

-
摘要: 为了解决在线课程(Massive open online course, MOOC)授课过程中, 缺乏对于学生学习情况的跟踪与教学效果评估问题, 本文依据视频信息对学生行为进行建模, 提出了一种评判学生听课专心程度的行为自动分析算法.该算法能够有效跟踪学生的学习状态, 提取学生的行为特征参数, 并对这些参数进行D-S融合判决, 以获得学生的听课专注度.经过多次实验的结果表明, 本文采用的方法能够有效评判学生在授课期间的专心程度, 在数据融合上, 与贝叶斯推理方法相比, 采用D-S融合方法能有效提高实验结果的准确性和可靠性.Abstract: Aiming at solving the problems of students learning behavior tracking and instructors teaching evaluation in massive open online course (MOOC), a modeling approach of student attention is proposed first, then an automatic behavior analysis and decision making fusion algorithm (ABA) is proposed to evaluate the concentration of the students during lectures. The proposed method can effectively track the student' learning state and acquire the characteristic parameters of the student, and then give the concentration evaluation of the student after data fusion and decision making. Multiple experiments are carried out using the approach proposed in this paper, the results show that the proposed method can effectively reduce the uncertainty in student behavior decision making.
-
Key words:
- Student attention modeling /
- feature extraction /
- decision fusion /
- massive open online course (MOOC)
1) 本文责任编委 朱军 -
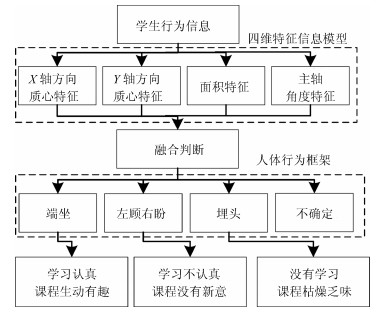
图 1 慕课授课过程中学生专注度自动检测与判定系统
Fig. 1 Automatic detection system on student focus during MOOC teaching
表 1 端坐时的基本概率赋值
Table 1 The probability distributions when sit up
$h_1$ $h_2$ $h_3$ $U$ $m(h_{1j1})$ 0 0.4444 0.4444 0.1112 $m(h_{1j2})$ 0 0.4528 0.4528 0.0944 $m(h_{1j3})$ 0 0.4528 0.4528 0.0944 $m(h_{2j1})$ 0.4444 0 0.4444 0.1112 $m(h_{2j2})$ 0.4528 0 0.4528 0.0944 $m(h_{2j3})$ 0.4528 0 0.4528 0.0944 $m(h_{3j1})$ 0.4444 0 0.4444 0.1112 $m(h_{3j2})$ 0.4528 0 0.4528 0.0944 $m(h_{3j3})$ 0.4528 0 0.4528 0.0944 $m(h_{4j1})$ 0 0 0.8888 0.1112 $m(h_{4j2})$ 0 0 0.9056 0.0944 $m(h_{4j3})$ 0 0 0.9056 0.0944  下载: 导出CSV
下载: 导出CSV
表 2 空间域融合后的结果
Table 2 The results of fusion in the spatial domain
$h_1$ $h_2$ $h_3$ $U$ $m(h_{j1})$ 0.0191 0.0036 0.9773 0 $m(h_{j2})$ 0.0142 0.0023 0.9834 0 $m(h_{j3})$ 0.0142 0.0023 0.9834 0
下载: 导出CSV
表 3 多维特征信息融合结果对比
Table 3 Comparison of multi-dimensional feature information fusion results
实验方法 实验结果 $m(h_{1})$ $m(h_{2})$ $m(h_{3})$ $m(U)$ $X+Y(baseline)$ 0.0042 0.0042 0.9916 0 $X+Y+S$ 0.0042 0 0.9958 0 $X+Y+S+\theta$ 0 0 0.9999 0
下载: 导出CSV
表 4 左顾右盼状态的基本概率赋值
Table 4 The probability distributions when look around
$h_1$ $h_2$ $h_3$ $U$ $m(h_{1j1})$ 0 0.4442 0.4442 0.1116 $m(h_{1j2})$ 0.6271 0.1394 0.1394 0.0942 $m(h_{1j3})$ 0.9058 0 0 0.0942 $m(h_{2j1})$ 0.4442 0 0.4442 0.1116 $m(h_{2j2})$ 0.4529 0 0.4529 0.0942 $m(h_{2j3})$ 0.0784 0.7490 0.0784 0.0942 $m(h_{3j1})$ 0.4442 0 0.4442 0.1116 $m(h_{3j2})$ 0.4529 0 0.4529 0.0942 $m(h_{3j3})$ 0.4529 0 0.4529 0.0942 $m(h_{4j1})$ 0.0261 0.0261 0.8361 0.1116 $m(h_{4j2})$ 0.3135 0.3135 0.2787 0.0942 $m(h_{4j3})$ 0.4529 0.4529 0 0.0942
下载: 导出CSV
表 5 空间域融合后的结果
Table 5 The results of fusion in the spatial domain
$h_1$ $h_2$ $h_3$ $U$ $m(h_{j1})$ 0.0249 0.0047 0.9704 0 $m(h_{j2})$ 0.7743 0.0047 0.2210 0 $m(h_{j3})$ 0.9228 0.0681 0.0091 0
下载: 导出CSV
表 6 埋头时的基本概率赋值
Table 6 The probability distributions when head drop
$h_1$ $h_2$ $h_3$ $U$ $m(h_{1j1})$ 0 0.4500 0.4500 0.1000 $m(h_{1j2})$ 0 0.4500 0.4500 0.1000 $m(h_{1j3})$ 0 0.4500 0.4500 0.1000 $m(h_{2j1})$ 0.2308 0.4385 0.2308 0.1000 $m(h_{2j2})$ 0 0.9000 0 0.1000 $m(h_{2j3})$ 0 0.9000 0 0.1000 $m(h_{3j1})$ 0.4269 0.0462 0.4269 0.1000 $m(h_{3j2})$ 0.2308 0.4385 0.2308 0.1000 $m(h_{3j3})$ 0 0.9000 0 0.1000 $m(h_{4j1})$ 0.2308 0.2308 0.4385 0.1000 $m(h_{4j2})$ 0.0923 0.0923 0.7154 0.1000 $m(h_{4j3})$ 0 0 0.9000 0.1000
下载: 导出CSV
表 7 空间域融合后的结果
Table 7 The results of fusion in the spatial domain
$h_1$ $h_2$ $h_3$ $U$ $m(h_{j1})$ 0.0658 0.2048 0.7294 0 $m(h_{j2})$ 0.0020 0.8131 0.1848 0 $m(h_{j3})$ 0 0.9221 0.0778 0
下载: 导出CSV
表 8 证据体的基本概率赋值(复杂状态实验1)
Table 8 Basic probability distribution of evidence bodies (Complex condition 1)
$h_1$ $h_2$ $h_3$ $U$ $m(h_{1j1})$ 0.1719 0.3617 0.3617 0.1048 $m(h_{1j2})$ 0.0859 0.4082 0.4082 0.0976 $m(h_{1j3})$ 0 0 0.4512 0.0976 $m(h_{2j1})$ 0.4333 0.0286 0.4333 0.1048 $m(h_{2j2})$ 0.4405 0.0215 0.4405 0.0976 $m(h_{2j3})$ 0.4512 0 0.4512 0.0976 $m(h_{3j1})$ 0.4369 0.0215 0.4369 0.1048 $m(h_{3j2})$ 0.4515 0 0.4512 0.0976 $m(h_{3j3})$ 0.4512 0.0430 0.4512 0.0976 $m(h_{4j1})$ 0.0645 0.0645 0.7663 0.1048 $m(h_{4j2})$ 0.0573 0.0573 0.7878 0.0976 $m(h_{4j3})$ 0 0 0.9024 0.0976
下载: 导出CSV
表 9 空间域融合后的结果(复杂状态实验1)
Table 9 Results of fusion in the spatial domain (Complex condition 1)
$h_1$ $h_2$ $h_3$ $U$ $m(h_{j1})$ 0.1003 0.0087 0.8910 0 $m(h_{j2})$ 0.0567 0.0056 0.9377 0 $m(h_{j3})$ 0.0151 0.0026 0.9823 0
下载: 导出CSV
表 10 证据体的基本概率赋值(复杂状态实验2)
Table 10 Basic probability distribution of evidence bodies (Complex condition 2)
$h_1$ $h_2$ $h_3$ $U$ $m(h_{1j1})$ 0.3027 0.2951 0.2951 0.1027 $m(h_{1j2})$ 0 0.4487 0.4487 0.1027 $m(h_{1j3})$ 0 0.4527 0.4527 0.0946 $m(h_{2j1})$ 0.4487 0 0.4487 0.1027 $m(h_{2j2})$ 0.1415 0.6144 0.1455 0.1027 $m(h_{2j3})$ 0 0.9054 0 0.0946 $m(h_{3j1})$ 0.4487 0 0.4487 0.1027 $m(h_{3j2})$ 0.1900 0.5174 0.1900 0.1027 $m(h_{3j3})$ 0 0.9054 0 0.0946 $m(h_{4j1})$ 0.3557 0.3557 0.1859 0.1027 $m(h_{4j2})$ 0.2425 0.2425 0.4123 0.1027 $m(h_{4j3})$ 0.4123 0.4123 0.0808 0.0946
下载: 导出CSV
表 11 空间域融合后的结果(复杂状态实验2)
Table 11 Results of fusion in the spatial domain (Complex condition 2)
$h_1$ $h_2$ $h_3$ $U$ $m(h_{j1})$ 0.6109 0.0162 0.3728 0 $m(h_{j2})$ 0.0164 0.7998 0.1837 0 $m(h_{j3})$ 0.0001 0.9973 0.0026 0
下载: 导出CSV
表 12 D-S推理方法和贝叶斯推理方法的对比
Table 12 Comparison of D-S inference and the Bayesian inference methods
对比实验 理论方法 $h_1$ $h_2$ $h_3$ $U$ 对比实验1 D-S理论 0.0001 0 0.9999 0 贝叶斯方法 0.2894 0.0415 0.6692 - 对比实验2 D-S理论 0.0001 0.9863 0.0136 0 贝叶斯方法 0.2705 0.5622 0.1673 -
下载: 导出CSV
-
[1] Wong K, Patzelt M, Poulette B, Hathaway R. Scenario-based learning in a MOOC specialization capstone on software product management. In: Proceedings of the IEEE/ACM 39th International Conference on Software Engineering Companion (ICSE-C). Buenos Aires, Argentina: IEEE, 2017. 317-318 https://www.researchgate.net/publication/318123881_Scenario-Based_Learning_in_a_MOOC_Specialization_Capstone_on_Software_Product_Management [2] Staubitz T, Willems C, Hagedorn C, Meinel C. The gamification of a MOOC platform. In: Proceedings of the 2017 IEEE Global Engineering Education Conference (EDUCON). Athens, Greece: IEEE, 2017. 383-892 http://www.researchgate.net/publication/316790928_The_Gamification_of_a_MOOC_Platform [3] Lei C U, Yeung Y C A, Kwok T T O, Lau R, Ang A. Leveraging videos and forums for small-class learning experience in a MOOC environment. In: Proceedings of the 2016 IEEE International Conference on Teaching, Assessment, and Learning for Engineering (TALE). Bangkok, Thailand: IEEE, 2016. 409-411 [4] Luo H, Millet A, Alley R, Zuo M. Dealing with ethical issues in MOOC design and delivery: a case study. In: Proceedings of the 2016 Blended Learning: Aligning Theory with Practices. ICBL 2016. Lecture Notes in Computer Science, vol. 9757. Cham, Switzerland: Springer, 2016. 128-138 doi: 10.1007/978-3-319-41165-1_12 [5] Kearney R C, Premaraj S, Smith B M, Olson G W, Williamson A E, Romanos G. Massive open online courses in dental education: two viewpoints: viewpoint 1: massive open online courses offer transformative technology for dental education and viewpoint 2: massive open online courses are not ready for primetime. Journal of Dental Education, 2016, 80(2): 121-127 http://cn.bing.com/academic/profile?id=1df6bb18edbf1e3bbb7a357ca961c6b1&encoded=0&v=paper_preview&mkt=zh-cn [6] Brinton C G, Buccapatnam S, Wong F M F, Chiang M, Poor H V. Social learning networks: efficiency optimization for MOOC forums. In: Proceedings of the IEEE INFOCOM 2016 — The 35th Annual IEEE International Conference on Computer Communications. San Francisco, USA: IEEE, 2016. 1-9 http://ieeexplore.ieee.org/document/7524579/ [7] Jaouedi N, Boujnah N, Htiwich O, Bouhlel M S. Human action recognition to human behavior analysis. In: Proceedings of the 7th International Conference on Sciences of Electronics, Technologies of Information and Telecommunications (SETIT). Hammamet, Tunisia: IEEE, 2016. 263-266 http://ieeexplore.ieee.org/abstract/document/7939877/ [8] Xiao B, Georgiou P, Baucom B, Narayanan S S. Head motion modeling for human behavior analysis in dyadic interaction. IEEE Transactions on Multimedia, 2015, 17(7): 1107-1119 doi: 10.1109/TMM.2015.2432671 [9] Tsai H C, Chuang C H, Tseng S P, Wang J F. The optical flow-based analysis of human behavior-specific system. In: Proceedings of the 1st International Conference on Orange Technologies (ICOT). Tainan, China: IEEE, 2013. 214-218 http://ieeexplore.ieee.org/document/6521195/ [10] Batchuluun G, Kim J H, Hong H G, Kang J K, Park K R. Fuzzy system based human behavior recognition by combining behavior prediction and recognition. Expert Systems with Applications, 2017, 81: 108-133 doi: 10.1016/j.eswa.2017.03.052 [11] Alonso J B, Cabrera J, Travieso C M, López-de-Ipiña K. First approach to continuous tracking of emotional temperature. In: Proceedings of the 4th International Work Conference on Bioinspired Intelligence (IWOBI). San Sebastian, Spain: IEEE, 2015. 177-184 http://ieeexplore.ieee.org/document/7160163/ [12] Hwang K A, Yang C H. Attentiveness assessment in learning based on fuzzy logic analysis. Expert Systems with Applications, 2009, 36(3): 6261-6265 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=CC025018788 [13] Durucan E, Ebrahimi T. Moving object detection between multiple and color images. In: Proceedings of the 2013 IEEE Conference on Advanced Video and Signal Based Surveillance. Miami, FL, USA: IEEE, 2003. 243-251 http://ieeexplore.ieee.org/xpls/icp.jsp?arnumber=1217928 [14] Hu M J, Liu Z, Zhang J Y, Zhang G J. Robust object tracking via multi-cue fusion. Signal Processing, 2017, 139: 86-95 http://cn.bing.com/academic/profile?id=90bbb8ab657b7b82722022921f518324&encoded=0&v=paper_preview&mkt=zh-cn [15] Zhang P, Zhuo T, Huang W, Chen K L, Kankanhalli M. Online object tracking based on CNN with spatial-temporal saliency guided sampling. Neurocomputing, 2017, 257: 115-127 doi: 10.1016/j.neucom.2016.10.073 [16] Bilge Y C, Kaya F, Cinbis N İ, Celikcan U, Sever H. Anomaly detection using improved background subtraction. In: Proceedings of the 25th Signal Processing and Communications Applications Conference (SIU). Antalya, Turkey: IEEE, 2017. 1-4 http://ieeexplore.ieee.org/document/7960592/ [17] Elyounsi A, Tlijani H, Bouhlel M S. Shape detection by mathematical morphology techniques for radar target classification. In: Proceedings of the 17th International Conference on Sciences and Techniques of Automatic Control and Computer Engineering (STA). Sousse, Tunisia: IEEE, 2016. 352-356 https://ieeexplore.ieee.org/document/7952078/ [18] Shi X S, Huang Y J, Liu Y G. Text on Oracle rubbing segmentation method based on connected domain. In: Proceedings of the 2016 IEEE Advanced Information Management, Communicates, Electronic and Automation Control Conference. Xi'an, China: IEEE, 2016. 414-418 http://ieeexplore.ieee.org/abstract/document/7867245/ [19] Shi H B, Yang S Y, Cao Z L, Pan W, Li W H. An improved evidence combination method of D-S theory. In: Proceedings of the 2016 International Symposium on Computer, Consumer and Control. Xi'an, China: IEEE, 2016. 319-322 http://ieeexplore.ieee.org/document/7545200/ [20] Chu Q, Ouyang W L, Li H S, Wang X G, Liu B, Yu N H. Online multi-object tracking using CNN-based single object tracker with spatial-temporal attention mechanism. In: Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV). Venice, Italy: IEEE. 2017. 4846-4855 -

 下载:
下载:









计量
- 文章访问数: 3582
- HTML全文浏览量: 753
- PDF下载量: 385
- 被引次数: 0
