

A Cascade Reinforcement Learning Strategy for Efficiently Enhancing the Reasoning Ability of Multimodal Large Language Models
-
摘要: 强化学习在提升多模态大语言模型的推理能力上展现出巨大潜力, 逐渐成为模型训练过程中的关键步骤. 然而, 在线强化学习算法需要策略模型在训练过程中实时采样, 且收敛速度较慢, 因此训练成本昂贵; 离线强化学习虽然整体成本更低, 但是也牺牲了性能上限. 本文尝试将离线强化学习训练成本低的特性与在线强化学习性能上限高的优势相结合, 提出一种新的训练策略--级联强化学习. 这套训练策略包含离线强化学习和在线强化学习两个训练阶段, 其中离线强化学习阶段用于加速模型收敛并提升后续训练的稳定性; 在线强化学习阶段对模型进行了更精细的训练, 进一步提升其性能上限. 本文通过一系列定量分析实验证明了相比单一的在线强化学习算法, 级联强化学习可以通过一半的训练成本达到更高的性能上限. 这种简单有效的训练策略将InternVL3.5-8B-Instruct和InternVL3.5-241B-A28B-Instruct在七个多模态推理评测基准上的平均准确率分别提升了6.7%和6.5%, 证明了这一策略的有效性和可扩展性.Abstract: Reinforcement learning has demonstrated substantial potential in enhancing the reasoning ability of multimodal large language models and has become a critical step during model training. However, online reinforcement learning algorithms require real-time sampling from the policy model during training and typically suffer from slow convergence, resulting in high training cost; Offline reinforcement learning offers lower overall cost but often sacrifices the upper bound of performance. In this paper, we propose a novel training strategy, termed cascade reinforcement learning, which integrates the cost efficiency of offline reinforcement learning with the superior performance potential of online reinforcement learning. This training strategy consists of two stages: An offline reinforcement learning stage that accelerates model convergence and improves subsequent training stability, followed by an online reinforcement learning stage that performs more fine-grained training to further enhance the model's performance ceiling. Through extensive quantitative analysis, we demonstrate that our cascade reinforcement learning achieves higher performance than standalone online reinforcement learning algorithm while requiring only half of the training cost. Using this simple yet effective training strategy, we improve the average accuracy of InternVL3.5-8B-Instruct and InternVL3.5-241B-A28B-Instruct by 6.7% and 6.5%, respectively, across seven multimodal reasoning evaluation benchmarks, validating the effectiveness and scalability of the proposed strategy.
-
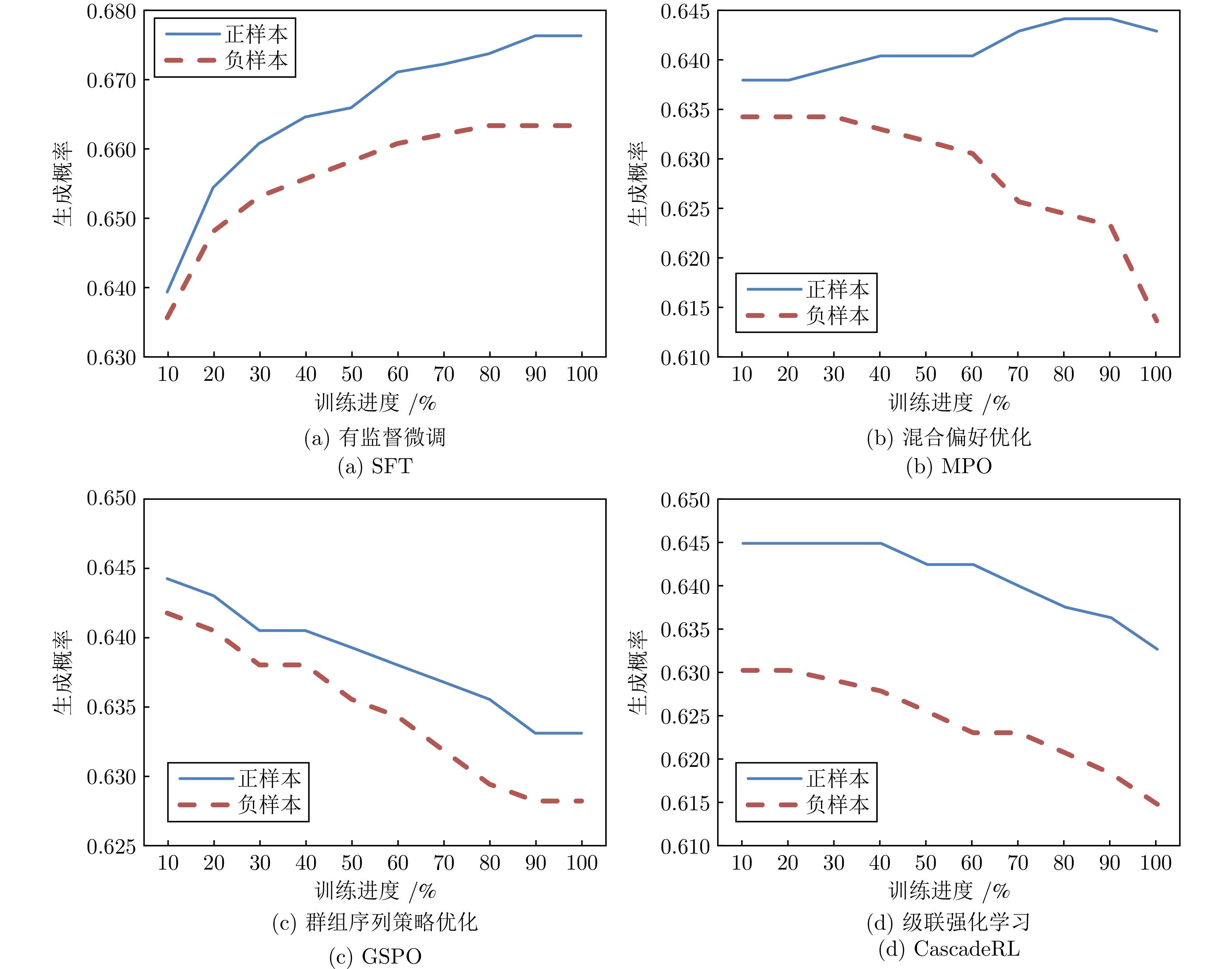
图 2 模型训练过程中关于起始模型的正负响应的生成概率
Fig. 2 Generation probabilities of positive and negative responses relative to the initial model during training

图 3 级联强化学习各阶段对模型推理性能的影响
Fig. 3 Effect of different CascadeRL stages on model reasoning performance
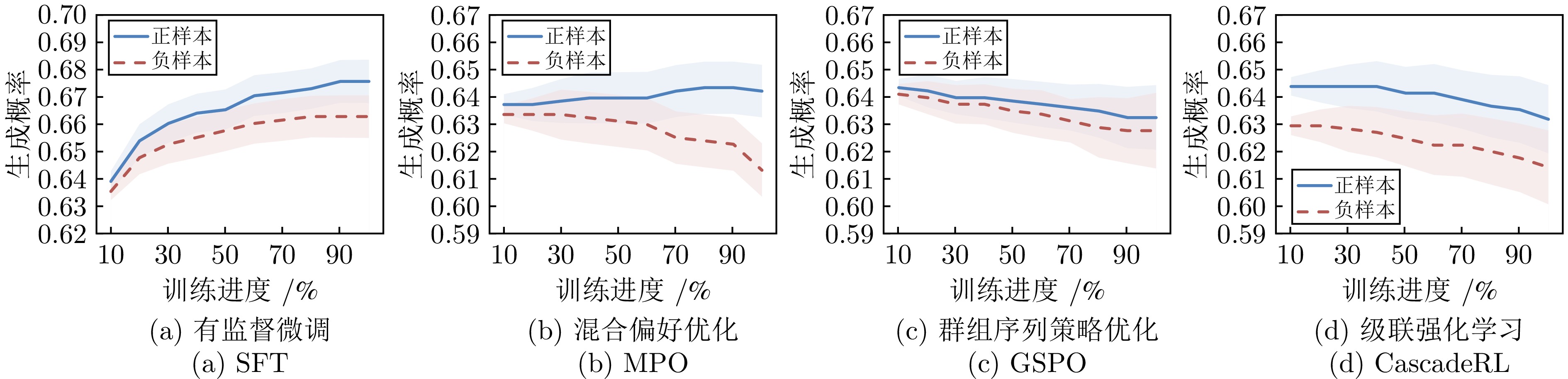
图 5 不同算法训练过程中, 模型关于起始模型的正负响应的生成概率
Fig. 5 Generation probabilities of positive and negative responses relative to the initial model during training with different algorithms
表 1 不同算法的训练结果对比
Table 1 Comparison of training results for different algorithms
模型 训练响应数量 显卡小时数 得分 基线模型 InternVL3.5-4B-Inst — — 57.5 有监督微调 SFT (Half) ~ 59.2 K 5.3 64.4 SFT (Half × 2) ~ 118.4 K 8.0 66.6 SFT (Full) ~ 124.3 K 8.0 67.0 离线强化学习算法 DPO (Half) ~ 64.5 K 4.5 67.3 DPO (Half × 2) ~ 129.1 K 8.5 70.2 DPO (Full) ~ 128.2 K 8.5 69.5 MPO (Half) ~ 64.5 K 4.6 68.0 MPO (Half × 2) ~ 129.1 K 8.5 70.8 MPO (Full) ~ 128.2 K 8.5 70.8 在线强化学习算法 GRPO (Half) ~ 62.9 K 65.2 63.9 GRPO (Half × 2) ~ 125.8 K 141.4 69.8 GRPO (Full) ~ 125.8 K 144.4 71.5 GSPO (Half) ~ 62.9 K 65.4 63.4 GSPO (Half × 2) ~ 125.8 K 159.3 67.3 GSPO (Full) ~ 125.8 K 168.6 72.0  下载: 导出CSV
下载: 导出CSV
表 2 相同数据成本下, 不同算法的训练结果
Table 2 Training results of different algorithms under the same data cost
模型 训练响应数量 显卡小时数 得分 SFT (Half × 2) ~ 118.4 K 8.0 66.6 SFT (Full) ~ 124.3 K 8.0 67.0 MPO (Half × 2) ~ 129.1 K 8.5 70.8 MPO (Full) ~ 128.2 K 8.5 70.8 GSPO (Half × 2) ~ 125.8 K 159.3 67.3 GSPO (Full) ~ 125.8 K 168.6 72.0 MPO → GSPO ~ 127.4 K 68.3 72.2
下载: 导出CSV
表 3 基于不同级联强化学习实例的训练结果
Table 3 Training results based on different CascadeRL instances
模型 训练响应数量 显卡小时数 得分 SFT → GRPO 122.1 K 66.0 70.3 SFT → GSPO 122.1 K 75.4 71.3 GRPO → DPO 127.4 K 73.2 70.1 GRPO → MPO 127.4 K 73.2 70.4 GSPO → DPO 127.4 K 73.4 68.1 GSPO → MPO 127.4 K 73.4 70.0 DPO → GRPO 127.4 K 63.2 69.9 DPO → GSPO 127.4 K 67.8 71.6 MPO → GRPO 127.4 K 68.1 71.5 MPO → GSPO 127.4 K 68.3 72.2 MPO (Full) → GRPO 191.1 K 70.4 72.3 MPO (Full) → GSPO 191.1 K 72.1 72.1
下载: 导出CSV
表 4 不同算法训练后的模型在域外评测集的性能
Table 4 Performance of models trained with different algorithms on out-of-domain evaluation sets
模型 M3CoT MMMU MathVerse InternVL3.5-4B-Inst 57.5 62.3 42.4 SFT (Full) 67.0 59.6 39.8 MPO (Full) 70.8 60.7 44.2 GSPO (Full) 72.0 63.3 43.5 GSPO → MPO 70.0 60.4 43.5 MPO → GSPO 72.2 62.8 44.8
下载: 导出CSV
表 5 不同超参数设置对训练结果的影响
Table 5 Effect of different hyperparameter settings on training results
实验设置 MPO GSPO InternVL3.5-4B-Inst 57.5 57.5 每个问题采样的响应数量 每个问题采样4条响应 63.4 60.1 每个问题采样8条响应 67.6 63.7 每个问题采样16条响应 70.8 72.0 每个问题采样32条响应 71.2 71.7 KL散度约束强度 coef = 0.000 — 71.7 coef = 0.001 — 71.7 coef = 0.100 — 71.8 coef = 1.000 — 71.1
下载: 导出CSV
表 6 不同比例离线和在线强化学习的训练效果
Table 6 Training effect of different offline and online reinforcement learning ratios
实验设置 显卡小时数 GSPO InternVL3.5-4B-Inst — 57.5 $ 2.0:0.0 $ ~ 8.5 K 70.8 $ 1.5:0.5 $ ~ 48.1 K 71.4 $ 1.0:1.0 $ ~ 68.3 K 72.2 $ 0.5:1.5 $ ~ 130.2 K 72.3 $ 0.0:2.0 $ ~ 168.6 K 72.0
下载: 导出CSV
表 7 不同模型的多模态推理性能对比
Table 7 Comparison of multimodal reasoning performance across different models
模型 MMMU
(val)MathVista
(mini)MathVision MathVerse
(vision-only)DynaMath
(worst case)WeMath LogicVista 均分 InternVL3-1B[42] 43.4 45.8 18.8 18.7 5.8 13.4 29.8 25.1 InternVL3.5-1B-CascadeRL 44.2 59.3 27.3 37.8 17.2 21.5 29.3 33.8 Ovis-2B[43] 45.6 64.1 17.7 29.4 10.0 9.9 34.7 30.2 Qwen2.5-VL-3B[44] 51.2 61.2 21.9 31.2 13.2 22.9 40.3 34.6 InternVL3-2B[42] 48.6 57.0 21.7 25.3 14.6 22.4 36.9 32.4 InternVL3.5-2B-CascadeRL 59.0 71.8 42.8 53.4 31.5 48.5 47.7 50.7 Ovis-4B[43] 49.0 69.6 21.5 38.5 18.0 16.9 35.3 35.5 MiniCPM-V-4-4B[45] 51.2 66.9 20.7 18.3 14.2 32.7 30.6 33.5 InternVL2.5-4B[46] 51.8 64.1 18.4 27.7 15.2 21.2 34.2 33.2 InternVL3.5-4B-CascadeRL 66.6 77.1 54.4 61.7 35.7 50.1 56.4 57.4 MiniCPM-o2.6[45] 50.9 73.3 21.7 35.0 10.4 25.2 36.0 36.1 Ovis-8B[43] 57.4 71.8 25.9 42.3 20.4 27.2 39.4 40.6 Qwen2.5-VL-8B[44] 55.0 67.8 25.4 41.1 21.0 35.2 44.1 41.4 MiMo-VL-RL-8B[47] 66.7 81.5 60.4 71.5 45.9 66.3 61.4 64.8 Keye-VL-8B[28] 71.4 80.7 50.8 54.8 37.3 60.7 54.8 58.6 GLM-4.1V-9B[27] 68.0 80.7 54.4 68.4 42.5 63.8 60.4 62.6 InternVL3-8B[42] 62.7 71.6 29.3 39.8 25.5 37.1 44.1 44.3 InternVL3.5-8B-CascadeRL 73.4 78.4 56.8 61.5 37.7 57.0 57.3 60.3 Gemma-3-12B[48] 55.2 56.1 30.3 21.1 20.8 33.6 41.2 36.9 Ovis2-16B[43] 60.7 73.7 30.1 45.8 26.3 45.0 47.4 47.0 InternVL3-14B[42] 67.1 75.1 37.2 44.4 31.3 43.0 51.2 49.9 InternVL3.5-14B-CascadeRL 73.3 80.5 59.9 62.8 38.7 58.7 60.2 62.0 Kimi-VL-A3B- 2506 [49]64.0 80.1 54.4 54.6 28.1 42.0 51.4 53.5 InternVL3.5-30B-A3B-CascadeRL 75.6 80.9 55.7 60.4 36.5 48.4 55.7 59.0 Gemma-3-27B[48] 64.9 59.8 39.8 34.0 28.5 37.9 47.3 44.6 Ovis2-34B[43] 66.7 76.1 31.9 50.1 27.5 51.9 49.9 50.6 Qwen2.5-VL-32B[44] 70.2 74.8 38.1 57.6 35.1 46.5 52.6 53.6 Skywork-R1V3-38B[50] 76.0 77.1 52.6 59.6 35.1 56.5 59.7 59.5 InternVL3-38B[42] 70.1 75.1 34.2 48.2 35.3 48.6 58.4 52.8 InternVL3.5-38B-CascadeRL 76.9 81.9 63.7 67.6 41.7 64.8 65.3 66.0 GPT-5-nano- 20250807 [51]72.6 73.1 59.7 66.6 47.9 59.4 57.5 62.4 GPT-5- 20250807 [51]81.8 81.9 72.0 81.2 60.9 71.1 70.0 74.1 Claude-3.7-Sonnet[52] 75.0 66.8 41.9 46.7 39.7 49.3 58.2 53.9 Gemini-2.0-Pro[53] 69.9 71.3 48.1 67.3 43.3 56.5 53.2 58.5 Gemini-2.5-Pro[53] 74.7 80.9 69.1 76.9 56.3 78.0 73.8 72.8 Doubao-1.5-Pro[54] 73.8 78.6 51.5 64.7 44.9 65.7 64.2 63.3 GLM-4.5V[27] 75.4 84.6 65.6 72.1 53.9 68.8 62.4 69.0 QvQ-72B-Preview[55] 70.3 70.3 34.9 48.2 30.7 39.0 58.2 50.2 Qwen2.5-VL-72B[44] 68.2 74.2 39.3 47.3 35.9 49.1 55.7 52.8 Step3-321B-A38B[56] 74.2 79.2 64.8 62.7 50.1 59.8 60.2 64.4 InternVL3-78B[42] 72.2 79.0 43.1 51.0 35.1 46.1 55.9 54.6 InternVL3.5-241B-A28B-CascadeRL 77.7 82.7 63.9 68.5 46.5 62.3 66.7 66.9
下载: 导出CSV
表 8 模型在不同训练阶段结束后的多模态推理性能对比
Table 8 Comparison of multimodal reasoning performance after different training stages
模型 MMMU
(val)MathVista
(mini)MathVision MathVerse
(vision-only)DynaMath
(worst case)WeMath LogicVista 均分 InternVL3.5-1B-Inst 37.2 48.6 15.8 27.0 8.4 13.9 29.1 25.7 + MPO 40.3 50.5 22.0 32.1 9.0 16.8 32.7 29.1 + CascadeRL 44.2 59.3 27.3 37.8 17.2 21.5 29.3 33.8 InternVL3.5-2B-Inst 53.0 60.8 27.0 39.6 19.8 28.1 41.2 38.5 + MPO 54.3 62.6 34.2 46.4 21.0 28.1 40.9 41.1 + CascadeRL 59.0 71.8 42.8 53.4 31.5 48.5 47.7 50.7 InternVL3.5-4B-Inst 64.3 71.4 40.5 50.0 30.7 35.6 53.5 49.4 + MPO 65.4 71.7 48.0 54.9 30.7 39.8 55.9 52.3 + CascadeRL 66.6 77.1 54.4 61.7 35.7 50.1 56.4 57.4 InternVL3.5-8B-Inst 68.1 74.2 46.4 55.8 30.7 46.0 53.9 53.6 + MPO 71.2 75.9 52.6 54.8 33.1 47.7 58.6 56.3 + CascadeRL 73.4 78.4 56.8 61.5 37.7 57.0 57.3 60.3 InternVL3.5-14B-Inst 71.8 73.4 48.7 55.5 31.9 45.7 57.5 54.9 + MPO 73.3 74.0 53.0 57.5 32.3 45.2 60.9 56.6 + CascadeRL 73.3 80.5 59.9 62.8 38.7 58.7 60.2 62.0 InternVL3.5-30B-A3B-Inst 72.3 73.3 45.1 50.4 31.9 39.7 56.4 52.7 + MPO 71.7 75.3 50.7 58.5 32.9 43.7 59.7 56.1 + CascadeRL 75.6 80.9 55.7 60.4 36.5 48.4 55.7 59.0 InternVL3.5-38B-Inst 73.9 75.9 58.2 59.0 29.7 47.5 60.0 57.7 + MPO 76.9 80.5 56.3 59.4 36.9 55.6 64.2 61.4 + CascadeRL 76.9 81.9 63.7 67.6 41.7 64.8 65.3 66.0 InternVL3.5-241B-A28B-Inst 76.2 80.1 55.6 61.7 36.5 49.7 63.3 60.4 + MPO 76.0 82.2 55.3 64.1 38.3 51.3 69.4 62.4 + CascadeRL 77.7 82.7 63.9 68.5 46.5 62.3 66.7 66.9
下载: 导出CSV
表 9 离线强化学习(MPO)、在线强化学习(GSPO)以及级联强化学习(CascadeRL)的训练效率及性能对比
Table 9 Comparison of training efficiency and performance among offline RL (MPO), online RL (GSPO), and CascadeRL
模型 显卡小时数 MMMU
(val)MathVista
(mini)MathVision MathVerse
(vision-only)DynaMath
(worst case)WeMath LogicVista 均分 InternVL3.5-8B-Inst - 68.1 74.2 46.4 55.8 30.7 46.0 53.9 53.6 +MPO ~ 0.3 K 71.2 75.9 52.6 54.8 33.1 47.7 58.6 56.3 +GSPO (1 episode) ~ 5.5 K 73.8 77.9 51.6 58.8 35.1 48.9 54.8 57.3 +GSPO (2 episodes) ~ 11.0 K 72.0 78.1 51.6 58.5 35.7 54.1 57.0 58.2 +CascadeRL (ours) ~ 5.8 K 73.4 78.4 56.8 61.5 37.7 57.0 57.3 60.3
下载: 导出CSV
-
[1] Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. Advances in Neural Information Processing Systems, 2024, 36. [2] Weiyun Wang, Zhe Chen, Wenhai Wang, Yue Cao, Yangzhou Liu, Zhangwei Gao, Jinguo Zhu, Xizhou Zhu, Lewei Lu, Yu Qiao, and Jifeng Dai. Enhancing the reasoning ability of multimodal large language models via mixed preference optimization. arXiv preprint arXiv: 2411.10442, 2024. [3] Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv: 2402.03300, 2024. [4] Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, Chang Gao, Kai Dang, Yuqiong Liu, Rui Men, An Yang, et al. Group sequence policy optimization. arXiv preprint arXiv: 2507.18071, 2025. [5] Qiguang Chen, Libo Qin, Jin Zhang, Zhi Chen, Xiao Xu, and Wanxiang Che. M3cot: A novel benchmark for multi-domain multi-step multi-modal chain-of-thought. arXiv preprint arXiv: 2405.16473, 2024. [6] Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3.5: Advancing open-source multimodal models in versatility, reasoning, and effciency. arXiv preprint arXiv: 2508.18265, 2025. [7] Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and effcient foundation language models. arXiv preprint arXiv: 2302.13971, 2023. [8] Zheng Cai, Maosong Cao, Haojiong Chen, Kai Chen, Keyu Chen, Xin Chen, Xun Chen, Zehui Chen, Zhi Chen, Pei Chu, et al. Internlm2 technical report. arXiv preprint arXiv: 2403.17297, 2024. [9] An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report. arXiv preprint arXiv: 2505.09388, 2025. [10] OpenAI. Introducing gpt-oss. https://openai.com/index/introducing-gpt-oss/, 2025. [11] Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul F. Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human feedback. In Sanmi Koyejo, S. Mohamed, A. Agarwal, Danielle Belgrave, K. Cho, and A. Oh, editors, NeurIPS 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28-December 9, 2022, 2022. [12] 徐正斐, 辛欣. 基于大语言模型的中文实体链接实证研究. 自动化学报, 2025, 51(2): 327−342 doi: 10.16383/j.aas.c240069Xu Zheng-fei and Xin Xin. An empirical study of chinese entity linking based on large language model. Acta Automatica Sinica, 2025, 51(2): 327−342 doi: 10.16383/j.aas.c240069 [13] 秦龙, 武万森, 刘丹, 胡越, 尹全军, 阳东升, 王飞跃. 基于大语言模型的复杂任务自主规划处理框架. 自动化学报, 2024, 50(4): 862−872 doi: 10.16383/j.aas.c240088Qin Long, Wu Wan-sen, Liu Dan, Hu Yue, Yin Quanjun, Yang Dong-sheng, and Wang Fei-yue. Autonomous planning and processing framework for complex tasks based on large language models. Acta Automatica Sinica, 2024, 50(4): 862−872 doi: 10.16383/j.aas.c240088 [14] 陈楚岩, 刘烨谞, 贾维宸, 何雨桐, 袁坤, 王立威. 一种基于单比特通信压缩的大模型训练方法研究. 自动化学报, xxx, xx(x): x−xxChen Chu-yan, Liu Ye-xu, Jia Wei-chen, He Yu-tong, Yuan Kun, and Wang Li-wei. An effective algorithm for llms training with one-bit communication compression. Acta Automatica Sinica, xxx, xx(x): x−xx [15] Hang Yan, Yang Gao, Chaoye Fei, Xiaopeng Yang, and Xipeng Qiu. Data and model architecture in base model training. In Proceedings of the 22nd Chinese National Conference on Computational Linguistics (Volume 2: Frontier Forum), pages 1-15, 2023. [16] Li Zejun, Zhang Jiwen, Wang Ye, Du Mengfei, Liu Qingwen, Wang Dianyi, Wu Binhao, Luo Ruipu, Huang Xuanjing, and Wei Zhongyu. From multi-modal pretraining to multi-modal large language models: An overview of architectures, training. In Proceedings of the 23rd Chinese National Conference on Computational Linguistics (Volume 2: Frontier Forum), pages 1-33, 2024. [17] 郑逸宁, 余镇, 李不凡, 杨捷, 殷林琪, 印张悦, 袁枫烨, 魏海洋, 陆嘉昊, 方世成, 陈爽, 邱锡鹏. 大语言模型的工具使用综述. 自动化学报, 2025, 51(11): 2371−2386 doi: 10.16383/j.aas.c240793Zheng Yi-ning, Yu Zhen, Li Bu-fan, Yang Jie, Yin Linqi, Yin Zhang-yue, Yuan Feng-ye, Wei Hai-yang, Lu Jia-hao, Fang-Shicheng, Chen Shuang, and Qiu Xipeng. Survey of tool use in large language models. Acta Automatica Sinica, 2025, 51(11): 2371−2386 doi: 10.16383/j.aas.c240793 [18] Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Wortsman, et al. Laion-5b: An open large-scale dataset for training next generation image-text models. Advances in Neural Information Processing Systems, 2022, 35: 25278−25294 doi: 10.52202/068431-1833 [19] Qingyun Li, Zhe Chen, Weiyun Wang, Wenhai Wang, Shenglong Ye, Zhenjiang Jin, Guanzhou Chen, Yinan He, Zhangwei Gao, Erfei Cui, et al. Omnicorpus: An unified multimodal corpus of 10 billion-level images interleaved with text. arXiv preprint arXiv: 2406.08418, 2024. [20] Hugo Laurençon, Lucile Saulnier, Léo Tronchon, Stas Bekman, Amanpreet Singh, Anton Lozhkov, Thomas Wang, Siddharth Karamcheti, Alexander Rush, Douwe Kiela, et al. Obelics: An open web-scale filtered dataset of interleaved image-text documents. Advances in Neural Information Processing Systems, 2023, 36: 71683−71702 doi: 10.52202/075280-3138 [21] Yangzhou Liu, Yue Cao, Zhangwei Gao, Weiyun Wang, Zhe Chen, Wenhai Wang, Hao Tian, Lewei Lu, Xizhou Zhu, Tong Lu, et al. Mminstruct: A high-quality multimodal instruction tuning dataset with extensive diversity. arXiv preprint arXiv: 2407.15838, 2024. [22] Weiyun Wang, Min Shi, Qingyun Li, Wenhai Wang, Zhenhang Huang, Linjie Xing, Zhe Chen, Hao Li, Xizhou Zhu, Zhiguo Cao, et al. The all-seeing project: Towards panoptic visual recognition and understanding of the open world. In The International Conference on Learning Representations, 2024. [23] John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv: 1707.06347, 2017. [24] Rui Zheng, Shihan Dou, Songyang Gao, Yuan Hua, Wei Shen, Binghai Wang, Yan Liu, Senjie Jin, Qin Liu, Yuhao Zhou, et al. Secrets of rlhf in large language models part i: Ppo. arXiv preprint arXiv: 2307.04964, 2023. [25] Ralph Allan Bradley and Milton E Terry. Rank analysis of incomplete block designs: I. the method of paired comparisons. Biometrika, 1952, 39(3/4): 324−345 doi: 10.2307/2527550 [26] Seungjae Jung, Gunsoo Han, Daniel Wontae Nam, and Kyoung-Woon On. Binary classifier optimization for large language model alignment. arXiv preprint arXiv: 2404.04656, 2024. [27] Wenyi Hong, Wenmeng Yu, Xiaotao Gu, Guo Wang, Guobing Gan, Haomiao Tang, Jiale Cheng, Ji Qi, Junhui Ji, Lihang Pan, et al. Glm-4.1 v-thinking: Towards versatile multimodal reasoning with scalable reinforcement learning. arXiv preprint arXiv: 2507.01006, 2025. [28] Team Kwai Keye, Biao Yang, Bin Wen, Changyi Liu, Chenglong Chu, Chengru Song, Chongling Rao, Chuan Yi, Da Li, Dunju Zang, et al. Kwai keye-vl technical report. arXiv preprint arXiv: 2507.01949, 2025. [29] Yoshua Bengio, Jérôme Louradour, Ronan Collobert, and Jason Weston. Curriculum learning. In Proceedings of the 26th annual international conference on machine learning, pages 41-48, 2009. [30] Xin Wang, Yudong Chen, and Wenwu Zhu. A survey on curriculum learning. IEEE transactions on pattern analysis and machine intelligence, 2021, 44(9): 4555−4576 [31] Zhiheng Xi, Wenxiang Chen, Boyang Hong, Senjie Jin, Rui Zheng, Wei He, Yiwen Ding, Shichun Liu, Xin Guo, Junzhe Wang, et al. Training large language models for reasoning through reverse curriculum reinforcement learning. ICML2024, 2024. [32] Jiaxi Wu, Dianmin Zhang, Shanlin Zhong, and Hong Qiao. Trajectory-based split hindsight reverse curriculum learning. In 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 3971-3978. IEEE, 2021. [33] Yuxiao Qu, Tianjun Zhang, Naman Garg, and Aviral Kumar. Recursive introspection: Teaching language model agents how to self-improve. Advances in Neural Information Processing Systems, 2024, 37: 55249−55285 doi: 10.52202/079017-1754 [34] Zhenting Wang, Guofeng Cui, Yu-Jhe Li, Kun Wan, and Wentian Zhao. Dump: Automated distributionlevel curriculum learning for rl-based llm post-training. arXiv preprint arXiv: 2504.09710, 2025. [35] Liang Wen, Yunke Cai, Fenrui Xiao, Xin He, Qi An, Zhenyu Duan, Yimin Du, Junchen Liu, Tanglifu Tanglifu, Xiaowei Lv, et al. Light-r1: Curriculum sft, dpo and rl for long cot from scratch and beyond. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 6: Industry Track), pages 318-327, 2025. [36] Xiao Bi, Deli Chen, Guanting Chen, Shanhuang Chen, Damai Dai, Chengqi Deng, Honghui Ding, Kai Dong, Qiushi Du, Zhe Fu, et al. Deepseek llm: Scaling open-source language models with longtermism. arXiv preprint arXiv: 2401.02954, 2024. [37] Chuanneng Sun, Gueyoung Jung, Tuyen X Tran, and Dario Pompili. Cascade reinforcement learning with state space factorization for o-ran-based traffc steering. In 2024 21st Annual IEEE International Conference on Sensing, Communication, and Networking (SECON), pages 1-9. IEEE, 2024. [38] Guillermo A Castillo, Bowen Weng, Wei Zhang, and Ayonga Hereid. Reinforcement learning-based cascade motion policy design for robust 3d bipedal locomotion. IEEE Access, 2022, 10: 20135−20148 doi: 10.1109/ACCESS.2022.3151771 [39] Jing Xu, Jiabin Qiao, Qianli Sun, and Keyan Shen. A deep reinforcement learning framework for cascade reservoir operations under runoff uncertainty. Water, 2025, 17(15): 2324 doi: 10.3390/w17152324 [40] Arka Pal, Deep Karkhanis, Samuel Dooley, Manley Roberts, Siddartha Naidu, and Colin White. Smaug: Fixing failure modes of preference optimisation with dpo-positive. arXiv preprint arXiv: 2402.13228, 2024. [41] Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A frontier large visionlanguage model with versatile abilities. arXiv preprint arXiv: 2308.12966, 2023. [42] Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models. arXiv preprint arXiv: 2504.10479, 2025. [43] Shiyin Lu, Yang Li, Qing-Guo Chen, Zhao Xu, Weihua Luo, Kaifu Zhang, and Han-Jia Ye. Ovis: Structural embedding alignment for multimodal large language model. arXiv preprint arXiv: 2405.20797, 2024. [44] Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2.5-vl technical report. arXiv preprint arXiv: 2502.13923, 2025. [45] Yuan Yao, Tianyu Yu, Ao Zhang, Chongyi Wang, Junbo Cui, Hongji Zhu, Tianchi Cai, Haoyu Li, Weilin Zhao, Zhihui He, et al. Minicpm-v: A gpt-4v level mllm on your phone. arXiv preprint arXiv: 2408.01800, 2024. [46] Zhe Chen, Weiyun Wang, Yue Cao, Yangzhou Liu, Zhangwei Gao, Erfei Cui, Jinguo Zhu, Shenglong Ye, Hao Tian, Zhaoyang Liu, et al. Expanding performance boundaries of open-source multimodal models with model, data, and test-time scaling. arXiv preprint arXiv: 2412.05271, 2024. [47] LLM-Core-Team Xiaomi. Mimo-vl technical report, 2025. [48] Gemma Team, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ramé, Morgane Rivière, et al. Gemma 3 technical report. arXiv preprint arXiv: 2503.19786, 2025. [49] Kimi Team, Angang Du, Bohong Yin, Bowei Xing, Bowen Qu, Bowen Wang, Cheng Chen, Chenlin Zhang, Chenzhuang Du, Chu Wei, et al. Kimi-vl technical report. arXiv preprint arXiv: 2504.07491, 2025. [50] Wei Shen, Jiangbo Pei, Yi Peng, Xuchen Song, Yang Liu, Jian Peng, Haofeng Sun, Yunzhuo Hao, Peiyu Wang, and Yahui Zhou. Skywork-r1v3 technical report. arXiv preprint arXiv: 2507.06167, 2025. [51] OpenAI. Gpt-5 system card. https://cdn.openai.com/pdf/8124a3ce-ab78-4f06-96eb-49ea29ffb52f/gpt5-system-card-aug7.pdf, 2025. [52] Anthropic. The claude 3 model family: Opus, sonnet, haiku. https://www.anthropic.com, 2024. [53] Google Deepmind. Introducing gemini 2.0: our new ai model for the agentic era. https://blog.google/technology/google-deepmind/google-gemini-ai-update-december-2024/, 2024. [54] Dong Guo, Faming Wu, Feida Zhu, Fuxing Leng, Guang Shi, Haobin Chen, Haoqi Fan, Jian Wang, Jianyu Jiang, Jiawei Wang, et al. Seed1. 5-vl technical report. arXiv preprint arXiv: 2505.07062, 2025. [55] Qwen Team. Qvq: To see the world with wisdom, December 2024. [56] StepFun Team. Step3: Cost-effective multimodal intelligence. [57] Qwen Team. Qwen2.5: A party of foundation models. https://qwenlm.github.io/blog/qwen2.5/, September 2024. [58] Gemma Team, Thomas Mesnard, Cassidy Hardin, Robert Dadashi, Surya Bhupatiraju, Shreya Pathak, Laurent Sifre, Morgane Rivière, Mihir Sanjay Kale, Juliette Love, et al. Gemma: Open models based on gemini research and technology. arXiv preprint arXiv: 2403.08295, 2024. [59] StepFun Research Team. Step-1v: A hundred billion parameter multimodal large model. https://platform.stepfun.com, 2024. [60] Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, et al. Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi. arXiv preprint arXiv: 2311.16502, 2023. [61] Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chunyuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai-Wei Chang, Michel Galley, and Jianfeng Gao. Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts. arXiv preprint arXiv: 2310.02255, 2023. [62] Ke Wang, Junting Pan, Weikang Shi, Zimu Lu, Mingjie Zhan, and Hongsheng Li. Measuring multimodal mathematical reasoning with math-vision dataset. arXiv preprint arXiv: 2402.14804, 2024. [63] Renrui Zhang, Dongzhi Jiang, Yichi Zhang, Haokun Lin, Ziyu Guo, Pengshuo Qiu, Aojun Zhou, Pan Lu, Kai-Wei Chang, Peng Gao, et al. Mathverse: Does your multi-modal llm truly see the diagrams in visual math problems? arXiv preprint arXiv: 2403.14624, 2024. [64] Chengke Zou, Xingang Guo, Rui Yang, Junyu Zhang, Bin Hu, and Huan Zhang. Dynamath: A dynamic visual benchmark for evaluating mathematical reasoning robustness of vision language models. arXiv preprint arXiv: 2411.00836, 2024. [65] Runqi Qiao, Qiuna Tan, Guanting Dong, Minhui Wu, Chong Sun, Xiaoshuai Song, Zhuoma GongQue, Shanglin Lei, Zhe Wei, Miaoxuan Zhang, et al. Wemath: Does your large multimodal model achieve human-like mathematical reasoning? arXiv preprint arXiv: 2407.01284, 2024. [66] Yijia Xiao, Edward Sun, Tianyu Liu, and Wei Wang. Logicvista: Multimodal llm logical reasoning benchmark in visual contexts. arXiv preprint arXiv: 2407.04973, 2024. [67] OpenCompass Contributors. Opencompass: A universal evaluation platform for foundation models. https://github.com/open-compass/opencompass, 2023. -


 下载:
下载:


计量
- 文章访问数: 336
- HTML全文浏览量: 323
- 被引次数: 0
