

A New Algorithm for Mining High Utility Sequential Patterns Based on Pattern-growth
-
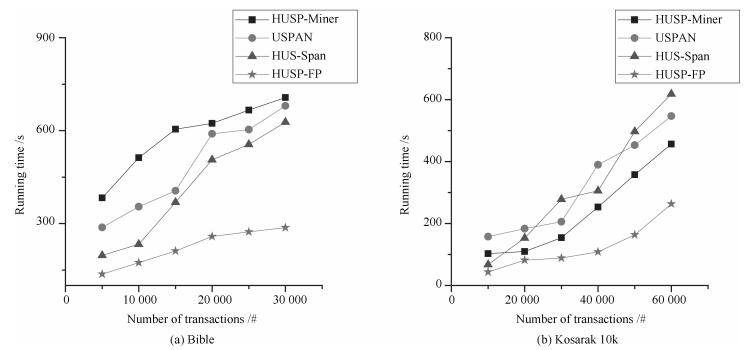
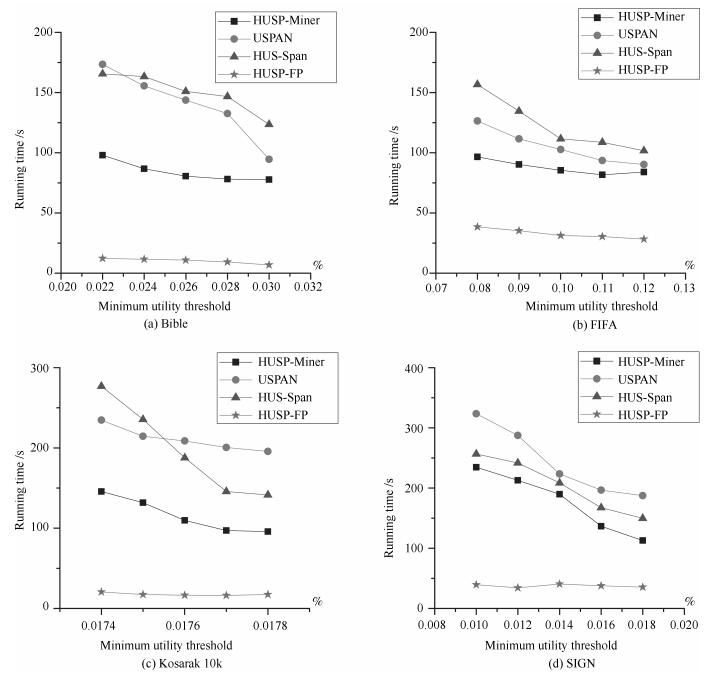
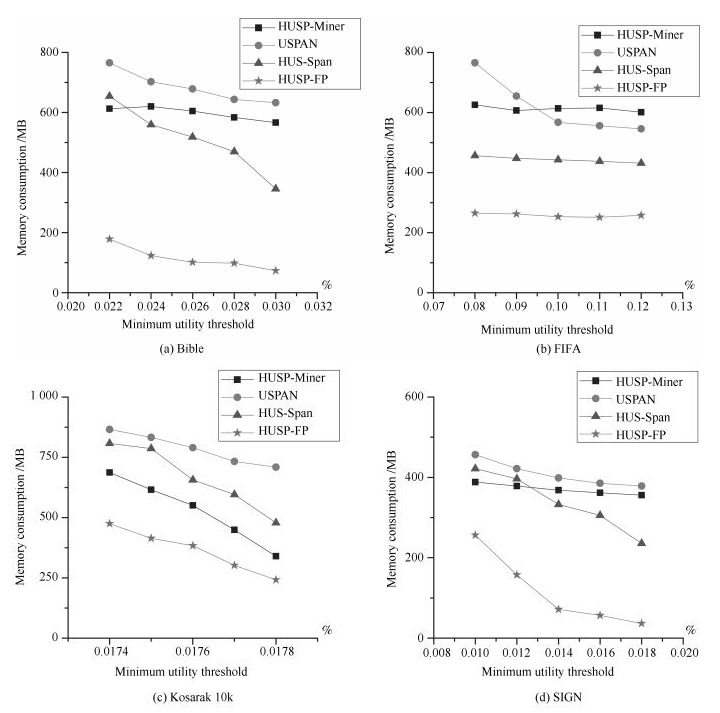
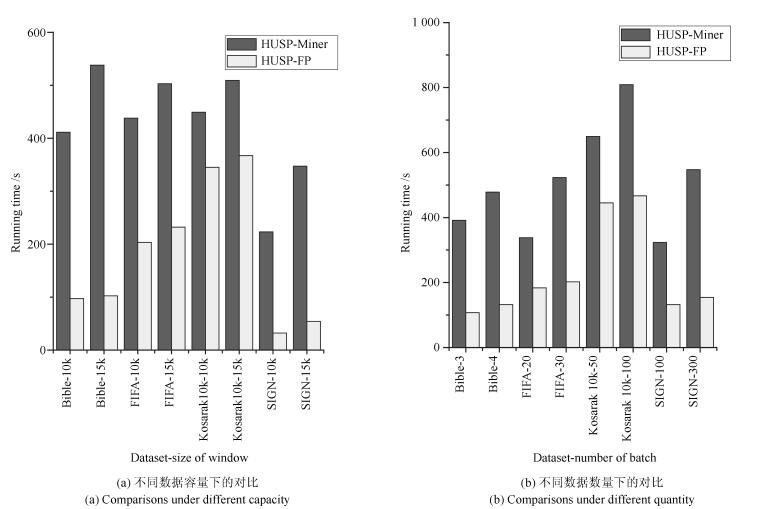
摘要: 高效用序列模式挖掘是数据挖掘领域的一项重要内容, 在生物信息学、消费行为分析等方面具有重要的应用.与传统基于频繁项模式挖掘方法不同, 高效用序列模式挖掘不仅考虑项集的内外效用, 更突出项集的时间序列含义, 计算复杂度较高.尽管已经有一定数量的算法被提出应用于解决该类问题, 挖掘算法的时空效率依然成为该领域的主要研究热点问题.鉴于此, 本文提出一个基于模式增长的高效用序列模式挖掘算法HUSP-FP.依据高效用序列项集必须满足事务效用闭包属性要求, 算法首先在去除无用项后建立全局树, 进而采用模式增长方法从全局树上获取全部高效用序列模式, 避免产生候选项集. 在实验环节与目前效率较好的HUSP-Miner、USPAN、HUS-Span三类算法进行了时空计算对比, 实验结果表明本文给出算法在较小阈值下仍能有效挖掘到相关序列模式, 并且在计算时间和空间使用效率两方面取得了较大的提高.Abstract: High utility sequential pattern mining is an important research topic in data mining. It plays an important role in many applications, such as bioinformatics and consumer behavior analysis. Difierent from traditional itemsets mining methods which take the appear numbers or the utility of the itemsets into account, high utility sequential pattern mining not only concerns the inner and outer utility but also the sequences of the items in the transactions, its computational complexity increases compared to the single frequent itemsets mining or high utility itemsets mining. Although a number of algorithms have been proposed to solve such problem, the e–ciency of mining algorithms is still the main research topic in this fleld. In view of this, this paper proposes an e–cient high utility sequential pattern mining algorithm named HUSP-FP based on pattern growth. Because the transaction utility value of the sequence itemset should satisfy the downward closure property, a global tree is established based on the sequential items in the transactions of the dataset after removing useless items. the HUSP-FP algorithm can e–ciently extract sequential patterns from global tree without generating candidate itemsets. Comparing with the state-of-the-art high-utility sequential pattern mining algorithms of HUSP-Miner、USPAN and HUS-Span in our experiments, the proposed HUSP-FP out-performed its counterpart signiflcantly.
-
Key words:
- High utility sequential pattern /
- pattern growth /
- downward closure property /
- data mining
1) 本文责任编委 张军平 -
表 1 高效用数据集
Table 1 High utility dataset
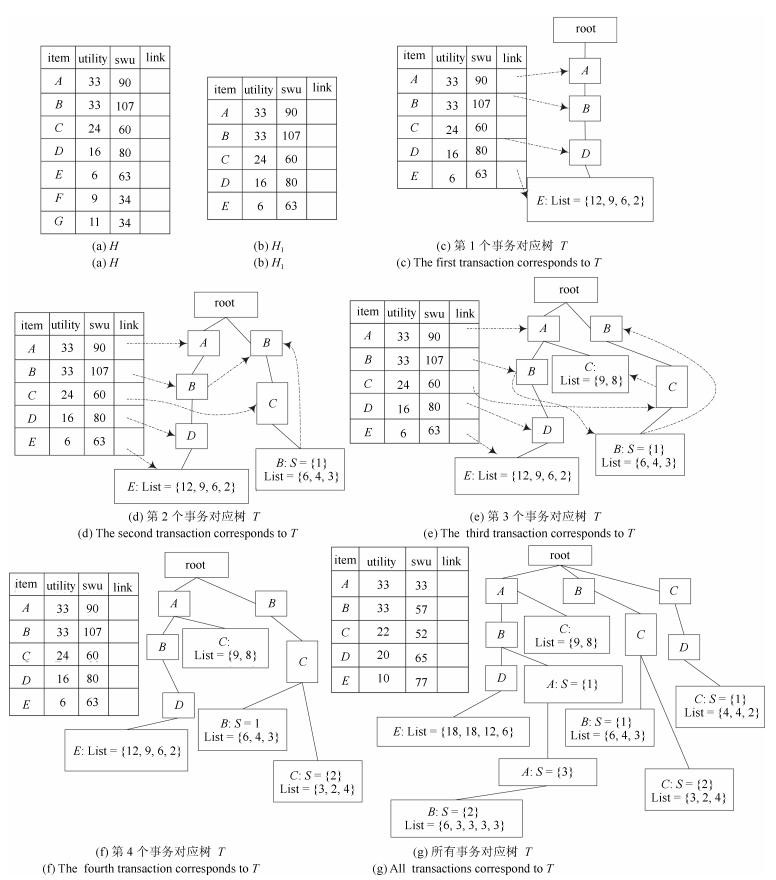
TID Transaction (item, quantity) $ t_1 $ $ (A, 4) (B, 3) (D, 3) (E, 1) $ $ t_2 $ $ (B, 2) (C, 2) (B, 1) (G, 4) $ $ t_3 $ $ (A, 3) (C, 4) $ $ t_4 $ $ (B, 1) (C, 1) (C, 2) $ $ t_5 $ $ (A, 2) (B, 3) (D, 3) (E, 2) (F, 9) $ $ t_6 $ $ (C, 2) (D, 2) (C, 1) (G, 7) $ $ t_7 $ $ (A, 2) (B, 1) (A, 1) (A, 1) (B, 1) $  下载: 导出CSV
下载: 导出CSV
表 2 利润表(外部效用值)
Table 2 A Profit Table (External utility value)
TID Transaction (item, quantity) $ A $ 3 $ B $ 3 $ C $ 2 $ D $ 2 $ E $ 2 $ F $ 1 $ G $ 1
下载: 导出CSV
表 3 算法复杂度比较
Table 3 Comparisons of algorithm complexity
算法 事务存储 效用存储 挖掘方式 候选项 HUSP-FP 全局树 叶子结点 模式增长, 一次性完成 无 HUSP-Miner 序列表格 序列树结点 表格搜索, 深度剪枝 有 USPAN 序列字典树 效用矩阵 枚举搜索, 剩余量剪枝 有 HUS-Span 序列枚举树 链表 效用上界深度搜索 有
下载: 导出CSV
表 4 算法复杂度比较
Table 4 Data characteristics
数据集 项数 序列事务项集平均长度 序列事务总数 Bible 13 905 21.64 36 369 FIFA 13 749 45.32 573 060 Kosarak 10k 39 998 11.64 638 811 SIGN 267 93.00 730
下载: 导出CSV
-
[1] Michele D, Fabrizio B, Jacopo L, Jacopo R, Salvatore T, Federico. Sequential pattern mining for ICT risk assessment and management. Journal of Logical and Algebraic Methods in Programming, 2019, 102(1): 1-16 http://www.sciencedirect.com/science/article/pii/S235222081830021X [2] Maryam A, Leyli M, Raffaela M. A sequential pattern mining model for application workload prediction in cloud environment. Journal of Network and Computer Applications, 2018, 105(3): 21-62 http://www.sciencedirect.com/science/article/pii/S1084804517304198 [3] Xue Yun, Li Tie-Chen, Liu Zhi-Wen, Pang Chao-Yi, Li Mei-Hang, Liao Zheng-Ling. A new approach for the deep order preserving submatrix problem based on sequential pattern mining. International Journal of Machine Learning and Cybernetics, 2018, 9(2): 263-279 doi: 10.1007/s13042-015-0384-z [4] Trang V, Bay V, Bac L. Mining sequential patterns with itemset constraints. Knowledge and Information Systems, 2018, 57(2): 311-330 doi: 10.1007/s10115-018-1161-6 [5] Shou Zhen-Yu, Di Xuan. Similarity analysis of frequent sequential activity pattern mining. Emerging Technologies, 2018, 96(11): 122-143 [6] Bac L, Duy T, Van N, Quang M, Philippe F V. An efficient algorithm for hiding high utility sequential patterns. International Journal of Approximate Reasoning, 2018, 95: 77-92 doi: 10.1016/j.ijar.2018.01.005 [7] Liu J Q Zhang X X, Benjamin C, Li J Y, Farkhund I. Opportunistic mining of top-n high utility patterns. Information Sciences, 2018, 441(5): 171-186 [8] Song W, Rong K K. Mining high utility sequential patterns using maximal remaining utility. In: Proceedings of Data Mining and Big Data. Shanghai, China: Springer, 2018. 466-477 [9] Ahmed, Chowdhury F. A novel approach for mining high-utility sequential patterns in sequence databases. Electronics and Telecommunications Research Institute, 2010, 32(5): 676-686 doi: 10.4218/etrij.10.1510.0066 [10] Yin J F, Zheng Z G, Cao L B. Uspan: An efficient algorithm for mining high utility sequential patterns. In: Proceeding of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York, USA: IEEE, 2012. 660-666 [11] Wang J Z, Huang J L, Chen Y C. On efficiently mining high utility sequential patterns. Knowledge and Information Systems, 2016, 49(2): 597-627 doi: 10.1007/s10115-015-0914-8 [12] Deng Z H, Ma S L, Li H. An efficient data structure for fast mining high utility itemset. Computer Science, 2015, 41: 214-223 doi: 10.1007/s10489-017-1130-x [13] Zhang B B, Jerry L, Philippe F V. Mining of high utility-probability sequential patterns from uncertain databases. Plos One, 2017, 12(7): e0180931 doi: 10.1371/journal.pone.0180931 [14] Zihayat M, Chen Y, An A. Memory-adaptive high utility sequential pattern mining over data streams. Machine Learning, 2017, 106: 799-836 doi: 10.1007/s10994-016-5617-1 [15] Zihayat M, Wu Cheng-Wei, An A. Efficiently mining high utility sequential patterns in static and streaming data. Intelligent Data Analysis, 2017, 21: 103-135 doi: 10.3233/IDA-170874 [16] Liu Meng-Chi, Qu Jun-Feng. Mining high utility itemsets without candidate generation. In: Proceedings of the 21st ACM International Conference on Information and Knowledge Management. Maui. USA: ACM, 2012. 55-64 [17] Philippe F V, Wu Cheng-Wei, Souleymane Z, Vincent S. FHM: faster high-utility itemset mining using estimated utility co-occurrence pruning. Intelligent Data Analysis, Switzerland: Springer, 2014. 83-92 [18] 王乐, 熊松泉, 常艳芬, 王水. 基于模式增长方式的高效用模式挖掘算法. 自动化学报, 2015, 41(9): 1616-1626 doi: 10.16383/j.aas.2015.c150056Wang Le, Xiong Song-Quan, Chang Yan-Fen, Wang Shui. An algorithm for mining high utility patterns based on pattern-growth. Acta Automatica Sinica, 2015, 41(9): 1616-1626 doi: 10.16383/j.aas.2015.c150056 [19] Philippe F V, Antonio G, Ted G. Spmf: a java open source pattern mining library. Journal of Machine Learning Research, 2014, 15: 3389-3393 [20] Zihayat M, Wu Cheng-Wei, An A. Efficient mining of high-utility sequential rule. In: Proceedings of Machine Learning and Data Mining. Hamburg, Germany: Springer, 2015. 157-171 [21] Martínez B M, Martínezá F, Troncoso A, Mining quantitative association rules based on evolutionary computation and its application to atmospheric pollution. Integrated Computer Aided Engineering, 2010, 17(3): 227-242 doi: 10.3233/ICA-2010-0340 [22] Vincent S T, Wu Cheng-Wei, Bai E S. UP-Growth: An efficient algorithm for high utility itemset mining. In: Proceedings of Knowledge Discovery and Data Mining. New York, USA: ACM, 2010. 253-262 -

 下载:
下载:
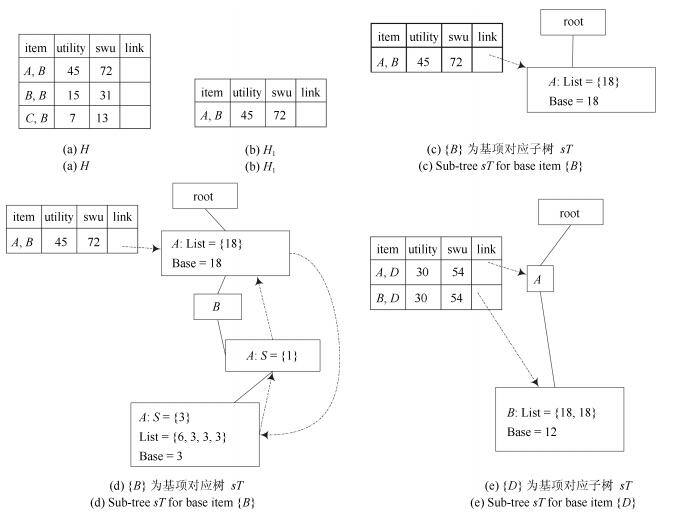
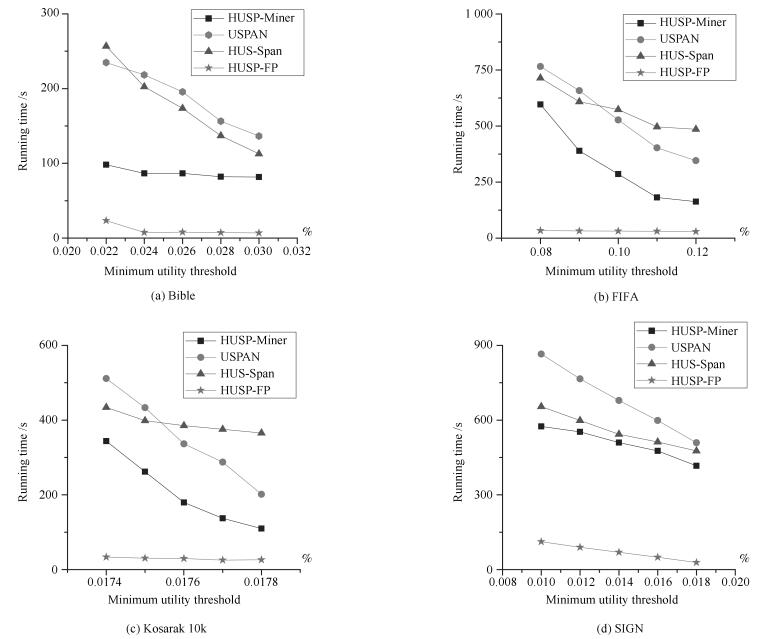
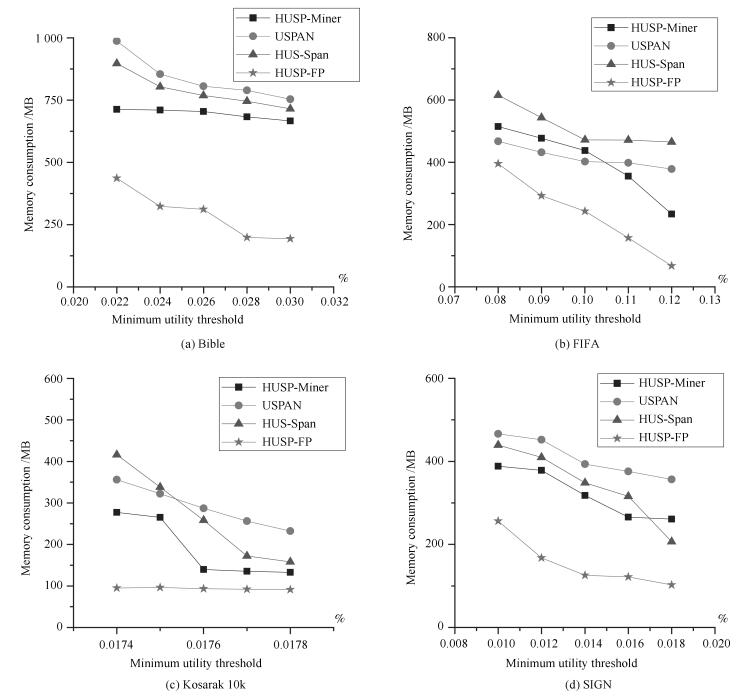
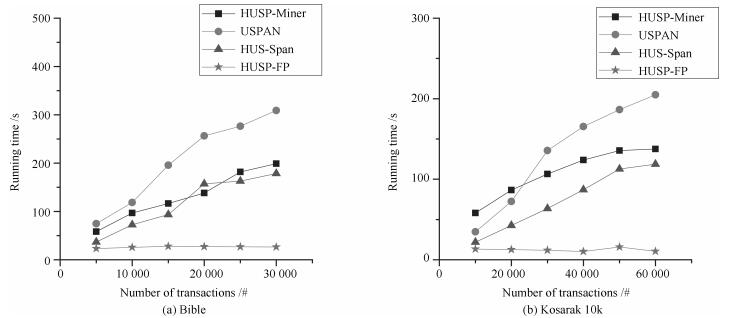

图(9) / 表(4)
计量
- 文章访问数: 1515
- HTML全文浏览量: 555
- PDF下载量: 217
- 被引次数: 0
