

-
摘要: 基于学习的图像超分辨率(Super-resolution,SR)算法利用样本先验知识来重建图像,相较于其他重建方法拥有明显的优势,也是近年来研究的热点.论文首先分析了影响图像重建质量的因素,然后对基于卷积神经网络的图像超分辨率重建算法(Super-resolution convolutional neural network,SRCNN)提出了两点改进:我们用随机线性纠正单元(Randomized rectified linear unit,RReLU)去避免原有网络学习中对图像某些重要的信息过压缩,同时我们用NAG(Nesterov's accelerated gradient)方法去加速网络的收敛并且避免了网络在梯度更新的时候产生较大的震荡.最后通过实验验证了我们改进网络可以获得更好的主观视觉评价和客观量化评价.Abstract: Learning-based image super-resolution method is a research hotspot in recent years which uses prior knowledge of sample to reconstruct the image and has obvious advantages over other reconstruction methods. In this paper, we first analyze the factors of reconstructed image quality. Then we use randomized rectified linear unit (RReLU) to solve the problem of over compression in the original network. Besides, Nesterov's accelerated gradient (NAG) is invoked to accelerate convergence and avoid large oscillations. Finally, we conduct a quantitative experiments to prove the validity of the proposed algorithm.
-
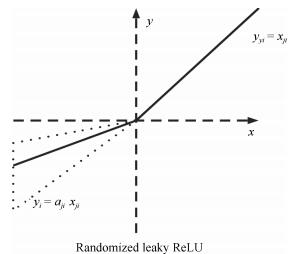
图 2 RReLU函数的示意图
(其中 $a_{ji}$ 为在抽样给定范围类的一个随机变量, 同时为了方便, 在测试阶段, 我们通常根据实际情况取一个固定值来进行测试)
Fig. 2 An illustration of RReLU
( $a_{ji}$ is a random variable of in the given sampling scope. And in the testing phase, we usually take a fixed value to test according to actual condition.)
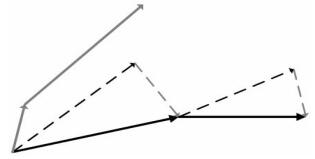
图 4 NAG方法更新方法示意
(首先按照原有路径方向更新一个步长(黑色虚线向量), 计算该位置的梯度值(灰色虚线向量), 然后用这个梯度值进行修正, 得到最终的更新方向(黑色实线向量).图中描述了NAG更新两步的示意图, 其中灰色实线向量表示CM方法更新路径)
Fig. 4 An illustration of NAG method
(which updates a step (the black dotted line vector in the figure) according to the original path direction, firstly. Then calculating the gradient value of the current position and correcting the update path (the gray dotted line vector in the figure). The black line vector is the final path of NAG and the gray line vector is the update path of CM.)
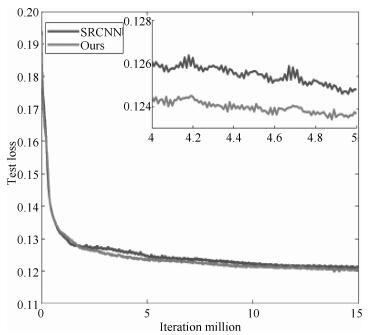
图 5 在Set 5测试集上, 随着迭代系数的增加, 不同方法的Test Loss曲线图
Fig. 5 The curve of Test Loss in Set 5 for different methods with the number of iterations increasing
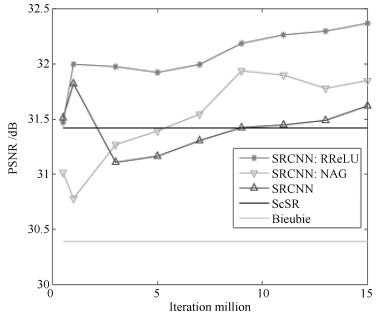
图 6 在Set 5测试集上, 随着迭代系数的增加, 不同方法的平均PSNR (dB)值的走势
Fig. 6 The average value of PSNR (dB) for different methods with the number of iterations increasing
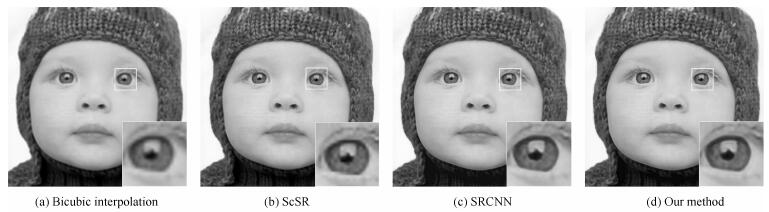
图 7 Set 5中的Baby_GT重建对比图
Fig. 7 The quality of reconstruction comparison for image Baby_GT in Set 5

图 8 Set 5中的Bird_GT重建对比图
Fig. 8 The quality of reconstruction comparison for image Bird_GT in Set 5
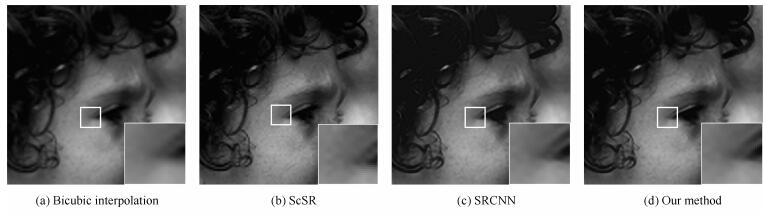
图 9 Set 14中的Face重建对比图
Fig. 9 The quality of reconstruction comparison for image Face in Set 14
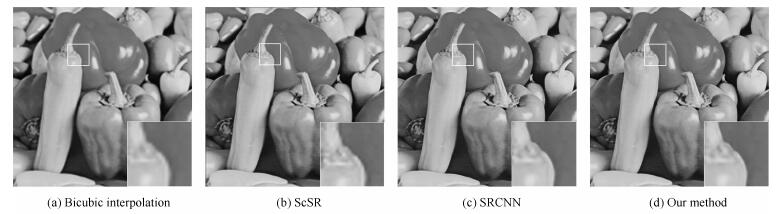
图 10 Set 14中的Pepper重建对比图
Fig. 10 The quality of reconstruction comparison for image Pepper in Set 14
-
[1] Tsai R Y, Huang T S. Multiple frame image restoration and registration. Advances in Computer Vision and Image Processing. Greenwich: JAI, 1984. 317-339 [2] Baker S, Kanade T. Limits on super-resolution and how to break them. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2002, 24(9): 1167-1183 [3] 苏衡, 周杰, 张志浩.超分辨率图像重建方法综述.自动化学报, 2013, 39(8): 1202-1213 http://www.aas.net.cn/CN/abstract/abstract18151.shtmlSu Heng, Zhou Jie, Zhang Zhi-Hao. Survey of super-resolution image reconstruction methods. Acta Automatica Sinica, 2013, 39(8): 1202-1213 http://www.aas.net.cn/CN/abstract/abstract18151.shtml [4] Zhou F, Yang W M, Liao Q M. Interpolation-based image super-resolution using multisurface fitting. IEEE Transactions on Image Processing, 2012, 21(7): 3312-3318 doi: 10.1109/TIP.2012.2189576 [5] Lin Z C, Shum H Y. Fundamental limits of reconstruction-based superresolution algorithms under local translation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2004, 26(1): 83-97 doi: 10.1109/TPAMI.2004.1261081 [6] 潘宗序, 禹晶, 胡少兴, 孙卫东.基于多尺度结构自相似性的单幅图像超分辨率算法.自动化学报, 2014, 40(4): 594-603 http://www.aas.net.cn/CN/abstract/abstract18325.shtmlPan Zong-Xu, Yu Jing, Hu Shao-Xing, Sun Wei-Dong. Single image super resolution based on multi-scale structural self-similarity. Acta Automatica Sinica, 2014, 40(4): 594-603 http://www.aas.net.cn/CN/abstract/abstract18325.shtml [7] 练秋生, 石保顺, 陈书贞.字典学习模型、算法及其应用研究进展.自动化学报, 2015, 41(2): 240-260 http://www.aas.net.cn/CN/abstract/abstract18604.shtmlLian Qiu-Sheng, Shi Bao-Shun, Chen Shu-Zhen. Research advances on dictionary learning models, algorithms and applications. Acta Automatica Sinica, 2015, 41(2): 240-260 http://www.aas.net.cn/CN/abstract/abstract18604.shtml [8] Freeman W T, Jones T R, Pasztor E C. Example-based super-resolution. IEEE Computer Graphics and Applications, 2002, 22(2): 56-65 doi: 10.1109/38.988747 [9] Polatkan G, Zhou M Y, Carin L, Blei D, Daubechies I. A Bayesian nonparametric approach to image super-resolution. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(2): 346-358 doi: 10.1109/TPAMI.2014.2321404 [10] Yang J C, Wright J, Huang T S, Ma Y. Image super-resolution via sparse representation. IEEE Transactions on Image Processing, 2010, 19(11): 2861-2873 doi: 10.1109/TIP.2010.2050625 [11] Yu D, Deng L. Deep learning and its applications to signal and information processing. IEEE Signal Processing Magazine, 2011, 28(1): 145-154 doi: 10.1109/MSP.2010.939038 [12] Yu D, Deng L, Seide F. The deep tensor neural network with applications to large vocabulary speech recognition. IEEE Transactions on Audio, Speech, and Language Processing, 2013, 21(2): 388-396 doi: 10.1109/TASL.2012.2227738 [13] Hutchinson B, Deng L, Yu D. Tensor deep stacking networks. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35(8): 1944-1957 doi: 10.1109/TPAMI.2012.268 [14] Dong C, Loy C C, He K M, Tang X O. Image super-resolution using deep convolutional networks. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2016, 38(2): 295-307 doi: 10.1109/TPAMI.2015.2439281 [15] Cui Z, Chang H, Shan S G, Zhong B E, Chen X L. Deep network cascade for image super-resolution. In: Proceedings of the 13th European Conference on Computer Vision. Zurich, Switzerland: Springer, 2014. 49-64 [16] Xu B, Wang N Y, Chen T Q, Li M. Empirical evaluation of rectified activations in convolutional network. In: Proceedings of the 32th International Conference on Machine Learning: Deep Learning Workshop. Lille, France: ICML, 2015. [17] Nesterov Y. A method of solving a convex programming problem with convergence rate O(1/k2). Soviet Mathematics Doklady, 1983, 27(2): 372-376 [18] Sutskever I, Martens J, Dahl G, Hinton G. On the importance of initialization and momentum in deep learning. In: Proceedings of the 30th International Conference on Machine Learning. Atlanta, Georgia, USA: JMLR, 2013. 1139-1147 [19] Jia Y Q, Shelhamer E, Donahue J, Karayev S, Long J, Girshick R, Guadarrama S, Darrell T. Caffe: convolutional architecture for fast feature embedding. In: Proceedings of the 22nd ACM International Conference on Multimedia. Orlando, Florida, USA: ACM, 2014. 675-678 [20] Nair V, Hinton G F. Rectified linear units improve restricted Boltzmann machines. In: Proceedings of the 27th International Conference on Machine Learning. Haifa, Israel: ICML, 2010. 807-814 [21] Nesterov Y. Introductory Lectures on Convex Optimization: A Basic Course. US: Springer, 2004. 63-66 [22] Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks. In: Proceedings of the 26th Annual Conference on Neural Information Processing Systems. Lake Tahoe, USA: Curran Associates, Inc., 2012. 25(2): 1097-1105 [23] He K M, Zhang X Y, Ren S Q, Sun J. Delving deep into rectifiers: surpassing human-level performance on ImageNet classification. In: Proceedings of the 2015 IEEE International Conference on Computer Vision. Santiago, Chile: IEEE, 2015. 1026-1034 [24] Lan G H. An optimal method for stochastic composite optimization. Mathematical Programming, 2012, 133(1-2): 365-397 doi: 10.1007/s10107-010-0434-y [25] Bevilacqua M, Roumy A, Guillemot C, Morel M L A. Low-complexity single-image super-resolution based on nonnegative neighbor embedding. In: Proceedings of the 2012 British Machine Vision Conference. Guildford, UK: University of Surrey, 2012. [26] Zeyde R, Elad M, Protter M. On single image scale-up using sparse-representations. In: Proceedings of the 7th International Conference on Curves and Surfaces. Avignon, France: Springer, 2010. 711-730 -

 下载:
下载:


计量
- 文章访问数: 3486
- HTML全文浏览量: 1186
- PDF下载量: 1920
- 被引次数: 0
