

Signal Priority Control for Trams Using Deep Reinforcement Learning
-
摘要: 现有的有轨电车信号优先控制系统存在诸多问题, 如无法适应实时交通变化、优化求解较为复杂等. 本文提出了一种基于深度强化学习的有轨电车信号优先控制策略. 不依赖于交叉口复杂交通建模, 采用实时交通信息作为输入, 在有轨电车整个通行过程中连续动态调整交通信号. 协同考虑有轨电车与社会车辆的通行需求, 在尽量保证有轨电车无需停车的同时, 降低社会车辆的通行延误. 采用深度Q网络算法进行问题求解, 并利用竞争架构、双Q网络和加权样本池改善学习性能. 基于SUMO的实验表明, 该模型能够有效地协同提高有轨电车与社会车辆的通行效率.Abstract: Current trams-priority signal control systems have many problems, such as low adaptability to real-time traffic changes and high complexity in optimization solutions, etc. In this paper, an active signal priority control model is proposed for the trams based on deep reinforcement learning. Considering the traffic demands from tram and general vehicles, it can reduce the traffic delay of general vehicles while minimizing the need for trams to stop at the intersection. Real-time traffic information is used to dynamically adjust the sequence of traffic signals throughout the whole passing process of the tram, without relying on the complex traffic modeling. We use deep Q-network algorithm for problem-solving, and adopt dueling network, double Q network, and prioritized experience replay to improve the learning performance. Experiments based on SUMO have demonstrated that the proposed model can excellently improve the efficiency of trams and general vehicles simultaneously.
-
Key words:
- Trams /
- signal priority /
- Markov decision process /
- deep reinforcement learning
-
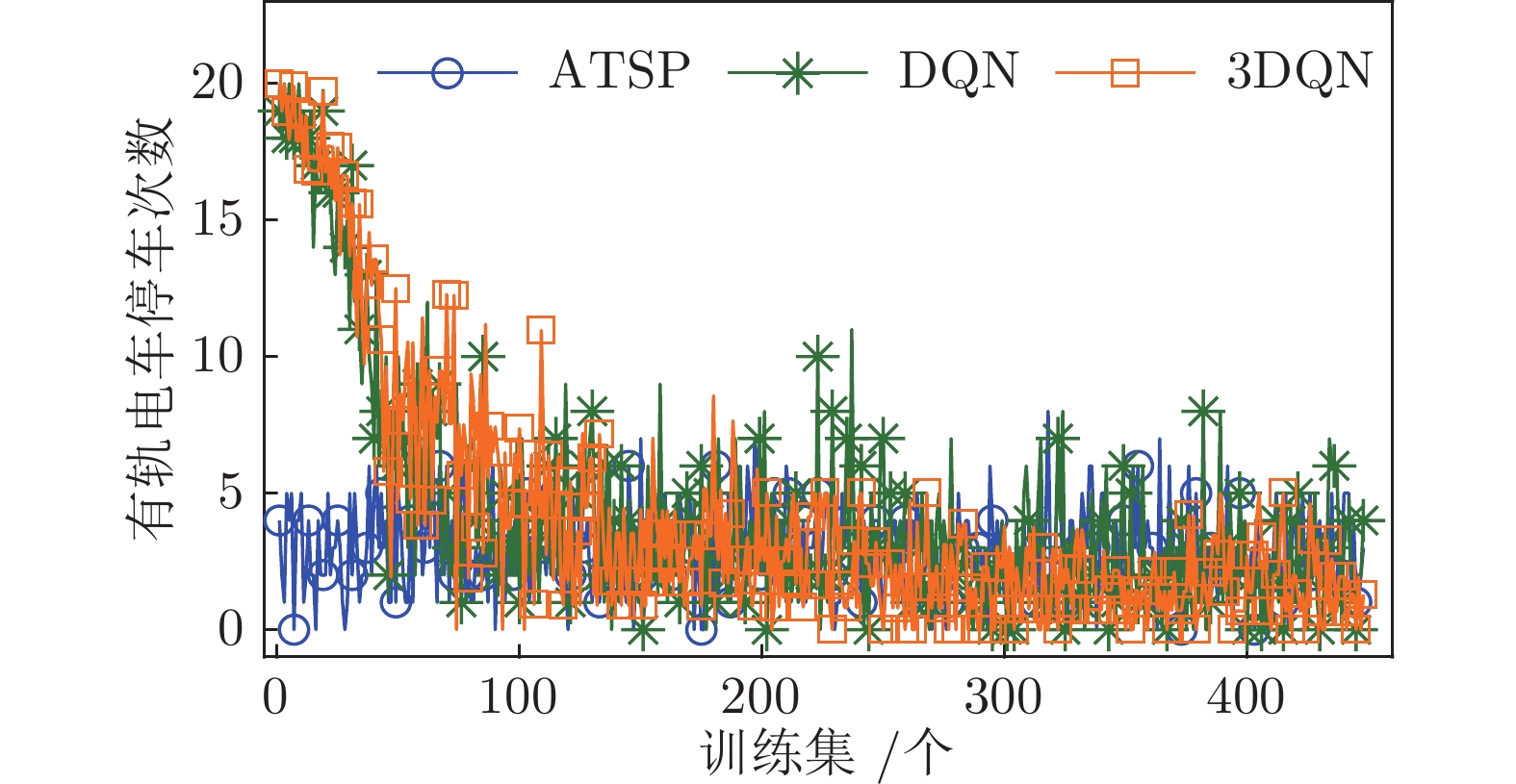
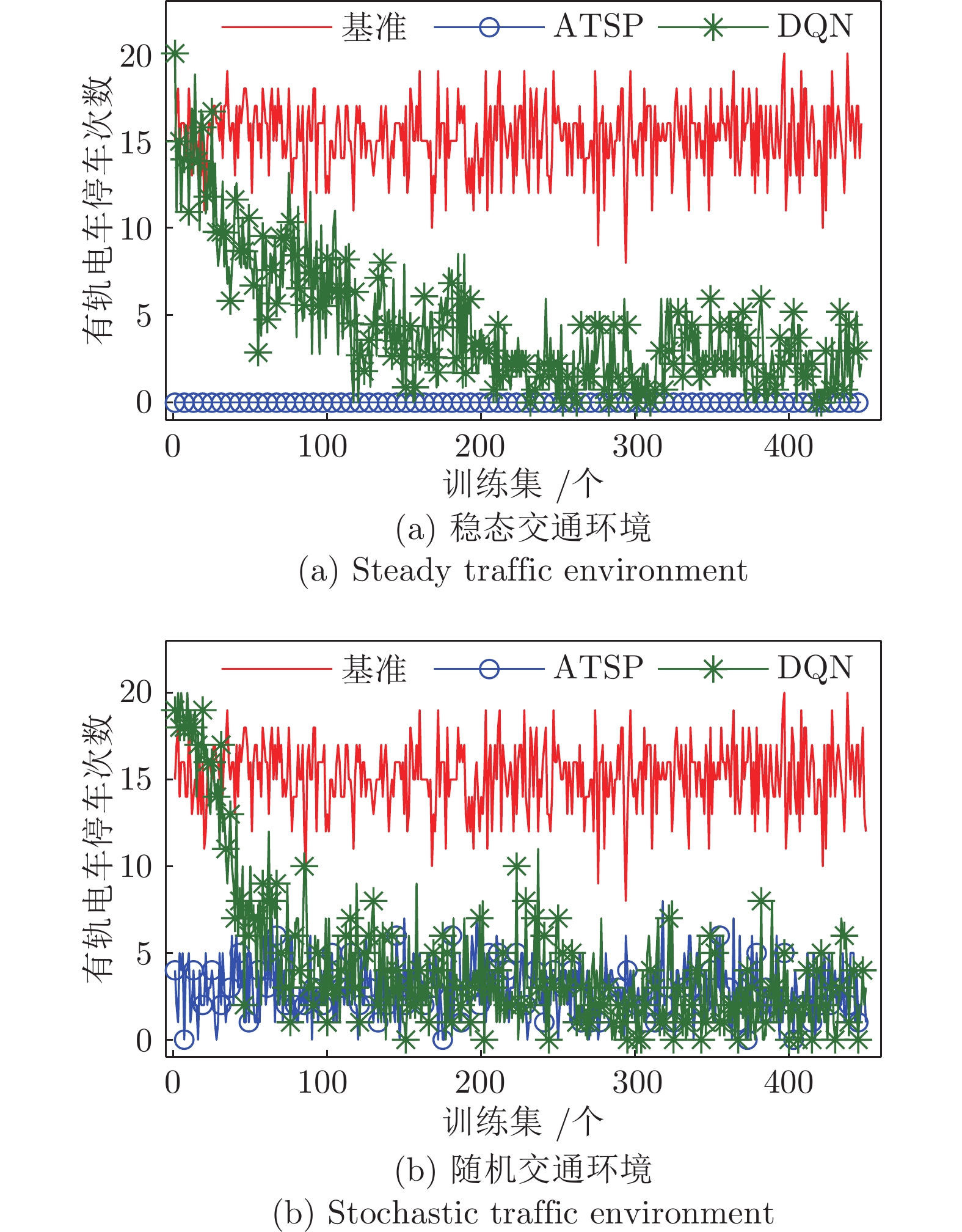
图 7 两种深度强化学习模型下有轨电车平均停车次数对比
Fig. 7 Comparison of tram mean stops under two deep reinforcement learning models
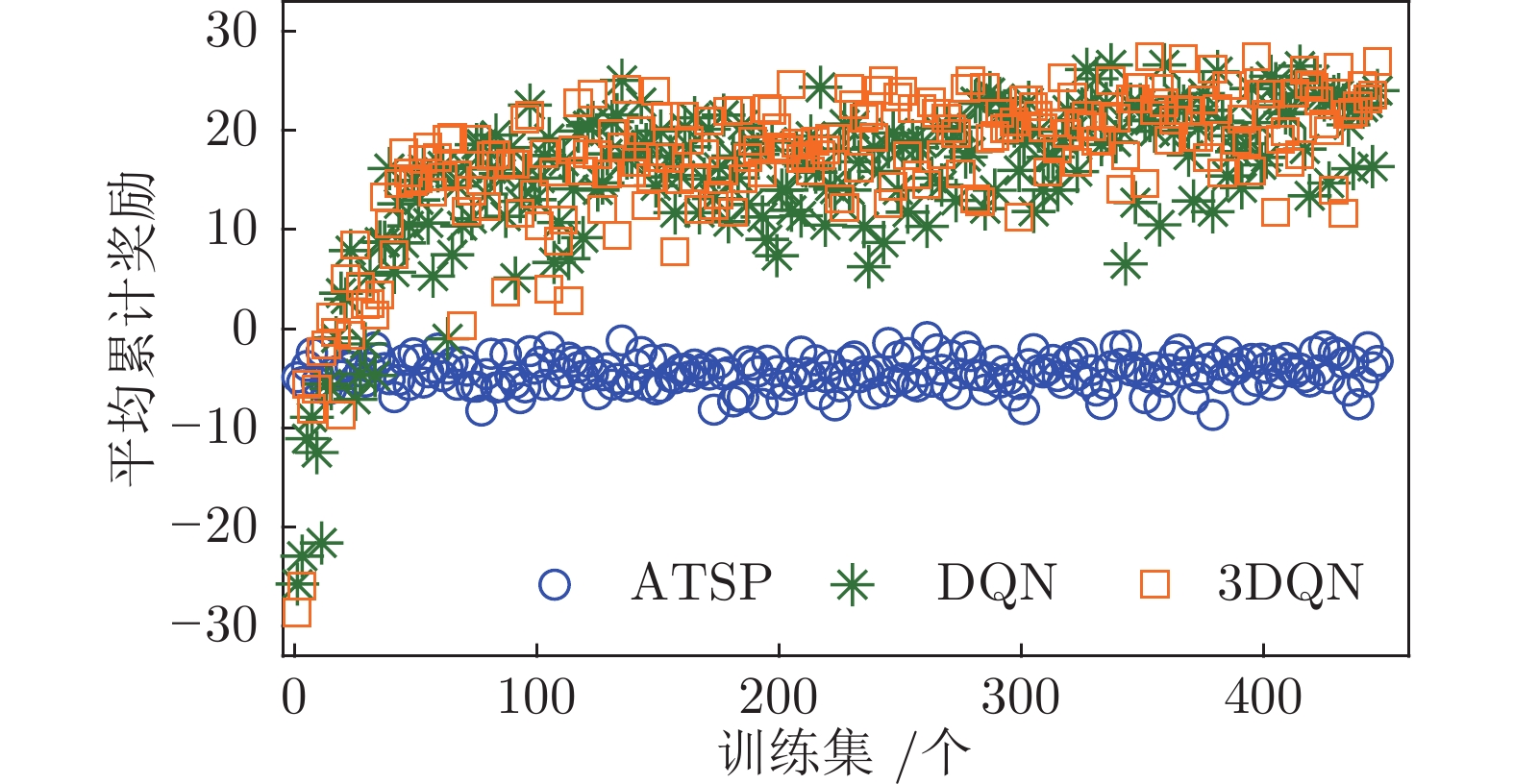
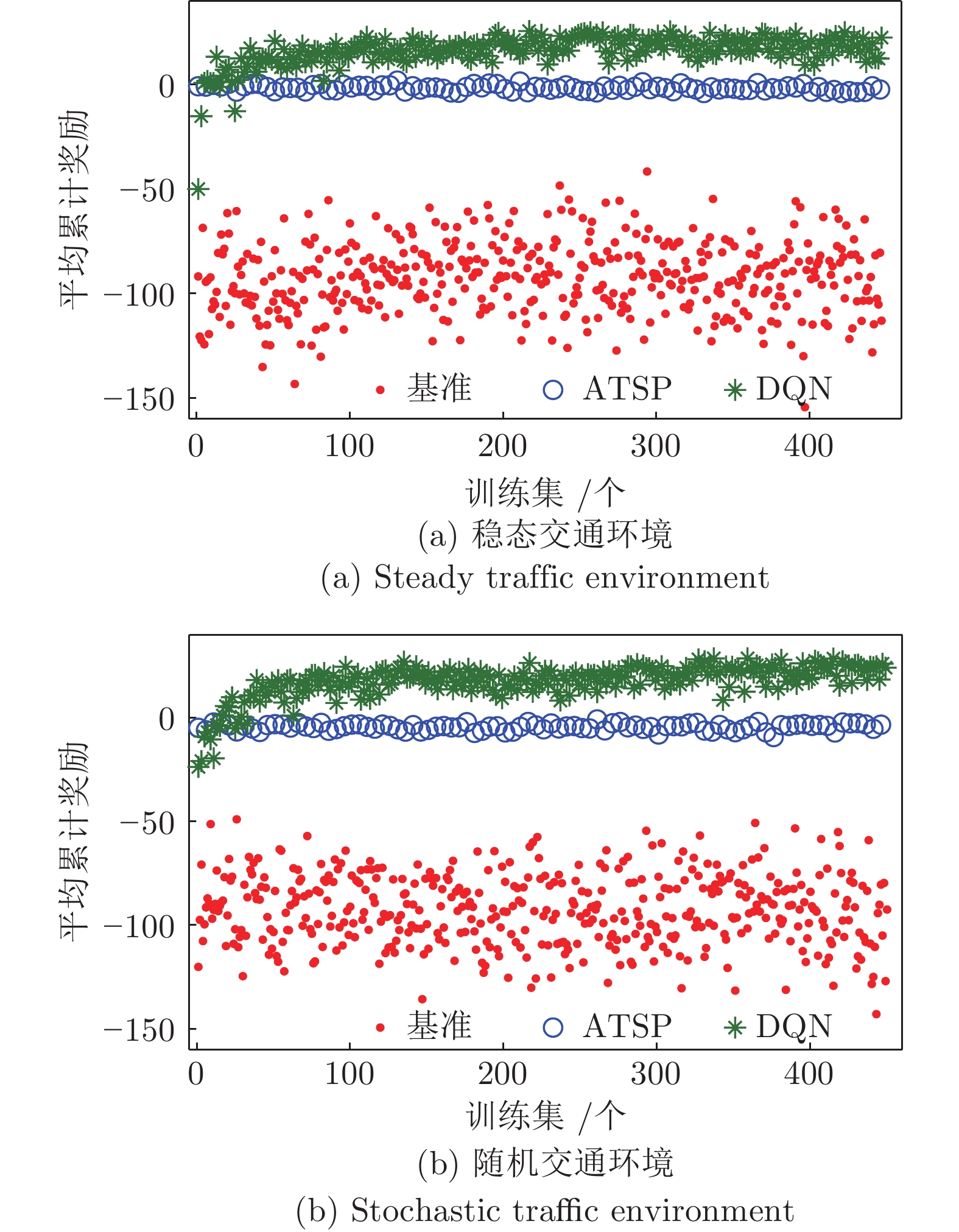
图 8 两种深度强化学习模型下累积奖励对比
Fig. 8 Comparison of cumulative reward under two deep reinforcement learning models
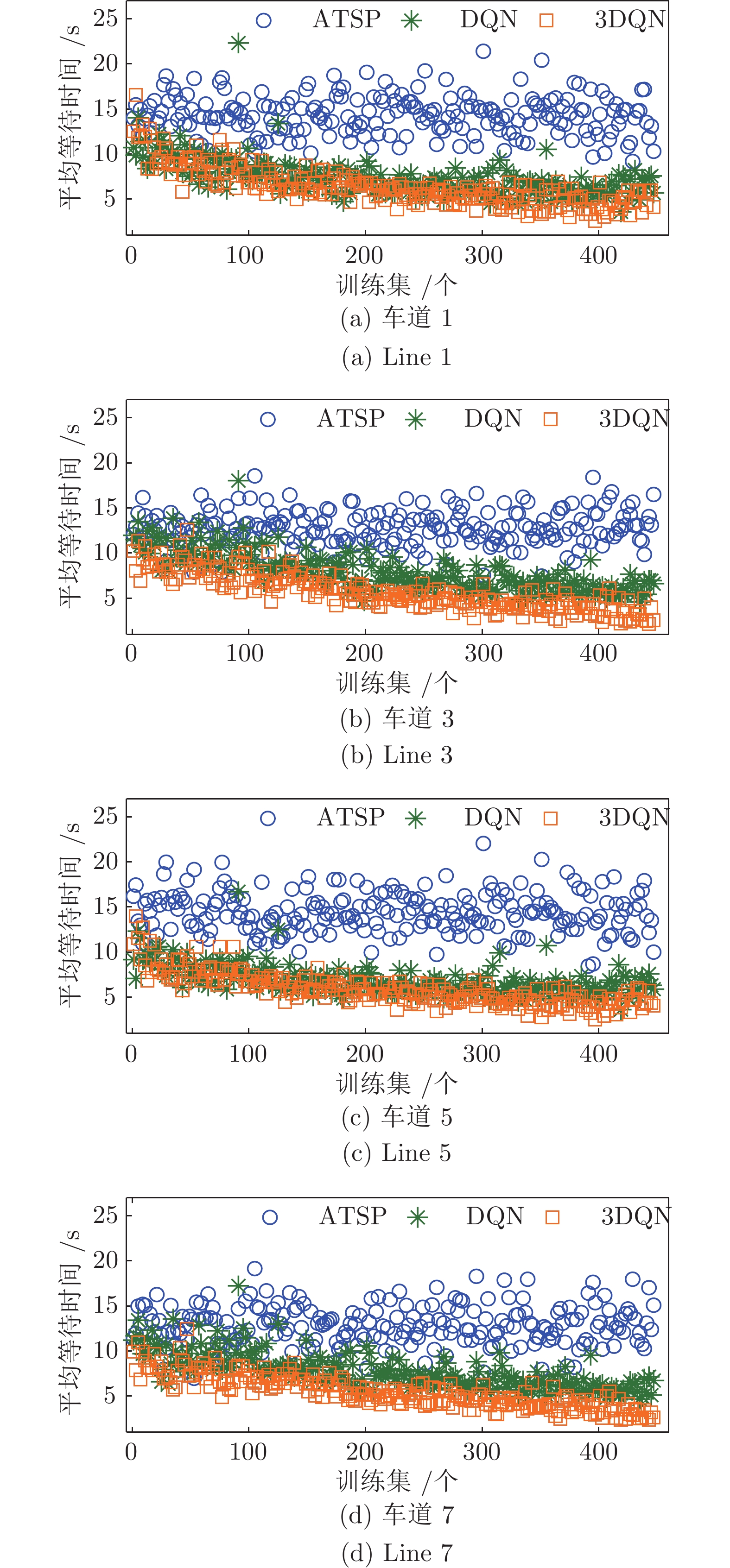
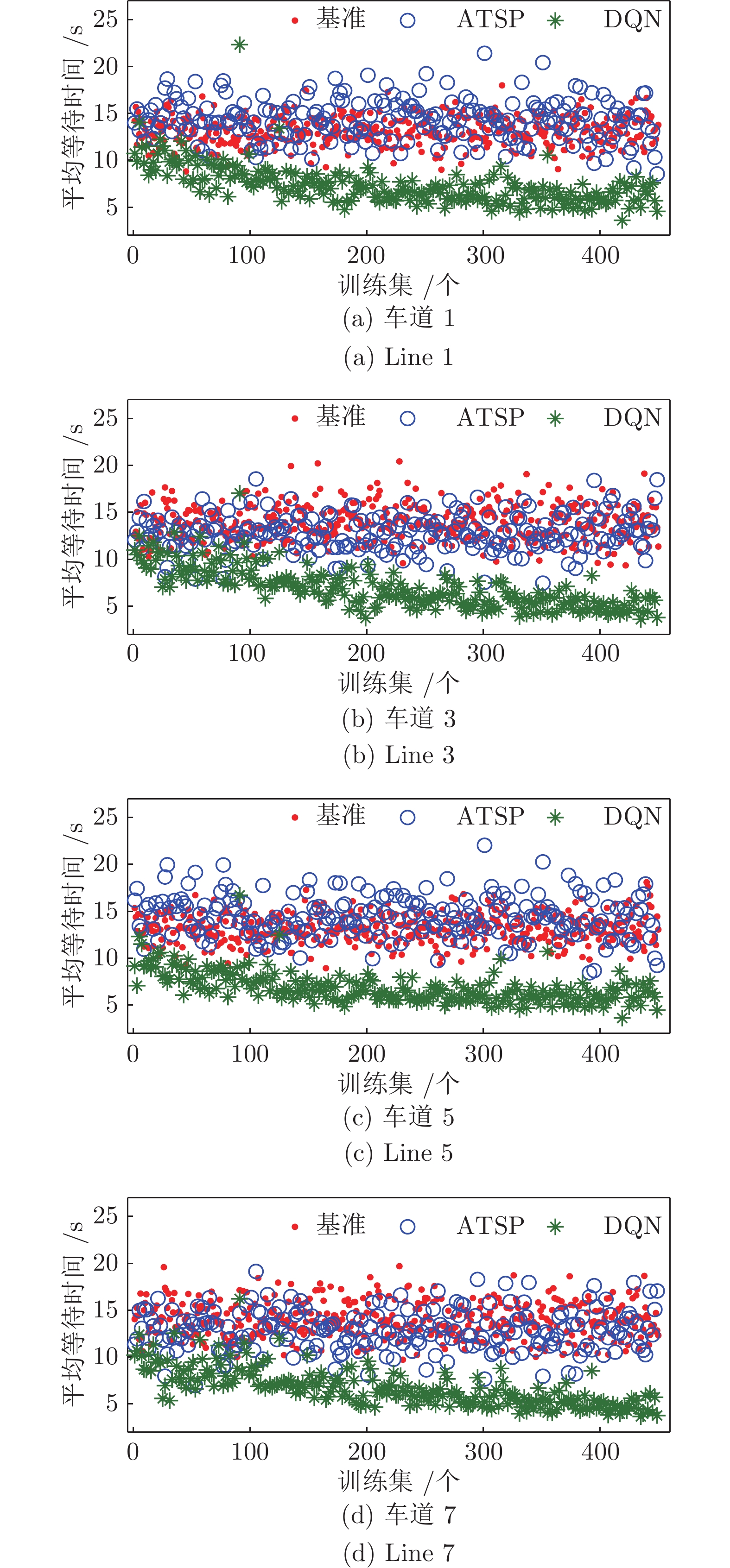
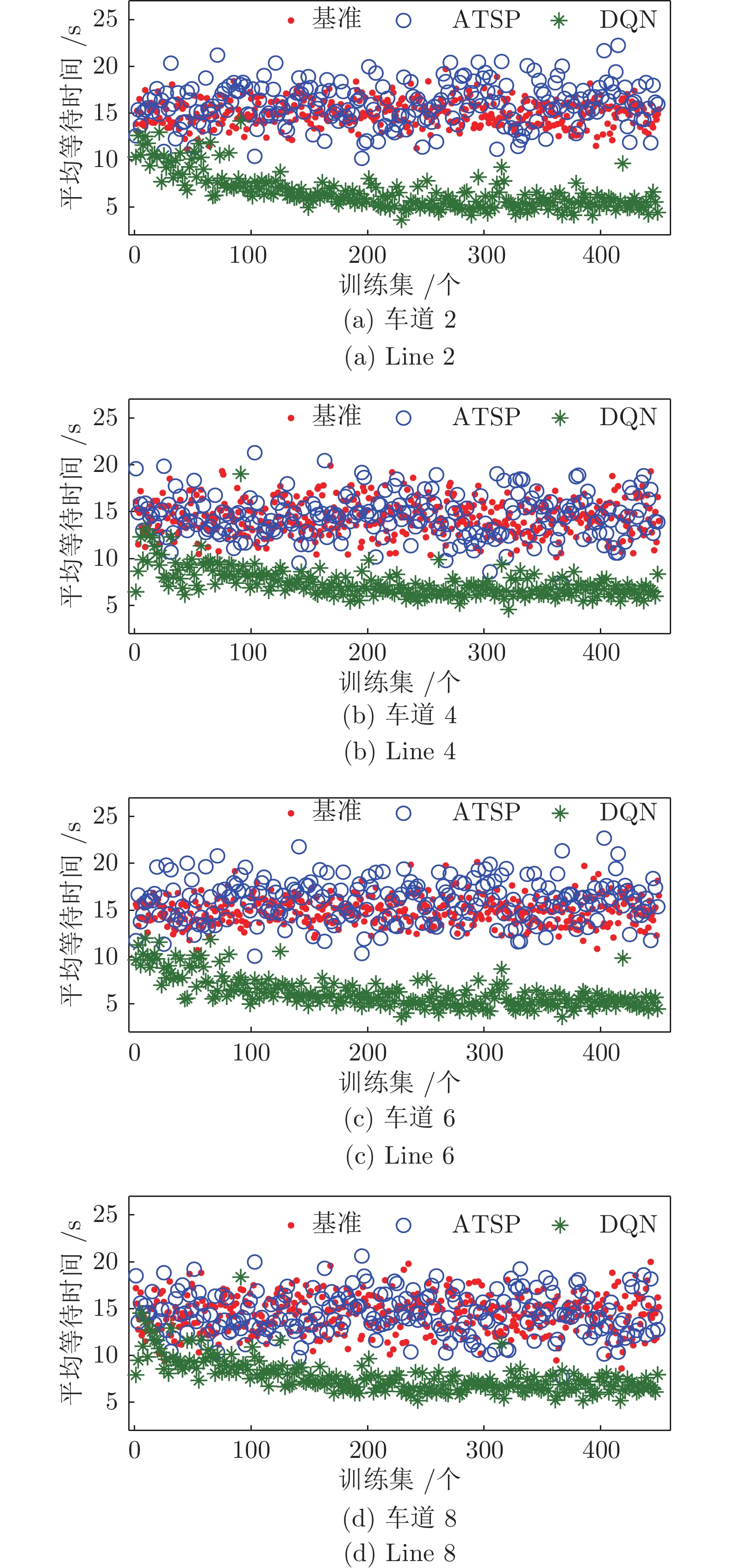
图 9 两种深度强化学习模型下各直行/右转车道平均停车等待时间对比
Fig. 9 Comparison of waiting time in direct/right turn lanes under two deep reinforcement learning models
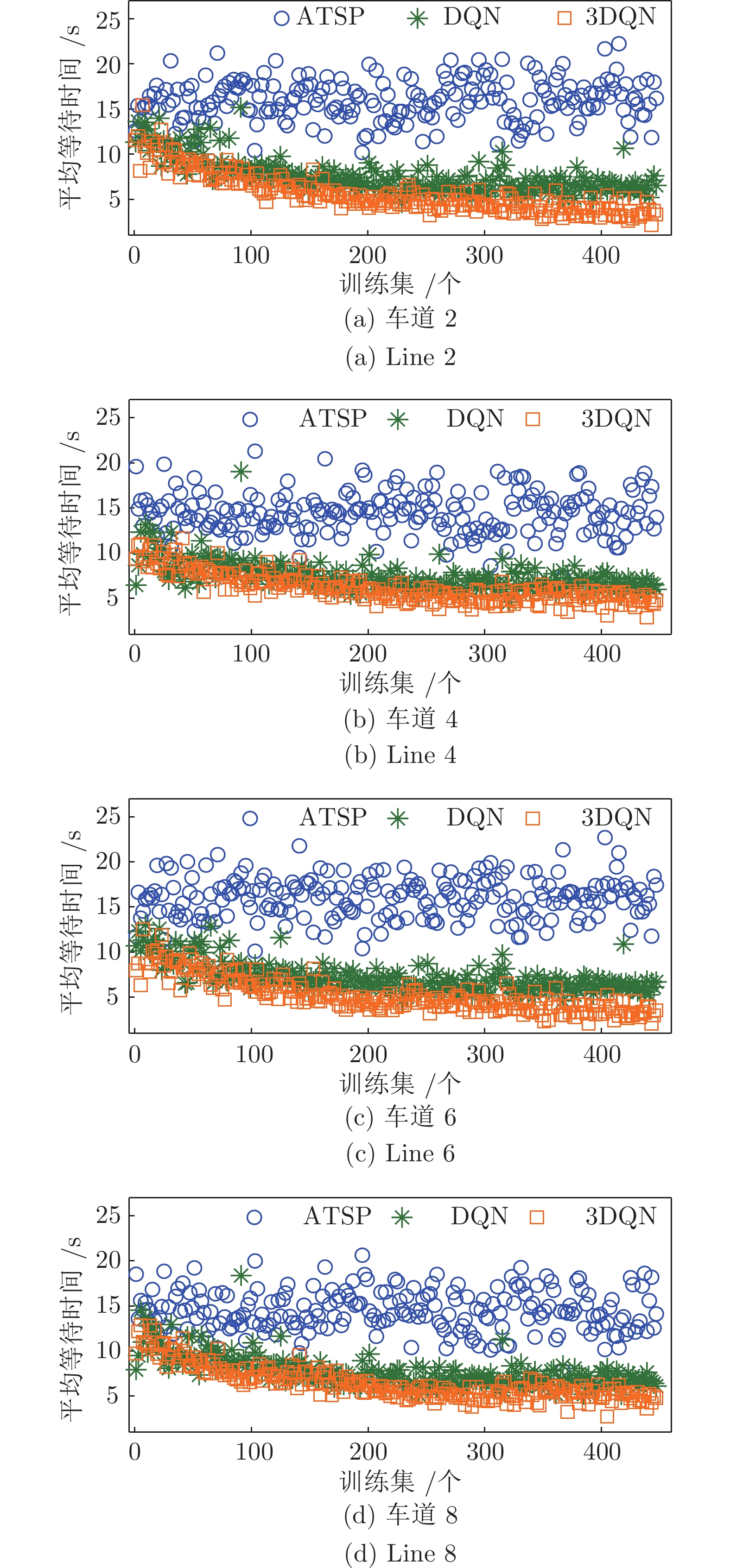
图 10 两种深度强化学习模型下各左转车道平均停车等待时间对比
Fig. 10 Comparison of waiting time in left turn lanes under two deep reinforcement learning models
表 1 模型参数
Table 1 Model parameters
参数 取值 $N$ 20 000 $m$ 32 $\Delta \varepsilon$ −0.001 $\gamma$ 0.99 $\alpha$ 0.001  下载: 导出CSV
下载: 导出CSV
-
[1] Ministry of tranport of China. Statistical bulletin on transportation industry development in 2018. [Online], available: http://xxgk.mot.gov.cn/jigou/zhghs/201904/t20190412_3186720.html, September 5, 2019 [2] 2 Shi J G, Sun Y S, Schonfeld P, Qi J. Joint optimization of tram timetables and signal timing adjustments at intersections. Transportation Research Part C: Emerging Technologies, 2017, 83(6): 104−119 [3] 3 Ji Y X, Tang Y, Du Y C, Zhang X. Coordinated optimization of tram trajectories with arterial signal timing resynchronization. Transportation Research Part C: Emerging Technologies, 2019, 99(4): 53−66 [4] Little J D C, Kelson M D, Gartner N M. Maxband: a program for setting signals on arteries and triangular networks. In: Proceedings of the 60th Annual Meeting of the Transportation Research Board. Washington, USA: Transportation Research Board, 1981. 40−46 [5] 5 Jeong Y J, Kim Y C. Tram passive signal priority strategy based on the maxband model. KSCE Journal of Civil Engineering, 2014, 18(5): 1518−1527 doi: 10.1007/s12205-014-0159-1 [6] 6 Ma W, Zou L, An K, Gartner N H, Wang M. A partition-enabled multi-mode band approach to arterial traffic signal optimization. IEEE Transactions on Intelligent Transportation Systems, 2019, 20(1): 313−322 doi: 10.1109/TITS.2018.2815520 [7] 7 Kim H, Cheng Y, Chang G. Variable signal progression bands for transit vehicles under dwell time uncertainty and traffic queues. IEEE Transactions on Intelligent Transportation Systems, 2019, 20(1): 109−122 doi: 10.1109/TITS.2018.2801567 [8] 8 Ji Y X, Tang Y, Wang W, Du Y C. Tram-oriented traffic signal timing resynchronization. Journal of Advanced Transportation, 2018, 2018(1): 1−13 [9] 9 Jacobson J, Sheffi Y. Analytical model of traffic delays under bus signal preemption: theory and application. Transportation Research Part B: Methodological, 1981, 15(2): 127−138 doi: 10.1016/0191-2615(81)90039-4 [10] 10 Yang M, Ding J, Wang W, Ma Y Y. A coordinated signal priority strategy for modern trams on arterial streets by predicting the tram dwell time. KSCE Journal of Civil Engineering, 2018, 22(2): 823−836 doi: 10.1007/s12205-017-1187-4 [11] 高阳, 陈世福, 陆鑫. 强化学习研究综述. 自动化学报, 2004, 30(1): 1−15 doi: 10.3969/j.issn.1003-8930.2004.01.00111 Gao Yang, Chen Shi-Fu, Lu Xin. Reseacrh on reinforcement learning technology: a review. Acta Automatica Sinica, 2004, 30(1): 1−15 doi: 10.3969/j.issn.1003-8930.2004.01.001 [12] 12 Bertsekas D P. Feature-based aggregation and deep reinforcement learning: a survey and some new implementations. IEEE/CAA Journal of Automatica Sinica, 2019, 6(1): 1−31 [13] 13 Samah E T, Abdulhai B, Abdelgawad H. Design of reinforcement learning parameters for seamless application of adaptive traffic signal control. Journal of Intelligent Transportation Systems, 2014, 18(3): 227−245 doi: 10.1080/15472450.2013.810991 [14] 段艳杰, 吕宜生, 张杰, 赵学亮, 王飞跃. 深度学习在控制领域的研究现状与展望. 自动化学报, 2016, 42(5): 643−65414 Duan Yan-Jie, Lv Yi-Sheng, Zhang Jie, Zhao Xue-Liang, Wang Fei-Yue. Deep learning for control: the state of the art and prospects. Acta Automatica Sinica, 2016, 42(5): 643−654 [15] 15 Li L, Lv Y, Wang F-Y. Traffic signal timing via deep reinforcement learning. IEEE/CAA Journal of Automatica Sinica, 2016, 3(3): 247−254 [16] 16 Liang X, Du X, Wang G, Han Z. A deep reinforcement learning network for traffic light cycle control. IEEE Transactions on Vehicular Technology, 2019, 68(2): 1243−1253 doi: 10.1109/TVT.2018.2890726 [17] 17 Ling K, Shalaby A. Automated transit headway control via adaptive signal priority. Journal of Advanced Transportation, 2004, 38(4): 45−67 [18] 舒波, 李大铭, 赵新良. 基于强化学习算法的公交信号优先策略. 东北大学学报(自然科学版), 2012, 33(10): 1513−1516 doi: 10.12068/j.issn.1005-3026.2012.10.03518 Shu Bo, Li Da-Ming, Zhao Xin-Liang. Transit signal priority strategy based on reinforcement learning algorithm. Journal of Northeastern University (Natural Science), 2012, 33(10): 1513−1516 doi: 10.12068/j.issn.1005-3026.2012.10.035 [19] 梁星星, 冯旸赫, 马扬, 程光权, 黄金才, 王琦等. 多agent深度强化学习综述. 自动化学报, 2019. DOI: 10.16383/j.aas.c180372Liang Xing-Xing, Feng Yang-He, Ma Yang, Cheng Guang-Quan, Huang Jin-Cai, Wang Qi, et al. Deep multi-agent reinforcement learning: a survey. Acta Automatica Sinica, 2019. DOI: 10.16383/j.aas.c180372 [20] 赵英男, 刘鹏, 赵巍, 唐降龙. 深度q学习的二次主动采样方法. 自动化学报, 2019, 45(10): 1870−1882 doi: 10.3969/j.issn.1003-8930.2019.01.00120 Zhao Ying-Nan, Liu Peng, Zhao Wei, Tang Xiang-Long. Twice sampling method in deep Q-network. Acta Automatica Sinica, 2019, 45(10): 1870−1882 doi: 10.3969/j.issn.1003-8930.2019.01.001 [21] Wang Z Y, Schaul T, Hessel M, Hasselt H, Lanctot M, Freitas N. Dueling network architectures for deep reinforcement learning. In: Proceedings of the 33rd International Conference on Machine Learning. New York, USA: PMLR, 2016. 1995−2003 [22] Hasselt H V, Guez A, Silver D. Deep reinforcement learning with double Q-learning. In: Proceedings of the 30th AAAI Conference on Artificial Intelligence, Phoenix, USA: MIT, 2015. 2094−2100 [23] Schaul T, Quan J, Antonoglou I, Silver D. Prioritized experience replay. In: Proceedings of the 2016 International Conference on Learning Representations 2016, San Juan, Puerto Rico: arXiv, 2016. 1−21 [24] Lopez P A, Behrisch M, Walz L B, Erdmann J, Flotterod Y, Hilbrich R, et al. Microscopic traffic simulation using sumo. In: Proceedings of the 21st IEEE International Conference on Intelligent Transportation Systems. Hawaii, USA: IEEE, 2018. 2575−2582 [25] 25 Islam M T, Tiwana J, Bhowmick A, Qiu T Z. Design of LRT signal priority to improve arterial traffic mobility. Journal of Transportation Engineering, 2016, 142(9): 04016034 doi: 10.1061/(ASCE)TE.1943-5436.0000831 -

 下载:
下载:

计量
- 文章访问数: 3442
- HTML全文浏览量: 1185
- PDF下载量: 509
- 被引次数: 0
