

Divide-and-conquer Test-time Adaptation With Retrieval-augmentation for Text-attributed Graph Foundation Model
-
摘要: 文本属性图基础模型(TAG-FM)旨在通过在大规模图数据集上预训练, 实现稳健的跨域泛化能力. 尽管TAG-FM已在多项下游任务中展现出良好的性能, 但是通过深入分析发现, 其在泛化能力方面仍存在关键弱点: 域适应阈值效应, 即, 当预训练域与测试域之间的分布偏移超过某一临界阈值时, 模型性能将出现显著退化. 由于基础模型复杂度高且测试数据稀缺, 引入测试时自适应方法成为缓解该问题的可行方案. 然而现有测试时自适应方法在实例层和域层均存在局限, 严重制约着TAG-FM对分布外数据的适应性能. 针对此问题, 提出一种面向TAG-FM的“检索−分治”测试时自适应方法, 该方法通过检索增强的特征共形融合模块生成融合图结构和节点文本语义的统一特征, 并引入一种分而治之的测试时自适应策略, 通过渐进式自适应过程学习泛化性语义. 在7个基准文本属性图数据集和12个严重域偏移文本属性图数据集上的实验结果表明, 本文方法能够显著增强TAG-FM的跨域泛化能力.Abstract: Text-attributed graph foundation model (TAG-FM) is designed to attain robust cross-domain generalization capability through pretraining on large-scale graph datasets. Although TAG-FM has demonstrated promising performance on various downstream tasks, our in-depth analysis reveals a critical limitation in its generalization capability: The domain adaptation threshold effect, i.e., model performance undergoes catastrophic degradation when distributional shifts between pretraining and testing domains surpass critical thresholds. Due to the excessive foundation model complexity and scarcity of testing data, a feasible solution to mitigate this issue is to introduce test-time adaptation approaches for TAG-FM. Nevertheless, existing test-time adaptation approaches exhibit substantial limitations at both the instance and domain levels, severely constraining the ability of TAG-FM to adapt to out-of-distribution data. To address this issue, we innovatively propose the divide-and-conquer test-time adaptation with retrieval-augmentation for TAG-FM. Specifically, a retrieval-augmented feature conformal integration module is introduced to construct consolidated node features by integrating graph structures with node textual semantics. Furthermore, a divide-and-conquer test-time adaptation strategy is developed to progressively capture generalizable semantics through an iterative adaptation process. Empirically, we verify that the proposed method achieves the state-of-the-art performance on 7 benchmark text-attributed graph datasets and 12 constructed text-attributed graph datasets exhibiting severe domain shifts, which confirms that our method effectively enhances the cross-domain generalization capability of TAG-FM.1)
1 1本文将TAG-FM的预训练数据视为预训练域, 将Cora、CiteSeer等测试数据集视为测试域, 一个测试数据集可视为一个测试域. 值得注意的是, TAG-FM的预训练数据仅用于探索实验, 所提方法的实际实现并未使用任何TAG-FM预训练数据.2)2 2对任意节点$ v_n $, 均存在对应的统一特征$ z_n $, 故可反向利用$ z_n $检索节点$ v_n $. -
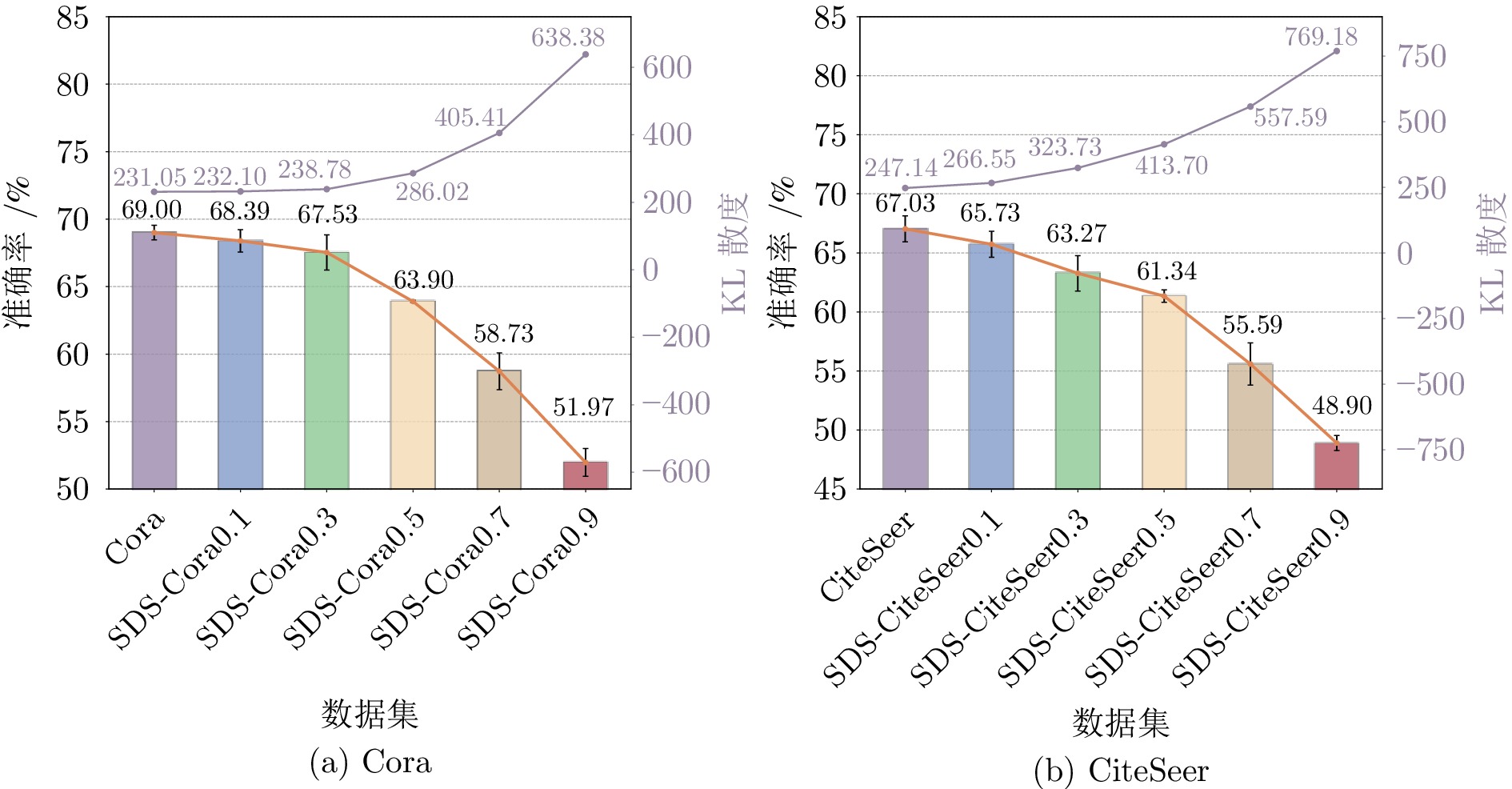
图 1 不同域偏移强度下TAG-FM性能及预训练域与测试域之间的KL散度
Fig. 1 TAG-FM performance and the KL divergence between the pretraining and testing domains under varying degrees of domain shifts
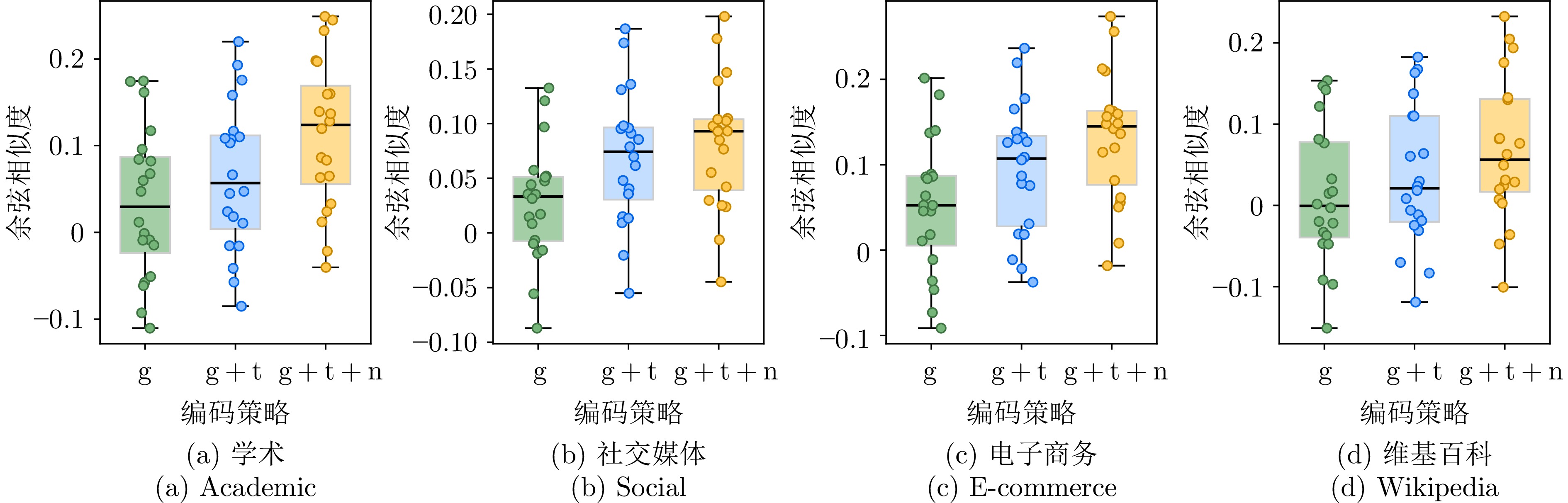
图 2 代表性实例对在不同编码策略下的语义相似度比较
Fig. 2 Comparison of semantic similarity for representative instance pairs across different encoding strategies
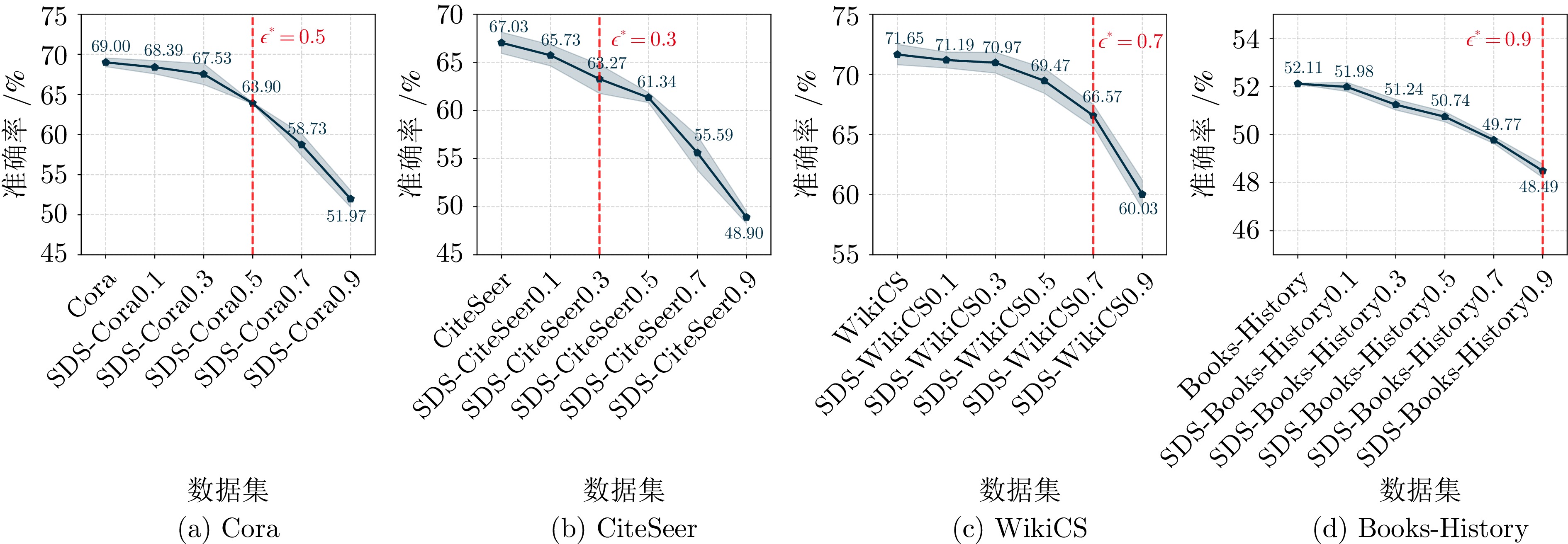
图 3 GraphCLIP在不同域偏移设置下的性能表现
Fig. 3 Performance of GraphCLIP under different domain shift settings
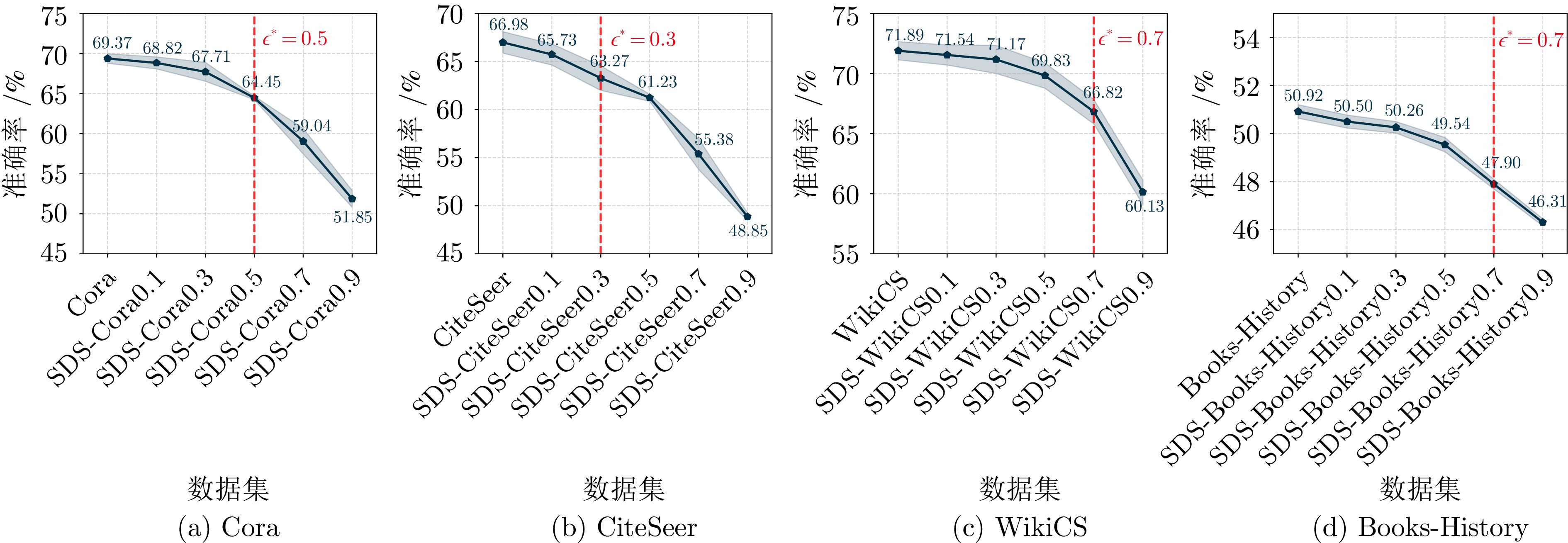
图 4 GraphCLIP+GTrans在不同域偏移下的性能表现
Fig. 4 Performance of GraphCLIP+GTrans under different domain shift settings
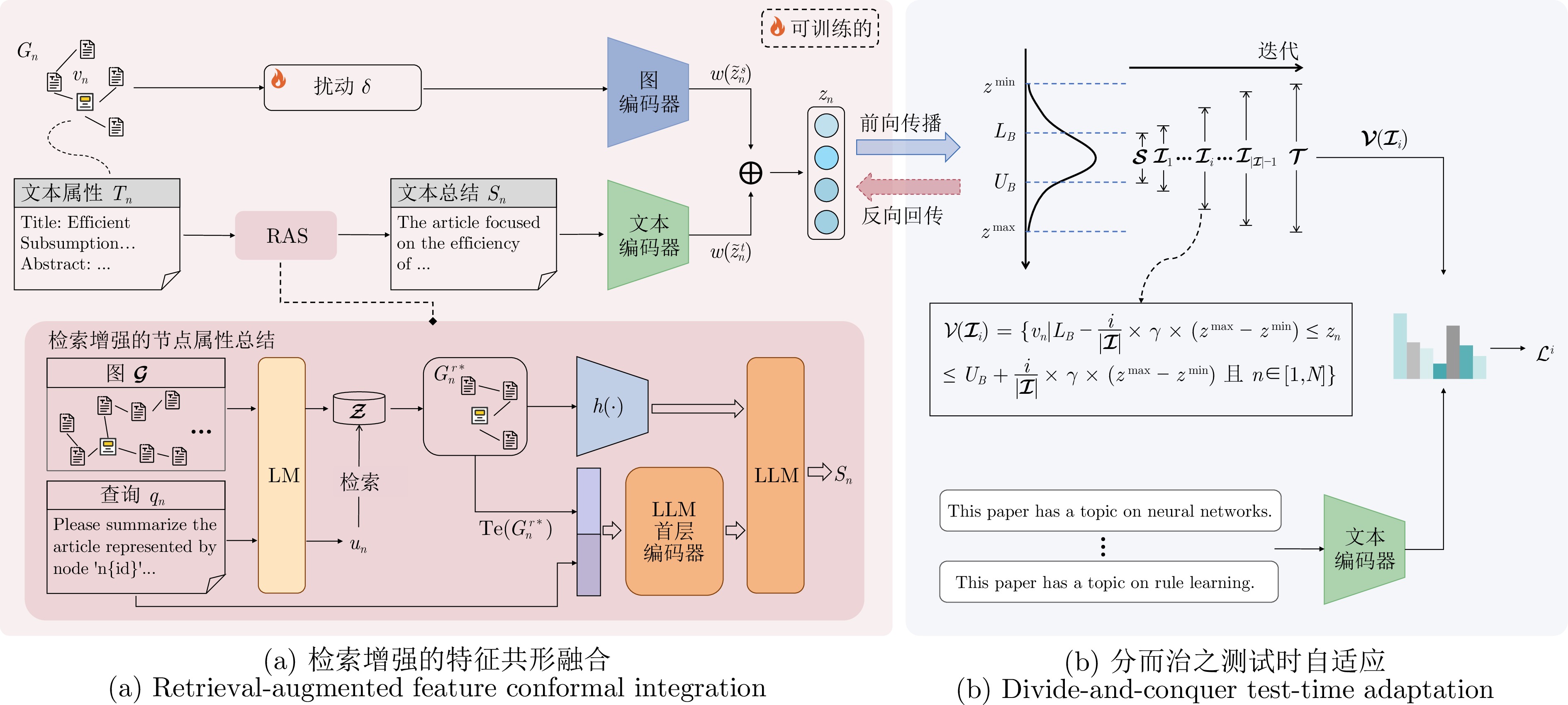
图 5 DORA的整体框架, 其中扰动$ \delta$随适应过程更新
Fig. 5 The overall framework of DORA, where the perturbation $ \delta$ is progressively updated during the adaptation process
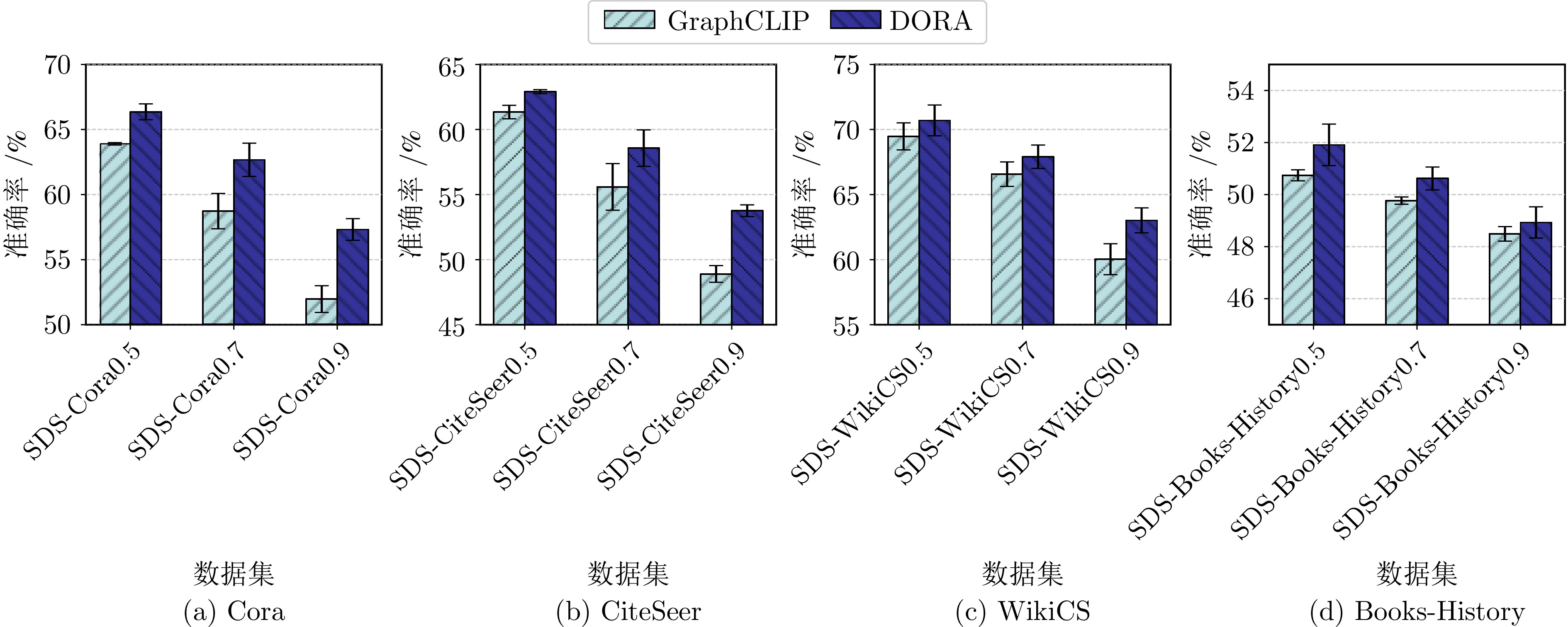
图 6 严重域偏移数据集上的节点分类任务准确率
Fig. 6 Accuracy for the node classification task on severe domain shift datasets
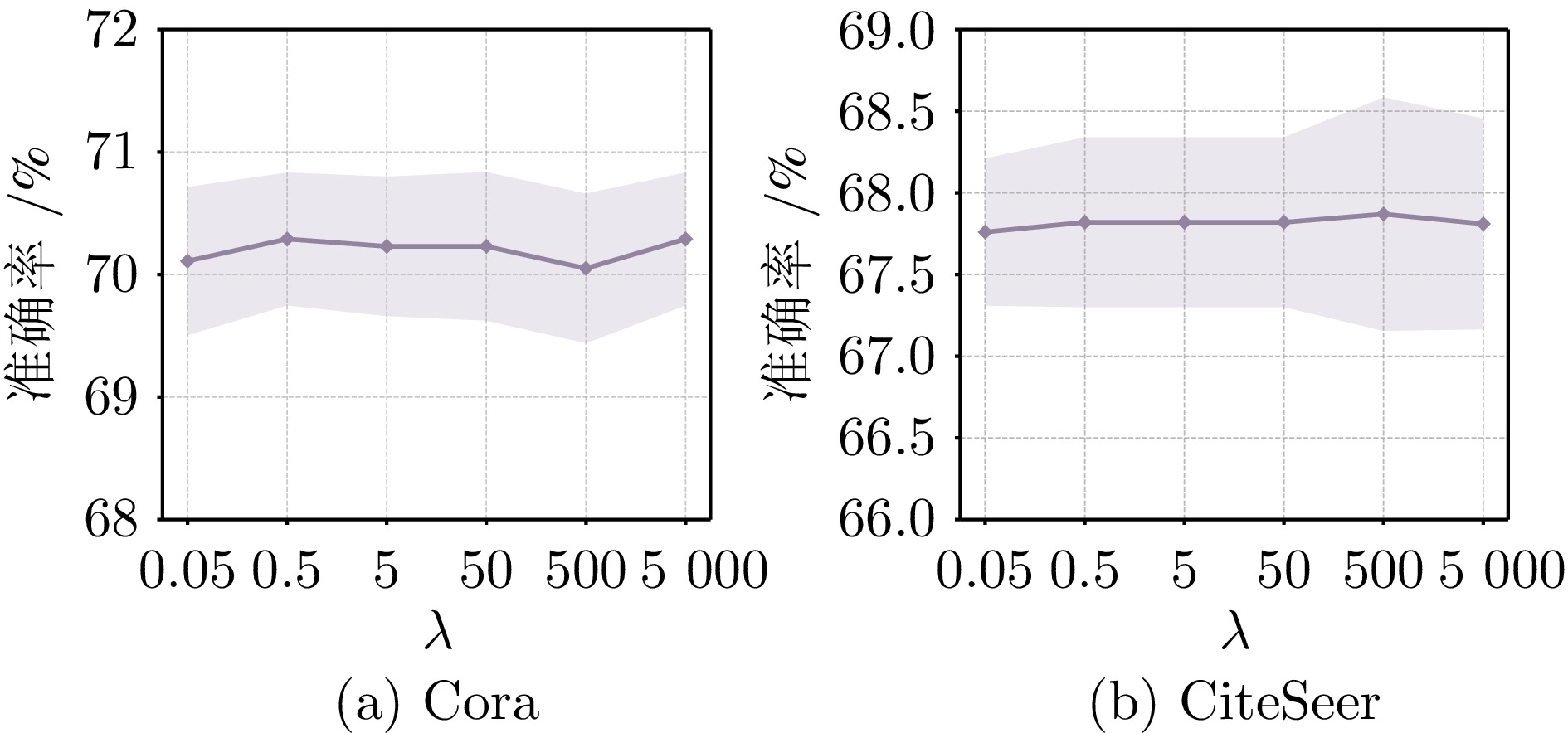
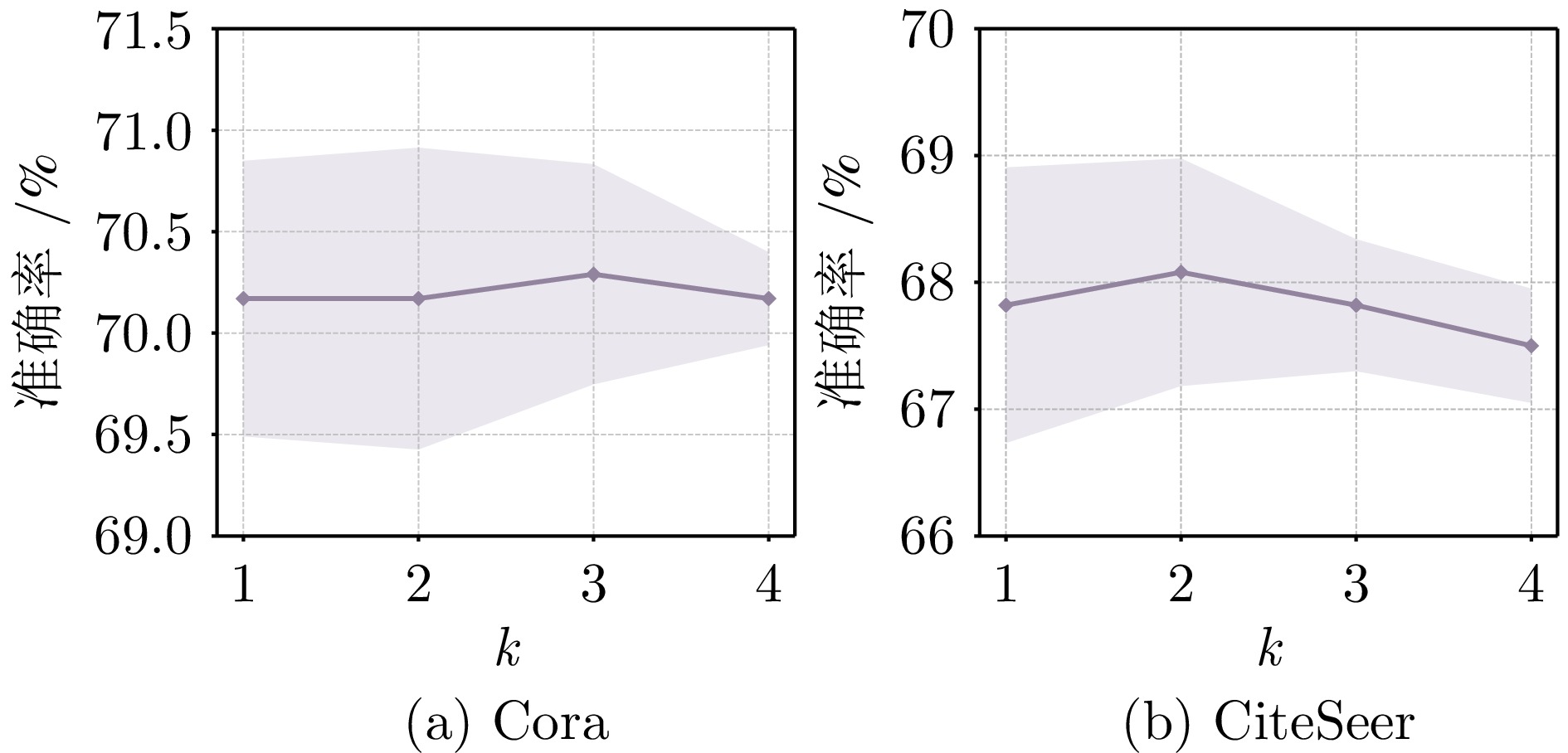
图 8 超参数$ \lambda$对模型性能的影响
Fig. 8 The impact of hyperparameter $ \lambda$ on model performance
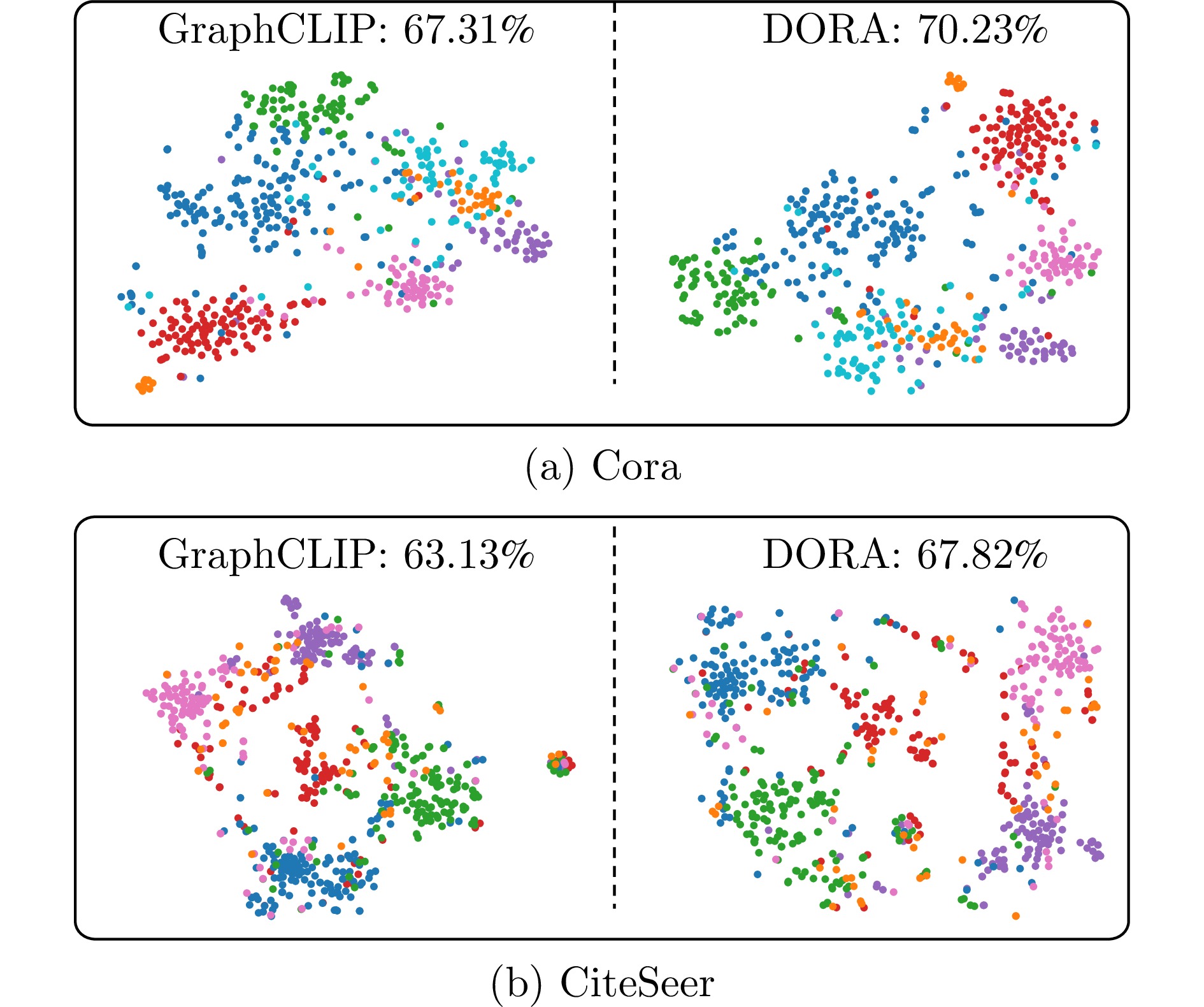
图 9 Cora和CiteSeer数据集上GraphCLIP与DORA所得特征的t-SNE可视化
Fig. 9 t-SNE visualization of features produced by GraphCLIP and DORA on Cora and CiteSeer datasets
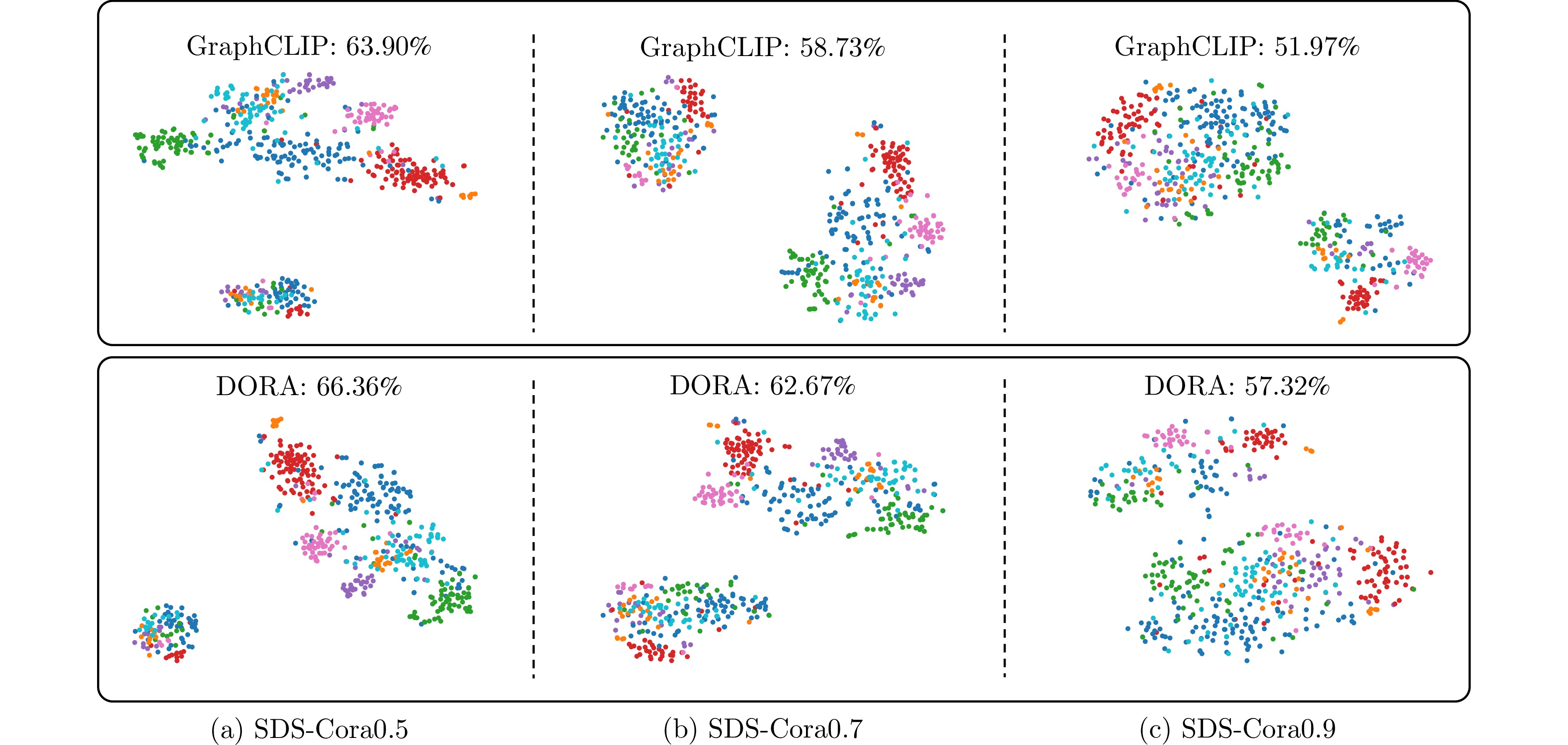
图 10 SDS-Cora系列严重域偏移数据集上GraphCLIP与DORA所得特征的t-SNE可视化
Fig. 10 t-SNE visualization of features produced by GraphCLIP and DORA on SDS-Cora series datasets with severe domain shifts
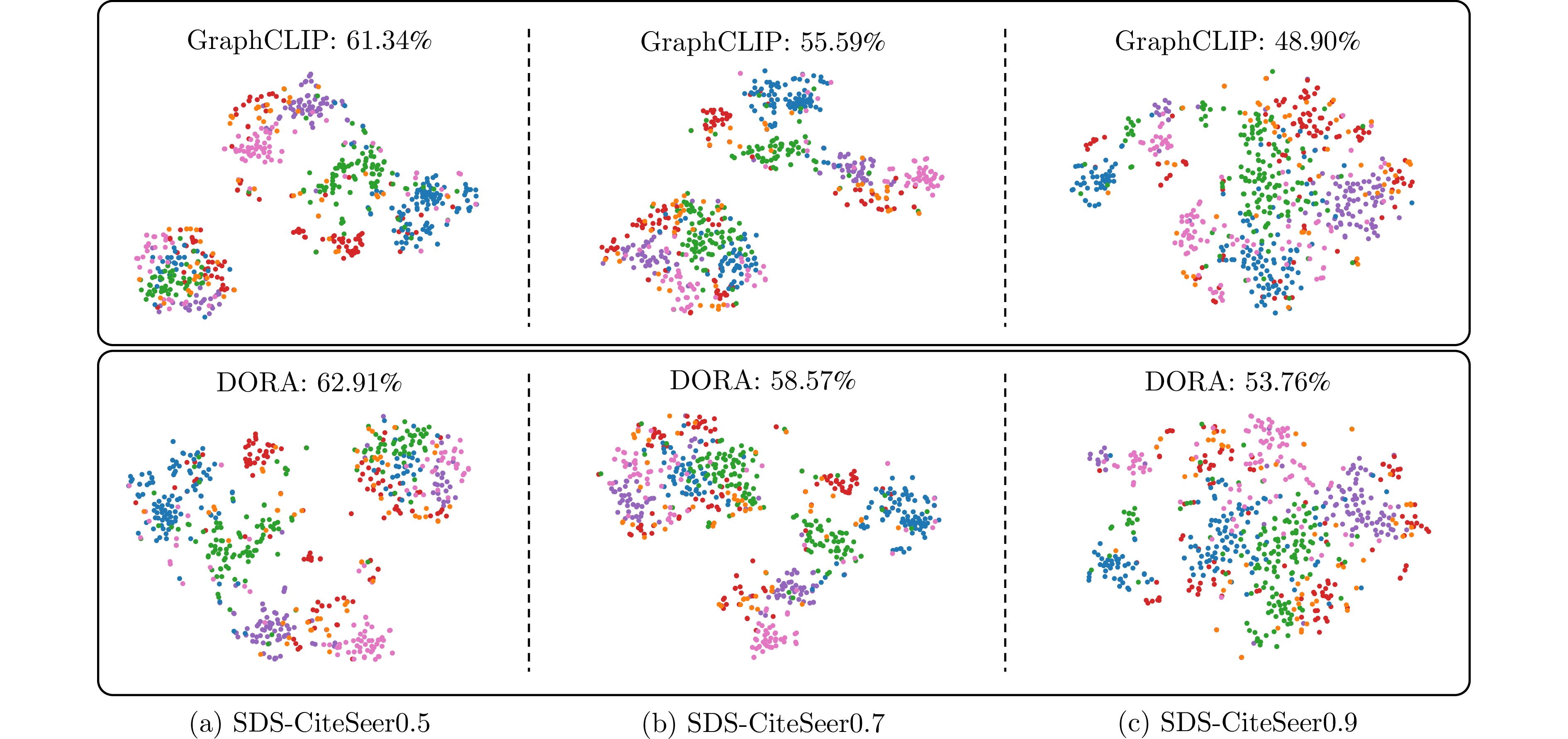
图 11 SDS-CiteSeer系列严重域偏移数据集上GraphCLIP与DORA所得特征的t-SNE可视化
Fig. 11 t-SNE visualization of features produced by GraphCLIP and DORA on SDS-CiteSeer series datasets with severe domain shifts
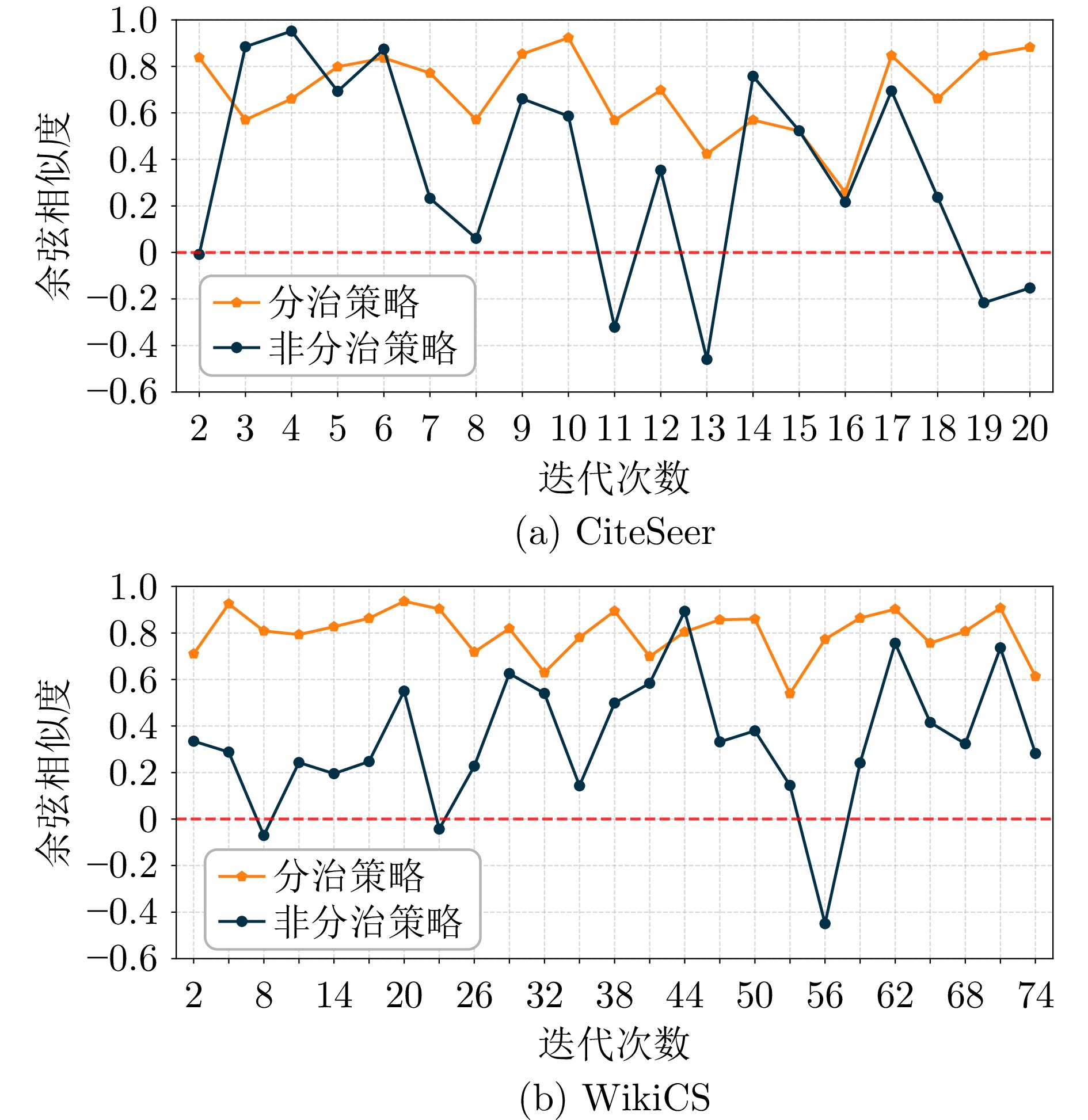
图 12 测试时自适应过程中相邻迭代步之间梯度的余弦相似度
Fig. 12 Cosine similarity of gradients between consecutive iterations during test-time adaptation
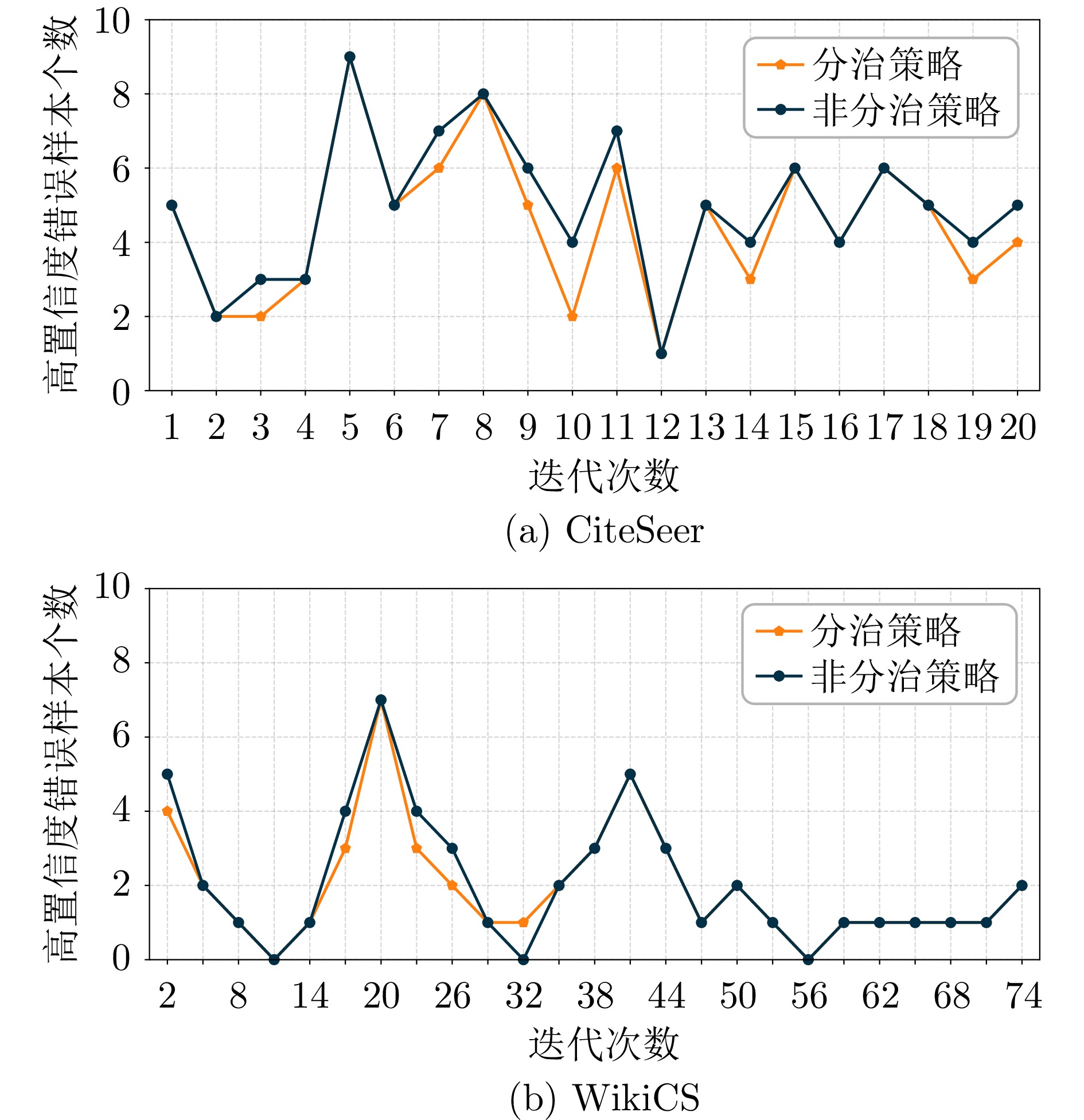
图 13 测试时自适应过程中高确定性错误样本数量
Fig. 13 Number of misclassified samples with high certainty during test-time adaptation
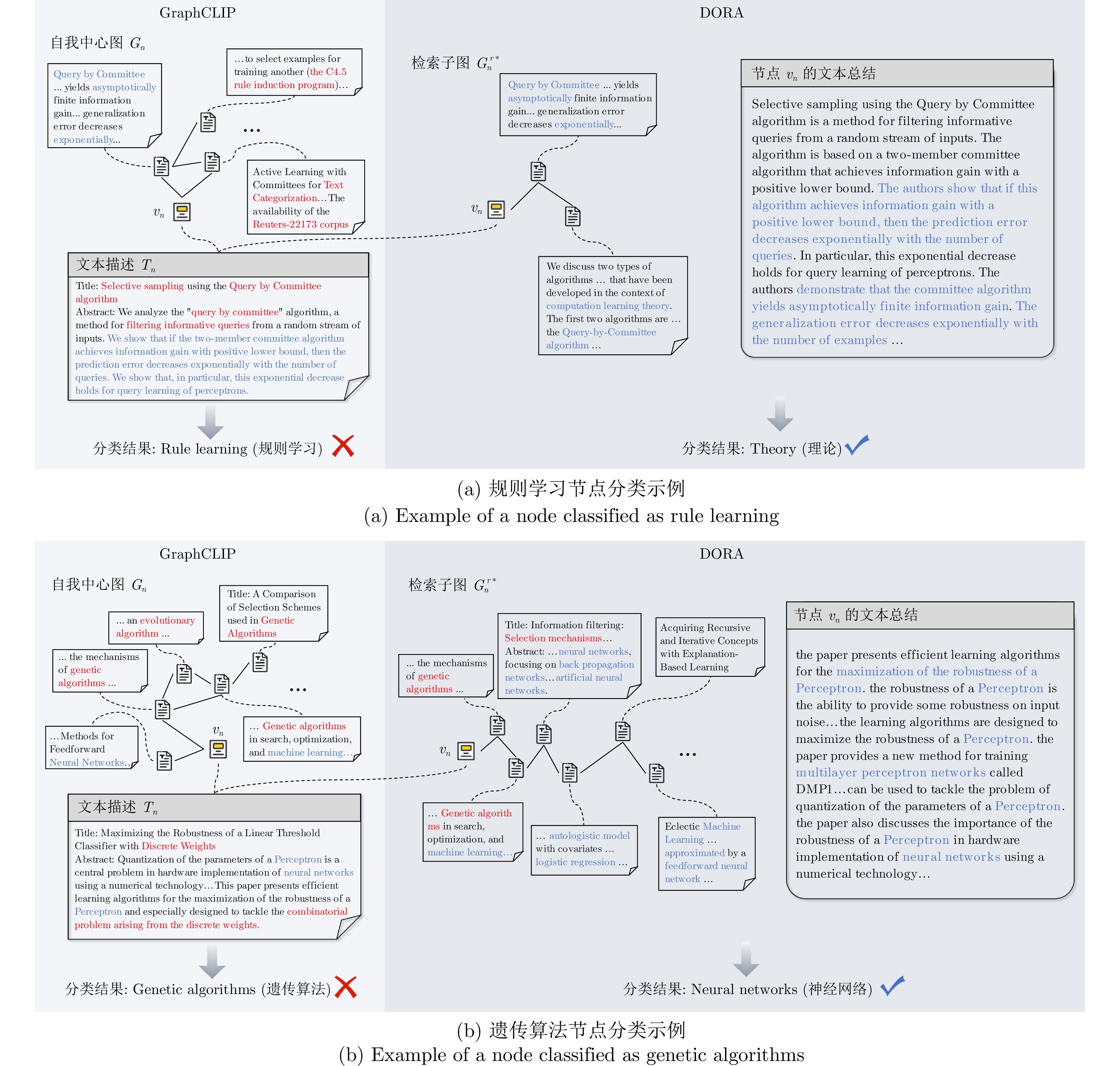
图 14 GraphCLIP与DORA在Cora数据集中两个典型节点上的分类结果对比分析
Fig. 14 Comparative analysis of classification results of GraphCLIP and DORA on two representative nodes in the Cora dataset
表 1 文本属性图数据集统计
Table 1 Statistics of text-attributed graph datasets
数据集 节点数 边数 领域 类别数 Cora 2708 5429 学术 7 CiteSeer 3186 4277 学术 6 Ele-Photo 48362 500928 电子商务 12 Ele-Computers 87229 721081 电子商务 10 Books-History 41551 358574 电子商务 12 WikiCS 11701 215863 维基百科 10 Instagram 11339 144010 社交媒体 2  下载: 导出CSV
下载: 导出CSV
表 2 类别相关提示模板汇总
Table 2 Summary of the class-relevant prompt templates
数据集 提示模板 Cora this paper has a topic on {class} {class_desc} CiteSeer good paper of {class} {class_desc} Ele-Photo this product belongs to {class} {class_desc} Ele-Computers is {class} category {class_desc} Books-History this book belongs to {class} {class_desc} WikiCS it belongs to {class} research area {class_desc} Instagram {class} {class_desc}
下载: 导出CSV
表 3 构建查询$ q_n$的提示模板汇总
Table 3 Summary of prompt templates used to construct the query $ q_n$
数据集 构建查询$q_n$的提示模板 Cora The textual description of the citation network centered on node ‘n{id}’ is shown above. Each node in the network represents a scholarly article, and each edge signifies a citation relationship between articles. The textual description of node ‘n{id}’ is: ‘{desc}’. Please summarize the core content of the article represented by node ‘n{id}’ using the information provided above in 200 words: CiteSeer The textual description of the citation network centered on node ‘n{id}’ is shown above. Each node in the network represents a scholarly article, and each edge signifies a citation relationship between articles. The textual description of node ‘n{id}’ is: ‘{desc}’. Please summarize the core content of the article represented by node ‘n{id}’ using the information provided above in 200 words: Ele-Photo The textual description of the Amazon Electronics graph centered on node ‘n{id}’ is shown above. Each node in the graph represents a electronic product, and each edge signifies frequent co-purchases or co-views. The user review with the most votes of node ‘n{id}’ is: ‘{desc}’. Please summarize the information provided above and re-describe the electronic product represented by node ‘n{id}’ based on the results of the summary in 200 words: Ele-Computers The textual description of the Amazon Electronics graph centered on node ‘n{id}’ is shown above. Each node in the graph represents a electronic product, and each edge signifies frequent co-purchases or co-views. The user review with the most votes of node ‘n{id}’ is: ‘{desc}’. Please summarize the information provided above and re-describe the electronic product represented by node ‘n{id}’ based on the results of the summary in 200 words: Books-
HistoryThe textual description of the Amazon-Books graph centered on node ‘n{id}’ is shown above. Each node in the graph represents a book focusing on items labeled as 'History', and each edge signifies frequent co-purchases or co-views between two books. The title and description of the book of node ‘n{id}’ is: ‘{desc}’. Please summarize the information provided above and re-describe the history book represented by node ‘n{id}’ based on the results of the summary in 200 words: WikiCS The textual description of the Wikipedia-based graph centered on node ‘n{id}’ is shown above. The textual description of node ‘n{id}’ is ‘{desc}’. Please summarize the information provided above and re-describe node ‘n{id}’ based on the results of the summary in 200 words: Instagram The textual description of the social network centered on node ‘n{id}’ is shown above. Each node in the graph signifys user, and each edge signifies following relationships. The textual description of node ‘n{id}’ is: ‘{desc}’. Please summarize the information provided above and re-describe the user represented by node ‘n{id}’ based on the results of the summary in 200 words:
下载: 导出CSV
表 4 轻度域偏移数据集上的节点分类任务准确率(%)
Table 4 Accuracy for the node classification task on mild domain shift datasets (%)
方法 Cora CiteSeer WikiCS Instagram Ele-Photo Ele-Computers Books-History 平均值 BERT[57] 19.56 $\pm$ 0.98 33.26 $\pm$ 2.35 29.37 $\pm$ 0.00 57.02 $\pm$ 0.57 21.80 $\pm$ 0.14 13.88 $\pm$ 0.29 9.95 $\pm$ 0.42 26.41 SBERT[58] 54.35 $\pm$ 1.26 50.47 $\pm$ 0.90 48.16 $\pm$ 0.00 48.34 $\pm$ 1.23 35.96 $\pm$ 0.44 41.82 $\pm$ 0.22 30.45 $\pm$ 0.19 44.22 DeBERTa[59] 16.42 $\pm$ 1.26 16.42 $\pm$ 1.26 15.29 $\pm$ 0.00 39.81 $\pm$ 0.58 12.38 $\pm$ 0.26 10.62 $\pm$ 0.15 9.70 $\pm$ 0.26 17.23 E5[60] 44.65 $\pm$ 0.82 42.57 $\pm$ 0.54 31.49 $\pm$ 0.00 61.28 $\pm$ 0.97 35.14 $\pm$ 0.28 16.54 $\pm$ 0.14 12.92 $\pm$ 0.48 34.94 Qwen2-7B-Instruct[61] 61.44 $\pm$ 1.29 53.57 $\pm$ 0.86 58.72 $\pm$ 0.25 39.13 $\pm$ 0.78 45.55 $\pm$ 0.12 59.18 $\pm$ 0.20 23.79 $\pm$ 0.34 48.77 Qwen2-72B-Instruct[61] 62.18 $\pm$ 0.98 60.97 $\pm$ 0.87 60.91 $\pm$ 0.08 47.70 $\pm$ 0.31 52.41 $\pm$ 0.39 60.88 $\pm$ 0.30 53.56 $\pm$ 0.64 56.94 LLaMA3.1-8B-Instruct[11] 57.75 $\pm$ 1.21 53.54 $\pm$ 1.71 58.32 $\pm$ 0.21 39.37 $\pm$ 1.14 34.38 $\pm$ 0.25 46.98 $\pm$ 0.21 22.28 $\pm$ 0.18 44.66 LLaMA3.1-70B-Instruct[11] 65.72 $\pm$ 1.24 62.79 $\pm$ 1.24 62.82 $\pm$ 0.04 43.68 $\pm$ 0.52 51.26 $\pm$ 0.53 61.62 $\pm$ 0.42 53.33 $\pm$ 0.55 57.32 OFA[12] 37.25 $\pm$ 1.38 29.64 $\pm$ 0.19 45.52 $\pm$ 1.06 32.71 $\pm$ 0.16 33.03 $\pm$ 0.64 22.09 $\pm$ 0.39 16.87 $\pm$ 0.93 31.02 ZeroG[13] 62.32 $\pm$ 1.91 52.55 $\pm$ 1.23 54.93 $\pm$ 0.06 48.97 $\pm$ 0.78 45.12 $\pm$ 0.65 56.20 $\pm$ 0.35 40.74 $\pm$ 0.65 51.55 GraphGPT[14] 23.25 $\pm$ 1.45 18.04 $\pm$ 1.45 6.30 $\pm$ 0.26 45.12 $\pm$ 1.16 7.62 $\pm$ 0.22 29.71 $\pm$ 0.83 15.92 $\pm$ 0.14 20.85 LLaGA[15] 21.44 $\pm$ 0.65 16.07 $\pm$ 1.15 2.65 $\pm$ 0.72 41.12 $\pm$ 0.94 6.50 $\pm$ 0.53 23.10 $\pm$ 0.33 11.17 $\pm$ 0.58 17.44 DGI[62] 24.03 $\pm$ 1.40 18.71 $\pm$ 1.22 18.86 $\pm$ 0.25 61.42 $\pm$ 1.12 13.96 $\pm$ 0.17 27.12 $\pm$ 0.03 15.77 $\pm$ 0.02 25.70 GRACE[63] 13.69 $\pm$ 1.27 22.88 $\pm$ 1.49 16.07 $\pm$ 0.32 62.23 $\pm$ 0.93 10.16 $\pm$ 0.13 10.94 $\pm$ 0.12 32.39 $\pm$ 0.11 24.05 BGRL[64] 31.99 $\pm$ 1.06 26.50 $\pm$ 1.22 18.35 $\pm$ 0.22 61.45 $\pm$ 0.82 5.21 $\pm$ 0.22 24.12 $\pm$ 0.22 16.28 $\pm$ 0.35 26.27 GraphMAE[65] 23.25 $\pm$ 1.07 20.75 $\pm$ 0.88 12.14 $\pm$ 0.20 62.39 $\pm$ 0.84 12.53 $\pm$ 0.08 8.36 $\pm$ 0.06 21.76 $\pm$ 0.17 23.03 G2P2[66] 41.51 $\pm$ 0.78 51.02 $\pm$ 0.62 31.92 $\pm$ 0.15 52.87 $\pm$ 0.78 22.21 $\pm$ 0.12 32.52 $\pm$ 0.13 26.18 $\pm$ 0.25 36.89 GraphCLIP[19] 67.31 $\pm$ 1.76 63.13 $\pm$ 1.13 70.19 $\pm$ 0.10 64.05 $\pm$ 0.34 53.40 $\pm$ 0.64 62.04 $\pm$ 0.21 53.88 $\pm$ 0.35 62.00 DORA 70.29 $\pm$ 0.54 67.82 $\pm$ 0.52 72.42 $\pm$ 0.67 64.83 $\pm$ 0.25 54.93 $\pm$ 0.42 63.25 $\pm$ 0.50 54.69 $\pm$ 0.43 64.03
下载: 导出CSV
表 5 不同测试时自适应方法在轻度域偏移数据集上的节点分类任务准确率(%)
Table 5 Accuracy for the node classification task on mild domain shift datasets with different TTA methods (%)
方法 Cora CiteSeer WikiCS Instagram Ele-Photo Ele-Computers Books-History 平均值 Tent[21] 64.27 $\pm$ 1.35 63.06 $\pm$ 2.49 57.27 $\pm$ 0.83 50.56 $\pm$ 0.39 44.90 $\pm$ 0.14 49.35 $\pm$ 0.20 24.99 $\pm$ 0.48 50.63 GTrans[24] 69.37 $\pm$ 0.60 66.98 $\pm$ 1.12 71.89 $\pm$ 0.77 64.02 $\pm$ 0.19 54.83 $\pm$ 0.29 61.16 $\pm$ 0.37 50.92 $\pm$ 0.28 62.74 Matcha[22] 69.49 $\pm$ 1.13 66.78 $\pm$ 1.39 72.82 $\pm$ 0.89 64.02 $\pm$ 0.50 51.34 $\pm$ 0.74 56.06 $\pm$ 0.30 45.34 $\pm$ 1.35 60.84 DORA 70.29 $\pm$ 0.54 67.82 $\pm$ 0.52 72.42 $\pm$ 0.67 64.83 $\pm$ 0.25 54.93 $\pm$ 0.42 63.25 $\pm$ 0.50 54.69 $\pm$ 0.43 64.03
下载: 导出CSV
表 6 消融实验结果(%)
Table 6 The results of the ablation experiment (%)
RFCI D&C-TTA Cora WikiCS Instagram RAS DFCI $\times$ $\times$ $\times$ 67.31 $\pm$ 1.76 70.19 $\pm$ 0.10 64.05 $\pm$ 0.34 $\times$ $ \checkmark$ $ \checkmark$ 69.13 $\pm$ 1.23 71.39 $\pm$ 0.74 64.21 $\pm$ 0.33 $ \checkmark$ $\times$ $ \checkmark$ 70.23 $\pm$ 0.57 72.16 $\pm$ 0.68 64.60 $\pm$ 0.31 $ \checkmark$ $ \checkmark$ $\times$ 70.05 $\pm$ 0.46 71.41 $\pm$ 1.35 64.80 $\pm$ 0.28 $ \checkmark$ $ \checkmark$ $ \checkmark$ 70.29 $\pm$ 0.54 72.42 $\pm$ 0.67 64.83 $\pm$ 0.25
下载: 导出CSV
-
[1] Rozemberczki B, Allen C, Sarkar R. Multi-scale attributed node embedding. Journal of Complex Networks, 2021, 9(2): Article No. cnab014 doi: 10.1093/comnet/cnab014 [2] Hu W H, Fey M, Zitnik M, Dong Y X, Ren H Y, Liu B W, et al. Open graph benchmark: Datasets for machine learning on graphs. arXiv preprint arXiv: 2005.00687, 2021. [3] Pareja A, Domeniconi G, Chen J, Ma T F, Suzumura T, Kanezashi H, et al. EvolveGCN: Evolving graph convolutional networks for dynamic graphs. In: Proceedings of the AAAI Conference on Artificial Intelligence. New York, USA: AAAI, 2020. 5363−5370 [4] 王振东, 徐振宇, 李大海, 王俊岭. 面向入侵检测的元图神经网络构建与分析. 自动化学报, 2023, 49(7): 1530−1548Wang Zhen-Dong, Xu Zhen-Yu, Li Da-Hai, Wang Jun-Ling. Construction and analysis of meta graph neural network for intrusion detection. Acta Automatica Sinica, 2023, 49(7): 1530−1548 [5] 陈露, 尚家兴, 刘大江, 张玉芳, 倪晚成. 基于异构图神经网络的可解释兵棋态势预测方法. 自动化学报, 2025, 51(6): 1248−1260Chen Lu, Shang Jia-Xing, Liu Da-Jiang, Zhang Yu-Fang, Ni Wan-Cheng. An interpretable wargame situation prediction method based on heterogeneous graph neural networks. Acta Automatica Sinica, 2025, 51(6): 1248−1260 [6] Li Y X, Hooi B. Prompt-based zero- and few-shot node classification: A multimodal approach. arXiv preprint arXiv: 2307.11572, 2023. [7] Tang Y R, Qiu R H, Liu Y L, Li X, Huang Z. CaseGNN: Graph neural networks for legal case retrieval with text-attributed graphs. In: Proceedings of the 46th European Conference on Information Retrieval. Glasgow, UK: Springer, 2024. 80−95 [8] He X X, Tian Y J, Sun Y F, Chawla N V, Laurent T, LeCun Y, et al. G-retriever: Retrieval-augmented generation for textual graph understanding and question answering. arXiv preprint arXiv: 2402.07630, 2024. [9] 徐正斐, 辛欣. 基于大语言模型的中文实体链接实证研究. 自动化学报, 2025, 51(2): 327−342 doi: 10.16383/j.aas.c240069Xu Zheng-Fei, Xin Xin. An empirical study of Chinese entity linking based on large language model. Acta Automatica Sinica, 2025, 51(2): 327−342 doi: 10.16383/j.aas.c240069 [10] 秦龙, 武万森, 刘丹, 胡越, 尹全军, 阳东升, 等. 基于大语言模型的复杂任务自主规划处理框架. 自动化学报, 2024, 50(4): 862−872 doi: 10.16383/j.aas.c240088Qin Long, Wu Wan-Sen, Liu Dan, Hu Yue, Yin Quan-Jun, Yang Dong-Sheng, et al. Autonomous planning and processing framework for complex tasks based on large language models. Acta Automatica Sinica, 2024, 50(4): 862−872 doi: 10.16383/j.aas.c240088 [11] Vavekanand R, Sam K. LLaMA 3.1: An in-depth analysis of the next-generation large language model [Online], available: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=6139407, July 1, 2026 [12] Liu H, Feng J R, Kong L C, Liang N Y, Tao D C, Chen Y X, et al. One for all: Towards training one graph model for all classification tasks. arXiv preprint arXiv: 2310.00149, 2024. [13] Li Y H, Wang P S, Li Z X, Yu J X, Li J. ZeroG: Investigating cross-dataset zero-shot transferability in graphs. In: Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. Barcelona, Spain: ACM, 2024. 1725−1735 [14] Tang J B, Yang Y H, Wei W, Shi L, Su L X, Cheng S Q, et al. GraphGPT: Graph instruction tuning for large language models. In: Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. Washington, USA: ACM, 2024. 491−500 [15] Chen R J, Zhao T, Jaiswal A, Shah N, Wang Z Y. LLaGA: Large language and graph assistant. In: Proceedings of the 41st International Conference on Machine Learning. Vienna, Austria: JMLR, 2024. Article No. 306 [16] Rosenfeld J S. Scaling Laws for Deep Learning. Cambridge: Massachusetts Institute of Technology, 2021. [17] Hernandez D, Kaplan J, Henighan T, McCandlish S. Scaling laws for transfer. arXiv preprint arXiv: 2102.01293, 2021. [18] Radford A, Kim J W, Hallacy C, Ramesh A, Goh G, Agarwal S, et al. Learning transferable visual models from natural language supervision. In: Proceedings of the 38th International Conference on Machine Learning. Virtual Event: PMLR, 2021. 8748−8763 [19] Zhu Y, Shi H Z, Wang X T, Liu Y C, Wang Y K, Peng B C, et al. GraphCLIP: Enhancing transferability in graph foundation models for text-attributed graphs. In: Proceedings of the ACM on Web Conference 2025. Sydney, Australia: ACM, 2025. 2183−2197 [20] Han Z Y, Gui X J, Sun H L, Yin Y L, Li S. Towards accurate and robust domain adaptation under multiple noisy environments. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(5): 6460−6479 doi: 10.24963/ijcai.2020/314 [21] Wang D Q, Shelhamer E, Liu S T, Olshausen B A, Darrell T. Tent: Fully test-time adaptation by entropy minimization. In: Proceedings of the 9th International Conference on Learning Representations. Virtual Event: OpenReview.net, 2021. [22] Bao W X, Zeng Z C, Liu Z N, Tong H H, He J R. Matcha: Mitigating graph structure shifts with test-time adaptation. In: Proceedings of the 13th International Conference on Learning Representations. Singapore: OpenReview.net, 2025. [23] Ju M X, Zhao T, Yu W H, Shah N, Ye Y F. GRAPHPATCHER: Mitigating degree bias for graph neural networks via test-time augmentation. In: Proceedings of the 37th International Conference on Neural Information Processing Systems. New Orleans, USA: Curran Associates Inc., 2023. Article No. 2434 [24] Jin W, Zhao T, Ding J Y, Liu Y Z, Tang J L, Shah N. Empowering graph representation learning with test-time graph transformation. In: Proceedings of the 11th International Conference on Learning Representations. Kigali, Rwanda: OpenReview.net, 2023. [25] Chatterjee S, Diaconis P. The sample size required in importance sampling. The Annals of Applied Probability, 2018, 28(2): 1099−1135 [26] McAllester D, Stratos K. Formal limitations on the measurement of mutual information. In: Proceedings of the 23rd International Conference on Artificial Intelligence and Statistics. Palermo, Italy: PMLR, 2020. 875−884 [27] Su G X, Wang H C, Wang J W, Zhang W J, Zhang Y, Pei J. Large language models meet text-attributed graphs: A survey of integration frameworks and applications. arXiv preprint arXiv: 2510.21131, 2025. [28] Beiranvand A, Vahidipour S M. Integrating structural and semantic signals in text-attributed graphs with BiGTex. arXiv preprint arXiv: 2504.12474, 2025. [29] Khoshraftar S, Abedini N, Hajian A. GraphiT: Efficient node classification on text-attributed graphs with prompt optimized LLMs. In: Proceedings of the ACM on Web Conference 2025. Sydney, Australia: ACM, 2025. 1824−1829 [30] Zhang Q Y, Bian Y T, Kong X K, Zhao P L, Zhang C Q. COME: Test-time adaption by conservatively minimizing entropy. In: Proceedings of the 13th International Conference on Learning Representations. Singapore: OpenReview.net, 2025. [31] Lee J, Jung D, Lee S, Park J, Shin J, Hwang U, et al. Entropy is not enough for test-time adaptation: From the perspective of disentangled factors. In: Proceedings of the 12th International Conference on Learning Representations. Vienna, Austria: OpenReview.net, 2024. [32] Hu Y H, Qiao C Y, Geng X, Xu N. Selective label enhancement learning for test-time adaptation. In: Proceedings of the 13th International Conference on Learning Representations. Singapore: OpenReview.net, 2025. [33] Chen G Z, Zhang J Y, Xiao X, Li Y. GraphTTA: Test time adaptation on graph neural networks. arXiv preprint arXiv: 2208.09126, 2022. [34] Wang Y Q, Li C Z, Zhao J N, Li R. Test-time training for graph neural networks. In: Proceedings of the 30th International Conference on Database Systems for Advanced Applications. Singapore: Springer, 2026. 349−364 [35] Mao H T, Du L, Zheng Y J, Fu Q, Li Z L, Chen X, et al. Source free graph unsupervised domain adaptation. In: Proceedings of the 17th ACM International Conference on Web Search and Data Mining. Merida, Mexico: ACM, 2024. 520−528 [36] Zheng X, Huang W, Zhou C, Li M, Pan S R. Test-time graph neural dataset search with generative projection. In: Proceedings of the 42nd International Conference on Machine Learning. Vancouver, Canada: PMLR, 2025. [37] Zhao Y S, Zhang Q X, Luo X, Luo J Y, Ju W, Xiao Z P, et al. Test-time adaptation on graphs via adaptive subgraph-based selection and regularized prototypes. In: Proceedings of the 42nd International Conference on Machine Learning. Vancouver, Canada: PMLR, 2025. [38] Gadermayr M, Eschweiler D, Klinkhammer B M, Boor P, Merhof D. Gradual domain adaptation for segmenting whole slide images showing pathological variability. In: Proceedings of the 8th International Conference on Image and Signal Processing. Cherbourg, France: Springer, 2018. 461−469 [39] Kumar A, Ma T Y, Liang P. Understanding self-training for gradual domain adaptation. In: Proceedings of the 37th International Conference on Machine Learning. Virtual Event: PMLR, 2020. 5468−5479 [40] Chen H Y, Chao W L. Gradual domain adaptation without indexed intermediate domains. In: Proceedings of the 35th International Conference on Neural Information Processing Systems. Virtual Event: Curran Associates Inc., 2021. Article No. 627 [41] Lei P I, Chen X M, Sheng Y J, Liu Y Y, Gong Z G, Yang Q. Gradual domain adaptation for graph learning. arXiv preprint arXiv: 2501.17443, 2025. [42] Zeng Z C, Qiu R Z, Bao W X, Wei T X, Lin X, Yan Y C, et al. Pave your own path: Graph gradual domain adaptation on fused Gromov-Wasserstein geodesics. arXiv preprint arXiv: 2505.12709, 2026. [43] Rampáček L, Galkin M, Dwivedi V P, Luu A T, Wolf G, Beaini D. Recipe for a general, powerful, scalable graph transformer. In: Proceedings of the 36th International Conference on Neural Information Processing Systems. New Orleans, USA: Curran Associates Inc., 2022. 14501−14515 [44] 胡正平, 孟鹏权. 全局孤立性和局部同质性图表示的随机游走显著目标检测算法. 自动化学报, 2011, 37(10): 1279−1284 doi: 10.3724/SP.J.1004.2011.01279Hu Zheng-Ping, Meng Peng-Quan. Graph presentation random walk salient object detection algorithm based on global isolation and local homogeneity. Acta Automatica Sinica, 2011, 37(10): 1279−1284 doi: 10.3724/SP.J.1004.2011.01279 [45] Bienstock D, Goemans M X, Simchi-Levi D, Williamson D. A note on the prize collecting traveling salesman problem. Mathematical Programming, 1993, 59(1−3): 413−420 doi: 10.1007/BF01581256 [46] Han Z B, Zhang C Q, Fu H Z, Zhou J T. Trusted multi-view classification with dynamic evidential fusion. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(2): 2551−2566 doi: 10.1109/TPAMI.2022.3171983 [47] Liu W T, Wang X Y, Owens J D, Li Y X. Energy-based out-of-distribution detection. In: Proceedings of the 34th International Conference on Neural Information Processing Systems. Vancouver, Canada: Curran Associates Inc., 2020. Article No. 1802 [48] Vinutha H P, Poornima B, Sagar B M. Detection of outliers using interquartile range technique from intrusion dataset. In: Proceedings of the 6th International Conference on FICTA. Singapore: Springer, 2018. 511−518 [49] Niu S C, Wu J X, Zhang Y F, Chen Y F, Zheng S J, Zhao P L, et al. Efficient test-time model adaptation without forgetting. In: Proceedings of the 39th International Conference on Machine Learning. Baltimore, USA: PMLR, 2022. 16888−16905 [50] Sen P, Namata G, Bilgic M, Getoor L, Gallagher B, Eliassi-Rad T. Collective classification in network data. AI Magazine, 2008, 29(3): 93−106 doi: 10.1609/aimag.v29i3.2157 [51] Giles C L, Bollacker K D, Lawrence S. CiteSeer: An automatic citation indexing system. In: Proceedings of the Third ACM Conference on Digital Libraries. Pittsburgh, USA: ACM, 1998. 89−98 [52] Yan H, Li C Z, Long R S, Yan C, Zhao J N, Zhuang W W, et al. A comprehensive study on text-attributed graphs: Benchmarking and rethinking. In: Proceedings of the 37th International Conference on Neural Information Processing Systems. New Orleans, USA: Curran Associates Inc., 2023. Article No. 755 [53] Ni J, Li J C, McAuley J. Justifying recommendations using distantly-labeled reviews and fine-grained aspects. In: Proceedings of the Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Hong Kong, China: ACL, 2019. 188−197 [54] Mernyei P, Cangea C. Wiki-CS: A wikipedia-based benchmark for graph neural networks. arXiv preprint arXiv: 2007.02901, 2020. [55] Huang X W, Han K Q, Yang Y, Bao D Z, Tao Q J, Chai Z W, et al. Can GNN be good adapter for LLMs? In: Proceedings of the ACM Web Conference 2024. Singapore: ACM, 2024. 893−904 [56] Reimers N, Gurevych I. Making monolingual sentence embeddings multilingual using knowledge distillation. In: Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP). Virtual Event: ACL, 2020. 4512−4525 [57] Devlin J, Chang M W, Lee K, Toutanova K. BERT: Pre-training of deep bidirectional transformers for language understanding. In: Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Minneapolis, USA: ACL, 2019. 4171−4186 [58] Reimers N, Gurevych I. Sentence-BERT: Sentence embeddings using Siamese BERT-networks. In: Proceedings of the Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). Hong Kong, China: ACL, 2019. 3982−3992 [59] He P C, Liu X D, Gao J F, Chen W Z. DeBERTa: Decoding-enhanced Bert with disentangled attention. In: Proceedings of the 9th International Conference on Learning Representations. Virtual Event: OpenReview.net, 2021. [60] Wang L, Yang N, Huang X L, Jiao B X, Yang L J, Jiang D X, et al. Text embeddings by weakly-supervised contrastive pre-training. arXiv preprint arXiv: 2212.03533, 2022. [61] Yang A, Yang B S, Zhang B C, Hui B Y, Zheng B, Yu B W, et al. Qwen2.5 technical report. arXiv preprint arXiv: 2412.15115, 2024. [62] Velickovic P, Fedus W, Hamilton W L, Liò P, Bengio Y, Hjelm R D. Deep graph infomax. In: Proceedings of the 7th International Conference on Learning Representations. Barcelona, Spain: OpenReview.net, 2019. [63] Zhu Y Q, Xu Y C, Yu F, Liu Q, Wu S, Wang L. Deep graph contrastive representation learning. arXiv preprint arXiv: 2006.04131, 2020. [64] Thakoor S, Tallec C, Azar M G, Munos R, Veličković P, Valko M. Bootstrapped representation learning on graphs. arXiv preprint arXiv: 2102.06514, 2021. [65] Hou Z Y, Liu X, Cen Y K, Dong Y X, Yang H X, Wang C J, et al. GraphMAE: Self-supervised masked graph autoencoders. In: Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. Washington, USA: ACM, 2022. 594−604 [66] Wen Z H, Fang Y. Augmenting low-resource text classification with graph-grounded pre-training and prompting. In: Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval. Taipei, China: ACM, 2023. 506−516 [67] van der Maaten L, Hinton G. Visualizing data using t-SNE. Journal of Machine Learning Research, 2008, 9(86): 2579−2605 -

 下载:
下载:

计量
- 文章访问数: 109
- HTML全文浏览量: 82
- 被引次数: 0
