

-
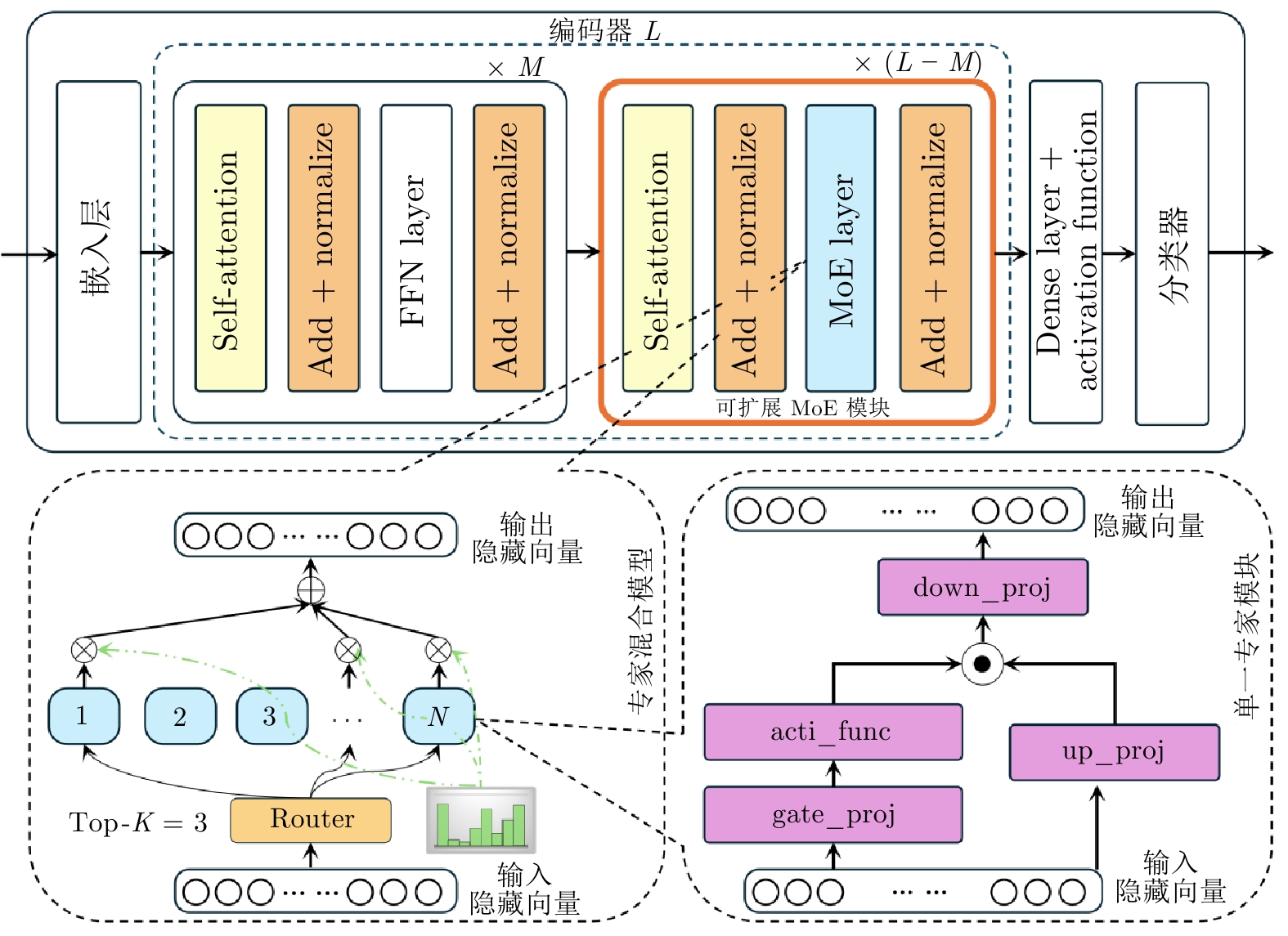
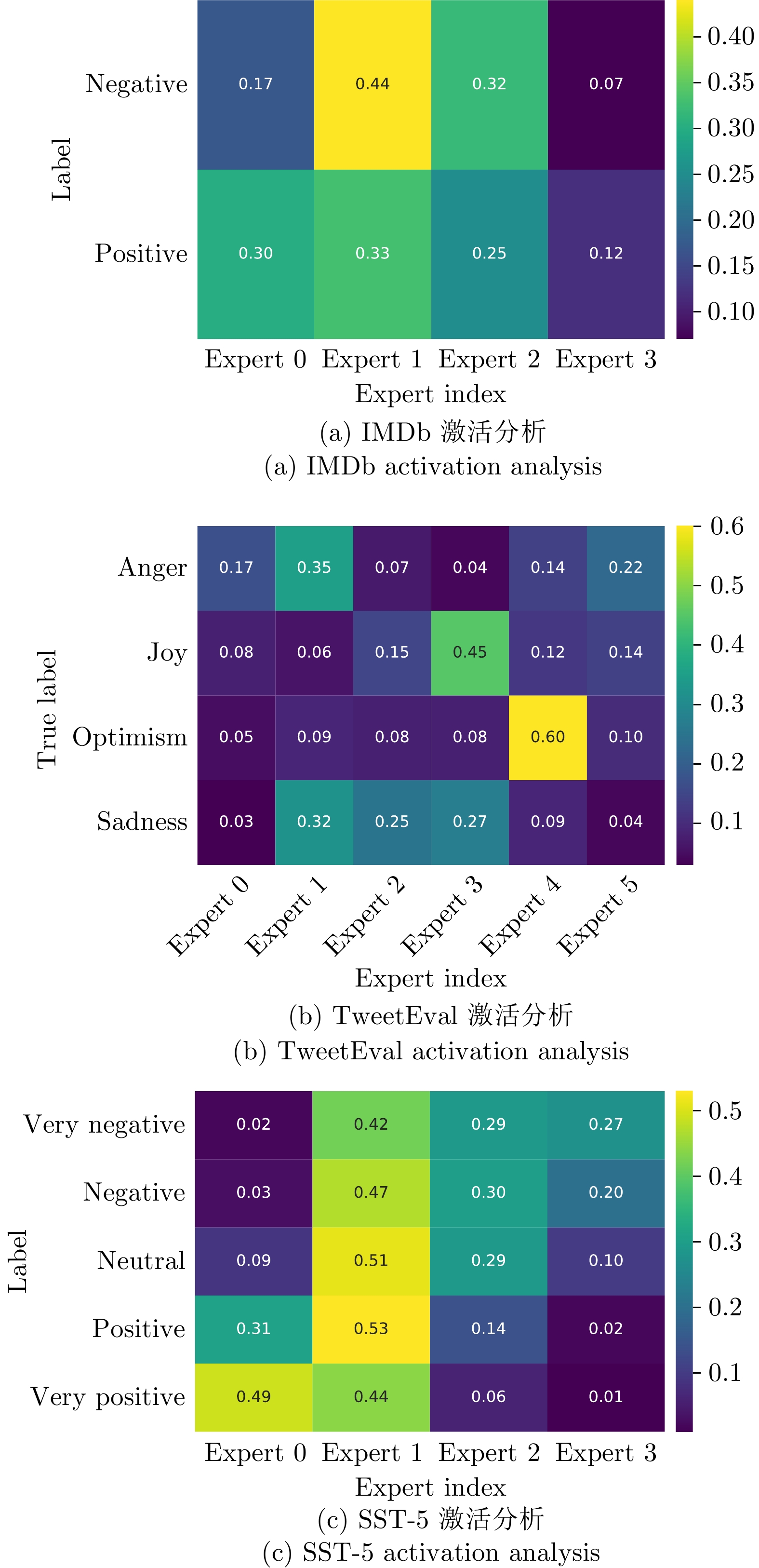
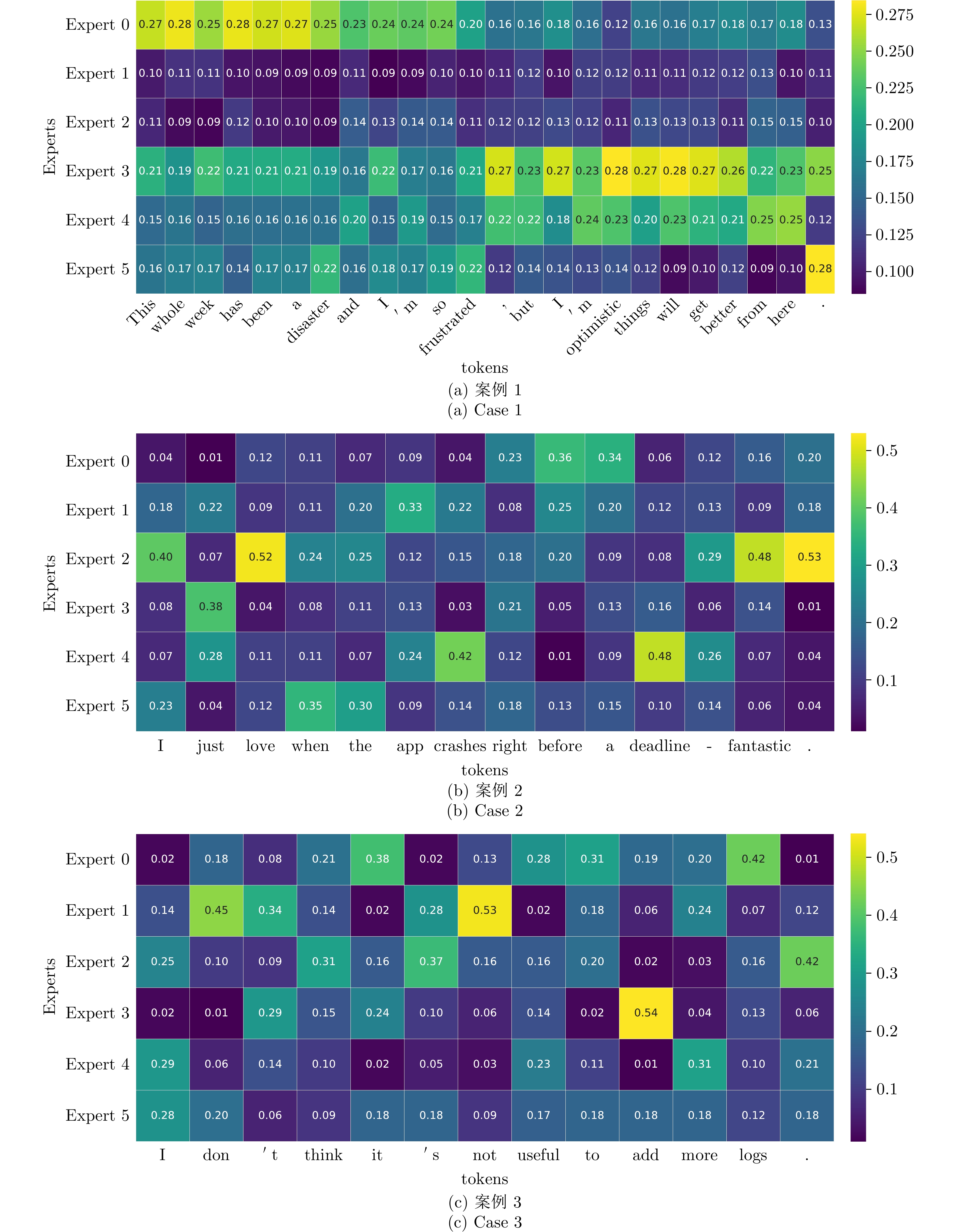
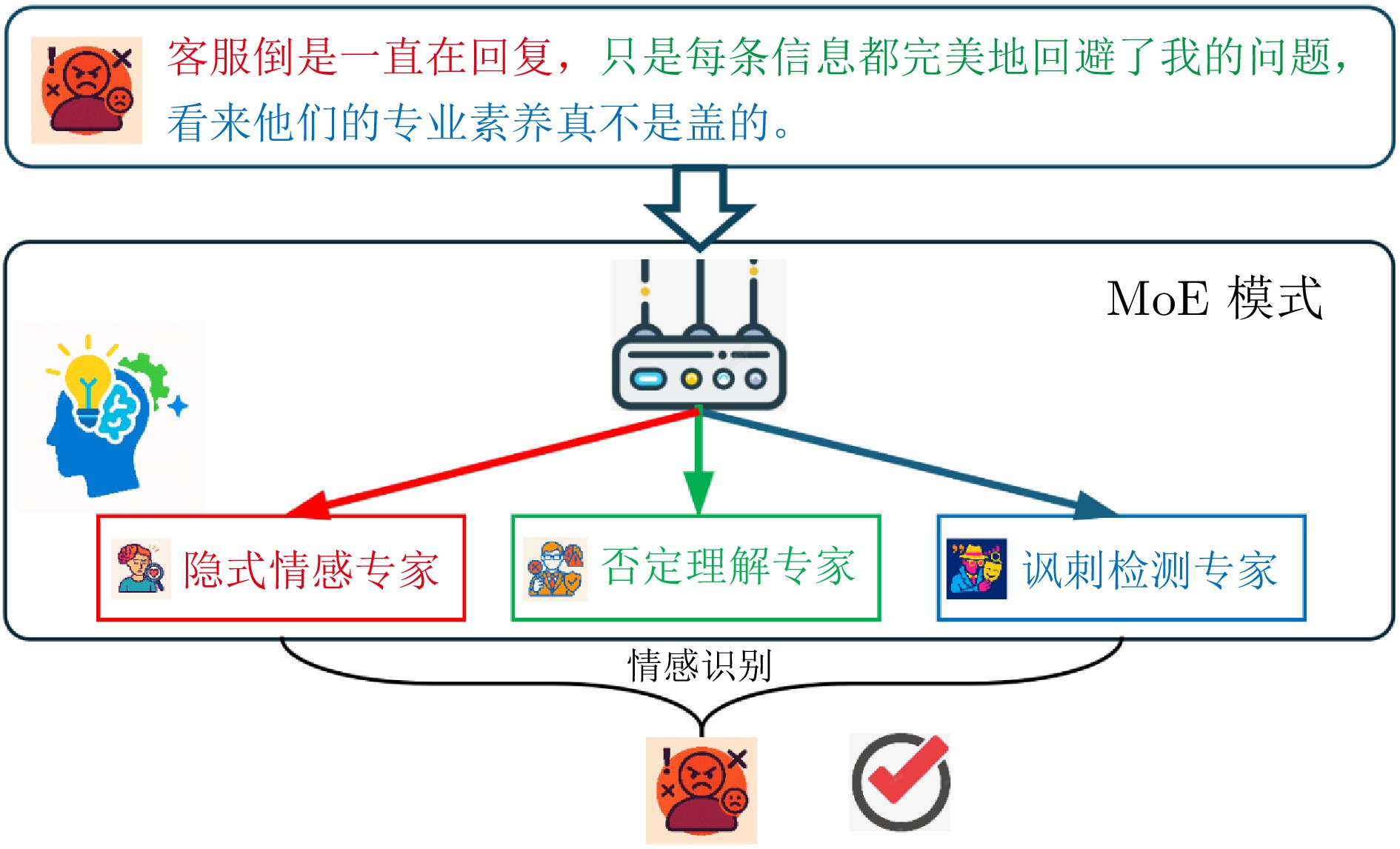
摘要: 情感分析作为自然语言处理领域的核心任务之一, 面临着精准捕捉细粒度情感特征以及提升模型可解释性的双重挑战. 为此, 提出一种基于混合专家模型的可扩展情感分析框架, 通过将门控机制融入专家内部, 设计可在任意预训练语言模型中扩展的混合专家模块. 该框架旨在以可控的计算开销扩展模型容量, 促进细粒度条件计算和专家专业化. 在三个典型情感分析数据集上的综合实验表明, 与基线模型相比, 本方法在关键指标上均取得显著提升, 尤其在处理复杂多分类任务时, 其性能已达到甚至超过主流参数高效微调大语言模型的水平. 更重要的是, 得益于稀疏激活机制, 模型在保持高性能的同时, 展现出卓越的推理效率. 通过对专家激活模式和输出表征的深入分析, 清晰地观察到不同专家针对特定语义模式形成功能专精. 这为模型决策提供直观且有力的可解释性证据, 验证该框架在构建高效、高性能且可信赖的情感分析系统中的巨大潜力.Abstract: As one of the core tasks in natural language processing, sentiment analysis faces dual challenges: Accurately capturing fine-grained emotional features and enhancing model interpretability. To address these issues, we propose a scalable sentiment analysis framework based on a mixture of experts (MoE) model. By integrating a gating mechanism into the expert modules, we design a mixture of experts module that can be extended to any pretrained language model. The framework aims to expand model capacity with controllable computational overhead, thereby enabling fine-grained conditional computation and expert specialization. Comprehensive experiments on three representative sentiment analysis datasets demonstrate that, compared with baseline models, our approach achieves significant improvements across key metrics. Notably, when handling complex multi-classification tasks, its performance rivals or even surpasses mainstream large language models that have undergone parameter-efficient fine-tuning. More importantly, benefiting from the sparse activation mechanism, the model maintains high performance while exhibiting exceptional inference efficiency. Through an in-depth analysis of expert activation patterns and output representations, we clearly observe that different experts develop functional specialization toward specific semantic patterns, providing intuitive and strong interpretability evidence for model decision-making. These findings validate the great potential of the proposed framework in building efficient, high-performance, and trustworthy sentiment analysis systems.
-
Key words:
- sentiment analysis /
- mixture of experts /
- interpretability /
- fine-grained feature capture /
- scalability
-
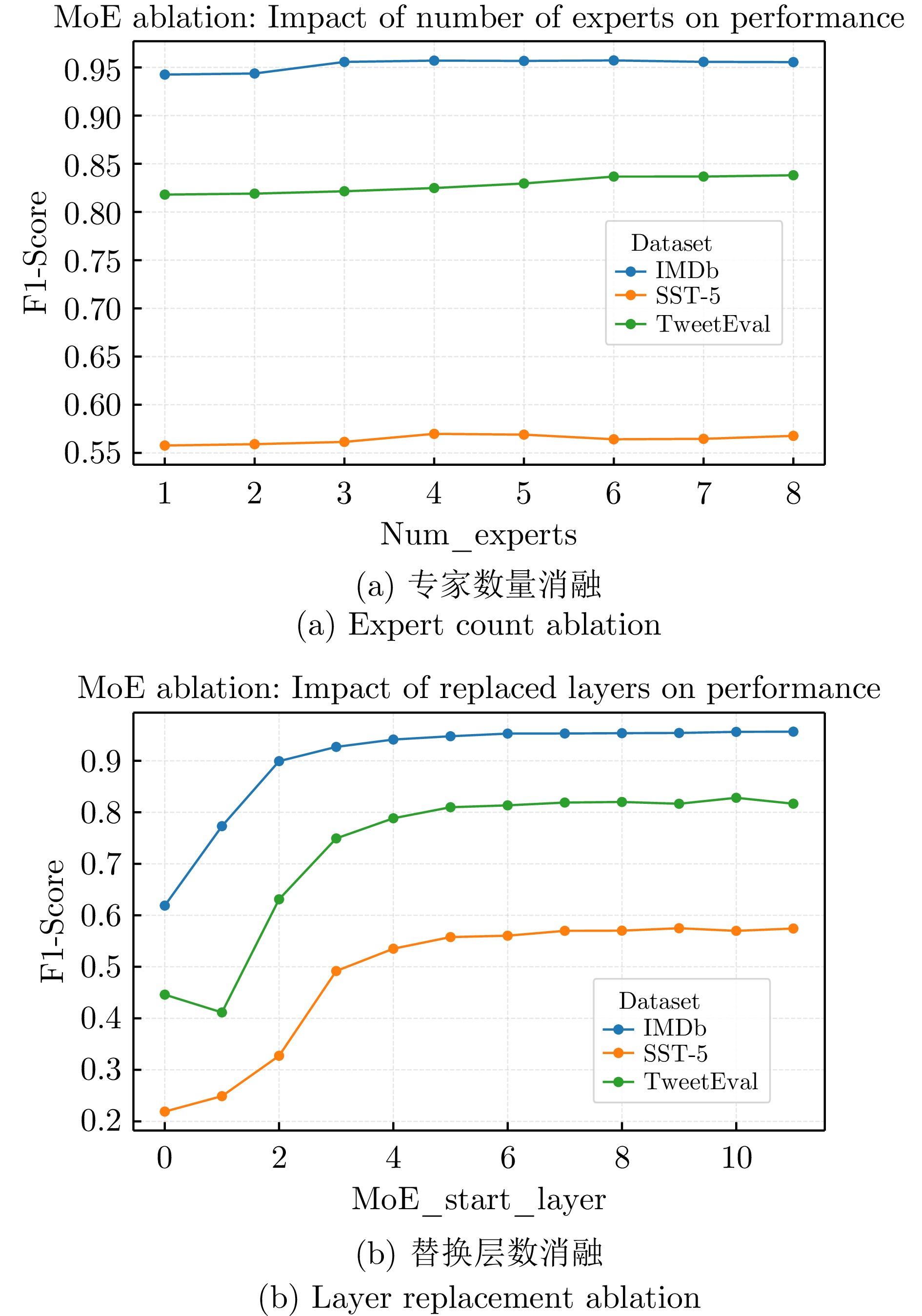
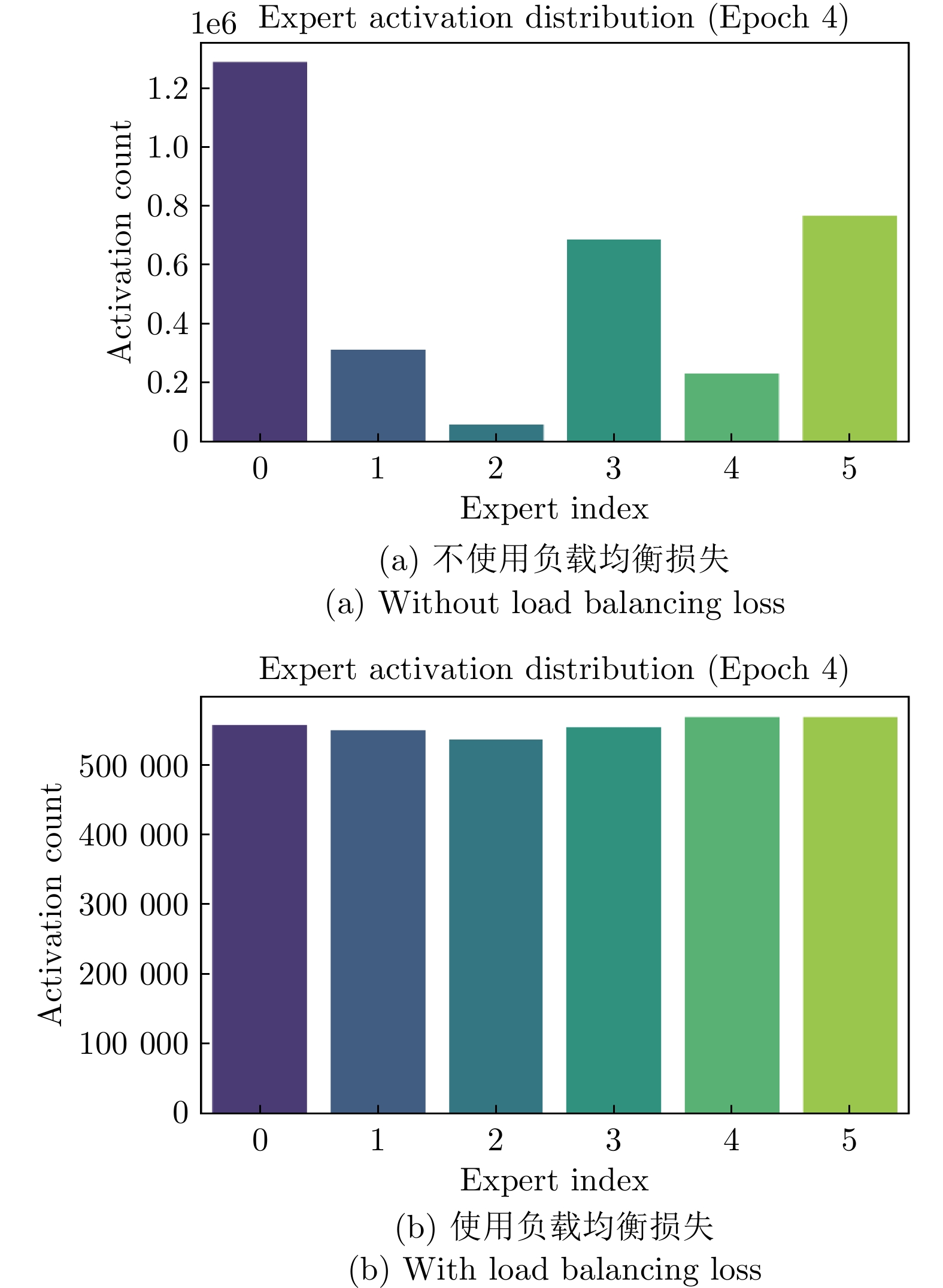
图 7 消融研究折线图(层数和专家数量变化)
Fig. 7 Ablation study line chart (varying number of layers and number of experts)
表 1 情感分析数据集统计信息
Table 1 Statistics of sentiment analysis datasets
统计项 训练集
样本数验证集
样本数测试集
样本数类别数 IMDb 25000 — 25000 2 TweetEval Emotion 3260 374 1420 4 SST-5 8540 1100 2210 5  下载: 导出CSV
下载: 导出CSV
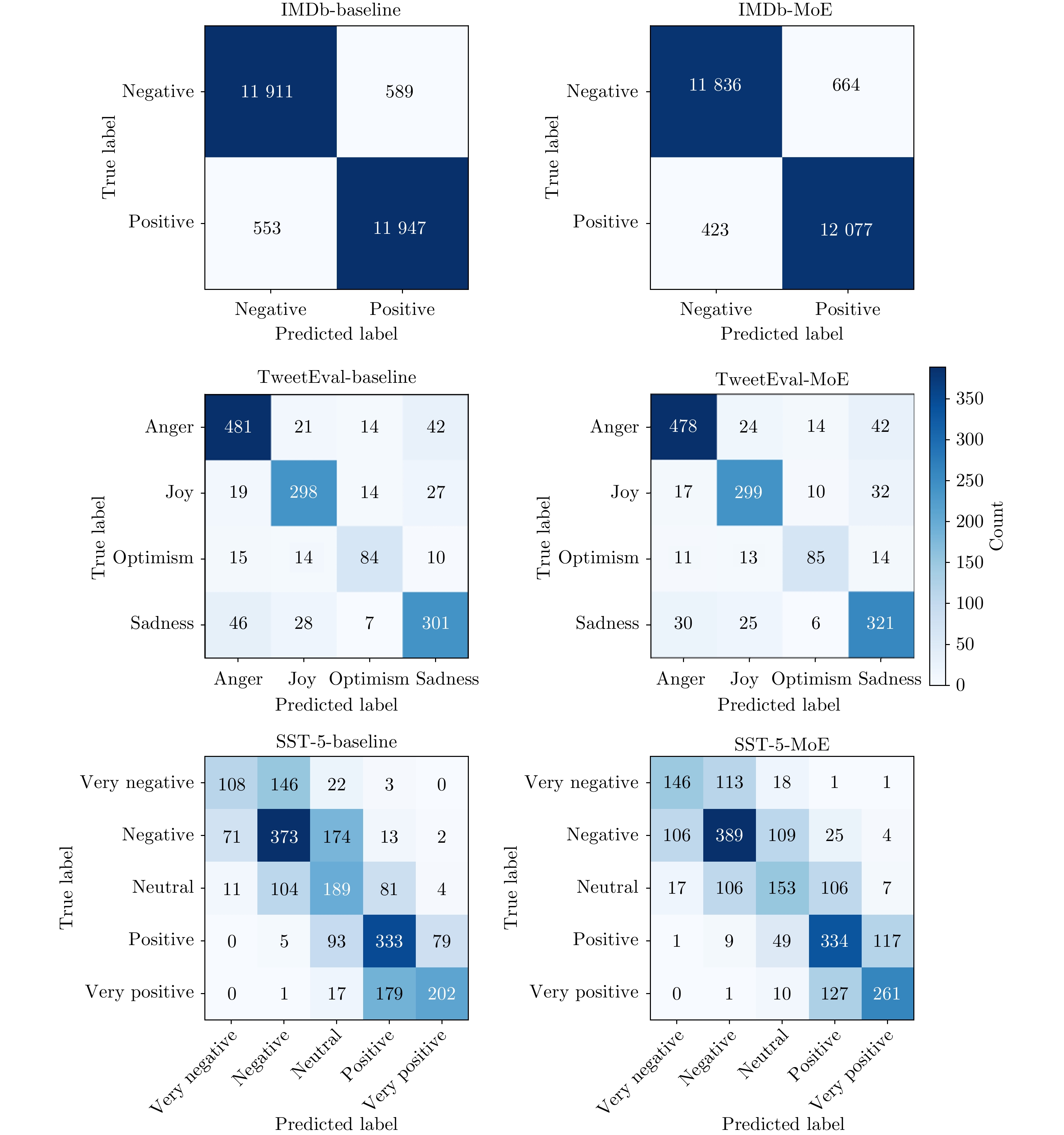
表 2 不同数据集上基线模型与 MoE 增强模型之间的性能比较
Table 2 Performance comparison between baseline and MoE-enhanced models on different datasets
数据集 模型结构 Accuracy Precision Recall F1-Score IMDb (二分类) 基线 0.9543 0.9543 0.9543 0.9543 MoE-RoBERTa 0.9565 0.9567 0.9565 0.9565 Llama-3-8B-Instruct + Zero-shot 0.9333 0.9164 0.9534 0.9346 Mistral-7B-Instruct + Zero-shot 0.9048 0.9751 0.8303 0.8969 Qwen2.5-7B-Instruct + Zero-shot 0.9424 0.9589 0.9240 0.9411 Llama-3-8B-Instruct + LoRA 0.9692 0.9660 0.9726 0.9693 Mistral-7B-Instruct + LoRA 0.9743 0.9724 0.9763 0.9743 Qwen2.5-7B-Instruct + LoRA 0.9659 0.9641 0.9678 0.9660 TweetEval (四分类) 基线 0.8191 0.8187 0.8191 0.8189 MoE-RoBERTa 0.8325 0.8338 0.8325 0.8327 Llama-3-8B-Instruct + Zero-shot 0.7570 0.7846 0.6611 0.6910 Mistral-7B-Instruct + Zero-shot 0.7720 0.7265 0.7433 0.7296 Qwen2.5-7B-Instruct + Zero-shot 0.7735 0.7416 0.7226 0.7265 Llama-3-8B-Instruct + LoRA 0.8248 0.8018 0.7978 0.7986 Mistral-7B-Instruct + LoRA 0.8381 0.8177 0.7902 0.8019 Qwen2.5-7B-Instruct + LoRA 0.7994 0.7974 0.7878 0.7928 SST-5 (五分类) 基线 0.5452 0.5621 0.5452 0.5464 MoE-RoBERTa 0.5805 0.5788 0.5805 0.5785 Llama-3-8B-Instruct + Zero-shot 0.3898 0.2697 0.3821 0.2495 Mistral-7B-Instruct + Zero-shot 0.4760 0.3922 0.4033 0.3531 Qwen2.5-7B-Instruct + Zero-shot 0.4841 0.4095 0.4322 0.3952 Llama-3-8B-Instruct + LoRA 0.5498 0.5568 0.5515 0.5541 Mistral-7B-Instruct + LoRA 0.6158 0.6148 0.5864 0.5888 Qwen2.5-7B-Instruct + LoRA 0.5398 0.5520 0.5429 0.5474
下载: 导出CSV
表 3 跨数据集和模型的性能与资源比较
Table 3 Performance and resource comparison across datasets and models
数据集 基座模型 方法 F1-Score Train (M) Total (M) Throughput (samples/s) GFLOPs Peak Mem (MB) IMDb Llama-3-8B-Instruct LoRA 0.9693 41.94 4582.54 2.997 4346.11 14955.8 Zero-shot 0.9346 — 4582.54 9.926 4037.17 — Mistral-7B-Instruct LoRA 0.9743 41.94 3800.31 2.239 4746.59 11248.3 Zero-shot 0.8969 — 3800.31 10.077 4327.97 — Qwen2.5-7B-Instruct LoRA 0.9660 40.37 4393.34 2.997 3634.03 19273.1 Zero-shot 0.9411 — 4393.34 8.187 3724.80 — RoBERTa BitFit 0.9036 0.10 124.65 873.470 45.90 1326.3 Full FT 0.9378 124.65 124.65 796.689 45.90 2702.8 LoRA 0.9310 0.89 125.53 659.302 46.05 1512.8 P-Tuning 0.7966 0.61 125.25 857.970 49.69 1439.2 MoE 0.9426 172.42 172.42 900.251 41.56 7429.5 TweetEval Llama-3-8B-Instruct LoRA 0.8083 41.94 4582.54 2.353 1171.26 11418.3 Zero-shot 0.6910 — 4582.54 50.868 1159.01 — Mistral-7B-Instruct LoRA 0.8019 41.94 3800.31 2.214 1280.33 11241.9 Zero-shot 0.7296 — 3800.31 48.024 1266.92 — Qwen2.5-7B-Instruct LoRA 0.8013 40.37 4393.34 3.124 1016.73 14166.8 Zero-shot 0.7265 — 4393.34 42.518 1010.61 — RoBERTa BitFit 0.1410 0.10 124.65 882.097 45.90 1326.3 Full FT 0.7962 124.65 124.65 835.678 45.90 2701.5 LoRA 0.5932 0.89 125.54 628.113 46.05 1512.8 P-Tuning 0.1410 0.61 125.26 889.742 49.69 1439.3 MoE 0.8039 200.74 200.74 890.958 42.65 8152.4 SST-5 Llama-3-8B-Instruct LoRA 0.5692 41.94 4582.54 2.385 1218.74 12301.7 Zero-shot 0.2495 — 4582.54 48.552 1225.63 — Mistral-7B-Instruct LoRA 0.5888 41.94 3800.31 2.204 1381.64 11578.2 Zero-shot 0.3531 — 3800.31 44.868 1378.78 — Qwen2.5-7B-Instruct LoRA 0.5649 40.37 4393.34 3.214 1093.97 15825.3 Zero-shot 0.3952 — 4393.34 40.558 1061.08 — RoBERTa BitFit 0.0870 0.10 124.65 888.373 45.90 1326.3 Full FT 0.5432 124.65 124.65 853.694 45.90 2699.3 LoRA 0.4805 0.89 125.54 651.461 46.05 1512.8 P-Tuning 0.1385 0.61 125.26 860.703 49.69 1439.3 MoE 0.5532 172.42 172.42 910.685 41.93 8404.0
下载: 导出CSV
表 4 不同数据集上基线与引入 MoE 后模型的性能对比
Table 4 Performance comparison between baseline and MoE-enhanced models on different datasets
数据集 模型结构 Accuracy Precision Recall F1-Score IMDb 普通FFN 0.9551 0.9552 0.9551 0.9551 门控专家 0.9565 0.9567 0.9565 0.9565 TweetEval 普通FFN 0.8220 0.8222 0.8220 0.8215 门控专家 0.8325 0.8338 0.8325 0.8327 SST-5 普通FFN 0.5683 0.5677 0.5683 0.5666 门控专家 0.5805 0.5788 0.5805 0.5785
下载: 导出CSV
-
[1] Bordoloi M, Biswas S K. Sentiment analysis: A survey on design framework, applications and future scopes. Artificial Intelligence Review, 2023, 56(11): 12505−12560 doi: 10.1007/s10462-023-10442-2 [2] 郑治豪, 吴文兵, 陈鑫, 胡荣鑫, 柳鑫, 王璞. 基于社交媒体大数据的交通感知分析系统. 自动化学报, 2018, 44(4): 656−666 doi: 10.16383/j.aas.2017.c160537Zheng Zhi-Hao, Wu Wen-Bing, Chen Xin, Hu Rong-Xin, Liu Xin, Wang Pu. A traffic sensing and analyzing system using social media data. Acta Automatica Sinica, 2018, 44(4): 656−666 doi: 10.16383/j.aas.2017.c160537 [3] 王会东, 李兆东, 姚金丽, 余德淦. 基于对称三角模糊集的股票投资者情绪传播模型. 自动化学报, 2020, 46(5): 1031−1043Wang Hui-Dong, Li Zhao-Dong, Yao Jin-Li, Yu De-Gan. Sentimental propagation model of stock investors based on symmetric triangular fuzzy set. Acta Automatica Sinica, 2020, 46(5): 1031−1043 [4] 何欣润, 李毅轩, 傅中正, 伍冬睿, 黄剑. 多标签情感计算中的TSK模糊系统与域适应方法研究. 自动化学报, 2025, 51(7): 1546−1561He Xin-Run, Li Yi-Xuan, Fu Zhong-Zheng, Wu Dong-Rui, Huang Jian. A study of TSK fuzzy system and domain adaptation method in multi-label affective computing. Acta Automatica Sinica, 2025, 51(7): 1546−1561 [5] Baccianella S, Esuli A, Sebastiani F. SentiWordNet 3.0: An enhanced lexical resource for sentiment analysis and opinion mining. In: Proceedings of the 7th International Conference on Language Resources and Evaluation (LREC). Valletta, Malta: European Language Resources Association, 2010. 83−90 [6] 栗雨晴, 礼欣, 韩煦, 宋丹丹, 廖乐健. 基于双语词典的微博多类情感分析方法. 电子学报, 2016, 44(9): 2068−2073Li Yu-Qing, Li Xin, Han Xu, Song Dan-Dan, Liao Le-Jian. A bilingual lexicon-based multi-class semantic orientation analysis for microblogs. Acta Electronica Sinica, 2016, 44(9): 2068−2073 [7] 赵妍妍, 秦兵, 石秋慧, 刘挺. 大规模情感词典的构建及其在情感分类中的应用. 中文信息学报, 2017, 31(2): 187−193Zhao Yan-Yan, Qin Bing, Shi Qiu-Hui, Liu Ting. Large-scale sentiment lexicon collection and its application in sentiment classification. Journal of Chinese Information Processing, 2017, 31(2): 187−193 [8] 杨爽, 陈芬. 基于SVM多特征融合的微博情感多级分类研究. 数据分析与知识发现, 2017, 1(2): 73−79Yang Shuang, Chen Fen. Analyzing sentiments of micro-blog posts based on support vector machine. Data Analysis and Knowledge Discovery, 2017, 1(2): 73−79 [9] Li J, Rao Y H, Jin F M, Chen H J, Xiang X Y. Multi-label maximum entropy model for social emotion classification over short text. Neurocomputing, 2016, 210: 247−256 doi: 10.1016/j.neucom.2016.03.088 [10] Alaie A I, Farooq U, Bhat W A, Khurana S S, Singh P. An empirical study on sentimental drug review analysis using lexicon and machine learning-based techniques. SN Computer Science, 2024, 5(1): Article No. 63 doi: 10.1007/s42979-023-02384-x [11] 王科, 夏睿. 情感词典自动构建方法综述. 自动化学报, 2016, 42(4): 495−511Wang Ke, Xia Rui. A survey on automatical construction methods of sentiment lexicons. Acta Automatica Sinica, 2016, 42(4): 495−511 [12] Lai Y N, Zhang L F, Han D H, Zhou R, Wang G R. Fine-grained emotion classification of Chinese microblogs based on graph convolution networks. World Wide Web, 2020, 23(5): 2771− 2787 doi: 10.1007/s11280-020-00803-0 [13] Chen L H, Varoquaux G. What is the role of small models in the LLM era: A survey. arXiv preprint arXiv: 2409.06857, 2025. [14] Rezapour M. Emotion detection with Transformers: A comparative study. arXiv preprint arXiv: 2403.15454, 2024. [15] di Palma D, de Bellis A, Servedio G, Anelli V W, Narducci F, di Noia T. LLaMAs have feelings too: Unveiling sentiment and emotion representations in LLaMA models through probing. In: Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Vienna, Austria: Association for Computational Linguistics, 2025: 6124−6142 [16] Chen K Z, Wang S, Ben H X, Tang S G, Hao Y B. Mixture of multimodal adapters for sentiment analysis. In: Proceedings of the Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). Albuquerque, New Mexico: Association for Computational Linguistics, 2025. 1822−1833 [17] Lo K M, Huang Z Y, Qiu Z H, Wang Z L, Fu J. A closer look into mixture-of-experts in large language models. Findings of the Association for Computational Linguistics: NAACL 2025, 2025. 4427−4447 doi: 10.1109/tkde.2025.3554028/mm1 [18] Mu S Y, Lin S. A comprehensive survey of mixture-of-experts: Algorithms, theory, and applications. arXiv preprint arXiv: 2503.07137, 2025. [19] Nnamdi J, Dimitri V, Amar S. Improving deep learning performance with mixture of experts and sparse activation. Preprints 2025, DOI: 10.20944/preprints202503.0611.v1 [20] Nguyen H, Ho N, Rinaldo A. On least square estimation in softmax gating mixture of experts. In: Proceedings of the 41st International Conference on Machine Learning (ICML). Vienna, Austria: PMLR, 2024. 37707−37735 [21] Wang K, Shen W Z, Yang Y Y, Quan X J, Wang R. Relational graph attention network for aspect-based sentiment analysis. In: Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Virtual Event: Association for Computational Linguistics, 2020. 3229−3238 [22] Talaat A S. Sentiment analysis classification system using hybrid BERT models. Journal of Big Data, 2023, 10(1): Article No. 110 doi: 10.1186/s40537-023-00781-w [23] Krishnamoorthy A, Sundhar K A, Naveen K V, Karthik V. Analyzing sentiments: A comprehensive study of Roberta-based sentiment analysis on twitters. In: Proceedings of the 4th International Conference on Advancement in Electronics & Communication Engineering (AECE). Ghaziabad, India: IEEE, 2024. 626−630 [24] Cai W L, Jiang J Y, Wang F, Tang J, Kim S, Huang J Y. A survey on mixture of experts in large language models. IEEE Transactions on Knowledge and Data Engineering, 2025, 37(7): 3896−3915 [25] Shazeer N, Mirhoseini A, Maziarz K, Davis A, Le Q, Hinton G, et al. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. In: Proceedings of the 5th International Conference on Learning Representations (ICLR). Toulon, France: OpenReview.net, 2017. [26] Fedus W, Zoph B, Shazeer N. Switch Transformers: Scaling to trillion parameter models with simple and efficient sparsity. The Journal of Machine Learning Research, 2022, 23(1): Article No. 120 [27] Du N, Huang Y P, Dai A M, Tong S, Lepikhin D, Xu Y Z, et al. GLaM: Efficient scaling of language models with mixture-of-experts. In: Proceedings of the 39th International Conference on Machine Learning (ICML). Baltimore, USA: PMLR, 2022. 5547−5569 [28] Zhu T, Qu X Y, Dong D Z, Ruan J C, Tong J Q, He C H, et al. LLaMA-MoE: Building mixture-of-experts from LLaMA with continual pre-training. In: Proceedings of the Conference on Empirical Methods in Natural Language Processing. Miami, USA: Association for Computational Linguistics, 2024. 15913−15923 [29] Tairin S, Mahmud S, Shen H Y, Iyer A. eMoE: Task-aware memory efficient mixture-of-experts-based (MoE) model inference. arXiv preprint arXiv: 2503.06823, 2025. [30] Liu Y H, Ott M, Goyal N, Du J F, Joshi M, Chen D Q, et al. RoBERTa: A robustly optimized BERT pretraining approach. arXiv preprint arXiv: 1907.11692, 2019. -

 下载:
下载:


计量
- 文章访问数: 520
- HTML全文浏览量: 366
- PDF下载量: 86
- 被引次数: 0
