

-
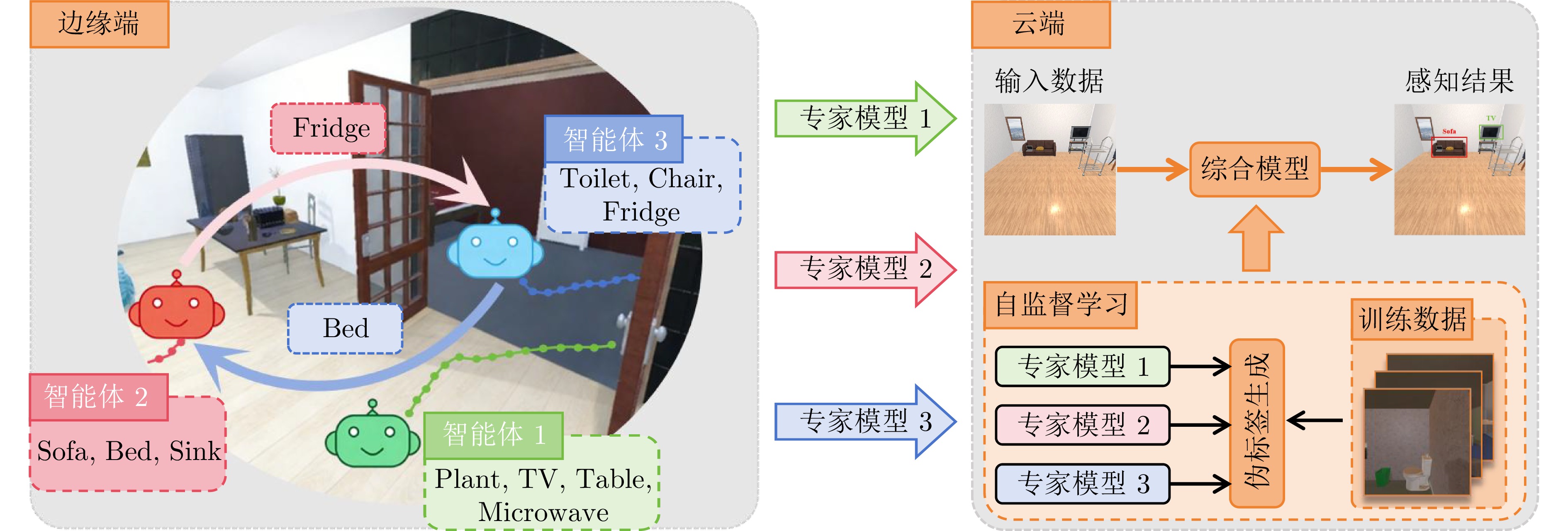
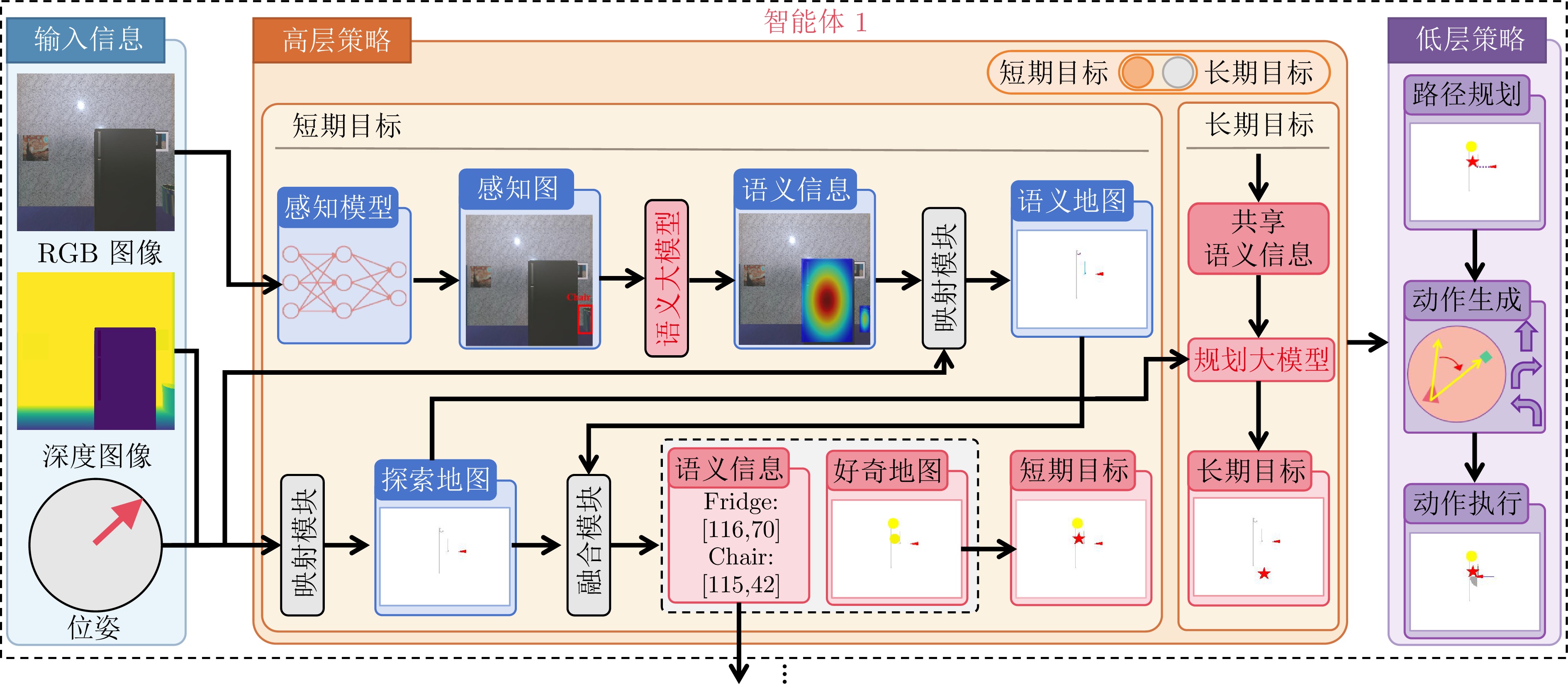
摘要: 具身学习通过智能体与环境的主动交互与数据采集, 结合模型迭代更新, 实现自主智能. 然而, 随着环境复杂度和任务规模增加, 传统单智能体方法面临数据采集效率低、样本利用效率低、训练效率低等瓶颈, 严重制约了系统可扩展性. 针对上述问题, 提出一种云边协同的多智能体具身学习框架, 充分利用视觉?语言模型的高级推理能力, 在无需额外训练的前提下实现多智能体高效在线探索与协同数据采集. 具体地, 各智能体通过视觉?语言模型对观测数据及感知信息进行解析, 构建融合语义与空间状态的好奇心地图, 以指导短期目标选择, 实现语义驱动的高价值区域利用与空间驱动的未知区域探索的协同推进; 在短期探索任务完成后, 智能体能够基于全局空间状态与共享语义信息开展长期探索规划, 以保障探索的全面性与战略性. 所有智能体完成全场景探索后, 边缘端利用采集数据进行本地模型训练, 并将更新参数和少量数据上传云端, 由云端进行多源知识聚合, 生成全局优化模型. 实验结果表明, 所提方法显著优于基线方法, 为大规模复杂环境下多机器人自主智能学习提供新的有效范式.Abstract: Embodied learning enables autonomous intelligence through active interaction and data collection between agents and the environment, combined with iterative model updates. However, as the complexity of the environment and the scale of tasks increase, conventional single-agent methods face critical bottlenecks, including low data acquisition efficiency, low sample utilization efficiency, and low training efficiency, which severely limit system scalability. To address these challenges, we proposes a cloud-edge collaborative multi-agent embodied learning framework that leverages the high-level reasoning capabilities of vision-language model (VLM) to achieve efficient online exploration and coordinated data collection without additional training. Specifically, each agent uses a VLM to interpret observation data and perception information, constructing curiosity maps that integrate semantic and spatial states to guide short-term goal selection, thereby enabling synergistic advancement of semantic-driven utilization of high-value regions and spatial-driven exploration of unknown regions. Upon completing short-term exploration tasks, agents perform long-term exploration planning based on global spatial states and shared semantic information to ensure comprehensive and strategic exploration. After all agents complete full-scene exploration, edge agents train local models using the collected data, and the updated parameters with a small amount of data are uploaded to the cloud for multi-source knowledge aggregation to generate a globally optimized model. Experimental results demonstrate that the proposed method significantly outperforms baseline methods, providing an effective paradigm for multi-robot autonomous intelligence learning in large-scale complex environments.
-
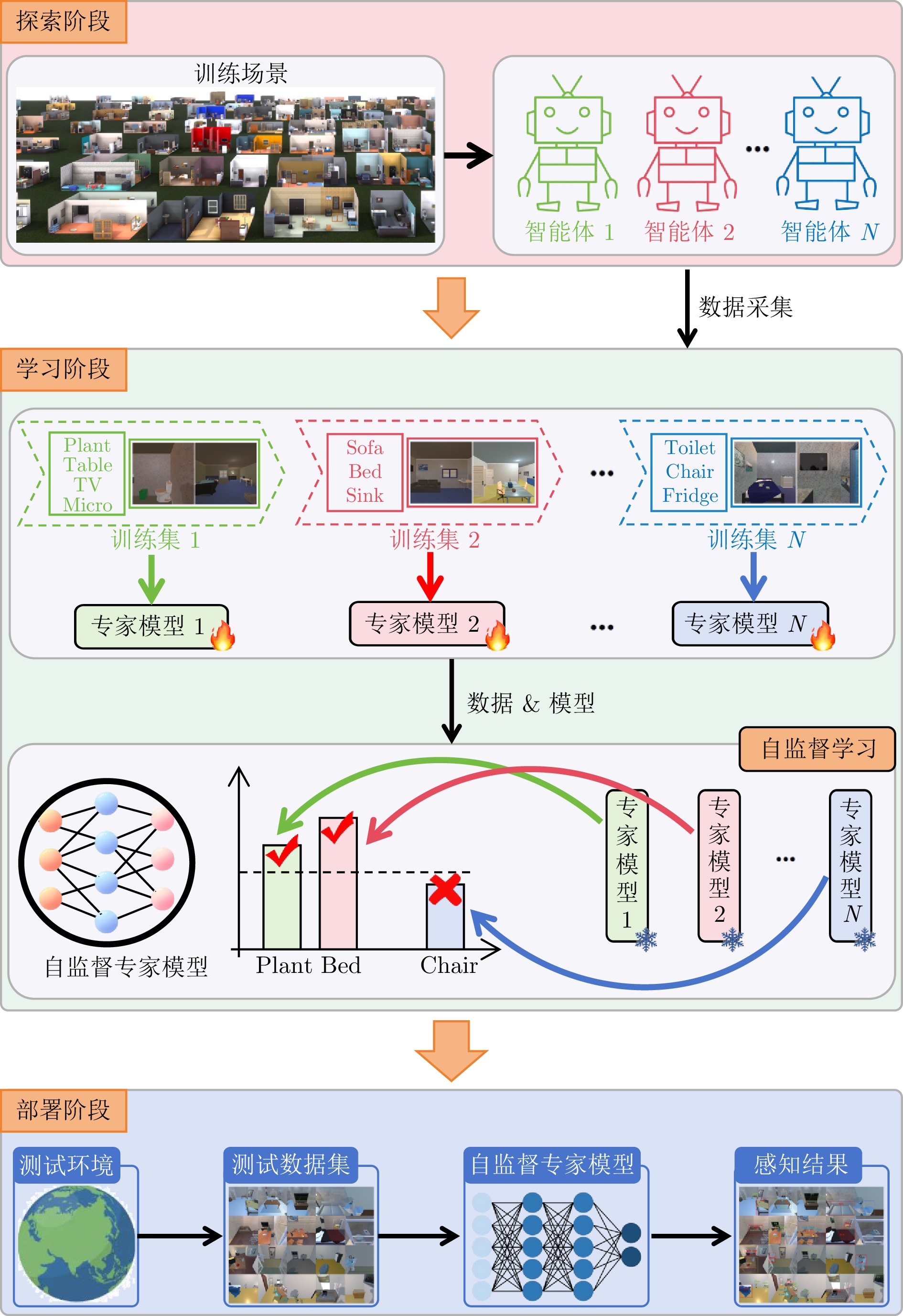
图 2 云边协同具身学习框架流程图
Fig. 2 A cloud-edge collaborative embodied learning framework flowchart

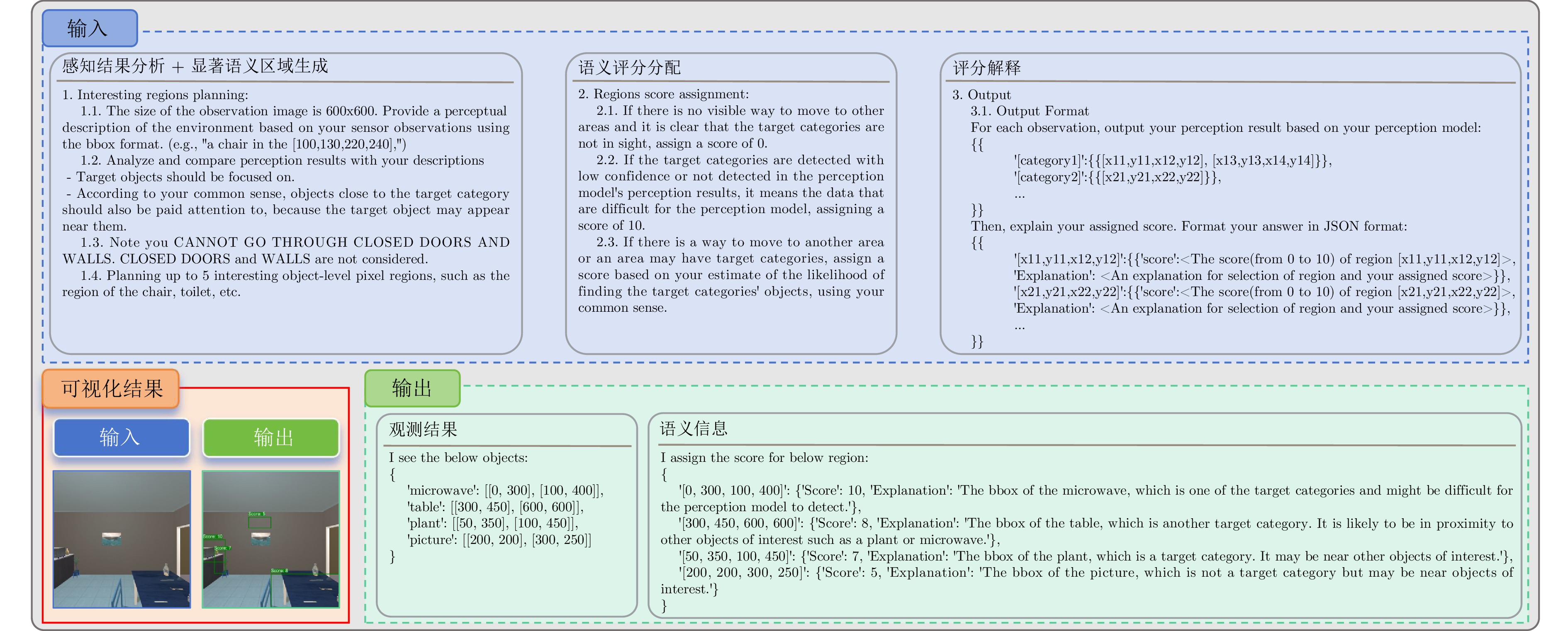
图 9 视觉$ - $语言模型错误视觉推理示例
Fig. 9 Examples of wrong visual reasoning by vision-language models
表 1 验证集上AP50性能
Table 1 The AP50 performance on the validation dataset
方法 数据 Plant Table TV Micr. Sofa Bed Sink Toilet Chair Fridge mAP50 Pretrain − 73.6 36.1 50.0 3.6 52.7 53.3 23.0 50.0 43.0 24.6 41.0 Random − 60.5 22.5 62.0 21.9 30.6 52.0 39.8 57.6 24.5 49.9 42.1 Random pl 53.2 19.2 49.5 7.4 26.3 33.1 17.5 41.9 17.3 38.8 30.4 Rule − 50.5 13.4 60.5 7.5 11.3 35.4 56.2 58.9 18.7 50.0 36.2 Rule pl 69.0 19.0 69.3 2.2 27.9 53.1 32.9 53.9 30.2 59.0 41.7 Moonshot − 84.0 36.6 74.5 17.1 1.6 65.7 63.0 73.9 33.6 77.1 52.7 Moonshot pl 80.6 38.6 76.5 19.0 26.2 73.0 69.3 68.2 40.4 53.0 54.5 Qwen − 85.2 35.9 83.0 11.1 12.8 68.6 59.6 74.2 33.7 67.3 53.1 Qwen pl 81.7 38.3 80.2 0.6 29.8 68.0 50.9 72.5 36.0 63.5 52.1  下载: 导出CSV
下载: 导出CSV
表 2 验证集上AP性能
Table 2 The AP performance on the validation dataset
方法 数据 Plant Table TV Micr. Sofa Bed Sink Toilet Chair Fridge mAP Pretrain - 49.4 27.9 29.9 2.8 50.3 33.7 20.5 41.4 30.6 23.8 31.0 Random - 46.7 15.7 47.9 8.4 25.9 38.9 35.6 55.3 13.5 43.7 33.2 Random pl 37.1 12.6 30.8 2.8 21.9 24.6 17.0 36.6 8.9 34.3 22.7 Rule - 61.8 18.2 75.0 13.8 14.5 44.2 61.2 64.4 32.1 52.6 43.8 Rule pl 48.4 13.2 49.5 1.5 23.7 37.1 30.2 44.1 16.3 54.0 31.8 Moonshot - 64.1 27.9 56.2 8.4 1.0 57.4 54.3 63.7 18.0 69.4 42.0 Moonshot pl 60.4 28.3 57.6 8.5 23.0 55.4 64.9 56.1 23.3 49.7 42.7 Qwen - 64.9 28.0 64.7 4.1 10.6 58.3 50.4 66.2 17.0 63.6 42.8 Qwen pl 54.1 29.1 61.3 0.3 26.6 51.2 48.3 61.6 20.6 56.0 40.9
下载: 导出CSV
表 3 验证集上AP50性能
Table 3 The AP50 performance on the validation dataset
Method Sem Plant Table TV Micr. Sofa Bed Sink Toilet Chair Fridge mAP50 Moonshot − 84.0 41.8 79.6 31.3 7.2 68.3 23.5 74.5 29.0 58.0 49.7 Moonshot √ 84.0 36.6 74.5 17.1 1.6 65.7 63.0 73.9 33.6 77.1 52.7 Qwen − 79.5 25.8 65.1 19.2 10.2 64.2 62.9 68.2 27.5 61.1 48.4 Qwen √ 85.2 35.9 83.0 11.1 12.8 68.6 59.6 74.2 33.7 67.3 53.1
下载: 导出CSV
表 4 验证集上AP性能
Table 4 The AP performance on the validation dataset
Method Sem Plant Table TV Micr. Sofa Bed Sink Toilet Chair Fridge mAP Moonshot − 63.9 33.6 66.8 18.0 6.1 56.3 22.4 67.4 15.8 51.7 40.2 Moonshot √ 64.1 27.9 56.2 8.4 1.0 57.4 54.3 63.7 18.0 69.4 42.0 Qwen − 53.5 18.0 52.5 9.4 8.8 55.5 58.6 62.3 14.4 58.1 39.1 Qwen √ 64.9 28.0 64.7 4.1 10.6 58.3 50.4 66.2 17.0 63.6 42.8
下载: 导出CSV
表 5 验证集上AP50性能
Table 5 The AP50 performance on the validation dataset
Method Data Plant Table TV Micr. Sofa Bed Sink Toilet Chair Fridge mAP50 Random pl 53.2 19.2 49.5 7.4 26.3 33.1 17.5 41.9 17.3 38.8 30.4 Random gt 58.6 25.7 60.1 9.4 27.5 52.7 13.9 43.2 29.7 61.0 38.2 Rule pl 69.0 19.0 69.3 2.2 27.9 53.1 32.9 53.9 30.2 59.0 41.7 Rule gt 64.9 20.4 66.5 3.0 29.0 57.2 47.7 57.9 30.9 69.4 44.7 Moonshot pl 80.6 38.6 76.5 19.0 26.2 73.0 69.3 68.2 40.4 53.0 54.5 Moonshot gt 74.5 37.3 79.6 22.5 36.3 77.2 70.9 78.5 43.5 69.5 59.0 Qwen pl 81.7 38.3 80.2 0.6 29.8 68.0 50.9 72.5 36.0 63.5 52.1 Qwen gt 81.8 38.7 78.3 11.8 28.9 72.7 67.5 76.7 40.1 58.7 55.5
下载: 导出CSV
表 6 验证集上AP性能
Table 6 The AP performance on the validation dataset
Method Data Plant Table TV Micr. Sofa Bed Sink Toilet Chair Fridge mAP Random pl 37.1 12.6 30.8 2.8 21.9 24.6 17.0 36.6 8.9 34.3 22.7 Random gt 44.1 17.0 44.0 4.2 24.3 41.0 13.3 35.8 17.8 54.3 29.6 Rule pl 48.4 13.2 49.5 1.5 23.7 37.1 30.2 44.1 16.3 54.0 31.8 Rule gt 48.5 14.1 47.1 0.8 25.3 43.8 45.5 54.6 17.2 64.2 36.1 Moonshot pl 60.4 28.3 57.6 8.5 23.0 55.4 64.9 56.1 23.3 49.7 42.7 Moonshot gt 59.2 28.9 61.8 8.8 33.2 62.2 65.9 69.3 25.2 60.5 47.5 Qwen pl 54.1 29.1 61.3 0.3 26.6 51.2 48.3 61.6 20.6 56.0 40.9 Qwen gt 57.6 30.6 62.3 4.9 24.6 60.3 64.4 68.1 23.8 53.3 45.0
下载: 导出CSV
-
[1] Liu H, Guo D, Cangelosi A. Embodied intelligence: A synergy of morphology, action, perception and learning. ACM Computing Surveys, 2025, 57(7): 1−36 [2] 刘华平, 郭迪, 孙富春, 张新钰. 基于形态的具身智能研究: 历史回顾与前沿进展. 自动化学报, 2023, 49(6): 1131−1154 doi: 10.16383/j.aas.c220564Liu H, Guo D, Sun F, Zhang X. Morphology-based embodied intelligence: Historical retrospect and research progress. Acta Automatica Sinica, 2023, 49(6): 1131−1154 doi: 10.16383/j.aas.c220564 [3] Chaplot D, Jiang H, Gupta S, Gupta A. Semantic curiosity for active visual learning. In: Proceedings of the 16th European Conference on Computer Vision (ECCV). Glasgow, UK: Springer, 2020. 309-326 [4] Siddiqui Y, Valentin J, Niener M. ViewAL: Active learning with viewpoint entropy for semantic segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2020. 9433-9443 [5] Nilsson D, Pirinen A, Grtner E, Sminchisescu C. Embodied visual active learning for semantic segmentation. In: Proceedings of the 35th AAAI Conference on Artificial Intelligence. AAAI, 2021. 2373-2383 [6] Nilsson D, Pirinen A, Grtner E, Sminchisescu C. Embodied learning for lifelong visual perception. arXiv preprint arXiv: 2112.14084, 2021 [7] Zurbrügg R, Blum H, Cadena C, Siegwart R, Schmid L. Embodied active domain adaptation for semantic segmentation via informative path planning. IEEE Robotics and Automation Letters, 2022, 7(4): 8691−8698 doi: 10.1109/LRA.2022.3188901 [8] Rückin J, Magistri F, Stachniss C, Popovi M. An informative path planning framework for active learning in UAV-based semantic mapping. IEEE Transactions on Robotics, 2023, 39(6): 4279−4296 doi: 10.1109/TRO.2023.3313811 [9] Rückin J, Magistri F, Stachniss C, Popovi M. Semi-supervised active learning for semantic segmentation in unknown environments using informative path planning. IEEE Robotics and Automation Letters, 2024, 9(3): 2662−2669 doi: 10.1109/LRA.2024.3359970 [10] Jing Y, Kong T. Learning to explore informative trajectories and samples for embodied perception. In: Proceedings of 2023 IEEE International Conference on Robotics and Automation (ICRA). London, UK: IEEE, 2023. 6050-6056 [11] Fang Z, Jain A, Sarch G, Harley A, Fragkiadaki K. Move to see better: Self-improving embodied object detection. arXiv preprint arXiv: 2012.00057, 2020 [12] Scarpellini G, Rosa S, Morerio P, Natale L, Del B. Look Around and Learn: Self-Training Object Detection by Exploration. arXiv preprint arXiv: 2302.03566, 2023 [13] Scarpellini G, Rosa S, Morerio P, Natale L, Del B. Self-improving object detection via disagreement reconciliation. arXiv preprint arXiv: 2302.10624, 2023 [14] Chaplot D, Dalal M, Gupta S, Malik J, Salakhutdinov R. SEAL: Self-supervised embodied active learning using exploration and 3D consistency. In: Proceedings of Advances in Neural Information Processing Systems (NeurIPS). Vancouver, BC, Canada: Curran Associates, 2021. 13086-13098 [15] Blum H, Müller M G, Gawel A, Siegwart R, Cadena C. SCIM: Simultaneous clustering, inference, and mapping for open-world semantic scene understanding. In: Proceedings of The International Symposium of Robotics Research (ISRR). Geneva, Switzerland: Springer, 2022. 119-135 [16] Liang X, Han A, Yan W, Raghunathan A, Abbeel P. Alp: Action-aware embodied learning for perception. arXiv preprint arXiv: 2306.10190, 2023 [17] Clay V, Pipa G, Kühnberger K, Knig P. Development of few-shot learning capabilities in artificial neural networks when learning through self-supervised interaction. IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2023, 46(1): 209−219 [18] Kotar K, Mottaghi R. Interactron: Embodied adaptive object detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New Orleans, LA, USA, IEEE, 2022. 14860-14869 [19] Tan S, Ge M, Guo D, Liu H, Sun F. Knowledge-based embodied question answering. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(10): 11948−11960 doi: 10.1109/TPAMI.2023.3277206 [20] Li X, Guo D, Liu H, Sun F. Embodied semantic scene graph generation. In: Proceedings of the Conference on Robot Learning (CoRL). Auckland, New Zealand: PMLR, 2022. 1585-1594 [21] Shridhar M, Manuelli L, Fox D. Cliport: What and where pathways for robotic manipulation. In: Proceedings of the Conference on Robot Learning (CoRL). Auckland, New Zealand, PMLR, 2022. 894-906 [22] Ji Z, Lin H, Gao Y. DyNaVLM: Zero-Shot Vision-Language Navigation System with Dynamic Viewpoints and Self-Refining Graph Memory. arXiv preprint arXiv: 2506.15096, 2025 [23] Driess D, Xia F, Sajjadi M, Lynch C, Chowdhery A, Ichter B, et al. Palm-e: An embodied multimodal language model. arXiv preprint arXiv: 2303.03378, 2023 [24] Jiang Y, Gupta A, Zhang Z, Wang G, Dou Y, Chen Y, et al. Vima: General robot manipulation with multimodal prompts. arXiv preprint arXiv: 2210.03094, 2022 [25] Brohan A, Brown N, Carbajal J, Chebotar Y, Dabis J, Finn C, et al. Rt-1: Robotics transformer for real-world control at scale. arXiv preprint arXiv: 2212.06817, 2022 [26] Zitkovich B, Yu T, Xu S, Xu P, Xiao T, Xia F, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. In: Proceedings of the Conference on Robot Learning. Georgia, USA: PMLR, 2023. 2165-2183 [27] Kim M J, Pertsch K, Karamcheti S, Xiao T, Balakrishna A, Nair S, et al. Openvla: An open-source vision-language-action model. arXiv preprint arXiv: 2406.09246, 2024 [28] Black K, Brown N, Darpinian J, Dhabalia K, Driess D, Esmail A, et al. π0.5: a Vision-Language-Action Model with Open-World Generalization. In: Proceedings of the 9th Annual Conference on Robot Learning. Seoul, Korea: PMLR, 2025. [29] Bjorck J, Castaeda F, Cherniadev N, Da X, Ding R, Fan L, et al. Gr00t n1: An open foundation model for generalist humanoid robots. arXiv preprint arXiv: 2503.14734, 2025 [30] Han, ByungOk, Jaehong Kim, and Jinhyeok Jang. A dual process vla: Efficient robotic manipulation leveraging vlm. arXiv preprint arXiv: 2410.15549, 2024 [31] Zhen, Haoyu, Chen P, Yang J, Yan X, Du Y, et al. 3d-vla: A 3d vision-language-action generative world model. arXiv preprint arXiv: 2403.09631, 2024 [32] Cen J, Yu C, Yuan H, Jiang Y, Huang S, Guo J, et al. Worldvla: Towards autoregressive action world model. arXiv preprint arXiv: 2506.21539, 2025 [33] Ye S, Ge Y, Zheng K, Gao S, Yu S, Kurian G, et al. World Action Models are Zero-shot Policies. arXiv preprint arXiv: 2602.15922, 2026 [34] Simmons R, Apfelbaum D, Burgard W, Fox D, Moors M, Thrun S, et al. Coordination for multi-robot exploration and mapping. In: Proceedings of the AAAI/IAAI. Austin, USA: AAAI Press, 2000. 852-858. [35] Yamauchi B. Frontier-based exploration using multiple robots. In: Proceedings of the Second International Conference on Autonomous Agents. Minneapolis, Minnesota, USA: ACM, 1998. 47-53 [36] Zhang Z, Yu J, Tang J, Tang J, Xu Y, Wang Y. MR-TopoMap: Multi-robot exploration based on topological map in communication restricted environment. IEEE Robotics and Automation Letters, 2022, 7(4): 10794−10801 doi: 10.1109/LRA.2022.3192765 [37] Liu X, Prabhu A, Cladera F, Miller I, Zhou L, Taylor C, et al. Active metric-semantic mapping by multiple aerial robots. arXiv preprint arXiv: 2209.08465, 2022 [38] Liu X, Lei J, Prabhu A, Tao Y, Spasojevic I, Chaudhari P. Slideslam: Sparse, lightweight, decentralized metric-semantic slam for multirobot navigation. IEEE Transactions on Robotics, 2025, 41: 6529−6548 doi: 10.1109/TRO.2025.3629786 [39] 俞文武, 杨晓亚, 李海昌, 王瑞, 胡晓惠. 面向多智能体协作的注意力意图与交流学习方法. 自动化学报, 2023, 49(11): 2311−2325Yu W, Yang X, Li H, Wang R, Hu X. Attentional intention and communication for multi-agent learning. Acta Automatica Sinica, 2023, 49(11): 2311−2325 [40] Foerster J, Farquhar G, Afouras T, Nardelli N, Whiteson S. Counterfactual multi-agent policy gradients. In: Proceedings of the AAAI Conference on Artificial Intelligence. New Orleans, Louisiana, USA: AAAI Press, 2018. 2961-2969 [41] Lowe R, Wu Y I, Tamar A, Harb J, Abbeel P, Mordatch I. Multi-agent actor-critic for mixed cooperative-competitive environments. In: Proceedings of the 31st Annual Conference on Neural Information Processing Systems. California, USA: Curran Associates, 2017. 30 [42] Yu C, Velu A, Vinitsky E, Gao J, Wang Y, Bayen A, et al. The surprising effectiveness of ppo in cooperative multi-agent games. In: Proceedings of the Annual Conference on Neural Information Processing Systems. New Orleans, Louisiana, USA: Curran Associates, 2022. 24611-24624 [43] Goel H, Omama M, Chalaki B, Tadiparthi V, Pari E, Chinchali S. R3DM: Enabling Role Discovery and Diversity Through Dynamics Models in Multi-agent Reinforcement Learning. arXiv preprint arXiv: 2505.24265, 2025 [44] Sagirova A, Kuratov Y, Burtsev M. SRMT: shared memory for multi-agent lifelong pathfinding. arXiv preprint arXiv: 2501.13200, 2025 [45] 施伟, 冯旸赫, 程光权, 黄红蓝, 黄金才, 刘忠, 等. 基于深度强化学习的多机协同空战方法研究. 自动化学报, 2021, 47(7): 1610−1623Shi W, Feng Y, Cheng G, Huang H, Huang J, Liu Z, et al. Research on multi-aircraft cooperative air combat method based on deep reinforcement learning. Acta Automatica Sinica, 2021, 47(7): 1610−1623 [46] 黄帅, 冯雨航, 郑太雄, 李永福. 云-边-端协同下考虑多车影响的混行车群集中式协同控制. 自动化学报, 2026, 52(1): 172−190 doi: 10.16383/j.aas.c240775Huang S, Feng Y, Zheng T, Li Y. Centralized cooperative control of mixed vehicle groups considering multi-vehicle influence under cloud-edge-end collaboration. Acta Automatica Sinica, 2026, 52(1): 172−190 doi: 10.16383/j.aas.c240775 [47] Gummadi S, Gasparino M V, Vasisht D, Chowdhary G. Fed-ec: Bandwidth-efficient clustering-based federated learning for autonomous visual robot navigation]. IEEE Robotics and Automation Letters, 2024, 9(12): 11841−11848 doi: 10.1109/LRA.2024.3498778 [48] Yuan Z, Xu S, Zhu M. Federated reinforcement learning for robot motion planning with zero-shot generalization. Automatica, 2024, 166: 111709 doi: 10.1016/j.automatica.2024.111709 [49] Lei S, Tang H, Li C, Zhang X, Xu C, Wu H. Federated MADDPG-based Collaborative Scheduling Strategy in Vehicular Edge Computing. IEEE Transactions on Mobile Computing, 2025, 25(1): 54−66 [50] Andong, Francisco Javier Esono Nkulu, Qi Min. Federated Multi-Agent Reinforcement Learning for Privacy-Preserving and Energy-Aware Resource Management in 6G Edge Networks. arXiv preprint arXiv: 2509.10163, 2025 [51] Kannan S S, Venkatesh V L N, Min B C. Smart-llm: Smart multi-agent robot task planning using large language models. In: Proceedings of the 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems. Abu Dhabi, United Arab Emirates: IEEE, 2024. 12140-12147 [52] Wang R, Hsu H L, Hunt D, Kim J, Luo S, Pajic M. LLM-MCoX: Large Language Model-based Multi-robot Coordinated Exploration and Search. arXiv preprint arXiv: 2509.26324, 2025 [53] Zhu Y, Chen J, Zhang X, Guo M, Li Z. DEXTER-LLM: Dynamic and Explainable Coordination of Multi-Robot Systems in Unknown Environments via Large Language Models. In: Proceedings of the 2025 IEEE/RSJ International Conference on Intelligent Robots and Systems. Hangzhou, China: IEEE, 2025. 10182-10189 -

 下载:
下载:





计量
- 文章访问数: 203
- HTML全文浏览量: 201
- 被引次数: 0
