

-
摘要: 在作为人工智能核心技术的机器学习领域,强化学习是一类强调机器在与环境的交互过程中进行学习的方法,其重要分支之一的自适应评判技术与动态规划及最优化设计密切相关.为了有效地求解复杂动态系统的优化控制问题,结合自适应评判,动态规划和人工神经网络产生的自适应动态规划方法已经得到广泛关注,特别在考虑不确定因素和外部扰动时的鲁棒自适应评判控制方面取得了很大进展,并被认为是构建智能学习系统和实现真正类脑智能的必要途径.本文对基于智能学习的鲁棒自适应评判控制理论与主要方法进行梳理,包括自学习鲁棒镇定,自适应轨迹跟踪,事件驱动鲁棒控制,以及自适应H∞控制设计等,并涵盖关于自适应评判系统稳定性、收敛性、最优性以及鲁棒性的分析.同时,结合人工智能、大数据、深度学习和知识自动化等新技术,也对鲁棒自适应评判控制的发展前景进行探讨.Abstract: In the machine learning field, the core technique of artificial intelligence, reinforcement learning is a class of strategies focusing on learning during the interaction process between machine and environment. As an important branch of reinforcement learning, the adaptive critic technique is closely related to dynamic programming and optimization design. In order to effectively solve optimal control problems of complex dynamical systems, the adaptive dynamic programming approach was proposed by combining adaptive critic, dynamic programming with artificial neural networks and has been attracted extensive attention. Particularly, great progress has been obtained on robust adaptive critic control design with uncertainties and disturbances. Now, it has been regarded as a necessary outlet to construct intelligent learning systems and achieve true brain-like intelligence. This paper presents a comprehensive survey on the learning-based robust adaptive critic control theory and methods, including self-learning robust stabilization, adaptive trajectory tracking, event-driven robust control, and adaptive H∞ control design. Therein, it covers a general analysis for adaptive critic systems in terms of stability, convergence, optimality, and robustness. In addition, considering novel techniques such as artificial intelligence, big data, deep learning, and knowledge automation, it also discusses future prospects of robust adaptive critic control.
-
Key words:
- Adaptive critic control /
- intelligent learning /
- neural networks /
- robust control /
- uncertain systems
1) 本文责任编委 吴立刚 -
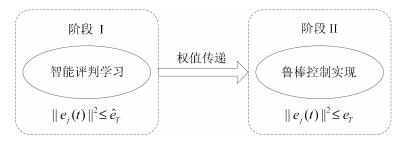
图 2 事件驱动鲁棒自适应评判控制设计过程图
Fig. 2 The design procedure of event-triggered robust adaptive critic control
-
[1] Silver D, Huang A, Maddison C J, Guez A, Sifre L, van den Driessche G, et al. Mastering the game of Go with deep neural networks and tree search. Nature, 2016, 529(7587):484-489 doi: 10.1038/nature16961 [2] LeCun Y, Bengio Y, Hinton G. Deep learning. Nature, 2015, 521(7553):436-444 doi: 10.1038/nature14539 [3] Schmidhuber J. Deep learning in neural networks:an overview. Neural Networks, 2015, 61:85-117 doi: 10.1016/j.neunet.2014.09.003 [4] Haykin S. Neural Networks: A Comprehensive Foundation (Second edition). Upper Saddle River, NJ: Prentice-Hall, 1999. [5] Sutton R S, Barto A G. Reinforcement Learning:An Introduction. Cambridge, MA:MIT Press, 1998. [6] Silver D, Schrittwieser J, Simonyan K, Antonoglou I, Huang A, Guez A, et al. Mastering the game of Go without human knowledge. Nature, 2017, 550:354-359 doi: 10.1038/nature24270 [7] Bellman R E. Dynamic Programming. Princeton, NJ:Princeton University Press, 1957. [8] Lewis F L, Vrabie D, Syrmos V L. Optimal Control (Third edition). New York:Wiley, 2012. [9] Werbos P J. Beyond Regression: New Tools for Prediction and Analysis in the Behavioral Sciences[Ph. D. dissertation], Harvard University, Cambridge, MA, 1974 [10] Werbos P J. Advanced forecasting methods for global crisis warning and models of intelligence. General Systems Yearbook, 1977, 22(6):25-38 [11] Werbos P J. Approximate dynamic programming for realtime control and neural modeling. Handbook of Intelligent Control: Neural, Fuzzy, and Adaptive Approaches. New York, NY: Van Nostrand Reinhold, 1992. [12] Prokhorov D V, Wunsch D C. Adaptive critic designs. IEEE Transactions on Neural Networks, 1997, 8(5):997-1007 doi: 10.1109/72.623201 [13] Murray J J, Cox C J, Lendaris G G, Saeks R. Adaptive dynamic programming. IEEE Transactions on Systems, Man, and Cybernetics, Part C:Applications and Reviews, 2002, 32(2):140-153 doi: 10.1109/TSMCC.2002.801727 [14] Si J, Wang Y T. Online learning control by association and reinforcement. IEEE Transactions on Neural Networks, 2001, 12(2):264-276 doi: 10.1109/72.914523 [15] Saridis G N, Wang F Y. Suboptimal control of nonlinear stochastic systems. Control Theory and Advanced Technology, 1994, 10(4):847-871 [16] Beard R W, Saridis G N, Wen J T. Galerkin approximations of the generalized Hamilton-Jacobi-Bellman equation. Automatica, 1997, 33(12):2159-2177 doi: 10.1016/S0005-1098(97)00128-3 [17] Abu-Khalaf M, Lewis F L. Nearly optimal control laws for nonlinear systems with saturating actuators using a neural network HJB approach. Automatica, 2005, 41(5):779-791 doi: 10.1016/j.automatica.2004.11.034 [18] Wang D, Liu D R, Wei Q L, Zhao D B, Jin N. Optimal control of unknown nona-ne nonlinear discrete-time systems based on adaptive dynamic programming. Automatica, 2012, 48(8):1825-1832 doi: 10.1016/j.automatica.2012.05.049 [19] Xu B, Yang C G, Shi Z K. Reinforcement learning output feedback NN control using deterministic learning technique. IEEE Transactions on Neural Networks and Learning Systems, 2014, 25(3):635-641 doi: 10.1109/TNNLS.2013.2292704 [20] 王鼎, 穆朝絮, 刘德荣.基于迭代神经动态规划的数据驱动非线性近似最优调节.自动化学报, 2017, 43(3):366-375 http://www.aas.net.cn/CN/abstract/abstract19015.shtmlWang Ding, Mu Chao-Xu, Liu De-Rong. Data-driven nonlinear near-optimal regulation based on iterative neural dynamic programming. Acta Automatica Sinica, 2017, 43(3):366-375 http://www.aas.net.cn/CN/abstract/abstract19015.shtml [21] Mu C X, Wang D, He H B. Novel iterative neural dynamic programming for data-based approximate optimal control design. Automatica, 2017, 81:240-252 doi: 10.1016/j.automatica.2017.03.022 [22] Vamvoudakis K G, Lewis F L. Online actor-critic algorithm to solve the continuous-time inflnite horizon optimal control problem. Automatica, 2010, 46(5):878-888 doi: 10.1016/j.automatica.2010.02.018 [23] Vamvoudakis K G, Miranda M F, Hespanha J P. Asymptotically stable adaptive-optimal control algorithm with saturating actuators and relaxed persistence of excitation. IEEE Transactions on Neural Networks and Learning Systems, 2016, 27(11):2386-2398 doi: 10.1109/TNNLS.2015.2487972 [24] Bhasin S, Kamalapurkar R, Johnson M, Vamvoudakis K G, Lewis F L, Dixon W E. A novel actor-critic-identifler architecture for approximate optimal control of uncertain nonlinear systems. Automatica, 2013, 49(1):82-92 doi: 10.1016/j.automatica.2012.09.019 [25] Modares H, Lewis F L. Optimal tracking control of nonlinear partially-unknown constrained-input systems using integral reinforcement learning. Automatica, 2014, 50(7):1780-1792 doi: 10.1016/j.automatica.2014.05.011 [26] Nodland D, Zargarzadeh H, Jagannathan S. Neural network-based optimal adaptive output feedback control of a helicopter UAV. IEEE Transactions on Neural Networks and Learning Systems, 2013, 24(7):1061-1073 doi: 10.1109/TNNLS.2013.2251747 [27] Lv Y F, Na J, Yang Q M, Wu X, Guo Y. Online adaptive optimal control for continuous-time nonlinear systems with completely unknown dynamics. International Journal of Control, 2016, 89(1):99-112 doi: 10.1080/00207179.2015.1060362 [28] Vrabie D, Lewis F. Neural network approach to continuous-time direct adaptive optimal control for partially unknown nonlinear systems. Neural Networks, 2009, 22(3):237-246 doi: 10.1016/j.neunet.2009.03.008 [29] Zhang H G, Cui L L, Zhang X, Luo Y H. Data-driven robust approximate optimal tracking control for unknown general nonlinear systems using adaptive dynamic programming method. IEEE Transactions on Neural Networks, 2011, 22(12):2226-2236 doi: 10.1109/TNN.2011.2168538 [30] Jiang Y, Jiang Z P. Global adaptive dynamic programming for continuous-time nonlinear systems. IEEE Transactions on Automatic Control, 2015, 60(11):2917-2929 doi: 10.1109/TAC.2015.2414811 [31] Bian T, Jiang Z P. Value iteration and adaptive dynamic programming for data-driven adaptive optimal control design. Automatica, 2016, 71:348-360 doi: 10.1016/j.automatica.2016.05.003 [32] Lee J Y, Park J B, Choi Y H. Integral reinforcement learning for continuous-time input-a-ne nonlinear systems with simultaneous invariant explorations. IEEE Transactions on Neural Networks and Learning Systems, 2015, 26(5):916-932 doi: 10.1109/TNNLS.2014.2328590 [33] Ha M M, Wang D, Liu D R. Event-triggered adaptive critic control design for discrete-time constrained nonlinear systems. IEEE Transactions on Systems, Man and Cybernetics:Systems, 2019, DOI: 10.1109/TSMC.2018.2868510 [34] Wang F Y, Zhang H G, Liu D R. Adaptive dynamic programming:an introduction. IEEE Computational Intelligence Magazine, 2009, 4(2):39-47 doi: 10.1109/MCI.2009.932261 [35] Lewis F L, Liu D R. Reinforcement Learning and Approximate Dynamic Programming for Feedback Control. Hoboken, NJ: John Wiley & Sons, Inc., 2012. [36] Zhang H G, Liu D R, Luo Y H, Wang D. Adaptive Dynamic Programming for Control: Algorithms and Stability. London, UK: Springer-Verlag, 2013. [37] 张化光, 张欣, 罗艳红, 杨珺.自适应动态规划综述.自动化学报, 2013, 39(4):303-311 http://www.aas.net.cn/CN/abstract/abstract17916.shtmlZhang Hua-Guang, Zhang Xin, Luo Yan-Hong, Yang Jun. An overview of research on adaptive dynamic programming. Acta Automatica Sinica, 2013, 39(4):303-311 http://www.aas.net.cn/CN/abstract/abstract17916.shtml [38] 刘德荣, 李宏亮, 王鼎.基于数据的自学习优化控制:研究进展与展望.自动化学报, 2013, 39(11):1858-1870 http://www.aas.net.cn/CN/abstract/abstract18225.shtmlLiu De-Rong, Li Hong-Liang, Wang Ding. Data-based selflearning optimal control:research progress and prospects. Acta Automatica Sinica, 2013, 39(11):1858-1870 http://www.aas.net.cn/CN/abstract/abstract18225.shtml [39] Wang D, He H B, Liu D R. Adaptive critic nonlinear robust control:a survey. IEEE Transactions on Cybernetics, 2017, 47(10):3429-3451 doi: 10.1109/TCYB.2017.2712188 [40] Wang D, Mu C X. Adaptive Critic Control with Robust Stabilization for Uncertain Nonlinear Systems. Singapore: Springer Singapore, 2019. [41] Liu D R, Wei Q L, Wang D, Yang X, Li H L. Adaptive Dynamic Programming with Applications in Optimal Control. Switzerland: Springer, 2017. [42] Jiang Y, Jiang Z P. Robust Adaptive Dynamic Programming. Hoboken, NJ:Wiley-IEEE Press, 2017. [43] 王飞跃.平行控制:数据驱动的计算控制方法.自动化学报, 2013, 39(4):293-302 http://www.aas.net.cn/CN/abstract/abstract17915.shtmlWang Fei-Yue. Parallel control:a method for data-driven and computational control. Acta Automatica Sinica, 2013, 39(4):293-302 http://www.aas.net.cn/CN/abstract/abstract17915.shtml [44] Hou Z S, Wang Z. From model-based control to datadriven control:Survey, classiflcation and perspective. Information Sciences, 2013, 235:3-35 doi: 10.1016/j.ins.2012.07.014 [45] Lavretsky E, Wise K A. Robust and Adaptive Control: with Aerospace Applications. London, UK: SpringerVerlag, 2013. [46] Krstic M, Kanellakopoulos I, Kokotovic P V. Nonlinear and Adaptive Control Design. New York, NY: John Wiley & Sons, 1995. [47] Lewis F L, Jagannathan S, Yesildirek A. Neural Network Control of Robot Manipulators and Non-linear Systems. London: Taylor & Francis, 1999. [48] Corless M, Leitmann G. Continuous state feedback guaranteeing uniform ultimate boundedness for uncertain dynamic systems. IEEE Transactions on Automatic Control, 1981, 26(5):1139-1144 doi: 10.1109/TAC.1981.1102785 [49] Lin F. Robust Control Design: An Optimal Control Approach. Chichester: John Wiley & Sons, 2007. [50] Lin F, Brand R D, Sun J. Robust control of nonlinear systems:Compensating for uncertainty. International Journal of Control, 1992, 56(6):1453-1459 doi: 10.1080/00207179208934374 [51] Adhyaru D M, Kar I N, Gopal M. Fixed flnal time optimal control approach for bounded robust controller design using Hamilton-Jacobi-Bellman solution. IET Control Theory & Applications, 2009, 3(9):1183-1195 [52] Adhyaru D M, Kar I N, Gopal M. Bounded robust control of nonlinear systems using neural network-based HJB solution. Neural Computing & Applications, 2011, 20(1):91-103 [53] Wang D, Liu D R, Li H L. Policy iteration algorithm for online design of robust control for a class of continuoustime nonlinear systems. IEEE Transactions on Automation Science and Engineering, 2014, 11(2):627-632 doi: 10.1109/TASE.2013.2296206 [54] Wang D, Liu D R, Li H L, Ma H W. Neural-network-based robust optimal control design for a class of uncertain nonlinear systems via adaptive dynamic programming. Information Sciences, 2014, 282:167-179 doi: 10.1016/j.ins.2014.05.050 [55] Wang D, Liu D R, Zhang Q C, Zhao D B. Data-based adaptive critic designs for nonlinear robust optimal control with uncertain dynamics. IEEE Transactions on Systems, Man, and Cybernetics:Systems, 2016, 46(11):1544-1555 doi: 10.1109/TSMC.2015.2492941 [56] Liu D R, Yang X, Wang D, Wei Q L. Reinforcementlearning-based robust controller design for continuoustime uncertain nonlinear systems subject to input constraints. IEEE Transactions on Cybernetics, 2015, 45(7):1372-1385 doi: 10.1109/TCYB.2015.2417170 [57] Wang D, Liu D R, Li H L, Luo B, Ma H W. An approximate optimal control approach for robust stabilization of a class of discrete-time nonlinear systems with uncertainties. IEEE Transactions on Systems, Man, and Cybernetics:Systems, 2016, 46(5):713-717 doi: 10.1109/TSMC.2015.2466191 [58] Wang D. Adaptation-oriented near-optimal control and robust synthesis of an overhead crane system. In: Proceedings of the 2017 International Conference on Neural Information Processing. Guangzhou, China: Springer, 2017. 42-50 [59] Zhong X N, He H B, Prokhorov D V. Robust controller design of continuous-time nonlinear system using neural network. In: Proceedings of the 2013 International Joint Conference on Neural Networks. Dallas, TX, USA: IEEE, 2013. 1-8 [60] Sun J L, Liu C S, Ye Q. Robust difierential game guidance laws design for uncertain interceptor-target engagement via adaptive dynamic programming. International Journal of Control, 2017, 90(5):990-1004 doi: 10.1080/00207179.2016.1192687 [61] Wang D, Li C, Liu D R, Mu C X. Data-based robust optimal control of continuous-time a-ne nonlinear systems with matched uncertainties. Information Sciences, 2016, 366:121-133 doi: 10.1016/j.ins.2016.05.034 [62] Yang X, Liu D R, Luo B, Li C. Data-based robust adaptive control for a class of unknown nonlinear constrained-input systems via integral reinforcement learning. Information Sciences, 2016, 369:731-747 doi: 10.1016/j.ins.2016.07.051 [63] Fan Q Y, Yang G H. Adaptive actor-critic design-based integral sliding-mode control for partially unknown nonlinear systems with input disturbances. IEEE Transactions on Neural Networks and Learning Systems, 2016, 27(1):165-177 doi: 10.1109/TNNLS.2015.2472974 [64] Jiang Y, Jiang Z P. Robust adaptive dynamic programming for large-scale systems with an application to multimachine power systems. IEEE Transactions on Circuits and Systems Ⅱ:Express Briefs, 2012, 59(10):693-697 doi: 10.1109/TCSII.2012.2213353 [65] Jiang Z P, Jiang Y. Robust adaptive dynamic programming for linear and nonlinear systems:an overview. European Journal of Control, 2013, 19(5):417-425 doi: 10.1016/j.ejcon.2013.05.017 [66] Jiang Y, Jiang Z P. Robust adaptive dynamic programming and feedback stabilization of nonlinear systems. IEEE Transactions on Neural Networks and Learning Systems, 2014, 25(5):882-893 doi: 10.1109/TNNLS.2013.2294968 [67] Bian T, Jiang Y, Jiang Z P. Decentralized adaptive optimal control of large-scale systems with application to power systems. IEEE Transactions on Industrial Electronics, 2015, 62(4):2439-2447 doi: 10.1109/TIE.2014.2345343 [68] Gao W N, Jiang Y, Jiang Z P, Chai T Y. Output-feedback adaptive optimal control of interconnected systems based on robust adaptive dynamic programming. Automatica, 2016, 72:37-45 doi: 10.1016/j.automatica.2016.05.008 [69] Dierks T, Jagannathan S. Optimal control of a-ne nonlinear continuous-time systems. In: Proceedings of the 2010 American Control Conference. Baltimore, MD, USA: IEEE, 2010. 1568-1573 [70] Zhang H G, Cui L L, Luo Y H. Near-optimal control for nonzero-sum difierential games of continuous-time nonlinear systems using single-network ADP. IEEE Transactions on Cybernetics, 2013, 43(1):206-216 doi: 10.1109/TSMCB.2012.2203336 [71] Yang X, Liu D R, Ma H W, Xu Y C. Online approximate solution of HJI equation for unknown constrained-input nonlinear continuous-time systems. Information Sciences, 2016, 328:435-454 doi: 10.1016/j.ins.2015.09.001 [72] Wang D, Mu C. Developing nonlinear adaptive optimal regulators through an improved neural learning mechanism. Science China Information Sciences, 2017, 60(5):058201 doi: 10.1007/s11432-016-9022-1 [73] Wang D, Mu C X. A novel neural optimal control framework with nonlinear dynamics:Closed-loop stability and simulation veriflcation. Neurocomputing, 2017, 266:353-360 doi: 10.1016/j.neucom.2017.05.051 [74] Wang D, Liu D R, Mu C X, Zhang Y. Neural network learning and robust stabilization of nonlinear systems with dynamic uncertainties. IEEE Transactions on Neural Networks and Learning Systems, 2018, 29(4):1342-1351 doi: 10.1109/TNNLS.2017.2749641 [75] Yang X, He H B. Self-learning robust optimal control for continuous-time nonlinear systems with mismatched disturbances. Neural Networks, 2018, 99:19-30 doi: 10.1016/j.neunet.2017.11.022 [76] Jiang Z P, Teel A R, Praly L. Small-gain theorem for ISS systems and applications. Mathematics of Control, Signals and Systems, 1994, 7(2):95-120 doi: 10.1007/BF01211469 [77] Mu C X, Sun C Y, Wang D, Song A G. Adaptive tracking control for a class of continuous-time uncertain nonlinear systems using the approximate solution of HJB equation. Neurocomputing, 2017, 260:432-442 doi: 10.1016/j.neucom.2017.04.043 [78] Wang D, Mu C X. Adaptive-critic-based robust trajectory tracking of uncertain dynamics and its application to a spring-mass-damper system. IEEE Transactions on Industrial Electronics, 2018, 65(1):654-663 doi: 10.1109/TIE.2017.2722424 [79] Wang D, Liu D R, Zhang Y, Li H Y. Neural network robust tracking control with adaptive critic framework for uncertain nonlinear systems. Neural Networks, 2018, 97:11-18 doi: 10.1016/j.neunet.2017.09.005 [80] Tabuada P. Event-triggered real-time scheduling of stabilizing control tasks. IEEE Transactions on Automatic Control, 2007, 52(9):1680-1685 doi: 10.1109/TAC.2007.904277 [81] Tallapragada P, Chopra N. On event triggered tracking for nonlinear systems. IEEE Transactions on Automatic Control, 2013, 58(9):2343-2348 doi: 10.1109/TAC.2013.2251794 [82] Vamvoudakis K G. Event-triggered optimal adaptive control algorithm for continuous-time nonlinear systems. IEEE/CAA Journal of Automatica Sinica, 2014, 1(3):282-293 doi: 10.1109/JAS.2014.7004686 [83] Sahoo A, Xu H, Jagannathan S. Neural networkbased event-triggered state feedback control of nonlinear continuous-time systems. IEEE Transactions on Neural Networks and Learning Systems, 2016, 27(3):497-509 doi: 10.1109/TNNLS.2015.2416259 [84] Zhong X N, He H B. An event-triggered ADP control approach for continuous-time system with unknown internal states. IEEE Transactions on Cybernetics, 2017, 47(3):683-694 doi: 10.1109/TCYB.2016.2523878 [85] Dong L, Tang Y F, He H B, Sun C Y. An event-triggered approach for load frequency control with supplementary ADP. IEEE Transactions on Power Systems, 2017, 32(1):581-589 doi: 10.1109/TPWRS.2016.2537984 [86] Zhu Y H, Zhao D B, He H B, Ji J H. Event-triggered optimal control for partially unknown constrained-input systems via adaptive dynamic programming. IEEE Transactions on Industrial Electronics, 2017, 64(5):4101-4109 doi: 10.1109/TIE.2016.2597763 [87] Wang D, Mu C X, He H B, Liu D R. Adaptive-critic-based event-driven nonlinear robust state feedback. In: Proceedings of the IEEE 55th Conference on Decision and Control. Las Vegas, NV, USA: IEEE, 2016. 5813-5818 [88] Wang D, Mu C X, He H B, Liu D R. Event-driven adaptive robust control of nonlinear systems with uncertainties through NDP strategy. IEEE Transactions on Systems, Man, and Cybernetics:Systems, 2017, 47(7):1358-1370 doi: 10.1109/TSMC.2016.2592682 [89] Wang D, Liu D R. Neural robust stabilization via eventtriggering mechanism and adaptive learning technique. Neural Networks, 2018, 102:27-35 doi: 10.1016/j.neunet.2018.02.007 [90] Zhang Q C, Zhao D B, Wang D. Event-based robust control for uncertain nonlinear systems using adaptive dynamic programming. IEEE Transactions on Neural Networks and Learning Systems, 2018, 29(1):37-50 doi: 10.1109/TNNLS.2016.2614002 [91] Abu-Khalaf M, Lewis F L, Huang J. Policy iterations on the Hamilton-Jacobi-Isaacs equation for H∞ state feedback control with input saturation. IEEE Transactions on Automatic Control, 2006, 51(12):1989-1995 doi: 10.1109/TAC.2006.884959 [92] Vamvoudakis K G, Lewis F L. Online solution of nonlinear two-player zero-sum games using synchronous policy iteration. International Journal of Robust and Nonlinear Control, 2012, 22(13):1460-1483 doi: 10.1002/rnc.v22.13 [93] Modares H, Lewis F L, Sistani M B N. Online solution of nonquadratic two-player zero-sum games arising in the H∞ control of constrained input systems. International Journal of Adaptive Control and Signal Processing, 2014, 28(3-5):232-254 doi: 10.1002/acs.v28.3-5 [94] Luo B, Wu H N, Huang T W. Ofi-policy reinforcement learning for H∞ control design. IEEE Transactions on Cybernetics, 2015, 45(1):65-76 doi: 10.1109/TCYB.2014.2319577 [95] Zhang H G, Qin C B, Jiang B, Luo Y H. Online adaptive policy learning algorithm for H∞ state feedback control of unknown a-ne nonlinear discrete-time systems. IEEE Transactions on Cybernetics, 2014, 44(12):2706-2718 doi: 10.1109/TCYB.2014.2313915 [96] Song R Z, Lewis F L, Wei Q L, Zhang H G. Ofi-policy actor-critic structure for optimal control of unknown systems with disturbances. IEEE Transactions on Cybernetics, 2016, 46(5):1041-1050 doi: 10.1109/TCYB.2015.2421338 [97] Wang D, He H B, Liu D R. Improving the critic learning for event-based nonlinear H∞ control design. IEEE Transactions on Cybernetics, 2017, 47(10):3417-3428 doi: 10.1109/TCYB.2017.2653800 [98] Zhang Q C, Zhao D B, Zhu Y H. Event-triggered H∞ control for continuous-time nonlinear system via concurrent learning. IEEE Transactions on Systems, Man, and Cybernetics:Systems, 2017, 47(7):1071-1081 doi: 10.1109/TSMC.2016.2531680 [99] Mu C X, Wang D, Sun C Y, Zong Q. Robust adaptive critic control design with network-based event-triggered formulation. Nonlinear Dynamics, 2017, 90(3):2023-2035 doi: 10.1007/s11071-017-3778-5 [100] Werbos P J. Computational intelligence for the smart gridhistory, challenges, and opportunities. IEEE Computational Intelligence Magazine, 2011, 6(3):14-21 doi: 10.1109/MCI.2011.941587 [101] Tang Y F, He H B, Wen J Y, Liu J. Power system stability control for a wind farm based on adaptive dynamic programming. IEEE Transactions on Smart Grid, 2015, 6(1):166-177 doi: 10.1109/TSG.2014.2346740 [102] Wang D, He H B, Mu C X, Liu D R. Intelligent critic control with disturbance attenuation for a-ne dynamics including an application to a microgrid system. IEEE Transactions on Industrial Electronics, 2017, 64(6):4935-4944 doi: 10.1109/TIE.2017.2674633 [103] Wang D, He H B, Zhong X N, Liu D R. Event-driven nonlinear discounted optimal regulation involving a power system application. IEEE Transactions on Industrial Electronics, 2017, 64(10):8177-8186 doi: 10.1109/TIE.2017.2698377 [104] Wei Q L, Lewis F L, Shi G, Song R Z. Error-tolerant iterative adaptive dynamic programming for optimal renewable home energy scheduling and battery management. IEEE Transactions on Industrial Electronics, 2017, 64(12):9527-9537 doi: 10.1109/TIE.2017.2711499 [105] Liu D R, Xu Y C, Wei Q L, Liu X L. Residential energy scheduling for variable weather solar energy based on adaptive dynamic programming. IEEE/CAA Journal of Automatica Sinica, 2018, 5(1):36-46 doi: 10.1109/JAS.2017.7510739 [106] Wang D, He H B, Liu D R. Intelligent optimal control with critic learning for a nonlinear overhead crane system. IEEE Transactions on Industrial Informatics, 2018, 14(7):2932-2940 doi: 10.1109/TII.2017.2771256 [107] 赵冬斌, 刘德荣, 易建强.基于自适应动态规划的城市交通信号优化控制方法综述.自动化学报, 2009, 35(6):676-681 http://www.aas.net.cn/CN/abstract/abstract13331.shtmlZhao Dong-Bin, Liu De-Rong, Yi Jian-Qiang. An overview on the adaptive dynamic programming based urban city tra-c signal optimal control. Acta Automatica Sinica, 2009, 35(6):676-681 http://www.aas.net.cn/CN/abstract/abstract13331.shtml [108] Gao W N, Jiang Z P, Ozbay K. Data-driven adaptive optimal control of connected vehicles. IEEE Transactions on Intelligent Transportation Systems, 2017, 18(5):1122-1133 doi: 10.1109/TITS.2016.2597279 [109] Bertsekas D P. Value and policy iterations in optimal control and adaptive dynamic programming. IEEE Transactions on Neural Networks and Learning Systems, 2017, 28(3):500-509 doi: 10.1109/TNNLS.2015.2503980 [110] Werbos P J. From ADP to the brain: Foundations, roadmap, challenges and research priorities. In: Proceedings of the 2014 International Joint Conference on Neural Networks. Beijing, China: IEEE, 2014. 107-111 -

 下载:
下载:
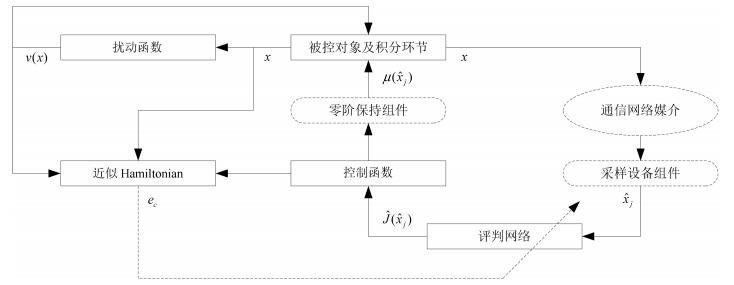

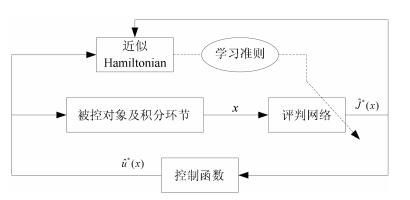
图(3)
计量
- 文章访问数: 3507
- HTML全文浏览量: 978
- PDF下载量: 1297
- 被引次数: 0
