

-
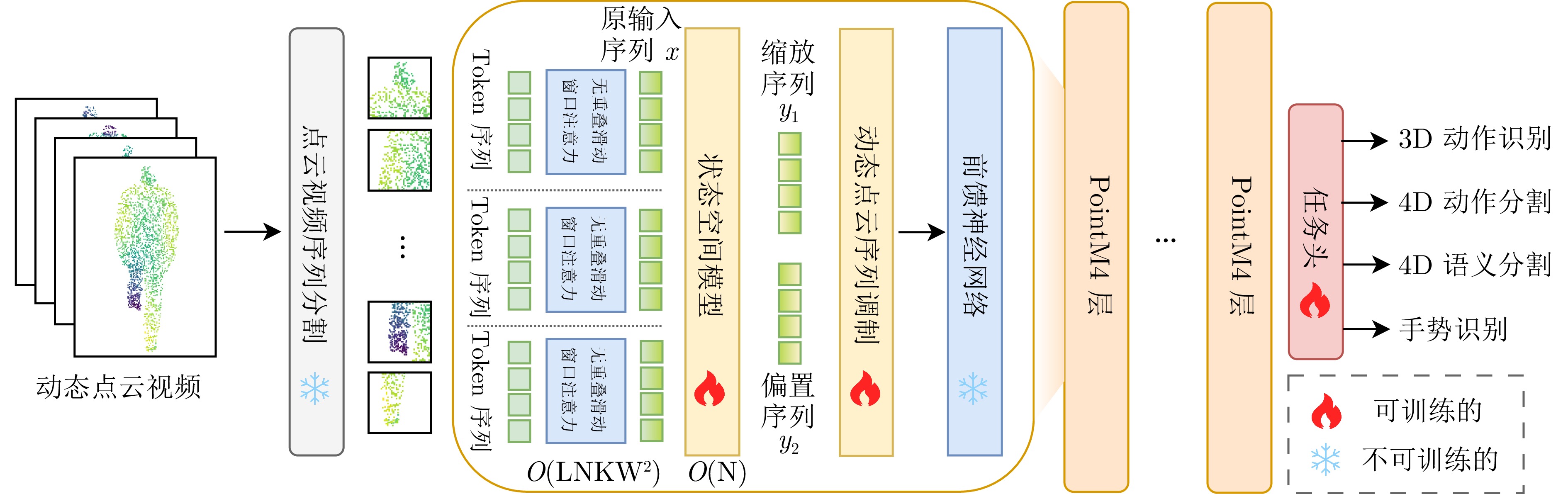
摘要: 动态点云视频时空耦合复杂, 现有端到端方法仅支持特定数据集与任务验证, 跨场景、跨任务泛化能力不足, 需重复训练. 为了能够挖掘可迁移的通用先验, 本文将研究视角重新聚焦于静态点云基础模型. 首先分析现有迁移学习方法存在的两大掣肘, 即密集计算与冗余设计. 为了实现轻量、紧凑的目标, 提出一种基于渐进式适配器的跨模态高效迁移学习方法. 该方法通过无重叠的3D滑动窗口注意力, 将自注意力复杂度由二次降为线性. 引入洗牌希尔伯特-Z序双向扫描曲线, 将动态点云视频约束为兼容Mamba的特征序列, 并以渐进式门控融合实现基础模型与新增适配器的高效协同. 整体方法不改变基础模型权重, 不依赖外部辅助设计. 在MSR-Action3D、HOI4D和SHREC'17上的实验结果表明, 仅微调1.8%参数即可获得超越现有基线模型的性能, 验证了该方法的优越性.Abstract: Dynamic point cloud videos exhibit intricate spatio-temporal coupling. Current end-to-end methods are only evaluated on specific datasets and tasks, generalize poorly across scenes or tasks, and must be retrained from scratch. To uncover transferable universal priors, we refocus our investigation on static point cloud foundation models. In this paper, we first identify two bottlenecks in existing transfer learning methods: heavy computation and redundant design. To obtain a compact and lightweight solution, we propose an efficient cross-modal transfer method that uses progressive adapters. It reduces self-attention from quadratic to linear complexity with non-overlapping 3D sliding window attention. A shuffled Hilbert-Z bidirectional scan converts the video into a Mamba-compatible sequence; progressive gating then lets the frozen backbone and the light adapter cooperate efficiently. The backbone weights remain unchanged and no external modules are required. Experiments on MSR-Action3D, HOI4D and SHREC'17 show that tuning only 1.8% of the parameters already surpasses prior baselines, confirming the effectiveness of our method.
-
Key words:
- point-cloud video /
- transfer learning /
- hybrid architecture /
- attention mechanism /
- efficient adapter
-
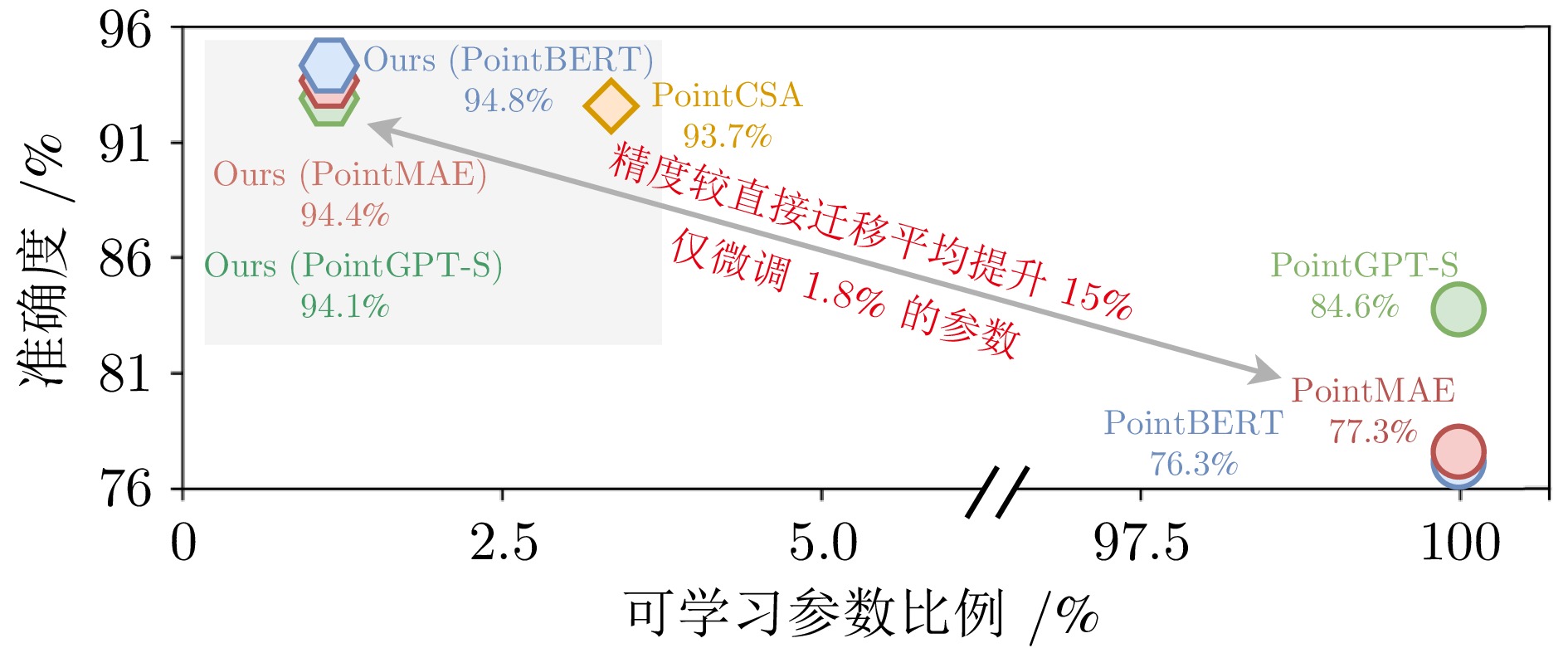
图 1 本文与现有方法在性能与可学习参数比例上的对比
Fig. 1 Comparison between our method and existing methods on performance and learnable parameter ratio
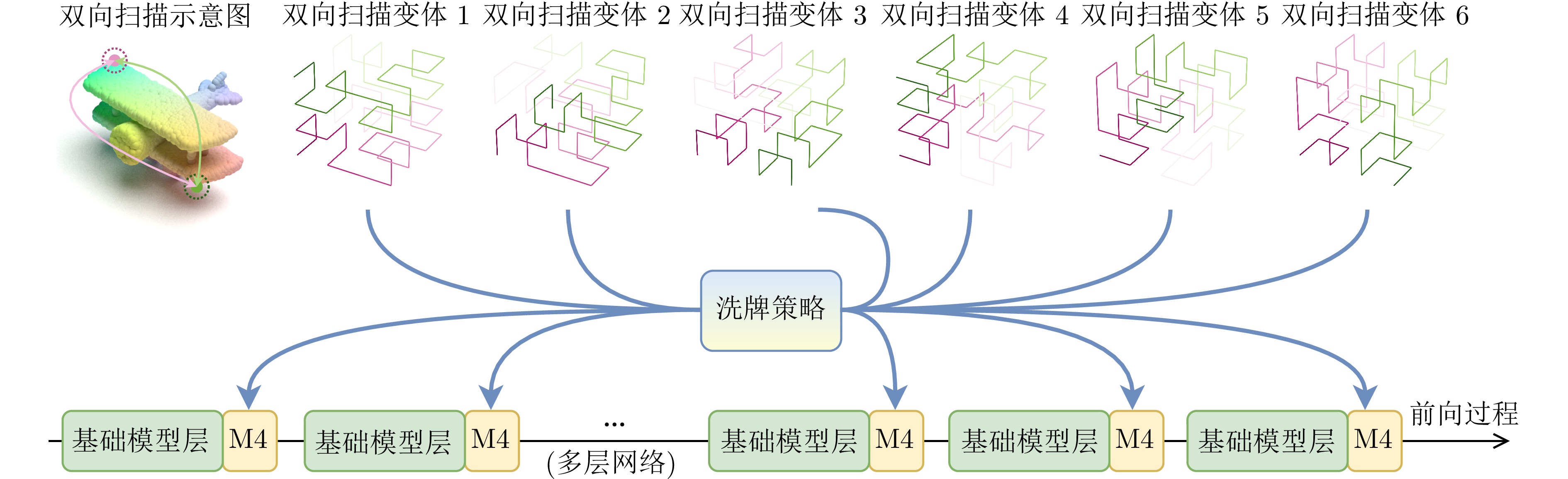
图 3 双向扫描与洗牌策略的示意图
Fig. 3 Schematic diagram of the bidirectional scan and shuffle strategy
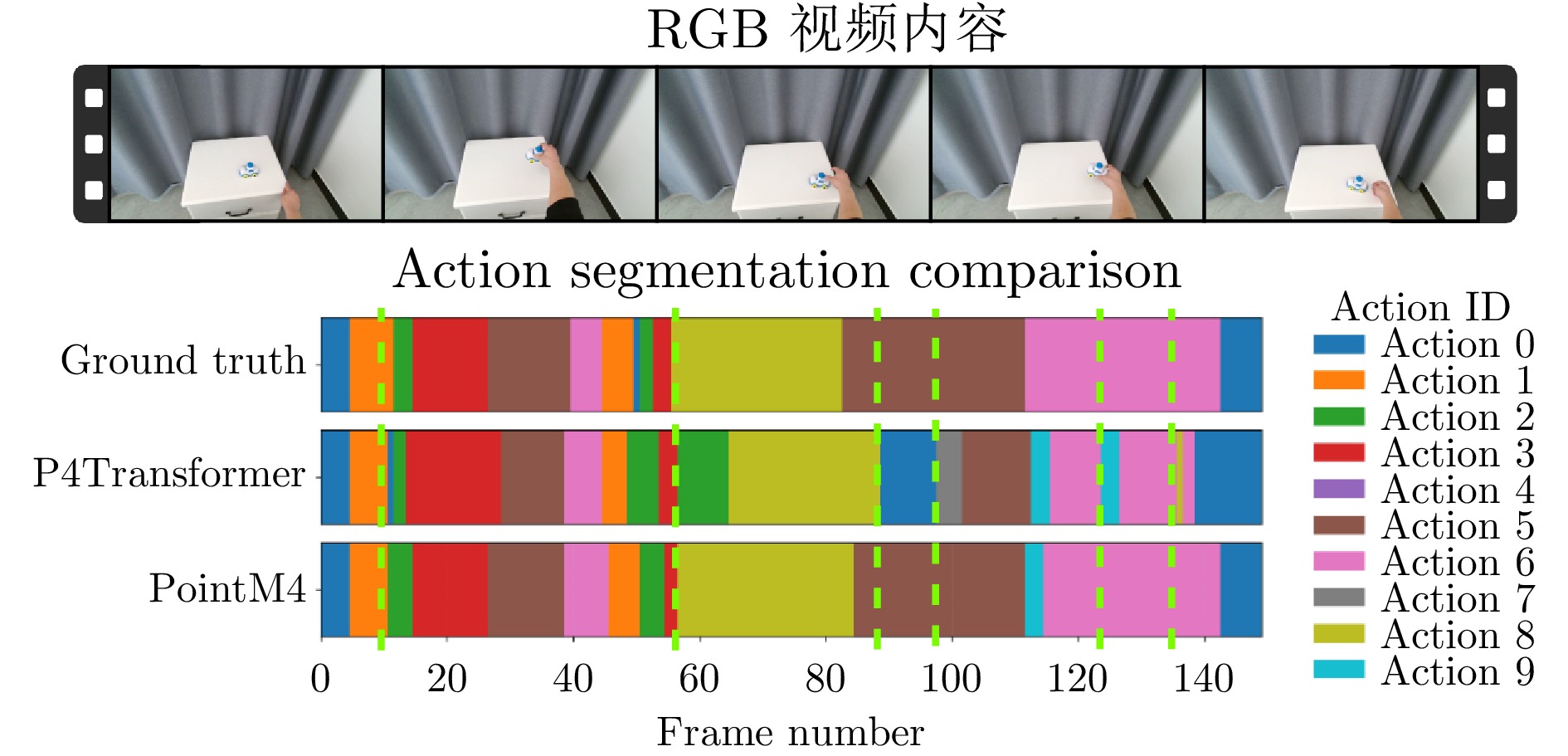
图 4 PointM4与基线模型的动作分割可视化对比图
Fig. 4 Visualization comparison of action segmentation between PointM4 and baseline Models.
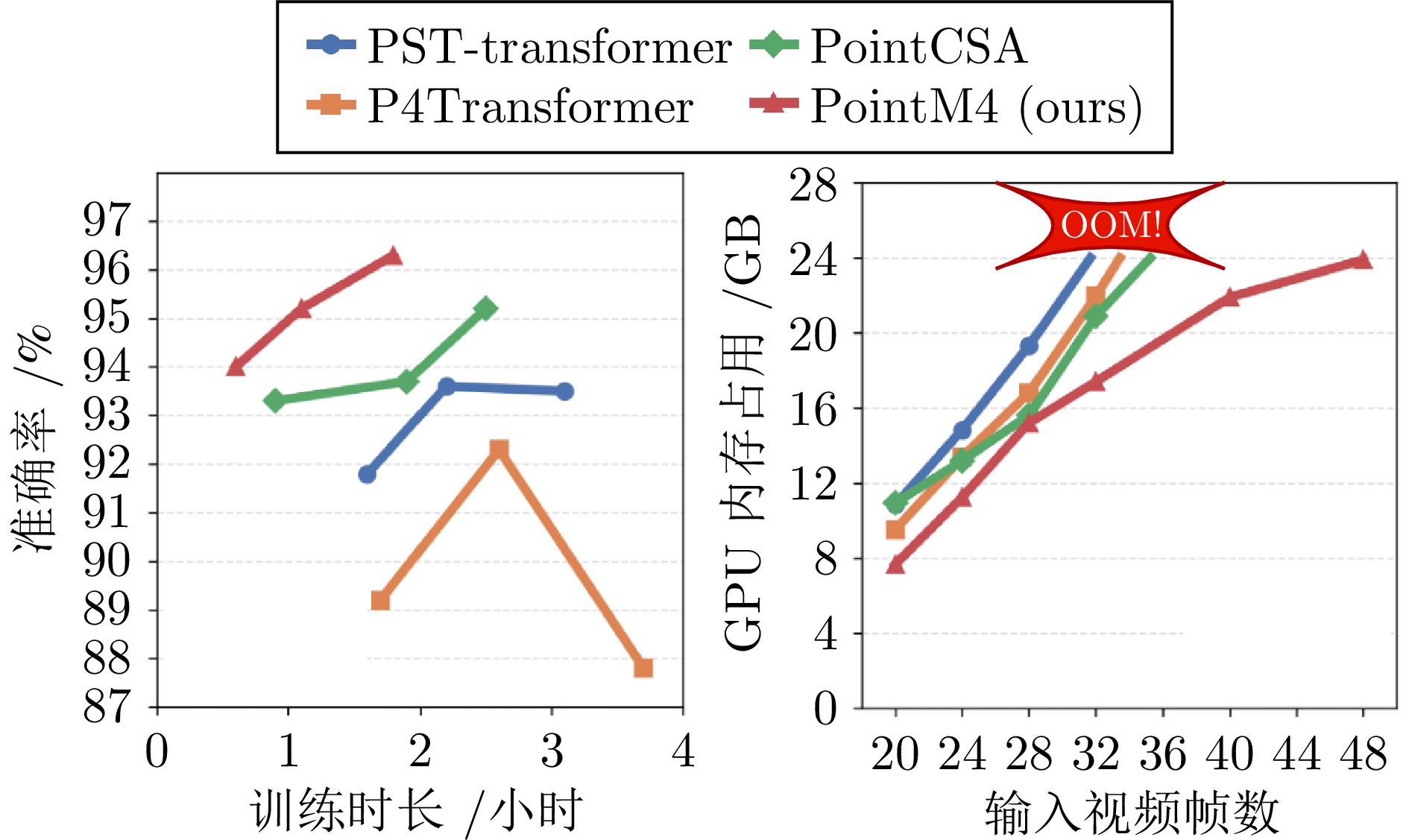
图 6 PointM4与现有方法在训练时长与GPU占用的对比
Fig. 6 Comparison of training time and GPU memory between PointM4 and existing methods
表 1 MSR-Action3D数据集动作识别准确率(%)
Table 1 Action recognition accuracy on the MSR-Action3D dataset (%)
方法 参考文献 12帧 16帧 24帧 32帧 有监督训练 MeteorNet[27] ICCV2019 86.53 88.21 88.50 N/A PSTNet[4] ICLR2021 87.88 89.90 91.20 N/A P4Transformer[3] CVPR2021 87.54 89.56 90.94 87.93 Kinet[28] CVPR2022 88.53 91.92 93.27 N/A PPTr[29] ECCV2022 89.89 90.31 92.33 N/A LeaF[30] ICCV2023 N/A 91.50 93.84 N/A PST-Transformer[19] TPAMI2023 88.15 91.98 93.73 N/A X4D-SceneFormer[31] AAAI2024 N/A 92.56 93.90 N/A MAMBA4D[20] CVPR2025 N/A N/A 93.38 93.10 自监督训练(端到端微调) CPR[5] AAAI2023 91.00 92.15 93.03 N/A C2P[32] CVPR2023 N/A 91.89 94.76 N/A PointCMP[33] CVPR2023 91.58 92.26 93.27 N/A PointCPSC[34] ICCV2023 90.24 92.26 92.68 N/A MaST-Pre[6] ICCV2023 N/A N/A 94.08 N/A 跨模态迁移学习(3D预训练模型适配) PointCSA[9] CVPR2025 92.04 93.73 95.12 95.47 PointBERT+M4 - $ 92.33_{(+0.29)} $ $ {\bf{94.77}}_{(+1.04)} $ $ 95.47_{(+0.35)} $ $ 96.17_{(+0.70)} $ PointMAE+M4 - $ 93.37_{(+1.33)} $ $ 94.08_{(+0.35)} $ $ 95.12_{(+0.00)} $ $ {\bf{96.86}}_{(+1.39)} $ PointGPT-S+M4 - $ {\bf{93.72}}_{(+1.68)} $ $ 94.43_{(+0.70)} $ $ {\bf{95.62}}_{(+0.50)} $ $ 96.52_{(+1.05)} $  下载: 导出CSV
下载: 导出CSV
表 2 HOI4D数据集动作分割准确率(%)
Table 2 Action segmentation accuracy on the HOI4D dataset (%)
方法 参考文献 准确率 编辑距离 F1@50 有监督训练 P4Trans[3] CVPR2021 71.2 73.1 58.2 PPTr[29] ECCV2022 77.4 80.1 69.5 MAMBA4D[20] CVPR2025 85.5 91.3 85.5 自监督训练(端到端微调) P4Trans+C2P[32] CVPR2023 73.5 76.8 62.4 PPTr+C2P[32] CVPR2023 81.1 84.0 74.1 X4D[31] AAAI2024 84.1 91.1 84.8 CrossVideo[36] ICRA2024 83.7 86.0 76.0 跨模态迁移学习(3D预训练模型适配) P4Trans+M4 - $ {\bf{80.1}}_{(+8.9)} $ $ {\bf{74.7}}_{(+1.6)} $ $ {\bf{71.7}}_{(+13.5)} $
下载: 导出CSV
表 4 SHREC'17数据集手势识别准确率(%)
Table 4 Gesture recognition accuracy on the SHREC'17 dataset (%)
方法 参考文献 准确率 有监督训练 PLSTM-base[38] CVPR2020 87.6 PLSTM-early[38] CVPR2020 93.5 PLSTM-PSS[38] CVPR2020 93.1 PLSTM-middle[38] CVPR2020 94.7 PLSTM-late[38] CVPR2020 93.5 Kinet[28] CVPR2022 95.2 自监督训练(端到端微调) PointCMP[33] CVPR2023 93.3 MaST-Pre[6] ICCV2023 92.4 跨模态迁移学习(3D预训练模型适配) PointBERT+CSA[9] CVPR2025 96.2 PointMAE+CSA[9] CVPR2025 95.2 PointGPT-S+CSA[9] CVPR2025 96.5 PointBERT+M4 - $ {\bf{96.4}}_{(+0.2)} $ PointMAE+M4 - $ {\bf{96.3}}_{(+1.1)} $ PointGPT-S+M4 - $ {\bf{96.7}}_{(+0.2)} $
下载: 导出CSV
表 5 滑动窗口尺寸对注意力效率以及模型性能的影响
Table 5 Effect of sliding window size on attention efficiency and model performance
模型 窗口尺寸(点) 帧/秒(s) 注意力占比(%) 准确率(%) A0 $ 640 \times 240 \times 3 $ 102.9 54.5 94.4 A1 $ 16 \times 16 \times 3 $ 110.7 36.9 95.4 A2 $ 8 \times 8 \times 3 $ 112.5 36.6 96.8 A3 $ 4 \times 4 \times 3 $ 113.2 36.5 96.2
下载: 导出CSV
表 6 Mamba扫描策略及变体数量对模型性能的影响(%)
Table 6 Impact of Mamba scanning strategy and number of variants on model performance (%)
模型 双向扫描 洗牌策略 六种变体 准确率 xyz yxz xzy zxy yzx zyx B0 $ \times $ $ \checkmark $ $ \checkmark $ $ \checkmark $ $ \checkmark $ $ \checkmark $ $ \checkmark $ $ \checkmark $ 94.9 B1 $ \checkmark $ $ \times $ $ \checkmark $ $ \checkmark $ $ \checkmark $ $ \checkmark $ $ \checkmark $ $ \checkmark $ 94.2 B2 $ \checkmark $ $ \checkmark $ $ \checkmark $ $ \checkmark $ $ \checkmark $ $ \checkmark $ $ \checkmark $ $ \checkmark $ 96.8 B3 $ \checkmark $ $ \checkmark $ $ \checkmark $ $ \checkmark $ $ \times $ $ \times $ $ \checkmark $ $ \checkmark $ 95.8 B4 $ \checkmark $ $ \checkmark $ $ \times $ $ \times $ $ \checkmark $ $ \checkmark $ $ \checkmark $ $ \checkmark $ 95.1 B5 $ \checkmark $ $ \checkmark $ $ \checkmark $ $ \checkmark $ $ \times $ $ \times $ $ \times $ $ \times $ 94.9 B6 $ \checkmark $ $ \checkmark $ $ \times $ $ \times $ $ \checkmark $ $ \checkmark $ $ \times $ $ \times $ 94.7 B7 $ \checkmark $ $ \checkmark $ $ \times $ $ \times $ $ \times $ $ \times $ $ \checkmark $ $ \checkmark $ 94.7 B8 $ \times $ $ \times $ $ \times $ $ \times $ $ \times $ $ \times $ $ \times $ $ \times $ 92.3
下载: 导出CSV
表 7 适配方法对模型性能的影响
Table 7 Impact of adaptation methods on model performance
模型 适配方法 具体操作 准确率(%) C0 跳过 $ X $ 92.4 C1 相加 $ X+Y $ 92.3 C2 最大值 $ \max (X,\; Y) $ 90.2 C3 拼接 $ {\rm{Linear}}([X,\; Y]) $ 95.5 C4 渐进式适配 $ {\rm{ProAda}}\left(X,\; Y_1,\; Y_2\right) $ 96.8
下载: 导出CSV
表 8 级联顺序对模型性能的影响
Table 8 Impact of cascade order on model performance
模型 是否适配 级联顺序 准确率(%) D0 $ \checkmark $ [TM]$ \times $12 96.8 D1 $ \times $ [T]$ \times $12 [M]$ \times $12 90.6 D2 $ \times $ [T]$ \times $6 [TMM]$ \times $6 92.5 D3 $ \checkmark $ [TTMM]$ \times $6 93.8
下载: 导出CSV
表 9 整体推理流程的时间分析(ms)
Table 9 Overall reasoning process time analysis (ms)
方法 帧数 预处理时间 模型推理 后处理时间 准确率(%) PointCSA 24 3.3 6.7 0.9 95.1 36 不适用(out of memory, OOM) PointM4 24 4.8 3.2 0.9 95.1 36 5.0 3.8 1.0 96.8
下载: 导出CSV
-
[1] 王耀南, 华和安, 张辉, 钟杭, 樊叶心, 梁鸿涛, 常浩, 方勇纯. 性能函数引导的无人机集群深度强化学习控制方法. 自动化学报, 2025, 51(5): 905−916 doi: 10.16383/j.aas.c240519Wang Yao-Nan, Hua He-An, Zhang Hui, Zhong Hang, Fan Ye-Xin, Liang Hong-Tao, Chang Hao, Fang Yong-Chun. Performance function-guided deep reinforcement learning control for UAV swarm. Acta Automatica Sinica, 2025, 51(5): 905−916 doi: 10.16383/j.aas.c240519 [2] 田永林, 沈宇, 李强, 王飞跃. 平行点云: 虚实互动的点云生成与三维模型进化方法. 自动化学报, 2020, 46(12): 2572−2582 doi: 10.16383/j.aas.c200800Tian Yong-Lin, Shen Yu, Li Qiang, Wang Fei-Yue. Parallel point clouds: Point clouds generation and 3D model evolution via virtual-real interaction. Acta Automatica Sinica, 2020, 46(12): 2572−2582 doi: 10.16383/j.aas.c200800 [3] H. Fan, Y. Yang, and M. Kankanhalli. Point 4d transformer networks for spatio-temporal modeling in point cloud videos. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2021. [4] H. Fan, X. Yu, Y. Ding, Y. Yang, and M. Kankanhalli. PSTNet: Point spatio-temporal convolution on point cloud sequences. Proceedings of the International Conference on Learning Representations, 2021. [5] X. Sheng, Z. Shen, and G. Xiao. Contrastive predictive autoencoders for dynamic point cloud self-supervised learning. AAAI Conference on Artificial Intelligence, 2023, 37(8): 9802−9810 [6] Z. Shen, X. Sheng, H. Fan, L. Wang, Y. Guo, Q. Liu, H. Wen, and X. Zhou. Masked spatio-temporal structure prediction for self-supervised learning on point cloud videos. Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 16580-16589. [7] Y. Sun, H. Cheng, C. Lu, Z. Li, M. Wu, H. Lu, and J. Zhu. HyperPoint: Multimodal 3D foundation model in hyperbolic space. Pattern Recognit., 2026, 173: 112800 doi: 10.1016/j.patcog.2025.112800 [8] Y. Sun, J. Zhu, H. Cheng, C. Lu, Z. Yang, L. Chen, and Y. Wang. Align then Adapt: Rethinking Parameter-Efficient Transfer Learning in 4D Perception. IEEE Trans. Multimedia, online, 2026. [9] B. Lv, Y. Zha, T. Dai, X. Yuerong, K. Chen, and S.-T. Xia. Adapting pre-trained 3d models for point cloud video understanding via cross-frame spatio-temporal perception. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2025, pp. 12413-12422. [10] Y. Pang, W. Wang, F. E. Tay, W. Liu, Y. Tian, and L. Yuan. Masked autoencoders for point cloud self-supervised learning. European Conference on Computer Vision, Springer, 2022, pp. 604-621. [11] G. Chen, M. Wang, Y. Yang, K. Yu, L. Yuan, and Y. Yue. PointGPT: Auto-regressively generative pre-training from point clouds. Proceedings of the Advances in Neural Information Processing Systems, vol. 36, 2024. [12] Gu, Albert, and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces. Conference on Language Modeling, 2024. [13] C. R. Qi, H. Su, K. Mo, and L. J. Guibas. PointNet: Deep learning on point sets for 3d classification and segmentation. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 652-660. [14] S. Xie, J. Gu, D. Guo, C. R. Qi, and L. G. O. Litany. Pointcontrast: Unsupervised pre-training for 3d point cloud understanding. European Conference on Computer Vision, 2020. [15] M. Afham, I. Dissanayake, D. Dissanayake, A. Dharmasiri, K. Thilakarathna, and R. Rodrigo. Crosspoint: Self-supervised cross-modal contrastive learning for 3d point cloud understanding. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2022, pp. 9902-9912. [16] R. Zhang, Z. Guo, P. Gao, R. Fang, B. Zhao, D. Wang, Y. Qiao, and H. Li. Point-m2ae: Multi-scale masked autoencoders for hierarchical point cloud pre-training. Proceedings of the Advances in Neural Information Processing Systems, 2022. [17] C. Choy, J. Gwak, and S. Savarese. 4d spatio-temporal convnets: Minkowski convolutional neural networks. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2019, pp. 3075-3084. [18] Z. Deng, X. Li, X. Li, Y. Tong, S. Zhao, and M. Liu. Vg4d: Vision-language model goes 4d video recognition. Proceedings of the IEEE International Conference on Robotics and Automation, 2024, pp. 5014-5020. [19] H. Fan, Y. Yang, and M. Kankanhalli. Point spatio-temporal transformer networks for point cloud video modeling. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(2): 2181−2192 doi: 10.1109/TPAMI.2022.3161735 [20] J. Liu, J. Han, L. Liu, A. I. Aviles-Rivero, C. Jiang, Z. Liu, and H. Wang. Mamba4d: Efficient 4d point cloud video understanding with disentangled spatial-temporal state space models. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2025, pp. 17626-17636. [21] Z. Wang, Z. Chen, Y. Wu, Z. Zhao, L. Zhou, and D. Xu. PointMamba: A hybrid transformer-mamba framework for point cloud analysis. arXiv preprint arXiv: 2405.15463, 2024. [22] Y. Li, R. Bu, M. Sun, W. Wu, X. Di, and B. Chen. PointCNN: Convolution on x-transformed points. Proceedings of the Advances in Neural Information Processing Systems, vol. 31, 2018. [23] X. Han, Y. Tang, Z. Wang, and X. Li. Mamba3d: Enhancing local features for 3d point cloud analysis via state space model. Proceedings of the 32nd ACM International Conference on Multimedia, 2024, pp. 4995-5004. [24] X. Yu, L. Tang, Y. Rao, T. Huang, J. Zhou, and J. Lu. PointBERT: Pre-training 3d point cloud transformers with masked point modeling. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2022. [25] A. X. Chang, T. Funkhouser, L. Guibas, P. Hanrahan, Q. Huang, Z. Li, S. Savarese, M. Savva, S. Song, H. Su et al. ShapeNet: An information-rich 3D model repository. arXiv preprint arXiv: 1512.03012, 2015. [26] W. Li, Z. Zhang, and Z. Liu. Action recognition based on a bag of 3D points. IEEE Conference on Computer Vision and Pattern Recognition Workshops, 2010, pp. 9-14. [27] X. Liu, M. Yan, and J. Bohg. MeteorNet: Deep learning on dynamic 3D point cloud sequences. Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019. [28] J.-X. Zhong, K. Zhou, Q. Hu, B. Wang, N. Trigoni, and A. Markham. No pain, big gain: Classify dynamic point cloud sequences with static models by fitting feature-level space-time surfaces. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2022, pp. 8510-8520. [29] H. Wen, Y. Liu, J. Huang, B. Duan, and L. Yi. Point primitive transformer for long-term 4D point cloud video understanding. European Conference on Computer Vision, Springer, 2022, pp. 19-35. [30] Y. Liu, J. Chen, Z. Zhang, J. Huang, and L. Yi. LEAF: Learning frames for 4D point cloud sequence understanding. Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 604-613. [31] L. Jing, Y. Xue, X. Yan, C. Zheng, D. Wang, R. Zhang, Z. Wang, H. Fang, B. Zhao, and Z. Li. X4D-SceneFormer: Enhanced scene understanding on 4D point cloud videos through cross-modal knowledge transfer. AAAI Conference on Artificial Intelligence, 2024, 38(3): 2670−2678 doi: 10.1609/aaai.v38i3.28045 [32] Z. Zhang, Y. Dong, Y. Liu, and L. Yi. Complete-to-partial 4D distillation for self-supervised point cloud sequence representation learning. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2023, pp. 17661-17670. [33] Z. Shen, X. Sheng, L. Wang, Y. Guo, Q. Liu, and X. Zhou. PointCMP: Contrastive mask prediction for self-supervised learning on point cloud videos. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2023, pp. 1212-1222. [34] X. Sheng, Z. Shen, G. Xiao, L. Wang, Y. Guo, and H. Fan. Point contrastive prediction with semantic clustering for self-supervised learning on point cloud videos. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2023, pp. 16515-16524. [35] Y. Liu, Y. Liu, C. Jiang, K. Lyu, W. Wan, H. Shen, B. Liang, Z. Fu, H. Wang, and L. Yi. HOI4D: A 4D egocentric dataset for category-level human-object interaction. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, June 2022, pp. 21013-21022. [36] Y. Liu, C. Chen, Z. Wang, and L. Yi. CrossVideo: Self-supervised cross-modal contrastive learning for point cloud video understanding. IEEE International Conference on Robotics and Automation, IEEE, 2024, pp. 12436-12442. [37] Q. de Smedt, H. Wannous, J.-P. Vandeborre, J. Guerry, B. Le Saux, and D. Filliat. SHREC'17 Track: 3D hand gesture recognition using a depth and skeletal dataset. 3DOR–10th Eurographics Workshop on 3D Object Retrieval, Apr. 2017, pp. 1-6. [38] Y. Min, Y. Zhang, X. Chai, and X. Chen. An efficient PointLSTM for point clouds based gesture recognition. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2020, pp. 5760-5769. -

 下载:
下载:


计量
- 文章访问数: 169
- HTML全文浏览量: 94
- 被引次数: 0
