

-
摘要: 具身智能系统通过智能体与环境不断交互, 从而提升智能体能力, 受到学术界和产业界的广泛关注. 视觉−语言−动作模型作为一种受到大模型发展启发的机器人通用控制模型, 提高了具身智能系统中智能体与环境交互的能力, 大大扩展了具身智能机器人的应用场景. 本文对具身操作中的视觉−语言−动作模型进行综述. 首先, 详细介绍视觉−语言−动作模型的发展历程. 然后, 对视觉−语言−动作模型架构、训练数据、预训练方法、后训练方法和模型评估5个方面的研究现状进行详细分析. 最后, 针对视觉−语言−动作模型发展过程和落地应用中面临的挑战和未来可能的发展方向进行总结.
-
关键词:
- 具身智能 /
- 视觉−语言−动作模型 /
- 机器人 /
- 基础模型
Abstract: Embodied intelligence systems, which enhance agent capabilities through continuous environment interactions, have garnered significant attention from both academia and industry. Vision-language-action (VLA) models, inspired by advancements in large foundation models, serve as universal robotic control frameworks that substantially improve agent-environment interaction capabilities in embodied intelligence systems. This expansion has broadened application scenarios for embodied intelligence robots. This survey comprehensively reviews VLA models for embodied manipulation. Firstly, it introduces the developmental history of VLA models. Subsequently, it conducts a detailed analysis of current research status across 5 critical dimensions: VLA model structures, training datasets, pre-training methods, post-training methods, and model evaluation. Finally, it summarizes key challenges in VLA model development and real-world deployment, while outlining promising future development directions.-
Key words:
- embodied intelligence /
- vision-language-action models /
- robotics /
- foundation models
-
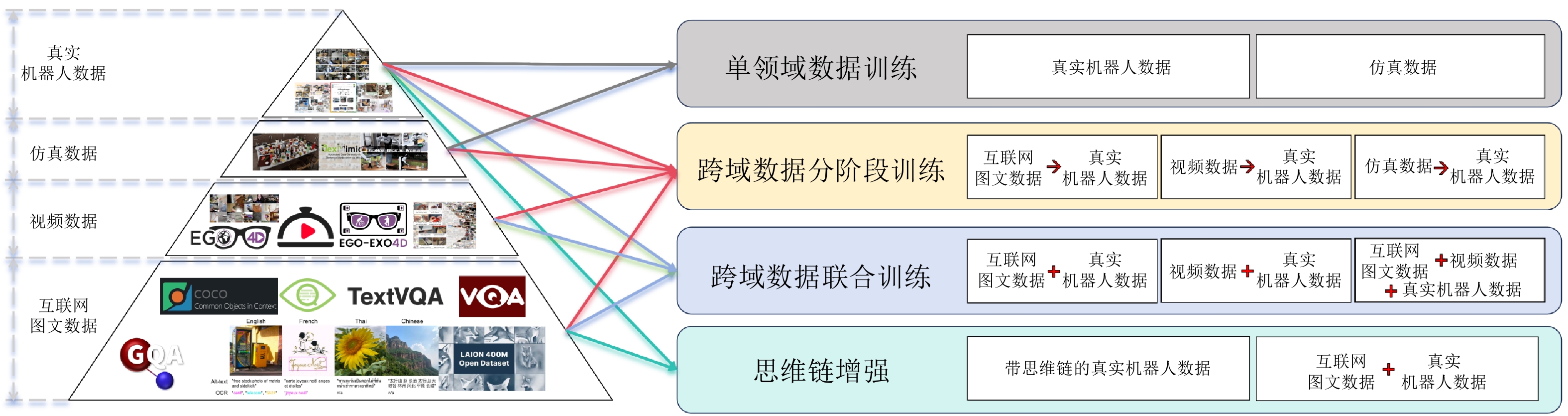
图 8 数据金字塔和VLA预训练方法(彩色箭头表示不同的训练方法所使用的数据类型. 在每个训练方法中, 红色“$ \rightarrow $”表示使用数据的顺序, 红色“$ + $”表示不同的数据一起使用实现联合训练)
Fig. 8 Data pyramid and VLA pre-training methods (The colored arrows represent the data types used by different training methods. In each training method, the red “$ \rightarrow $” indicates the order in which the data is used, and the red “$ + $” indicates that different data are used together to achieve joint training)
表 2 数据集与相关方法汇总
Table 2 Summary of datasets and related methods
分类 名称 描述 规模 支持任务 相关方法 互
联
网
图
文
数
据CapsFusion[101] 大规模图像−文本对数据集, 为多模态预训练设计, 旨在解决现有图像−文本数据集的噪声问题和低质量标注问题 1.2亿个图像−文本对 图像描述生成, 多模态预训练 $ \pi_0 $[42] COCO[102] 大规模图像数据集, 包含80个物体类别和91种材料类别, 每张图片包含5个语句描述, 且有25万个带关键点标注的行人 33万张图片 目标检测, 实例分割, 关键点检测, 图像描述生成 $ \pi_0 $[42], ChatVLA[50],
ChatVLA-2[94]GQA[103] 大规模视觉问答数据集, 专注于真实世界的视觉推理和组合性问答 2260 万个问题, 11.3万张图像组合性推理, 视觉问答 ChatVLA[50],
ChatVLA-2[94]LAION-400M[104] 大规模图像−文本对数据集, 包含图像URL、图像和图像描述的嵌入、图像与描述之间的相似性评分以及元数据 4亿个图像−文本对 图文检索, 图文生成, 多模态预训练 UniPi[45] PixMo[105] 大规模图像−文本对数据集, 图像涵盖70多个主题, 每张图像描述由3位标注者通过语音生成 71.2万张图像, 130万个描述 图像描述生成, 多模态预训练 $ \pi_0 $[42] TextVQA[106] 大规模视觉问答数据集, 要求模型理解图像中的文本内容来回答问题 2.8万张图片, 4.53万个问题, 45.3万条回答 文本推理, 视觉问答 ChatVLA[50],
ChatVLA-2[94]VQAv2[107] 大规模开放式问答数据集, 由人工标注, 面向开放世界视觉问答任务 26.5万张图片, 44.3万个问题, 443万条回答 常识推理, 视觉问答 $ \pi_0 $[42] WebLI[108] 超大规模多语言图像−文本对数据集, 涵盖36种语言和多样化文化背景, 包含13亿张图像−文本对, 旨在提升视觉语言模型在全球范围内的泛化能力与文化适应性 100亿个图像−文本对 光学字符识别, 图文检索, 图像描述生成, 视觉问答, 多模态预训练 RT-2[10] 视
频
数
据Ego-4D[109] 大规模第一人称视角视频数据集, 涵盖数百种场景, 由来自全球74个地点和9个不同国家的931名参与者拍摄 3670 小时视频视频理解, 多模态感知 GO-1[64], GR-1[47], GR00T N1[57], Magma[110],
UniVLA[65]Ego-Exo-4D[111] 由Ego-4D数据集扩展的大规模第一/第三人称视角的多模态视频数据集, 增加多视角同步捕捉, 专注于技能活动研究 1286 小时视频跨视角表征学习, 技能理解, 多模态感知 GR00T N1[57] EPIC-KITCHENS-100[112] 大规模第一人称视角视频数据集, 包含45个厨房环境下的动作识别, 捕捉多种家庭活动, 包括9万个动作 2 000万帧图像,
100小时视频动作识别, 环境理解, 多模态推理, 场景泛化 ARM4R[70], CoT-VLA[66], GR-2[48], GR00T N1[57], Magma[110], HPT[33] Howto100M 大规模叙述视频数据集, 主要是教学视频, 其中内容创建者教授复杂的任务, 并明确解释屏幕上的视觉内容 1.36亿个视频片段 图像描述生成, 多模态预训练 GR-2[48] Kinetics-700[113] 大规模视频数据集, 涵盖700种人类动作类别, 包含人与物体及人与人之间的互动 65万个视频 动作识别, 视频理解 GR-2[48] Something-Something V2[114] 大规模带标记视频数据集, 包含人类使用日常物品执行的174种基本动作 22万个视频片段 动作识别, 自监督学习, 多模态推理 CoT-VLA[66], GR-2[48],
LAPA[49], Magma[110],
TriVLA[54], VPP[46]仿
真
数
据DexMimicGen[115] 大规模仿真数据集, 涵盖涉及精密操作和灵巧手场景下多种复杂操作任务, 通过人类演示与仿真生成 2.1万条轨迹 灵巧操作学习, 精细控制, 仿真到现实迁移 GR00T N1[57],
GR00T N1.5[57]RoboCasa[116] 大规模仿真数据集, 提供120种厨房场景与 2500 个3D物体, 结合大语言模型生成任务与自动轨迹生成, 支持通用机器人操作与策略学习超过10万条轨迹 策略学习, 环境理解, 多模态预训练, 仿真到现实迁移 GR00T N1[57] SynGrasp-1B[117] 大规模合成动作数据集, 专注于机器人抓取技能的学习, 涵盖240个物体类别和1万个物体 10亿帧图像 抓取策略学习, 仿真到现实迁移, 跨任务泛化 GraspVLA[117] 真
实
机
器
人
数
据AgiBot World[64] 大规模多场景数据集, 涵盖家居、餐饮、工业、商超及办公5大核心场景, 涵盖超过100种真实场景和 3000 多种日常物品, 其中80%的任务为长程任务100多万条轨迹, 2976.4 小时交互数据多任务学习, 跨场景泛化, 多模态预训练, 仿真与真实结合训练 GO-1[64], GR00T N1[57] BC-Z[20] 大规模机器人模仿学习数据集, 涵盖100种操作任务, 通过专家远程操作与自主收集, 支持零样本任务泛化和语言与视频条件下的策略学习 2.58万条轨迹 多任务学习, 跨场景泛化, 多模态预训练 $ \pi_0 $[42], CoT-VLA[66],
TraceVLA[118],
UniPi[45]真
实
机
器
人
数
据Bridge Data[119] 大规模多任务操作数据集, 涵盖使用WidowX机械臂在10个环境中收集的71个厨房任务 7200 条轨迹多任务学习, 跨场景泛化, 多模态预训练 UniPi[45], GR-2[48] Bridge Data V2[120] 大规模多任务操作数据集, 使用WidowX机械臂在24个环境中收集, 涵盖广泛任务与环境变化, 支持图像和语言条件下的多任务学习与技能泛化 6万条轨迹 多任务学习, 跨场景泛化, 多模态预训练 $ \pi_0 $[42], ECoT[121],
LAPA[49], NORA[122],
RDT[31], TraceVLA[118]DROID[123] 大规模真实机器人操作数据集, 覆盖564个多样化场景和86种任务类型, 支持丰富动作和环境组合, 促进机器人通用操作技能学习 7.6万条轨迹, 350小时交互数据 多任务学习, 多机器人协同学习, 跨场景泛化, 多模态预训练 $ \pi_0 $[42], DreamVLA[68], DiVLA[124], HybridVLA[99], NORA[122], UniAct[125], RDT[31], SpatialVLA[69] Moblie ALOHA[126] 大规模数据集, 支持双臂移动操作, 涵盖厨房、实验室等多场景下的复合任务学习, 融合人类示教与自动化采集两种采集范式 500条轨迹 多任务学习, 导航学习, 多模态预训练 RDT[31] FrodoBots-2k 大规模多模态数据集, 遥控操作收集涵盖视频、GPS、IMU、音频与人类控制数据, 覆盖全球10多座城市, 支持移动机器人导航与感知研究 2000 小时交互数据驾驶策略学习, 跨场景泛化, 多模态预训练 HPT[33] OXE[32] 大规模多机器人操作数据集, 涵盖22种机器人的527种技能和16万项任务, 提供标准化格式支持, 促进跨形态经验迁移与通用策略学习 超过100万条轨迹 多任务学习, 跨场景泛化, 多模态预训练 $ \pi_0 $[42], CogACT[40],
CoT-VLA[66], DiVLA[124], GR00T N1[57], HPT[33], HybridVLA[99], LAPA[49], NORA[122], RDT[31], RoboVLMs[44], SpatialVLA[69], TriVLA[54], UniAct[125], UniVLA[65], VPP[46]RDT-1B[31] 大规模机器人操作数据集, 涵盖单臂、双臂与移动机械臂等多种机器人形态 超过100万条轨迹 多任务学习, 跨形态泛化, 跨场景泛化, 多模态预训练 RDT[31] RH20T[127] 大规模多模态机器人操作数据集, 包含4种主流机械臂、4种夹爪和3种力传感器共7种机器人硬件配置组合, 涵盖147种任务与42种技能 11万条序列, 5 000万张图像 力觉感知融合, 多形态技能泛化, 多模态预训练 RDT[31] RoboSet[128] 大规模真实机器人操作数据集, 专注于厨房环境, 包含动觉示教与遥操示教的多视角轨迹及丰富场景变化 2.85万条轨迹 多任务学习, 变化场景适应, 多模态预训练 RDT[31] RoboMIND[129] 大规模机器人操作数据集, 涵盖479种任务、96种物体类别, 38种操作技能及多种机械臂与人形机器人, 支持任务执行性能提升与失败案例分析 10.7万条成功轨迹, 5000 条失败轨迹多任务学习, 失败分析与自适应改进, 多模态预训练 HybridVLA[99] RT-1[21] 大规模真实机器人数据集, 包含13台机械臂上采集的带语言指令标注的视频, 涵盖700多种任务, 支持零样本泛化和复杂操作技能学习 13万个视频片段 多任务学习, 跨场景泛化, 多模态预训练 Gen2Act[130], GR-2[48], RDT[31], RT-1[21],
RT-2[10], TraceVLA[118] 下载: 导出CSV
下载: 导出CSV
表 3 VLA后训练方法汇总
Table 3 Summary of VLA post-training methods
类别 相关工作 主要贡献/优势 缺陷 适用场景 发表 年份 监督微调 $ \pi_{0} $[42] 提出基于流匹配的动作解码器, 在高质量真实机器人数据上通过监督微调, 有效提升模型在复杂、长程任务中的执行稳定性与成功率 对专家数据的质量与覆盖度较为敏感, 分布外泛化与跨场景迁移受限, 需要进行域内微调 适用于长时序任务及不便进行在线探索的真实部署环境 RSS 2025 GO-1[64] 在海量互联网异构视频与真实机器人数据上预训练, 并结合MoE结构, 仅需少量真实数据的监督微调即可快速适应新任务与新场景, 显著降低数据需求 预训练数据噪声与域间分布差异产生错误对齐; MoE带来训练与推理的系统复杂度和算力开销, 缺乏稀有技能与密集接触场景真机数据 数据相对稀缺但任务多样、需快速落地的新场景迁移 arXiv 2025 GR00T N1[57] 在多样化人形机器人感知与控制数据上预训练, 结合快速反射与规划推理的双系统架构, 后训练既具备高反应速度, 又能进行复杂任务规划, 在多种场景中展现出鲁棒的人形机器人控制能力 依赖大规模高质量人形数据与复杂系统集成, 训练与推理的算力/工程成本高; 密集接触工况或强约束环境中需要额外安全策略与调参 需要同时具备灵敏即时反应和高层规划的人形机器人应用, 例如服务场景、多步骤装配、移动操作与协作任务 arXiv 2025 GR-1[47] 在40万条跨形态机器人数据上进行模仿预训练, 构建首个开放的多任务、多机器人形态统一策略基线, 在少量目标机器人真实数据上通过监督微调进行后训练, 实现“单模型多机器人”控制的可行性, 并显著降低多形态适配成本 依赖大规模异构数据的质量与覆盖度;对极端工况/特定形态的细粒度控制可能仍需额外调参, 且通才策略在个别边缘任务上可能不如专才策略 多形态、多任务的统一部署与快速落地, 以及对维护成本敏感、需快速适配新形态的应用 ICLR 2024 GR-2[48] 在GR-1框架基础上加入视觉−语言−动作三模态对齐, 并引入更大规模的互联网视频自监督数据进行预训练, 在少量目标机器人真实数据上通过监督微调进行后训练, 进一步提升复杂指令理解和跨场景任务执行的泛化能力 依赖互联网视频与多模态对齐质量, 可能受噪声与域间偏移影响; 模型规模与训练/对齐流程复杂, 密集接触任务的安全性与精细控制仍需额外工程与人为监督 真机数据稀缺但可获取大量弱标视频的应用; 需快速适配新环境/新任务的指令驱动型操作; 跨机器人形态迁移与多步骤长程任务执行 arXiv 2024 GR-3[138] 采用跨域数据联合训练, 将预训练数据规模扩展至百万级, 重点强化语言指令理解与零样本跨环境泛化能力, 在少量目标机器人真实数据上通过监督微调进行后训练, 显著提升了在未见任务与新环境中的执行稳定性和成功率 高度依赖大规模异构数据的质量与对齐, 数据清洗与标注成本高; 训练与部署的系统/算力开销较大, 密集接触与高精度控制仍可能需要额外专用微调策略 数据分布多样、需频繁迁移的新环境任务; 指令驱动的长程多步骤操作 arXiv 2025 Helix[56] 首个人形VLA, 在Figure人形的大规模感知与控制数据上进行预训练, 可对整个人形上半身输出高频连续控制, 在少量目标任务的真实机器人数据上通过监督微调进行后训练, 实现精确且稳定的上肢协调控制 训练数据仅限于当前机器人形态, 迁移到异构人形可能需额外标定与微调;高频连续控制带来训练与推理算力/实时性压力, 密集接触场景仍需安全机制与细致调参 需要精细上肢操作与稳定协同的人形应用, 例如装配、工具使用、开关/旋钮操作与服务场景 arXiv 2025 HPT[33] 分层提示微调, 将LLM生成的文字描述拆分为“层次化结构”与“语义文本”两种提示并同步学习, 在多任务机器人数据上预训练后, 用少量目标任务的真实数据监督微调后训练, 保持语言理解能力同时显著提升任务执行的稳定性与泛化性 需要高质量的层次化指令生成与标注, 分层提示设计与超参较多、工程复杂度偏高; 对密集接触/高频闭环控制仍可能需额外控制器或安全机制配合 语义复杂、步骤明确的多步骤操作, 例如装配、烹饪式流程、服务机器人任务 Neur-IPS 2024 Magma[110] 微软提出的多模态基础模型, 可同时感知视觉与语言并输出动作, 在少量目标机器人真实数据上通过监督微调进行后训练, 实现从数字智能体到实体机器人的高效迁移, 在真实环境任务中表现出稳定的感知−行动能力 预训练与对齐流程复杂, 对多模态同步标注与时间对齐敏感; 推理开销与系统集成成本较高, 密集接触或高精度操作仍需专才策略与安全约束 需要从仿真/视频智能体快速落地到真实机器人、任务多样且数据相对有限的应用, 例如服务机器人、仓储与装配等真实场景的多任务部署 CVPR 2025 Octo[30] 首个完全开源的通用Transformer Diffusion架构, 在少量目标机器人真实数据上通过监督微调进行后训练, 实现跨机器人形态的快速适配与任务迁移, 在多样任务中保持高执行性能 扩散式动作生成推理开销较大, 对密集接触/高精度操作仍可能需要专用微调方法与安全机制; 性能对专家数据分布与对齐质量较为敏感 跨形态迁移与多任务统一基线搭建、研究与工业落地的可复现方案, 以及以少量目标数据完成快速适配的真实部署 arXiv 2024 OpenVLA[39] 70亿参数开源VLA, 在少量目标机器人真实数据上通过监督微调进行后训练, 内置多机器人形态的适配能力, 从而实现高效迁移, 显著降低跨形态适配成本并且可以保持任务的执行性能 模型规模与推理开销较大, 对实时性与边缘设备部署有压力; 在密集接触/高精度任务上仍依赖高质量对齐与额外标定和安全机制 作为跨形态统一基线与研究/工业的可复现方案, 在数据有限的场景进行快速适配与任务迁移, 可在多机器人形态间共享策略 CoRL 2024 监督微调 RDT[31] 首个双臂操作扩散基础模型, 在稀缺数据场景下能够生成多模态动作分布, 在少量目标任务的真实双臂机器人数据上通过监督微调进行后训练, 显著提升了在复杂协作操作任务中的稳定性与成功率 扩散生成带来推理时延与算力开销, 对实时高频控制有压力; 对精细力控与密集接触场景仍需额外传感/控制层或专用微调方法, 且对演示对齐质量较敏感 双臂协作的装配、整理、搬运与工具协同等任务, 数据有限但需高稳定性的工业/服务场景 ICLR 2025 RoboFlamingo[37] 以OpenFlamingo作为视觉−语言底座, 在少量目标机器人真实演示数据上通过监督微调进行后训练, 在多任务指令条件下显著提升了执行成功率与泛化能力 性能对指令−动作对齐质量与专家轨迹丰富度敏感; 在密集接触、强时延约束或高频闭环控制任务上仍受限, 需要额外控制器与安全机制 指令驱动的多任务桌面操作与服务场景、数据有限但可快速收集少量演示的部署 ICLR 2024 RT-2[10] 使用互联网数据和机器人轨迹数据预训练实现端到端机器人控制, 在少量目标机器人的真实演示数据上通过动作映射进行后训练, 赋予模型“语义推理”能力, 并在未见场景下显著提升任务成功率 依赖大规模跨域数据的对齐与清洗; 对密集接触/高精度控制需额外控制器与安全机制支持, 推理与部署成本较高; 操作泛化能力比较差 指令驱动、语义复杂且环境多变的服务/家居/仓储任务 CoRL 2023 UniVLA[65] 将视觉、语言与动作离散化为统一令牌序列, 并用单一自回归Transformer进行统一建模, 在结合世界模型预训练后, 在少量目标机器人真实数据上通过监督微调进行后训练, 显著提升了长时序任务的迁移能力与执行稳定性 离散化与自回归解码在高频控制下存在时延与信息损失风险; 世界模型预训练和对齐流程复杂, 对数据质量与时间对齐敏感 需要长程规划与多步骤执行的指令驱动任务、跨形态/跨场景迁移 arXiv 2025 VPP[46] 将视频扩散模型的未来表征嵌入策略网络, 以隐式方式学习逆动力学, 在少量目标任务的真实机器人数据上通过监督微调进行后训练, 显著提升了长时预测下的控制稳定性与样本效率 依赖视频扩散模型的质量与时序对齐, 训练/推理开销较高; 在密集接触与精细力控任务中可能存在动力学失配, 需要额外控制器或微调 长程、多步骤、需要前瞻规划的操作, 例如装配、整理、导航取放 ICML 2025 强化微调 ConRFT[146] 在预训练VLA的基础上, 采用一致性策略并结合人为干预, 通过在线强化学习在真实机器人上进行强化微调后训练; 仅需45$ \sim $90 min即可将任务成功率提升至96% 需要在线交互与人类干预, 工程与系统集成复杂度较高; 对一致性目标/超参较敏感, 迁移到密集接触或新设备时仍需额外调参与校准 真实机器人上的快速任务适配与性能冲刺, 尤其是密集接触、风险较高且需稳定性的工业/服务场景 arXiv 2025 GRAPE[147] 利用VLM将复杂任务分解为子目标并生成轨迹级偏好奖励, 在真实机器人交互数据上通过直接偏好优化(DPO)进行后训练, 无需额外人工标注即可提升任务成功率和与人类偏好的一致性 偏好可信度受VLM评估与分解粒度影响, 可能引入噪声或阶段性误导; 对长程依赖与接触密集场景仍需精心设计阶段/约束, 训练稳定性对数据分布较敏感 难以手工设计奖励, 但能获取交互数据的真实部署; 需要对齐人类偏好(安全、舒适、效率等)的服务/家居/协作操作以及多目标权衡的长程任务 arXiv 2025 iRe-VLA[148] 提出迭代式RL-SFT环(内环强化微调, 外环监督微调), 在真实与仿真任务数据上仅更新轻量动作解码器进行后训练, 实现高样本效率的稳定收敛, 并在多任务中保持良好的泛化性能 依赖在线交互与环路调度, 例如PPO超参、数据混合比例, 对安全与复位机制有要求; 骨干冻结限制了感知侧的进一步提升 真机/仿真均可交互、真实数据有限但需快速适配与稳健收敛的多任务部署 ICRA 2025 PARL[149] 在预训练VLA的基础上, 通过Q函数迭代优化动作, 并以模仿学习方式学习这些优化后的动作, 在真实机器人数据上进行后训练, 稳定提升模型的任务执行性能 质量高度依赖Q函数的准确性与覆盖度; 若Q学习出现过估计, 将把错误信号蒸馏进策略; 在线阶段仍需一定交互与工程调参(候选采样、优化步数等) 具备一定离线数据或Q函数容易训练的真实/仿真操控任务; 希望在不改动大模型骨干的前提下, 以低风险方式持续提升任务执行性能的工业与服务场景 ICLR 2024 Policy Decorator[150] 将大型离线模仿策略作为基础策略, 在真实机器人数据上在线叠加可学习残差控制器, 结合受控探索与信任域优化进行强化微调后训练, 实现对下层策略模型不可知、稳定且高效的性能提升 性能上限仍受基础策略能力与误差耦合制约; 残差与主策略的协同需要细致的权重/约束设计, 可能引入额外超参调试成本 已有成熟模仿策略部署、需在真实环境中快速提效且不希望改动主干的部署 ICLR 2025 ReinboT[151] 将强化学习的累计回报目标显式融入VLA损失函数, 在真实机器人数据上通过稳定的训练流程进行训练, 提升任务执行性能并保持训练收敛的稳定性 价值学习容易受到奖励设计/标注与时序的影响; 引入回报条件与价值分支增加系统与算力开销 具备一定真实交互或离线回放数据、希望在不大改骨干的前提下系统性提效的多任务部署 ICML 2025 RIPT-VLA[152] 在1-demo监督微调起点上, 通过交互式强化微调并结合RLOO确保梯度稳定, 在仿真环境中完成全部实验, 成功率可提升至97%, 验证了在极少示例条件下的高效任务学习能力 主要在仿真中验证, 真实部署的感知噪声与复位/安全成本未充分评估; 对二元成功信号与采样分组策略敏感, 探索策略易陷入局部最优 数据极度稀缺但可进行大量模拟交互的场景; 具有明确成败判据的短/中程操控任务 arXiv 2025 强化微调 RLDG[153] 在真实机器人上通过强化学习生成高质量的自监督轨迹, 并将这些“内生数据”蒸馏回大模型, 无需额外人类示范即可迭代提升模型性能, 实现真机环境下的高效自我改进 依赖稳健的在线RL基础设施与安全复位机制, 训练易受奖励设计/不稳定性影响; 真机交互与算力成本仍不低, 且策略采样数据可能带来偏置与遗忘风险, 需要精心的数据筛选与蒸馏配方 具备可自动判定成败/奖励的操作任务与可用机器人集群的场景; 希望以极少人类示范实现长期、持续迭代学习的真实部署 arXiv 2024 TGRPO[154] 在GRPO基础上进行拓展, 同时利用时间步级与轨迹级奖励对模型进行微调, 全部实验均在仿真环境中完成, 显著提升了连续控制任务的动作质量与长时序一致性 目前主要在仿真环境中验证, 真实环境中的感知噪声、延迟与安全约束尚未系统评估; 对组内采样与优势归一化等超参较敏感, 奖励/成功判据设计不当可能削弱收益 需要长程依赖与连续控制的多步骤操控, 例如装配、抓取−放置序列 arXiv 2025 VLA-RL[155] 在预训练VLA的基础上, 结合PPO与RPRM[155]进行微调, 并利用并行仿真环境加速训练, 全部实验均在仿真中完成, 实现了更快的收敛速度与更高的任务执行性能 基于仿真验证, 真实环境的传感噪声、延迟与安全约束尚未充分评估; 对超参与奖励设计敏感, 仿真到现实存在潜在性能落差 需要大规模离线/并行仿真进行策略筛选与组合搜索的多任务操控 arXiv 2025 推理扩展 FOREWARN[156] 利用VLM的轨迹评估能力, 对VLA生成的多个候选动作规划进行评估筛选, 在真实机器人数据上完成全部训练与验证, 避免奖励函数设计和值函数学习的需求, 并提升任务执行的稳定性与成功率 依赖VLM评估的可靠性与无偏性, 易受分布外场景与部分可观测性的影响; 多候选采样与评估带来计算与时延开销 难以手工设计奖励的真实部署任务、需要快速稳健提效而不改动训练流程的场景以及评估器判断可靠性高低的工业与服务机器人应用 arXiv 2025 Hume[60] 训练分层控制系统的S2系统通过预测值函数来评估生成动作序列的质量, 在仿真与真实机器人数据上进行训练与验证, 提升动作决策的可靠性与任务执行性能 分层架构与价值评估带来系统与推理复杂度、实时性开销; 价值学习对数据与超参敏感 需要深度推理与高频控制并存的复杂长程任务, 例如装配、工具使用与多步骤服务操作 arXiv 2025 ITPS[157] 在动作生成过程中允许人类通过交互方式输入轨迹偏好, 并通过引导扩散过程生成期望的动作序列, 在仿真与真实机器人数据上进行训练和验证, 提升模型对人类意图的响应能力与任务执行的可控性 需在线人机交互与额外推理开销; 偏好可行度低或引导强度不当可能导致过度约束或目标漂移, 对实时性与稳定性提出更高要求 需要按用户偏好动态定制行为的服务/协作任务、对安全与舒适有要求的真实部署 ICRA 2025 RoboMonkey[158] 提出一种“采样−验证”的推理期扩展框架, 并验证了动作误差与生成样本数量之间近似符合幂律关系, 在仿真与真实机器人数据上进行评估, 有效降低推理过程中的动作错误率并提升任务成功率 依赖高质量验证器与评估信号, 分布外场景可能失效; 多候选采样与验证增加推理时延与算力开销, 在实时高频控制与密集接触任务中需谨慎权衡 允许较大推理预算以换取稳健性的部署, 例如离线规划、低速高精度操作、关键任务执行前的安全校验 CoRL 2025 V-GPS[159] 针对同一指令在VLA上并行采样多条候选动作轨迹, 并利用实时视觉估计进行评分, 选择并平滑最优轨迹后下发控制, 在仿真与真实机器人数据上进行验证, 有效提升了安全性与成功率 依赖在线视觉感知与评分器可靠性, 多候选采样与评估增加推理时延与算力开销; 在密集接触操作中, 视觉滞后与估计误差导致评分偏差 对安全与稳健性要求高、允许一定推理预算的真实部署, 例如抓取与装配、拥挤/狭窄环境操作 CoRL 2024
下载: 导出CSV
表 4 不同VLA模型在真实环境中的测试结果[168]
Table 4 Test results of different VLA models in real-world environment[168]
排名 VLA模型 Score SD A/B Evals 1 $ \pi_{0.5} $-DROID 1883 26.1 339 2 PaliGemma-FAST-specialist-DROID 1851 25.8 741 3 $ \pi_{0} $-FAST-DROID 1814 24.8 505 4 PaliGemma-VQ-DROID 1765 33.3 526 5 PaliGemma-FAST-DROID 1759 35.5 723 6 PaliGemma-Diffusion-DROID 1585 56.4 514 7 DAM 1213 210.5 53 8 $ \pi_{0} $-DROID 894 28.5 781 9 PaliGemma-Bining-DROID 734 26.2 404
下载: 导出CSV
表 5 VLA测评基准与仿真器
Table 5 Evaluation benchmarks and simulators for VLA
仿真环境 仿真引擎 输入 机器人 任务 相关方法 CALVIN[175] PyBullet RGB/D, 语言指令 Franka Emika Panda 长序列、语言指令驱动的桌面操作任务 DreamVLA[68], GR-1[47], GR-2[48], RoboFlamingo[37], RoboVLMs[44], TriVLA[54], UniVLA[65], UP-VLA[63], VPP[46] Franka-Kitchen[179] MuJoCo RGB/D Franka Emika Panda 厨房多物体交互、多目标组合任务 HiRT[53] SimplerEnv[177] SAPIEN RGB/D, 语言指令 WindowX, Google Robot 多样化、语言指令驱动的桌面操作任务 CogACT[40], HPT[33], Hume[60], LAPA[49], Octo[30], OpenVLA[39], RoboVLMs[44], RT-1[21], SpatialVLA[69], TraceVLA[118], UniVLA[65] LIBERO[176] MuJoCo RGB/D, 语言指令 Franka Emika Panda 专注于终身学习的程序化生成任务 BitVLA[72], CoT-VLA[66], Fast ECoT[121], FLIP[180], Hume[60], NORA[122], OpenVLA[39], OpenVLA-OFT[77], SmolVLA[71], SpatialVLA[69], SP-VLA[181], TriVLA[54], UniAct[125], UniVLA[65], WorldVLA[67] Meta-World[173] MuJoCo RGB/D Sawyer 50种用于元学习/多任务学习的桌面操作任务 HiRT[53], HPT[33], TinyVLA[182], VPP[46] RLBench[172] CoppeliaSim RGB/D, 语言指令 Franka Emika Panda 100种大规模、带语言标注的多样化操作任务 HybridVLA[99] RoboMimic[183] MuJoCo RGB/D, 语言指令 Franka Emika Panda 基于人类演示的模仿学习任务集 HPT[33]
下载: 导出CSV
VLA模型 空间 对象 目标 长程 平均 $ \pi_0 $[42] 97 99 96 85 94 $ \pi_0 $-FAST[42] 96 97 89 60 86 BitVLA[72] 97 99 94 88 94 CoT-VLA[66] 88 92 88 69 84 Fast ECoT[121] 83 85 83 69 80 GR00T N1[57] 94 98 93 91 94 Hume[60] 97 99 99 97 98 NORA[122] 86 88 77 45 74 OpenVLA[39] 85 88 79 54 77 OpenVLA-OFT[77] 96 98 96 91 95 SmolVLA[71] 93 94 91 77 89 SpatialVLA[69] 88 90 79 56 78 SP-VLA[181] 75 86 84 54 75 TriVLA[54] 91 94 90 73 87 UniAct[125] 77 87 77 70 78 UniVLA[65] 97 97 96 92 95 WorldVLA[67] 73 88 80 27 67
下载: 导出CSV
表 7 不同VLA模型在SimplerEnv[177]中的测试结果(%)
Table 7 Test results of different VLA models in SimplerEnv[177] (%)
VLA模型 Google Robot WidowX Robot 拿可乐罐 移动物体 开/关抽屉 把物体放进抽屉 把胡萝卜放到盘子里 把勺子放在毛巾上 叠方块 把鸡蛋放到篮子里 $ \pi_0 $[42] 73 65 38 — 0 29 17 63 $ \pi_0 $-FAST[42] 75 68 43 62 22 29 83 48 CogACT[40] 91 85 72 51 51 72 15 68 HPT[175] 60 24 56 — — — — — Hume[60] 97 80 59 — 67 58 46 73 LAPA[49] — — — — 46 71 54 58 Octo-Small[30] — — — — 10 47 4 57 Octo-Base[30] 17 4 23 — 8 13 0 43 OpenVLA[39] 16 46 36 — 0 0 0 4 RoboVLMs[44] 77 62 43 24 21 46 4 79 RT-1[21] 3 5 14 — 4 0 0 0 SpatialVLA[69] 86 78 57 75 25 17 29 43 TraceVLA[118] 44 55 44 — — — — — UniVLA[65] — — — — 56 53 3 81
下载: 导出CSV
表 8 国内外产业界发布的VLA模型
Table 8 Industrial VLA models released domestically and internationally
公司 代表模型 应用场景 国外 Google RT-2[10], Gemini Robotics[59] 通用桌面操作场景 NVIDIA GR00T N1[57], GR00T N1.5 人形移动操作场景 Figure AI Helix[56] 家居场景、工业场景、物流场景 Physical Intelligence $ \pi_0 $[42], $ \pi_{0.5} $[78] 家居场景 国内 字节跳动 RoboFlamingo[37], GR-1[47], GR-2[48], GR-3[138] 通用桌面操作场景 阿里巴巴 RynnVLA-001[188] 桌面操作场景 美的 DexVLA[187], ChatVLA[50], ChatVLA-2[94] 通用桌面操作场景 银河通用 GraspVLA[117] 桌面抓放场景 智元 G0-1[64] 桌面操作场景 星海图 G0[190] 移动操作场景 星尘智能 DuoCore-WB[191], ControlVLA[192] 移动操作场景、家居场景 自变量 WALL-OSS[189] 桌面操作场景 灵初智能 DexGraspVLA[55] 桌面操作场景
下载: 导出CSV
-
[1] Chen Y R, Cui W B, Chen Y W, Tan M N, Zhang X Y, Liu J R, et al. RoboGPT: An LLM-based long-term decision-making embodied agent for instruction following tasks. IEEE Transactions on Cognitive and Developmental Systems, 2025, 17(5): 1163−1174 doi: 10.1109/TCDS.2025.3543364 [2] Jin Y X, Li D Z, A Y, Shi J, Hao P, Sun F C, et al. RobotGPT: Robot manipulation learning from ChatGPT. IEEE Robotics and Automation Letters, 2024, 9(3): 2543−2550 doi: 10.1109/LRA.2024.3357432 [3] 白辰甲, 许华哲, 李学龙. 大模型驱动的具身智能: 发展与挑战. 中国科学: 信息科学, 2024, 54(9): 2035−2082 doi: 10.1360/SSI-2024-0076Bai Chen-Jia, Xu Hua-Zhe, Li Xue-Long. Embodied-AI with large models: Research and challenges. SCIENTIA SINICA Informationis, 2024, 54(9): 2035−2082 doi: 10.1360/SSI-2024-0076 [4] 王文晟, 谭宁, 黄凯, 张雨浓, 郑伟诗, 孙富春. 基于大模型的具身智能系统综述. 自动化学报, 2025, 51(1): 1−19 doi: 10.16383/j.aas.c240542Wang Wen-Sheng, Tan Ning, Huang Kai, Zhang Yu-Nong, Zheng Wei-Shi, Sun Fu-Chun. Embodied intelligence systems based on large models: A survey. Acta Automatica Sinica, 2025, 51(1): 1−19 doi: 10.16383/j.aas.c240542 [5] Ma Y E, Song Z X, Zhuang Y Z, Hao J Y, King I. A survey on vision-language-action models for embodied AI. arXiv preprint arXiv: 2405.14093, 2024. [6] Sapkota R, Cao Y, Roumeliotis K I, Karkee M. Vision-language-action models: Concepts, progress, applications and challenges. arXiv preprint arXiv: 2505.04769, 2025. [7] Zhong Y F, Bai F S, Cai S F, Huang X C, Chen Z, Zhang X W, et al. A survey on vision-language-action models: An action tokenization perspective. arXiv preprint arXiv: 2507.01925, 2025. [8] Xiang T Y, Jin A Q, Zhou X H, Gui M J, Xie X L, Liu S Q, et al. Parallels between VLA model post-training and human motor learning: Progress, challenges, and trends. arXiv preprint arXiv: 2506.20966, 2025. [9] Din M U, Akram W, Saoud L S, Rosell J, Hussain I. Vision language action models in robotic manipulation: A systematic review. arXiv preprint arXiv: 2507.10672, 2025. [10] Zitkovich B, Yu T H, Xu S C, Xu P, Xiao T, Xia F, et al. RT-2: Vision-language-action models transfer web knowledge to robotic control. In: Proceedings of the Conference on Robot Learning. Atlanta, USA: PMLR, 2023. 2165−2183 [11] Zhen H Y, Qiu X W, Chen P H, Yang J C, Yan X, Du Y L, et al. 3D-VLA: A 3D vision-language-action generative world model. In: Proceedings of the 41st International Conference on Machine Learning. Vienna, Austria: OpenReview.net, 2024. [12] Yu J W, Liu H R, Yu Q J, Ren J J, Hao C, Ding H T, et al. ForceVLA: Enhancing VLA models with a force-aware MoE for contact-rich manipulation. arXiv preprint arXiv: 2505.22159, 2025. [13] Zhang C F, Hao P, Cao X G, Hao X S, Cui S W, Wang S. VTLA: Vision-tactile-language-action model with preference learning for insertion manipulation. arXiv preprint arXiv: 2505.09577, 2025. [14] Matuszek C. Grounded language learning: Where robotics and NLP meet. In: Proceedings of the 27th International Joint Conference on Artificial Intelligence. Stockholm, Sweden: IJCAI, 2018. 5687−5691 [15] Stepputtis S, Campbell J, Phielipp M, Lee S, Baral C, ben Amor H. Language-conditioned imitation learning for robot manipulation tasks. In: Proceedings of the 34th International Conference on Neural Information Processing Systems. Vancouver, Canada: Curran Associates, 2020. Article No. 1102 [16] Shridhar M, Manuelli L, Fox D. CLIPort: What and where pathways for robotic manipulation. In: Proceedings of the Conference on Robot Learning. London, UK: PMLR, 2021. 894−906 [17] Radford A, Kim J W, Hallacy C, Ramesh A, Goh G, Agarwal S, et al. Learning transferable visual models from natural language supervision. In: Proceedings of the 38th International Conference on Machine Learning. Virtual Event: PMLR, 2021. 8748−8763 [18] Zeng A, Florence P, Thompson J, Welker S, Chien J, Attarian M, et al. Transporter networks: Rearranging the visual world for robotic manipulation. In: Proceedings of the 4th Conference on Robot Learning. Cambridge, USA: PMLR, 2020. 726−747 [19] Perez E, Strub F, de Vries H, Dumoulin V, Courville A. FiLM: Visual reasoning with a general conditioning layer. In: Proceedings of the 32nd AAAI Conference on Artificial Intelligence. New Orleans, USA: AAAI Press, 2018. 3942−3951 [20] Jang E, Irpan A, Khansari M, Kappler D, Ebert F, Lynch C, et al. BC-Z: Zero-shot task generalization with robotic imitation learning. In: Proceedings of the 5th Conference on Robot Learning. London, UK: PMLR, 2021. 991−1002 [21] Brohan A, Brown N, Carbajal J, Chebotar Y, Dabis J, Finn C, et al. RT-1: Robotics Transformer for real-world control at scale. In: Proceedings of the 19th Robotics: Science and Systems. Daegu, South Korea: IEEE Robotics and Automation Society, 2023. [22] Tan M X, Le Q V. EfficientNet: Rethinking model scaling for convolutional neural networks. In: Proceedings of the 36th International Conference on Machine Learning. Long Beach, USA: PMLR, 2019. 6105−6114 [23] Cer D, Yang Y F, Kong S Y, Hua N, Limtiaco N, St. John R, et al. Universal sentence encoder for English. In: Proceedings of the Empirical Methods in Natural Language Processing. Brussels, Belgium: ACL, 2018. 169−174 [24] Jiang Y F, Gupta A, Zhang Z C, Wang G Z, Dou Y Q, Chen Y J, et al. VIMA: Robot manipulation with multimodal prompts. In: Proceedings of the 40th International Conference on Machine Learning. Honolulu, USA: ACM, 2023. Article No. 611 [25] Reed S E, Zolna K, Parisotto E, Gómez Colmenarejo S, Novikov A, Barth-Maron G, et al. A generalist agent. Transactions on Machine Learning Research, 2022: 1−42 [26] Zhao T Z, Kumar V, Levine S, Finn C. Learning fine-grained bimanual manipulation with low-cost hardware. In: Proceedings of the 19th Robotics: Science and Systems. Daegu, South Korea: IEEE Robotics and Automation Society, 2023. [27] Chi C, Feng S Y, Du Y L, Xu Z J, Cousineau E, Burchfiel B, et al. Diffusion policy: Visuomotor policy learning via action diffusion. In: Proceedings of the 19th Robotics: Science and Systems. Daegu, South Korea: IEEE Robotics and Automation Society, 2023. [28] Chen Y H, Li H R, Zhao D B. Boosting continuous control with consistency policy. In: Proceedings of the 23rd International Conference on Autonomous Agents and Multiagent Systems. Auckland, New Zealand: ACM, 2024. 335−344 [29] Li H R, Jiang Z N, Chen Y H, Zhao D B. Generalizing consistency policy to visual RL with prioritized proximal experience regularization. In: Proceedings of the 38th International Conference on Neural Information Processing Systems. Vancouver, Canada: Curran Associates, 2024. Article No. 3480 [30] Ghosh D, Walke H R, Pertsch K, Black K, Mees O, Dasari S, et al. Octo: An open-source generalist robot policy. arXiv preprint arXiv: 2405.12213, 2024. [31] Liu S M, Wu L X, Li B G, Tan H K, Chen H Y, Wang Z Y, et al. RDT-1B: A diffusion foundation model for bimanual manipulation. In: Proceedings of the 13th International Conference on Learning Representations. Singapore: OpenReview.net, 2025. [32] O'Neill A, Rehman A, Maddukuri A, Gupta A, Padalkar A, Lee A, et al. Open X-embodiment: Robotic learning datasets and RT-X models: Open X-embodiment collaboration. In: Proceedings of the International Conference on Robotics and Automation (ICRA). Yokohama, Japan: IEEE, 2024. 6892−6903 [33] Wang L R, Chen X L, Zhao J L, He K M. Scaling proprioceptive-visual learning with heterogeneous pre-trained Transformers. In: Proceedings of the 38th International Conference on Neural Information Processing Systems. Vancouver, Canada: Curran Associates, 2024. Article No. 3952 [34] Ma N Y, Goldstein M, Albergo M S, Boffi N M, Vanden-Eijnden E, Xie S N. SiT: Exploring flow and diffusion-based generative models with scalable interpolant Transformers. In: Proceedings of the 18th European Conference on Computer Vision. Milan, Italy: Springer, 2024. 23−40 [35] Zhai X H, Mustafa B, Kolesnikov A, Beyer L. Sigmoid loss for language image pre-training. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). Paris, France: IEEE, 2023. 11941−11952 [36] Driess D, Xia F, Sajjadi M S M, Lynch C, Chowdhery A, Ichter B, et al. PaLM-E: An embodied multimodal language model. In: Proceedings of the 40th International Conference on Machine Learning. Honolulu, USA: ACM, 2023. Article No. 340 [37] Li X H, Liu M H, Zhang H B, Yu C J, Xu J, Wu H T, et al. Vision-language foundation models as effective robot imitators. In: Proceedings of the 12th International Conference on Learning Representations. Vienna, Austria: OpenReview.net, 2024. [38] Alayrac J B, Donahue J, Luc P, Miech A, Barr I, Hasson Y, et al. Flamingo: A visual language model for few-shot learning. In: Proceedings of the 36th International Conference on Neural Information Processing Systems. New Orleans, USA: Curran Associates, 2022. Article No. 1723 [39] Kim M J, Pertsch K, Karamcheti S, Xiao T, Balakrishna A, Nair S, et al. OpenVLA: An open-source vision-language-action model. In: Proceedings of the 8th Conference on Robot Learning. Munich, Germany: PMLR, 2024. 2679−2713 [40] Li Q X, Liang Y B, Wang Z Y, Luo L, Chen X, Liao M Z, et al. CogACT: A foundational vision-language-action model for synergizing cognition and action in robotic manipulation. arXiv preprint arXiv: 2411.19650, 2024. [41] Touvron H, Lavril T, Izacard G, Martinet X, Lachaux M A, Lacroix T, et al. LLaMA: Open and efficient foundation language models. arXiv preprint arXiv: 2302.13971, 2023. [42] Black K, Brown N, Driess D, Esmail A, Equi M, Finn C, et al. π0: A vision-language-action flow model for general robot control. In: Proceedings of the Robotics: Science and Systems. San Francisco, USA: IEEE Robotics and Automation Society, 2025. [43] Beyer L, Steiner A, Pinto A S, Kolesnikov A, Wang X, Salz D, et al. PaliGemma: A versatile 3B VLM for transfer. arXiv preprint arXiv: 2407.07726, 2024. [44] Li X H, Li P Y, Liu M H, Wang D, Liu J R, Kang B Y, et al. Towards generalist robot policies: What matters in building vision-language-action models. arXiv preprint arXiv: 2412.14058, 2024. [45] Du Y L, Yang M J, Dai B, Dai H J, Nachum O, Tenenbaum J B, et al. Learning universal policies via text-guided video generation. In: Proceedings of the 37th International Conference on Neural Information Processing Systems. New Orleans, USA: Curran Associates, 2023. Article No. 403 [46] Hu Y C, Guo Y J, Wang P C, Chen X Y, Wang Y J, Zhang J K, et al. Video prediction policy: A generalist robot policy with predictive visual representations. In: Proceedings of the 42nd International Conference on Machine Learning. Vancouver, Canada: OpenReview.net, 2025. [47] Wu H T, Jing Y, Cheang C, Chen G Z, Xu J F, Li X H, et al. Unleashing large-scale video generative pre-training for visual robot manipulation. In: Proceedings of the 12th International Conference on Learning Representations. Vienna, Austria: OpenReview.net, 2024. [48] Cheang C L, Chen G Z, Jing Y, Kong T, Li H, Li Y F, et al. GR-2: A generative video-language-action model with web-scale knowledge for robot manipulation. arXiv preprint arXiv: 2410.06158, 2024. [49] Ye S, Jang J, Jeon B, Joo S J, Yang J W, Peng B L, et al. Latent action pretraining from videos. In: Proceedings of the 13th International Conference on Learning Representations. Singapore: OpenReview.net, 2025. [50] Zhou Z Y, Zhu Y C, Zhu M J, Wen J J, Liu N, Xu Z Y, et al. ChatVLA: Unified multimodal understanding and robot control with vision-language-action model. arXiv preprint arXiv: 2502.14420, 2025. [51] Bu Q W, Li H Y, Chen L, Cai J S, Zeng J, Cui H M, et al. Towards synergistic, generalized, and efficient dual-system for robotic manipulation. arXiv preprint arXiv: 2410.08001, 2024. [52] Shi L X, Ichter B, Equi M R, Ke L Y M, Pertsch K, Vuong Q, et al. Hi Robot: Open-ended instruction following with hierarchical vision-language-action models. In: Proceedings of the 42nd International Conference on Machine Learning. Vancouver, Canada: OpenReview.net, 2025. [53] Zhang J K, Guo Y J, Chen X Y, Wang Y J, Hu Y C, Shi C M, et al. HiRT: Enhancing robotic control with hierarchical robot Transformers. In: Proceedings of the 8th Conference on Robot Learning. Munich, Germany: PMLR, 2024. 933−946 [54] Liu Z Y, Gu Y C, Zheng S X, Xue X Y, Fu Y W. TriVLA: A unified triple-system-based unified vision-language-action model for general robot control. arXiv preprint arXiv: 2507.01424, 2025. [55] Zhong Y F, Huang X C, Li R C, Zhang C Y, Liang Y T, Yang Y D, et al. DexGraspVLA: A vision-language-action framework towards general dexterous grasping. arXiv preprint arXiv: 2502.20900, 2025. [56] Cui C, Ding P X, Song W X, Bai S H, Tong X Y, Ge Z R, et al. OpenHelix: A short survey, empirical analysis, and open-source dual-system VLA model for robotic manipulation. arXiv preprint arXiv: 2505.03912, 2025. [57] Bjorck J, Castañeda F, Cherniadev N, Da X Y, Ding R Y, Fan L X, et al. GR00T N1: An open foundation model for generalist humanoid robots. arXiv preprint arXiv: 2503.14734, 2025. [58] Chen H, Liu J M, Gu C Y, Liu Z Y, Zhang R R, Li X Q, et al. Fast-in-Slow: A dual-system foundation model unifying fast manipulation within slow reasoning. arXiv preprint arXiv: 2506.01953, 2025. [59] Gemini Robotics Team. Gemini robotics: Bringing AI into the physical world. arXiv preprint arXiv: 2503.20020, 2025. [60] Song H M, Qu D L, Yao Y Q, Chen Q Z, Lv Q, Tang Y W, et al. Hume: Introducing system-2 thinking in visual-language-action model. arXiv preprint arXiv: 2505.21432, 2025. [61] Zawalski M, Chen W, Pertsch K, Mees O, Finn C, Levine S. Robotic control via embodied chain-of-thought reasoning. In: Proceedings of the 8th Conference on Robot Learning. Munich, Germany: PMLR, 2024. 3157−3181 [62] Sun Q, Hong P F, Pala T D, Toh V, Tan U X, Ghosal D, et al. Emma-X: An embodied multimodal action model with grounded chain of thought and look-ahead spatial reasoning. In: Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics. Vienna, Austria: ACL, 2025. 14199−14214 [63] Zhang J K, Guo Y J, Hu Y C, Chen X Y, Zhu X, Chen J Y. UP-VLA: A unified understanding and prediction model for embodied agent. arXiv preprint arXiv: 2501.18867, 2025. [64] Team AgiBot-World. AgiBot World Colosseo: A large-scale manipulation platform for scalable and intelligent embodied systems. arXiv preprint arXiv: 2503.06669, 2025. [65] Bu Q W, Yang Y T, Cai J S, Gao S Y, Ren G H, Yao M Q, et al. UniVLA: Learning to act anywhere with task-centric latent actions. arXiv preprint arXiv: 2505.06111, 2025. [66] Zhao Q Q, Lu Y, Kim M J, Fu Z P, Zhang Z Y, Wu Y C, et al. CoT-VLA: Visual chain-of-thought reasoning for vision-language-action models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Nashville, USA: IEEE, 2025. 1702−1713 [67] Cen J, Yu C H, Yuan H J, Jiang Y M, Huang S T, Guo J Y, et al. WorldVLA: Towards autoregressive action world model. arXiv preprint arXiv: 2506.21539, 2025. [68] Zhang W Y, Liu H S, Qi Z K, Wang Y N, Yu X Q, Zhang J Z, et al. DreamVLA: A vision-language-action model dreamed with comprehensive world knowledge. arXiv preprint arXiv: 2507.04447, 2025. [69] Qu D L, Song H M, Chen Q Z, Wang D, Yao Y Q, Ye X Y, et al. SpatialVLA: Exploring spatial representations for visual-language-action model. In: Proceedings of the Robotics: Science and Systems. Los Angeles, USA: IEEE Robotics and Automation Society, 2025. [70] Niu D T, Sharma Y, Xue H R, Biamby G, Zhang J Y, Ji Z T, et al. Pre-training auto-regressive robotic models with 4D representations. arXiv preprint arXiv: 2502.13142, 2025. [71] Shukor M, Aubakirova D, Capuano F, Kooijmans P, Palma S, Zouitine A, et al. SmolVLA: A vision-language-action model for affordable and efficient robotics. arXiv preprint arXiv: 2506.01844, 2025. [72] Wang H Y, Xiong C Y, Wang R P, Chen X L. BitVLA: 1-bit vision-language-action models for robotics manipulation. arXiv preprint arXiv: 2506.07530, 2025. [73] Yang Y T, Wang Y H, Wen Z C, Luo Z W, Zou C, Zhang Z P, et al. EfficientVLA: Training-free acceleration and compression for vision-language-action models. arXiv preprint arXiv: 2506.10100, 2025. [74] Black K, Galliker M Y, Levine S. Real-time execution of action chunking flow policies. arXiv preprint arXiv: 2506.07339, 2025. [75] Dosovitskiy A, Beyer L, Kolesnikov A, Weissenbern D, Zhai X H, Unterthiner T, et al. An image is worth 16×16 words: Transformers for image recognition at scale. arXiv preprint arXiv: 2010.11929, 2021. [76] Oquab M, Darcet T, Moutakanni T, Vo H V, Szafraniec M, Khalidov V, et al. DINOv2: Learning robust visual features without supervision. arXiv preprint arXiv: 2304.07193, 2024. [77] Kim M J, Finn C, Liang P. Fine-tuning vision-language-action models: Optimizing speed and success. arXiv preprint arXiv: 2502.19645, 2025. [78] Black K, Brown N, Dharpanian J, Dhabalia K, Driess D, Esmail A, et al. π0.5: A vision-language-action model with open-world generalization. In: Proceedings of the 9th Conference on Robot Learning. Seoul, South Korea: PMLR, 2025. 17−40 [79] Pertsch K, Stachowicz K, Ichter B, Driess D, Nair S, Vuong Q, et al. FAST: Efficient action tokenization for vision-language-action models. arXiv preprint arXiv: 2501.09747, 2025. [80] Li C M, Wen J J, Peng Y, Peng Y X, Feng F F, Zhu Y C. PointVLA: Injecting the 3D world into vision-language-action models. arXiv preprint arXiv: 2503.07511, 2025. [81] Cui W B, Zhao C Y, Chen Y H, Li H R, Zhang Z Z, Zhao D B, et al. CL3R: 3D reconstruction and contrastive learning for enhanced robotic manipulation representations. arXiv preprint arXiv: 2507.08262, 2025. [82] Li Y X, Chen Y H, Zhou M C, Li H R. QDepth-VLA: Quantized depth prediction as auxiliary supervision for vision-language-action models. arXiv preprint arXiv: 2510.14836, 2025. [83] Lyu J R, Li Z M, Shi X S, Xu C Y, Wang Y Z, Wang H. DyWA: Dynamics-adaptive world action model for generalizable non-prehensile manipulation. arXiv preprint arXiv: 2503.16806, 2025. [84] Yang R J, Chen G, Wen C, Gao Y. FP3: A 3D foundation policy for robotic manipulation. arXiv preprint arXiv: 2503.08950, 2025. [85] Singh I, Goyal A, Birchfield S, Fox D, Garg A, Blukis V. OG-VLA: 3D-aware vision language action model via orthographic image generation. arXiv preprint arXiv: 2506.01196, 2025. [86] Li P Y, Chen Y X, Wu H T, Ma X, Wu X N, Huang Y, et al. BridgeVLA: Input-output alignment for efficient 3D manipulation learning with vision-language models. arXiv preprint arXiv: 2506.07961, 2025. [87] Jia Y R, Liu J M, Chen S X, Gu C Y, Wang Z, Luo L Z, et al. Lift3D Policy: Lifting 2D foundation models for robust 3D robotic manipulation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Nashville, USA: IEEE, 2025. 17347−17358 [88] Goyal A, Xu J, Guo Y J, Blukis V, Chao Y W, Fox D. RVT: Robotic view Transformer for 3D object manipulation. In: Proceedings of the 7th Conference on Robot Learning. Atlanta, USA: PMLR, 2023. 694−710 [89] Goyal A, Blukis V, Xu J, Guo Y J, Chao Y W, Fox D. RVT-2: Learning precise manipulation from few demonstrations. arXiv preprint arXiv: 2406.08545, 2024. [90] Hao P, Zhang C F, Li D Z, Cao X G, Hao X S, Cui S W, et al. TLA: Tactile-language-action model for contact-rich manipulation. arXiv preprint arXiv: 2503.08548, 2025. [91] Huang J L, Wang S, Lin F Q, Hu Y H, Wen C, Gao Y. Tactile-VLA: Unlocking vision-language-action model's physical knowledge for tactile generalization. arXiv preprint arXiv: 2507.09160, 2025. [92] Sun Y H, Cheng N, Zhang S X, Li W Z, Yang L Y, Cui S W, et al. Tactile data generation and applications based on visuo-tactile sensors: A review. Information Fusion, 2025, 121: Article No. 103162 doi: 10.1016/j.inffus.2025.103162 [93] Feng R X, Hu J Y, Xia W K, Gao T C, Shen A, Sun Y H, et al. AnyTouch: Learning unified static-dynamic representation across multiple visuo-tactile sensors. In: Proceedings of the 13th International Conference on Learning Representations. Singapore: OpenReview.net, 2025. [94] Zhou Z Y, Zhu Y C, Wen J J, Shen C M, Xu Y. ChatVLA-2: Vision-language-action model with open-world embodied reasoning from pretrained knowledge. arXiv preprint arXiv: 2505.21906, 2025. [95] Gu A, Dao T. Mamba: Linear-time sequence modeling with selective state spaces. arXiv preprint arXiv: 2312.00752, 2024. [96] Liu J M, Liu M Z, Wang Z Y, An P J, Li X Q, Zhou K C, et al. RoboMamba: Efficient vision-language-action model for robotic reasoning and manipulation. In: Proceedings of the 38th International Conference on Neural Information Processing Systems. Vancouver, Canada: Curran Associates, 2024. Article No. 1266 [97] Shafiullah N M, Cui Z J, Altanzaya A, Pinto L. Behavior Transformers: Cloning k modes with one stone. In: Proceedings of the 36th International Conference on Neural Information Processing Systems. New Orleans, USA: Curran Associates, 2022. Article No. 1668 [98] Lee S J, Wang Y B, Etukuru H, Kim H J, Shafiullah N M, Pinto L. Behavior generation with latent actions. In: Proceedings of the 41st International Conference on Machine Learning. Vienna, Austria: OpenReview.net, 2024. [99] Liu J M, Chen H, An P J, Liu Z Y, Zhang R R, Gu C Y, et al. HybridVLA: Collaborative diffusion and autoregression in a unified vision-language-action model. arXiv preprint arXiv: 2503.10631, 2025. [100] Driess D, Springenberg J T, Ichter B, Yu L L, Li-Bell A, Pertsch K, et al. Knowledge insulating vision-language-action models: Train fast, run fast, generalize better. arXiv preprint arXiv: 2505.23705, 2025. [101] Yu Q Y, Sun Q, Zhang X S, Cui Y F, Zhang F, Cao Y, et al. CapsFusion: Rethinking image-text data at scale. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, USA: IEEE, 2024. 14022−14032 [102] Lin T Y, Maire M, Belongie S, Hays J, Perona P, Ramanan D, et al. Microsoft COCO: Common objects in context. In: Proceedings of the 13th European Conference on Computer Vision. Zurich, Switzerland: Springer, 2014. 740−755 [103] Hudson D A, Manning C D. GQA: A new dataset for real-world visual reasoning and compositional question answering. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, USA: IEEE, 2019. 6693−6702 [104] Schuhmann C, Vencu R, Beaumont R, Kaczmarczyk R, Mullis C, Katta A, et al. LAION-400M: Open dataset of CLIP-filtered 400 million image-text pairs. arXiv preprint arXiv: 2111.02114, 2021. [105] Deitke M, Clark C, Lee S, Tripathi R, Yang Y, Park J S, et al. Molmo and PixMo: Open weights and open data for state-of-the-art vision-language models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Nashville, USA: IEEE, 2025. 91−104 [106] Singh A, Natarajan V, Shah M, Jiang Y, Chen X L, Batra D, et al. Towards VQA models that can read. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, USA: IEEE, 2019. 8309−8318 [107] Jia Z H, Zhang Z C, Qian J Y, Wu H N, Sun W, Li C Y, et al. VQA2: Visual question answering for video quality assessment. arXiv preprint arXiv: 2411.03795, 2024. [108] Wang X, Alabdulmohsin I, Salz D, Li Z, Rong K, Zhai X H. Scaling pre-training to one hundred billion data for vision language models. arXiv preprint arXiv: 2502.07617, 2025. [109] Grauman K, Westbury A, Byrne E, Chavis Z, Furnari A, Girdhar R, et al. Ego4D: Around the world in 3 000 hours of egocentric video. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New Orleans, USA: IEEE, 2022. 18973−18990 [110] Yang J W, Tan R, Wu Q H, Zheng R J, Peng B L, Liang Y Y, et al. Magma: A foundation model for multimodal AI agents. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, USA: IEEE, 2025. 14203−14214 [111] Grauman K, Westbury A, Torresani L, Kitani K, Malik J, Afouras T, et al. Ego-Exo4D: Understanding skilled human activity from first-and third-person perspectives. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, USA: IEEE, 2024. 19383−19400 [112] Damen D, Doughty H, Farinella G M, Fidler S, Furnari A, Kazakos E, et al. Scaling egocentric vision: The EPIC-KITCHENS dataset. arXiv preprint arXiv: 1804.02748, 2018. [113] Carreira J, Noland E, Hillier C, Zisserman A. A short note on the kinetics-700 human action dataset. arXiv preprint arXiv: 1907.06987, 2019. [114] Goyal R, Kahou S E, Michalski V, Materzynska J, Westphal S, Kim H, et al. The “something something” video database for learning and evaluating visual common sense. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV). Venice, Italy: IEEE, 2017. 5843−5851 [115] Jiang Z Y, Xie Y Q, Lin K, Xu Z J, Wan W K, Mandlekar A, et al. DexMimicGen: Automated data generation for bimanual dexterous manipulation via imitation learning. In: Proceedings of the IEEE International Conference on Robotics and Automation (ICRA). Atlanta, USA: IEEE, 2025. 16923−16930 [116] Nasiriany S, Maddukuri A, Zhang L C, Parikh A, Lo A, Joshi A, et al. RoboCasa: Large-scale simulation of everyday tasks for generalist robots. arXiv preprint arXiv: 2406.02523, 2024. [117] Deng S L, Yan M, Wei S L, Ma H X, Yang Y X, Chen J Y, et al. GraspVLA: A grasping foundation model pre-trained on billion-scale synthetic action data. arXiv preprint arXiv: 2505.03233, 2025. [118] Zheng R J, Liang Y Y, Huang S Y, Gao J F, Daumé Ⅲ H, Kolobov A, et al. TraceVLA: Visual trace prompting enhances spatial-temporal awareness for generalist robotic policies. In: Proceedings of the 13th International Conference on Learning Representations. Singapore: OpenReview.net, 2025. [119] Ebert F, Yang Y L, Schmeckpeper K, Bucher B, Georgakis G, Daniilidis K, et al. Bridge data: Boosting generalization of robotic skills with cross-domain datasets. arXiv preprint arXiv: 2109.13396, 2021. [120] Walke H R, Black K, Zhao T Z, Vuong Q, Zheng C Y, Hansen-Estruch P, et al. BridgeData V2: A dataset for robot learning at scale. In: Proceedings of the 7th Conference on Robot Learning. Atlanta, USA: PMLR, 2023. 1723−1736 [121] Duan Z K, Zhang Y, Geng S K, Liu G W, Boedecker J, Lu C X. Fast ECoT: Efficient embodied chain-of-thought via thoughts reuse. arXiv preprint arXiv: 2506.07639, 2025. [122] Hung C Y, Sun Q, Hong P F, Zadeh A, Li C, Tan U X, et al. NORA: A small open-sourced generalist vision language action model for embodied tasks. arXiv preprint arXiv: 2504.19854, 2025. [123] Khazatsky A, Pertsch K, Nair S, Balakrishna A, Dasari S, Karamcheti S, et al. DROID: A large-scale in-the-wild robot manipulation dataset. arXiv preprint arXiv: 2403.12945, 2025. [124] Wen J J, Zhu Y C, Zhu M J, Tang Z B, Li J M, Zhou Z Y, et al. DiffusionVLA: Scaling robot foundation models via unified diffusion and autoregression. In: Proceedings of the 42nd International Conference on Machine Learning. Vancouver, Canada: OpenReview.net, 2025. [125] Zheng J L, Li J X, Liu D X, Zheng Y N, Wang Z H, Ou Z H, et al. Universal actions for enhanced embodied foundation models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Nashville, USA: IEEE, 2025. 22508−22519 [126] Fu Z P, Zhao T Z, Finn C. Mobile ALOHA: Learning bimanual mobile manipulation using low-cost whole-body teleoperation. In: Proceedings of the 8th Conference on Robot Learning. Munich, Germany: PMLR, 2024. 4066−4083 [127] Fang H S, Fang H J, Tang Z Y, Liu J R, Wang C X, Wang J B, et al. RH20T: A comprehensive robotic dataset for learning diverse skills in one-shot. In: Proceedings of the IEEE International Conference on Robotics and Automation (ICRA). Yokohama, Japan: IEEE, 2024. 653−660 [128] Kumar V, Shah R, Zhou G Y, Moens V, Caggiano V, Vakil J, et al. RoboHive: A unified framework for robot learning. In: Proceedings of the 37th International Conference on Neural Information Processing Systems. New Orleans, USA: Curran Associates, 2023. Article No. 1918 [129] Wu K, Hou C K, Liu J M, Che Z P, Ju X Z, Yang Z Q, et al. RoboMIND: Benchmark on multi-embodiment intelligence normative data for robot manipulation. arXiv preprint arXiv: 2412.13877, 2024. [130] Bharadhwaj H, Dwibedi D, Gupta A, Tulsiani S, Doersch C, Xiao T, et al. Gen2Act: Human video generation in novel scenarios enables generalizable robot manipulation. In: Proceedings of the 9th Conference on Robot Learning. Seoul, South Korea: PMLR, 2025. [131] Yang R H, Yu Q X, Wu Y C, Yan R, Li B R, Cheng A C, et al. EgoVLA: Learning vision-language-action models from egocentric human videos. arXiv preprint arXiv: 2507.12440, 2025. [132] Luo H, Feng Y C, Zhang W P, Zheng S P, Wang Y, Yuan H Q, et al. Being-H0: Vision-language-action pretraining from large-scale human videos. arXiv preprint arXiv: 2507.15597, 2025. [133] Liu X, Chen Y R, Li H R. Sample-efficient unsupervised policy cloning from ensemble self-supervised labeled videos. In: Proceedings of the IEEE International Conference on Robotics and Automation (ICRA). Atlanta, USA: IEEE, 2025. 3632−3639 [134] Chen T X, Chen Z X, Chen B J, Cai Z J, Liu Y B, Liang Q W, et al. RobotWIN 2.0: A scalable data generator and benchmark with strong domain randomization for robust bimanual robotic manipulation. arXiv preprint arXiv: 2506.18088, 2025. [135] Liu W H, Wan Y X, Wang J L, Kuang Y X, Cui W B, Shi X S, et al. FetchBot: Learning generalizable object fetching in cluttered shelves via zero-shot Sim2Real. arXiv preprint arXiv: 2502.17894, 2025. [136] Wang Z Q, Zheng H, Nie Y S, Xu W J, Wang Q W, Ye H, et al. All robots in one: A new standard and unified dataset for versatile, general-purpose embodied agents. arXiv preprint arXiv: 2408.10899, 2024. [137] Esser P, Rombach R, Ommer B. Taming Transformers for high-resolution image synthesis. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Nashville, USA: IEEE, 2021. 12868−12878 [138] Cheang C, Chen S J, Cui Z R, Hu Y D, Huang L Q, Kong T, et al. GR-3 technical report. arXiv preprint arXiv: 2507.15493, 2025. [139] Clark J, Mirchandani S, Sadigh D, Belkhale S. Action-free reasoning for policy generalization. arXiv preprint arXiv: 2502.03729, 2025. [140] Tang W L, Jing D, Pan J H, Lu Z W, Liu Y H, Li L E, et al. Incentivizing multimodal reasoning in large models for direct robot manipulation. arXiv preprint arXiv: 2505.12744, 2025. [141] Zhang J, Wu S H, Luo X, Wu H, Gao L L, Shen H T, et al. InSpire: Vision-language-action models with intrinsic spatial reasoning. arXiv preprint arXiv: 2505.13888, 2025. [142] Lin F Q, Nai R Q, Hu Y D, You J C, Zhao J M, Gao Y. OneTwoVLA: A unified vision-language-action model with adaptive reasoning. arXiv preprint arXiv: 2505.11917, 2025. [143] Chen W, Belkhale S, Mirchandani S, Mees O, Driess D, Pertsch K, et al. Training strategies for efficient embodied reasoning. arXiv preprint arXiv: 2505.08243, 2025. [144] Kumar K, Ashraf T, Thawakar O, Anwer R M, Cholakkal H, Shah M, et al. LLM post-training: A deep dive into reasoning large language models. arXiv preprint arXiv: 2502.21321, 2025. [145] Chi C, Xu Z J, Pan C, Cousineau E, Burchfiel B, Feng S Y, et al. Universal manipulation interface: In-the-wild robot teaching without in-the-wild robots. arXiv preprint arXiv: 2402.10329, 2024. [146] Chen Y H, Tian S, Liu S G, Zhou Y T, Li H R, Zhao D B. ConRFT: A reinforced fine-tuning method for VLA models via consistency policy. arXiv preprint arXiv: 2502.05450, 2025. [147] Zhang Z J, Zheng K Y, Chen Z R, Jang J, Li Y, Han S W, et al. GRAPE: Generalizing robot policy via preference alignment. arXiv preprint arXiv: 2411.19309, 2025. [148] Guo Y J, Zhang J K, Chen X Y, Ji X, Wang Y J, Hu Y C, et al. Improving vision-language-action model with online reinforcement learning. In: Proceedings of the IEEE International Conference on Robotics and Automation (ICRA). Atlanta, USA: IEEE, 2025. 15665−15672 [149] Mark M S, Gao T, Sampaio G G, Srirama M K, Sharma A, Finn C, et al. Policy-agnostic RL: RL fine-tuning of any policy class and backbone. In: Proceedings of the 7th Robot Learning Workshop at ICLR 2025. Singapore: ICLR, 2025. [150] Yuan X, Mu T Z, Tao S, Fang Y H, Zhang M K, Su H. Policy decorator: Model-agnostic online refinement for large policy model. In: Proceedings of the 13th International Conference on Learning Representations. Singapore: OpenReview.net, 2025. [151] Zhang H Y, Zhuang Z F, Zhao H, Ding P X, Lu H C, Wang D L. ReinboT: Amplifying robot visual-language manipulation with reinforcement learning. In: Proceedings of the 42nd International Conference on Machine Learning. Vancouver, Canada: OpenReview.net, 2025. [152] Tan S H, Dou K R, Zhao Y, Krähenbuehl P. Interactive post-training for vision-language-action models. arXiv preprint arXiv: 2505.17016, 2025. [153] Xu C, Li Q Y, Luo J L, Levine S. RLDG: Robotic generalist policy distillation via reinforcement learning. arXiv preprint arXiv: 2412.09858, 2024. [154] Chen Z J, Niu R L, Kong H, Wang Q. TGRPO: Fine-tuning vision-language-action model via trajectory-wise group relative policy optimization. arXiv preprint arXiv: 2506.08440, 2025. [155] Lu G X, Guo W K, Zhang C B, Zhou Y H, Jiang H N, Gao Z F, et al. VLA-RL: Towards masterful and general robotic manipulation with scalable reinforcement learning. arXiv preprint arXiv: 2505.18719, 2025. [156] Wu Y L, Tian R, Swamy G, Bajcsy A. From foresight to forethought: VLM-in-the-loop policy steering via latent alignment. arXiv preprint arXiv: 2502.01828, 2025. [157] Wang Y W, Wang L R, Du Y L, Sundaralingam B, Yang X N, Chao Y W, et al. Inference-time policy steering through human interactions. In: Proceedings of the IEEE International Conference on Robotics and Automation (ICRA). Atlanta, USA: IEEE, 2025. 15626−15633 [158] Kwok J, Agia C, Sinha R, Foutter M, Li S L, Stoica I, et al. RoboMonkey: Scaling test-time sampling and verification for vision-language-action models. In: Proceedings of the 9th Conference on Robot Learning. Seoul, South Korea: PMLR, 2025. 3200−3217 [159] Nakamoto M, Mees O, Kumar A, Levine S. Steering your generalists: Improving robotic foundation models via value guidance. In: Proceedings of the 8th Conference on Robot Learning. Munich, Germany: PMLR, 2024. 4996−5013 [160] Guo D Y, Yang D J, Zhang H W, Song J X, Wang P Y, Zhu Q H, et al. DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning. Nature, 2025, 645(8081): 633−638 doi: 10.1038/s41586-025-09422-z [161] Liu J J, Gao F, Wei B W, Chen X L, Liao Q M, Wu Y, et al. What can RL bring to VLA generalization? An empirical study. arXiv preprint arXiv: 2505.19789, 2025. [162] Zheng J L, Li J X, Wang Z H, Liu D X, Kang X R, Feng Y C, et al. X-VLA: Soft-prompted Transformer as scalable cross-embodiment vision-language-action model. arXiv preprint arXiv: 2510.10274, 2025. [163] Fang I, Zhang J X, Tong S B, Feng C. From intention to execution: Probing the generalization boundaries of vision-language-action models. arXiv preprint arXiv: 2506.09930, 2025. [164] Jangir Y, Zhang Y D, Yamazaki K, Zhang C Y, Tu K H, Ke T W, et al. RobotArena ∞: Scalable robot benchmarking via real-to-sim translation. arXiv preprint arXiv: 2510.23571, 2025. [165] Gao J, Belkhale S, Dasari S, Balakrishna A, Shah D, Sadigh D. A taxonomy for evaluating generalist robot policies. arXiv preprint arXiv: 2503.01238, 2025. [166] Zhou J M, Ye K, Liu J Y, Ma T L, Wang Z F, Qiu R H, et al. Exploring the limits of vision-language-action manipulations in cross-task generalization. arXiv preprint arXiv: 2505.15660, 2025. [167] Wang Z J, Zhou Z H, Song J Y, Huang Y H, Shu Z, Ma L. VLATest: Testing and evaluating vision-language-action models for robotic manipulation. Proceedings of the ACM on Software Engineering, 2025, 2(FSE): 1615−1638 doi: 10.1145/3729343 [168] Atreya P, Pertsch K, Lee T, Kim M J, Jain A, Kuramshin A, et al. RoboArena: Distributed real-world evaluation of generalist robot policies. In: Proceedings of the 9th Conference on Robot Learning. Seoul, South Korea: PMLR, 2025. [169] Wang Y R, Ung C, Tannert G, Duan J F, Li J, Le A, et al. RoboEval: Where robotic manipulation meets structured and scalable evaluation. arXiv preprint arXiv: 2507.00435, 2025. [170] Luo J L, Xu C, Liu F C, Tan L, Lin Z P, Wu J, et al. FMB: A functional manipulation benchmark for generalizable robotic learning. The International Journal of Robotics Research, 2025, 44(4): 592−606 doi: 10.1177/02783649241276017 [171] Zhou Z Y, Atreya P, Tan Y L, Pertsch K, Levine S. AutoEval: Autonomous evaluation of generalist robot manipulation policies in the real world. In: Proceedings of the 9th Conference on Robot Learning. Seoul, South Korea: PMLR, 2025. 1997−2017 [172] James S, Ma Z C, Arrojo D R, Davison A J. RLBench: The robot learning benchmark & learning environment. IEEE Robotics and Automation Letters, 2020, 5(2): 3019−3026 doi: 10.1109/LRA.2020.2974707 [173] Yu T H, Quillen D, He Z P, Julian R, Hausman K, Finn C, et al. Meta-World: A benchmark and evaluation for multi-task and meta reinforcement learning. In: Proceedings of the 3rd Conference on Robot Learning. Osaka, Japan: PMLR, 2019. 1094−1100 [174] Mandlekar A, Xu D F, Wong J, Nasiriany S, Wang C, Kulkarni R, et al. What matters in learning from offline human demonstrations for robot manipulation. In: Proceedings of the 5th Conference on Robot Learning. London, UK: PMLR, 2021. 1678−1690 [175] Mees O, Hermann L, Rosete-Beas E, Burgard W. CALVIN: A benchmark for language-conditioned policy learning for long-horizon robot manipulation tasks. IEEE Robotics and Automation Letters, 2022, 7(3): 7327−7334 doi: 10.1109/LRA.2022.3180108 [176] Liu B, Zhu Y F, Gao C K, Feng Y H, Liu Q, Zhu Y K, et al. LIBERO: Benchmarking knowledge transfer for lifelong robot learning. In: Proceedings of the 37th International Conference on Neural Information Processing Systems. New Orleans, USA: Curran Associates, 2023. Article No. 1939 [177] Li X L, Hsu K, Gu J Y, Mees O, Pertsch K, Walke H R, et al. Evaluating real-world robot manipulation policies in simulation. In: Proceedings of the 8th Conference on Robot Learning. Munich, Germany: PMLR, 2024. 3705−3728 [178] Gu J Y, Xiang F B, Li X L, Ling Z, Liu X Q, Mu T Z, et al. ManiSkill2: A unified benchmark for generalizable manipulation skills. arXiv preprint arXiv: 2302.04659, 2023. [179] Gupta A, Kumar V, Lynch C, Levine S, Hausman K. Relay policy learning: Solving long-horizon tasks via imitation and reinforcement learning. In: Proceedings of the 3rd Conference on Robot Learning. Osaka, Japan: PMLR, 2019. 1025−1037 [180] Gao C K, Zhang H Z, Xu Z X, Cai Z H, Lin S. FLIP: Flow-centric generative planning as general-purpose manipulation world model. In: Proceedings of the 13th International Conference on Learning Representations. Singapore: OpenReview.net, 2025. [181] Li Y, Meng Y, Sun Z W, Ji K Y, Tang C, Fan J J, et al. SP-VLA: A joint model scheduling and token pruning approach for VLA model acceleration. arXiv preprint arXiv: 2506.12723, 2025. [182] Wen J J, Zhu Y C, Li J M, Zhu M J, Tang Z B, Wu K, et al. TinyVLA: Toward fast, data-efficient vision-language-action models for robotic manipulation. IEEE Robotics and Automation Letters, 2025, 10(4): 3988−3995 doi: 10.1109/LRA.2025.3544909 [183] Yan F, Liu F F, Zheng L M, Zhong Y F, Huang Y Y, Guan Z C, et al. RoboMM: All-in-one multimodal large model for robotic manipulation. arXiv preprint arXiv: 2412.07215, 2024. [184] 1X World Model Team. 1X World Model: Evaluating bits, not atoms [Online], available: https://www.1x.tech/1x-world-model.pdf, November 6, 2025 [185] Huang S Q, Wu J L, Zhou Q X, Miao S C, Long M S. Vid2World: Crafting video diffusion models to interactive world models. arXiv preprint arXiv: 2505.14357, 2025. [186] Li Y X, Zhu Y C, Wen J J, Shen C M, Xu Y. WorldEval: World model as real-world robot policies evaluator. arXiv preprint arXiv: 2505.19017, 2025. [187] Wen J J, Zhu Y C, Li J M, Tang Z B, Shen C M, Feng F F. DexVLA: Vision-language model with plug-in diffusion expert for general robot control. arXiv preprint arXiv: 2502.05855, 2025. [188] Jiang Y M, Huang S T, Xue S K, Zhao Y X, Cen J, Leng S C, et al. RynnVLA-001: Using human demonstrations to improve robot manipulation. arXiv preprint arXiv: 2509.15212, 2025. [189] Zhai A, Liu B, Fang B, Cai C, Ma E, Yin E, et al. Igniting VLMs toward the embodied space. arXiv preprint arXiv: 2509.11766, 2025. [190] Jiang T, Yuan T Y, Liu Y C, Lu C H, Cui J N, Liu X, et al. Galaxea open-world dataset and G0 dual-system VLA model. arXiv preprint arXiv: 2509.00576, 2025. [191] Gao G, Wang J N, Zuo J B, Jiang J N, Zhang J F, Zeng X W, et al. Towards human-level intelligence via human-like whole-body manipulation. arXiv preprint arXiv: 2507.17141, 2025. [192] Li P H, Wu Y Y, Xi Z H, Li W L, Huang Y Z, Zhang Z Y, et al. ControlVLA: Few-shot object-centric adaptation for pre-trained vision-language-action models. In: Proceedings of the 9th Conference on Robot Learning. Seoul, South Korea: PMLR, 2025. 1898−1913 -

 下载:
下载:

计量
- 文章访问数: 4214
- HTML全文浏览量: 2191
- PDF下载量: 812
- 被引次数: 0
