

-
摘要: 视觉−语言−动作(VLA)模型作为具身智能发展的核心方向, 旨在构建统一的多模态表示与感知–决策–执行一体化架构, 以突破传统模块化系统在功能割裂、语义对齐不足及泛化能力有限等方面的瓶颈. 本文系统回顾前VLA时代的技术积淀, 梳理模块化、端到端和混合三类主流建模范式, 分析其结构特点、能力优势与面临的关键挑战. 在此基础上, 总结当前代表性VLA模型的体系结构、训练机制、多模态融合策略及应用成效, 并对典型数据集与评测基准进行分类比较. 最后, 结合跨模态协同、知识注入、长时序规划与真实环境泛化等方面, 展望未来VLA模型的发展趋势与研究方向.
-
关键词:
- 具身智能 /
- 视觉–语言–动作模型 /
- 多模态融合 /
- 端到端学习 /
- 任务泛化
Abstract: The Vision-Language-Action (VLA) model, as a core direction in the development of embodied intelligence, aims to construct a unified multimodal representation and an integrated perception-decision-execution architecture, in order to overcome the bottlenecks of traditional modular systems, such as functional fragmentation, insufficient semantic alignment and limited generalization capability. This paper systematically reviews the technical foundations laid in the pre-VLA era, outlining three mainstream modeling paradigms: Modular, end-to-end and hybrid, and analyzing their structural characteristics, capability advantages and key challenges. On this basis, it summarizes the architectures, training mechanisms, multimodal fusion strategies, and application outcomes of current representative VLA models, while providing a categorized comparison of typical datasets and evaluation benchmarks. Finally, the paper envisions future trends and research directions for VLA models, focusing on cross-modal collaboration, knowledge injection, long-term planning and generalization in real-world environments. -
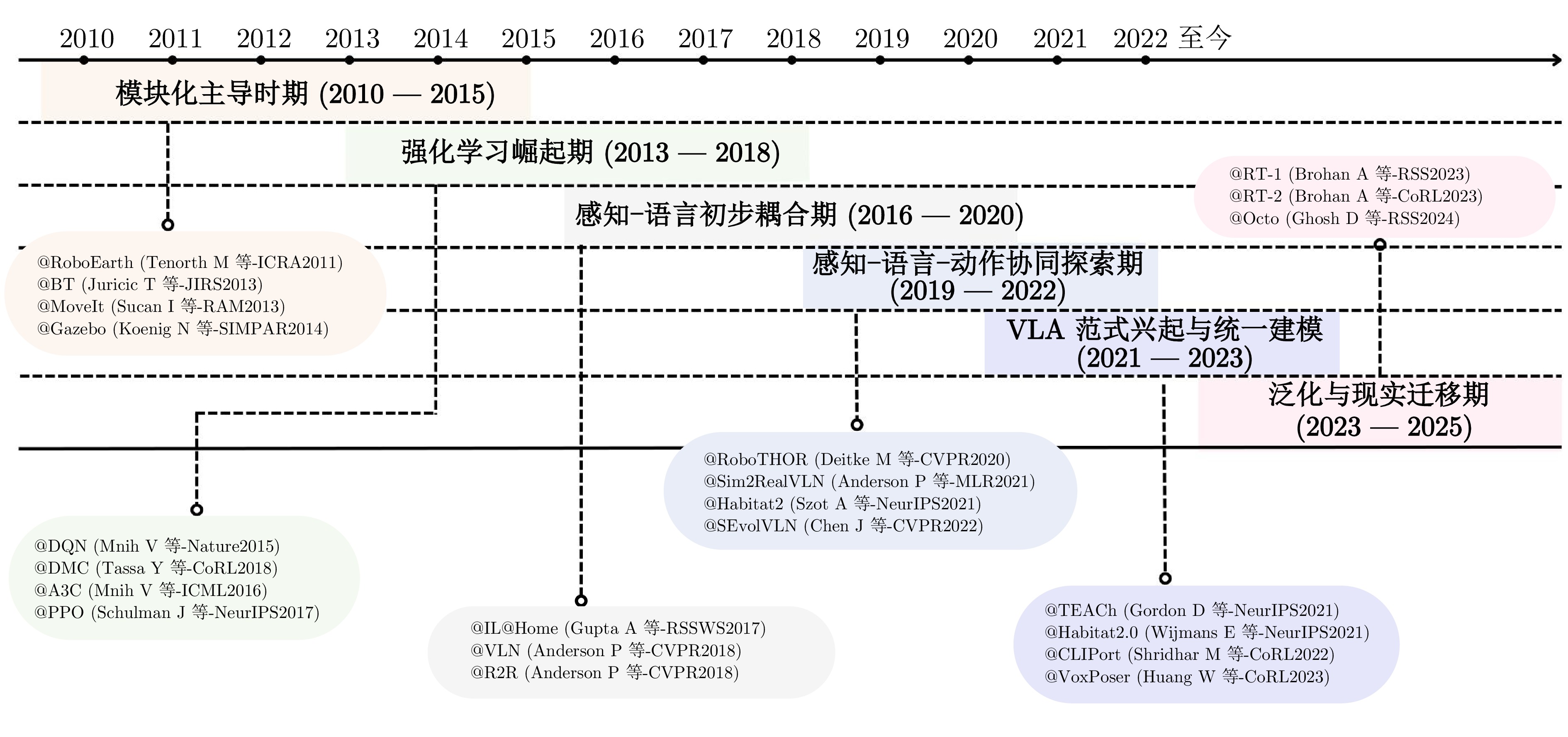
图 1 具身智能的技术演进路径示意图
Fig. 1 Illustration of technological evolution path of embodied intelligence
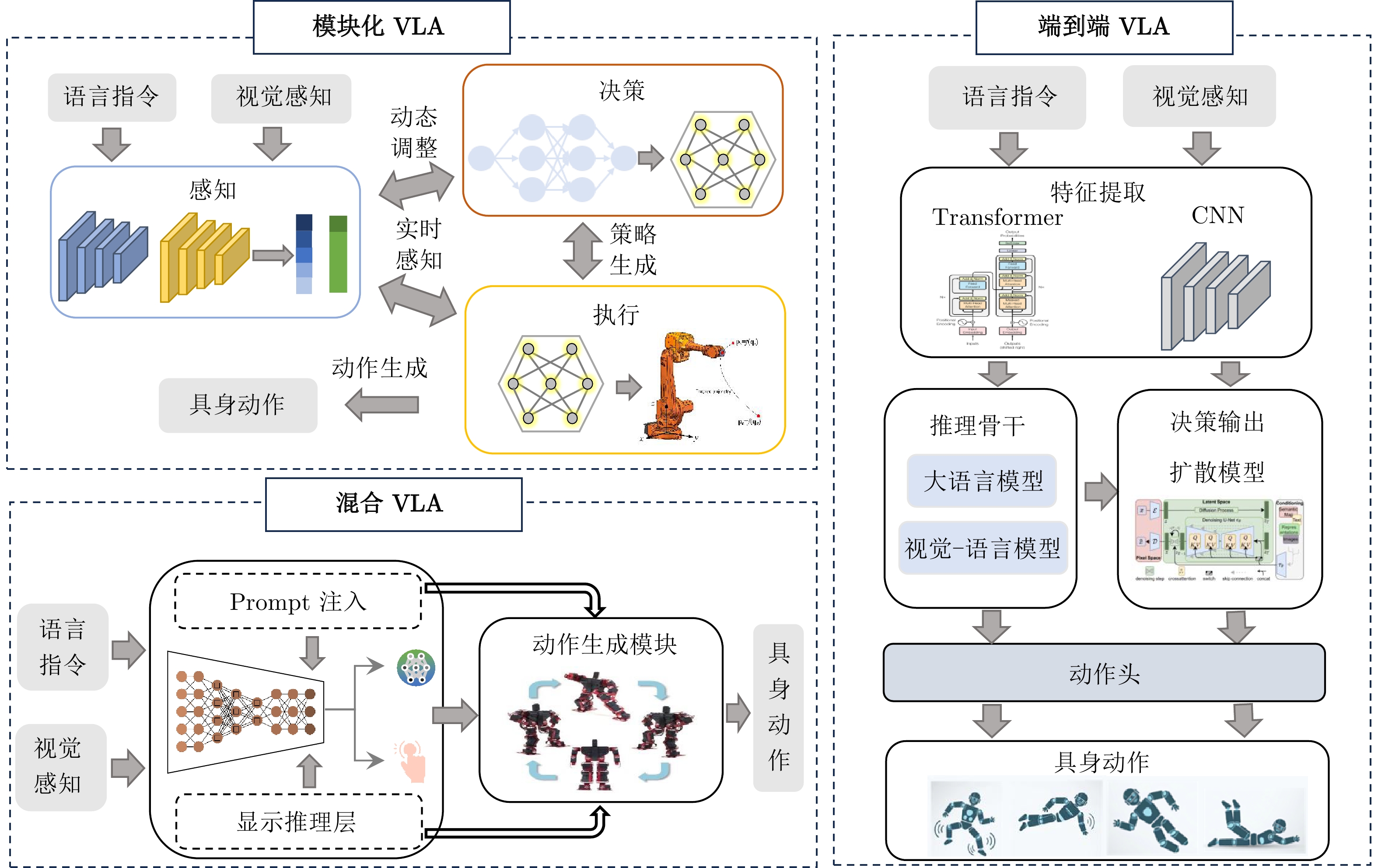
图 3 VLA架构分类: 模块化VLA、端到端VLA和混合VLA
Fig. 3 VLA architecture classification: Modular VLA, end-to-end VLA and hybrid VLA
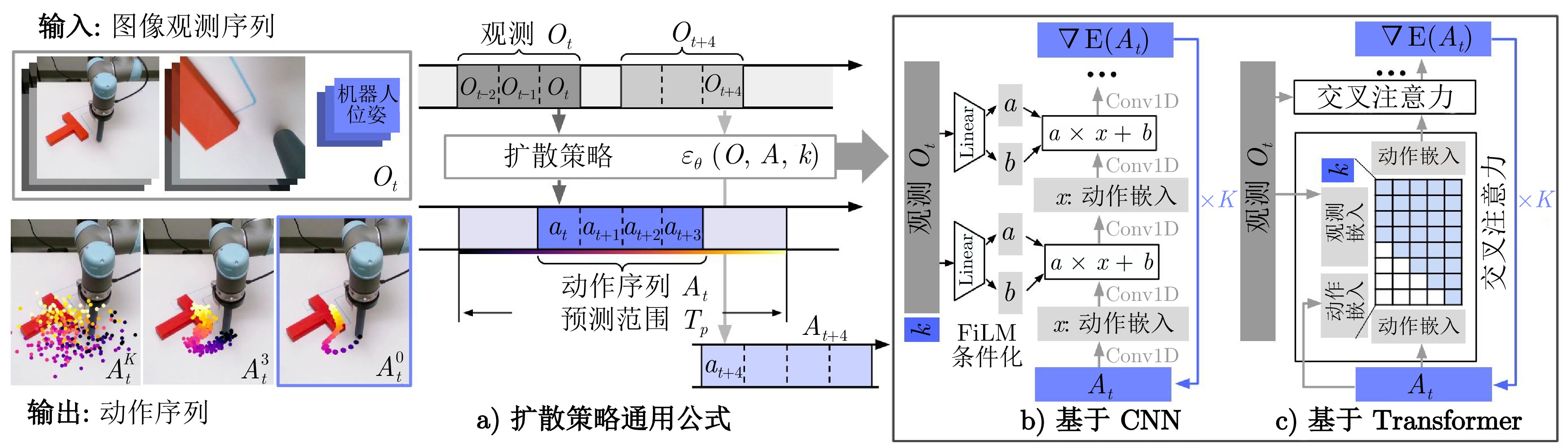
图 7 基于扩散模型的Diffusion policy框架
Fig. 7 Diffusion policy architecture based on diffusion model
表 1 强化学习与模仿学习算法在具身智能中的应用特性对比
Table 1 Application characteristic comparison of reinforcement learning and imitation learning algorithms in embodied intelligence
算法 类型 核心机制 优势 局限性 DQN[25] 强化学习 Q值函数学习$+ $$\varepsilon {\text{-}} $贪心策略 结构清晰, 适用于离散动作控制 难扩展至连续控制, 样本效率较低 PPO[26] 强化学习 策略梯度$+ $概率剪切(Clipping) 收敛稳定, 鲁棒性好, 应用广泛 超参数敏感, 收敛速度较慢 SAC[27] 强化学习 最大熵策略$+ $双策略结构 支持连续控制, 收敛较快, 探索充分 结构复杂, 调参成本高 TD3[32] 强化学习 双 Q 网络$+ $策略平滑 缓解过估计, 训练稳定性强 计算开销较大, 超参数较多 A3C[33] 强化学习 多线程异步 Actor-Critic 高效并行, 能适应大规模任务 收敛不稳定, 梯度噪声较大 BC[34] 模仿学习 监督式模仿专家演示 简单高效, 适合小样本场景, 训练稳定 泛化较弱, 对专家数据质量依赖高 Dagger[30] 模仿学习 专家纠正$+ $迭代数据聚合 缓解分布偏移, 性能稳健 需专家频繁参与, 代价较高  下载: 导出CSV
下载: 导出CSV
表 2 模块化、端到端与混合范式 VLA 模型结构对比分析
Table 2 Comparison analysis of modular, end-to-end and hybrid VLA model architectures
模型类型 系统结构特点 训练方式 优势 局限性 模块化结构 多子模块解耦, 分阶段执行 分模块独立训练 可解释性强, 结构清晰, 支持局部优化与升级 缺乏联合优化, 信息传递割裂, 泛化能力不足 端到端结构 所有输入统一Token表示, 由Transformer整体建模 端到端整体训练 表达能力强, 适应性好, 任务复用性高 可解释性弱, 调试困难, 对数据和算力依赖大 混合结构 通过 Prompt 驱动整体流程, 在关键位置保留接口与指令控制 灵活训练方式, 可结合端到端与模块化策略 模型灵活, 可同时支持多任务与 Prompt 控制 Prompt 设计复杂, 依赖度高, 调试与维护成本大
下载: 导出CSV
表 3 典型 VLA 模型的能力与挑战
Table 3 Capability and challenge of representative VLA models
建模范式 模型 核心能力 多模态结构 技术特点 主要挑战 模块化 SayCan[9] 可行性驱动的语义规划与执行选择 LLM$+ $感知/技能库 模块边界清晰, 语义链条透明 缺少端到端联合优化, 模块耦合度高, 跨任务泛化弱 PerAct[39] 细粒度操作动作生成 点云$+ $语言$+ $低级动作 控制粒度细, 低层执行能力强 任务级语义理解不足, 全局策略规划能力弱 端到端 Gato[36] 多任务统一策略生成 图像/文本/动作统一 Token Token 级建模, 支持跨任务迁移与共享 可解释性弱, 数据需求大, 任务相互干扰 RT-2[38] 从网页知识迁移到机器人执行 文本$+ $图像$+ $动作 语言–视觉迁移强, 能支持现实任务执行 控制链复杂, 语料依赖重, 开放场景泛化待验证 PaLM-E[35] 通用多模态机器人控制 传感器/语言/图像/动作融合 端到端映射复杂输入到动作 参数规模大, 算力与部署门槛高 混合范式 VoxPoser[40] 空间约束下的任务分解与动作规划 语言$ +$图像$+ $3D空间表示 LLM生成约束, 规划可解释 依赖精确空间建模, 复杂场景鲁棒性不足 3D-VLA[41] 三维环境感知与跨模态融合 3D视觉$+ $语言$+ $动作 3D特征编码结合语言引导, 空间理解更强 3D数据获取/计算代价高, 泛化受限 Inner Monologue[42] 语言驱动的显式自我规划与修正 图像$+ $语言$+ $动作(语言推理为中间层) 通过内部语言推理提升透明度与可介入性 语言规划的一致性与稳定性有待提升
下载: 导出CSV
表 4 真实环境数据集以及仿真环境数据集
Table 4 Real-world environment datasets and simulated environment datasets
名称 收集方式 指令形式 具身平台(仿真平台) 场景数 任务数 片段数 MIME[107] 人工操作 演示 Baxter机器人 1 20 8.3 K RoboNet[108] 脚本预设 目标图像 7种机器人 10 — 162 K MT-Opt[109] 脚本预设 自然语言 7种机器人 1 12 800 K BC-Z[77] 人工操作 自然语言/演示 Everyday机器人 1 100 25.9 K RT-1_Kitchen[10] 人工操作 自然语言 Everyday机器人 2 700 + 130 K RoboSet[110] 人工/脚本 自然语言 Franka Panda机械臂 11 38 98.5 K BridgeData V2[111] 人工/脚本 自然语言 Widow X 250机械臂 24 — 60.1 K RH20T[112] 人工操作 自然语言 4种机器人 7 147 110 K + DROID[113] 人工操作 自然语言 Franka Panda机械臂 564 — 76 K OXE[114] 聚合数据集 自然语言 22种机器人 311 160000 +1 M + Static ALOHA[120] 人工操作 演示 ALOHA机器人 1 10 + 825 VIMA-Data[37]* 脚本预设 自然语言/图像 PyBullet 1 13 650 K SynGrasp-1B[116]* 仿真模拟 视觉/动作轨迹 BoDex/CuRobo — 1 —
下载: 导出CSV
表 5 四种评估方法对比
Table 5 Comparison of four evaluation methods
评估方法 简述 优点 局限 代表性工作 分阶段评估 “仿真大筛选$+ $真机小样本核验”的闭环; 真实$ \rightarrow $仿真$ \rightarrow $真实迭代收敛 低边际成本, 可控性强, 可信度较强 仿真−现实的差距可能累积; 仿真建模、对齐成本高 RialTo[132]、VR-Robo[138]、DREAM[139] 域自适应评估 显式划分源、目标域, 在给定适配预算下度量域迁移的性能 公平比较“适配速度与收益”; 贴近于实际应用 需统一协议与预算; 不同任务的跨域差异难完全对齐 Meta-RL-sim2real[140]、ADR[141]、BDA[142] 虚实协同评估 以与现实双向同步的虚拟环境做对照评测与故障注入 高度保真, 与现实一致性强; 绝对可控且安全 构建、维护虚拟环境的传感与建模成本高; 存在同步性、误差累积等问题 RoboTwin[143]、Real-is-Sim[144]、DT synchronization[145] 在线自适应评估 “测试即适配”, 在执行过程中实时监测−再适配 直接衡量反应速度、通信与计算开销等指标 安全风险较高; 实现极为复杂 MonTA[146]、RMA[147]、A-RMA[148]
下载: 导出CSV
表 6 基准测试常用评估指标名称、解释以及其适用任务
Table 6 Names, explanations and application tasks of common evaluation metrics in benchmarking testing
名称 解释 适用任务 成功率 成功完成任务比例 所有基准测试通用 路径效率加权成功率 考虑路径效率的成功率 导航任务、操作任务等 样本效率 达到目标性能所需的训练样本数 强化学习、模仿学习等 泛化得分 在未见过的环境/对象上的性能表现 跨任务、跨场景任务等 导航误差 终点与目标位置之间的距离误差 导航类任务 任务完成率 完整任务序列的完成比例 多步骤、长序列任务评估 前向迁移 学习新任务时利用已有知识的能力 多任务学习、终身学习等 后向迁移 学习新任务后对旧任务性能的影响 多任务学习、终身学习等 回合奖励 单轮任务的累计奖励值 强化学习算法 鲁棒性得分 面对噪声、扰动时的稳定性 算法可靠性评估
下载: 导出CSV
表 7 常用基准测试
Table 7 Common benchmark tests
名称 指令形式 任务描述 评估指标 CALVIN[155] 自然语言 长序列、多步骤操作 连续任务成功率、语言理解得分、长期规划 RLBench[152] 视觉引导 视觉操控 成功率、样本效率 VLN-CE[151] 自然语言 3D 环境语言导航 成功率、路径效率加权成功率、导航误差 LIBERO[156] 自然语言 终身学习 前向迁移、后向迁移、任务间相互干扰水平 Meta-World[153] 目标向量 多任务元学习 平均成功率、前向学习、后向学习 Franka Kitchen[154] 目标向量 长时程厨房操控 任务完成率、子任务完成率、鲁棒性得分 DeepMind Control[157] 连续控制 连续控制任务 回合奖励、样本效率
下载: 导出CSV
-
[1] Lake B M, Ullman T D, Tenenbaum J B, Gershman S J. Building machines that learn and think like people. Behavioral and Brain Sciences, 2017, 40: Article No. e253 doi: 10.1017/S0140525X16001837 [2] Brooks R A. Intelligence without representation. Artificial Intelligence, 1991, 47(1−3): 139−159 doi: 10.1016/0004-3702(91)90053-M [3] Shridhar M, Thomason J, Gordon D, Bisk Y, Han W, Mottaghi R, et al. ALFRED: A benchmark for interpreting grounded instructions for everyday tasks. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, USA: IEEE, 2020. 10737−10746 [4] Anderson P, Wu Q, Teney D, Bruce J, Johnson M, Sünderhauf N, et al. Vision-and-language navigation: Interpreting visually-grounded navigation instructions in real environments. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 3674−3683 [5] Artzi Y, Zettlemoyer L. Weakly supervised learning of semantic parsers for mapping instructions to actions. Transactions of the Association for Computational Linguistics, 2013, 1: 49−62 doi: 10.1162/tacl_a_00209 [6] Radford A, Kim J W, Hallacy C, Ramesh A, Goh G, Agarwal S, et al. Learning transferable visual models from natural language supervision. In: Proceedings of the 38th International Conference on Machine Learning. Virtual Event: PMLR, 2021. 8748−8763 [7] Brown T B, Mann B, Ryder N, Subbiah M, Kaplan J, Dhariwal P, et al. Language models are few-shot learners. In: Proceedings of the 34th International Conference on Neural Information Processing Systems. Vancouver, Canada: Curran Associates Inc., 2020. Article No. 159 [8] Shridhar M, Manuelli L, Fox D. CLIPort: What and where pathways for robotic manipulation. In: Proceedings of the 5th Conference on Robot Learning. London, UK: PMLR, 2022. 894−906 [9] Ichter B, Brohan A, Chebotar Y, Finn C, Hausman K, Herzog A, et al. Do as I can, not as I say: Grounding language in robotic affordances. In: Proceedings of the 6th Conference on Robot Learning. Auckland, New Zealand: PMLR, 2023. 287−318 [10] Brohan A, Brown N, Carbajal J, Chebotar Y, Dabis J, Finn C, et al. RT-1: Robotics Transformer for real-world control at scale. In: Proceedings of the 19th Robotics: Science and Systems. Daegu, Republic of Korea: Robotics: Science and Systems, 2023. [11] Chen C, Wu Y F, Yoon J, Ahn S. TransDreamer: Reinforcement learning with Transformer world models. arXiv preprint arXiv: 2202.09481, 2022. [12] Ren L, Dong J B, Liu S, Zhang L, Wang L H. Embodied intelligence toward future smart manufacturing in the era of AI foundation model. IEEE/ASME Transactions on Mechatronics, 2025, 30(4): 2632−2642 doi: 10.1109/TMECH.2024.3456250 [13] Ma Y E, Song Z X, Zhuang Y Z, Hao J Y, King I. A survey on vision-language-action models for embodied AI. arXiv preprint arXiv: 2405.14093, 2025. [14] Zhong Y F, Bai F S, Cai S F, Huang X C, Chen Z, Zhang X W, et al. A survey on vision-language-action models: An action tokenization perspective. arXiv preprint arXiv: 2507.01925, 2025. [15] Din M U, Akram W, Saoud L S, Rosell J, Hussain I. Vision language action models in robotic manipulation: A systematic review. arXiv preprint arXiv: 2507.10672, 2025. [16] Sapkota R, Cao Y, Roumeliotis K I, Karkee M. Vision-language-action models: Concepts, progress, applications and challenges. arXiv preprint arXiv: 2505.04769, 2025. [17] 王飞跃. 平行系统方法与复杂系统的管理和控制. 控制与决策, 2004, 19(5): 485−489 doi: 10.3321/j.issn:1001-0920.2004.05.002Wang Fei-Yue. Parallel system methods for management and control of complex systems. Control and Decision, 2004, 19(5): 485−489 doi: 10.3321/j.issn:1001-0920.2004.05.002 [18] 杨静, 王晓, 王雨桐, 刘忠民, 李小双, 王飞跃. 平行智能与CPSS: 三十年发展的回顾与展望. 自动化学报, 2023, 49(3): 614−634Yang Jing, Wang Xiao, Wang Yu-Tong, Liu Zhong-Min, Li Xiao-Shiang, Wang Fei-Yue. Parallel intelligence and CPSS in 30 years: An ACP approach. Acta Automatica Sinica, 2023, 49(3): 614−634 [19] Wang X X, Yang J, Liu Y H, Wang Y T, Wang F Y, Kang M Z, et al. Parallel intelligence in three decades: A historical review and future perspective on ACP and cyber-physical-social systems. Artificial Intelligence Review, 2024, 57(9): Article No. 255 doi: 10.1007/s10462-024-10861-9 [20] 李柏, 郝金第, 孙跃硕, 田永林, 黄峻, 贺正冰. 平行智能范式视角下的视觉语言动作模型发展现状与展望. 智能科学与技术学报, 2025, 7(3): 290−306Li Bai, Hao Jin-Di, Sun Yue-Shuo, Tian Yong-Lin, Huang Jun, He Zheng-Bing. Vision-language-action models under ACP paradigm: The state of the art and future perspectives. Chinese Journal of Intelligent Science and Technology, 2025, 7(3): 290−306 [21] Villaroman N, Rowe D, Swan B. Teaching natural user interaction using OpenNI and the Microsoft Kinect sensor. In: Proceedings of the Conference on Information Technology Education. West Point, USA: ACM, 2011. 227−232 [22] Chitta S. MoveIt!: An introduction. Robot Operating System (ROS): The Complete Reference (Volume 1). Cham: Springer, 2016. 3−27 [23] Tellex S, Knepper R, Li A, Rus D, Roy N. Asking for help using inverse semantics. In: Proceedings of the Robotics: Science and Systems 2014. Berkeley, USA: Robotics: Science and Systems, 2014. [24] Colledanchise M, Ögren P. Behavior trees in robotics and AI: An introduction. arXiv preprint arXiv: 1709.00084, 2017. [25] Mnih V, Kavukcuoglu K, Silver D, Rusu A A, Veness J, Bellemare M G, et al. Human-level control through deep reinforcement learning. Nature, 2015, 518(7540): 529−533 doi: 10.1038/nature14236 [26] Schulman J, Wolski F, Dhariwal P, Radford A, Klimov O. Proximal policy optimization algorithms. arXiv preprint arXiv: 1707.06347, 2017. [27] Haarnoja T, Zhou A, Abbeel P, Levine S. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. In: Proceedings of the 35th International Conference on Machine Learning. Stockholm, Sweden: PMLR, 2018. 1861−1870 [28] Hafner D, Pasukonis J, Ba J, Lillicrap T. Mastering diverse domains through world models. arXiv preprint arXiv: 2301.04104, 2023. [29] Hafner D, Lillicrap T, Fischer I, Villegas R, Ha D, Lee H, et al. Learning latent dynamics for planning from pixels. In: Proceedings of the 36th International Conference on Machine Learning. Long Beach, USA: PMLR, 2019. 2555−2565 [30] Ross S, Gordon G, Bagnell D. A reduction of imitation learning and structured prediction to no-regret online learning. In: Proceedings of the 14th International Conference on Artificial Intelligence and Statistics. Fort Lauderdale, USA: PMLR, 2011. 627−635 [31] Ouyang L, Wu J, Jiang X, Almeida D, Wainwright C L, Mishkin P, et al. Training language models to follow instructions with human feedback. In: Proceedings of the 36th International Conference on Neural Information Processing Systems. New Orleans, USA: Curran Associates Inc., 2022. Article No. 2011 [32] Fujimoto S, Hoof H, Meger D. Addressing function approximation error in actor-critic methods. In: Proceedings of the 35th International Conference on Machine Learning. Stockholm, Sweden: PMLR, 2018. 1587−1596 [33] Mnih V, Badia A P, Mirza M, Graves A, Lillicrap T, Harley T, et al. Asynchronous methods for deep reinforcement learning. In: Proceedings of the 33rd International Conference on Machine Learning. New York, USA: PMLR, 2016. 1928−1937 [34] Pomerleau D A. ALVINN: An autonomous land vehicle in a neural network. In: Proceedings of the 2nd International Conference on Neural Information Processing Systems. Denver, USA: MIT Press, 1988. 305−313 [35] Driess D, Xia F, Sajjadi M S M, Lynch C, Chowdhery A, Ichter B, et al. PaLM-E: An embodied multimodal language model. In: Proceedings of the 40th International Conference on Machine Learning. Honolulu, USA: PMLR, 2023. 8469−8488 [36] Reed S, Zolna K, Parisotto E, Colmenarejo S G, Novikov A, Barth-Maron G, et al. A generalist agent. Transactions on Machine Learning Research, 2022, 2022: 1−42 [37] Jiang Y F, Gupta A, Zhang Z C, Wang G Z, Dou Y Q, Chen Y J, et al. VIMA: General robot manipulation with multimodal prompts. arXiv preprint arXiv: 2210.03094, 2022. [38] Zitkovich B, Yu T H, Xu S C, Xu P, Xiao T, Xia F, et al. RT-2: Vision-language-action models transfer web knowledge to robotic control. In: Proceedings of the 7th Conference on Robot Learning. Atlanta, USA: PMLR, 2023. 2165−2183 [39] Shridhar M, Manuelli L, Fox D. PERCEIVER-ACTOR: A multi-task Transformer for robotic manipulation. In: Proceedings of the 6th Conference on Robot Learning. Auckland, New Zealand: PMLR, 2023. 785−799 [40] Huang W L, Wang C, Zhang R H, Li Y Z, Wu J J, Fei-Fei L. VoxPoser: Composable 3D value maps for robotic manipulation with language models. In: Proceedings of the 7th Conference on Robot Learning. Atlanta, USA: PMLR, 2023. 540−562 [41] Zhen H Y, Qiu X W, Chen P H, Yang J C, Yan X, Du Y L, et al. 3D-VLA: A 3D vision-language-action generative world model. In: Proceedings of the 41st International Conference on Machine Learning. Vienna, Austria: PMLR, 2024. 61229−61245 [42] Huang W L, Xia F, Xiao T, Chan H, Liang J, Florence P, et al. Inner monologue: Embodied reasoning through planning with language models. In: Proceedings of the 6th Conference on Robot Learning. Auckland, New Zealand: PMLR, 2023. 1769−1782 [43] Dosovitskiy A, Beyer L, Kolesnikov A, Weissenborn D, Zhai X H, Unterthiner T, et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. In: Proceedings of the 9th International Conference on Learning Representations. Virtual Event: ICLR, 2021. [44] Huang S Y, Chang H N, Liu Y H, Zhu Y M, Dong H, Boularias A, et al. A3VLM: Actionable articulation-aware vision language model. In: Proceedings of the 8th Conference on Robot Learning. Munich, Germany: PMLR, 2025. 1675−1690 [45] Oquab M, Darcet T, Moutakanni T, Vo H V, Szafraniec M, Khalidov V, et al. DINOv2: Learning robust visual features without supervision. Transactions on Machine Learning Research, 2024, 2024: 1−31 [46] Gbagbe K F, Cabrera M A, Alabbas A, Alyunes O, Lykov A, Tsetserukou D. Bi-VLA: Vision-language-action model-based system for bimanual robotic dexterous manipulations. In: Proceedings of the IEEE International Conference on Systems, Man, and Cybernetics. Kuching, Malaysia: IEEE, 2024. 2864−2869 [47] Bai J Z, Bai S, Yang S S, Wang S J, Tan S N, Wang P, et al. Qwen-VL: A versatile vision-language model for understanding, localization, text reading, and beyond. arXiv preprint arXiv: 2308.12966, 2023. [48] Nair S, Rajeswaran A, Kumar V, Finn C, Gupta A. R3M: A universal visual representation for robot manipulation. In: Proceedings of the 6th Conference on Robot Learning. Auckland, New Zealand: PMLR, 2023. 892−909 [49] Li C M, Wen J J, Peng Y, Peng Y X, Feng F F, Zhu Y C. PointVLA: Injecting the 3D world into vision-language-action models. arXiv preprint arXiv: 2503.07511, 2025. [50] Sun L, Xie B, Liu Y F, Shi H, Wang T C, Cao J L. GeoVLA: Empowering 3D representations in vision-language-action models. arXiv preprint arXiv: 2508.09071, 2025. [51] Tang W L, Pan J H, Liu Y H, Tomizuka M, Li L E, Fu C W, et al. GeoManip: Geometric constraints as general interfaces for robot manipulation. arXiv preprint arXiv: 2501.09783, 2025. [52] Zhou Z Y, Zhu Y C, Zhu M J, Wen J J, Liu N, Xu Z Y, et al. Chatvla: Unified multimodal understanding and robot control with vision-language-action model. arXiv preprint arXiv: 2502.14420, 2025. [53] Hancock A J, Ren A Z, Majumdar A. Run-time observation interventions make vision-language-action models more visually robust. In: Proceedings of the IEEE International Conference on Robotics and Automation (ICRA). Atlanta, USA: IEEE, 2025. 9499−9506 [54] Kirillov A, Mintun E, Ravi N, Mao H Z, Rolland C, Gustafson L, et al. Segment anything. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). Paris, France: IEEE, 2023. 3992−4003 [55] Minderer M, Gritsenko A, Stone A, Neumann M, Weissenborn D, Dosovitskiy A, et al. Simple open-vocabulary object detection. In: Proceedings of the 17th European Conference on Computer Vision. Tel Aviv, Israel: Springer, 2022. 728−755 [56] Yang J W, Tan R B, Wu Q H, Zheng R J, Peng B L, Liang Y Y, et al. Magma: A foundation model for multimodal AI agents. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Nashville, USA: IEEE, 2025. 14203−14214 [57] Zhao W, Ding P X, Min Z, Gong Z F, Bai S H, Zhao H, et al. VLAS: Vision-language-action model with speech instructions for customized robot manipulation. In: Proceedings of the 13th International Conference on Learning Representations. Singapore: ICLR, 2025. [58] Touvron H, Lavril T, Izacard G, Martinet X, Lachaux M A, Lacroix T, et al. LLaMA: Open and efficient foundation language models. arXiv preprint arXiv: 2302.13971, 2023. [59] Jones J, Mees O, Sferrazza C, Stachowicz K, Abbeel P, Levine S. Beyond sight: Finetuning generalist robot policies with heterogeneous sensors via language grounding. In: Proceedings of the IEEE International Conference on Robotics and Automation (ICRA). Atlanta, USA: IEEE, 2025. 5961−5968 [60] Samson M, Muraccioli B, Kanehiro F. Scalable, training-free visual language robotics: A modular multi-model framework for consumer-grade GPUs. In: Proceedings of the IEEE/SICE International Symposium on System Integration (SII). Munich, Germany: IEEE, 2025. 193−198 [61] Khan M H, Asfaw S, Iarchuk D, Cabrera M A, Moreno L, Tokmurziyev I, et al. Shake-VLA: Vision-language-action model-based system for bimanual robotic manipulations and liquid mixing. In: Proceedings of the 20th ACM/IEEE International Conference on Human-Robot Interaction (HRI). Melbourne, Australia: IEEE, 2025. 1393−1397 [62] Li J N, Li D X, Savarese S, Hoi S. BLIP-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. In: Proceedings of the 40th International Conference on Machine Learning. Honolulu, USA: PMLR, 2023. 19730−19742 [63] Wen J J, Zhu Y C, Li J M, Tang Z B, Shen C M, Feng F F. DexVLA: Vision-language model with plug-in diffusion expert for general robot control. arXiv preprint arXiv: 2502.05855, 2025. [64] Zhang H, Li X, Bing L D. Video-LLaMA: An instruction-tuned audio-visual language model for video understanding. In: Proceedings of the Conference on Empirical Methods in Natural Language Processing: System Demonstrations. Singapore: ACL, 2023. 543−553 [65] Cheng A C, Ji Y D, Yang Z J, Gongye Z T, Zou X Y, Kautz J, et al. NaVILA: Legged robot vision-language-action model for navigation. arXiv preprint arXiv: 2412.04453, 2024. [66] Xu Z, Chiang H T L, Fu Z P, Jacob M G, Zhang T N, Lee T W E, et al. Mobility VLA: Multimodal instruction navigation with long-context VLMs and topological graphs. In: Proceedings of the 8th Conference on Robot Learning. Munich, Germany: PMLR, 2025. 3866−3887 [67] Shi L X, Ichter B, Equi M, Ke L Y M, Pertsch K, Vuong Q, et al. Hi Robot: Open-ended instruction following with hierarchical vision-language-action models. arXiv preprint arXiv: 2502.19417, 2025. [68] Zollo T P, Zemel R. Confidence calibration in vision-language-action models. arXiv preprint arXiv: 2507.17383, 2025. [69] Wu Y L, Tian R, Swamy G, Bajcsy A. From foresight to forethought: VLM-In-the-loop policy steering via latent alignment. arXiv preprint arXiv: 2502.01828, 2025. [70] Ji Y H, Tan H J, Shi J Y, Hao X S, Zhang Y, Zhang H Y, et al. RoboBrain: A unified brain model for robotic manipulation from abstract to concrete. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Nashville, USA: IEEE, 2025. 1724−1734 [71] Wu Z Y, Zhou Y H, Xu X W, Wang Z W, Yan H B. MoManipVLA: Transferring vision-language-action models for general mobile manipulation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Nashville, USA: IEEE, 2025. 1714−1723 [72] Li Y, Deng Y Q, Zhang J, Jang J, Memmel M, Garrett C R, et al. HAMSTER: Hierarchical action models for open-world robot manipulation. In: Proceedings of the 13th International Conference on Learning Representations. Singapore: ICLR, 2025. [73] Huang C P, Wu Y H, Chen M H, Wang Y C F, Yang F E. ThinkAct: Vision-language-action reasoning via reinforced visual latent planning. arXiv preprint arXiv: 2507.16815, 2025. [74] Qi Z K, Zhang W Y, Ding Y F, Dong R P, Yu X Q, Li J W, et al. SoFar: Language-grounded orientation bridges spatial reasoning and object manipulation. arXiv preprint arXiv: 2502.13143, 2025. [75] Li Y L, Yan G, Macaluso A, Ji M Z Y, Zou X Y, Wang X L. Integrating LMM planners and 3D skill policies for generalizable manipulation. arXiv preprint arXiv: 2501.18733, 2025. [76] Bi J X, Ma K Y, Hao C, Shou M Z, Soh H. VLA-touch: Enhancing vision-language-action models with dual-level tactile feedback. arXiv preprint arXiv: 2507.17294, 2025. [77] Jang E, Irpan A, Khansari M, Kappler D, Ebert F, Lynch C, et al. BC-Z: Zero-shot task generalization with robotic imitation learning. In: Proceedings of the 5th Conference on Robot Learning. London, UK: PMLR, 2022. 991−1002 [78] Ghosh D, Walke H, Pertsch K, Black K, Mees O, Dasari S, et al. Octo: An open-source generalist robot policy. In: Proceedings of the 19th Robotics: Science and Systems. Delft, The Netherlands: Robotics: Science and Systems, 2024. [79] Gu J Y, Kirmani S, Wohlhart P, Lu Y, Arenas M G, Rao K, et al. Robotic task generalization via hindsight trajectory sketches. In: Proceedings of the 1st Workshop on Out-of-Distribution Generalization in Robotics at CoRL 2023. Atlanta, USA: CoRL, 2023. [80] Zhao T Z, Kumar V, Levine S, Finn C. Learning fine-grained bimanual manipulation with low-cost hardware. In: Proceedings of the 19th Robotics: Science and Systems. Daegu, Republic of Korea: Science and Systems, 2023. [81] Ma Y E, Chi D F, Wu S G, Liu Y C, Zhuang Y Z, Hao J Y, et al. Actra: Optimized Transformer architecture for vision-language-action models in robot learning. arXiv preprint arXiv: 2408.01147, 2024. [82] Liu J M, Liu M Z, Wang Z Y, An P J, Li X Q, Zhou K C, et al. RoboMamba: Efficient vision-language-action model for robotic reasoning and manipulation. In: Proceedings of the 38th International Conference on Neural Information Processing Systems. Vancouver, Canada: Curran Associates Inc., 2024. Article No. 1266 [83] Chi C, Xu Z J, Feng S Y, Cousineau E, Du Y L, Burchfiel B, et al. Diffusion policy: Visuomotor policy learning via action diffusion. The International Journal of Robotics Research, DOI: 10.1177/02783649241273668 [84] Liu S M, Wu L X, Li B G, Tan H K, Chen H Y, Wang Z Y, et al. RDT-1B: A diffusion foundation model for bimanual manipulation. In: Proceedings of the 13th International Conference on Learning Representations. Singapore: ICLR, 2025. [85] Hou Z, Zhang T Y, Xiong Y W, Duan H N, Pu H J, Tong R L, et al. Dita: Scaling diffusion Transformer for generalist vision-language-action policy. arXiv preprint arXiv: 2503.19757, 2025. [86] Hou Z, Zhang T Y, Xiong Y W, Pu H J, Zhao C Y, Tong R L, et al. Diffusion Transformer policy. arXiv preprint arXiv: 2410.15959, 2024. [87] Touvron H, Martin L, Stone K, Albert P, Almahairi A, Babaei Y, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv: 2307.09288, 2023. [88] Chiang W L, Li Z H, Lin Z, Sheng Y, Wu Z H, Zhang H, et al. Vicuna: An open-source Chatbot impressing GPT-4 with 90%* ChatGPT quality [Online], available: https://vicuna.lmsys.org, April 14, 2023 [89] Zhang J Z, Wang K Y, Wang S A, Li M H, Liu H R, Wei S L, et al. Uni-NaVid: A video-based vision-language-action model for unifying embodied navigation tasks. arXiv preprint arXiv: 2412.06224, 2024. [90] Fu H Y, Zhang D K, Zhao Z C, Cui J F, Liang D K, Zhang C, et al. ORION: A holistic end-to-end autonomous driving framework by vision-language instructed action generation. arXiv preprint arXiv: 2503.19755, 2025. [91] Song W X, Chen J Y, Ding P X, Huang Y X, Zhao H, Wang D L, et al. CEED-VLA: Consistency vision-language-action model with early-exit decoding. arXiv preprint arXiv: 2506.13725, 2025. [92] Zhai X H, Mustafa B, Kolesnikov A, Beyer L. Sigmoid loss for language image pre-training. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). Paris, France: IEEE, 2023. 11941−11952 [93] Li S L, Wang J, Dai R, Ma W Y, Ng W Y, Hu Y B, et al. RoboNurse-VLA: Robotic scrub nurse system based on vision-language-action model. arXiv preprint arXiv: 2409.19590, 2024. [94] Ding P X, Zhao H, Zhang W J, Song W X, Zhang M, Huang S T, et al. QUAR-VLA: Vision-language-action model for quadruped robots. In: Proceedings of the 18th European Conference on Computer Vision. Milan, Italy: Springer, 2024. 352−367 [95] Dey S, Zaech J N, Nikolov N, van Gool L, Paudel D P. ReVLA: Reverting visual domain limitation of robotic foundation models. In: Proceedings of the IEEE International Conference on Robotics and Automation (ICRA). Atlanta, USA: IEEE, 2025. 8679−8686 [96] Chen P, Bu P, Wang Y Y, Wang X Y, Wang Z M, Guo J, et al. CombatVLA: An efficient vision-language-action model for combat tasks in 3D action role-playing games. arXiv preprint arXiv: 2503.09527, 2025. [97] Kim M J, Pertsch K, Karamcheti S, Xiao T, Balakrishna A, Nair S, et al. OpenVLA: An open-source vision-language-action model. In: Proceedings of the 8th Conference on Robot Learning. Munich, Germany: PMLR, 2025. 2679−2713 [98] Budzianowski P, Maa W, Freed M, Mo J X, Hsiao W, Xie A, et al. EdgeVLA: Efficient vision-language-action models. arXiv preprint arXiv: 2507.14049, 2025. [99] Arai H, Miwa K, Sasaki K, Watanabe K, Yamaguchi Y, Aoki S, et al. CoVLA: Comprehensive vision-language-action dataset for autonomous driving. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV). Tucson, USA: IEEE, 2025. 1933−1943 [100] Yang Z Y, Li L J, Lin K, Wang J F, Lin C C, Liu Z C, et al. The dawn of LMMs: Preliminary explorations with GPT-4V (ision). arXiv preprint arXiv: 2309.17421, 2023. [101] Zhang J K, Guo Y J, Chen X Y, Wang Y J, Hu Y C, Shi C M, et al. HiRT: Enhancing robotic control with hierarchical robot transformers. In: Proceedings of the 8th Conference on Robot Learning. Munich, Germany: PMLR, 2025. 933−946 [102] Zhao H, Song W X, Wang D L, Tong X Y, Ding P X, Cheng X L, et al. MoRE: Unlocking scalability in reinforcement learning for quadruped vision-language-action models. arXiv preprint arXiv: 2503.08007, 2025. [103] Shukor M, Aubakirova D, Capuano F, Kooijmans P, Palma S, Zouitine A, et al. SmolVLA: A vision-language-action model for affordable and efficient robotics. arXiv preprint arXiv: 2506.01844, 2025. [104] Huang S Y, Chen L L, Zhou P F, Chen S C, Jiang Z K, Hu Y, et al. EnerVerse: Envisioning embodied future space for robotics manipulation. arXiv preprint arXiv: 2501.01895, 2025. [105] Zhao Q Q, Lu Y, Kim M J, Fu Z P, Zhang Z Y, Wu Y C, et al. CoT-VLA: Visual chain-of-thought reasoning for vision-language-action models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Nashville, USA: IEEE, 2025. 1702−1713 [106] Zhang W Y, Liu H S, Qi Z K, Wang Y N, Yu X Q, Zhang J Z, et al. DreamVLA: A vision-language-action model dreamed with comprehensive world knowledge. arXiv preprint arXiv: 2507.04447, 2025. [107] Sharma P, Mohan L, Pinto L, Gupta A. Multiple interactions made easy (MIME): Large scale demonstrations data for imitation. In: Proceedings of the 2nd Conference on robot learning. Zürich, Switzerland: PMLR, 2018. 906−915 [108] Dasari S, Ebert F, Tian S, Nair S, Bucher B, Schmeckpeper K, et al. RoboNet: Large-scale multi-robot learning. In: Proceedings of the 3rd Conference on Robot Learning. Osaka, Japan: PMLR, 2020. 885−897 [109] Kalashnikov D, Varley J, Chebotar Y, Swanson B, Jonschkowski R, Finn C, et al. MT-Opt: Continuous multi-task robotic reinforcement learning at scale. arXiv preprint arXiv: 2104.08212, 2021. [110] Kumar V, Shah R, Zhou G Y, Moens V, Caggiano V, Vakil J, et al. RoboHive: A unified framework for robot learning. In: Proceedings of the 37th International Conference on Neural Information Processing Systems. New Orleans, USA: Curran Associates Inc., 2023. Article No. 1918 [111] Walke H R, Black K, Zhao T Z, Vuong Q, Zheng C Y, Hansen-Estruch P, et al. BridgeData V2: A dataset for robot learning at scale. In: Proceedings of the 7th Conference on Robot Learning. Atlanta, USA: PMLR, 2023. 1723−1736 [112] Fang H S, Fang H J, Tang Z Y, Liu L R, Wang C X, Wang J B, et al. RH20T: A comprehensive robotic dataset for learning diverse skills in one-shot. In: Proceedings of the IEEE International Conference on Robotics and Automation (ICRA). Yokohama, Japan: IEEE, 2024. 653−660 [113] Khazatsky A, Pertsch K, Nair S, Balakrishna A, Dasari S, Karamcheti S, et al. DROID: A large-scale in-the-wild robot manipulation dataset. In: Proceedings of the 19th Robotics: Science and Systems. Delft, The Netherlands: Robotics: Science and Systems, 2024. [114] O'Neill A, Rehman A, Maddukuri A, Gupta A, Padalkar A, Lee A, et al. Open X-embodiment: Robotic learning datasets and RT-X models: Open X-embodiment collaboration.0. In: Proceedings of the IEEE International Conference on Robotics and Automation (ICRA). Yokohama, Japan: IEEE, 2024. 6892−6903 [115] Nasiriany S, Maddukuri A, Zhang L C, Parikh A, Lo A, Joshi A, et al. RoboCasa: Large-scale simulation of everyday tasks for generalist robots. arXiv preprint arXiv: 2406.02523, 2024. [116] Deng S L, Yan M, Wei S L, Ma H X, Yang Y X, Chen J Y, et al. GraspVLA: A grasping foundation model pre-trained on billion-scale synthetic action data. arXiv preprint arXiv: 2505.03233, 2025. [117] Liu W H, Wan Y X, Wang J L, Kuang Y X, Shi X S, Li H R, et al. FetchBot: Object fetching in cluttered shelves via zero-shot Sim2Real. arXiv preprint arXiv: 2502.17894, 2025. [118] Chen T X, Chen Z X, Chen B J, Cai Z J, Liu Y B, Li Z X, et al. RoboTwin 2.0: A scalable data generator and benchmark with strong domain randomization for robust bimanual robotic manipulation. arXiv preprint arXiv: 2506.18088, 2025. [119] Jiang Z Y, Xie Y Q, Lin K, Xu Z J, Wan W K, Mandlekar A, et al. DexMimicGen: Automated data generation for bimanual dexterous manipulation via imitation learning. In: Proceedings of the IEEE International Conference on Robotics and Automation (ICRA). Atlanta, USA: IEEE, 2025. 16923−16930 [120] Fu Z P, Zhao T Z, Finn C. Mobile ALOHA: Learning bimanual mobile manipulation with low-cost whole-body teleoperation. arXiv preprint arXiv: 2401.02117, 2024. [121] Xiao T, Chan H, Sermanet P, Wahid A, Brohan A, Hausman K, et al. Robotic skill acquisition via instruction augmentation with vision-language models. In: Proceedings of the 19th Robotics: Science and Systems. Daegu, Republic of Korea: Robotics: Science and Systems, 2023. [122] Ahn M, Dwibedi D, Finn C, Arenas M G, Gopalakrishnan K, Hausman K, et al. AutoRT: Embodied foundation models for large scale orchestration of robotic agents. arXiv preprint arXiv: 2401.12963, 2024. [123] Wu H T, Jing Y, Cheang C, Chen G Z, Xu J F, Li X H, et al. Unleashing large-scale video generative pre-training for visual robot manipulation. In: Proceedings of the 12th International Conference on Learning Representations. Vienna, Austria: ICLR, 2024. [124] Ye S, Jang J, Jeon B, Joo S J, Yang J W, Peng B L, et al. Latent action pretraining from videos. In: Proceedings of the 13th International Conference on Learning Representations. Singapore: ICLR, 2025. [125] Bu Q W, Cai J S, Chen L, Cui X Q, Ding Y, Feng S Y, et al. AgiBot world Colosseo: A large-scale manipulation platform for scalable and intelligent embodied systems. arXiv preprint arXiv: 2503.06669, 2025. [126] Yang R H, Yu Q X, Wu Y C, Yan R, Li B R, Cheng A C, et al. EgoVLA: Learning vision-language-action models from egocentric human videos. arXiv preprint arXiv: 2507.12440, 2025. [127] Luo H, Feng Y C, Zhang W P, Zheng S P, Wang Y, Yuan H Q, et al. Being-H0: Vision-language-action pretraining from large-scale human videos. arXiv preprint arXiv: 2507.15597, 2025. [128] Lin F Q, Nai R Q, Hu Y D, You J C, Zhao J M, Gao Y. OneTwoVLA: A unified vision-language-action model with adaptive reasoning. arXiv preprint arXiv: 2505.11917, 2025. [129] Pertsch K, Stachowicz K, Ichter B, Driess D, Nair S, Vuong Q, et al. FAST: Efficient action tokenization for vision-language-action models. arXiv preprint arXiv: 2501.09747, 2025. [130] Duan Z K, Zhang Y, Geng S K, Liu G W, Boedecker J, Lu C X. Fast ECoT: Efficient embodied chain-of-thought via thoughts reuse. arXiv preprint arXiv: 2506.07639, 2025. [131] Kalashnikov D, Irpan A, Pastor P, Ibarz J, Herzog A, Jang E, et al. Scalable deep reinforcement learning for vision-based robotic manipulation. In: Proceedings of the 2nd Conference on Robot Learning. Zürich, Switzerland: PMLR, 2018. 651−673 [132] Torne M, Simeonov A, Li Z C, Chan A, Chen T, Gupta A, et al. Reconciling reality through simulation: A real-to-sim-to-real approach for robust manipulation. In: Proceedings of the 19th Robotics: Science and Systems. Delft, The Netherlands: Robotics: Science and Systems, 2024. [133] Ma Y J, Liang W, Wang G Z, Huang D A, Bastani O, Jayaraman D, et al. Eureka: Human-level reward design via coding large language models. In: Proceedings of the 12th International Conference on Learning Representations. Vienna, Austria: ICLR, 2024. [134] Bjorck J, Castañeda F, Cherniadev N, Da X Y, Ding R Y, Fan L X, et al. GR00T N1: An open foundation model for generalist humanoid robots. arXiv preprint arXiv: 2503.14734, 2025. [135] Li M L, Zhao S Y, Wang Q N, Wang K R, Zhou Y, Srivastava S, et al. Embodied agent interface: Benchmarking LLMs for embodied decision making. In: Proceedings of the 38th International Conference on Neural Information Processing Systems. Vancouver, Canada: Curran Associates Inc., 2024. Article No. 3188 [136] Yang R, Chen H Y, Zhang J Y, Zhao M, Qian C, Wang K R, et al. EmbodiedBench: Comprehensive benchmarking multi-modal large language models for vision-driven embodied agents. arXiv preprint arXiv: 2502.09560, 2025. [137] Li D P, Cai T L, Tang T C, Chai W H, Driggs-Campbell K R, Wang G A. EMMOE: A comprehensive benchmark for embodied mobile manipulation in open environments. arXiv preprint arXiv: 2503.08604, 2025. [138] Zhu S T, Mou L Z, Li D R, Ye B J, Huang R H, Zhao H. VR-Robo: A real-to-sim-to-real framework for visual robot navigation and locomotion. IEEE Robotics and Automation Letters, 2025, 10(8): 7875−7882 doi: 10.1109/LRA.2025.3575648 [139] Lou H Z, Zhang M T, Geng H R, Zhou H Y, He S C, Gao Z Y, et al. DREAM: Differentiable real-to-sim-to-real engine for learning robotic manipulation. In: Proceedings of the 3rd RSS Workshop on Dexterous Manipulation: Learning and Control with Diverse Data. Los Angeles, United States: RSS, 2025. [140] Arndt K, Hazara M, Ghadirzadeh A, Kyrki V. Meta reinforcement learning for sim-to-real domain adaptation. In: Proceedings of the IEEE International Conference on Robotics and Automation (ICRA). Paris, France: IEEE, 2020. 2725−2731 [141] Mehta B, Diaz M, Golemo F, Pal C J, Paull L. Active domain randomization. In: Proceedings of the 3rd Conference on Robot Learning. Osaka, Japan: PMLR, 2020. 1162−1176 [142] Truong J, Chernova S, Batra D. Bi-directional domain adaptation for Sim2Real transfer of embodied navigation agents. IEEE Robotics and Automation Letters, 2021, 6(2): 2634−2641 doi: 10.1109/LRA.2021.3062303 [143] Mu Y, Chen T X, Peng S J, Chen Z X, Gao Z Y, Zou Y D, et al. RoboTwin: Dual-arm robot benchmark with generative digital twins (early version). In: Proceedings of the 18th European Conference on Computer Vision. Milan, Italy: Springer, 2024. 264−273 [144] Abou-Chakra J, Sun L F, Rana K, May B, Schmeckpeper K, Minniti M V, et al. Real-is-sim: Bridging the sim-to-real gap with a dynamic digital twin for real-world robot policy evaluation. arXiv preprint arXiv: 2504.03597, 2025. [145] Cakir L V, Al-Shareeda S, Oktug S F, Özdem M, Broadbent M, Canberk B. How to synchronize digital twins? A communication performance analysis. In: Proceedings of the IEEE 28th International Workshop on Computer Aided Modeling and Design of Communication Links and Networks (CAMAD). Edinburgh, United Kingdom: IEEE, 2023. 123−127 [146] Liu S P, Zhang B S, Huang Z H. Benchmark real-time adaptation and communication capabilities of embodied agent in collaborative scenarios. arXiv preprint arXiv: 2412.00435, 2024. [147] Kumar A, Fu Z P, Pathak D, Malik J. RMA: Rapid motor adaptation for legged robots. In: Proceedings of the 17th Robotics: Science and Systems. Virtual Event: RSS, 2021. [148] Kumar A, Li Z Y, Zeng J, Pathak D, Sreenath K, Malik J. Adapting rapid motor adaptation for bipedal robots. In: Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). Kyoto, Japan: IEEE, 2022. 1161−1168 [149] Atreya P, Pertsch K, Lee T, Kim M J, Jain A, Kuramshin A, et al. RoboArena: Distributed real-world evaluation of generalist robot policies. arXiv preprint arXiv: 2506.18123, 2025. [150] Srivastava S, Li C S, Lingelbach M, Martín-Martín R, Xia F, Vainio K E, et al. BEHAVIOR: Benchmark for everyday household activities in virtual, interactive, and ecological environments. In: Proceedings of the 5th Conference on Robot Learning. London, UK: PMLR, 2022. 477−490 [151] Krantz J, Wijmans E, Majumdar A, Batra D, Lee S. Beyond the nav-graph: Vision-and-language navigation in continuous environments. In: Proceedings of the 16th European Conference on Computer Vision. Glasgow, UK: Springer, 2020. 104−120 [152] James S, Ma Z C, Arrojo D R, Davison A J. RLBench: The robot learning benchmark & learning environment. IEEE Robotics and Automation Letters, 2020, 5(2): 3019−3026 doi: 10.1109/LRA.2020.2974707 [153] Yu T H, Quillen D, He Z P, Julian R, Hausman K, Finn C, et al. Meta-world: A benchmark and evaluation for multi-task and meta reinforcement learning. In: Proceedings of the 3rd Conference on Robot Learning. Osaka, Japan: PMLR, 2020. 1094−1100 [154] Gupta A, Kumar V, Lynch C, Levine S, Hausman K. Relay policy learning: Solving long-horizon tasks via imitation and reinforcement learning. In: Proceedings of the 3rd Conference on Robot Learning. Osaka, Japan: PMLR, 2020. 1025−1037 [155] Mees O, Hermann L, Rosete-Beas E, Burgard W B. CALVIN: A benchmark for language-conditioned policy learning for long-horizon robot manipulation tasks. IEEE Robotics and Automation Letters, 2022, 7(3): 7327−7334 doi: 10.1109/LRA.2022.3180108 [156] Liu B, Zhu Y F, Gao C K, Feng Y H, Liu Q, Zhu Y K, et al. LIBERO: Benchmarking knowledge transfer for lifelong robot learning. In: Proceedings of the 37th International Conference on Neural Information Processing Systems. New Orleans, USA: Curran Associates Inc., 2023. Article No. 1939 [157] Tassa Y, Doron Y, Muldal A, Erez T, Li Y Z, de Las Casas D, et al. DeepMind control suite. arXiv preprint arXiv: 1801.00690, 2018. [158] Zhou X C, Han X Y, Yang F, Ma Y P, Knoll A C. OpenDriveVLA: Towards end-to-end autonomous driving with large vision language action model. arXiv preprint arXiv: 2503.23463, 2025. [159] Sautenkov O, Yaqoot Y, Lykov A, Mustafa M A, Tadevosyan G, Akhmetkazy A, et al. UAV-VLA: Vision-language-action system for large scale aerial mission generation. In: Proceedings of the 20th ACM/IEEE International Conference on Human-Robot Interaction (HRI). Melbourne, Australia: IEEE, 2025. 1588−1592 [160] Eslami S, de Melo G. Mitigate the gap: Investigating approaches for improving cross-modal alignment in CLIP. arXiv preprint arXiv: 2406.17639, 2024. [161] Song S Z, Li X P, Li S S, Zhao S, Yu J, Ma J, et al. How to bridge the gap between modalities: A comprehensive survey on multimodal large language model. arXiv preprint arXiv: 2311.07594, 2023. [162] Chen Y, Ding Z H, Wang Z Q, Wang Y, Zhang L J, Liu S. Asynchronous large language model enhanced planner for autonomous driving. In: Proceedings of the 18th European Conference on Computer Vision. Milan, Italy: Springer, 2024. 22−38 [163] Qian C, Yu X R, Huang Z W, Li D Y, Ma Q, Dang F, et al. SpotVLM: Cloud-edge collaborative real-time VLM based on context transfer. arXiv preprint arXiv: 2508.12638, 2025. [164] Kwon T, di Palo N, Johns E. Language models as zero-shot trajectory generators. IEEE Robotics and Automation Letters, 2024, 9(7): 6728−6735 doi: 10.1109/LRA.2024.3410155 [165] Wei H, Zhang Z H, He S H, Xia T, Pan S J, Liu F. PlanGenLLMs: A modern survey of LLM planning capabilities. In: Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Vienna, Austria: ACL, 2025. 19497−19521 [166] Bruce J, Dennis M D, Edwards A, Parker-Holder J, Shi Y G, Hughes E, et al. Genie: Generative interactive environments. In: Proceedings of the 41st International Conference on Machine Learning. Vienna, Austria: ICML, 2024. [167] Kang B Y, Yue Y, Lu R, Lin Z J, Zhao Y, Wang K X, et al. How far is video generation from world model: A physical law perspective. arXiv preprint arXiv: 2411.02385, 2025. [168] Black K, Brown N, Driess D, Esmail A, Equi M, Finn C, et al. π0: A vision-language-action flow model for general robot control. arXiv preprint arXiv: 2410.24164, 2024. -

 下载:
下载:

计量
- 文章访问数: 9462
- HTML全文浏览量: 8778
- PDF下载量: 5102
- 被引次数: 0
