

Toward Trustworthy Policy Optimization for Autonomous Driving: An Adversarial Robust Reinforcement Learning Approach
-
摘要: 虽然强化学习近年来取得显著成功, 但策略鲁棒性仍然是其在安全攸关的自动驾驶领域部署的关键瓶颈之一. 一个根本性挑战在于, 许多现实世界中的自动驾驶任务面临难以预测的环境变化和不可避免的感知噪声, 这些不确定性因素可能导致系统执行次优的决策与控制, 甚至引发灾难性后果. 针对上述多源不确定性问题, 提出一种对抗鲁棒强化学习方法, 实现可信端到端控制策略优化. 首先, 构建一个可在线学习的对手模型, 用于同时逼近最坏情况下环境动态扰动与状态观测扰动. 其次, 基于零和博弈建模自动驾驶智能体与环境动态扰动之间的对抗性. 再次, 针对所模拟的多源不确定性, 提出鲁棒约束演员–评论家算法, 在连续动作空间下实现策略累积奖励最大化的同时, 有效约束环境动态扰动与状态观测扰动对所学端到端控制策略的影响. 最后, 将所提出的方案在不同的场景、交通流及扰动条件下进行评估, 并与三种代表性的方法进行对比分析, 验证了该方法在复杂工况和对抗环境中的有效性与鲁棒性.Abstract: While reinforcement learning has achieved remarkable success in recent years, policy robustness remains one of the critical bottlenecks for its deployment in safety-critical autonomous driving domains. A fundamental challenge lies in the unpredictable environmental changes and unavoidable perception noises that many real-world autonomous driving tasks face. These uncertainties can lead the system to make suboptimal decision and control, potentially resulting in catastrophic consequences. To address the aforementioned multi-source uncertainty issues, we propose an adversarial robust reinforcement learning approach to achieve trustworthy end-to-end control policy optimization. First, we construct an online-learnable adversary model that simultaneously approximates the worst-case perturbations in both environmental dynamics and state observations. Second, the interaction between the autonomous driving agent and environmental dynamic perturbations is formulated as a zero-sum game to model their adversarial nature. Third, to address the simulated multi-source uncertainties, we propose a robust constrained actor-critic algorithm that maximizes policy cumulative rewards in the continuous action space while effectively constraining the impact of perturbations in environmental dynamics and state observations on the learned end-to-end control policy. Finally, the proposed approach is evaluated across diverse scenarios, traffic flows and perturbation conditions, and is compared with three representative methods. The results validate its effectiveness and robustness under complex working conditions and adversarial environments.
-

图 1 面向可信自动驾驶策略优化的对抗鲁棒强化学习框架
Fig. 1 Adversarial robust reinforcement learning framework for trustworthy autonomous driving policy optimization

图 2 自动驾驶策略模型的评估方案((a)和(b)分别表示自动驾驶智能体在无对抗观测扰动和 存在对抗观测扰动下的评估方案)
Fig. 2 Evaluation scheme for autonomous driving policy models ((a) and (b) show evaluation schemes of the autonomous driving agent under the conditions of no adversarial observation perturbation and the presence of adversarial observation perturbation, respectively)

图 3 不同强化学习方法训练的策略模型性能对比((a) ~ (c)分别展示各模型在平均回报、成功率及行驶效率方面的性能)
Fig. 3 Performance comparison of policy models trained with different reinforcement learning methods ((a) ~ (c) show the performance of each model in terms of average return, success rate, and driving efficiency, respectively)
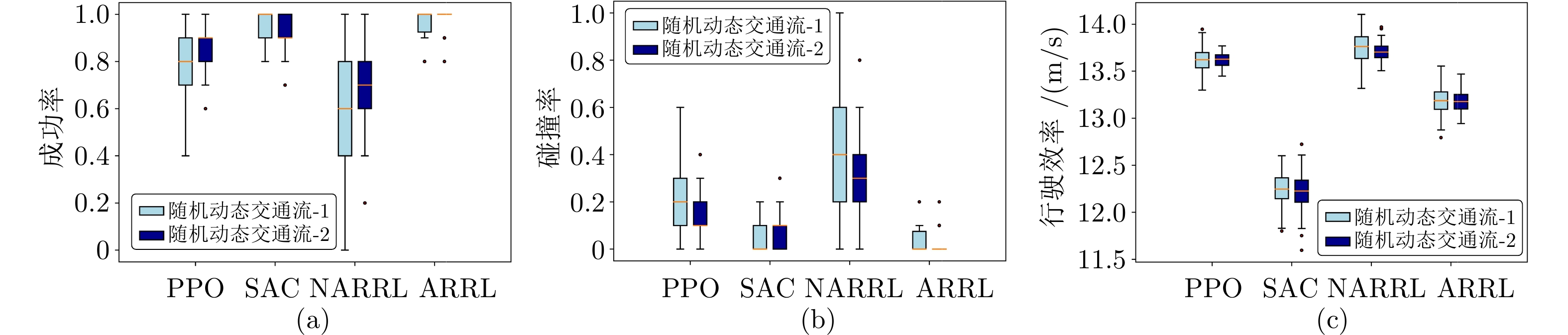
图 4 自动驾驶策略模型在不同交通流下的性能对比((a) ~ (c)分别展示各模型在成功率、碰撞率及行驶效率方面的性能)
Fig. 4 Performance comparison of autonomous driving policy models under different traffic flows ((a) ~ (c) show the performance of each model in terms of success rate, collision rate, and driving efficiency, respectively)
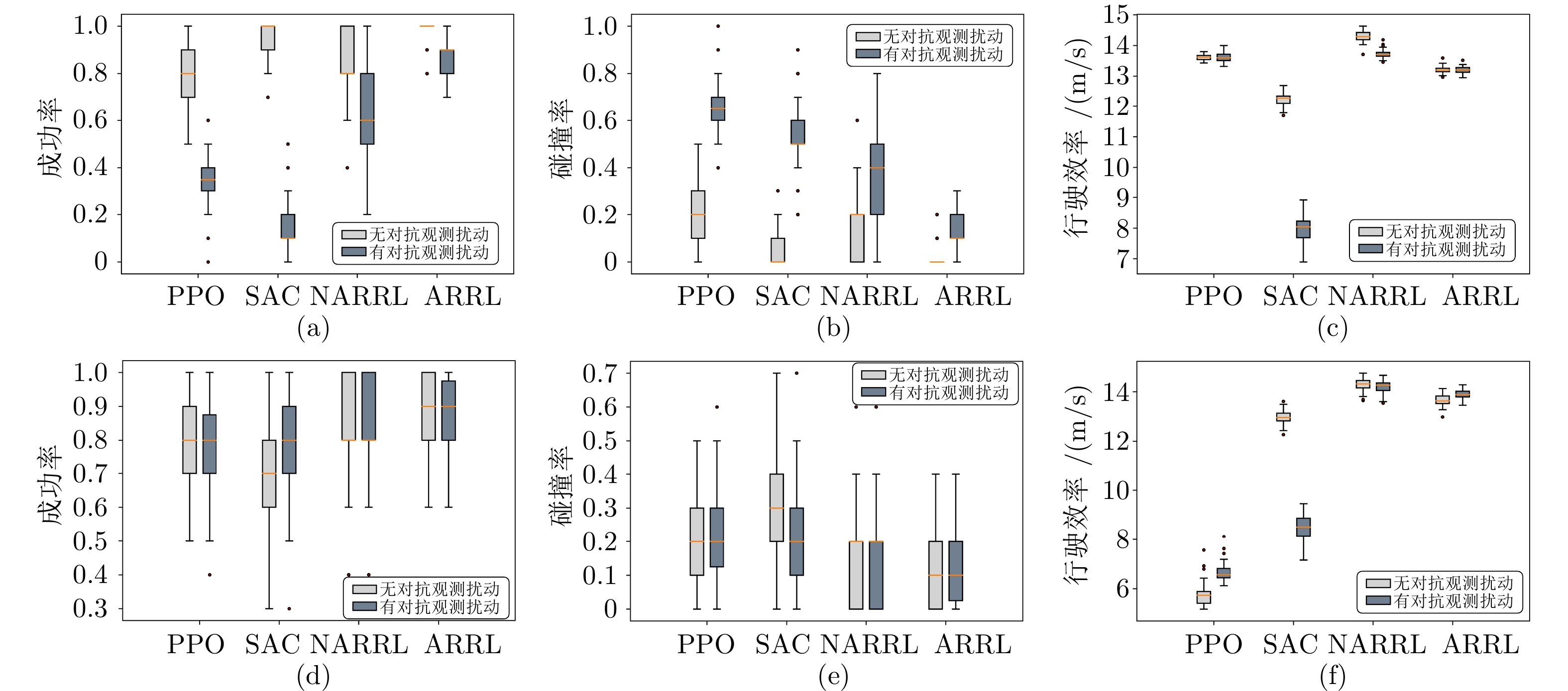
图 5 自动驾驶策略模型在不同交通环境和对抗条件下的性能对比((a) ~ (c)分别展示各模型在交叉口场景下的成功率、 碰撞率及行驶效率方面的性能; (d) ~ (f)分别展示各模型在匝道场景下的性能)
Fig. 5 Performance comparison of autonomous driving policy models under different traffic environments and adversarial conditions ((a) ~ (c) respectively show the performance of each model in terms of success rate, collision rate, and driving efficiency in the intersection scenario; (d) ~ (f) respectively show the performance of each model in the ramp scenario)
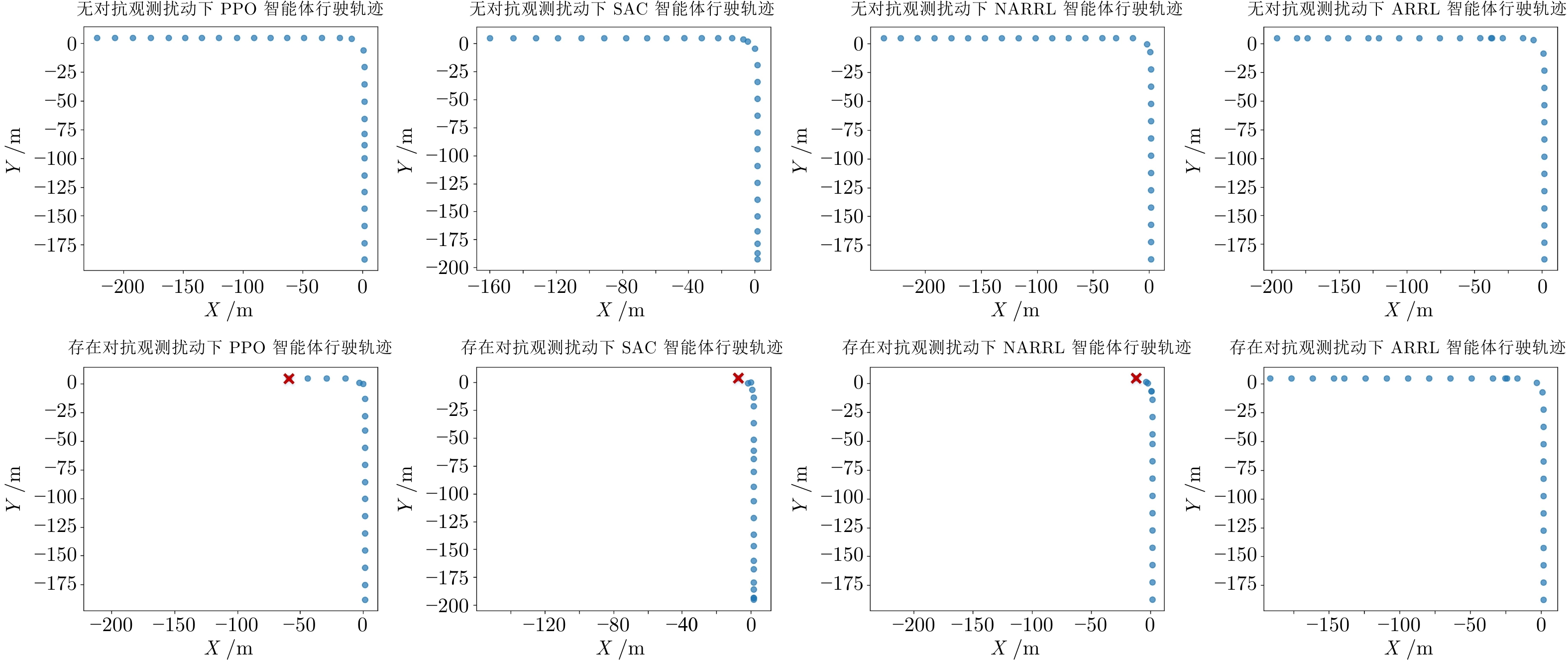
图 6 自动驾驶智能体在不同对抗攻击条件下的行驶轨迹
Fig. 6 The driving trajectories of autonomous driving agents under different adversarial attack conditions
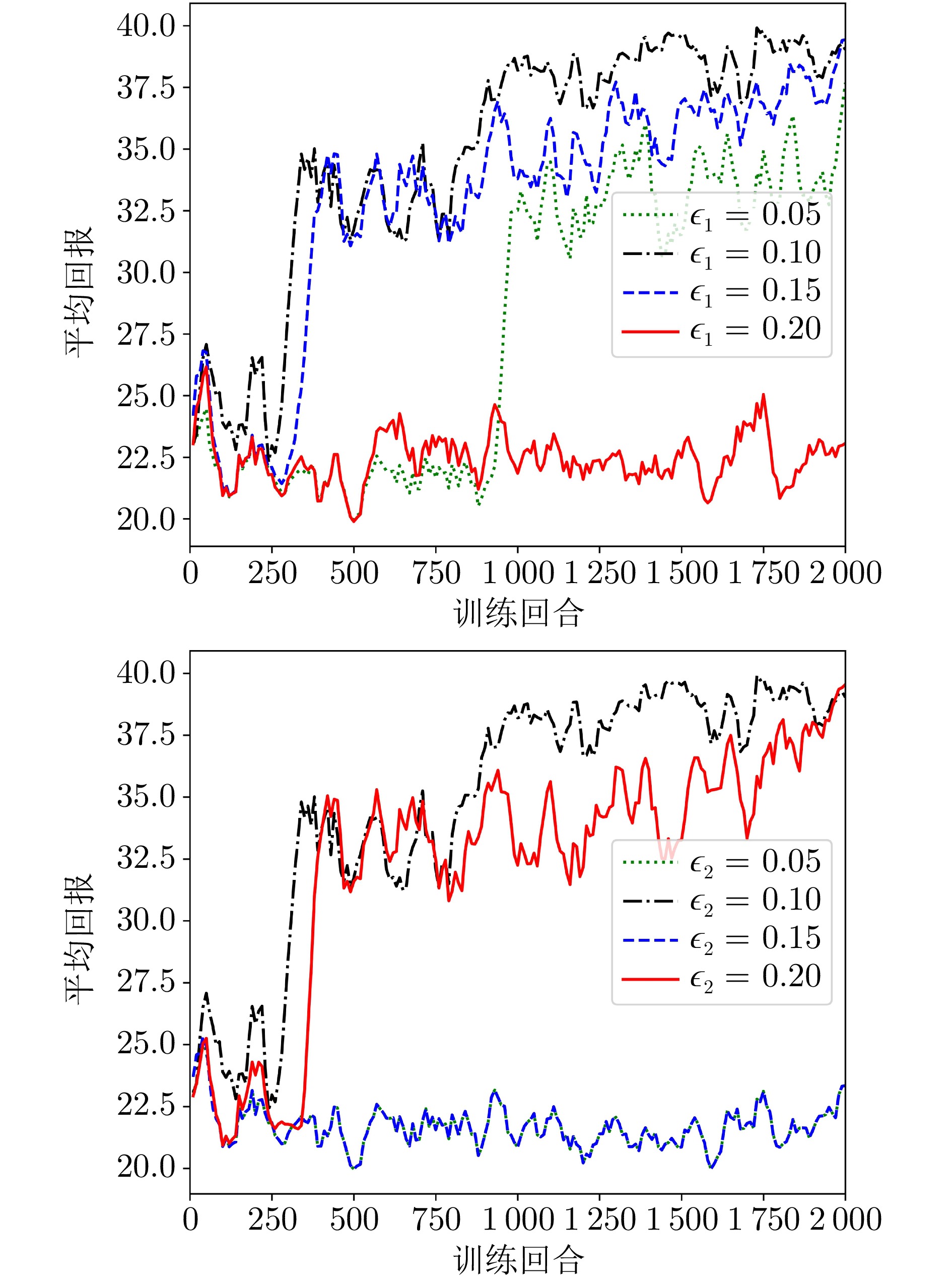
图 7 约束函数上界设定对模型性能的影响分析与对比
Fig. 7 Analysis and comparison of the impact of constraint function upper bound settings on model performance
表 1 自动驾驶智能体在不同交通流条件下模型测试统计结果
Table 1 Statistical results of model testing of autonomous driving agents under different traffic flow conditions
指标 PPO SAC NARRL ARRL 交通流-1 交通流-2 交通流-1 交通流-2 交通流-1 交通流-2 交通流-1 交通流-2 平均回报 $ 36.41 \pm 2.69 $ $ 37.58 \pm 2.34 $ $ 35.93 \pm 1.37 $ $ 35.33 \pm 1.54 $ $ 33.27 \pm 6.11 $ $ 34.40 \pm 4.74 $ $ {\bf{38.90}} \pm {\bf{1.42}} \;$ $ {\bf{39.09}} \pm {\bf{1.33}} \;$ 成功率 $ 0.78 \pm 0.12 $ $ 0.84 \pm 0.11 $ $ 0.95 \pm 0.07 $ $ 0.93 \pm 0.08 $ $ 0.64 \pm 0.26 $ $ 0.70 \pm 0.21 $ $ {\bf{0.97}} \pm {\bf{0.05}}\;$ $ {\bf{0.98}} \pm {\bf{0.04}}\;$ 碰撞率 $ 0.22 \pm 0.12 $ $ 0.16 \pm 0.11 $ $ 0.04 \pm 0.06 $ $ 0.07 \pm 0.08 $ $ 0.36 \pm 0.26 $ $ 0.30 \pm 0.21 $ $ {\bf{0.03}} \pm {\bf{0.05}}\; $ $ {\bf{0.02}} \pm {\bf{0.04}}\; $ 行驶效率 $ 13.62 \pm 0.13 $ $ 13.62 \pm 0.08 $ $ 12.22 \pm 0.19 $ $ 12.21 \pm 0.21 $ $ {\bf{13.77}} \pm {\bf{0.17}}\; $ $ {\bf{13.71}} \pm {\bf{0.10}} \;$ $ 13.20 \pm 0.17 $ $ 13.18 \pm 0.11 $  下载: 导出CSV
下载: 导出CSV
表 2 不同攻击条件下自动驾驶智能体在交叉口场景中的模型测试统计结果
Table 2 Statistical results of model testing of autonomous driving agents in the intersection scenario under different attack conditions
指标 PPO SAC NARRL ARRL 无攻击 有攻击 无攻击 有攻击 无攻击 有攻击 无攻击 有攻击 平均回报 $ 36.71 \pm 2.56 $ $ 31.61 \pm 2.96 $ $ 35.83 \pm 1.34 $ $ 20.94 \pm 1.13 $ $ 38.92 \pm 3.71 $ $ 33.45 \pm 4.93 $ $ {\bf{39.00}} \pm {\bf{1.45}} \;$ $ {\bf{37.01}} \pm {\bf{1.92}} \;$ 成功率 $ 0.80 \pm 0.12 $ $ 0.35 \pm 0.13 $ $ 0.95 \pm 0.07 $ $ 0.14 \pm 0.12 $ $ 0.83 \pm 0.15 $ $ 0.65 \pm 0.21 $ $ {\bf{0.98}} \pm {\bf{0.05}} \;$ $ {\bf{0.88}} \pm {\bf{0.09}} \;$ 碰撞率 $ 0.20 \pm 0.12 $ $ 0.65 \pm 0.13 $ $ 0.05 \pm 0.07 $ $ 0.55 \pm 0.17 $ $ 0.17 \pm 0.15 $ $ 0.35 \pm 0.21 $ $ {\bf{0.02}} \pm {\bf{0.05}} \;$ $ {\bf{0.12}} \pm {\bf{0.09}} \;$ 行驶效率 $ 13.61 \pm 0.09 $ $ 13.61 \pm 0.15 $ $ 12.23 \pm 0.19 $ $ 7.98 \pm 0.41 $ $ {\bf{14.30}} \pm {\bf{0.17}}\; $ $ {\bf{13.71}} \pm {\bf{0.15}}\; $ $13.21 \pm 0.12 $ $ 13.21 \pm 0.11 $ 鲁棒性 — $ 0.17 \pm 0.00 $ — $ 0.36 \pm 0.04 $ — $ 0.15 \pm 0.04 $ — $ {\bf{0.04}} \pm {\bf{0.01}} \;$
下载: 导出CSV
表 3 不同攻击条件下自动驾驶智能体在匝道场景中的模型测试统计结果
Table 3 Statistical results of model testing of autonomous driving agents in the ramp scenario under different attack conditions
指标 PPO SAC NARRL ARRL 无攻击 有攻击 无攻击 有攻击 无攻击 有攻击 无攻击 有攻击 平均回报 $ 14.34 \pm 1.32 $ $ 16.42 \pm 1.56 $ $ 31.80 \pm 4.38 $ $ 21.25 \pm 3.13 $ $ {\bf{38.48}} \pm {\bf{5.31}} \;$ $ {\bf{38.39}} \pm {\bf{5.03}} \;$ $ 37.30 \pm 3.55 $ $\; 37.87 \pm 3.72 $ 成功率 $ 0.77 \pm 0.14 $ $ 0.77 \pm 0.12 $ $ 0.72 \pm 0.15 $ $ 0.76 \pm 0.15 $ $ 0.84 \pm 0.16 $ $ 0.86 \pm 0.15 $ $ {\bf{0.88}} \pm {\bf{0.11}}\; $ $ {\bf{0.87}} \pm {\bf{0.11}}\; $ 碰撞率 $ 0.23 \pm 0.14 $ $ 0.23 \pm 0.12 $ $ 0.28 \pm 0.15 $ $ 0.24 \pm 0.15 $ $ 0.16 \pm 0.16 $ $ 0.14 \pm 0.15 $ $ {\bf{0.12}} \pm {\bf{0.11}} \;$ $ {\bf{0.13}} \pm {\bf{0.11}}\; $ 行驶效率 $ 5.77 \pm 0.47 $ $ 6.66 \pm 0.36 $ $ 12.97 \pm 0.26 $ $ 8.50 \pm 0.52 $ $ {\bf{14.31}} \pm {\bf{0.26}} \;$ $ {\bf{14.19}} \pm {\bf{0.26}} \;$ $ 13.65 \pm 0.22 $ $ 13.90 \pm 0.19 $ 鲁棒性 — $ 0.17 \pm 0.00 $ — $ 0.26 \pm 0.01 $ — $ 0.13 \pm 0.06 $ — $ {\bf{0.10}} \pm {\bf{0.02}}\; $
下载: 导出CSV
-
[1] Chen L, Wu P, Chitta K, Jaeger B, Geiger A, Li H. End-to-end autonomous driving: Challenges and frontiers. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024, 46(12): 10164−10183 doi: 10.1109/TPAMI.2024.3435937 [2] Almaskati D, Kermanshachi S, Pamidimukkala A. Convergence of emerging transportation trends: A comprehensive review of shared autonomous vehicles. Journal of Intelligent and Connected Vehicles, 2024, 7(3): 177−189 doi: 10.26599/JICV.2023.9210043 [3] 褚端峰, 王如康, 王竞一, 花俏枝, 陆丽萍, 吴超仲. 端到端自动驾驶的研究进展及挑战. 中国公路学报, 2024, 37(10): 209−232Chu Duan-Feng, Wang Ru-Kang, Wang Jing-Yi, Hua Qiao-Zhi, Lu Li-Ping, Wu Chao-Zhong. End-to-end autonomous driving: Advancements and challenges. China Journal of Highway and Transport, 2024, 37(10): 209−232 [4] Pomerleau D A. ALVINN: An autonomous land vehicle in a neural network. In: Proceedings of the 2nd International Conference on Neural Information Processing Systems (NIPS). Denver, CO, USA: NIPS Foundation, 1988. 305−313 [5] Bojarski M, del Testa D, Dworakowski D, Firner B, Flepp B, Goyal P, et al. End to end learning for self-driving cars. arXiv preprint arXiv: 1604.07316, 2016. [6] Couto G C K, Antonelo E A. Generative adversarial imitation learning for end-to-end autonomous driving on urban environments. In: Proceedings of 2021 IEEE Symposium Series on Computational Intelligence (SSCI). Orlando, FL, USA: IEEE, 2021. 1−7 [7] Du J, Bai Y, Li Y, Geng J, Huang Y, Chen H. Evolutionary end-to-end autonomous driving model with continuous-time neural networks. IEEE/ASME Transactions on Mechatronics, 2024, 29(4): 2983−2990 doi: 10.1109/TMECH.2024.3402126 [8] Yang S, Wang W, Liu C, Deng W. Scene understanding in deep learning-based end-to-end controllers for autonomous vehicles. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2018, 49(1): 53−63 [9] Zheng W, Song R, Guo X, Zhang C, Chen L. GenAD: Generative end-to-end autonomous driving. In: Proceedings of the European Conference on Computer Vision. Milan, Italy: ECVA, 2024. 87−104 [10] Tampuu A, Matiisen T, Semikin M, Fishman D, Muhammad N. A survey of end-to-end driving: Architectures and training methods. IEEE Transactions on Neural Networks and Learning Systems, 2020, 33(4): 1364−1384 [11] le Mero L, Yi D, Dianati M, Mouzakitis A. A survey on imitation learning techniques for end-to-end autonomous vehicles. IEEE Transactions on Intelligent Transportation Systems, 2022, 23(9): 14128−14147 doi: 10.1109/TITS.2022.3144867 [12] 高阳, 陈世福, 陆鑫. 强化学习研究综述. 自动化学报, 2004, 30(1): 86−100Gao Yang, Chen Shi-Fu, Lu Xin. Research on reinforcement learning technology: A review. Acta Automatica Sinica, 2004, 30(1): 86−100 [13] Wang X, Wang S, Liang X, Zhao D, Huang J, Xu X, et al. Deep reinforcement learning: A survey. IEEE Transactions on Neural Networks and Learning Systems, 2022, 35(4): 5064−5078 [14] Kiran B R, Sobh I, Talpaert V, Mannion P, al Sallab A A, Yogamani S, et al. Deep reinforcement learning for autonomous driving: A survey. IEEE Transactions on Intelligent Transportation Systems, 2021, 23(6): 4909−4926 [15] He X, Wu J, Huang Z, Hu Z, Wang J, Sangiovanni-Vincentelli A, et al. Fear-neuro-inspired reinforcement learning for safe autonomous driving. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024, 46(1): 267−279 doi: 10.1109/TPAMI.2023.3322426 [16] 张兴龙, 陆阳, 李文璋, 徐昕. 基于滚动时域强化学习的智能车辆侧向控制算法. 自动化学报, 2023, 49(12): 2481−2492Zhang Xing-Long, Lu Yang, Li Wen-Zhang, Xu Xin. Receding horizon reinforcement learning algorithm for lateral control of intelligent vehicles. Acta Automatica Sinica, 2023, 49(12): 2481−2492 [17] Wu J, Huang C, Huang H, Lv C, Wang Y, Wang F Y. Recent advances in reinforcement learning-based autonomous driving behavior planning: A survey. Transportation Research Part C: Emerging Technologies, 2024, 164: 1−28 [18] Schulman J, Wolski F, Dhariwal P, Radford A, Klimov O. Proximal policy optimization algorithms. arXiv preprint arXiv: 1707.06347, 2017. [19] Haarnoja T, Zhou A, Hartikainen K, Tucker G, Ha S, Tan J, et al. Soft actor-critic algorithms and applications. arXiv preprint arXiv: 1812.05905, 2018. [20] Haarnoja T, Zhou A, Abbeel P, Levine S. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. In: Proceedings of International Conference on Machine Learning (ICML). Stockholm, Sweden: PMLR, 2018. 1861−1870 [21] Toromanoff M, Wirbel E, Moutarde F. End-to-end model-free reinforcement learning for urban driving using implicit affordances. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Washington, USA: IEEE, 2020. 7153−7162 [22] Osiński B, Jakubowski A, Zięcina P, Miłoś P, Galias C, Homoceanu S, et al. Simulation-based reinforcement learning for real-world autonomous driving. In: Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA). Paris, France: IEEE, 2020. 6411−6418 [23] Anzalone L, Barra P, Barra S, Castiglione A, Nappi M. An end-to-end curriculum learning approach for autonomous driving scenarios. IEEE Transactions on Intelligent Transportation Systems, 2022, 23(10): 19817−19826 doi: 10.1109/TITS.2022.3160673 [24] Chen J, Li S E, Tomizuka M. Interpretable end-to-end urban autonomous driving with latent deep reinforcement learning. IEEE Transactions on Intelligent Transportation Systems, 2021, 23(6): 5068−5078 [25] Amini A, Gilitschenski I, Phillips J, Moseyko J, Banerjee R, Karaman S, et al. Learning robust control policies for end-to-end autonomous driving from data-driven simulation. IEEE Robotics and Automation Letters, 2020, 5(2): 1143−1150 doi: 10.1109/LRA.2020.2966414 [26] Chen S, Wang M, Song W, Yang Y, Li Y, Fu M. Stabilization approaches for reinforcement learning-based end-to-end autonom-ous driving. IEEE Transactions on Vehicular Technology, 2020, 69(5): 4740−4750 doi: 10.1109/TVT.2020.2979493 [27] Peng B, Sun Q, Li S E, Kum D, Yin Y, Wei J, et al. End-to-end autonomous driving through dueling double deep Q-network. Automotive Innovation, 2021, 4: 328−337 doi: 10.1007/s42154-021-00151-3 [28] Moos J, Hansel K, Abdulsamad H, Stark S, Clever D, Peters J. Robust reinforcement learning: A review of foundations and recent advances. Machine Learning and Knowledge Extraction, 2022, 4(1): 276−315 doi: 10.3390/make4010013 [29] Mannor S, Mebel O, Xu H. Lightning does not strike twice: Robust MDPs with coupled uncertainty. In: Proceedings of the 29th International Coference on International Conference on Machine Learning (ICML). Edinburgh, Scotland: PMLR, 2012. 451−458 [30] Tirinzoni A, Petrik M, Chen X, Ziebart B. Policy-conditioned uncertainty sets for robust Markov decision processes. In: Proceedings of the 32nd Conference on Neural Information Processing Systems (NeurIPS 2018). Montréal, Canada: NIPS Foundation, 2018. 1−11 [31] Bhardwaj M, Xie T, Boots B, Jiang N, Cheng C A. Adversarial model for offline reinforcement learning. In: Proceedings of the 37th Conference on Neural Information Processing Systems (NeurIPS 2023). New Orleans, Louisiana, USA: NIPS Foundation, 2023. 1245−1269 [32] Zhang H, Chen H, Xiao C, Li B, Liu M, Boning D, et al. Robust deep reinforcement learning against adversarial perturbations on state observations. In: Proceedings of the 34th Conference on Neural Information Processing Systems (NeurIPS 2020). Vancouver, Canada: NIPS Foundation, 2020. 21024−21037 [33] Tessler C, Efroni Y, Mannor S. Action robust reinforcement learning and applications in continuous control. In: Proceedings of the 36th International Conference on Machine Learning (ICML). Long Beach, California, USA: PMLR, 2019. 6215−6224 [34] Kumar A, Levine A, Feizi S. Policy smoothing for provably robust reinforcement learning. In: Proceedings of the 10th International Conference on Learning Representations (ICLR). Virtual Event: ICLR, 2022. [35] Wu F, Li L, Huang Z, Vorobeychik Y, Zhao D, Li B. CROP: Certifying robust policies for reinforcement learning through functional smoothing. In: Proceedings of the 10th International Conference on Learning Representations (ICLR). Virtual Event: ICLR, 2022. [36] He X, Lou B, Yang H, Lv C. Robust decision making for autonomous vehicles at highway on-ramps: A constrained adversarial reinforcement learning approach. IEEE Transactions on Intelligent Transportation Systems, 2023, 24(4): 4103−4113 doi: 10.1109/TITS.2022.3229518 [37] He X, Huang W, Lv C. Toward trustworthy decision-making for autonomous vehicles: A robust reinforcement learning approach with safety guarantees. Engineering, 2024, 33: 77−89 doi: 10.1016/j.eng.2023.10.005 [38] Lopez P A, Behrisch M, Bieker-Walz L, Erdmann J, Fltterd Y P, Hilbrich R, et al. Microscopic traffic simulation using SUMO. In: Proceedings of 21st International Conference on Intelligent Transportation Systems (ITSC). Maui, HI, USA: IEEE, 2018. 2575−2582 [39] Bae I, Moon J, Jhung J, Suk H, Kim T, Park H, et al. Self-driving like a human driver instead of a robocar: Personalized comfortable driving experience for autonomous vehicles. arXiv preprint arXiv: 2001.03908, 2020. [40] Goodfellow I J, Shlens J, Szegedy C. Explaining and harnessing adversarial examples. In: Proceedings of the 3rd International Conference on Learning Representations (ICLR). San Diego, California, USA: ICLR, 2015. 1−11 -

 下载:
下载:

计量
- 文章访问数: 920
- HTML全文浏览量: 764
- PDF下载量: 176
- 被引次数: 0
