

Graph Attention-driven Reinforcement Learning for Cross-Scenario Cooperative Interception
-
摘要: 针对复杂动态场景下大规模无人集群拦截任务, 提出一种基于图注意力机制与动态分组的集群协同拦截框架. 现有基于规则或优化的方法在实时性、泛化性与目标分配效能方面存在局限, 而多智能体强化学习在复杂动态场景下面临维度爆炸、策略泛化性不足等挑战. 为提升复杂动态场景下集群拦截策略学习效率以及跨场景泛化能力, 创新性地设计了目标动态分组模块、图注意力模块与改进多智能体强化学习(MARL)模块, 并融合成一套闭环算法框架: 1)目标分组模块通过周期性聚类将敌方集群分解为低维战术小组, 敌方小组信息作为节点传输给图注意力模块, 降低状态-动作维度; 2)图注意力模块利用敌方小组节点信息, 基于图注意力网络进行特征融合并构建敌我智能体-小组间相对关系, 生成目标重要性权重以引导差异化奖励函数设计, 提升策略目标分配与泛化能力; 3)MARL模块结合差异化奖励函数与融合特征, 基于SAC算法与对抗性训练机制进行策略学习, 进一步增强策略泛化性. 仿真实验表明该框架显著提升复杂动态场景下集群拦截效率以及跨场景泛化能力.Abstract: For large-scale unmanned swarm interception in complex dynamic scenarios, this paper proposes a collaborative interception framework based on graph attention mechanisms and dynamic grouping. Existing rule-based or optimization-based methods suffer from poor real-time performance, weak generalization, and low target allocation efficiency, while MARL faces dimensionality explosion and limited policy generalization in such environments. To improve learning efficiency and cross-scenario generalization, this work integrates three modules—a dynamic grouping module, a graph attention module, and an improved MARL module—into a closed-loop framework. The grouping module periodically clusters enemy units into low-dimensional tactical groups and passes the group information as nodes to the graph attention module, reducing state–action dimensionality. The graph attention module uses group-node data, applies graph attention networks for feature fusion, builds relative relations between friendly agents and enemy groups, and outputs target-importance weights to guide differentiated reward design, improving target allocation and generalization. The MARL module combines these differentiated rewards with fused features, adopting the SAC algorithm and adversarial training to further enhance policy generalization. Simulation results show that the framework significantly improves swarm interception efficiency and cross-scenario generalization in complex dynamic environments.
-
Key words:
- coordinated interception /
- MARL /
- graph attention mechanism /
- dynamic grouping
-
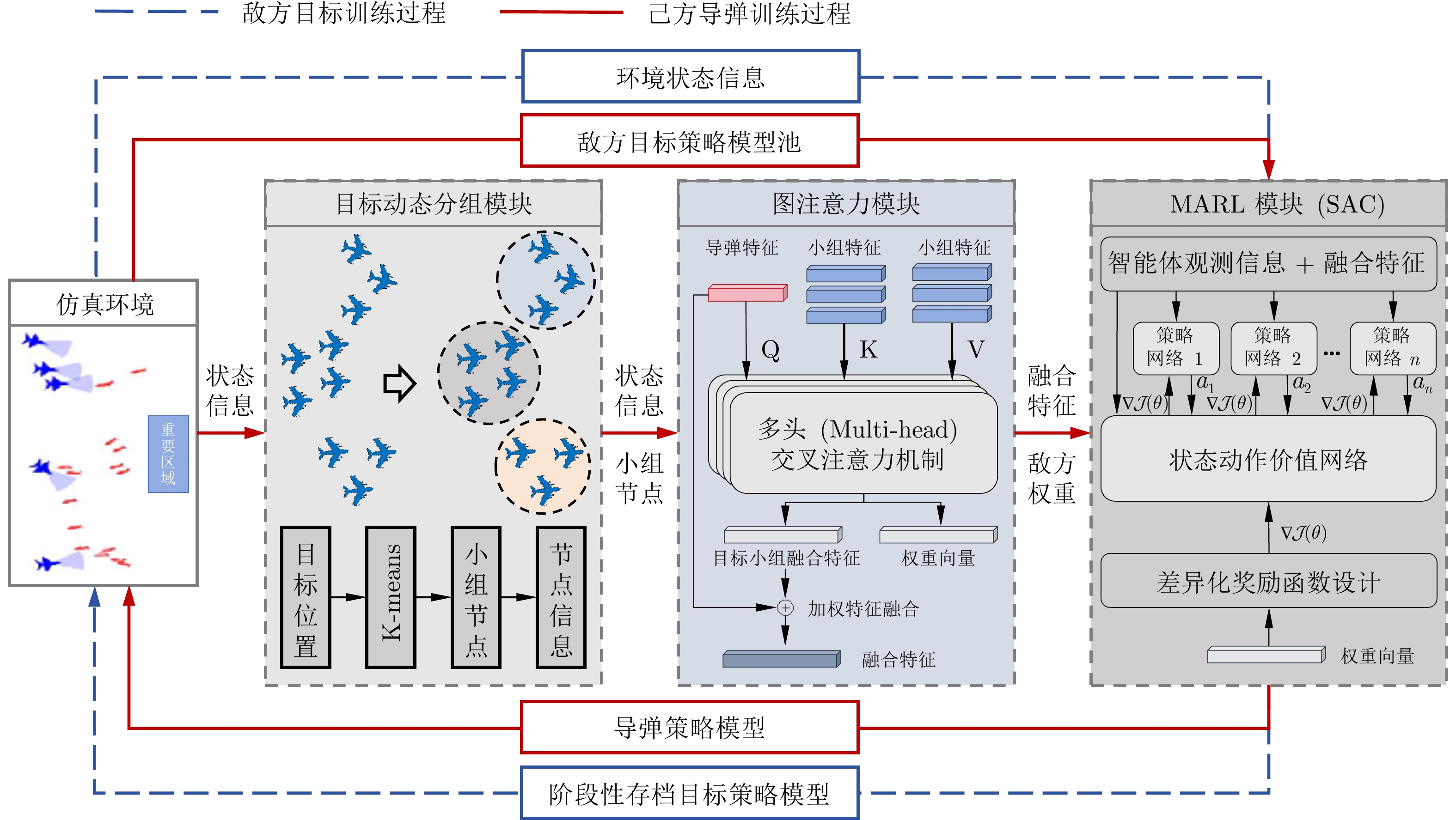
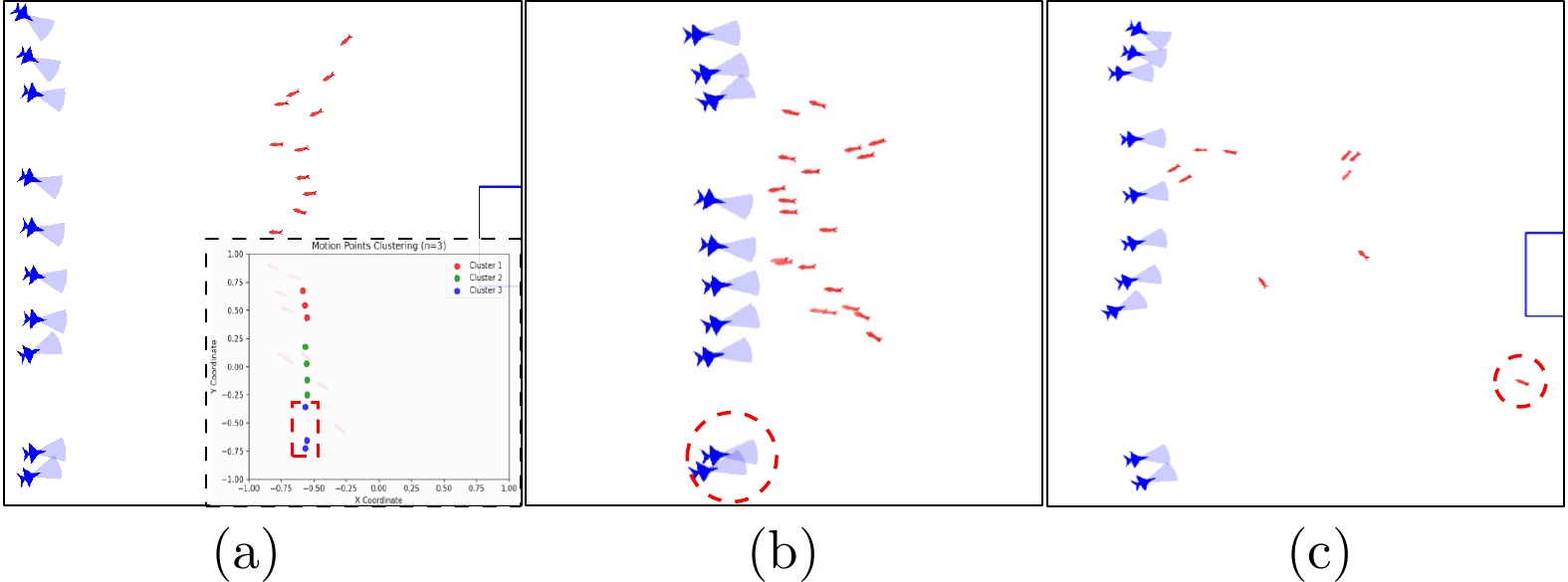
图 2 动态分组图注意力集群拦截算法框架
Fig. 2 Dynamic grouping graph attention swarm interception algorithm framework
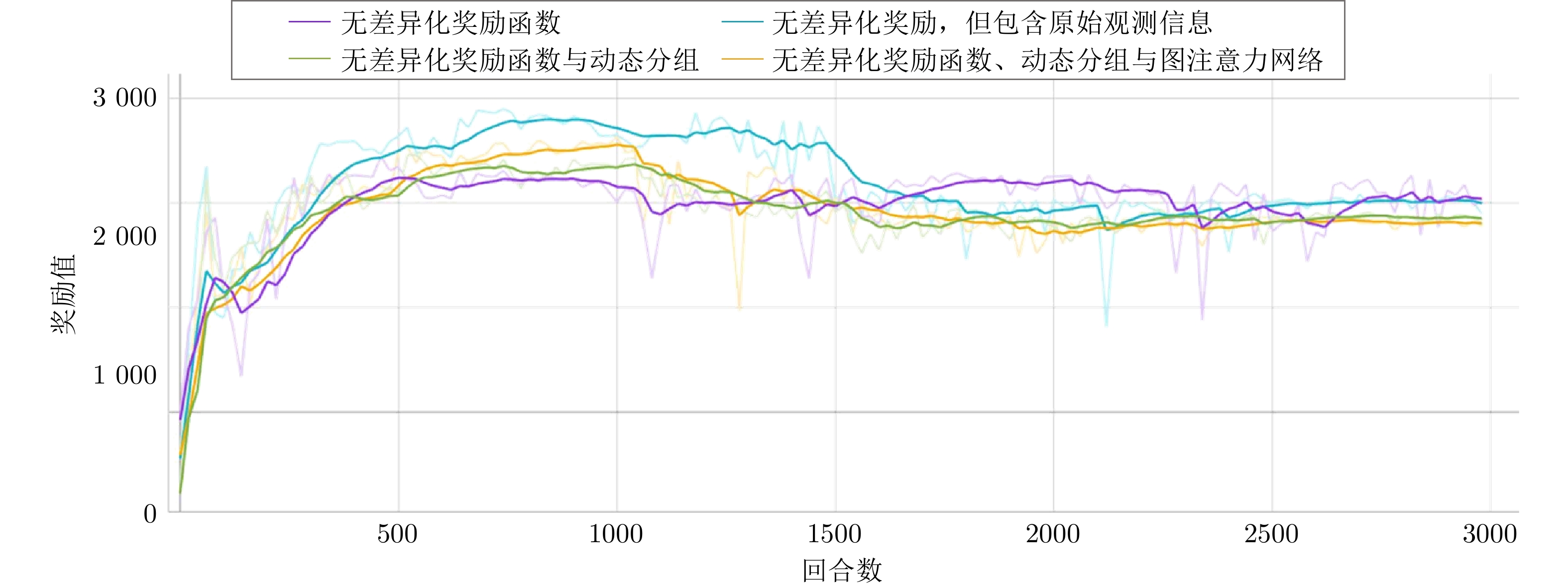
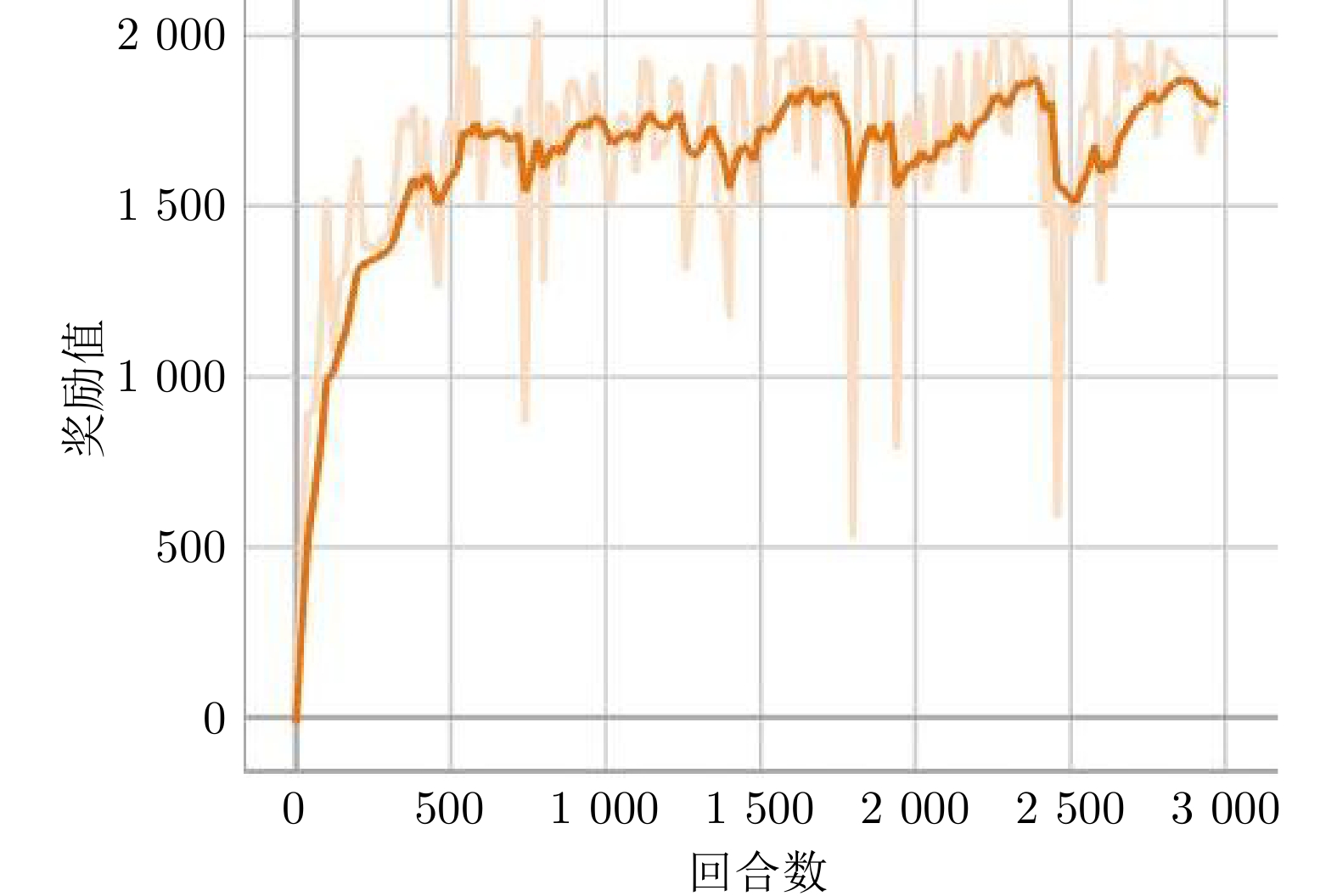
图 6 消融实验不同设置奖励函数曲线对比
Fig. 6 Comparison of reward function curves in ablation experiments with different setting
表 1 神经网络配置
Table 1 Neural network configuration
名称 设定值 目标网络隐藏层层数 2 目标网络隐藏层宽度 256$ \times $256 Critic网络隐藏层层数 2 Critic网络隐藏层宽度 256$ \times $256 Actor网络隐藏层层数 2 Actor网络隐藏层宽度 256$ \times $256 激活函数 ReLU 优化器 Adam  下载: 导出CSV
下载: 导出CSV
表 2 算法训练超参数
Table 2 Hyperparameters for algorithm training
参数 设定值 批量大小(Batch size) 4 096 经验池大小(Buffer size) 1 536 000 学习率 0.0001 折扣率 0.99 熵项系数 0.2 目标网络更新参数 0.02
下载: 导出CSV
表 3 奖励函数设计
Table 3 Reward function design
己方导弹拦截任务 奖励设置 导弹靠近或者远离目标$ j $ $ \Delta d_1 \cdot 10 \cdot \omega_{i,\; j} $ 目标$ j $进入导弹伤害范围且成功击毁 $ +20.0 \cdot \omega_{i,\; j} $ 目标$ j $进入导弹伤害范围但未成功击毁 $ +5.0 \cdot \omega_{i,\; j} $ 队友碰撞 $ -0.1 $ 步数惩罚 $ -0.05 $ 2) 敌方目标入侵任务 奖励设置 目标靠近或者远离目标区域 $ \Delta d_2 \cdot 100/\text{Distance} $ 目标到达目标区域完成任务 $ +100.0 $ 目标进入导弹伤害范围且被击毁 $ -5.0 $ 目标进入导弹伤害范围但未被击毁 $ -0.2 $ 队友碰撞 $ -0.1 $ 步数惩罚 $ -0.05 $
下载: 导出CSV
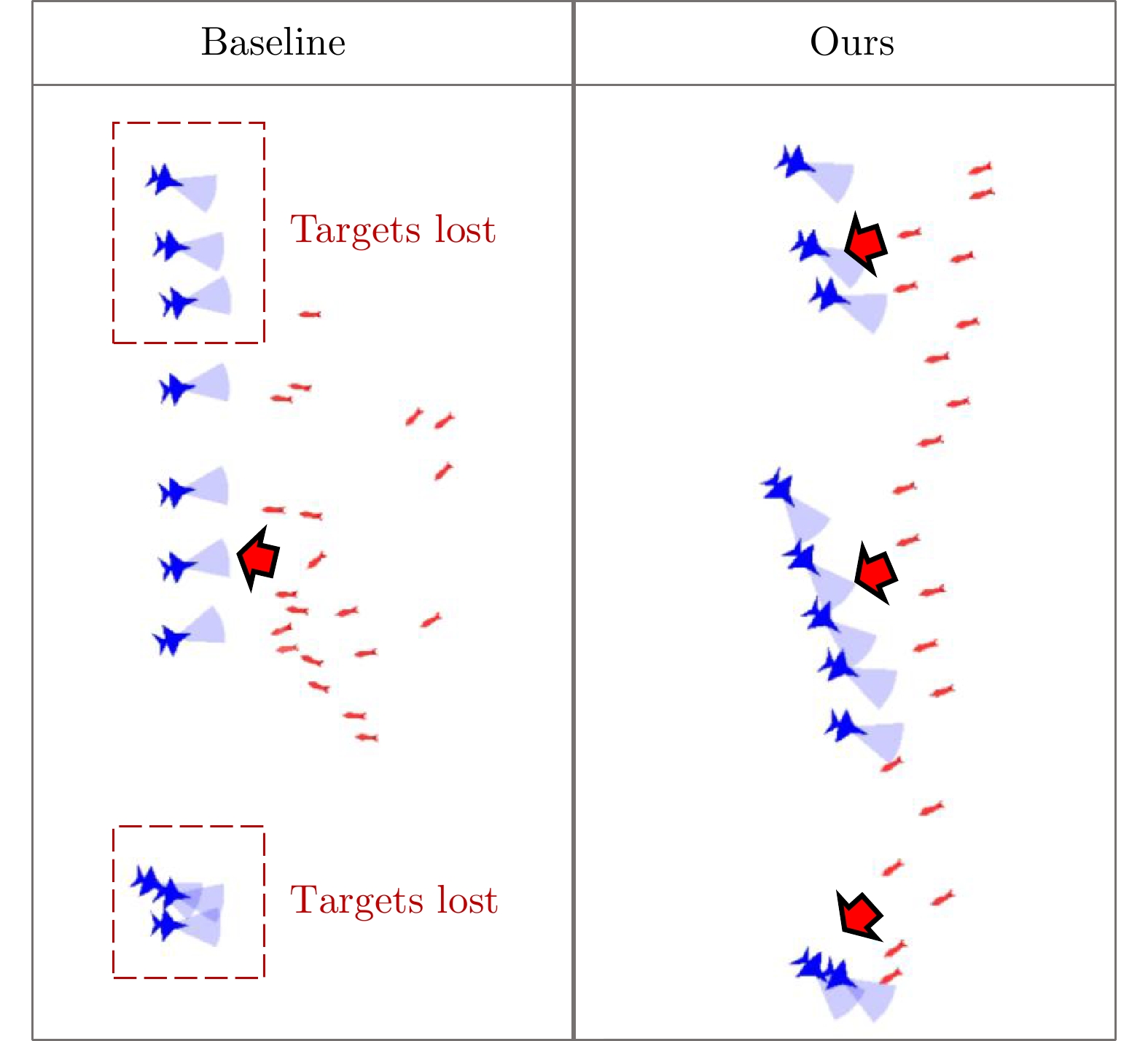
表 4 不同对抗规模实验
Table 4 Experiments with different scales of combat
己方vs敌方 Ours (SR/AK/AS) Baseline (SR/AK/AS) 20 vs 10 97% / 9.97 / 220.00 93% / 9.93 / 197.48 15 vs 10 95% / 9.91 / 317.34 91% / 9.87 / 279.72 10 vs 10 34% / 8.81 / 509.00 4% / 7.88 / 455.37
下载: 导出CSV
表 5 不同敌方策略实验
Table 5 Experiments with different enemy policies
敌方策略 Ours (SR/AK/AS) Baseline (SR/AK/AS) 训练策略 97% / 9.97 / 220.00 93% / 9.93 / 197.48 训练外策略1 100% / 10.00 / 210.35 96% / 9.96 / 186.41 训练外策略2 99% / 9.99 / 199.08 71% / 9.62 / 420.87 训练外策略3 95% / 9.94 / 274.66 62% / 9.30 / 962.25
下载: 导出CSV
表 6 不同敌方速度实验
Table 6 Experiments with different enemy speed
敌方速度 Ours (SR/AK/AS) Baseline (SR/AK/AS) $ v_{train} $ 97% / 9.97 / 220.00 93% / 9.93 / 197.48 $ v_{train}+50\% $ 85% / 9.81 / 198.45 38% / 8.44 / 251.29 $ v_{train}+100\% $ 40% / 8.60 / 197.75 20% / 7.25 / 196.30
下载: 导出CSV
表 7 不同敌方队形实验
Table 7 Experiments with different enemy formation
敌方队形 Ours (SR/AK/AS) Baseline (SR/AK/AS) 一字型 97% / 9.97 / 220.00 93% / 9.93 / 197.48 3-3-4队形 64% / 9.16 / 459.36 0% / 4.76 / 282.36
下载: 导出CSV
表 8 不同消融设置实验
Table 8 Experimentals of different ablation settings
消融设置 SR AK AS 设置1) 98% 9.96 187.60 设置2) 95% 9.90 315.33 设置3) 100% 10.00 201.18 设置4) 80% 9.33 387.47 设置5) 65% 9.31 783.25
下载: 导出CSV
-
[1] 贾永楠, 田似营, 李擎. 无人机集群研究进展综述. 航空学报, 2020, 41(S1): 723−738Jia Yong-Nan, Tian Si-Ying, Li Qing. Recent development of unmanned aerial vehicle swarms. Acta Aeronautica et Astronautica Sinica, 2020, 41(S1): 723−738 [2] 薛健, 赵琳, 向贤财, 吕科, 宏晨, 张宝琳, 等. 非完全信息下无人机集群对抗研究综述. 电子与信息学报, 2024, 46(4): 1157−1172 doi: 10.11999/JEIT230544Xue Jian, Zhao Lin, Xiang Xian-Cai, Lv Ke, Hong Chen, Zhang Bao-Lin, et al. A review of the research on UAV swarm confrontation under incomplete information. Journal of Electronics and Information Technology, 2024, 46(4): 1157−1172 doi: 10.11999/JEIT230544 [3] 高树一, 林德福, 郑多, 胡馨予. 针对集群攻击的飞行器智能协同拦截策略. 航空学报, 2023, 44(18): 328301−328301 doi: 10.7527/S1000-6893.2023.28301Gao Shu-Yi, Lin De-Fu, Zheng Duo, Hu Xin-Yu. Intelligent cooperative interception strategy of aircraft against cluster attack. Acta Aeronautica et Astronautica Sinica, 2023, 44(18): 328301−328301 doi: 10.7527/S1000-6893.2023.28301 [4] Duan H B, Zhang D F, Fan Y M, Deng Y M. From wolf pack intelligence to UAV swarm cooperative decision-making. Science China Information Sciences, 2019, 49: 112−118 doi: 10.1360/n112018-00168 [5] 周末, 孙海文, 王亮, 于邵祯, 孟祥尧, 李丹. 国外反无人机蜂群作战研究. 指挥控制与仿真, 2023, 45(2): 24−30 doi: 10.3969/j.issn.1009-086x.2023.04.001Zhou Mo, Sun Hai-Wen, Wang Liang, Yu Shao-Zhen, Meng Xiang-Yao, Li Dan. Research on foreign anti-UAV swarm warfare. Command Control and Simulation, 2023, 45(2): 24−30 doi: 10.3969/j.issn.1009-086x.2023.04.001 [6] Luo R N, Huang S C, Zhao Y. Guidance strategy of mother-son missile against unmanned aerial vehicle cluster. Systems Engineering and Electronics, 2023, 45(10): 3249−3258 [7] Burgin G H and Sidor L B, Rule-based air combat simulation. Titan Systems Inc., La Jolla, CA, USA, Technical Report, 1988 [8] Park H, Lee B Y, Tahk M J. Differential game based air combat maneuver generation using scoring function matrix. International Journal of Aeronautical and Space Sciences, 2016, 17(2): 204−213 doi: 10.5139/IJASS.2016.17.2.204 [9] Sunehag P, Lever G, Gruslys A, Czarnecki W M, Zambaldi V, Jaderberg M, et al. Value-Decomposition Networks For Cooperative Multi-Agent Learning Based On Team Reward. In: Proceedings of the 17th International Conference on Autonomous Agents and MultiAgent Systems. Stockholm, Sweden: 2018. 2085–2087 [10] Rashid T, Samvelyan M, De Witt C S, Farquhar G, Foerster J, Whiteson S. Monotonic value function factorisation for deep multi-agent reinforcement learning. Journal of Machine Learning Research, 2020, 21(178): 1−51 [11] 俞文武, 杨晓亚, 李海昌, 王瑞, 胡晓惠. 面向多智能体协作的注意力意图与交流学习方法. 自动化学报, 2023, 49(11): 2311−2325Yu Wen-Wu, Yang Xiao-Ya, Li Hai-Chang, Wang Rui, Hu Xiao-Hui. Attentional intention and commu-nication for multi-agent learning. Acta Automatica Sinica, 2023, 49(11): 2311−2325 [12] 王耀南, 华和安, 张辉, 钟杭, 樊叶心, 梁鸿涛, 等. 性能函数引导的无人机集群深度强化学习控制方法. 自动化学报, 2025, 51(5): 905−916 doi: 10.16383/j.aas.c240519Wang Yao-Nan, Hua He-An, Zhang Hui, Zhong Hang, Fan Ye-Xin, Liang Hong-Tao, et al. Performance function-guided deep reinforcement learning control for UAV swarm. Acta Automatica Sinica, 2025, 51(5): 905−916 doi: 10.16383/j.aas.c240519 [13] Zheng Z, Wei C, Duan H. UAV swarm air combat maneuver decision-making method based on multi-agent reinforcement learning and transferring. Science China Information Sciences, 2024, 67(8): 180−204 [14] Yu C, Velu A, Vinitsky E, Gao J, Wang Y, Bayen A, et al. The surprising effectiveness of ppo in cooperative multi-agent games. In: Proceedings of 2022 Advances in Neural Information Processing Systems. New Orleans, USA: 2022. 35: 24611–24624 [15] Xuan S, Ke L. UAV swarm attack-defense confrontation based on multi-agent reinforcement learning. In: Proceedings of 2020 International Conference on Guidance, Navigation and Control. Tianjin, China: 2020. 5599–5608 [16] Lowe R, Wu Y, Tamar A, Harb J, Abbeel P, Mordatch I. Multi-agent actor-critic for mixed cooperative-competitive environments. In: Proceedings of 2017 Advances in Neural Information Processing Systems. Long Beach, USA: 2017. 6379–6390 [17] Wang B, Li S, Gao X, Xie T. UAV swarm confrontation using hierarchical multiagent reinforcement learning. International Journal of Aerospace Engineering, 2021, 2021: Article No. 3360116 [18] Pope A P, Ide J S, Mićović D, Diaz H, Rosenbluth D, Ritholtz L, et al. Hierarchical reinforcement learning for air-to-air combat. In: Proceedings of 2021 International Conference on Unmanned Aircraft Systems. Athens, Greece: IEEE, 2021. 275–284 [19] Cai H, Li X, Zhang Y, Gao H. Interception of a Single Intruding Unmanned Aerial Vehicle by Multiple Missiles Using the Novel EA-MADDPG Training Algorithm. Drones, 2024, 8(10): 524 doi: 10.3390/drones8100524 [20] Han Y, Piao H, Hou Y, Sun Y, Sun Z, Zhou D. Deep relationship graph reinforcement learning for multi-aircraft air combat. In: Proceedings of International Joint Conference on Neural Networks. Padua, Italy: IEEE, 2022. 1–8 [21] Scarselli F, Gori M, Tsoi A C, Hagenbuchner M, Monfardini G. The graph neural network model. IEEE Transactions on Neural Networks, 2008, 20(1): 61−80 [22] Sun Z, Wu H, Shi Y, Yu X, Gao Y, Pei W, et al. Multi-agent air combat with two-stage graph-attention communication. Neural Computing and Applications, 2023, 35(27): 19765−19781 doi: 10.1007/s00521-023-08784-7 [23] Foerster J, Nardelli N, Farquhar G, Afouras T, Torr P, Kohli P, et al. Stabilising experience replay for deep multi-agent reinforcement learning. In: Proceedings of International Conference on Machine Learning. Sydney, Australia: PMLR, 2017. 1146–1155 [24] Koh W, Oh W, Kim S, Shin S, Kim H, Jang J, et al. FlickerFusion: Intra-trajectory domain generalizing multi-agent reinforcement learning. In: Proceedings of The 13th International Conference on Learning Representations. Singapore, 2025. 59197–59234 [25] Cao Y, Kou Y, Xu A, Xi Z. Target threat assessment in air combat based on improved glowworm swarm optimization and ELM neural network. International Journal of Aerospace Engineering, 2021, 2021(1): Article No. 4687167 doi: 10.1155/2021/4687167 [26] Veličković P, Cucurull G, Casanova A, Romero A, Liò P, Bengio Y. Graph attention networks. arXiv preprint arXiv: 1710.10903, 2017. [27] Haarnoja T, Zhou A, Hartikainen K, Tucker G, Ha S, Tan J, et al. Soft actor-critic algorithms and applications. arXiv preprint arXiv: 1812.05905, 2018. [28] Liu E, Zhu J, Lin Z, Ning X, Wang S, Blaschko M B, et al. Linear combination of saved checkpoints makes consistency and diffusion models better. arXiv preprint arXiv: 2404.02241, 2024. [29] Vinyals O, Babuschkin I, Czarnecki W M, Mathieu M, Dudzik A, Chung J, et al. Grandmaster level in StarCraft II using multi-agent reinforcement learning. Nature, 2019, 575(7782): 350−354 doi: 10.1038/s41586-019-1724-z [30] Yuan G, He M, Ma Z, Zhang W, Liu X, Li W. Multiagent Following Multileader Algorithm Based on K-means Clustering. Journal of System Simulation, 2023, 35(3): 616−622 [31] Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez A N, et al. Attention is all you need. In: Advances in Neural Information Processing Systems. Long Beach, USA: 2017. 6000–6010 [32] Tao F, Wu M, Cao Y. Generalized maximum entropy reinforcement learning via reward shaping. IEEE Transactions on Artificial Intelligence, 2023, 5(4): 1563−1572 doi: 10.1109/tai.2023.3297988 -

 下载:
下载:

计量
- 文章访问数: 219
- HTML全文浏览量: 135
- 被引次数: 0
