

Weakly Supervised Segmentation Method With Autoregressive Liver Tumor Synthesis Augmentation
-
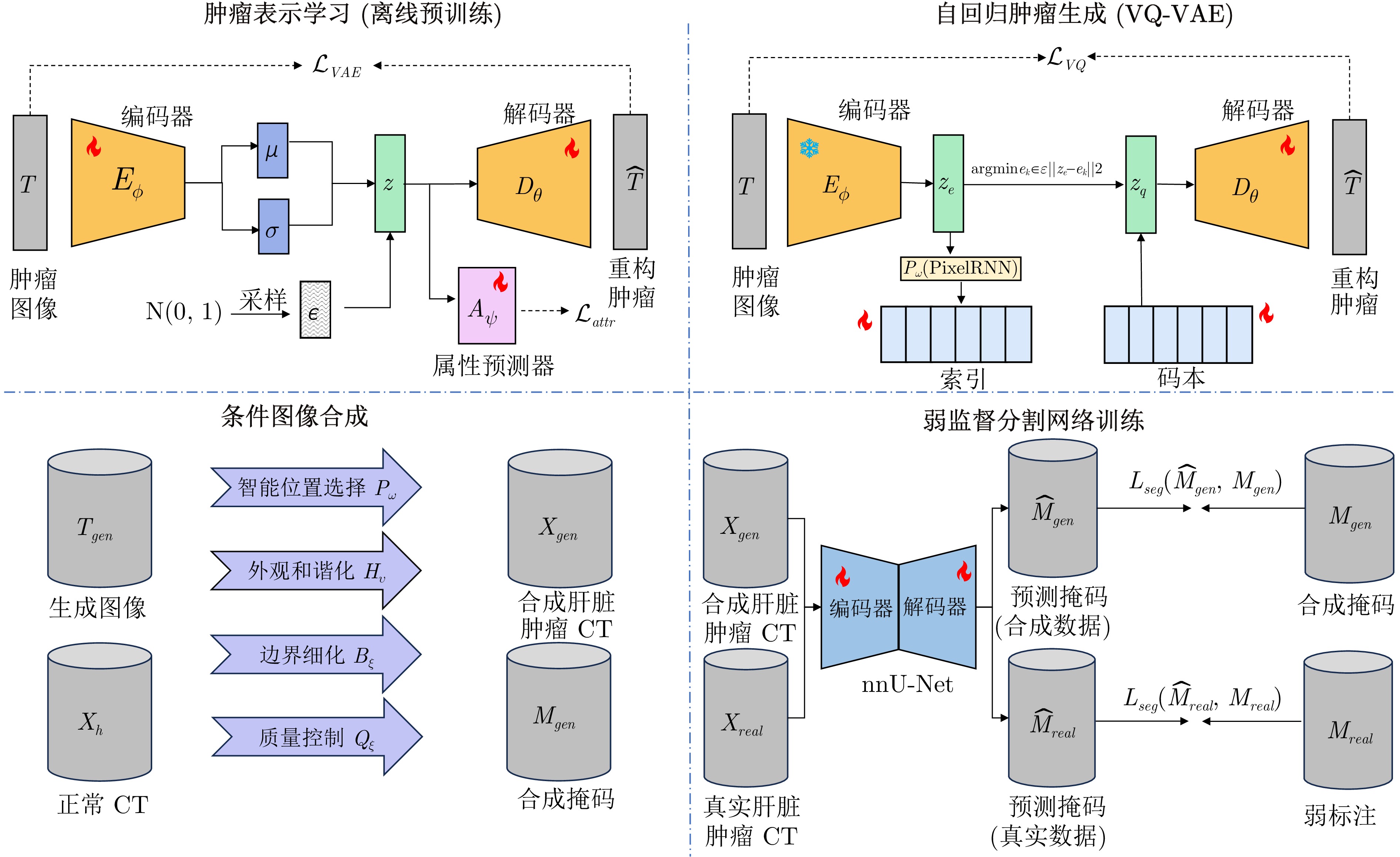
摘要: 肝脏肿瘤精准分割是计算机辅助诊断中的关键任务, 但现有深度学习方法高度依赖大规模像素级标注, 而医学图像标注需要专业放射科医生参与, 成本高且耗时, 限制了临床应用. 为此, 提出AutoSynth-Liver, 一种基于自回归模型的肝脏肿瘤合成增强框架. 该框架通过学习真实肿瘤的外观特征与空间分布规律, 生成多样化且逼真的合成肿瘤, 并自然融合到健康肝脏区域, 从而构建大量带精确标注的训练数据, 实现低标注条件下的高性能分割. 具体包括: 1)基于PixelCNN或VQ-VAE结合Transformer的自回归肿瘤生成模块, 用于建模肿瘤纹理与边界特征; 2)条件图像合成模块, 用于保证肿瘤融合的解剖学合理性; 3)混合监督分割训练模块, 通过联合使用合成数据与少量真实标注数据提升分割性能. 在LiTS17、3DIRCADb和CHAOS数据集上的实验表明, 仅使用合成数据训练时, AutoSynth-Liver的DSC即可达到66.2%, 相当于全监督方法(71.2%)的93.0%; 结合10%真实标注数据后, DSC提升至69.1%, 接近全监督水平. 同时, 该框架将人工标注工作量减少90%以上, 并在病灶检测率和体积测量等临床指标上达到可接受水平.Abstract: Precise liver tumor segmentation is a key task in computer-aided diagnosis. However, existing deep learning methods heavily rely on large-scale pixel-level annotations, while medical image labeling requires professional radiologists and is both costly and time-consuming, which limits clinical application. To address this issue, AutoSynth-Liver, an autoregressive-model-based liver tumor synthesis augmentation framework, is proposed. The framework learns the appearance characteristics and spatial distribution patterns of real tumors to generate diverse and realistic synthetic tumors, which are naturally integrated into healthy liver regions to construct large-scale training data with accurate annotations, enabling high-performance segmentation under limited annotation conditions. Specifically, AutoSynth-Liver consists of: 1) An autoregressive tumor generation module based on PixelCNN or VQ-VAE combined with Transformer for modeling tumor texture and boundary features; 2) A conditional image synthesis module that ensures anatomically plausible tumor fusion; 3) A hybrid-supervised segmentation training module that jointly utilizes synthetic data and a small amount of real annotated data to enhance segmentation performance. Experiments on the LiTS17, 3DIRCADb, and CHAOS datasets demonstrate that AutoSynth-Liver achieves a DSC of 66.2% using only synthetic data for training, reaching 93.0% of fully supervised method (71.2%); With an additional 10% of real annotated data, the DSC further improves to 69.1%, approaching fully supervised performance. Meanwhile, the framework reduces manual annotation workload by more than 90% and achieves acceptable performance in clinical indicators such as lesion detection rate and volume measurement.
-
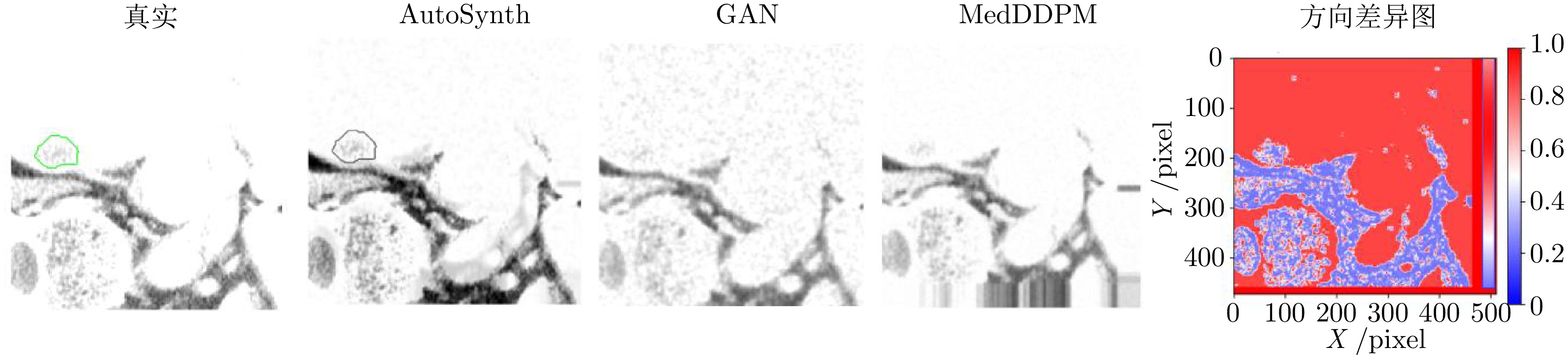
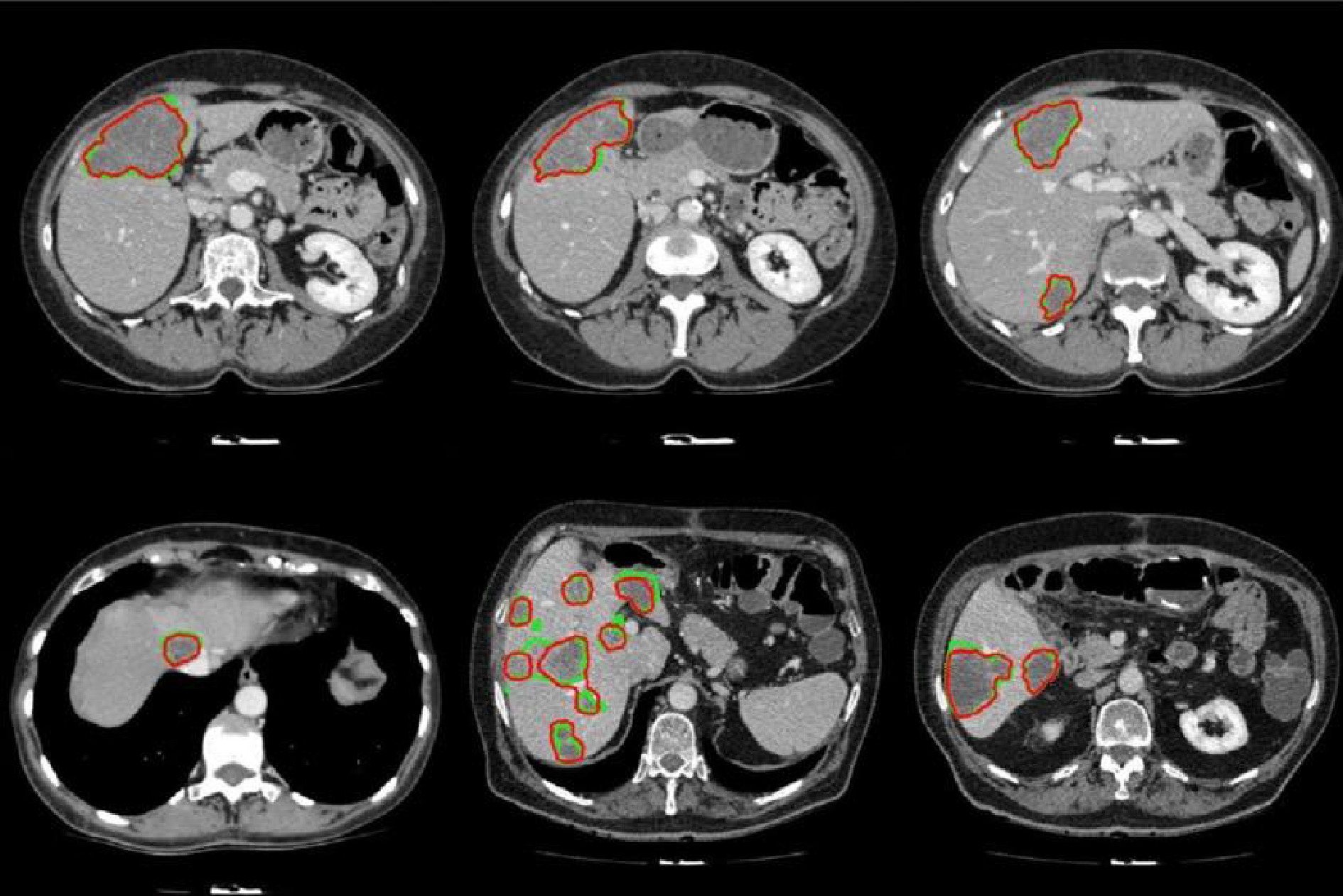
图 2 不同生成方法下的肿瘤合成结果与方向差异热图
Fig. 2 Tumor synthesis results and directional difference heatmaps generated by different methods
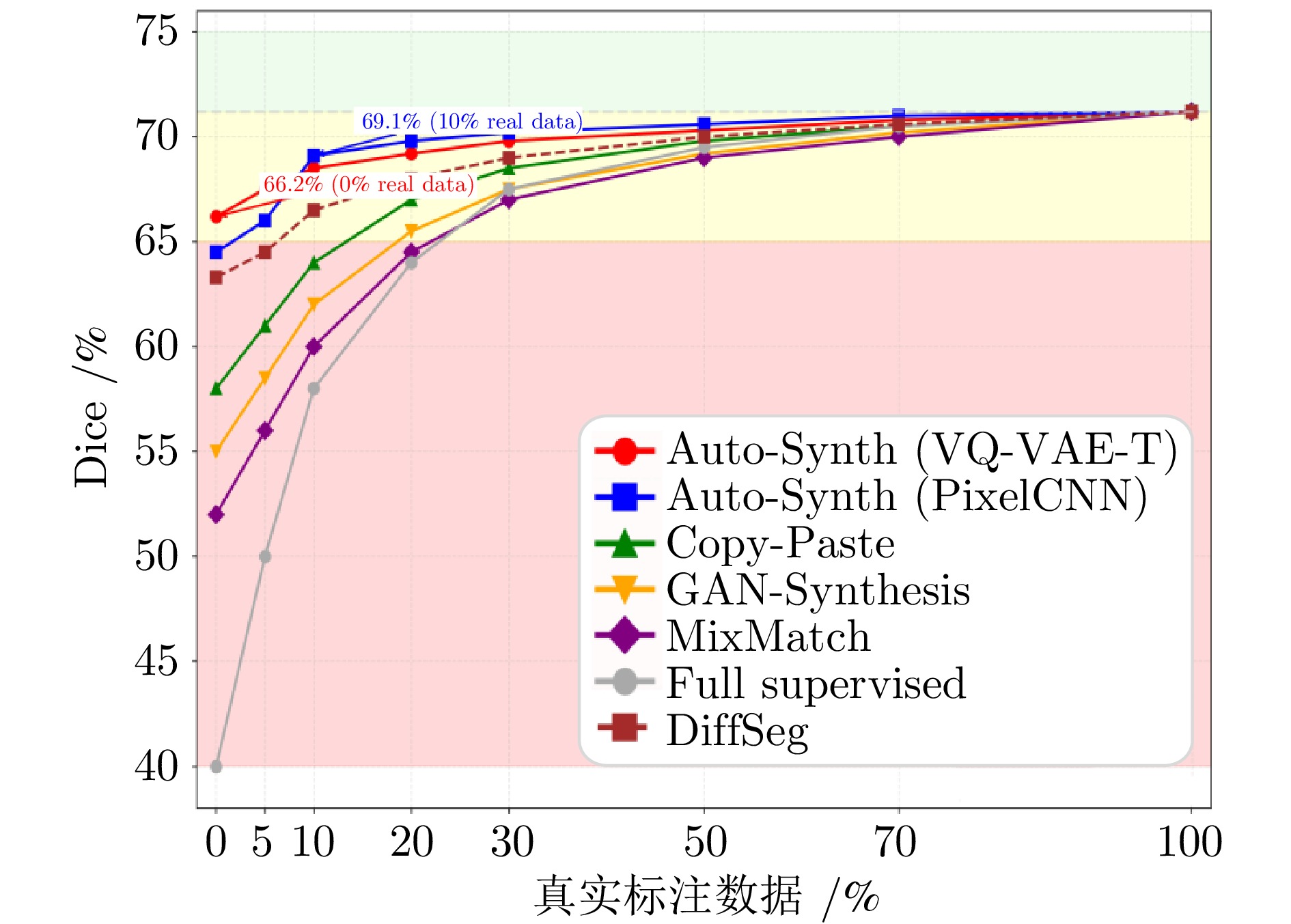
图 4 分割性能随真实标注数据比例的变化
Fig. 4 Variation of segmentation performance with the proportion of annotated ground truth data
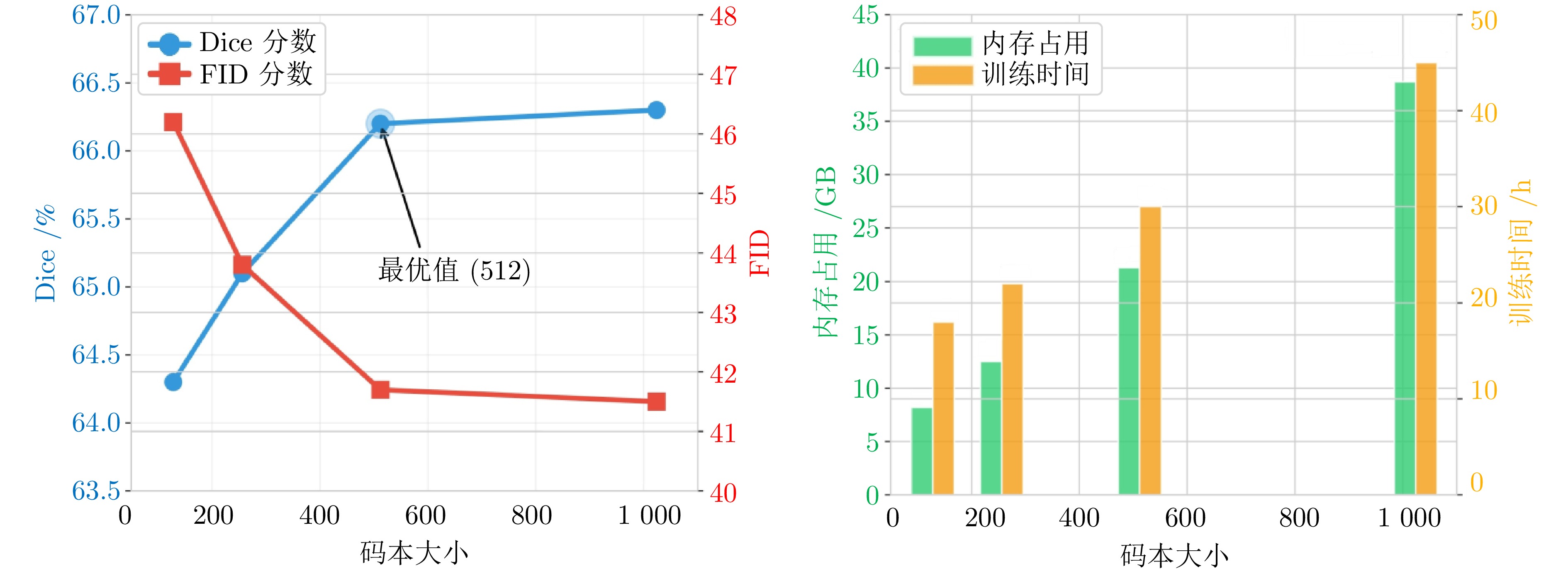
图 5 码本大小对模型性能和计算资源的影响
Fig. 5 Impact of codebook size on model performance and computational resources
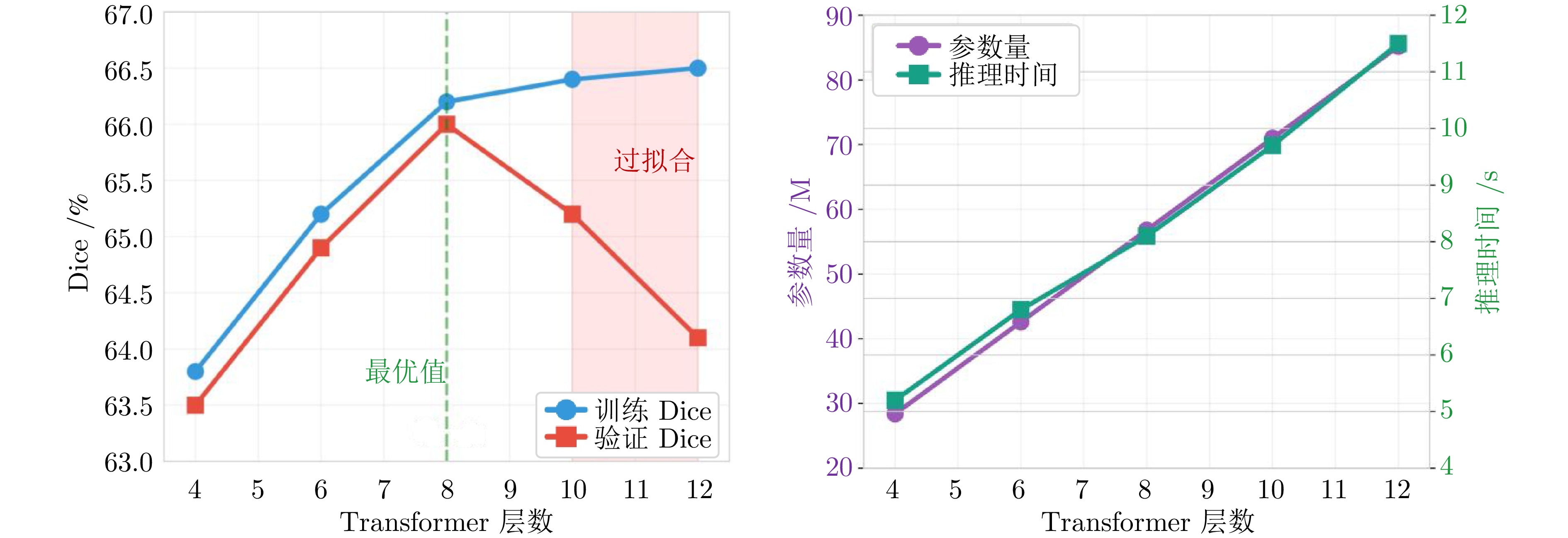
图 6 Transformer层数对性能和复杂度的影响
Fig. 6 Impact of Transformer depth on performance and complexity
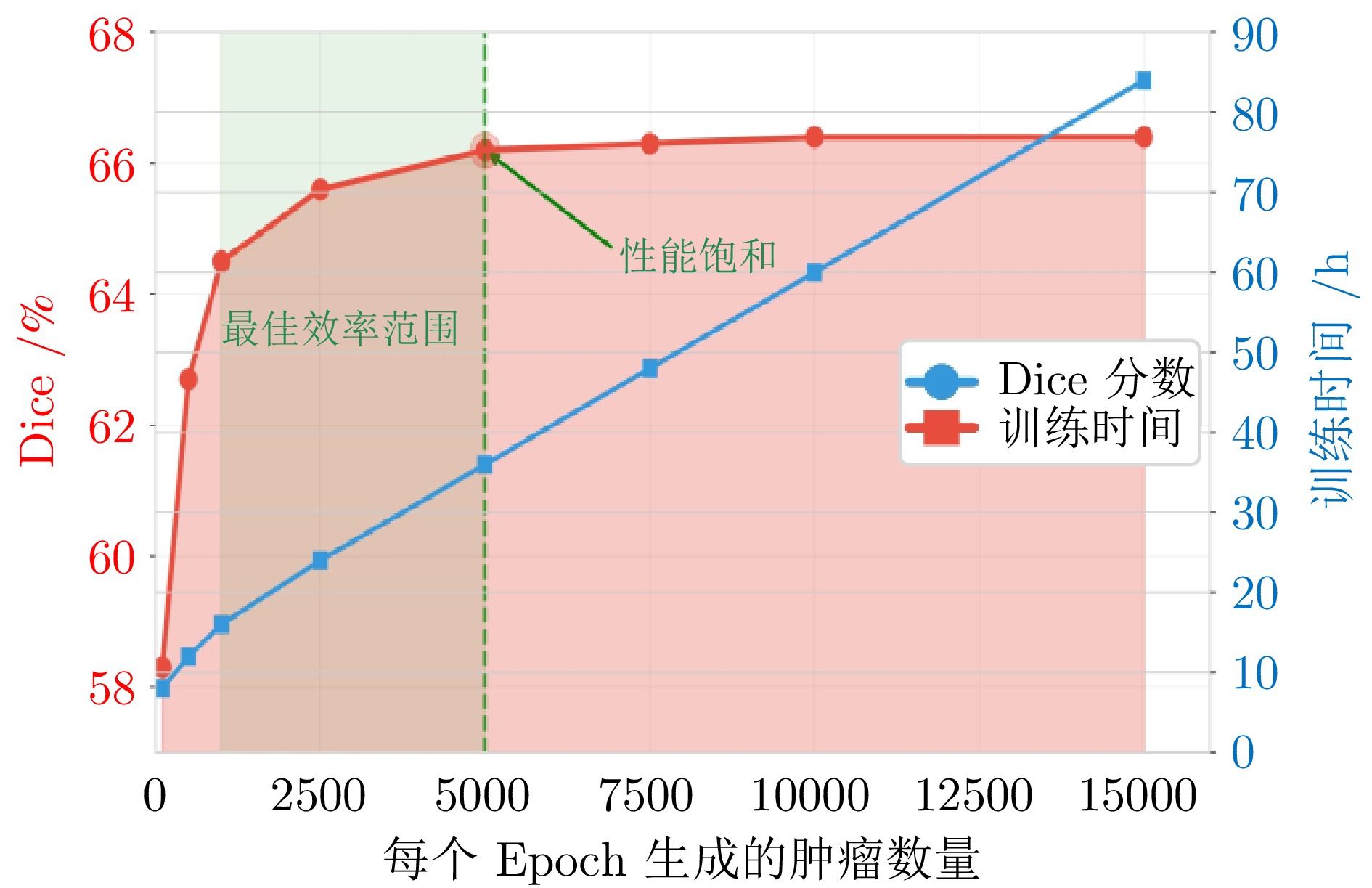
图 7 合成肿瘤数量对分割性能和训练时间的影响
Fig. 7 Impact of the number of synthesized tumors on segmentation performance and training time
表 1 LiTS17测试集上的分割性能比较
Table 1 Comparison of segmentation performance on the LiTS17 test set
方法 监督类型 真实数据 DSC (%) $ \uparrow $ VOE (%) $ \downarrow $ ASSD (mm) $ \downarrow $ 95HD (mm) $ \downarrow $ Recall (%) $ \uparrow $ Precision (%) $ \uparrow $ 全监督方法 nnU-Net 全监督 100% 71.2$ \pm $11.9 39.8$ \pm $15.2 1.28$ \pm $0.51 6.2$ \pm $3.0 77.8$ \pm $9.8 68.1$ \pm $13.2 TransUNet 全监督 100% 70.5$ \pm $12.4 40.6$ \pm $15.8 1.35$ \pm $0.56 6.7$ \pm $3.3 78.2$ \pm $10.2 66.9$ \pm $13.8 Swin-Unet 全监督 100% 69.8$ \pm $12.7 41.3$ \pm $16.1 1.41$ \pm $0.59 7.1$ \pm $3.5 76.5$ \pm $10.5 66.2$ \pm $14.1 MedSAM 基础模型 100% 68.7$ \pm $13.2 42.1$ \pm $16.4 1.48$ \pm $0.62 7.1$ \pm $3.6 75.4$ \pm $11.0 65.2$ \pm $14.5 SegVol 基础模型 100% 70.1$ \pm $12.5 40.8$ \pm $15.9 1.34$ \pm $0.58 6.5$ \pm $3.2 76.9$ \pm $10.4 67.4$ \pm $13.8 弱监督方法 ScribbleSup 涂鸦 100% 52.3$ \pm $16.8 58.9$ \pm $18.7 3.21$ \pm $1.32 15.8$ \pm $6.9 61.2$ \pm $15.3 47.8$ \pm $17.9 BoxSup 边界框 100% 48.7$ \pm $17.4 62.4$ \pm $19.2 3.89$ \pm $1.58 18.3$ \pm $7.6 57.9$ \pm $16.1 44.2$ \pm $18.5 MixMatch 半监督 10% 58.9$ \pm $15.1 51.2$ \pm $17.3 2.34$ \pm $0.98 11.2$ \pm $5.1 68.4$ \pm $12.7 53.6$ \pm $16.2 UniverSeg 弱监督 20% 64.3$ \pm $14.5 45.8$ \pm $17.2 1.72$ \pm $0.78 9.4$ \pm $4.8 70.2$ \pm $12.5 59.8$ \pm $15.6 合成数据方法 Copy-Paste 合成 0% 60.4$ \pm $15.2 49.7$ \pm $17.1 2.01$ \pm $0.89 9.1$ \pm $4.5 69.0$ \pm $12.3 53.3$ \pm $16.8 GAN-Synthesis 合成 0% 57.8$ \pm $15.9 52.1$ \pm $17.6 2.28$ \pm $0.96 10.4$ \pm $4.9 66.3$ \pm $13.1 51.9$ \pm $16.5 TumorGAN 合成 0% 61.2$ \pm $14.8 48.9$ \pm $16.8 1.92$ \pm $0.85 8.7$ \pm $4.2 70.1$ \pm $11.9 54.7$ \pm $16.1 MedSegDiff 合成 0% 61.8$ \pm $15.6 48.7$ \pm $17.1 1.95$ \pm $0.79 9.8$ \pm $4.0 68.5$ \pm $12.6 55.3$ \pm $15.7 DiffSeg 合成 0% 63.3$ \pm $14.2 47.2$ \pm $16.5 1.83$ \pm $0.77 9.1$ \pm $3.6 71.5$ \pm $11.8 57.1$ \pm $14.8 本文方法 AutoSynth-Liver (PixelCNN) 合成 0% 63.9$ \pm $13.8 46.3$ \pm $16.2 1.74$ \pm $0.71 8.3$ \pm $3.9 71.8$ \pm $11.2 58.6$ \pm $15.2 AutoSynth-Liver (VQ-VAE-T) 合成 0% 66.2$ \pm $12.9 44.1$ \pm $15.6 1.65$ \pm $0.65 7.4$ \pm $3.5 73.1$ \pm $10.8 61.9$ \pm $14.3 AutoSynth-Liver + 10% real 混合 10% 69.1$ \pm $12.5 42.3$ \pm $15.3 1.41$ \pm $0.58 6.9$ \pm $3.3 75.0$ \pm $10.4 64.2$ \pm $13.9  下载: 导出CSV
下载: 导出CSV
表 2 临床指标评估结果(%)
Table 2 Clinical metric evaluation results (%)
方法 病灶检测率 体积误差 最大径误差 全监督(nnU-Net) 93.1 $ 8.7 \pm 6.2 $ $ 3.2 \pm 2.1 $ AutoSynth-Liver (VQ-VAE-T) 89.2 $ 12.3 \pm 8.1 $ $ 4.1 \pm 2.7 $ AutoSynth-Liver + 10% real 91.8 $ 9.8 \pm 6.9 $ $ 3.5 \pm 2.3 $
下载: 导出CSV
表 3 不同自回归架构的性能比较
Table 3 Performance comparison of different autoregressive architectures
架构 DSC (%) FID 训练时间(h) random noise 52.4 — — VAE Only 58.7 68.3 12 PixelRNN 62.1 51.2 96 PixelCNN 63.9 48.5 24 VQ-VAE + MLP 64.5 45.8 18 VQ-VAE + Transformer 66.2 41.7 30
下载: 导出CSV
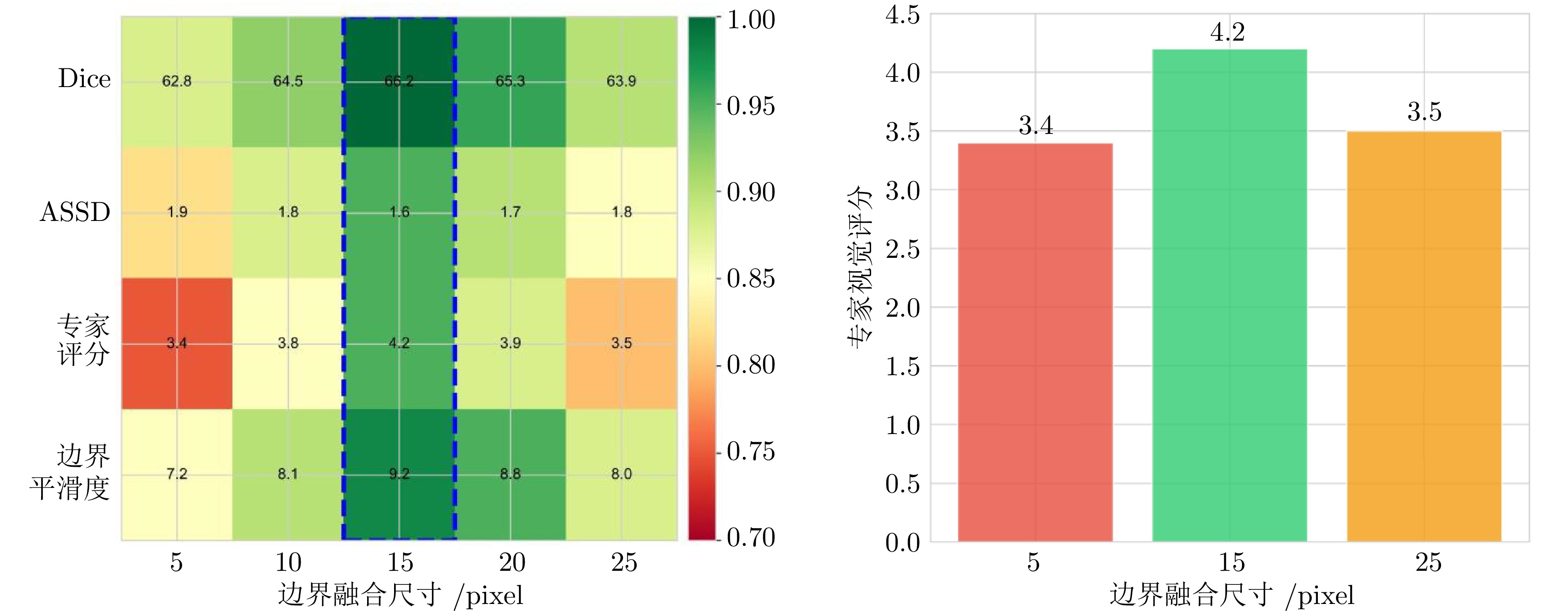
表 4 合成框架的消融实验
Table 4 Ablation study of the synthesis framework
设置 DSC (%) ASSD (mm) 专家视觉评分 完整模型 66.2 1.65 4.2 w/o属性预测 65.0 1.70 4.1 w/o位置约束 59.2 2.34 2.8 w/o外观和谐化 61.7 2.01 3.1 w/o边界细化 63.1 1.89 3.5 w/o质量控制 64.8 1.73 3.9
下载: 导出CSV
表 5 真实数据比例对分割性能的影响
Table 5 Effect of real data proportion on segmentation performance
真实数据比例 VOE (%) ASSD (mm) 95HD (mm) 0% 44.1 1.65 7.4 5% 43.0 1.52 7.1 10% 42.3 1.41 6.9 20% 41.8 1.37 6.7 50% 41.3 1.34 6.6 100% 41.3 1.33 6.6
下载: 导出CSV
表 6 3DIRCADb数据集上的zero-shot性能
Table 6 Zero-shot performance on the 3DIRCADb dataset
方法 DSC (%) ASSD (mm) 95HD (mm) nnU-Net 62.3 2.14 9.8 Copy-Paste 54.1 2.89 12.6 AutoSynth-Liver (VQ-VAE-T) 58.9 2.43 10.6 AutoSynth-Liver + 10% real 61.2 2.21 10.1
下载: 导出CSV
表 7 CHAOS数据集上的zero-shot性能
Table 7 Zero-shot performance on the CHAOS dataset
方法 微调方式 DSC (%) 95HD (mm) ASSD (mm) nnU-Net $ \checkmark$ 58.7 5.31 2.84 CycleGAN-Seg $ \checkmark$ 60.2 5.12 2.61 AutoSynth-Liver $ \checkmark$ 62.8 4.89 2.43 AutoSynth-Liver +
10% real$ \times $ 65.1 4.72 2.36
下载: 导出CSV
表 8 不同肿瘤类型的分割性能(DSC (%))
Table 8 Segmentation performance (DSC (%)) for different tumor types
方法 HCC 转移瘤 血管瘤 其他 全监督 72.3 69.8 74.5 68.1 AutoSynth-Liver 67.8 65.1 69.2 62.9 相对性能 93.8 93.3 92.9 92.4
下载: 导出CSV
表 9 计算效率比较
Table 9 Computational efficiency comparison
阶段 时间 GPU内存(GB) 备注 VAE训练 12.0 h 16 一次性 自回归模型训练 30.0 h 32 一次性 合成 1000 个肿瘤2.5 h 8 单个epoch 分割网络训练 20.0 h 24 总计 推理单个病例 8.0 s 4 部署阶段
下载: 导出CSV
-
[1] Zhou J, Sun H C, Wang Z, Cong W M, Zeng M S, Zhou W P, et al. Guidelines for the diagnosis and treatment of primary liver cancer (2022 edition). Liver Cancer, 2023, 12(5): 405−444 doi: 10.1159/000530495 [2] Yao S H, Feng Z C, Liang Q, Li H L, Jiang Y, Xie W Z, et al. Contrast-enhanced computed tomography radiomics models for predicting microvascular invasion in hepatocellular carcinoma based on multiset feature selection and feature fusion. EngMedicine, 2025, 2(4): Article No. 100104 doi: 10.1016/j.engmed.2025.100104 [3] 方超伟, 李雪, 李钟毓, 焦李成, 张鼎文. 基于双模型交互学习的半监督医学图像分割. 自动化学报, 2023, 49(4): 805−819 doi: 10.16383/j.aas.c210667Fang Chao-Wei, Li Xue, Li Zhong-Yu, Jiao Li-Cheng, Zhang Ding-Wen. Interactive dual-model learning for semi-supervised medical image segmentation. Acta Automatica Sinica, 2023, 49(4): 805−819 doi: 10.16383/j.aas.c210667 [4] Ronneberger O, Fischer P, Brox T. U-Net: Convolutional networks for biomedical image segmentation. In: Proceedings of the 18th International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI). Munich, Germany: Springer, 2015. 234−241 [5] Oktay O, Schlemper J, le Folgoc L, Lee M, Heinrich M, Misawa K, et al. Attention U-Net: Learning where to look for the pancreas. In: Proceedings of the Medical Imaging With Deep Learning. Amsterdam, Netherlands: OpenReview.net, 2018. [6] Zhou Z W, Rahman S M, Tajbakhsh N, Liang J M. UNet++: Redesigning skip connections to exploit multiscale features in image segmentation. IEEE Transactions on Medical Imaging, 2020, 39(6): 1856−1867 doi: 10.1109/TMI.2019.2959609 [7] Chen J N, Lu Y Y, Yu Q H, Luo X D, Adeli E, Wang Y, et al. TransUNet: Transformers make strong encoders for medical image segmentation. arXiv preprint arXiv: 2102.04306, 2021. [8] 廖苗, 杨睿新, 赵于前, 邸拴虎, 杨振. 基于CE TransNet的腹部CT图像多器官分割. 自动化学报, 2025, 51(6): 1371−1387 doi: 10.16383/j.aas.c240489Liao Miao, Yang Rui-Xin, Zhao Yu-Qian, Di Shuan-Hu, Yang Zhen. Multi-organ segmentation from abdominal CT images based on CE TransNet. Acta Automatica Sinica, 2025, 51(6): 1371−1387 doi: 10.16383/j.aas.c240489 [9] Lin D, Dai J F, Jia J Y, He K M, Sun J. ScribbleSup: Scribble-supervised convolutional networks for semantic segmentation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, USA: IEEE, 2016. 3159−3167 [10] Kervadec H, Dolz J, Wang S S, Granger E, Ayed I B. Bounding boxes for weakly supervised segmentation: Global constraints get close to full supervision. In: Proceedings of the Medical Imaging With Deep Learning (MIDL). Montreal, Canada: OpenReview.net, 2020. 365−381 [11] Zhou B L, Khosla A, Lapedriza A, Oliva A, Torralba A. Learning deep features for discriminative localization. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, USA: IEEE, 2016. 2921−2929 [12] Lee D H. Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks. In: Proceedings of the Challenges in Representation Learning (WREPL). Atlanta, USA, 2013. Article No. 89 [13] Tarvainen A, Valpola H. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. In: Proceedings of the 31st International Conference on Neural Information Processing Systems. Long Beach, USA: Curran Associates Inc., 2017. 1195−1204 [14] Goodfellow I, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, Ozair S, et al. Generative adversarial nets. In: Proceedings of the 28th International Conference on Neural Information Processing Systems. Montreal, Canada: MIT Press, 2014. 2672−2680 [15] Yi X, Walia E, Babyn P. Generative adversarial network in medical imaging: A review. Medical Image Analysis, 2019, 58: Article No. 101552 doi: 10.1016/j.media.2019.101552 [16] Zhang L, Wang X S, Yang D, Sanford T, Harmon S, Turkbey B, et al. Generalizing deep learning for medical image segmentation to unseen domains via deep stacked transformation. IEEE Transactions on Medical Imaging, 2020, 39(7): 2531−2540 doi: 10.1109/TMI.2020.2973595 [17] van den Oord A, Kalchbrenner N, Vinyals O, Espeholt L, Graves A, Kavukcuoglu K. Conditional image generation with PixelCNN decoders. In: Proceedings of the 30th International Conference on Neural Information Processing Systems. Barcelona, Spain: Curran Associates Inc., 2016. 4797−4805 [18] van den Oord A, Vinyals O, Kavukcuoglu K. Neural discrete representation learning. In: Proceedings of the 31st International Conference on Neural Information Processing Systems. Long Beach, USA: Curran Associates Inc., 2017. 6309−6318 [19] Heimann T, van Ginneken B, Styner M A, Arzhaeva Y, Aurich V, Bauer C, et al. Comparison and evaluation of methods for liver segmentation from CT datasets. IEEE Transactions on Medical Imaging, 2009, 28(8): 1251−1265 doi: 10.1109/TMI.2009.2013851 [20] Li C M, Xu C Y, Gui C F, Fox M D. Distance regularized level set evolution and its application to image segmentation. IEEE Transactions on Image Processing, 2010, 19(12): 3243−3254 doi: 10.1109/TIP.2010.2069690 [21] Çiçek Ö, Abdulkadir A, Lienkamp S S, Brox T, Ronneberger O. 3D U-Net: Learning dense volumetric segmentation from sparse annotation. In: Proceedings of the 19th International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI 2016). Athens, Greece: Springer, 2016. 424−432 [22] Milletari F, Navab N, Ahmadi S A. V-Net: Fully convolutional neural networks for volumetric medical image segmentation. In: Proceedings of the 4th International Conference on 3D Vision (3DV). Stanford, USA: IEEE, 2016. 565−571 [23] Roy A G, Navab N, Wachinger C. Concurrent spatial and channel 'squeeze & excitation' in fully convolutional networks. In: Proceedings of the 21st International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI 2018). Granada, Spain: Springer, 2018. 421−429 [24] Isensee F, Jaeger P F, Kohl S A A, Petersen J, Maier-Hein K H. nnU-Net: A self-configuring method for deep learning-based biomedical image segmentation. Nature Methods, 2021, 18(2): 203−211 doi: 10.1038/s41592-020-01008-z [25] Cao H, Wang Y Y, Chen J, Jiang D S, Zhang X P, Tian Q, et al. Swin-Unet: Unet-like pure Transformer for medical image segmentation. In: Proceedings of the Computer Vision (ECCV 2022). Tel Aviv, Israel: Springer, 2022. 205−218 [26] Fang X, Yan P K. Multi-organ segmentation over partially labeled datasets with multi-scale feature abstraction. IEEE Transactions on Medical Imaging, 2020, 39(11): 3619−3629 doi: 10.1109/TMI.2020.3001036 [27] Tang M, Djelouah A, Perazzi F, Boykov Y, Schroers C. Normalized cut loss for weakly-supervised CNN segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 1818−1827 [28] Wang G T, Zuluaga M A, Li W Q, Pratt R, Patel P A, Aertsen M, et al. DeepIGeoS: A deep interactive geodesic framework for medical image segmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019, 41(7): 1559−1572 doi: 10.1109/TPAMI.2018.2840695 [29] Qu H, Wu P X, Huang Q Y, Yi J R, Yan Z N, Li K, et al. Weakly supervised deep nuclei segmentation using partial points annotation in histopathology images. IEEE Transactions on Medical Imaging, 2020, 39(11): 3655−3666 doi: 10.1109/TMI.2020.3002244 [30] Selvaraju R R, Cogswell M, Das A, Vedantam R, Parikh D, Batra D. Grad-CAM: Visual explanations from deep networks via gradient-based localization. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV). Venice, Italy: IEEE, 2017. 618−626 [31] Zhu W T, Lou Q, Vang Y S, Xie X H. Deep multi-instance networks with sparse label assignment for whole mammogram classification. In: Proceedings of the 20th International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI 2017). Quebec City, Canada: Springer, 2017. 603−611 [32] Ouyang X, Xue Z, Zhan Y Q, Zhou X S, Wang Q F, Zhou Y, et al. Weakly supervised segmentation framework with uncertainty: A study on pneumothorax segmentation in chest X-ray. In: Proceedings of the 22nd International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI 2019). Shenzhen, China: Springer, 2019. 613−621 [33] Haghighi F, Taher M R H, Zhou Z W, Gotway M B, Liang J M. Transferable visual words: Exploiting the semantics of anatomical patterns for self-supervised learning. IEEE Transactions on Medical Imaging, 2021, 40(10): 2857−2868 doi: 10.1109/TMI.2021.3060634 [34] Zhao Y, Lu K, Xue J, Wang S H, Lu J. Semi-supervised medical image segmentation with voxel stability and reliability constraints. IEEE Journal of Biomedical and Health Informatics, 2023, 27(8): 3912−3923 doi: 10.1109/JBHI.2023.3273609 [35] Simard P Y, Steinkraus D, Platt J C. Best practices for convolutional neural networks applied to visual document analysis. In: Proceedings of the 7th International Conference on Document Analysis and Recognition. Edinburgh, UK: IEEE, 2003. 958−963 [36] Zhao A, Balakrishnan G, Durand F, Guttag J V, Dalca A V. Data augmentation using learned transformations for one-shot medical image segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, USA: IEEE, 2019. 8535−8545 [37] Han C, Kitamura Y, Kudo A, Ichinose A, Rundo L, Furukawa Y, et al. Synthesizing diverse lung nodules wherever massively: 3D multi-conditional GAN-based CT image augmentation for object detection. In: Proceedings of the International Conference on 3D Vision (3DV). Quebec City, Canada: IEEE, 2019. 729−737 [38] Isola P, Zhu J Y, Zhou T H, Efros A A. Image-to-image translation with conditional adversarial networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, USA: IEEE, 2017. 5967−5976 [39] Shin H C, Tenenholtz N A, Rogers J K, Schwarz C G, Senjem M L, Gunter J L, et al. Medical image synthesis for data augmentation and anonymization using generative adversarial networks. In: Proceedings of the 3rd International Workshop on Simulation and Synthesis in Medical Imaging. Granada, Spain: Springer, 2018. 1−11 [40] Nie D, Trullo R, Petitjean C, Ruan S, Shen D G. Medical image synthesis with context-aware generative adversarial networks. In: Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI 2017). Quebec, Canada: Springer, 2017. 417−425 [41] Zhu J Y, Park T, Isola P, Efros A A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV). Venice, Italy: IEEE, 2017. 2242−2251 [42] Zhang Z Z, Yang L, Zheng Y F. Translating and segmenting multimodal medical volumes with cycle-and shape-consistency generative adversarial network. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 9242−9251 [43] Frid-Adar M, Diamant I, Klang E, Amitai M, Goldberger J, Greenspan H. GAN-based synthetic medical image augmentation for increased CNN performance in liver lesion classification. Neurocomputing, 2018, 321: 321−331 doi: 10.1016/j.neucom.2018.09.013 [44] Karpakam S, Kumareshan N. A multi-modality framework for precise brain tumor detection and multi-class classification using hybrid GAN approach. Biomedical Signal Processing and Control, 2025, 104: Article No. 107559 doi: 10.1016/j.bspc.2025.107559 [45] Wolleb J, Bieder F, Sandkühler R, Cattin P C. Diffusion models for medical anomaly detection. In: Proceedings of the 25th International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI 2022). Singapore: Springer, 2022. 35−45 [46] Karazija L, Laina I, Vedaldi A, Rupprecht C. Diffusion models for open-vocabulary segmentation. In: Proceedings of the 18th European Conference on Computer Vision (ECCV 2024). Milan, Italy: Springer, 2024. 299−317 [47] Butoi V I, Ortiz J J G, Ma T Y, Sabuncu M R, Guttag J, Dalca A V. UniverSeg: Universal medical image segmentation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). Paris, France: IEEE, 2023. 21381−21394 [48] Ma J, He Y T, Li F F, Han L, You C Y, Wang B. Segment anything in medical images. Nature Communications, 2024, 15(1): Article No. 654 doi: 10.1038/s41467-024-44824-z [49] Du Y X, Bai F, Huang T J, Zhao B. SegVol: Universal and interactive volumetric medical image segmentation. In: Proceedings of the 38th International Conference on Neural Information Processing Systems. Vancouver, Canada: Curran Associates Inc., 2024. Article No. 3516 [50] Salimans T, Karpathy A, Chen X, Kingma D P. PixelCNN++: Improving the PixelCNN with discretized logistic mixture likelihood and other modifications. In: Proceedings of the 5th International Conference on Learning Representations. Toulon, France: Curran Associates Inc., 2017. [51] Razavi A, van den Oord A, Vinyals O. Generating diverse high-fidelity images with VQ-VAE-2. In: Proceedings of the 33rd International Conference on Neural Information Processing Systems. Vancouver, Canada: Curran Associates Inc., 2019. Article No. 1331 [52] Esser P, Rombach R, Ommer B. Taming Transformers for high-resolution image synthesis. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Nashville, USA: IEEE, 2021. 12868−12878 [53] Kohl S A A, Romera-Paredes B, Meyer C, de Fauw J, Ledsam J R, Maier-Hein K H, et al. A probabilistic U-Net for segmentation of ambiguous images. In: Proceedings of the 32nd International Conference on Neural Information Processing Systems. Montréal, Canada: Curran Associates Inc., 2018. 6965−6975 [54] Kohl S A A, Romera-Paredes B, Maier-Hein K H, Rezende D J, Eslami S M A, Kohli P, et al. A hierarchical probabilistic U-Net for modeling multi-scale ambiguities. arXiv preprint arXiv: 1905.13077, 2019. [55] Kingma D P, Welling M. Auto-encoding variational Bayes. In: Proceedings of the International Conference on Learning Representations. Banff, Canada: OpenReview.net, 2014. [56] Johnson J, Alahi A, Li F F. Perceptual losses for real-time style transfer and super-resolution. In: Proceedings of the 14th European Conference on Computer Vision (ECCV 2016). Amsterdam, Netherlands: Springer, 2016. 694−711 [57] Higgins I, Matthey L, Pal A, Burgess C, Glorot X, Botvinick M, et al. beta-VAE: Learning basic visual concepts with a constrained variational framework. In: Proceedings of the 5th International Conference on Learning Representations (ICLR 2017). Toulon, France: OpenReview.net, 2017. Article No. 122 [58] Perez E, Strub F, de Vries H, Dumoulin V, Courville A. FiLM: Visual reasoning with a general conditioning layer. In: Proceedings of the 32nd AAAI Conference on Artificial Intelligence. New Orleans, USA: AAAI Press, 2018. 3942−3951 [59] Karimi D, Salcudean S E. Reducing the Hausdorff distance in medical image segmentation with convolutional neural networks. IEEE Transactions on Medical Imaging, 2020, 39(2): 499−513 doi: 10.1109/TMI.2019.2930068 [60] Bilic P, Christ P, Li H B, Vorontsov E, Ben-Cohen A, Kaissis G, et al. The liver tumor segmentation benchmark (LiTS). Medical Image Analysis, 2023, 84: Article No. 102680 doi: 10.1016/j.media.2022.102680 [61] Soler L, Hostettler A, Agnus V, Charnoz A, Fasquel J B, Moreau J, et al. 3D Image Reconstruction for Comparison of Algorithm Database: A Patient-Specific Anatomical and Medical Image Database. IRCAD, Strasbourg, France, 2010. [62] Kavur A E, Gezer N S, Barış M, Aslan S, Conze P H, Groza V, et al. CHAOS challenge-combined (CT-MR) healthy abdominal organ segmentation. Medical Image Analysis, 2021, 69: Article No. 101950 doi: 10.1016/j.media.2020.101950 [63] Dai J F, He K M, Sun J. BoxSup: Exploiting bounding boxes to supervise convolutional networks for semantic segmentation. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV). Santiago, Chile: IEEE, 2015. 1635−1643 [64] Berthelot D, Carlini N, Goodfellow I, Oliver A, Papernot N, Raffel C. MixMatch: A holistic approach to semi-supervised learning. In: Proceedings of the 33rd International Conference on Neural Information Processing Systems. Vancouver, Canada: Curran Associates Inc., 2019. Article No. 454 [65] Zhang H N, Li H H, Lin J R, Zhang Y J, Fan J H, Liu H, et al. Seg-CycleGAN: SAR-to-optical image translation guided by a downstream task. IEEE Geoscience and Remote Sensing Letters, 2025, 22: Article No. 4005205 doi: 10.1109/lgrs.2025.3538868/mm1 [66] Wu J D, Fu R, Fang H H, Zhang Y, Yang Y H, Xiong H Y, et al. MedSegDiff: Medical image segmentation with diffusion probabilistic model. In: Proceedings of the Medical Imaging with Deep Learning. Nashville, USA: PMLR, 2023. 1623−1639 [67] Shuai Z H, Chen Y N, Mao S Q, Zho Y H, Zhang X H. DiffSeg: A segmentation model for skin lesions based on diffusion difference. arXiv preprint arXiv: 2404.16474, 2024. -

 下载:
下载:

计量
- 文章访问数: 157
- HTML全文浏览量: 93
- 被引次数: 0
