

-
摘要: 强化学习是一类特殊的机器学习, 通过与所在环境的自主交互来学习决策策略, 使得策略收到的长期累积奖赏最大. 最近, 在围棋和电子游戏等领域, 强化学习被成功用于取得人类水平的操作能力, 受到了广泛关注. 本文将对强化学习进行简要介绍, 重点介绍基于函数近似的强化学习方法, 以及在围棋等领域中的应用.Abstract: Reinforcement learning is a particular type of machine learning that autonomously learns from interactions with the environment, so that its long-term reward is maximized. It has recently been successfully applied to playing the game of Go and video games, and human expert level is demonstrated. Since these results are receiving increasing attentions, this paper briefly introduces reinforcement learning, focusing on the methods with function approximation, and its applications in the game of Go.
-
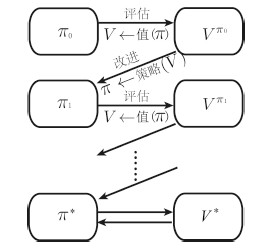
图 2 广义策略迭代:值函数与策略交互直到最优
Fig. 2 General value iteration: iterative update between the value function and the policy until convergence
表 1 经典算法中值函数更新公式的区别与联系
Table 1 Updating formulas in classical reinforcement learning
算法 f ωt ω' TD V st st+1 Sarsa Q (st,at) (st+1,at+1) Q学习 Q (st,at) ({s_{t+1}},\arg \mathop {\max }\limits_{a' \in A} Q({s_{t+1}},a'))  下载: 导出CSV
下载: 导出CSV
-
[1] 周志华. 机器学习. 北京: 清华大学出版社, 2016.Zhou Zhi-Hua. Machine Learning. Beijing: Tsinghua University Press, 2016. [2] Sutton R S, Barto A G. Reinforcement Learning: an Introduction. Cambridge, MA: MIT Press, 1998. [3] 高阳, 陈世福, 陆鑫. 强化学习研究综述. 自动化学报, 2004, 30(1): 86-100Gao Yang, Chen Shi-Fu, Lu Xin. Research on reinforcement learning technology: a review. Acta Automatica Sinica, 2004, 30(1): 86-100 [4] Sutton R S. Learning to predict by the methods of temporal differences. Machine Learning, 1988, 3(1): 9-44 [5] Dayan P. The convergence of TD (λ) for general λ. Machine Learning, 1992, 8(3-4): 341-362 [6] Singh S, Jaakkola T, Littman M L, Szepesvári C. Convergence results for single-step on-policy reinforcement-learning algorithms. Machine Learning, 2000, 38(3): 287-308 [7] Watkins C J C H, Dayan P. Q-learning. Machine Learning, 1992, 8(3-4): 279-292 [8] Jaakkola T, Jordan M I, Singh S P. On the convergence of stochastic iterative dynamic programming algorithms. Neural Computation, 1994, 6(6): 1185-1201 [9] Tsitsiklis J N. Asynchronous stochastic approximation and Q-learning. Machine Learning, 1994, 16(3): 185-202 [10] Barto A G, Mahadevan S. Recent advances in hierarchical reinforcement learning. Discrete Event Dynamic Systems, 2003, 13(4): 341-379 [11] Dietterich T G. Hierarchical reinforcement learning with the MAXQ value function decomposition. Journal of Artificial Intelligence Research, 2000, 13: 227-303 [12] Dietterich T G. The MAXQ method for hierarchical reinforcement learning. In: Proceedings of the 15th International Conference on Machine Learning. San Francisco, CA: Morgan Kaufmann, 1998. 118-126 [13] Morimoto J, Doya K. Acquisition of stand-up behavior by a real robot using hierarchical reinforcement learning. Robotics and Autonomous Systems, 2001, 36(1): 37-51 [14] Dietterich T G. An overview of MAXQ hierarchical reinforcement learning. In: Proceedings of the 4th International Symposium on Abstraction, Reformulation, and Approximation. Horseshoe Bay, USA: Springer, 2000. 26-44 [15] Marthi B, Russell S, Latham D, Guestrin C. Concurrent hierarchical reinforcement learning. In: Proceedings of the 19th International Joint Conference on Artificial Intelligence. San Francisco, CA, USA: Morgan Kaufmann Publishers Inc., 2005. 779-785 [16] Hengst B. Discovering hierarchy in reinforcement learning with HEXQ. In: Proceedings of the 19th International Conference on Machine Learning. San Francisco: Morgan Kaufmann Publishers, 2002. 243-250 [17] Mehta N, Natarajan S, Tadepalli P, Fern A. Transfer in variable-reward hierarchical reinforcement learning. Machine Learning, 2008, 73(3): 289-312 [18] Ravindran B, Barto A G. Model minimization in hierarchical reinforcement learning. In: Proceedings of the 5th International Symposium on Abstraction, Reformulation, and Approximation. Kananaskis, Alberta, Canada: Springer, 2002. 196-211 [19] Ghavamzadeh M, Mahadevan S. Continuous-time hierarchical reinforcement learning. In: Proceedings of the 18th International Conference on Machine Learning. San Francisco, CA: Morgan Kaufmann Publishers Inc., 2001. 186-193 [20] Goel S, Huber M. Subgoal discovery for hierarchical reinforcement learning using learned policies. In: Proceedings of the 16th International FLAIRS Conference. St. Augustine, Florida, USA: AAAI, 2003. 346-350 [21] Taylor M E, Whiteson S, Stone P. Transfer via inter-task mappings in policy search reinforcement learning. In: Proceedings of the 6th International Joint Conference on Autonomous Agents and Multi-agent Systems. New York: ACM, 2007. Article No. 37 [22] Taylor M, Stone P. Transfer learning for reinforcement learning domains: a survey. The Journal of Machine Learning Research, 2009, 10: 1633-1685 [23] Konidaris G, Barto A G. Building portable options: skill transfer in reinforcement learning. In: Proceedings of the 20th International Joint Conference on Artificial Intelligence. Hyderabad, India: AAAI, 2007. 895-900 [24] Taylor M E, Stone P. Behavior transfer for value-function-based reinforcement learning. In: Proceedings of the 4th International Joint Conference on Autonomous Agents and Multiagent Systems. Utrecht, The Netherlands: ACM Press, 2005. 53-59 [25] Taylor M E, Stone P. Cross-domain transfer for reinforcement learning. In: Proceedings of the 24th International Conference on Machine Learning. New York, NY, USA: ACM, 2007. 879-886 [26] Liu Y X, Stone P. Value-function-based transfer for reinforcement learning using structure mapping. In: Proceedings of the 21st National Conference on Artificial Intelligence. Boston, MA: AAAI, 2006. 415-420 [27] Torrey L, Walker T, Shavlik J, Maclin R. Using advice to transfer knowledge acquired in one reinforcement learning task to another. In: Proceedings of the 16th European Conference on Machine Learning on Machine Learning: ECML 2005. Porto, Portugal: Springer, 2005. 412-424 [28] Mahadevan S. Enhancing transfer in reinforcement learning by building stochastic models of robot actions. In: Proceedings of the 9th International Workshop on Machine Learning. San Francisco, CA, USA: Morgan Kaufmann Publishers Inc., 1992. 290-299 [29] Torrey L, Shavlik J, Walker T, Maclin R. Relational macros for transfer in reinforcement learning. In: Proceedings of the 17th International Conference on Inductive Logic Programming. Corvallis, OR, USA: Springer, 2008. 254-268 [30] 王皓, 高阳, 陈兴国. 强化学习中的迁移: 方法和进展. 电子学报, 2008, 36(12A): 39-43Wang Hao, Gao Yang, Chen Xing-Guo. Transfer of reinforcement learning: the state of the art. Acta Electronica Sinica, 2008, 36(12A): 39-43 [31] Bertsekas D P, Tsitsiklis J N, Tsitsiklis J. Neuro-dynamic Programming. Athens, Greece: Athena Scientific Press, 1996. [32] Bradtke S J. Incremental Dynamic Programming for On-line Adaptive Optimal Control [Ph.D. dissertation], University of Massachusetts, USA, 1995. [33] Bradtke S J, Barto A G. Linear least-squares algorithms for temporal difference learning. Machine Learning, 1996, 22(1): 33-57 [34] Boyan J A. Technical update: least-squares temporal difference learning. Machine Learning, 2002, 49(2): 233-246 [35] Lagoudakis M G, Parr R. Least-squares policy iteration. The Journal of Machine Learning Research, 2003, 4: 1107-1149 [36] Silver D, Sutton R S, Müller M. Reinforcement learning of local shape in the game of Go. In: Proceedings of the 20th International Joint Conferences on Artificial Intelligence. San Francisco, CA, USA: Morgan Kaufmann Publishers Inc., 2007. 1053-1058 [37] Silver D, Sutton R S, Müller M. Temporal-difference search in computer Go. Machine Learning, 2012, 87(2): 183-219 [38] Geramifard A, Bowling M H, Zinkevich M, Sutton R S. iLSTD: eligibility traces and convergence analysis. In: Advances in Neural Information Processing Systems 19. Cambridge, MA: MIT Press, 2006. 441-448 [39] Sutton R S, Maei H R, Precup D, Bhatnagar S, Silver D, Szepesvári C, Wiewiora E. Fast gradient-descent methods for temporal-difference learning with linear function approximation. In: Proceedings of the 26th Annual International Conference on Machine Learning. New York: ACM, 2009. 993-1000 [40] Sutton R S, McAllester D, Singh S, Mansour Y. Policy gradient methods for reinforcement learning with function approximation. In: Advances in Neural Information Processing Systems 12. Cambridge, MA: MIT Press, 1999. 1057-1063 [41] Kakade S M. A natural policy gradient. In: Advances in Neural Information Processing Systems 14. Cambridge, MA: MIT Press 2001. 1531-1538 [42] Peters J, Schaal S. Natural actor-critic. Neurocomputing, 2008, 71(7-9): 1180-1190 [43] Böhm N, Kókai G, Mandl S. An evolutionary approach to Tetris. In: Proceedings of the 6th Metaheuristics International Conference (MIC2005). Vienna, Austria, 2005. [44] Szita I, Lörincz A. Learning Tetris using the noisy cross-entropy method. Neural Computation, 2006, 18(12): 2936-2941 [45] Thiery C, Scherrer B. Improvements on learning Tetris with cross entropy. International Computer Games Association Journal, 2009, 32(1): 23-33 [46] Least-squares methods in reinforcement learning for control. In: Proceedings of the 2nd Hellenic Conference on AI, SETN, Methods and Applications of Artificial Intelligence. Thessaloniki, Greece, 2002. 249-260 [47] Thiery C, Scherrer B. Least-squares λ policy iteration: bias-variance trade-off in control problems. In: Proceedings of the 27th International Conference on Machine Learning (ICML-10). Haifa, Israel, 2010. 1071-1078 [48] Scherrer B. Performance bounds for λ policy iteration and application to the game of Tetris. The Journal of Machine Learning Research, 2013, 14: 1181-1227 [49] Gabillon V, Ghavamzadeh M, Scherrer B. Approximate dynamic programming finally performs well in the game of Tetris. In: Advances in Neural Information Processing Systems 26. Lake Tahoe, Nevada, USA: Curran Associates, Inc., 2013. 1754-1762 [50] Scherrer B, Ghavamzadeh M, Gabillon V, Lesner B, Geist M. Approximate modified policy iteration and its application to the game of Tetris. The Journal of Machine Learning Research, 2015, 16(1): 1629-1676 [51] Tsitsiklis J N, Van Roy B. An analysis of temporal-difference learning with function approximation. IEEE Transactions on Automatic Control, 1997, 42(5): 674-690 [52] Baird L. Residual algorithms: reinforcement learning with function approximation. In: Proceedings of the 12th International Conference on Machine Learning. San Francisco: Morgan Kaufmann, 1995. 30-37 [53] Sutton R S, Szepesvári C, Maei H R. A convergent O(n) algorithm for off-policy temporal-difference learning with linear function approximation. In: Proceedings of the 21st Advances in Neural Information Processing Systems. Cambridge, MA: MIT Press, 2008. 1609-1616 [54] Maei H R, Sutton R S. GQ(λ): a general gradient algorithm for temporal-difference prediction learning with eligibility traces. In: Proceedings of the 3rd Conference on Artificial General Intelligence. Paris: Atlantis Press, 2010. 91-96 [55] Maei H R, Szepesvái C, Bhatnagar S, Sutton R S. Toward off-policy learning control with function approximation. In: Proceedings of the 27th International Conference on Machine Learning. Haifa, Israel, 2010. 719-726 [56] Geramifard A, Bowling M, Sutton R S. Incremental least-squares temporal difference learning. In: Proceedings of the 21st AAAI Conference on Artificial Intelligence. Boston, MA: AAAI, 2006. 356-361 [57] Loth M, Davy M, Preux P. Sparse temporal difference learning using LASSO. In: Proceedings of the 2007 IEEE International Symposium on Approximate Dynamic Programming and Reinforcement Learning. Honolulu, HI: IEEE, 2007. 352-359 [58] Kolter J Z, Ng A Y. Regularization and feature selection in least-squares temporal difference learning. In: Proceedings of the 26th Annual International Conference on Machine Learning. New York, NY, USA: ACM 2009. 521-528 [59] Hoffman M W, Lazaric A, Ghavamzadeh M, Munos R. Regularized least squares temporal difference learning with nested l2 and l1 penalization. In: Proceedings of the 9th European Workshop on Recent Advances in Reinforcement Learning. Athens, Greece: Springer, 2012. 102-114 [60] Ghavamzadeh M, Lazaric A, Munos R, Hoffman M. Finite-sample analysis of lasso-TD. In: Proceedings of the 28th International Conference on Machine Learning. Bellevue, Washington, USA, 2011. 1177-1184 [61] Geist M, Scherrer B, Lazaric A, Ghavamzadeh M. A Dantzig selector approach to temporal difference learning. In: Proceedings of the 29th International Conference on Machine Learning. Edinburgh, Scotland, UK, 2012. [62] Ghavamzadeh M, Lazaric A, Maillard O A, Munos R. LSTD with random projections. In: Advances in Neural Information Processing Systems 23. Vancouver, British Columbia, Canada: Curran Associates, Inc., 2010. 721-729 [63] Bertsekas D P. Temporal difference methods for general projected equations. IEEE Transactions on Automatic Control, 2011, 56(9): 2128-2139 [64] Ormoneit D, Sen Ś. Kernel-based reinforcement learning. Machine Learning, 2002, 49(2-3): 161-178 [65] Schneegaβ D, Udluft S, Martinetz T. Kernel rewards regression: an information efficient batch policy iteration approach. In: Proceedings of the 24th IASTED International Multi-Conference on Artificial Intelligence and Applications. Innsbruck, Austria, 2006. 428-433 [66] Jong N K, Stone P. Kernel-based models for reinforcement learning. In: Proceedings of the ICML-06 Workshop on Kernel Machines for Reinforcement Learning. Pittsburgh, PA, 2006. [67] Deisenroth M P, Peters J, Rasmussen C E. Approximate dynamic programming with Gaussian processes. In: Proceedings of the 2008 American Control Conference. Seattle, WA: IEEE, 2008. 4480-4485 [68] Reisinger J, Stone P, Miikkulainen R. Online kernel selection for Bayesian reinforcement learning. In: Proceedings of the 25th International Conference on Machine Learning. Helsinki, Finland, 2008. 816-823 [69] Antos A, Szepesvári C, Munos R. Learning near-optimal policies with Bellman-residual minimization based fitted policy iteration and a single sample path. Machine Learning, 2008, 71(1): 89-129 [70] Bethke B, How J P, Ozdaglar A. Kernel-based reinforcement learning using Bellman residual elimination. Journal of Machine Learning Research, to be published [71] Bethke B, How J P. Approximate dynamic programming using Bellman residual elimination and Gaussian process regression. In: Proceedings of the 2009 American Control Conference. St. Louis, MO: IEEE, 2009. 745-750 [72] Taylor G, Parr R. Kernelized value function approximation for reinforcement learning. In: Proceedings of the 26th Annual International Conference on Machine Learning. Montreal, Quebec, Canada, 2009. 1017-1024 [73] Kroemer O B, Peters J. A non-parametric approach to dynamic programming. In: Proceedings of Advances in Neural Information Processing Systems 24. Granada, Spain: Curran Associates, Inc., 2011. 1719-1727 [74] Engel Y, Mannor S, Meir R. Bayes meets Bellman: the Gaussian process approach to temporal difference learning. In: Proceedings of the 20th International Conference on Machine Learning. Washington DC: AAAI, 2003. 154-161 [75] Engel Y, Mannor S, Meir R. Reinforcement learning with Gaussian processes. In: Proceedings of the 22nd International Conference on Machine Learning. Bonn, Germany, 2005. 201-208 [76] Xu X. A sparse kernel-based least-squares temporal difference algorithm for reinforcement learning. In: Proceedings of the 2nd International Conference on Advances in Natural Computation. Xi'an, China: Springer, 2006. 47-56 [77] Xu X, Hu D W, Lu X C. Kernel-based least squares policy iteration for reinforcement learning. IEEE Transactions on Neural Networks, 2007, 18(4): 973-992 [78] Orabona F, Keshet J, Caputo B. The projectron: a bounded kernel-based perceptron. In: Proceedings of the 25th International Conference on Machine Learning. Helsinki, Finland: ACM, 2008. 816-823 [79] Orabona F, Keshet J, Caputo B. Bounded kernel-based online learning. The Journal of Machine Learning Research, 2009, 10: 2643-2666 [80] Robards M, Sunehag P, Sanner S, Marthi B. Sparse Kernel-SARSA (λ) with an eligibility trace. In: Proceedings of the 22nd European Conference on Machine Learning and Knowledge Discovery in Databases. Athens, Greece: Springer, 2011. 1-17 [81] Chen X G, Gao Y, Wang R L. Online selective kernel-based temporal difference learning. IEEE Transactions on Neural Networks and Learning Systems, 2013, 24(12): 1944-1956 [82] 汪洪桥, 孙富春, 蔡艳宁, 陈宁, 丁林阁. 多核学习方法. 自动化学报, 2010, 36(8): 1037-1050Wang Hong-Qiao, Sun Fu-Chun, Cai Yan-Ning, Chen Ning, Ding Lin-Ge. On multiple kernel learning methods. Acta Automatica Sinica, 2010, 36(8): 1037-1050 [83] Orabona F, Jie L, Caputo B. Multi kernel learning with online-batch optimization. The Journal of Machine Learning Research, 2012, 13: 227-253 [84] Tobar F A, Kung S-Y, Mandic D P. Multikernel least mean square algorithm. IEEE Transactions on Neural Networks and Learning Systems, 2014, 25(2): 265-277 [85] Kersting K, Driessens K. Non-parametric policy gradients: a unified treatment of propositional and relational domains. In: Proceedings of the 25th International Conference on Machine Learning (ICML'08). Helsinki, Finland: ACM, 2008. 456-463 [86] Yu Y, Hou P-F, Da Q, Qian Y. Boosting nonparametric policies. In: Proceedings of the 15th International Conference on Autonomous Agents and Multiagent Systems (AAMAS'16). Singapore, 2016. [87] Da Q, Yu Y, Zhou Z-H. Napping for functional representation of policy. In: Proceedings of the 13th International Conference on Autonomous Agents and Multi-Agent Systems (AAMAS'14). Paris, France, 2014. 189-196 [88] Tesauro G. TD-Gammon, a self-teaching backgammon program, achieves master-level play. Neural Computation, 1994, 6(2): 215-219 [89] Tesauro G. Temporal difference learning and TD-Gammon. Communications of the ACM, 1995, 38(3): 58-68 [90] Hinton G E, Osindero S, Teh Y-W. A fast learning algorithm for deep belief nets. Neural Computation, 2006, 18(7): 1527-1554 [91] LeCun Y, Bengio Y, Hinton G. Deep learning. Nature, 2015, 521(7553): 436-444 [92] Lange S, Riedmiller M. Deep auto-encoder neural networks in reinforcement learning. In: Proceedings of the 2010 International Joint Conference on Neural Networks (IJCNN). Barcelona: IEEE, 2010. 1-8 [93] Riedmiller M, Braun H. A direct adaptive method for faster backpropagation learning: the RPROP algorithm. In: Proceedings of the IEEE International Conference on Neural Networks. San Francisco, CA: IEEE, 1993. 586-591 [94] Mnih V, Kavukcuoglu K, Silver D, Graves A, Antonoglou I, Wierstra D, Riedmiller M. Playing Atari with deep reinforcement learning. In: Proceedings of Deep Learning, Neural Information Processing Systems Workshop. Harrahs and Harveys, Lake Tahoe, USA, 2013. [95] Mnih V, Kavukcuoglu K, Silver D, Rusu A A, Veness J, Bellemare M G, Graves A, Riedmiller M, Fidjeland A K, Ostrovski G, Petersen S, Beattie C, Sadik A, Antonoglou I, King H, Kumaran D, Wierstra D, Legg S, Hassabis D. Human-level control through deep reinforcement learning. Nature, 2015, 518(7540): 529-533 [96] Oh J, Guo X X, Lee H, Lewis R, Singh S. Action-conditional video prediction using deep networks in Atari games. In: Proceedings of Advances in Neural Information Processing Systems 28. Montreal, Quebec, Canada, 2015. 2845-2853 [97] Guo X X, Singh S, Lee H, Lewis R L, Wang X S. Deep learning for real-time Atari game play using offline Monte-Carlo tree search planning. In: Proceedings of Advances in Neural Information Processing Systems 27. Montreal, Quebec, Canada, 2014. 3338-3346 [98] Kocsis L, Szepesvári C. Bandit based Monte-Carlo planning. In: Proceedings of the 17th European Conference on Machine Learning. Berlin, Heidelberg: Springer-Verlag, 2006. 282-293 [99] Van Der Ree M, Wiering M. Reinforcement learning in the game of Othello: learning against a fixed opponent and learning from self-play. In: Proceedings of the 2013 IEEE Symposium on Adaptive Dynamic Programming and Reinforcement Learning (ADPRL). Singapore: IEEE, 2013. 108-115 [100] Gelly S, Silver D. Achieving master-level play in 9×9 computer Go. In: Proceedings of the 23rd AAAI Conference on Artificial Intelligence. Chicago, Illinois: AAAI, 2008. 1537-1540 [101] Silver D, Sutton R S, Müller M. Sample-based learning and search with permanent and transient memories. Proceedings of the 25th International Conference on Machine Learning. New York: ACM, 2008. 968-975 [102] Silver D, Huang A, Maddison C J, Guez A, Sifre L, van den Driessche G, Schrittwieser J, Antonoglou I, Panneershelvam V, Lanctot M, Dieleman S, Grewe D, Nham J, Kalchbrenner N, Sutskever I, Lillicrap T, Leach M, Kavukcuoglu K, Graepel T, Hassabis D. Mastering the game of Go with deep neural networks and tree search . Nature, 2016, 529(7587): 484-489 [103] Szita I. Reinforcement learning in games. Reinforcement Learning. Berlin Heidelberg: Springer-Verlag, 2012. 539-577 -

 下载:
下载:
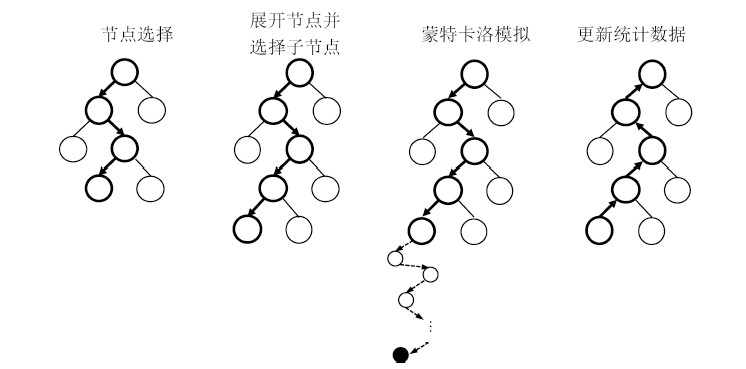

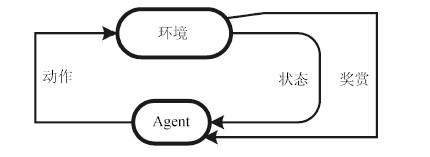
图(3) / 表(1)
计量
- 文章访问数: 4742
- HTML全文浏览量: 1683
- PDF下载量: 4039
- 被引次数: 0
