

-
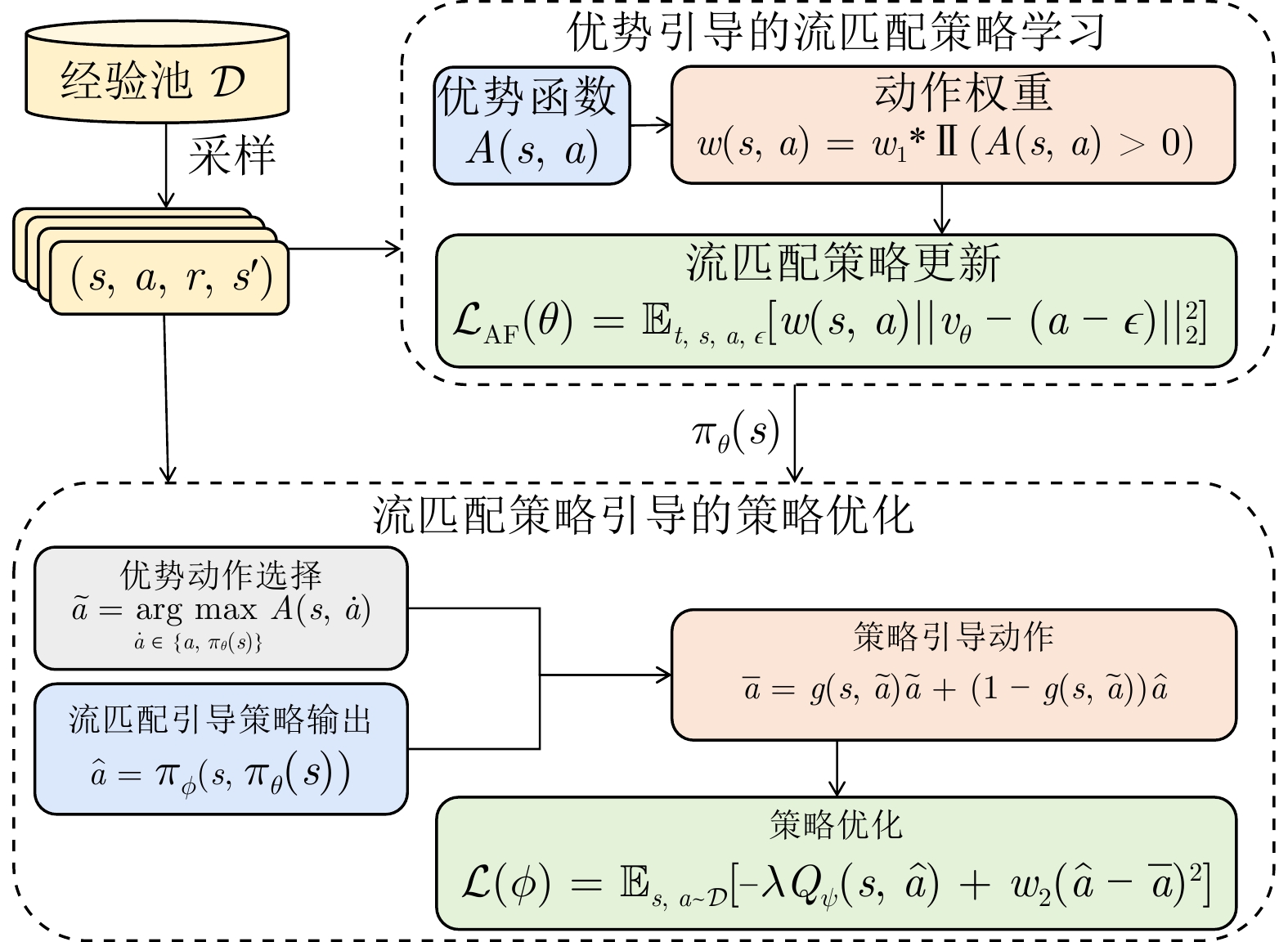
摘要: 离线强化学习旨在利用预先采集的行为数据集优化智能体策略, 其面临的主要挑战是迭代优化的目标策略与产生数据集的行为策略之间存在分布偏移. 现有方法通常采用策略正则化以缓解该问题, 但其难以根据行为数据质量自适应地调整学习过程的约束强度, 并且难以有效建模行为策略中复杂的多峰分布. 针对上述问题, 提出基于流匹配策略优化的离线强化学习方法(FMPO). FMPO利用流匹配模型对行为策略分布进行建模, 从流匹配策略中选择高优势动作以形成自适应约束, 引导学习策略在行为数据分布邻域内进行优化; 同时, 将流匹配策略生成的动作作为先验输入条件, 利用行为先验促进策略的高效学习. 通过基于流匹配策略的优化机制, FMPO能够在策略提升与满足数据集分布约束之间实现动态平衡. 实验结果表明, FMPO在D4RL基准任务上取得了先进性能, 显著优于现有主流离线强化学习方法.Abstract: Offline reinforcement learning aims to optimize agent policies using pre-collected behavior datasets. Its central challenge lies in the distribution shift between the iteratively optimized target policy and the behavior policy that generated the dataset. Existing methods typically employ policy regularization to mitigate this issue; however, they struggle to adaptively adjust the strength of the constraints during learning according to the quality of the behavior data, and they have difficulty effectively modeling the complex multimodal distributions of behavior policies. To address these issues, this paper proposes Flow Matching Policy Optimization (FMPO), an offline reinforcement learning method based on flow matching policy optimization. FMPO leverages a flow matching model to characterize the behavior policy distribution, and selects high-advantage actions from the flow matching policy to form an adaptive constraint that guides the learned policy to be optimized within the neighborhood of the behavior data distribution. Meanwhile, actions generated by the flow matching policy are incorporated as prior conditioning inputs, exploiting the behavioral prior to facilitate efficient policy learning. Through this flow-matching-based optimization mechanism, FMPO is able to achieve a dynamic balance between policy improvement and adherence to the dataset distribution constraint. Experimental results demonstrate that FMPO achieves state-of-the-art performance on the D4RL benchmark, significantly outperforming existing mainstream offline reinforcement learning methods.1)
1 1https://github.com/tinkoff-ai/CORL -
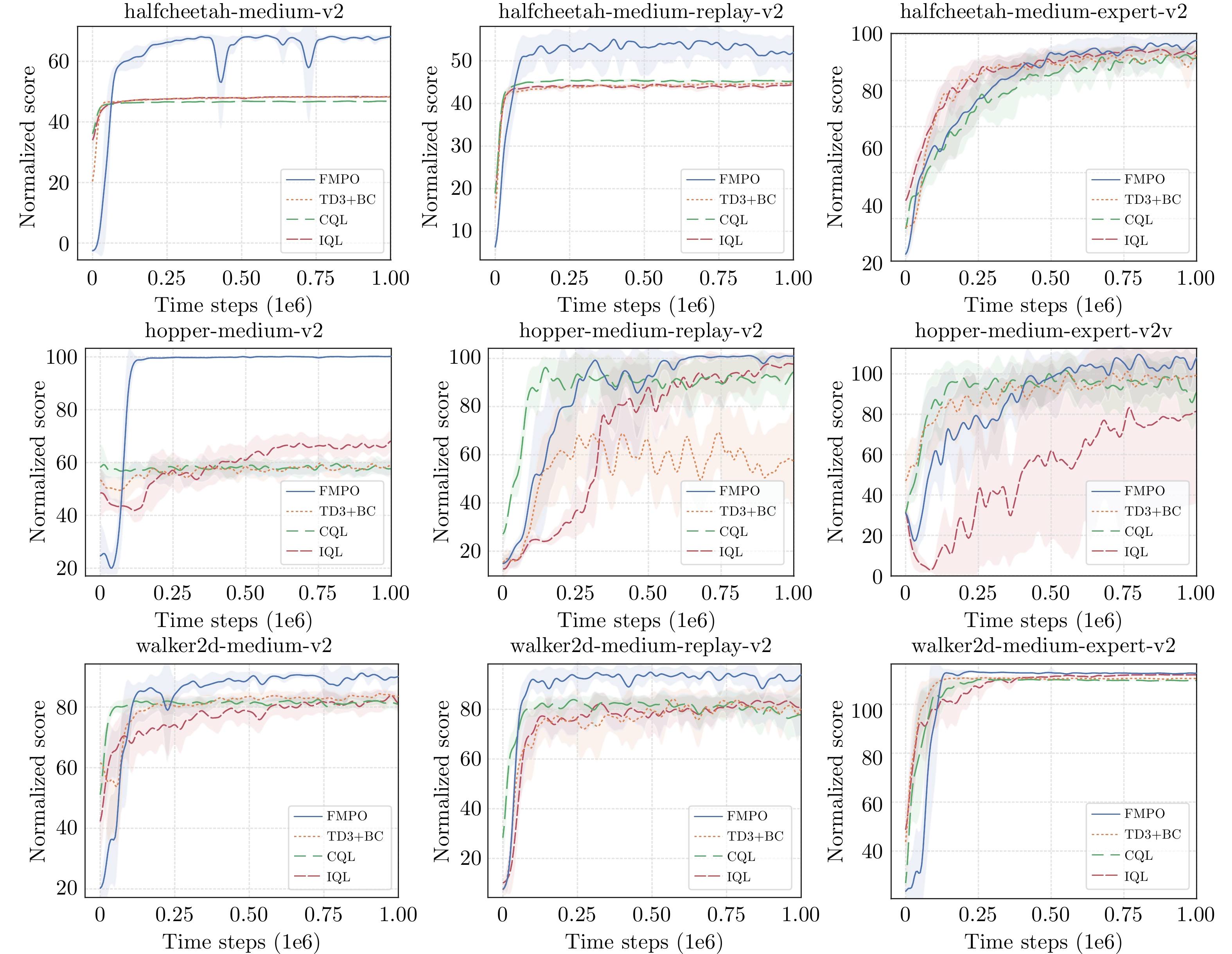
图 2 在D4RL基准的九个任务上进行的性能比较结果.
Fig. 2 Performance comparison results on nine tasks of the D4RL benchmark.
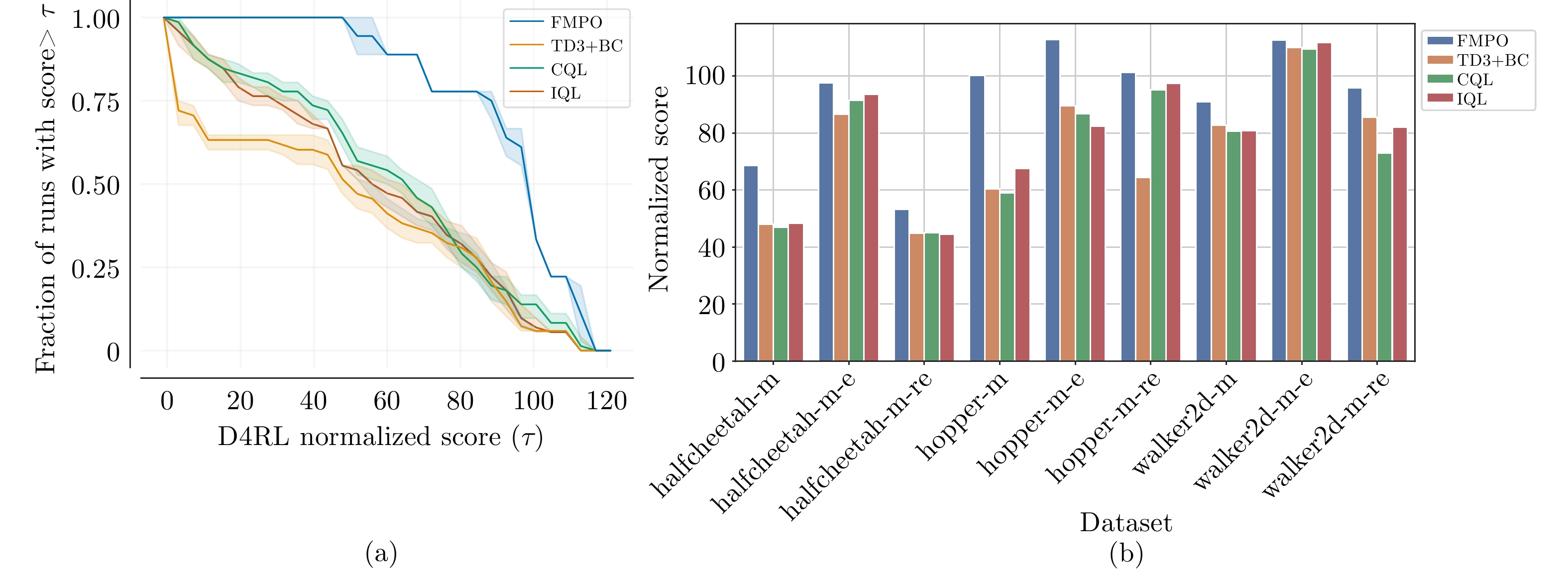
图 4 D4RL基准任务的性能与鲁棒性分析 ((a) 所有任务上的累计性能分布; (b) 九个任务上的最终性能比较).
Fig. 4 Performance and robustness analysis on D4RL benchmark tasks ((a) cumulative performance distribution over all tasks; (b) final performance comparison on nine tasks).

图 3 基于D4RL中15项任务的可靠性评估(95%置信区间).
Fig. 3 Reliability evaluation on 15 tasks in D4RL (95% confidence intervals).
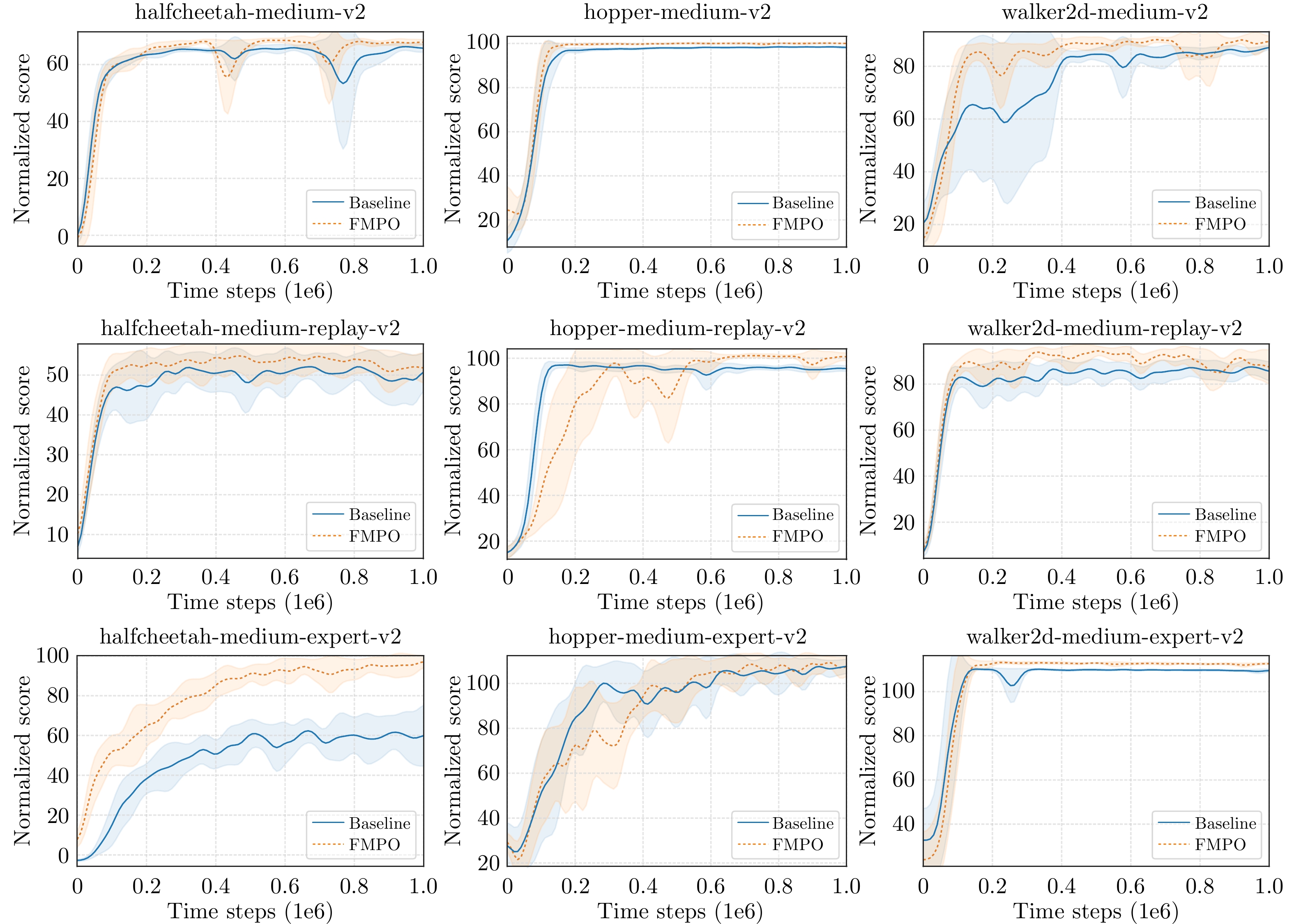
图 5 FMPO与优势门控行为克隆基线的性能对比.
Fig. 5 Performance comparison between FMPO and advantage-gated behavior cloning baseline on nine tasks.
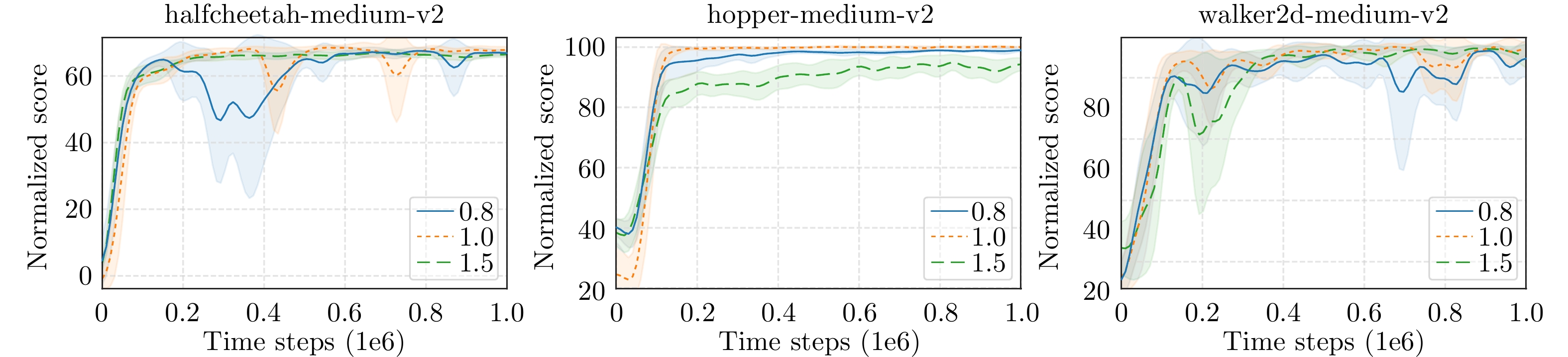
图 6 权重系数$ \omega_2 $的超参数敏感性分析.
Fig. 6 Hyperparameter sensitivity analysis of the weighting coefficient $ \omega_2 $.
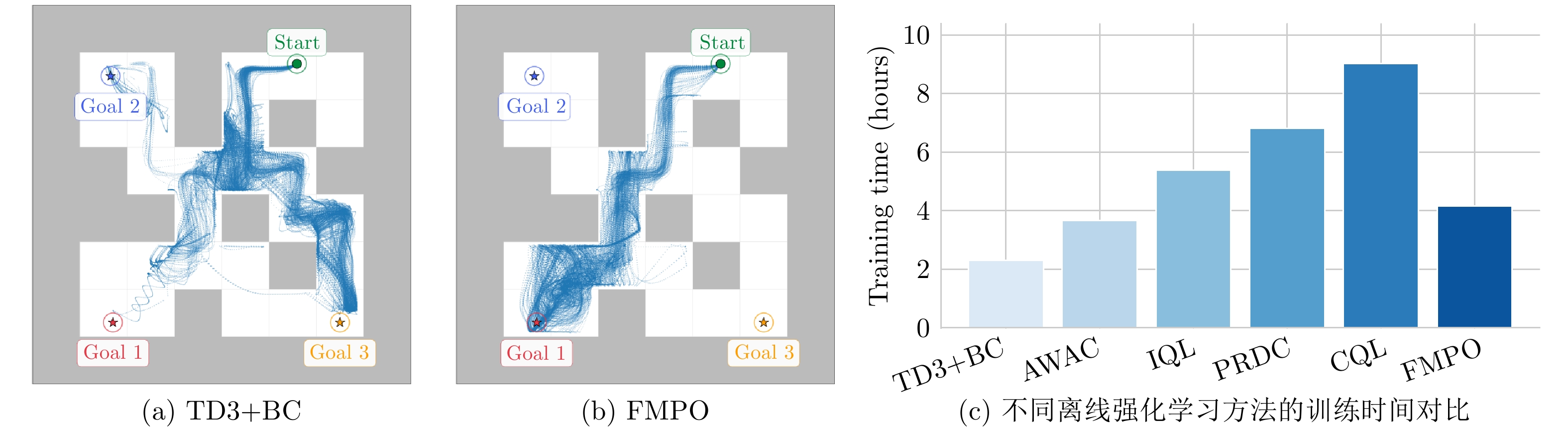
图 7 多目标迷宫任务中的策略轨迹分布与计算效率对比 ((a)k__ge (b) 轨迹分布评估; (c) 训练时间对比).
Fig. 7 Comparison of policy trajectory distributions and computational efficiency in multi-goal maze task ((a)--(b) trajectory distribution evaluation; (c) training time comparison).
表 2 超参数设置
Table 2 Hyperparameter settings
参数名称 数值 FMPO 流匹配时间采样分布 $ {\rm{Unif}}([0,\; 1]) $ 流匹配模型步数 $ 10 $ 迭代次数 1e6 目标网络更新率$ \tau $ 5e-3 策略噪声 0.2 策略噪声截断 (−0.5, 0.5) 策略更新频率 2 折扣因子 0.99 执行器学习率 3e-4 评价器学习率 3e-4 网络结构 执行器/评价器隐藏层维度 256 执行器/评价器层数 3 激活函数 ReLU 批大小 256 优化器 Adam  下载: 导出CSV
下载: 导出CSV
表 1 FMPO及对比基线方法在D4RL数据集上的性能表现.
Table 1 Performance comparisons of FMPO and baseline methods on D4RL datasets.
任务类型 TD3+BC BCQ BEAR CQL SfBC Diffusion-QL DTQL QIPO FMPO (Ours) halfcheetah-medium $ 48.3 $ $ 47.0 $ $ 41.0 $ $ 44.0 $ $ 45.9 \pm 2.2 $ $ 51.1 \pm 0.5 $ $ 57.9 \pm 0.13 $ $ 54.16 \pm 1.27 $ 68.70±0.26 hopper-medium $ 59.3 $ $ 56.7 $ $ 51.9 $ $ 58.5 $ $ 57.1 \pm 4.1 $ $ 90.5 \pm 4.6 $ $ 99.6 \pm 0.87 $ $ 94.05 \pm 13.27 $ 100.33±0.25 walker2d-medium $ 83.7 $ $ 72.6 $ $ 80.9 $ $ 72.5 $ $ 77.9 \pm 2.5 $ $ 87.0 \pm 0.9 $ $ 89.4 \pm 0.13 $ $ 87.61 \pm 1.46 $ 90.92±1.82 halfcheetah-medium-replay $ 44.6 $ $ 40.4 $ $ 29.7 $ $ 45.5 $ $ 37.1 \pm 1.7 $ $ {47.8 \pm 0.33} $ $ 50.9 \pm 0.11 $ $ 48.04 \pm 0.79 $ 53.34±3.29 hopper-medium-replay $ 60.9 $ $ 53.3 $ $ 37.3 $ $ 95.0 $ $ 86.2 \pm 9.1 $ $ {101.3 \pm 0.6} $ $ 100.0 \pm 0.13 $ $ 101.25 \pm 2.18 $ 101.37±0.24 walker2d-medium-replay $ 81.8 $ $ 52.1 $ $ 18.5 $ $ 77.2 $ $ 65.1 \pm 5.6 $ $ {95.5 \pm 1.5} $ $ 88.5\pm2.16 $ $ 78.57 \pm 26.09 $ 95.94±2.46 halfcheetah-medium-expert $ 90.7 $ $ 89.1 $ $ 38.9 $ $ {91.6} $ $ 92.6 \pm 0.5 $ $ 96.8 \pm 0.33 $ $ 92.7\pm0.2 $ $ 94.45 \pm 0.49 $ 97.66±0.66 hopper-medium-expert $ 98.0 $ $ 81.8 $ $ 17.7 $ $ {105.4} $ $ 108.6 \pm 2.1 $ $ {111.1 \pm 1.3} $ $ 109.3\pm1.49 $ $ 108.02 \pm 5.19 $ 112.79 ±0.36 walker2d-medium-expert $ 110.1 $ $ 109.5 $ $ 95.4 $ $ 108.8 $ $ 109.8 \pm 0.2 $ $ 110.1 \pm 0.33 $ $ 110.0\pm0.07 $ $ 110.87 \pm 1.04 $ 112.71±0.22 Gym上的平均性能 $ 677.4 $ $ 602.5 $ $ 411.3 $ $ 698.5 $ $ 680.4 $ $ 792.0 $ $ 798.3 $ $ 776.7 $ 833.8 antmaze-umaze-play $ 91.3 $ $ 0.0 $ $ 73.0 $ $ 84.8 $ $ 92.0 \pm 2.1 $ $ 93.4\pm3.4 $ $ 94.8\pm1.00 $ $ 93.62\pm7.05 $ 97.5.00±4.33 antmaze-umaze-diverse $ 54.6 $ $ 61.0 $ $ 61.0 $ $ 43.3 $ 85.3±3.6 $ 66.2\pm8.6 $ $ 78.8\pm1.83 $ $ 76.12\pm9.93 $ $ {82.50\pm19.20} $ antmaze-medium-play $ 0.0 $ $ 0.0 $ $ 0.0 $ $ 65.2 $ $ 81.3 \pm 2.6 $ $ 76.6\pm10.8 $ $ 79.6\pm1.8 $ $ 80.00\pm13.66 $ 82.50±4.33 antmaze-medium-diverse $ 0.0 $ $ 0.0 $ $ 8.0 $ $ 54.0 $ $ 82.0 \pm 3.1 $ $ 78.6\pm10.3 $ $ {82.8\pm1.71} $ 86.42±5.44 $ {80.00\pm7.07} $ antmaze-large-play $ 0.0 $ $ 6.7 $ $ 0.0 $ $ 18.8 $ 59.3±14.3 $ 46.6\pm8.3 $ $ 52.0\pm2.23 $ $ 55.5\pm29.39 $ $ {57.50\pm8.29} $ antmaze-large-diverse $ 0.0 $ $ 2.2 $ $ 0.0 $ $ 31.6 $ $ 45.5 \pm 6.6 $ $ 56.6\pm7.6 $ $ 54.0\pm2.23 $ $ 32.13\pm23.16 $ 62.50±8.29 Antmaze上的平均性能 $ 145.9 $ $ 69.9 $ $ 142.0 $ $ 297.7 $ $ 445.2 $ $ 417.6 $ $ 441.6 $ $ 423.8 $ 462.5 总平均性能 $ 823.3 $ $ 672.4 $ $ 553.3 $ $ 996.2 $ $ 1125.6 $ $ 1209.6 $ $ 1239.9 $ $ 1200.5 $ 1296.3
下载: 导出CSV
表 3 实验硬件配置
Table 3 Experimental hardware configuration
组件 配置 GPU NVIDIA RTX 3090 CPU 12th Gen Intel(R) Core(TM) i7-12900K
下载: 导出CSV
表 4 实验软件环境
Table 4 Experimental software environment
软件 版本 Python 3.9.19 D4RL 1.1 MuJoCo 3.1.5 Gym 0.23.1 mujoco-py 2.1.2.14 PyTorch 1.13.1 + cu11.7
下载: 导出CSV
-
[1] 刘全, 翟建伟, 章宗长, 钟珊, 周倩, 章鹏, 等. 深度强化学习综述. 计算机学报, 2018, 41(1): 1−27 doi: 10.13973/j.cnki.robot.240176Liu Quan, Zhai Jian-Wei, Zhang Zong-Chang, Zhong Shan, Zhou Qian, Zhang Peng, et al. A survey on deep reinforcement learning. Chinese Journal of Computers, 2018, 41(1): 1−27 doi: 10.13973/j.cnki.robot.240176 [2] 孙长银, 穆朝絮. 多智能体深度强化学习的若干关键科学问题. 自动化学报, 2020, 46(7): 1301−1312Sun Chang-Yin, Mu Chao-Xu. Important scientific problems of multi-agent deep reinforcement learning. Acta Automatica Sinica, 2020, 46(7): 1301−1312 [3] Guo D, Yang D, Zhang H, et al. DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning. Nature, 2025, 645(8081): 633−638 doi: 10.1038/s41586-025-09422-z} [4] Silver D, Schrittwieser J, Simonyan K, Antonoglou I, Huang A, Guezet A, et al. Mastering the game of go without human knowledge. Nature, 2017, 550(7676): 354−359 doi: 10.1038/nature24270 [5] Vinyals O, Babuschkin I, Czarnecki W M, Mathieu M, Dudzik A, Chung J, et al. Grandmaster level in StarCraft Ⅱ using multi-agent reinforcement learning. Nature, 2019, 575(7782): 350−354 doi: 10.1038/s41586-019-1724-z [6] 吴晓光, 刘绍维, 杨磊, 邓文强, 贾哲恒. 基于深度强化学习的双足机器人斜坡步态控制方法. 自动化学报, 2021, 47(8): 1974−1987Wu Xiao-Guang, Liu Shao-Wei, Yang Lei, Deng Wen-Qiang, Jia Zhe-Heng. A gait control method for biped robot on slope based on deep reinforcement learning. Acta Automatica Sinica, 2021, 47(8): 1974−1987 [7] 张威振, 何真, 汤张帆. 风扰下无人机栖落机动的强化学习控制设计. 上海交通大学学报, 2024, 58(11): 1753−1761 doi: 10.16183/j.cnki.jsjtu.2024.187Zhang Wei-Zhen, He Zhen, Tang Zhang-Fan. Reinforcement learning control design for perching maneuver of unmanned aerial vehicles with wind disturbances. Journal of Shanghai Jiao Tong University, 2024, 58(11): 1753−1761 doi: 10.16183/j.cnki.jsjtu.2024.187 [8] Levine S, Kumar A, Tucker G, Fu J. Offline reinforcement learning: Tutorial, review, and perspectives on open problems. arXiv preprint arXiv: 2005.01643, 2020 [9] Huang Z H, Xu X, He H B, Tan J, Sun Z P. Parameterized batch reinforcement learning for longitudinal control of autonomous land vehicles. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2019, 49(4): 730−741 doi: 10.1109/TSMC.2017.2712561 [10] 王雪松, 王荣荣, 程玉虎. 基于表征学习的离线强化学习方法研究综述. 自动化学报, 2024, 50(6): 1104−1128 doi: 10.16383/j.aas.c230546Wang Xue-Song, Wang Rong-Rong, Cheng Yu-Hu. A review of offline reinforcement learning based on representation learning. Acta Automatica Sinica, 2024, 50(6): 1104−1128 doi: 10.16383/j.aas.c230546 [11] 陈鹏宇, 刘士荣, 段帅, 端军红, 刘扬. 基于梯度损失的离线强化学习算法. 自动化学报, 2025, 51(6): 1218−1232Chen Peng-Yu, Liu Shi-Rong, Duan Shuai, Duan Jun-Hong, Liu Yang. Gradient loss for offline reinforcement learning. Acta Automatica Sinica, 2025, 51(6): 1218−1232 [12] 顾扬, 程玉虎, 王雪松. 基于优先采样模型的离线强化学习. 自动化学报, 2024, 50(1): 143−153 doi: 10.16383/j.aas.c230019Gu Yang, Cheng Yu-Hu, Wang Xue-Song. Offline reinforcement learning based on prioritized sampling model. Acta Automatica Sinica, 2024, 50(1): 143−153 doi: 10.16383/j.aas.c230019 [13] Liu T, Xu X, Xie X, Lan Y, et al. Intrinsic value-aligned policy optimization for offline-to-online reinforcement learning. IEEE Transactions on Neural Networks and Learning Systems, 2026, DOI: 10.1109/TNNLS.2026.3688490 [14] Fujimoto S, Gu S S. A minimalist approach to offline reinforcement learning. Advances in Neural Information Processing Systems, 2021, 34: 20132−20145 doi: 10.52202/075280-0511 [15] Fujimoto S, Hoof H, Meger D. Addressing function approximation error in actor-critic methods. In: Proceedings of the 35th International Conference on Machine Learning. Stockholm Sweden: PMLR, 2018. 1587-1596 [16] Jaques N, Ghandeharioun A, Shen J H, Ferguson C, Lapedriza G, Jones N, et al. Way off-policy batch deep reinforcement learning of implicit human preferences in dialog. arXiv preprint arXiv: 1907.00456, 2019. [17] Kostrikov I, Fergus R, Tompson J, Nachum O. Offline reinforcement learning with fisher divergence critic regularization. In: Proceedings of the 38th International Conference on Machine Learning. PMLR, 2021. 139: 5774-5783, . [18] Kumar A, Fu J, Soh M, Tucker G, Levine S. Stabilizing off-policy Q-learning via bootstrapping error reduction. In: Proceedings of the 33rd Annual Conference on Neural Information Processing Systems. Vancouver, Canada: MIT Press, 2019. 11784- 11794 [19] Rouxel Q, Donoso C, Chen F, et al. Extremum flow matching for offline goal conditioned reinforcement learning. In: Proceedings of the 2025 IEEE-RAS 24th International Conference on Humanoid Robots. IEEE, 2025: 981-988. [20] Liu Z, Yang Z, Xu J, et al. ADG: Ambient diffusion-guided dataset recovery for corruption-robust offline reinforcement learning. Advances in Neural Information Processing Systems, 2026, 38: 163045−163079 [21] Liu T, Li J, Zheng Y, et al. Skill expansion and composition in parameter space. In: Proceedings of the 13th International Conference on Learning Representations. Singapore: OpenReview, 2025. [22] Fujimoto S, Meger D, Precup D. Off-policy deep reinforcement learning without exploration. In: Proceedings of the 36th International Conference on Machine Learning. Long Beach, USA: PMLR, 2019. 2052-2062. [23] Wu J, Wu H, Qiu Z, Wang J, Long M. Supported policy optimization for offline reinforcement learning. Advances in Neural Information Processing Systems, 2022, 35: 31278−31291 doi: 10.52202/068431-2268 [24] Wang Z, Hunt J J, Zhou M. Diffusion policies as an expressive policy class for offline reinforcement learning. In: Proceedings of the 11th International Conference on Learning Representations. Kigali Rwanda: OpenReview, 2023. [25] Ho J, Jain A, Abbeel P. Denoising diffusion probabilistic models. Advances in Neural Information Processing Systems, 2020, 33: 6840−6851 [26] Chen H, Lu C, Ying C, et al. Offline reinforcement learning via high-fidelity generative behavior modeling. In: Proceedings of the 11th International Conference on Learning Representations. Kigali Rwanda: OpenReview, 2023. [27] Hansen-Estruch P, Kostrikov I, Janner M, et al. Idql: Implicit q-learning as an actor-critic method with diffusion policies. arXiv preprint arXiv: 2304.10573, 2023. [28] Park S, Li Q, Levine S. Flow Q-learning. In: Proceedings of the 42nd International Conference on Machine Learning, 2025. [29] Liu T, Li Y, Lan Y, et al. Adaptive advantage-guided policy regularization for offline reinforcement learning. In: Proceedings of the 41st International Conference on Machine Learning. Vienna Austria: PMLR, 2024. 31406-31424. [30] Mao Y, Wang Q, Qu Y, et al. Doubly mild generalization for offline reinforcement learning. Advances in Neural Information Processing Systems, 2024, 37: 51436−51473 doi: 10.52202/079017-1628 [31] Gao C X, Wu C, Cao M, et al. Behavior-regularized diffusion policy optimization for offline reinforcement learning. In: Proceedings of the 42nd International Conference on Machine Learning. Vancouver Canada: PMLR, 2025. 18630-18657. [32] Zhang H, Zhang S, Jin J, et al. Balancing signal and variance: Adaptive offline rl post-training for vla flow models. In: Proceedings of the 40th AAAI Conference on Artificial Intelligence. 2026, 40(22): 18755-18763. [33] Lyu L, Li Y, Luo Y, et al. Flow-based policy for online reinforcement learning. Advances in Neural Information Processing Systems, 2026, 38: 93967−93990 [34] Espinosa-Dice N, Zhang Y, Chen Y, et al. Scaling offline rl via efficient and expressive shortcut models. Advances in Neural Information Processing Systems, 2026, 38: 2376−2414 [35] Ki D, Oh J H, Shim S W, et al. Prior-guided diffusion planning for offline reinforcement learning. Advances in Neural Information Processing Systems, 2026, 38: 59790−59820 [36] Hu X, Li S, Xu Y, et al. Enhancing diffusion policies with distribution-matching generator in offline reinforcement learning. In: Proceedings of the 40th AAAI Conference on Artificial Intelligence. 2026, 40(26): 21894-21902. [37] Fang L, Liu R, Zhang J, et al. Diffusion actor-critic: Formulating constrained policy iteration as diffusion noise regression for offline reinforcement learning. In: Proceedings of International Conference on Learning Representations. 2025. [38] Chen T, Wang Z, Zhou M. Diffusion policies creating a trust region for offline reinforcement learning. Advances in Neural Information Processing Systems, 2024, 37: 50098−50125 doi: 10.52202/079017-1585 [39] Mao L, Xu H, Zhan X, et al. Diffusion-DICE: In-sample diffusion guidance for offline reinforcement learning. Advances in Neural Information Processing Systems, 2024, 37: 98806−98834 [40] Dong Z, Hao J, Yuan Y, et al. DiffuserLite: Towards real-time diffusion planning. Advances in Neural Information Processing Systems, 2024, 37: 122556−122583 doi: 10.52202/079017-3895 [41] Chen H, Zheng K, Su H, et al. Aligning diffusion behaviors with Q-functions for efficient continuous control. Advances in Neural Information Processing Systems, 2024, 37: 119949−119975 doi: 10.52202/079017-3812 [42] Ma Y, Liu T, Lan Y, et al. Diffusion policies with value-conditional optimization for offline reinforcement learning. In: Proceedings of the 2025 IEEE/RSJ International Conference on Intelligent Robots and Systems. Hangzhou China: IEEE, 2025. 13468-13475. [43] Chen H, Lu C, Wang Z, et al. Score regularized policy optimization through diffusion behavior. In: Proceedings of the 12th International Conference on Learning Representations. Vienna Austria: OpenReview, 2024. [44] Ding Z, Jin C. Consistency models as a rich and efficient policy class for reinforcement learning. In: Proceedings of the 12th International Conference on Learning Representations. Vienna Austria: OpenReview, 2024. [45] Espinosa-Dice N, Brantley K, Sun W. Expressive Value Learning for Scalable Offline Reinforcement Learning. arXiv preprint arXiv: 2510.08218, 2025. [46] Zhang S, Zhang W, Gu Q. Energy-weighted flow matching for offline reinforcement learning. In: Proceedings of the 13th International Conference on Learning Representations. Singapore: OpenReview, 2025. [47] Lipman Y, Chen R T Q, Ben-Hamu H, et al. Flow matching for generative modeling. In: Proceedings of the 11th International Conference on Learning Representations. Kigali Rwanda: OpenReview, 2023. [48] Kumar A, Zhou A, Tucker G, Levine S. Conservative Q-learning for offline reinforcement learning. Advances in Neural Information Processing Systems, 2020, 33: 1179−1191 doi: 10.52202/068431-0125 [49] Tarasov D, Nikulin A, Akimov D, et al. CORL: Research-oriented deep offline reinforcement learning library. Advances in Neural Information Processing Systems, 2023, 36: 30997−31020 doi: 10.52202/075280-1351 [50] Qin R J, Zhang X, Gao S, et al. NeoRL: A near real-world benchmark for offline reinforcement learning. Advances in Neural Information Processing Systems, 2022, 35: 24753−24765 doi: 10.52202/068431-1795 [51] Yuan L, Zhang Z, Li L, et al. A survey of progress on cooperative multi-agent reinforcement learning in open environment. arXiv: 2312.01058, 2023. [52] Feng Z, Xue R, Yuan L, et al. Multi-agent embodied AI: Advances and future directions. arXiv: 2505.05108, 2025. -

 下载:
下载:

计量
- 文章访问数: 135
- HTML全文浏览量: 109
- 被引次数: 0
