

Distributed Elastic Inference Framework for Large Models in Heterogeneous Industrial Edge Clusters
-
摘要: 在工业4.0时代, 大语言模型向工业边缘异构集群的迁移已成为一项关键技术挑战.边缘设备计算与存储资源受限、动态负载波动、异构架构复杂以及网络高延迟等特性, 使得传统推理框架难以满足工业场景对实时性、鲁棒性和隐私保护的需求.提出一种动态弹性推理框架(Dynama), 设计全域心跳被动感知器和实时弹性量化调度算法.该框架采用管道环并行结构, 实现模型层动态分配与懒加载; 通过被动监测设备延迟向量, 触发实时弹性量化调度算法在不改变层分配前提下优化量化版本, 平衡延迟最小化和精度损失. Dynama通过优化数据传输与量化策略, 显著提升高延迟网络环境下的推理效率, 适应工业边缘的动态环境变化.实验结果表明, Dynama在工业边缘异构集群中展现出优异的实时性与鲁棒性, 为工业智能的落地应用提供高效、可靠的解决方案.Abstract: In the era of Industry 4.0, the migration of large language models to heterogeneous industrial edge clusters has become a key technical challenge. The limited computing and storage resources, dynamic workload fluctuations, complex heterogeneous architectures, and high network latency of edge devices hinder traditional inference frameworks from meeting the real-time, robustness, and privacy protection requirements of industrial scenarios. In this paper, a dynamic elastic inference framework (Dynama), is proposed, and a global heartbeat passive sensor and a real-time elastic quantization scheduling algorithm are designed. This framework employs pipeline ring parallelism structure to enable dynamic model layer allocation and lazy loading; By passively monitoring device latency vectors, the real-time elastic quantization scheduling algorithm is activated to optimize the quantization version without changing layer allocation, thereby balancing latency minimization and accuracy loss. Dynama significantly improves inference efficiency in high-latency network environments and adapts to dynamic environmental changes at the industrial edge by optimizing data transmission and quantization strategies. Experimental results demonstrate that Dynama exhibits excellent real-time performance and robustness in heterogeneous industrial edge clusters, providing an efficient and reliable solution for the practical deployment of industrial intelligence.
-
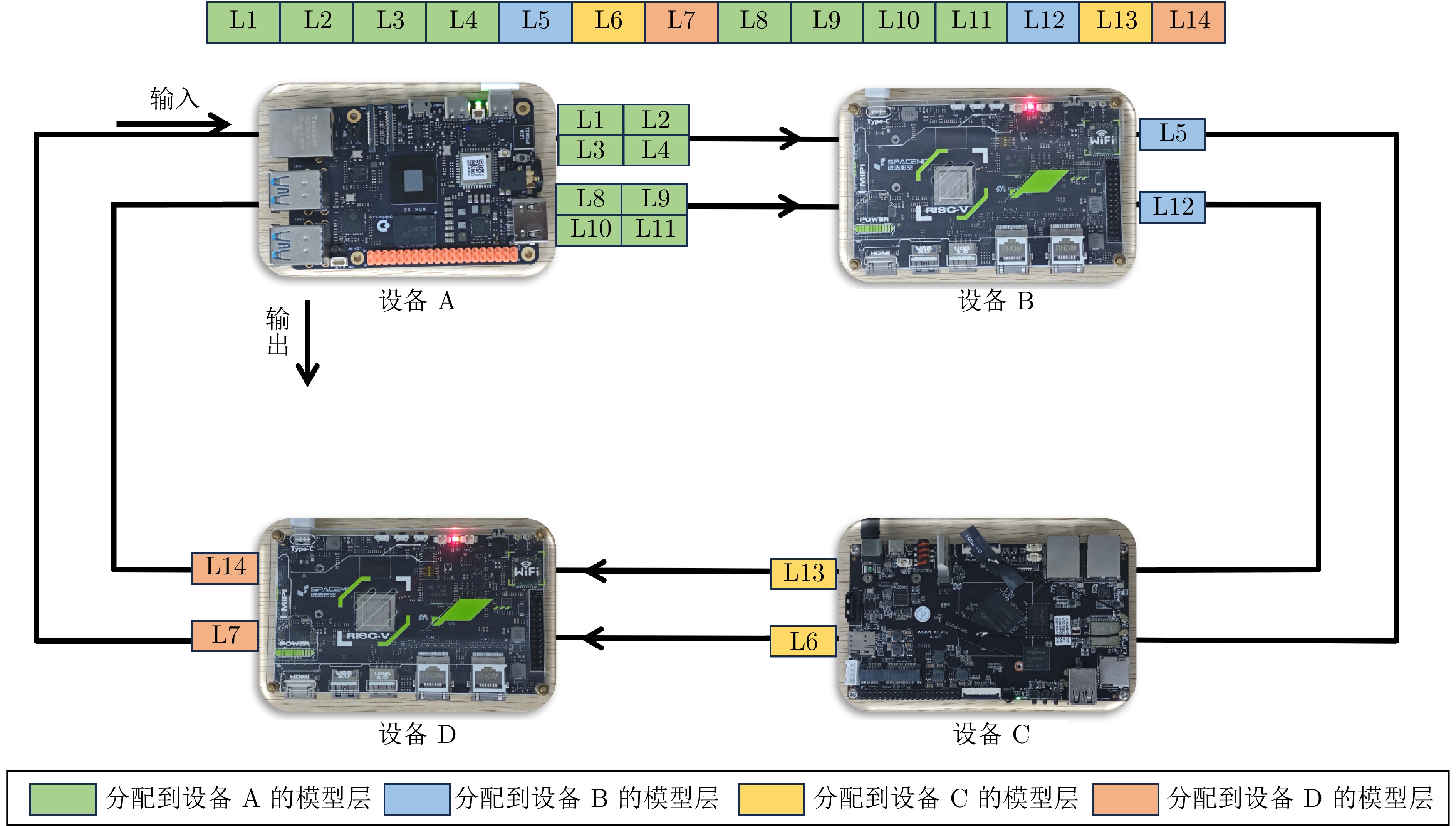
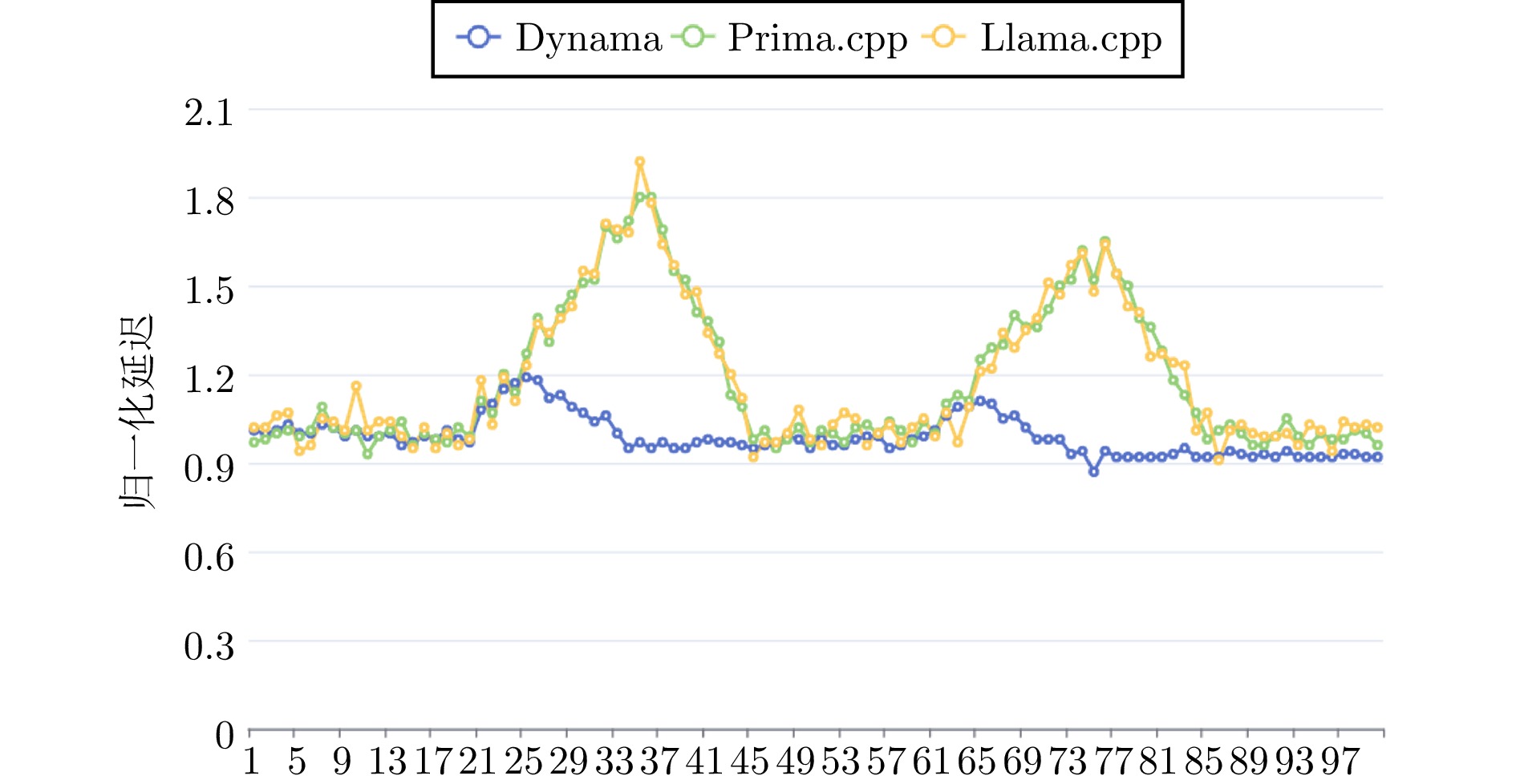
图 4 异构设备集群的大模型模拟推理
Fig. 4 Large model inference simulation in heterogeneous device clusters
表 1 不同触发阈值下的性能
Table 1 Performance at different trigger thresholds
阈值τ TPOT (ms) 较τ = 15%变化 ΔPPL 10% 682.6 +12.9% 1.68% 12% 655.9 +8.6% 1.93% 15% 604.2 ±0% 2.11% 18% 662.9 +9.7% 2.37% 20% 694.8 +14.9% 2.41%  下载: 导出CSV
下载: 导出CSV
表 2 不同方法能耗对比
Table 2 Energy consumption comparison of different methods
模型 平均每token消耗能量(J/token) llama.cpp prima.cpp Dynama Qwen2.5-0.5B 2.61 2.81 3.14 Qwen2.5-1.5B 7.57 7.98 8.52
下载: 导出CSV
表 3 不同方法下每个设备的内存使用率(%)
Table 3 Memory usage percentage of each device under different methods (%)
模型 llama.cpp prima.cpp Dynama 设备A 设备A 设备B 设备C 设备D 设备A 设备B 设备C 设备D Qwen2.5-0.5B 23.2 3.7 3.3 2.4 3.3 3.2 2.7 2.5 2.8 Qwen2.5-1.5B 48.4 10.7 9.5 7.1 9.4 9.6 8.9 7.6 8.8 Qwen2.5-3B 73.1 21.4 19.1 14.3 19.2 19.4 16.2 12.3 16.3 Qwen2.5-7B 92.9 49.5 44.3 31.2 44.2 42.5 39.2 30.4 39.2 Llama3.2-1B 42.5 7.3 6.8 5.2 6.9 6.4 5.7 5.2 5.7 Llama3.2-3B 70.3 20.2 18.5 14.2 18.4 19.2 16.8 12.7 16.7 DeepSeek-1.5B 49.7 10.4 9.4 7.9 9.4 9.2 8.5 7.3 8.5 DeepSeek-7B 95.3 50.5 47.2 35.3 47.3 43.7 40.2 31.5 40.1
下载: 导出CSV
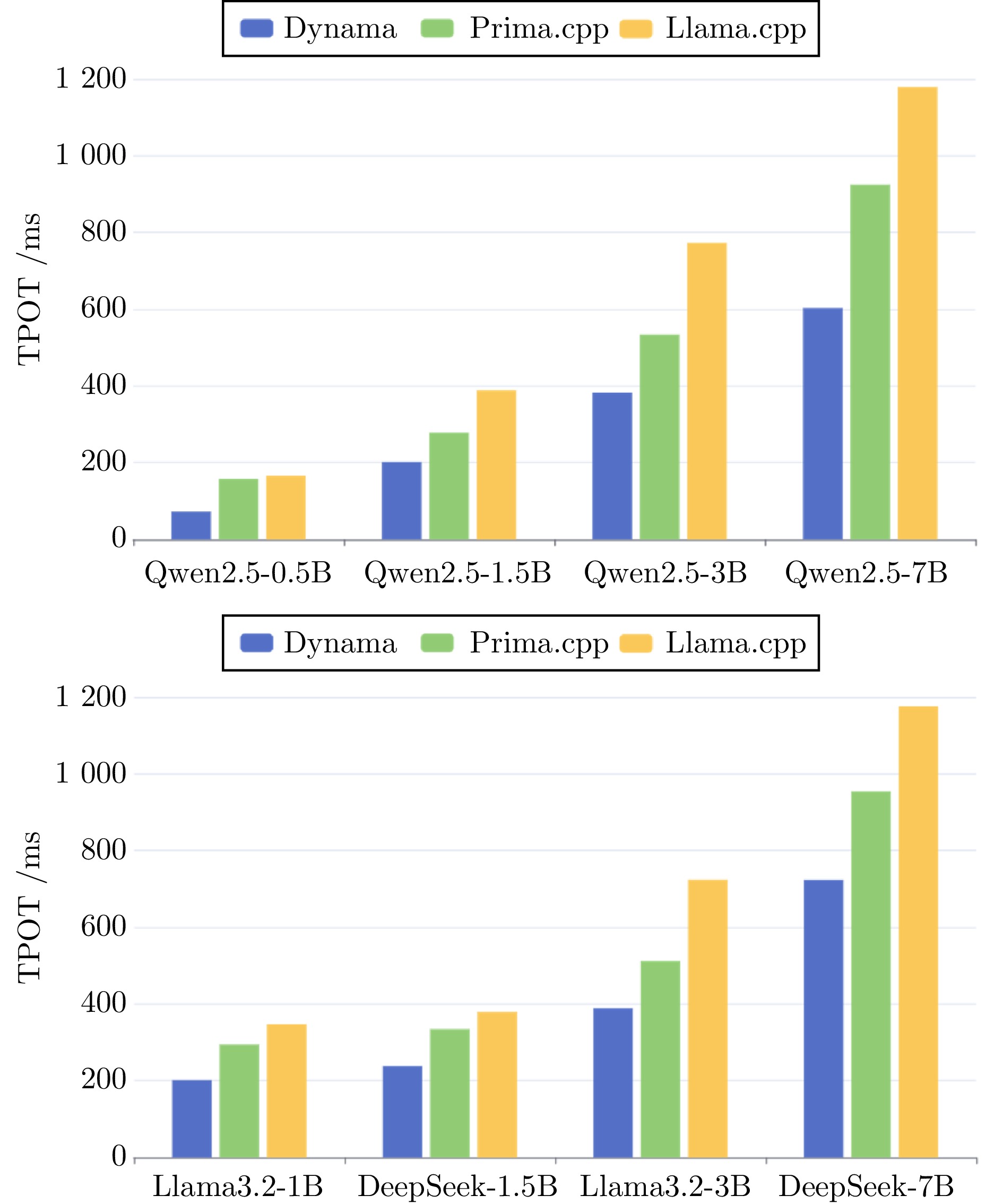
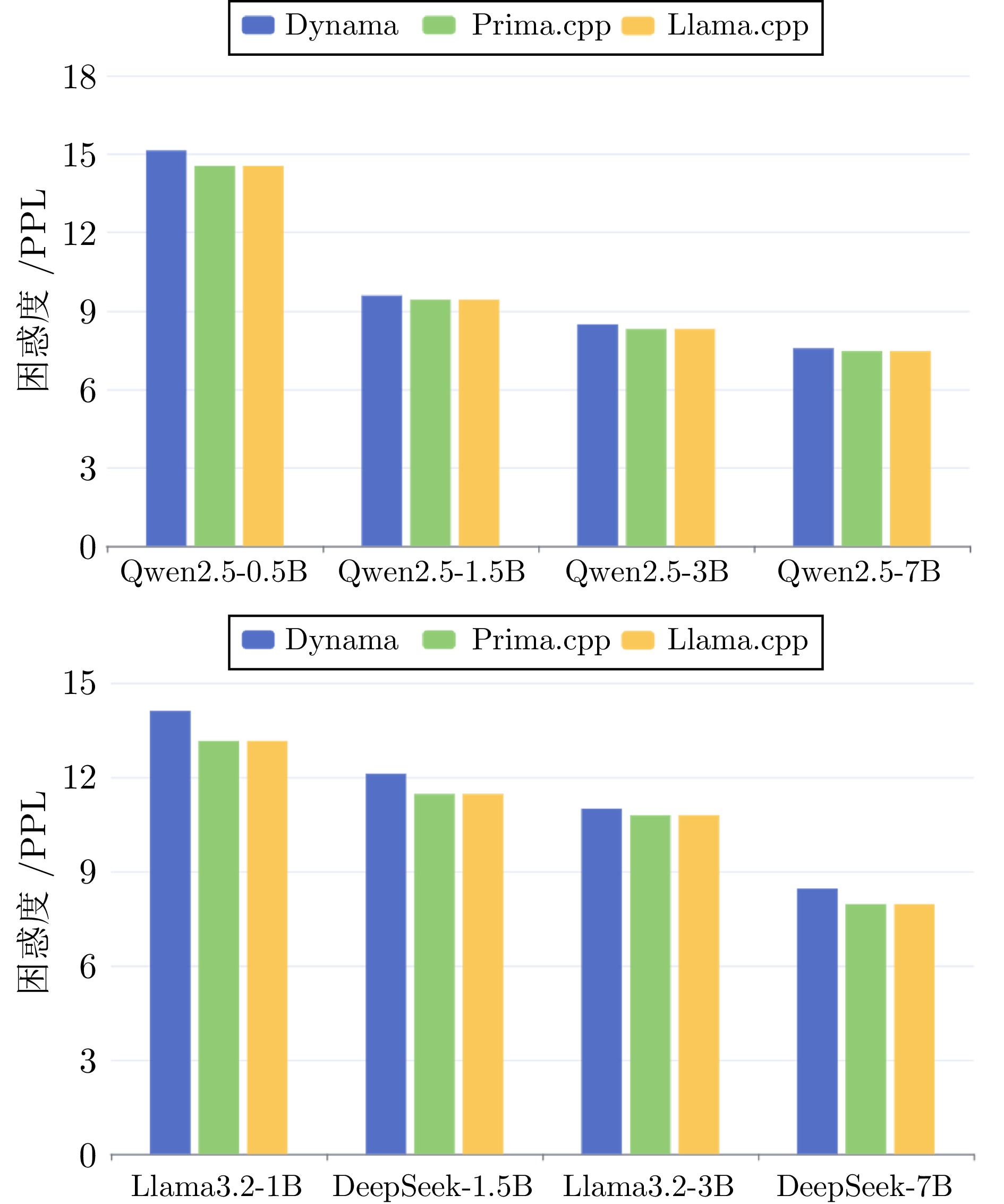
表 4 推理测试数据汇总
Table 4 Summary of reasoning test data
模型 Dynama (TPOT) prima.cpp (TPOT) llama.cpp (TPOT) Dynama (PPL) prima.cpp (PPL) Qwen2.5-0.5B 72.33 157.71 166.26 15.133 14.541 Qwen2.5-1.5B 202.01 278.19 388.75 9.591 9.434 Qwen2.5-3B 382.90 534.15 773.15 8.495 8.312 Qwen2.5-7B 603.14 924.67 1179.32 7.577 7.471 Llama3.2-1B 203.19 294.23 346.87 14.104 13.155 Llama3.2-3B 388.89 511.95 723.83 10.995 10.787 DeepSeek-1.5B 237.96 334.57 379.16 12.106 11.458 DeepSeek-7B 723.49 954.13 1175.29 8.451 7.954
下载: 导出CSV
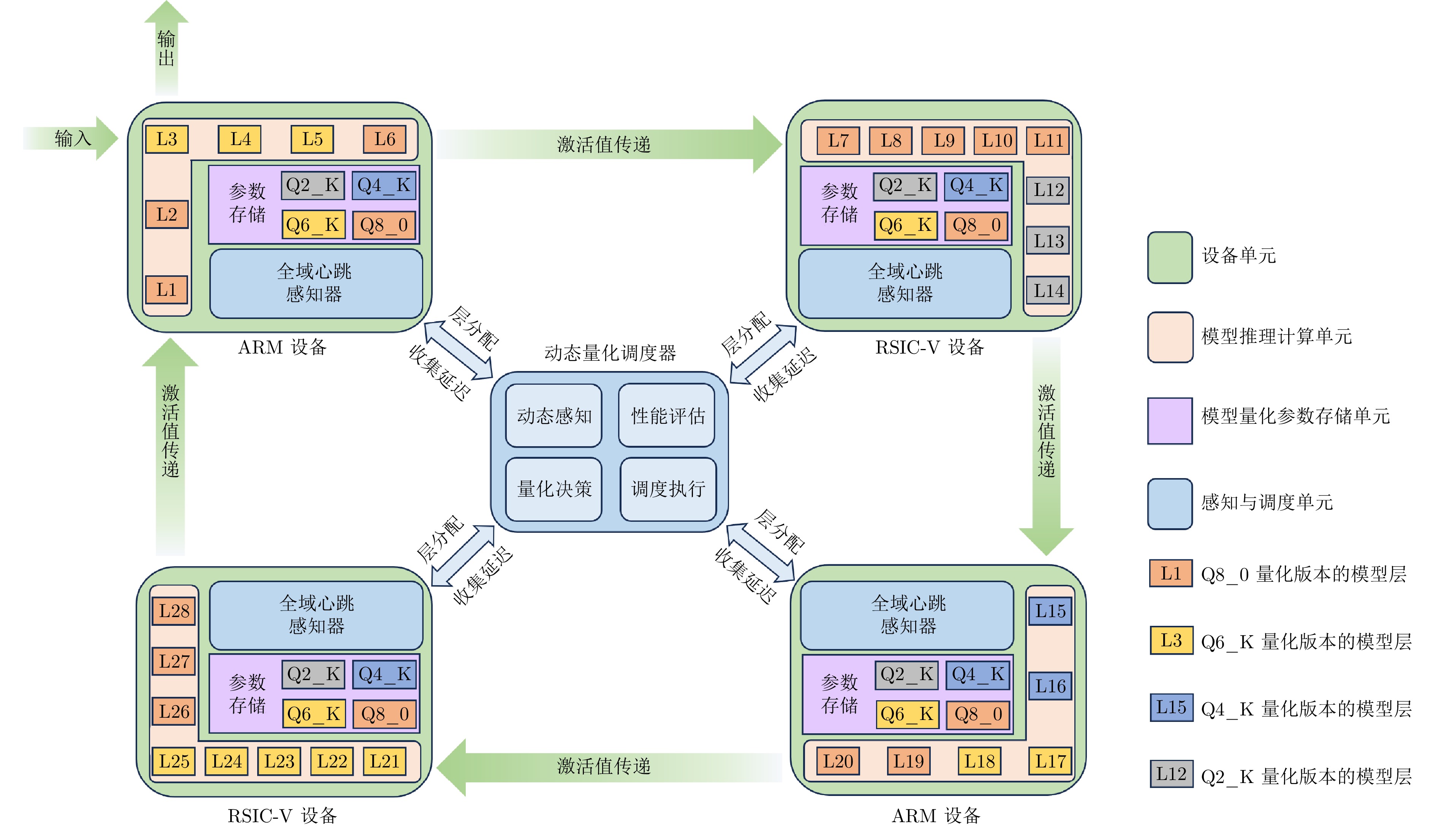
符号 说明 I 集群中的设备总数 $ d_i $ 第i个设备($ i=1,\; \cdots,\; I $) L 模型总层数 l 模型层索引 $ L_i $ 设备$ d_i $处理的层数 $ w_i $ 分配给设备$ d_i $的窗口大小 $ n_i $ GPU中计算的层数 $ {\cal{Q}} $ 量化版本集合 $ q_l $ 模型第l层的量化版本 $ {\boldsymbol{q}} $ 量化版本决策向量 N token总数 $ t_i $ 第i个token K 迭代次数 $ \mathbb{I} $ 指示函数 τ 触发阈值 $ T_{{\rm{token}}} $ 端到端生成延迟 $ \alpha_i $ 计算延迟 $ \beta_i $ 通信延迟 $ \gamma_i $ 磁盘加载延迟 $ \delta_i $ 内存访问延迟 κ 常数项 $ f_q^i $ 每层FLOPs $ f_{q,\; \,\; {\rm{out}}}^{i} $ 输出层FLOPs $ s_{{\rm{cpu}},\; \,\; q}^i $ CPU实时吞吐量 $ s_{{\rm{gpu}},\; \,\; q}^i $ GPU实时吞吐量 $ s_{{\rm{disk}}_{i}} $ 磁盘读取速度 $ r_{{\rm{ram}}_{i}} $ RAM读取速度 $ r_{{\rm{vram}}_{i}} $ VRAM读取速度 $ \nu_i $ 有效网络延迟系数 $ \mu_i $ 固定网络延迟 $ p_f^i $ 实时页面故障率 $ a_s $ 单轮激活张量大小 $ b_{{\rm{ser}}} $ 序列化开销 $ b_{{\rm{buffer}}} $ 缓冲区开销 $ b_{{\rm{lio}}} $ 层间I/O基线 $ b / V $ 额外I/O开销 $ L_i^{{\rm{gpu}}} $ GPU计算层数 $ w_i^* $ 静态层窗口大小 $ \eta_q $ 量化缩放因子 $ \zeta_q $ 量化压缩因子 $ \rho_q $ 量化压缩比率 $ \phi_i $ 内存访问频率因子 $ \psi_i $ 页面故障惩罚系数 $ \xi_i $ I/O调整因子 $ P_{\max} $ 困惑度预算阈值 $ \Delta P_{l} $ 困惑度增量 $ \Theta_i $ 磁盘加载数据大小 $ M_l(q_l) $ 每层内存占用 $ M_{{\rm{avail}}_{i}} $ 可用内存 $ c_{{\rm{cpu}}} $ CPU缓存大小 $ o_{{\rm{ram}},\; \,\; q}^i $ 每层RAM占用 $ o_{{\rm{vram}},\; \,\; q}^i $ 每层VRAM占用 $ h_k、h_v $ 注意力头数量 $ e_k、e_v $ 嵌入大小 $ n_{{\rm{kv}}} $ KV缓存数量
下载: 导出CSV
-
[1] 王文晟, 谭宁, 黄凯, 张雨浓, 郑伟诗, 孙富春. 基于大模型的具身智能系统综述. 自动化学报, 2025, 51(1): 1−19 doi: 10.16383/j.aas.c240542Wang W S, Tan N, Huang K, Zhang Y N, Zheng W S, Sun F C. Embodied intelligence systems based on large models: A survey. Acta Automatica Sinica, 2025, 51(1): 1−19 doi: 10.16383/j.aas.c240542 [2] Lin Z, Qu G Q, Chen Q Y, Chen X H, Chen Z, Huang K. Pushing Large Language Models to the 6G Edge: Vision, Challenges, and Opportunities. IEEE Communications Magazine, 2025, 63(9): 52−59 doi: 10.1109/MCOM.001.2400764 [3] Shen Y F, Shao J W, Zhang X J, Lin Z H, Pan H, Li D S, et al. Large language models empowered autonomous edge AI for connected intelligence. IEEE Communications Magazine, 2024, 62(10): 140−146 doi: 10.1109/MCOM.001.2300550 [4] 任磊, 王海腾, 董家宝, 贾子翟, 李世祥, 王宇清, 等. 工业大模型: 体系架构、关键技术与典型应用. 中国科学: 信息科学, 2024, 54(11): 2606−2622 doi: 10.1360/SSI-2024-0185Lei REN, Haiteng WANG, Jiabao DONG, Zizhai JIA, Shixiang LI, Yuqing WANG, et al. Industrial foundation model: architecture, key technologies, and typical applications. Sci Sin Inform, 2024, 54(11): 2606−2622 doi: 10.1360/SSI-2024-0185 [5] 侯卫锋, 古绍武, 张志铭, 谢磊, 苏宏业. 工业大模型赋能的新型流程工业智能工厂核心工业软件体系. 中国科学: 信息科学, 2025, 55(7): 1783−1800 doi: 10.1360/SSI-2025-0109Weifeng HOU, Shaowu GU, Zhiming ZHANG, Lei XIE, Hongye SU. Core industrial software system of the new process industrial intelligent factory enabled by the industrial large model. Sci Sin Inform, 2025, 55(7): 1783−1800 doi: 10.1360/SSI-2025-0109 [6] 任磊, 董家宝, 曾宪超, 王宇清, 杨凌远, 赖李媛君, 等. 数字族谱: 驱动工业具身智能世界模型. 中国科学: 信息科学, 2025, 55(7): 1748−1765 doi: 10.1360/SSI-2025-0093Lei REN, Jiabao DONG, Xianchao ZENG, Yuqing WANG, Lingyuan YANG, Liyuan JIE, et al. Digital genealogy: empowering industrial embodied intelligence world model. Sci Sin Inform, 2025, 55(7): 1748−1765 doi: 10.1360/SSI-2025-0093 [7] 缪青海, 王兴霞, 杨静, 赵勇, 王雨桐, 陈圆圆, 等. 从基础智能到通用智能: 基于大模型的GenAI和AGI之现状与展望. 自动化学报, 2024, 50(4): 674−687 doi: 10.16383/j.aas.c240156Miao Q H, Wang X X, Yang J, Zhao Y, Wang Y T, Chen Y Y, et al. From foundation intelligence to general intelligence: The state-of-art and perspectives of GenAI and AGI based on foundation models. Acta Automatica Sinica, 2024, 50(4): 674−687 doi: 10.16383/j.aas.c240156 [8] 秦龙, 武万森, 刘丹, 胡越, 尹全军, 阳东升, 等. 基于大语言模型的复杂任务自主规划处理框架. 自动化学报, 2024, 50(4): 862−872 doi: 10.16383/j.aas.c240088Qin Long, Wu Wan-Sen, Liu Dan, Hu Yue, Yin Quan-Jun, Yang Dong-Sheng, et al. Autonomous planning and processing framework for complex tasks based on large language models. Acta Automatica Sinica, 2024, 50(4): 862−872 doi: 10.16383/j.aas.c240088 [9] 孙长银, 袁心, 王远大, 柳文章. 具身智能自主无人系统技术. 自动化学报, 2025, 51(4): 762−777 doi: 10.16383/j.aas.c240456Sun Chang-Yin, Yuan Xin, Wang Yuan-Da, Liu Wen-Zhang. Embodied intelligence autonomous unmanned systems technology. Acta Automatica Sinica, 2025, 51(4): 762−777 doi: 10.16383/j.aas.c240456 [10] Zhang L, Cheng W, Zhang S, Xing J, Nie Z L, Chen X F, Lan D P, et al. How large AI model empowers time-series forecasting for the operation and maintenance of industrial automation system?. IEEE Transactions on Industrial Informatics, 2025, 21(11): 8201−8213 doi: 10.1109/TⅡ.2025.3575118 [11] Kompally V S. A Review of Large Language Models in Edge Computing: Applications, Challenges, Benefits, and Deployment Strategies. International Journal of Data Science and Machine Learning, 2025, 5(1): 300−322 doi: 10.55640/ijdsml-05-01-25 [12] Gkonis P, Giannopoulos A, Trakadas P, Masip-Bruin X, D'Andria F. A survey on IoT-edge-cloud continuum systems: Status, challenges, use cases, and open issues. Future Internet, 2023, 15(12): 383 doi: 10.3390/fi15120383 [13] Munkhdalai T, Faruqui M, Gopal S. Leave no context behind: Efficient infinite context transformers with infini-attention. arXiv preprint arXiv: 2404.07143, 2024: 101 [14] Jin Chao, Zhang Zili, Jiang Xuanlin, Liu Fangyue, Liu Shufan, Liu Xuanzhe, et al. RAGCache: Efficient knowledge caching for retrieval-augmented generation. ACM Trans Comput Syst, 2025, 44(1): 2 doi: 10.1145/3768628 [15] Prabhu R, Nayak A, Mohan J, Ramjee R, Panwar A. vAttention: Dynamic memory management for serving LLMs without PagedAttention. Proceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 1, 20251133−1150 doi: 10.1145/3669940.3707256 [16] Sun Y T, Dong L, Zhu Y, Huang S H, Wang W H, Ma S M, Zhang Q L, et al. You only cache once: Decoder-decoder architectures for language models. The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. [17] Lee W, Lee J, Seo J, Sim J. InfiniGen: Efficient generative inference of large language models with dynamic KV cache management. 18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24), 2024155−172 [18] Jiang H Q, Li Y C, Zhang C R D, Wu Q H, Luo X F, Ahn S, et al. MInference 1.0: Accelerating pre-filling for long-context LLMs via dynamic sparse attention. Advances in Neural Information Processing Systems, 2024, 37(52481): 52515 doi: 10.52202/079017-1663 [19] Kamath A K, Prabhu R, Mohan J, Peter S, Ramjee R, Panwar A. POD-Attention: Unlocking full prefill-decode overlap for faster LLM inference. Proceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2, 2025897−912 doi: 10.1145/3676641.3715996 [20] Hong K, Dai G H, Xu J M, Mao Q L, Li X H, Liu J, et al. FlashDecoding++: Faster large language model inference with asynchronization, flat GEMM optimization, and heuristics. Proceedings of Machine Learning and Systems, 2024, 6: 148−161 [21] Zhang H L, Ji X D, Chen Y L, Fu F C, Miao X P, Nie X N, et al. PQCache: Product quantization-based KVCache for long context LLM inference. Proceedings of the ACM on Management of Data, 2025, 3(3): 201 doi: 10.1145/3725338 [22] Wu B Y, Liu S Y, Zhong Y M, Sun P, Liu X Z, Jin X. LoongServe: Efficiently serving long-context large language models with elastic sequence parallelism. Proceedings of the ACM SIGOPS 30th Symposium on Operating Systems Principles, 2024640−654 doi: 10.1145/3694715.3695948 [23] Tao W, Zhang B, Qu X Y, Wan J G, Wang J Z. Cocktail: Chunk-adaptive mixed-precision quantization for long-context LLM inference. 2025 Design, Automation & Test in Europe Conference (DATE), 20251−7 doi: 10.23919/DATE64628.2025.10992912 [24] Qin R Y, Li Z H, He W R, Cui J L, Ren F, Zhang M X, et al. Mooncake: Trading more storage for less computation − A KVCache-centric architecture for serving LLM chatbot. 23rd USENIX Conference on File and Storage Technologies (FAST 25), 2025155−170 [25] Abhyankar R, He Z J, Srivatsa V, Zhang H, Zhang Y Y. InferCept: Efficient intercept support for augmented large language model inference. Forty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024, 2024. [26] Song W, Jayanthi S M, Ronanki S, Sathyendra K M, Shin J, Galstyan A, et al. Compress, Gather, and Recompute: REFORMing Long-Context Processing in Transformers. arXiv preprint arXiv: 2506.01215, 2025 [27] Choi D, Oh S, Dingliwal S, Tack J, Kim K, Song W, et al. Mamba Drafters for Speculative Decoding. arXiv preprint arXiv: 2506.01206, 2025 [28] 陈致蓬, 韩杰, 阳春华, 桂卫华. 工业垂域具身智控大模型构建新范式探索. 自动化学报, 2025, 51(11): 1−19 doi: 10.16383/j.aas.c250247Chen Zhi-Peng, Han Jie, Yang Chun-Hua, Gui Wei-Hua. An exploration of a new paradigm for constructing industrial domain-specific embodied intelligent control large models. Acta Automatica Sinica, 2025, 51(11): 1−19 doi: 10.16383/j.aas.c250247 [29] 周鸿祎, 黄绍莽, 潘剑锋, 彭敏, 郑涵中. 一种紧凑的多专家协同大语言模型框架. 计算, 2025, 1(2): 40−48 doi: 10.11991/cccf.202506007Zhou Hongyi, Huang Shaomang, Pan Jianfeng, Peng Min, Zheng Han-Zhong. A compact large language models with collaboration of experts. Computing Magazine of the CCF, 2025, 1(2): 40−48 doi: 10.11991/cccf.202506007 [30] Oh H, Kim K, Kim J, Kim S, Lee J, Chang D, et al. ExeGPT: Constraint-aware resource scheduling for LLM inference. Proceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2, 2024369−384 doi: 10.1145/3620665.3640383 [31] Mitzenmacher M, Shahout R. Queueing, Predictions, and Large Language Models: Challenges and Open Problems. Stochastic Systems, 2025, 15(3): 195−219 doi: 10.1287/stsy.2025.0106 [32] Kwon W, Li Z H, Zhuang S Y, Sheng Y, Zheng L M, Yu C H, et al. Efficient memory management for large language model serving with PagedAttention. Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023611−626 doi: 10.1145/3600006.3613165 [33] Wan Z W, Wu X J, Zhang Y, Xin Y, Tao C F, Zhu Z H, et al. D2O: Dynamic discriminative operations for efficient long-context inference of large language models. The Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025, 2025. [34] Zhang Z Y, Sheng Y, Zhou T Y, Chen T L, Zheng L M, Cai R S, et al. H2O: Heavy-hitter oracle for efficient generative inference of large language models. Advances in Neural Information Processing Systems, 2023, 36: 34661−34710 [35] Xiang W, Li Y K, Ren Y Q, Jiang F, Xin C H, Gupta V, et al. Gö del: Unified large-scale resource management and scheduling at ByteDance. Proceedings of the 2023 ACM Symposium on Cloud Computing, 2023308−323 doi: 10.1145/3620678.3624663 [36] Zheng Z, Pan Z F, Wang D L, Zhu K, Zhao W Y, Guo T Y, et al. BladeDISC: Optimizing dynamic shape machine learning workloads via compiler approach. Proceedings of the ACM on Management of Data, 2023, 1(3): 206 doi: 10.1145/3617327 [37] Nie X N, Miao X P, Wang Z L, Yang Z C, Xue J L, Ma L X, et al. FlexMoE: Scaling large-scale sparse pre-trained model training via dynamic device placement. Proceedings of the ACM on Management of Data, 2023, 1(1): 110 doi: 10.1145/3588964 [38] Picano B, Hoang D T, Nguyen D N. A matching game for LLM layer deployment in heterogeneous edge networks. IEEE Open Journal of the Communications Society, 2025, 6: 3795−3805 doi: 10.1109/OJCOMS.2025.3561605 [39] Zhang M J, Shen X M, Cao J N, Cui Z Y, Jiang S. EdgeShard: Efficient LLM inference via collaborative edge computing. IEEE Internet of Things Journal, 2025, 12(10): 13119−13131 doi: 10.1109/JIOT.2024.3524255 [40] Huang M Q, Shen A, Li K, Peng H X, Li B Y, Yu H. EdgeLLM: A highly efficient CPU-FPGA heterogeneous edge accelerator for large language models. arXiv preprint arXiv: 2407.21325, 2024. doi: 10.48550/ARXIV.2407.21325 [41] Li C, Yin Y H, Wu X T, Zhu J C, Gao Z T Y, Niu D M, et al. H2-LLM: Hardware-dataflow co-exploration for heterogeneous hybrid-bonding-based low-batch LLM inference. Proceedings of the 52nd Annual International Symposium on Computer Architecture, 2025194−210 doi: 10.1145/3695053.3731008 [42] 李仁刚, 唐轶男, 郭振华, 王丽, 宗瓒, 杨广文. 大规模异构一致性融合计算系统的性能建模与优化. 计算机研究与发展, 2025, 62(6): 1363−1379 doi: 10.7544/issn1000-1239.202550120Li R G, Tang Y N, Guo Z H, Wang L, Zong Z, Yang G W. Performance Modeling and Optimization for Large-Scale Heterogeneous Consistency Integrated Computing System. Journal of Computer Research and Development, 2025, 62(6): 1363−1379 doi: 10.7544/issn1000-1239.202550120 [43] Hu J Y, Liang Y S, Chen Y P, Liu G, Chen W W, Duan L X. Performance optimization of split federated learning in heterogeneous edge computing environments. IEEE Transactions on Industrial Informatics, 20251−11 doi: 10.1109/TII.2025.3609069 [44] Xia L Q, Hu Y X, Pang J Z, Zhang X Y, Liu C. Leveraging large language models to empower Bayesian networks for reliable human-robot collaborative disassembly sequence planning in remanufacturing. IEEE Transactions on Industrial Informatics, 2025, 21(4): 3117−3126 doi: 10.1109/TII.2024.3523551 [45] Li Z H, Li T, Feng W, Xiao R X, She J S, Huang H, et al. PRIMA. CPP: Speeding Up 70B-Scale LLM Inference on Low-Resource Everyday Home Clusters. arXiv preprint arXiv: 2504.08791, 2025 [46] Frantar E, Ashkboos S, Hoefler T, Alistarh D. GPTQ: Accurate post-training quantization for generative pre-trained transformers. Proceedings of the 11th International Conference on Learning Representations, 2023. [47] Li X, Xing Z Y, Li Y M, Qu L P, Zhen H L, Yao Y W, et al. KVTuner: Sensitivity-aware layer-wise mixed-precision KV cache quantization for efficient and nearly lossless LLM inference. Proceedings of the 42nd International Conference on Machine Learning, 2025, 267: 36451−36485 -

 下载:
下载:

计量
- 文章访问数: 897
- HTML全文浏览量: 1369
- 被引次数: 0
