

Scalable Dynamic Event-triggered Optimal Control for Nonlinear Systems via Integral Reinforcement Learning
-
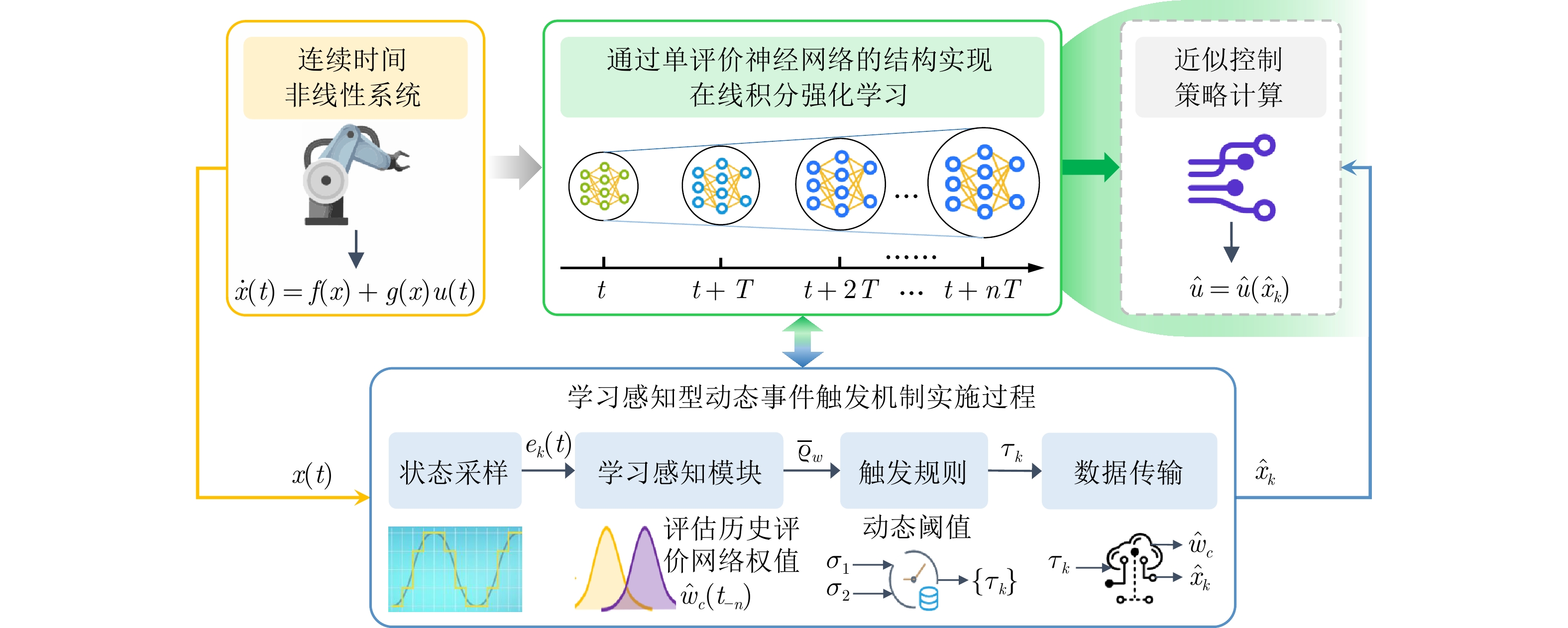
摘要: 事件触发机制, 尤其是动态事件触发机制, 近年来在控制领域引起广泛关注, 其核心挑战在于平衡控制性能与通信资源利用率. 当该机制与学习系统结合时, 这种平衡变得尤为关键, 因为还需兼顾学习效率. 针对具有未知动态的非线性连续时间系统, 提出一种集成积分强化学习、最优控制与学习感知设计的新型动态事件触发最优控制方法, 该方法采用仅含评价网络的自适应结构在线学习最优控制策略, 并通过灵活配置的动态触发规则调控数据传输. 其核心创新在于设计了一种学习感知型动态事件触发机制, 该机制通过分析评价网络权值的历史变化趋势, 构建学习感知参数, 进而自适应地调整事件触发规则中的动态阈值参数. 这使得系统能适宜地在学习关键期采用“繁忙采样”以保障控制与学习精度, 在学习平稳期切换至“空闲采样”以节约通信与计算资源, 从而实现控制性能、学习效率与资源消耗的有效平衡. 理论分析严格证明了闭环系统的渐近稳定性和权值误差的一致最终有界性. 最后, 在一个基准非线性系统和一个单连杆机械臂系统进行了仿真验证与对比实验, 结果表明与传统静态及动态事件触发方法相比, 提出方法能以更少的通信代价获得相当甚至更优的学习与控制效果.Abstract: Event-triggered mechanisms, particularly dynamic ones, have garnered significant interest in the control community, with a key challenge being the balance between control performance and resource utilization. This balance becomes even more crucial when integrating these mechanisms into learning systems, where learning efficiency plays a vital role. This paper presents a learning-based dynamic event-triggered framework that combines optimal control formulation, learning-aware design, and integral reinforcement learning, allowing the system to adapt the triggering process based on learning status and state changes. Using only partial knowledge of the dynamics, an optimal control policy can be learned online via a critic neural network, with data transmission flexibly regulated by dynamic triggering rules. This enables the system to intelligently adopt “busy sampling” when the weight changes dramatically, and switch to “idle sampling” during smooth learning periods to save communication/computational resources, thereby achieving an effective balance between control performance, learning efficiency, and resource consumption. Theoretical analysis rigorously proves the asymptotic stability of closed-loop systems and the uniform ultimate boundedness of weight errors. Finally, the proposed method is comparatively verified on a benchmark nonlinear system and a single-link robotic arm system, indicating that it can achieve comparable or even better learning and control effects with less communication cost.1)
1 1在不引起混淆的情况下, 后续表达中将省略时间变量$ t $.2)2 2在不引起混淆的情况下, 本文中“基于事件的”、“事件驱动的”和“事件触发”等术语将互换使用.3)3 3为紧凑表示起见, 后续将使用简洁表达式$ \nabla\phi=\frac{\partial\phi(x)}{\partial x} $和$ \nabla\varepsilon= $$ \frac{\partial\varepsilon(x)}{\partial x }$.4)4 4在本文中, 如果一个事件机制的触发阈值函数仅依赖于时间或系统状态信息, 则称之为静态的; 而在动态触发机制中, 阈值函数不仅包括状态信息, 还包括一些动态演化表征的辅助变量. -
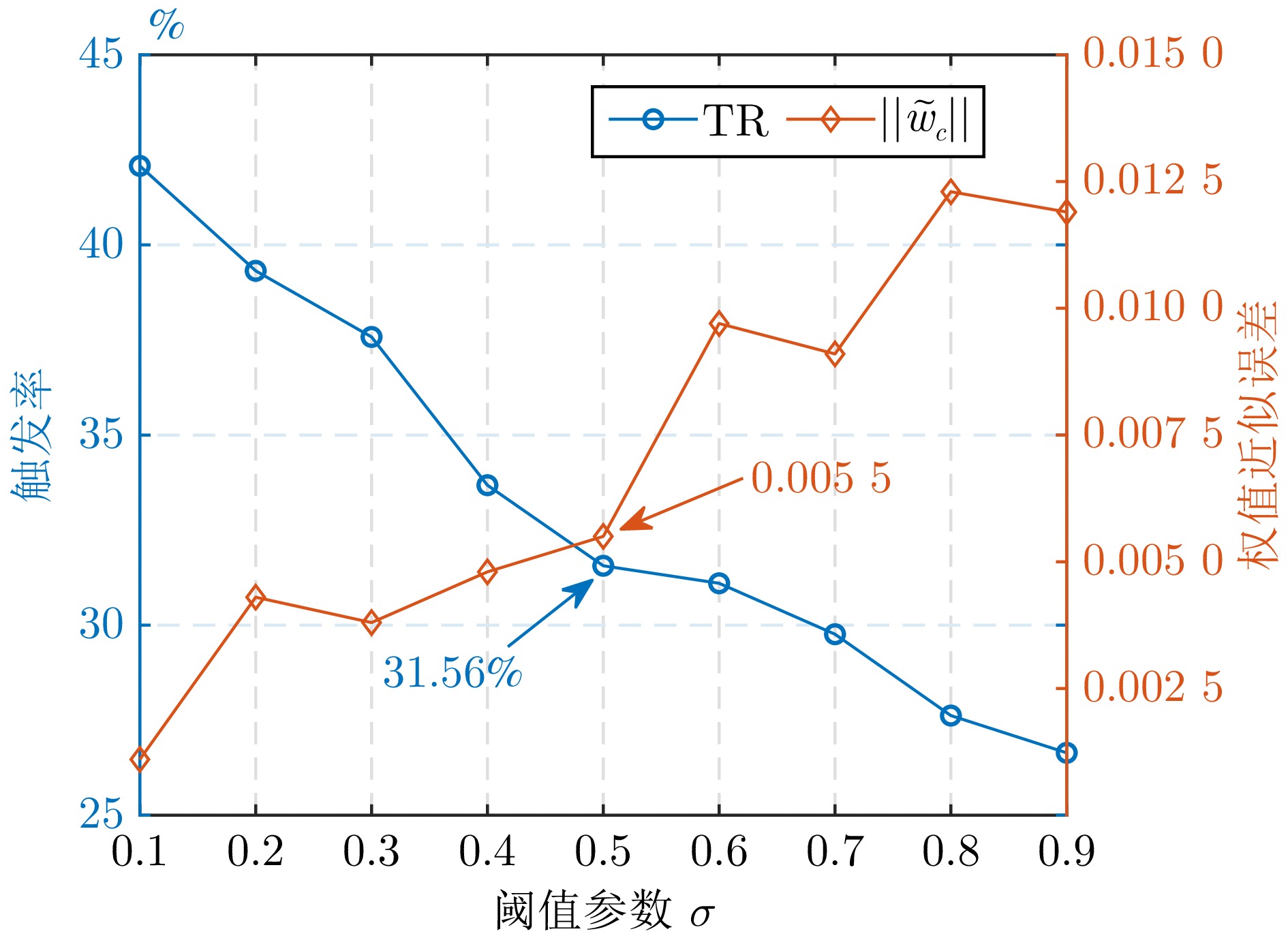
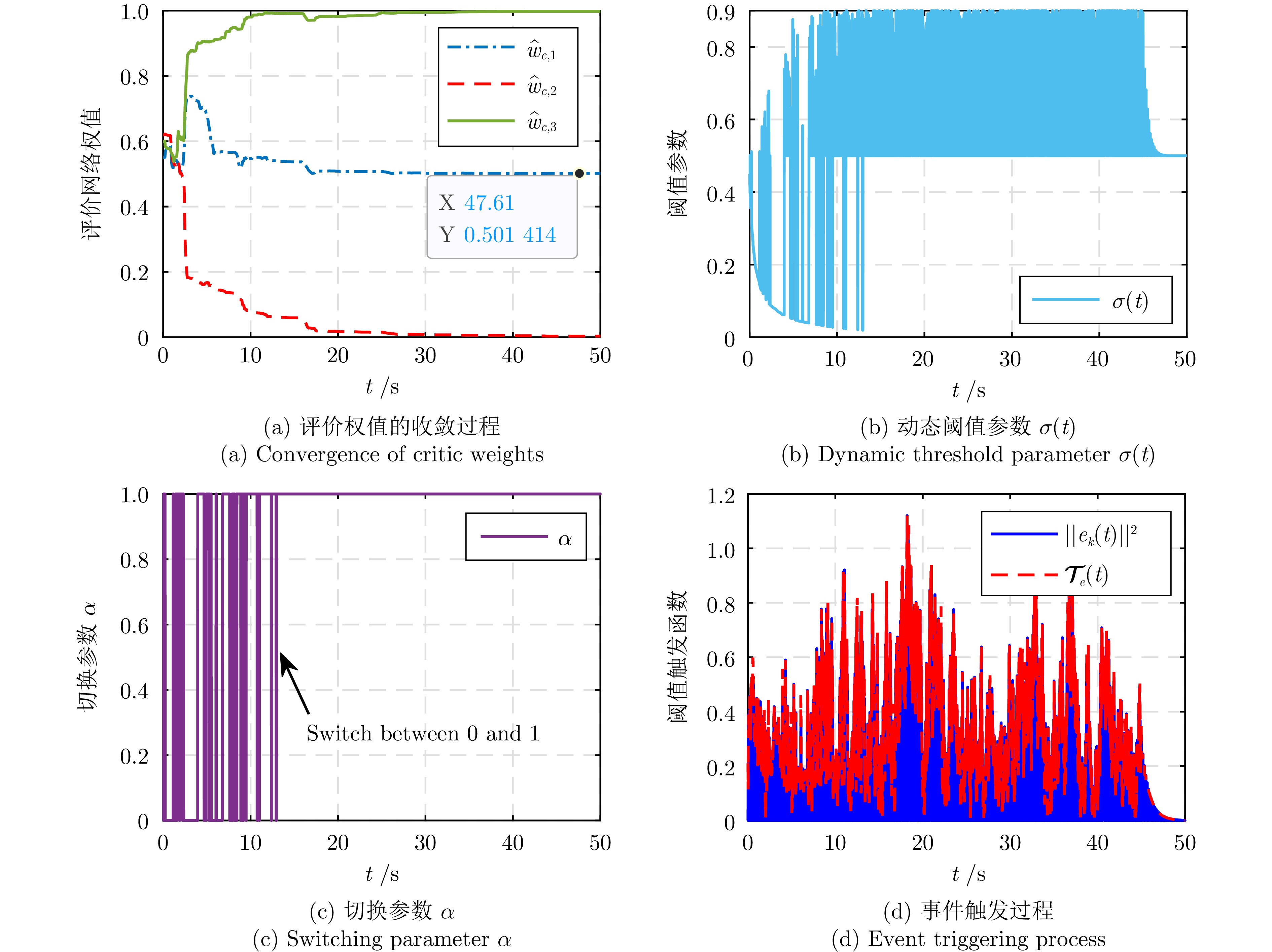
图 2 SETM中的触发率与权值近似误差
Fig. 2 The triggering rate versus weight error approximation in SETM
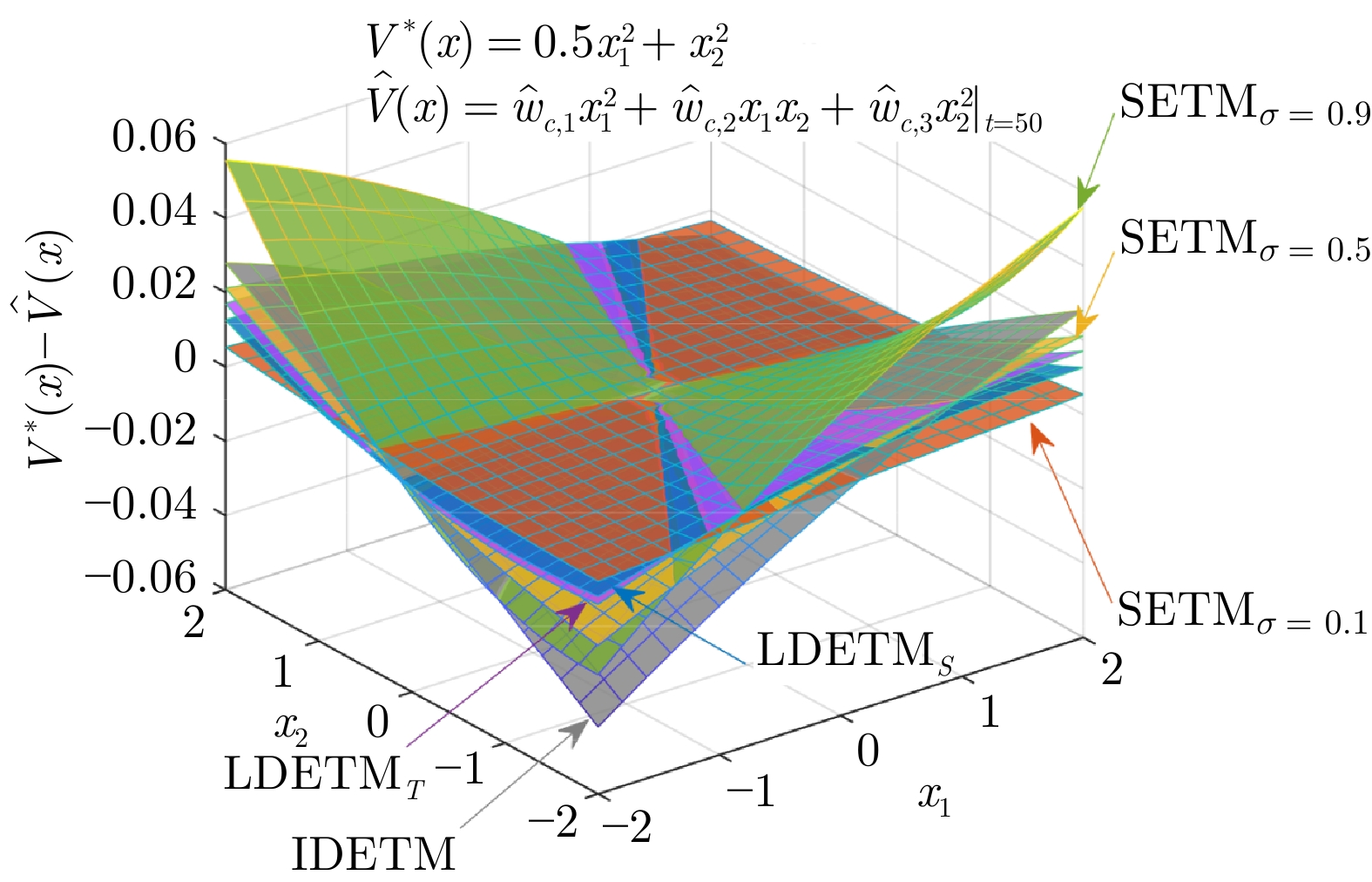
图 5 区间$x_1,\;x_2\in[-2,\;2]$上不同ETM的值函数近似误差
Fig. 5 Cost approximation errors under different ETMs, which are plotted on intervals $x_1,\;x_2\in[-2,\;2]$
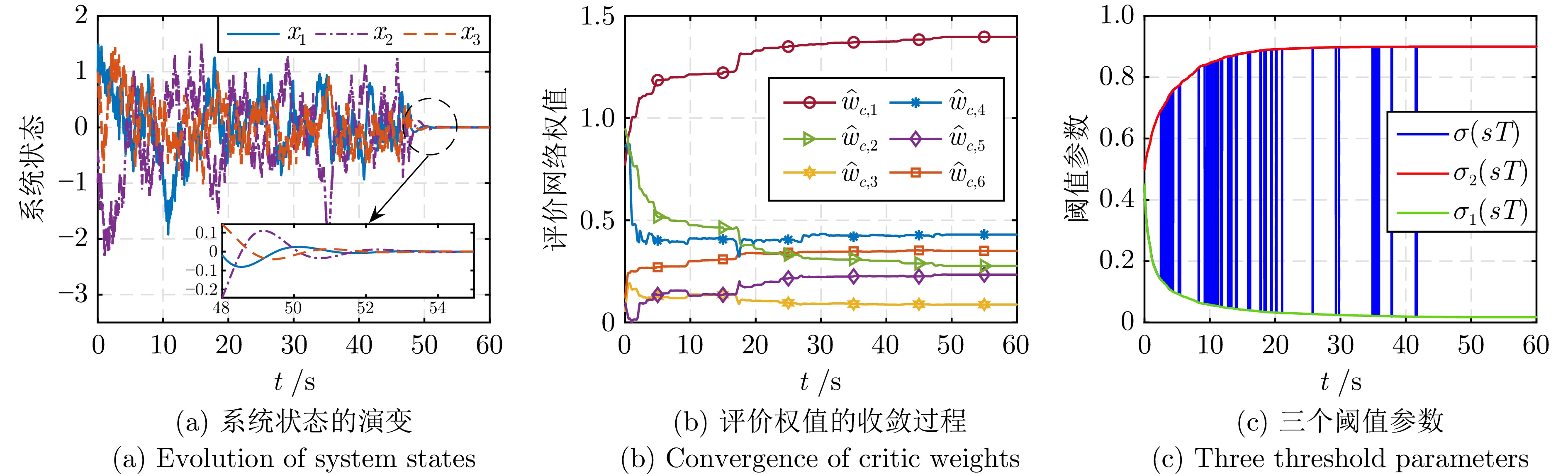
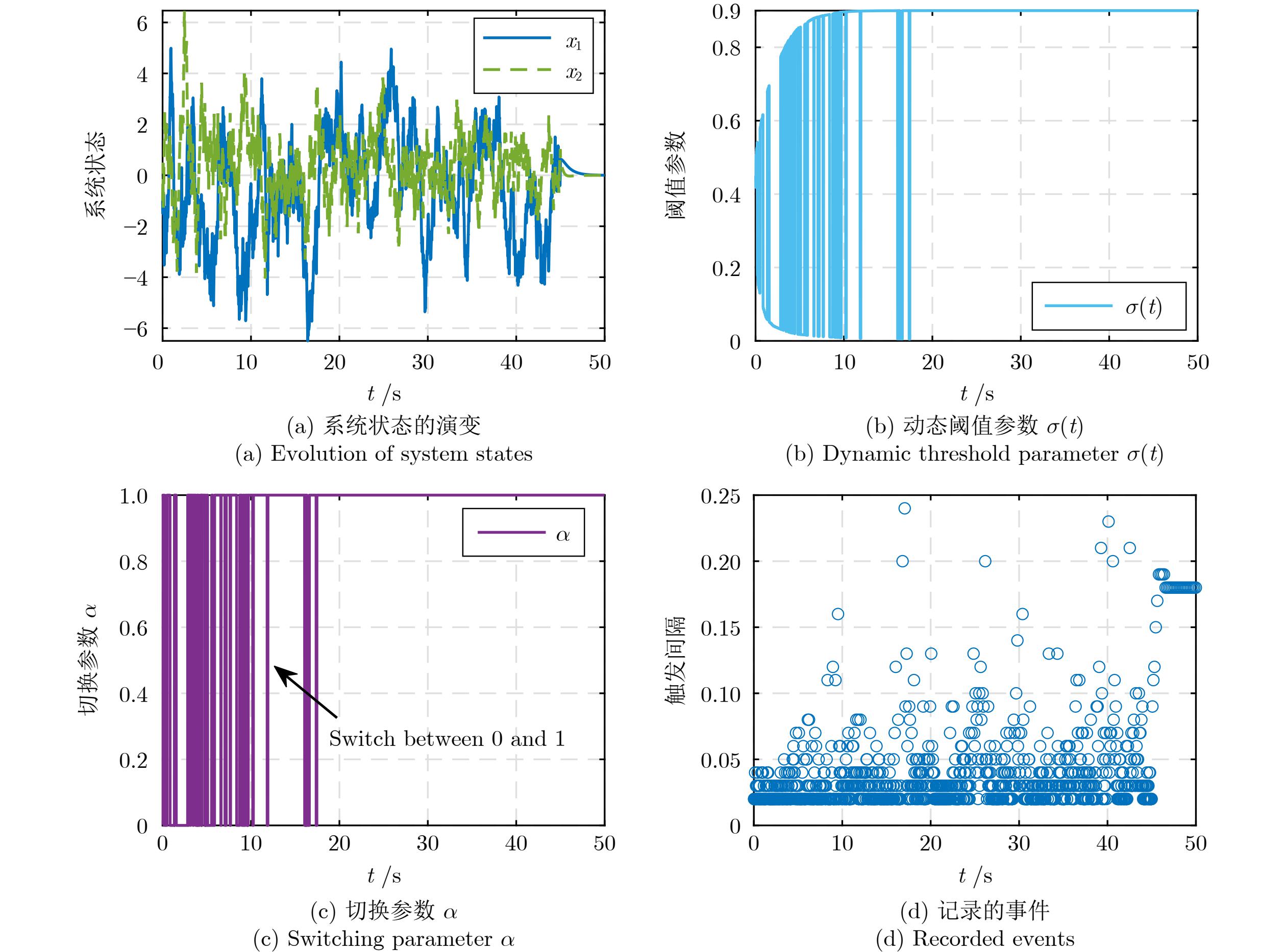
图 7 LDETMT在单连杆机械臂系统上的学习和触发结果
Fig. 7 Learning and triggering results of LDETMT on the one-link manipulator
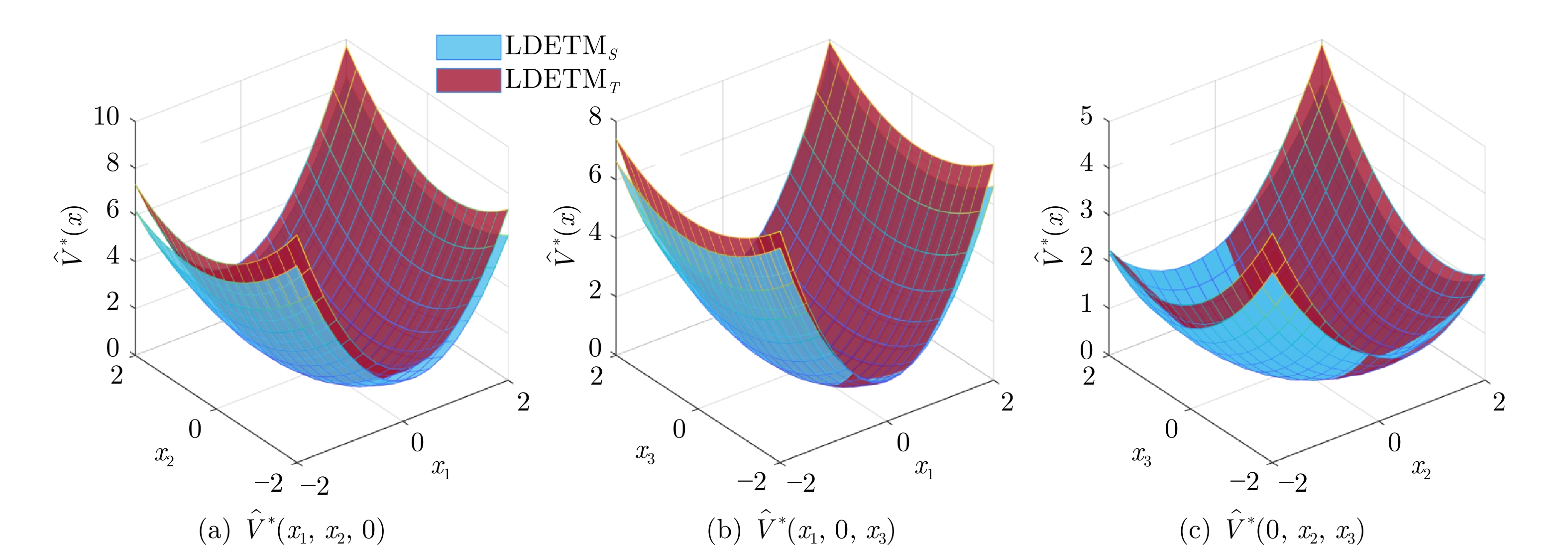
图 8 近似值函数的对比结果($x_1,\;x_2,\;x_3\in[-2,\;2] $)
Fig. 8 Comparison of approximate value functions for $ x_1,\;x_2,\;x_3\in[-2,\;2] $
表 1 两个算例的主要仿真参数
Table 1 The main simulation parameters of the two examples
$ \alpha_c $ $ {\cal{L}}_{u} $ $ \sigma_1(0) $ $ \sigma_2(0) $ $ \underline{\sigma} $ $ \bar{\sigma} $ $ \xi $ $ \vartheta $ 算例1 0.15 4.5 0.45 0.5 0.5 0.9 25 0.01 算例2 10.00 4.5 0.45 0.5 0.5 0.9 25 0.01  下载: 导出CSV
下载: 导出CSV
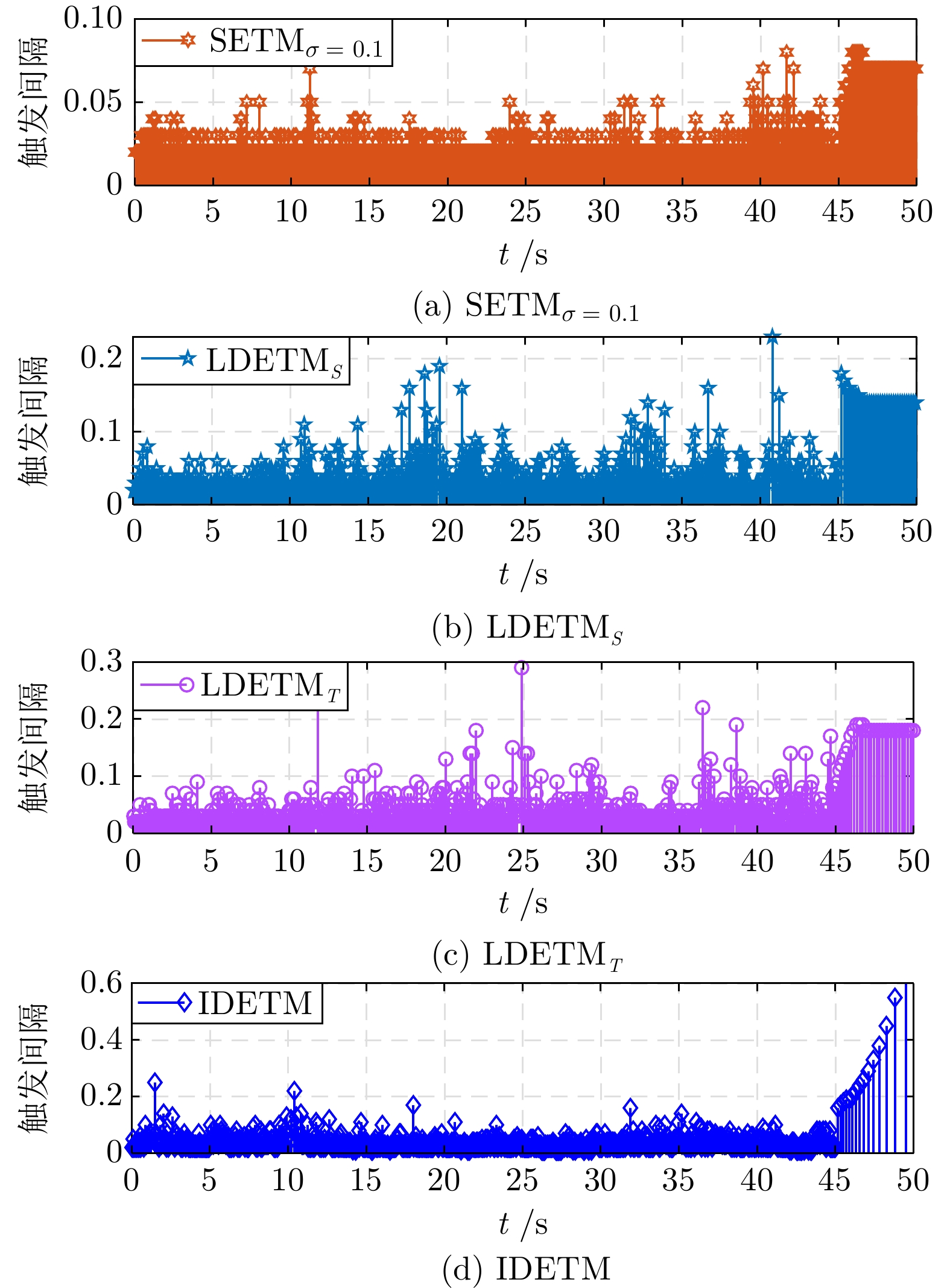
表 2 算例1中不同事件触发机制的对比结果
Table 2 Comparative results of different ETMs in Example 1
事件触发方法 NoRE
($ \downarrow $)TR (%)
($ \downarrow $)EoCW
($ \downarrow $)EoVF ($\times 10^{-2} $)
($\downarrow $)${\mathrm{SETM}} _{\sigma\,=\,0.1} $ 2 104 42.08 0.001 1 [−0.27, 0.51] $ {\mathrm{SETM}} _{\sigma\,=\,0.5} $ 1 587 31.56 0.0055 [–1.99, 1.96] ${\mathrm{SETM}} _{\sigma\,=\,0.9} $ 1 332 26.64 0.0119 [–2.76, 5.57] ${\mathrm{LDETM}} _S $ 1 564 31.28 0.0033 [–0.78, 1.26] LDETMT 1 479 29.58 0.0043 [–0.98, 1.71] IDETM 1 497 29.94 0.0089 [–4.19, 2.80] 注: 粗体表示各指标最优结果.
下载: 导出CSV
表 3 算例2中不同事件触发机制的对比结果
Table 3 Comparative results of different ETMs in Example 2
事件触发方法 NoRE ($ \downarrow $) TR (%) ($ \downarrow $) EoCW ($ \downarrow $) ${\mathrm{SETM}} _{\sigma=0.5} $ 1 412 23.53 0.0296 $ {\mathrm{LDETM}}_S $ 1 446 24.10 0.0207 LDETMT 1 298 21.63 0.0213 IDETM 1 335 22.25 0.0301
下载: 导出CSV
-
[1] Song Y L, Romero A, Müller M, Koltun V, Scaramuzza D. Reaching the limit in autonomous racing: Optimal control versus reinforcement learning. Science Robotics, 2023, 8(82): Article No. eadg1462 doi: 10.1126/scirobotics.adg1462 [2] Dawson C, Gao S, Fan C. Safe control with learned certificates: A survey of neural Lyapunov, barrier, and contraction methods for robotics and control. IEEE Transactions on Robotics, 2023, 39(3): 1749−1767 doi: 10.1109/TRO.2022.3232542 [3] Paden B, Čáp M, Yong S Z, Yershov D, Frazzoli E. A survey of motion planning and control techniques for self-driving urban vehicles. IEEE Transactions on Intelligent Vehicles, 2016, 1(1): 33−55 doi: 10.1109/TIV.2016.2578706 [4] Ma C D, Li A M, Du Y L, Deng H, Yang Y D. Efficient and scalable reinforcement learning for large-scale network control. Nature Machine Intelligence, 2024, 6(9): 1006−1020 [5] Bertsekas D. Reinforcement Learning and Optimal Control. Boston: Athena Scientific, 2019. [6] 罗彪, 胡天萌, 周育豪, 黄廷文, 阳春华, 桂卫华. 多智能体强化学习控制与决策研究综述. 自动化学报, 2025, 51(3): 510−539Luo Biao, Hu Tian-Meng, Zhou Yu-Hao, Huang Ting-Wen, Yang Chun-Hua, Gui Wei-Hua. Survey on multiagent reinforcement learning for control and decision-making. Acta Automatica Sinica, 2025, 51(3): 510−539 [7] Na J, Lv Y F, Zhang K X, Zhao J. Adaptive identifier-critic-based optimal tracking control for nonlinear systems with experimental validation. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2020, 52(1): 459−472 doi: 10.1109/tsmc.2020.3003224 [8] Lewis F L, Vrabie D, Vamvoudakis K G. Reinforcement learning and feedback control: Using natural decision methods to design optimal adaptive controllers. IEEE Control Systems Magazine, 2012, 32(6): 76−105 doi: 10.1109/MCS.2012.2214134 [9] Wang D, Hu L Z, Wang H, Qiao J F. Nonperiodic and periodic event-triggered online H∞ control for constrained nonlinear systems. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2025, 55(1): 331−343 doi: 10.1109/TSMC.2024.3461781 [10] Wang K, Mu C X. Learning-based control with decentralized dynamic event-triggering for vehicle systems. IEEE Transactions on Industrial Informatics, 2022, 19(3): 2629−2639 doi: 10.1109/tii.2022.3168034 [11] Jiang Y, Liu L, Feng G. Adaptive optimal tracking control of networked linear systems under two-channel stochastic dropouts. Automatica, 2024, 165: Article No. 111690 doi: 10.1016/j.automatica.2024.111690 [12] Mailhot N, Abouheaf M, Spinello D. Model-free force control of cable-driven parallel manipulators for weight-shift aircraft actuation. IEEE Transactions on Instrumentation and Measurement, 2023, 73: Article No. 2505108 doi: 10.1109/tim.2023.3346524 [13] Cohen M H, Belta C. Safe exploration in model-based reinforcement learning using control barrier functions. Automatica, 2023, 147: Article No. 110684 doi: 10.1016/j.automatica.2022.110684 [14] Liu D R, Xue S, Zhao B, Luo B, Wei Q L. Adaptive dynamic programming for control: A survey and recent advances. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2020, 51(1): 142−160 [15] Wallace B A, Si J. Continuous-time reinforcement learning control: A review of theoretical results, insights on performance, and needs for new designs. IEEE Transactions on Neural Networks and Learning Systems, 2024, 35(8): 10199−10219 doi: 10.1109/TNNLS.2023.3245980 [16] Tan J K, Xue S S, Li H, Guo Z H, Cao H, Chen B D. Hierarchical safe reinforcement learning control for leader-follower systems with prescribed performance. IEEE Transactions on Automation Science and Engineering, 2025, 22: 19568−19581 doi: 10.1109/TASE.2025.3596912 [17] Zhao M M, Wang D, Song S J, Qiao J F. Safe Q-learning for data-driven nonlinear optimal control with asymmetric state constraints. IEEE/CAA Journal of Automatica Sinica, 2024, 11(12): 2408−2422 [18] Liang Y L, Zhang H G, Zhang J, Ming Z Y. Event-triggered guarantee cost control for partially unknown stochastic systems via explorized integral reinforcement learning strategy. IEEE Transactions on Neural Networks and Learning Systems, 2024, 35(6): 7830−7844 doi: 10.1109/TNNLS.2022.3221105 [19] Mu C X, Zhang Y, Sun C Y. Data-based feedback relearning control for uncertain nonlinear systems with actuator faults. IEEE Transactions on Cybernetics, 2023, 53(7): 4361−4374 doi: 10.1109/TCYB.2022.3171047 [20] Zhou Y H, Luo B, Xu X D, Yang C H. Adaptive robust attitude control for multiple quadrotor systems via integral reinforcement learning. IEEE Transactions on Aerospace and Electronic Systems, 2025, 61(4): 10799−10810 doi: 10.1109/TAES.2025.3560941 [21] Zhao F, Gao W N, Liu T, Jiang Z P. Event-triggered robust adaptive dynamic programming with output feedback for large-scale systems. IEEE Transactions on Control of Network Systems, 2022, 10(1): 63−74 [22] 孙长银, 穆朝絮. 多智能体深度强化学习的若干关键科学问题. 自动化学报, 2020, 46(7): 1301−1312Sun Chang-Yin, Mu Chao-Xu. Important scientific problems of multi-agent deep reinforcement learning. Acta Automatica Sinica, 2020, 46(7): 1301−1312 [23] Girard A. Dynamic triggering mechanisms for event-triggered control. IEEE Transactions on Automatic Control, 2015, 60(7): 1992−1997 doi: 10.1109/TAC.2014.2366855 [24] Ge X H, Han Q L, Zhang X M, Ding D R. Communication resource-efficient vehicle platooning control with various spacing policies. IEEE/CAA Journal of Automatica Sinica, 2024, 11(2): 362−376 doi: 10.1109/JAS.2023.123507 [25] Ge X H, Han Q L, Zhang X M, Ding D R. Dynamic event-triggered control and estimation: A survey. International Journal of Automation and Computing, 2021, 18(6): 857−886 doi: 10.1007/s11633-021-1306-z [26] Wang D, Hu L Z, Zhao M M, Qiao J F. Adaptive critic for event-triggered unknown nonlinear optimal tracking design with wastewater treatment applications. IEEE Transactions on Neural Networks and Learning Systems, 2023, 34(9): 6276−6288 doi: 10.1109/TNNLS.2021.3135405 [27] Mu C X, Wang K, Ni Z. Adaptive learning and sampled-control for nonlinear game systems using dynamic event-triggering strategy. IEEE Transactions on Neural Networks and Learning Systems, 2022, 33(9): 4437−4450 doi: 10.1109/TNNLS.2021.3057438 [28] Chen L, Hao F. Optimal tracking control for unknown nonlinear systems with uncertain input saturation: A dynamic event-triggered ADP algorithm. Neurocomputing, 2024, 564: Article No. 126964 doi: 10.1016/j.neucom.2023.126964 [29] Zhang J, Yang D S, Zhang H G, Wang Y C, Zhou B W. Dynamic event-based tracking control of boiler turbine systems with guaranteed performance. IEEE Transactions on Automation Science and Engineering, 2024, 21(3): 4272−4282 doi: 10.1109/TASE.2023.3294187 [30] Shen H, Li Z, Wang J, Cao J. Nonzero-sum games using actor-critic neural networks: A dynamic event-triggered adaptive dynamic programming. Information Sciences, 2024, 662: Article No. 120236 doi: 10.1016/j.ins.2024.120236 [31] Modares H, Lewis F L. Optimal tracking control of nonlinear partially-unknown constrained-input systems using integral reinforcement learning. Automatica, 2014, 50(7): 1780−1792 doi: 10.1016/j.automatica.2014.05.011 [32] Khalil H K. Nonlinear Systems (3rd edition). Prentice-Hall: Upper Saddle River, 2002. [33] Tian E N, Peng C. Memory-based event-triggering H∞ load frequency control for power systems under deception attacks. IEEE Transactions on Cybernetics, 2020, 50(11): 4610−4618 doi: 10.1109/TCYB.2020.2972384 [34] Xie L, Cheng J, Zou Y, Wu Z G, Yan H. A dynamic-memory event-triggered protocol to multiarea power systems with semi-Markov jumping parameter. IEEE Transactions on Cybernetics, 2023, 53(10): 6577−6587 doi: 10.1109/TCYB.2022.3208363 [35] Vamvoudakis K G, Lewis F L. Online actor-critic algorithm to solve the continuous-time infinite horizon optimal control problem. Automatica, 2010, 46(5): 878−888 doi: 10.1016/j.automatica.2010.02.018 [36] Xue L, Zhang T, Zhang W, Xie X J. Global adaptive stabilization and tracking control for high-order stochastic nonlinear systems with time-varying delays. IEEE Transactions on Automatic Control, 2018, 63(9): 2928−2943 doi: 10.1109/TAC.2018.2797169 [37] Xing L, Wen C. Dynamic event-triggered adaptive control for a class of uncertain nonlinear systems. Automatica, 2023, 158: Article No. 111286 doi: 10.1016/j.automatica.2023.111286 -

 下载:
下载:

计量
- 文章访问数: 291
- HTML全文浏览量: 147
- PDF下载量: 79
- 被引次数: 0
