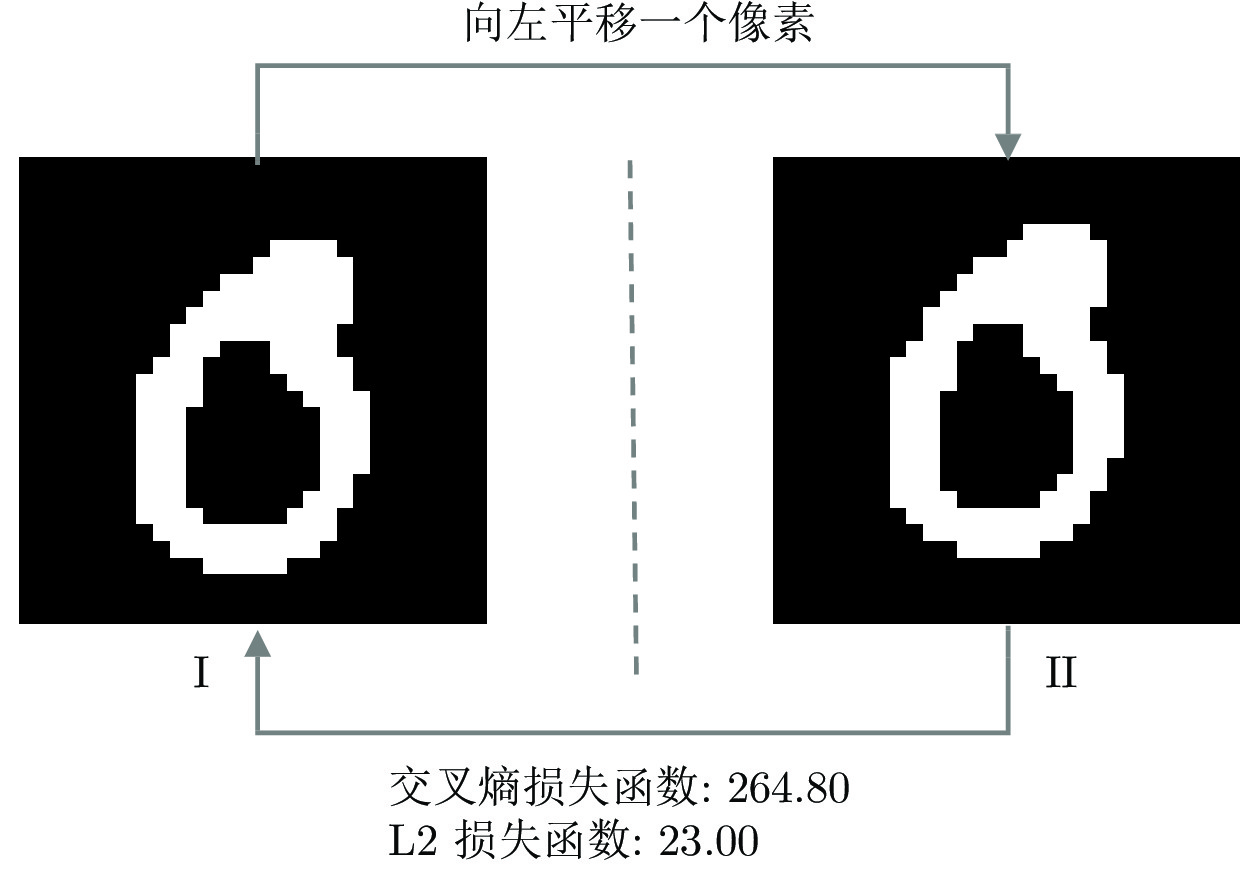
图 5 像素级损失函数的失效情况(分割结果II是分割结果I向左平移一个像素得到, 结果显示两个分割结果的交叉熵为264.80, L2为23.00)
Fig. 5 Failure of pixel level loss functions (Result I translates one pixel to the left to get Result II. Cross entropy between I and II is 264.80 and L2 is 23.00)
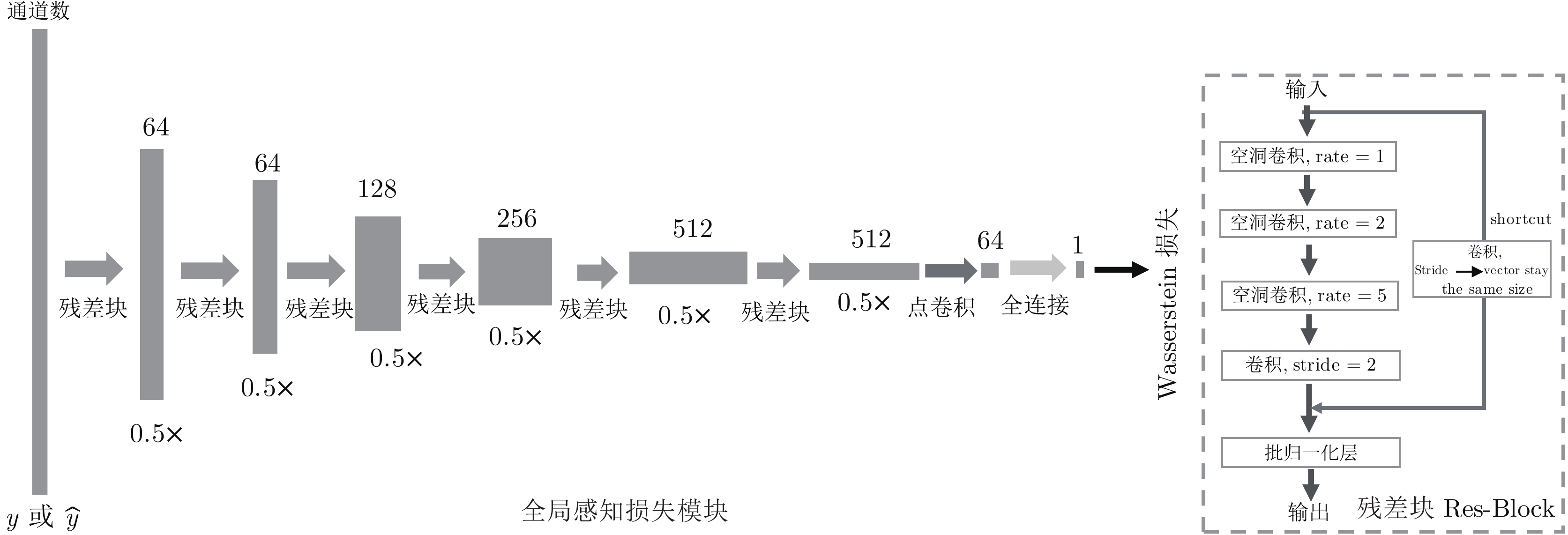
图 6 基于对抗结构的全局损失模块的结构图
Fig. 6 Adversarial structure based global perceptual loss module
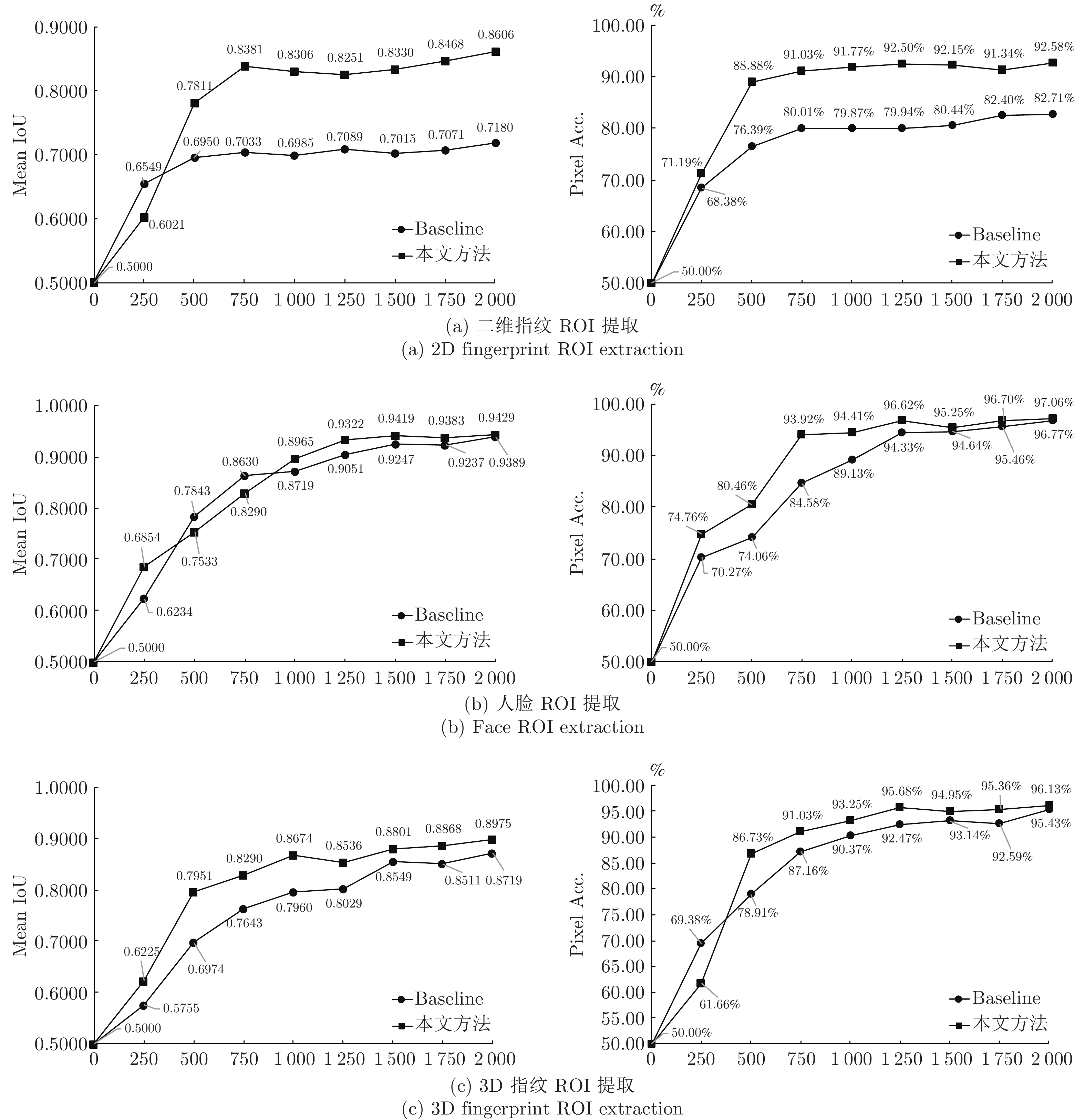
图 9 ROI提取模型的收敛折线图(第1列的评价指标为交并比; 第2列的评价指标为像素级准确率)
Fig. 9 The convergent plots for ROI extraction model (The evaluation metric of the first column is mean IoU, that of the second column is pixel Acc.)

图 10 不同训练次数下的2D指纹、人脸和3D指纹ROI的提取结果(从左至右依次是不同的迭代次数的模型分割结果. 上面一行是Baseline的分割结果, 下面一行是本文方法的分割结果)
Fig. 10 The results for 2D fingerprint, face and 3D fingerprint ROI extraction with different iteration numbers (From left to right, there are the extraction results with different iteration numbers. The upper row corresponds to the extraction results of baseline, and the lower row shows the results of the proposed method)

图 11 人脸ROI提取和2D指纹ROI提取结果
Fig. 11 The results for face ROI extraction and 2D fingerprint ROI extraction

图 12 基于全局感知模块的3D指纹ROI提取结果
Fig. 12 A set of images which show the ROI extraction result of our proposed method for 3D fingerprint

图 13 基于全局感知模块的汗孔提取结果
Fig. 13 The ROI extraction result of our proposed method for pore extraction
表 1 不同设置下的全局感知模块表现
Table 1 Investigation of global perceptual loss module with different settings
优化策略 2D传统指纹(Pixel Acc.(%)/Mean IoU) 人脸(Pixel Acc.(%)/Mean IoU) 3D指纹(Pixel Acc.(%)/Mean IoU) 本文方法 Baseline 本文方法 Baseline 本文方法 Baseline 损失函数 IoU loss[2] 92.07/0.8632 90.66/0.8380 92.05/0.8579 90.03/0.8254 96.97/0.8859 95.18/0.8640 Lovasz loss[25] 92.48/0.8648 93.14/0.8822 97.21/0.9475 96.71/0.9388 95.74/0.8788 95.69/0.8767 L2 loss 93.33/0.8613 89.33/0.8219 96.99/0.9434 96.90/0.9420 95.70/0.8850 94.14/0.8331 CrossEntropy loss (base) 92.58/0.8606 82.71/0.7180 97.06/0.9429 96.77/0.9389 96.13/0.8975 95.43/0.8719 优化器 AMSGrad[29] 93.65/0.8863 92.39/0.8672 96.50/0.9353 96.17/0.9289 93.56/0.8230 90.45/0.7540 Radam[30] 92.72/0.8694 92.27/0.8665 96.72/0.9390 96.52/0.9350 95.77/0.8806 95.19/0.8676 Adam (base)[27] 92.58/0.8606 82.71/0.7180 97.06/0.9429 96.77/0.9389 96.13/0.8975 95.43/0.8719  下载: 导出CSV
下载: 导出CSV
表 2 2D指纹ROI提取实验结果
Table 2 ROI extraction results of 2D fingerprints
方法 FVCs vs. NIST 29
pixel Acc. (%)/Mean IoUNIST 29 vs. FVCs
pixel Acc. (%)/Mean IoU平均值(Average)
pixel Acc. (%)/Mean IoUMean and variance based method[13] 76.71/0.6852 77.23/0.7551 76.97/0.7202 Orientation based method[12] 75.37/0.7532 74.46/0.6213 74.92/0.6873 Fourier based method[13] 65.45/0.6349 65.45/0.6349 65.45/0.6349 PSPNet[17] 87.74/0.8000 79.41/0.7209 83.58/0.7605 FCN[15] 87.20/0.7932 75.77/0.6736 81.49/0.7334 U-Net[16] 85.83/0.7839 76.46/0.7251 81.15/0.7545 Baseline 82.71/0.7180 73.12/0.7341 77.92/0.7261 Baseline+Dense-CRF[48] 90.33/0.7835 78.30/0.7347 84.32/0.7591 本文方法 92.58/0.8606 80.29/0.7469 86.44/0.8038 本文方法+Dense-CRF 94.67/0.8852 82.73/0.7852 88.70/0.8352
下载: 导出CSV
表 5 指纹汗孔提取实验结果
Table 5 Fingerprint pore extraction results
$ R_T$(%) $ R_F$(%) Gabor Filter[44] 75.90 (7.5) 23.00 (8.2) Adapt. Dog[14] 80.80 (6.5) 22.20 (9.0) DAPM[14] 84.80 (4.5) 17.60 (6.3) Xu等[45] 84.80 (4.5) 17.60 (6.3) Labati等[46] 84.69 (7.81) 15.31 (6.2) DeepPore[47] 93.09 (4.63) 8.64 (4.15) DeepPore* 96.33 (6.57) 6.45 (17.22) Baseline 97.48 (9.63) 7.57 (5.85) 本文方法 98.30 (9.2927) 7.83 (4.18)
下载: 导出CSV
-
[1] Caelles S, Maninis K K, Pont-Tuset J, Leal-Taixé L, Cremers D, Van Gool L. One-shot video object segmentation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, USA: IEEE, 2017. 5320−5329 [2] Rahman A, Wang Y. Optimizing intersection-over-union in deep neural networks for image segmentation. In: Proceedings of the 12th International Symposium on Visual Computing (ISVC). Las Vegas, USA: Springer, 2016. 234−244 [3] Wei Y C, Feng J S, Liang X D, Cheng M M, Zhao Y, Yan S C. Object region mining with adversarial erasing: A simple classification to semantic segmentation approach. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, USA: IEEE, 2017. 6488−6496 [4] Xu X W, Lu Q, Yang L, Hu S, Chen D, Hu Y, et al. Quantization of fully convolutional networks for accurate biomedical image segmentation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Salt Lake City, USA: IEEE, 2018. 8300−8308 [5] 刘青山, 卢汉清, 马颂德. 综述人脸识别中的子空间方法. 自动化学报, 2003, 29(6): 900-911Liu Qing-Shan, Lu Han-Qing, Ma Song-De. A survey: Subspace analysis for face recognition. Acta Automatica Sinica, 2003, 29(6): 900-911 [6] 高全学, 潘泉, 梁彦, 张洪才, 程咏梅. 基于描述特征的人脸识别研究. 自动化学报, 2006, 32(3): 386-392Gao Quan-Xue, Pan Quan, Liang Yan, Zhang Hong-Cai, Cheng Yong-Mei. Face recognition based on expressive features. Acta Automatica Sinica, 2006, 32(3): 386-392 [7] Wang S, Zhang W W, Wang Y S. New features extraction and application in fingerprint segmentation. Acta Automatica Sinica, 2003, 29(4): 622-627 [8] Yu C Q, Wang J B, Peng C, Gao C X, Yu G, Sang N. Learning a discriminative feature network for semantic segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Salt Lake City, USA: IEEE, 2018. 1857−1866 [9] Hsu C Y, Yang C H, Wang H C. Multi-threshold level set model for image segmentation. EURASIP Journal on Advances in Signal Processing, 2010, 2010(1): Article No. 950438 doi: 10.1155/2010/950438 [10] Taheri S, Ong S H, Chong V F H. Level-set segmentation of brain tumors using a threshold-based speed function. Image and Vision Computing, 2010, 28(1): 26-37 doi: 10.1016/j.imavis.2009.04.005 [11] Xu A P, Wang L J, Feng S, Qu Y X. Threshold-based level set method of image segmentation. In: Proceedings of the 3rd International Conference on Intelligent Networks and Intelligent Systems. Shenyang, China: IEEE, 2010. 703−706 [12] Feng J J, Zhou J, Jain A K. Orientation field estimation for latent fingerprint enhancement. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35(4): 925-940 doi: 10.1109/TPAMI.2012.155 [13] Maltoni D, Maio D, Jain A K, Prabhakar S. Handbook of Fingerprint Recognition (2nd edition). London: Springer, 2009. [14] Zhao Q J, Zhang D, Zhang L, Luo N. Adaptive fingerprint pore modeling and extraction. Pattern Recognition, 2010, 43(8): 2833-2844 doi: 10.1016/j.patcog.2010.02.016 [15] Long J, Shelhamer E, Darrell T. Fully convolutional networks for semantic segmentation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Boston, USA: IEEE, 2015. 3431−3440 [16] Ronneberger O, Fischer P, Brox T. U-Net: Convolutional networks for biomedical image segmentation. In: Proceedings of the 18th International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI). Munich, Germany: Springer, 2015. 234−241 [17] Zhao H S, Shi J P, Qi X J, Wang X G, Jia J Y. Pyramid scene parsing network. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, USA: IEEE, 2017. 6230−6239 [18] Lazebnik S, Schmid C, Ponce J. Beyond bags of features: Spatial pyramid matching for recognizing natural scene categories. In: Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR). New York, USA: IEEE, 2006. 2169−2178 [19] Chen L C, Zhu Y K, Papandreou G, Schroff F, Adam H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In: Proceedings of the 15th European Conference on Computer Vision (ECCV). Munich, Germany: Springer, 2018. 833−851 [20] Wang P Q, Chen P F, Yuan Y, Liu D, Huang Z H, Hou X D, et al. Understanding convolution for semantic segmentation. In: Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV). Lake Tahoe, USA: IEEE, 2018. 1451−1460 [21] Maio D, Maltoni D, Cappelli R, Wayman J L, Jain A K. FVC2000: Fingerprint verification competition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2002, 24(3): 402-412 doi: 10.1109/34.990140 [22] Maio D, Maltoni D, Cappelli R, Wayman J L, Jain A K. FVC2002: Second fingerprint verification competition. In: Proceedings of the International Conference on Pattern Recognition. Quebec City, Canada: IEEE, 2002. 811−814 [23] Maio D, Maltoni D, Cappelli R, Wayman J L, Jain A K. FVC2004: Third fingerprint verification competition. In: Proceedings of the 1st International Conference on Biometric Authentication (ICBA). Hong Kong, China: Springer, 2004. 1−7 [24] Watson C I. NIST Special Database 29: Plain and Rolled Images from Paired Fingerprint Cards, Internal Report 6801, National Institute of Standards and Technology, Gaithersburg, USA, 2001 [25] Berman M, Triki A R, Blaschko M B. The lovasz-softmax loss: A tractable surrogate for the optimization of the intersection-over-union measure in neural networks. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 4413−4421 [26] Tieleman T, Hinton G. Lecture 6.5-rmsprop: Divide the gradient by a running average of its recent magnitude. COURSERA: Neural Networks for Machine Learning, 2012, 4(2): 26-31 [27] Kingma D P, Ba J. Adam: A method for stochastic optimization. arXiv preprint arXiv: 1412.6980, 2014. [28] Wilson A C, Roelofs R, Stern M, Srebro N, Recht B. The marginal value of adaptive gradient methods in machine learning. In: Proceedings of the 31st International Conference on Neural Information Processing Systems. Long Beach, USA: Curran Associates Inc., 2017. 4151−4161 [29] Luo L C, Xiong Y H, Liu Y, Sun X. Adaptive gradient methods with dynamic bound of learning rate. In: Proceedings of the 7th International Conference on Learning Representations (ICLR). New Orleans, USA: OpenReview.net, 2019. [30] Liu L Y, Jiang H M, He P C, Chen W Z, Liu X D, Gao J F, et al. On the variance of the adaptive learning rate and beyond. In: Proceedings of the 8th International Conference on Learning Representations (ICLR). Addis Ababa, Ethiopia: OpenReview.net, 2020. [31] Goodfellow I J, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, Ozair S, et al. Generative adversarial nets. In: Proceedings of the 27th International Conference on Neural Information Processing Systems. Montreal, Canada: MIT Press, 2014. 2672−2680 [32] Ganin Y, Lempitsky V. Unsupervised domain adaptation by backpropagation. In: Proceedings of the 32nd International Conference on International Conference on Machine Learning. Lille, France: JMLR.org, 2015. 1180−1189 [33] Pan S J, Yang Q. A survey on transfer learning. IEEE Transactions on Knowledge and Data Engineering, 2010, 22(10): 1345-1359 doi: 10.1109/TKDE.2009.191 [34] He K M, Zhang X Y, Ren S Q, Sun J. Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA: IEEE, 2016. 770−778 [35] Kaggle. AISegment.com-Matting human datasets [Online], available: https://www.kaggle.com/laurentmih/aisegmentcom-matting-human-datasets/, March 20, 2020 [36] Shen X Y, Tao X, Gao H Y, Zhou C, Jia J Y. Deep automatic portrait matting. In: Proceedings of the 14th European Conference on Computer Vision (ECCV). Amsterdam, the Netherlands: Springer, 2016. 92−107 [37] Arjovsky M, Chintala S, Bottou L. Wasserstein generative adversarial networks. In: Proceedings of the 34th International Conference on Machine Learning. Sydney, NSW, Australia: PMLR, 2017. 214−223 [38] Maas A L, Hannun A Y, Ng A Y. Rectifier nonlinearities improve neural network acoustic models. In: Proceedings of the 30th International Conference on Machine Learning (ICML). Atlanta, USA: JMLR, 2013. [39] Madhero88. Layers of the skin [Online], available: https://en.wikipedia.org/wiki/File:Skin_layers.png, March 20, 2020 [40] Liu F, Shen L L, Liu H Z, Shen C X, Liu G J, Liu Y H, et al. A-benchmark-database-using-optical-coherence-tomography-for-fingerprints [Online], available: https://github.com/CV-SZU/A-Benchmark-Database-using-Optical-Coherence-Tomography-for-Fingerprints, March 20, 2020 [41] Liu F, Shen C X, Liu H Z, Liu G J, Liu Y H, Guo Z H, et al. A flexible touch-based fingerprint acquisition device and a benchmark database using optical coherence tomography. IEEE Transactions on Instrumentation and Measurement, 2020, 69(9): 6518-6529 doi: 10.1109/TIM.2020.2967513 [42] Liu F, Liu G J, Wang X Z. High-accurate and robust fingerprint anti-spoofing system using optical coherence tomography. Expert Systems With Applications, 2019, 130: 31-44 doi: 10.1016/j.eswa.2019.03.053 [43] Liu H Z, Zhang W T, Liu F, Qi Y. 3D fingerprint gender classification using deep learning. In: Proceedings of the 14th Chinese Conference on Biometric Recognition (CCBR). Zhuzhou, China: Springer, 2019. 37−45 [44] Jain A, Chen Y, Demirkus M. Pores and ridges: Fingerprint matching using level 3 features. In: Proceedings of the 18th International Conference on Pattern Recognition (ICPR). Hong Kong, China: IEEE, 2006. 477−480 [45] Xu Y R, Lu G M, Liu F, Li Y X. Fingerprint pore extraction based on multi-scale morphology. In: Proceedings of the 12th Chinese Conference on Biometric Recognition (CCBR). Shenzhen, China: Springer, 2017. 288−295 [46] Labati R D, Genovese A, Muñoz E, Piuri V, Scotti F. A novel pore extraction method for heterogeneous fingerprint images using Convolutional Neural Networks. Pattern Recognition Letters, 2018, 113: 58-66 doi: 10.1016/j.patrec.2017.04.001 [47] Jang H U, Kim D, Mun S M, Choi S, Lee H K. DeepPore: Fingerprint pore extraction using deep convolutional neural networks. IEEE Signal Processing Letters, 2017, 24(12): 1808-1812 doi: 10.1109/LSP.2017.2761454 [48] Chen L C, Papandreou G, Kokkinos I, Murphy K, Yuille A L. Semantic image segmentation with deep convolutional nets and fully connected CRFs. arXiv preprint arXiv: 1412.7062, 2014. [49] Chen L C, Papandreou G, Kokkinos I, Murphy K, Yuille A L. DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(4): 834-848 doi: 10.1109/TPAMI.2017.2699184 -

 下载:
下载:



计量
- 文章访问数: 2038
- HTML全文浏览量: 663
- PDF下载量: 207
- 被引次数: 0

{kind=link}