

-
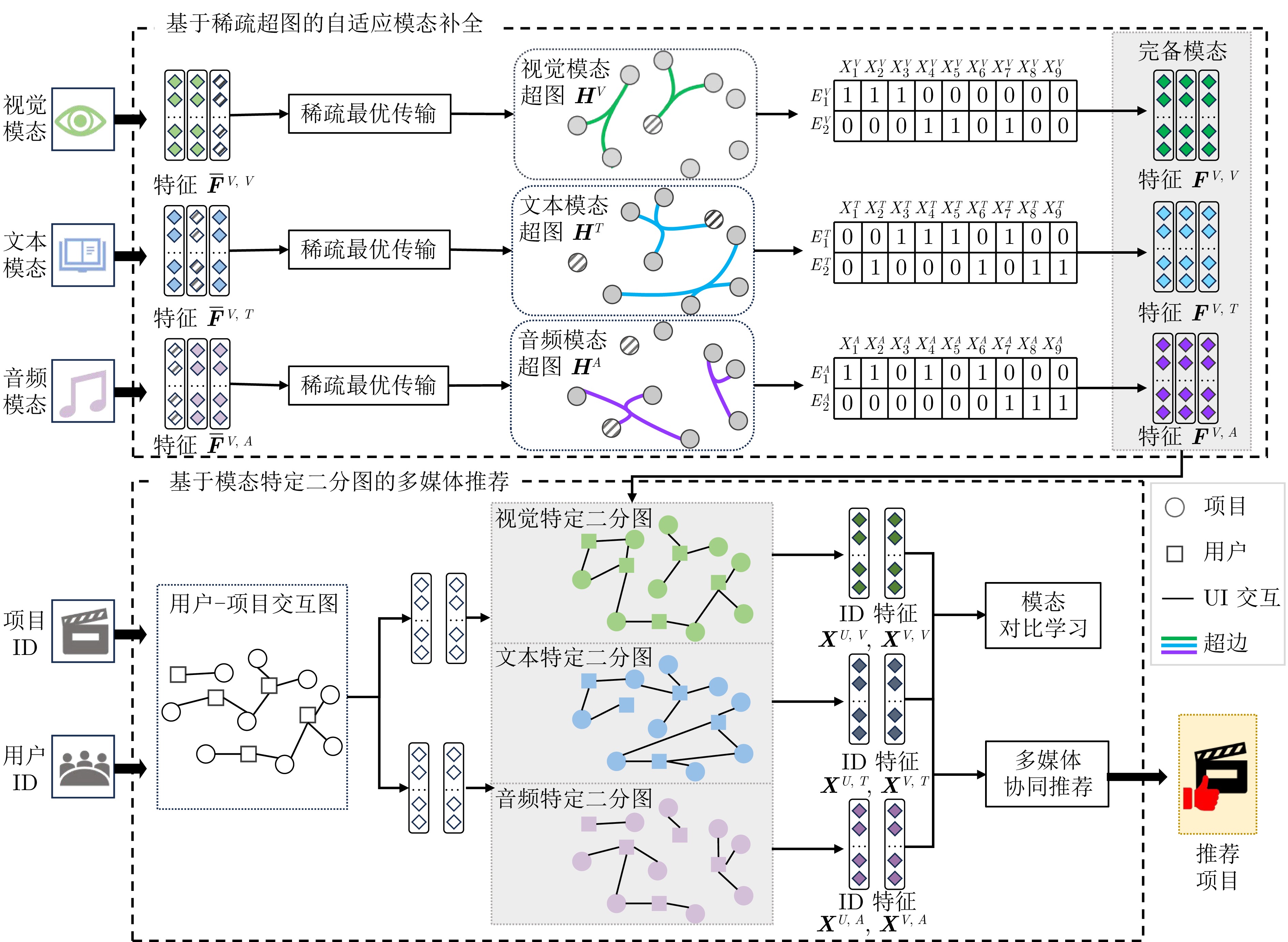
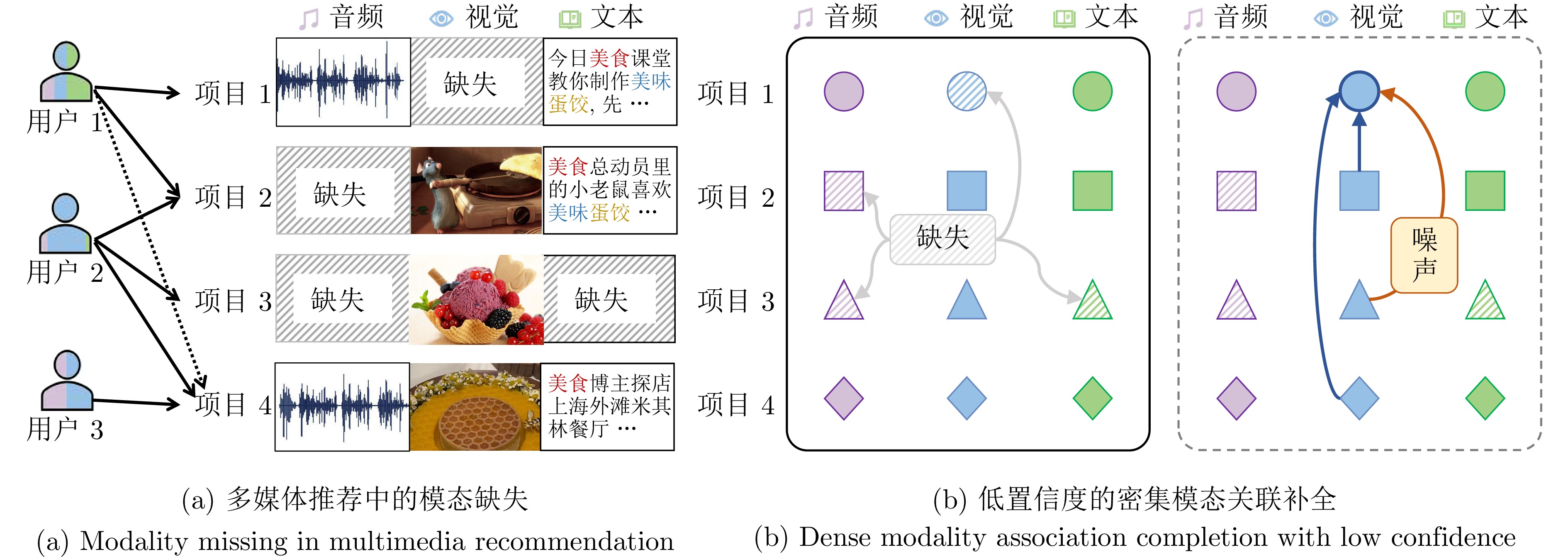
摘要: 随着多模态内容的快速增长, 多媒体推荐系统在数据挖掘中发挥着重要作用. 然而, 现有方法通常假设项目具有完备的多模态信息, 难以适应真实场景中的模态缺失问题. 针对这一挑战, 提出一种融合稀疏超图与模态特定二分图的非完备多媒体推荐框架(S2GRec). 该框架通过基于稀疏超图的自适应模态补全机制, 捕获模态内高阶相似性, 实现无监督的缺失模态补全, 并进一步利用模态特定二分图建模用户在不同模态视角下的偏好, 以提升推荐性能. 在多个公开数据集及大规模工业数据集上的实验结果表明, S2GRec在召回率、准确率和NDCG等指标上较现有方法平均提升4.42%, 验证了其在非完备多媒体推荐任务中的有效性.Abstract: With the rapid growth of multi-modal content, multimedia recommendation systems play an important role in data mining. However, existing methods typically assume that items possess complete multi-modal information, making it difficult to adapt to the issue of missing modalities in real-world scenarios. To address this challenge, this paper proposes a novel framework named S2GRec (sparse hypergraph and modality-specific bipartite graphs for incomplete multimedia recommendation). The framework captures high-order intra-modal similarities via an adaptive modality completion mechanism based on sparse hypergraphs to achieve unsupervised missing modality completion. Furthermore, it utilizes modality-specific bipartite graphs to model user preferences from different modal perspectives, thereby enhancing recommendation performance. Experimental results on multiple public datasets and large-scale industrial datasets demonstrate that S2GRec achieves an average improvement of 4.42% over state-of-the-art methods in terms of Recall, Precision, and NDCG, validating its effectiveness in incomplete multimedia recommendation tasks.
-
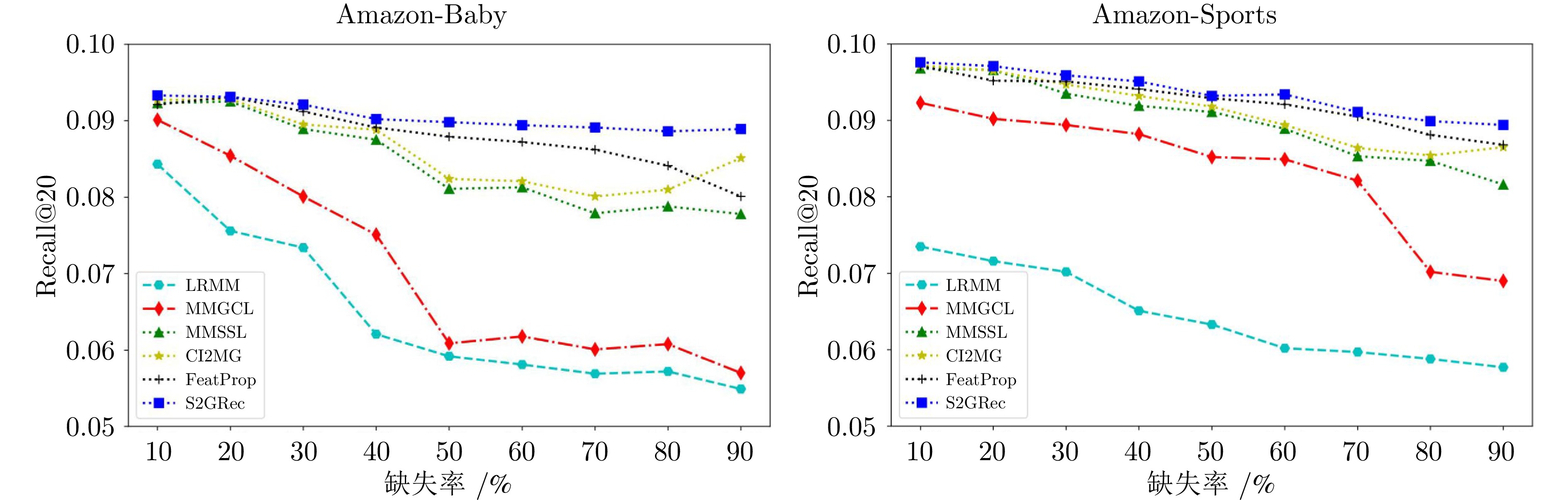
图 3 不同缺失率下的S2GRec与其他方法在Amazon-Baby和Amazon-Sports数据集上的Recall@20性能比较
Fig. 3 Recall@20 performance comparison of S2GRec and other methods under different missing rates on Amazon-Baby and Amazon-Sports datasets
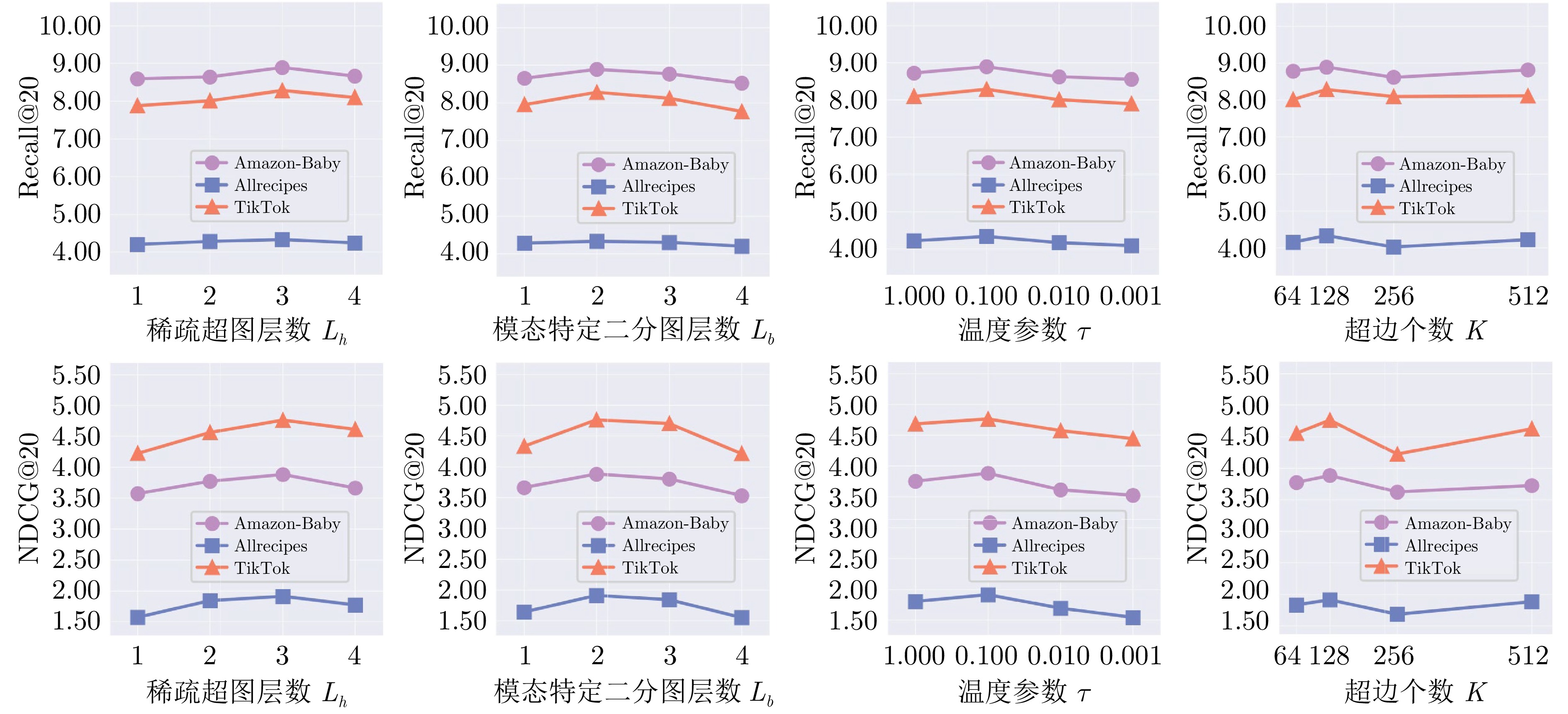
图 4 不同超参数下的S2GRec框架在Amazon-Baby、Allrecipes和TikTok数据集上关于Recall@20、NDCG@20的性能
Fig. 4 Performance of the S2GRec framework with different hyperparameters on Amazon-Baby, Allrecipes, and TikTok datasets for Recall@20 and NDCG@20
表 1 基本符号定义表
Table 1 Basic notation definition table
符号 定义 $ {\boldsymbol{R}} $ 用户和项目间的购买关系描述矩阵 $ {\overline{\boldsymbol{F}}}^{V,\; m} $ $ m \; $模态下项目的原始特征 $ {\boldsymbol{H}}^{m} $ $ m \; $模态下项目的稀疏超图结构 $ {\boldsymbol{F}}^{V,\; m} $ $ m \; $模态下补全后的项目的多模态特征 $ {\boldsymbol{E}}^V $、$ {\boldsymbol{E}}^T $、$ {\boldsymbol{E}}^A $ 视觉、文本、音频模态下的项目超边嵌入 $ {\hat{\boldsymbol{\Psi}}}^U $、$ {\hat{\boldsymbol{\Psi}}}^V $ 用户或项目的多模态融合表征  下载: 导出CSV
下载: 导出CSV
表 2 包含视觉(V)、音频(A)和文本(T)内容的多模态实验数据集统计
Table 2 Statistics of multimodal experimental dataset containing visual (V), audio (A), and textual (T) content
数据集 Amazon-Baby Amazon-Sports TikTok Allrecipes 模态嵌入 V T V T V A T V T 嵌入维度 4 096 1 024 4 096 1 024 128 128 768 2 048 20 用户数量 19 445 35 598 9 319 19 805 项目数量 7 050 18 357 6 710 10 067 交互数量 160 792 296 337 59 541 58 922 稀疏度 99.883% 99.955% 99.904% 99.970%
下载: 导出CSV
表 3 在Amazon-Baby、Amazon-Sports、Allrecipes和TikTok多媒体数据集上的实验对比结果(%)
Table 3 Experimental comparison results on the Amazon-Baby, Amazon-Sports, Allrecipes, and TikTok multimedia datasets (%)
数据集 指标 MF-
BPRNGCF Light-
GCNSGL NCL HCCF Light-
GCN-MMM-
GCLSLM-
RecMM-
SSLCI2-
MGS2GRec Imp. Amazon-Baby R@20 4.40 5.90 6.98 6.78 7.00 7.05 5.29 5.70 7.01 7.78 8.51 8.89 4.47 P@20 0.24 0.32 0.37 0.36 0.38 0.37 0.28 0.31 0.39 0.41 0.45 0.47 4.44 N@20 2.00 2.61 3.19 2.96 3.11 3.08 2.24 2.57 3.21 3.41 3.69 3.88 5.15 Amazon-Sports R@20 4.30 6.95 7.82 7.79 7.65 7.79 4.27 6.90 7.87 8.16 8.65 8.94 3.35 P@20 0.23 0.37 0.42 0.41 0.40 0.41 0.23 0.37 0.40 0.43 0.46 0.48 4.35 N@20 2.02 3.18 3.69 3.61 3.49 3.61 2.48 3.28 3.77 3.81 3.98 4.23 6.28 Allrecipes R@20 1.37 1.65 2.12 1.91 2.24 2.25 3.38 3.82 3.28 3.35 4.12 4.33 5.10 P@20 0.07 0.08 0.10 0.10 0.10 0.11 0.17 0.19 0.15 0.17 0.21 0.22 4.76 N@20 0.50 0.59 0.76 0.69 0.77 0.82 1.34 1.70 1.41 1.51 1.85 1.91 3.24 TikTok R@20 3.40 6.04 6.53 6.03 6.58 6.62 6.82 5.84 7.11 7.64 8.03 8.28 3.11 P@20 0.17 0.30 0.33 0.30 0.34 0.29 0.34 0.29 0.32 0.38 0.41 0.43 4.88 N@20 1.30 2.30 2.82 2.38 2.69 2.67 2.83 2.59 4.25 4.42 4.58 4.76 3.93 注: 其中R@20、P@20和N@20分别是评价指标Recall@20、Precision@20和NDCG@20的缩写; 下划线表示次佳实验结果; 效果提升(Imp.)为 S2GRec相比次佳模型的性能提升.
下载: 导出CSV
表 4 消融实验结果(%)
Table 4 Ablation experimental results (%)
数据集 指标 基础模型 基础 + 补全 基础 + 补全 + 多模态 Amazon-Baby R@20 5.29 7.31 8.89 P@20 0.28 0.35 0.47 N@20 2.24 3.09 3.88 Amazon-Sports R@20 4.27 7.26 8.94 P@20 0.23 0.33 0.48 N@20 2.48 3.87 4.23 Allrecipes R@20 3.38 4.11 4.33 P@20 0.17 0.19 0.22 N@20 1.34 1.45 1.91 TikTok R@20 6.82 7.68 8.28 P@20 0.34 0.40 0.43 N@20 2.83 3.96 4.76
下载: 导出CSV
表 5 工业数据集统计
Table 5 Industrial dataset statistics
数据集 用户数量 项目数量 交互数量 WeStream-Small 649万 58万 3.2959 亿WeStream-Large 2225万 195万 12.3531 亿
下载: 导出CSV
表 6 在WeStream-Small和WeStream-Large数据集上的实验对比结果(%)
Table 6 Experimental comparison results on WeStream-Small and WeStream-Large datasets (%)
数据集 指标 CI2MG S2GRec Imp. WeStream-Small R@50 3.40 3.54 4.12 R@100 5.02 5.19 3.39 R@150 6.29 6.50 3.34 N@50 1.80 1.95 8.33 N@100 2.78 3.01 8.27 N@150 3.55 3.80 7.04 WeStream-Large R@50 3.81 3.94 3.41 R@100 5.63 5.82 3.37 R@150 7.13 7.33 2.80 N@50 2.12 2.34 10.38 N@100 3.26 3.53 8.28 N@150 4.17 4.45 6.71
下载: 导出CSV
-
[1] 袁勇, 周涛, 周傲英, 段永朝, 王飞跃. 区块链技术: 从数据智能到知识自动化. 自动化学报, 2017, 43(9): 1485−1490Yuan Yong, Zhou Tao, Zhou Ao-Ying, Duan Yong-Chao, Wang Fei-Yue. Blockchain technology: From data intelligence to know-ledge automation. Acta Automatica Sinica, 2017, 43(9): 1485−1490 [2] Lin Z H, Tan Y C, Zhan Y F, Liu W M, Wang F, Chen C C, et al. Contrastive intra- and inter-modality generation for enhancing incomplete multimedia recommendation. In: Proceedings of the 31st ACM International Conference on Multimedia. Ottawa, Canada: ACM, 2023. 6234−6242 [3] Bai H Y, Hou M, Wu L, Yang Y H, Zhang K, Hong R C, et al. GoRec: A generative cold-start recommendation framework. In: Proceedings of the 31st ACM International Conference on Multimedia. Ottawa, Canada: ACM, 2023. 1004−1012 [4] Rendle S, Freudenthaler C, Gantner Z, Schmidt-Thieme L. BPR: Bayesian personalized ranking from implicit feedback. In: Proceedings of the 25th Conference on Uncertainty in Artificial Intelligence. Montreal, Canada: AUAI Press, 2009. 452−461 [5] Bronstein M M, Bruna J, Cohen T, Veličković P. Geometric deep learning: Grids, groups, graphs, geodesics, and gauges. arXiv preprint arXiv: 2104.13478, 2021. [6] Scarselli F, Gori M, Tsoi A C, Hagenbuchner M, Monfardini G. The graph neural network model. IEEE Transactions on Neural Networks, 2009, 20(1): 61−80 doi: 10.1109/TNN.2008.2005605 [7] Tao Z L, Wei Y W, Wang X, He X N, Huang X L, Chua T S. MGAT: Multimodal graph attention network for recommendation. Information Processing & Management, 2020, 57(5): Article No. 102277 doi: 10.1016/j.ipm.2020.102277 [8] Wang Q F, Wei Y W, Yin J H, Wu J L, Song X M, Nie L Q. DualGNN: Dual graph neural network for multimedia recommendation. IEEE Transactions on Multimedia, 2023, 25: 1074−1084 doi: 10.1109/TMM.2021.3138298 [9] 张颖, 张冰冰, 董微, 安峰民, 张建新, 张强. 基于语言−视觉对比学习的多模态视频行为识别方法. 自动化学报, 2024, 50(2): 417−430 doi: 10.16383/j.aas.c230159Zhang Ying, Zhang Bing-Bing, Dong Wei, An Feng-Min, Zhang Jian-Xin, Zhang Qiang. Multi-modal video action recognition method based on language-visual contrastive learning. Acta Automatica Sinica, 2024, 50(2): 417−430 doi: 10.16383/j.aas.c230159 [10] Du X Y, Yuan H H, Zhao P P, Fang J H, Liu G F, Liu Y C, et al. Contrastive enhanced slide filter mixer for sequential recommendation. In: Proceedings of the 39th International Conference on Data Engineering (ICDE). Anaheim, USA: IEEE, 2023. 2673−2685 [11] Wang S W, Liu X W, Liu L, Tu W X, Zhu X Z, Liu J Y, et al. Highly-efficient incomplete largescale multiview clustering with consensus bipartite graph. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New Orleans, USA: IEEE, 2022. 9766−9775 [12] Li H X, Zheng C Y, Wu P. StableDR: Stabilized doubly robust learning for recommendation on data missing not at random. In: Proceedings of the 11th International Conference on Learning Representations (ICLR). Kigali, Rwanda: OpenReview.net, 2023. [13] Cho J W, Kim D J, Choi J, Jung Y, Kweon I S. Dealing with missing modalities in the visual question answer-difference prediction task through knowledge distillation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). Nashville, USA: IEEE, 2021. 1592−1601 [14] Xia D X, Yang Y, Yang S H, Li T R. Incomplete multi-view clustering via kernelized graph learning. Information Sciences, 2023, 625: 1−19 doi: 10.2139/ssrn.4994362 [15] Deng S J, Wen J, Liu C L, Yan K, Xu G H, Xu Y. Projective incomplete multi-view clustering. IEEE Transactions on Neural Networks and Learning Systems, 2024, 35(8): 10539−10551 doi: 10.1109/TNNLS.2023.3242473 [16] Liu S Y, Zhang J P, Wen Y, Yang X H, Wang S W, Zhang Y, et al. Sample-level cross-view similarity learning for incomplete multi-view clustering. In: Proceedings of the 38th AAAI Conference on Artificial Intelligence. Vancouver, Canada: AAAI Press, 2024. 14017−14025 [17] Hu J W, Liu Y C, Zhao J M, Jin Q. MMGCN: Multimodal fusion via deep graph convolution network for emotion recognition in conversation. In: Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Virtual Event: Association for Computational Linguistics, 2021. 5666−5675 [18] Du W Z, Su H Y, Cam-Tu N, Sun J. Enhancing product representation with multi-form interactions for multimodal conversational recommendation. In: Proceedings of the 31st ACM International Conference on Multimedia. Ottawa, Canada: ACM, 2023. 6491−6500 [19] Huang J, Lu T, Zhou X B, Cheng B, Hu Z B, Yu W H, et al. HyperDNE: Enhanced hypergraph neural network for dynamic network embedding. Neurocomputing, 2023, 527: 155−166 doi: 10.1016/j.neucom.2023.01.039 [20] Goldberg D, Nichols D, Oki B M, Terry D. Using collaborative filtering to weave an information tapestry. Communications of the ACM, 1992, 35(12): 61−70 doi: 10.1145/138859.138867 [21] Resnick P, Iacovou N, Suchak M, Bergstrom P, Riedl J. GroupLens: An open architecture for collaborative filtering of netnews. In: Proceedings of the ACM Conference on Computer Supported Cooperative Work. Chapel Hill, USA: ACM, 1994. 175−186 [22] Paterek A. Improving regularized singular value decomposition for collaborative filtering. In: Proceedings of the KDD Cup and Workshop. San Jose, USA: ACM, 2007. 39−42 [23] Koren Y, Bell R, Volinsky C. Matrix factorization techniques for recommender systems. Computer, 2009, 42(8): 30−37 doi: 10.18297/etd/3661 [24] He X N, Liao L Z, Zhang H W, Nie L Q, Hu X, Chua T S. Neural collaborative filtering. In: Proceedings of the 26th International Conference on World Wide Web. Perth, Australia: ACM, 2017. 173−182 [25] Wang X, He X N, Wang M, Feng F L, Chua T S. Neural graph collaborative filtering. In: Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval. Paris, France: ACM, 2019. 165−174 [26] 林景栋, 吴欣怡, 柴毅, 尹宏鹏. 卷积神经网络结构优化综述. 自动化学报, 2020, 46(1): 24−37Lin Jing-Dong, Wu Xin-Yi, Chai Yi, Yin Hong-Peng. Structure optimization of convolutional neural networks: A survey. Acta Automatica Sinica, 2020, 46(1): 24−37 [27] Li Y, Jin Y L, Song G J, Zhu Z H, Shi C, Wang Y M. GraphMSE: Efficient meta-path selection in semantically aligned feature space for graph neural networks. In: Proceedings of the 35th AAAI Conference on Artificial Intelligence. Virtual Event: AAAI Press, 2021. 4206−4214 [28] Luo H T, Meng X Y, Wang S H, Cao H Y, Zhang W Y, Wang Y Q, et al. Spectral-based graph neural networks for complementary item recommendation. In: Proceedings of the 38th AAAI Conference on Artificial Intelligence. Vancouver, Canada: AAAI Press, 2024. 8868−8876 [29] Feng Y F, You H X, Zhang Z Z, Ji R R, Gao Y. Hypergraph neural networks. In: Proceedings of the 33rd AAAI Conference on Artificial Intelligence. Honolulu, USA: AAAI Press, 2019. 3558−3565 [30] Wei C Y, Liang J, Bai B, Liu D. Dynamic hypergraph learning for collaborative filtering. In: Proceedings of the 31st ACM International Conference on Information & Knowledge Management. Atlanta, USA: ACM, 2022. 2108−2117 [31] Yu J L, Yin H Z, Li J D, Wang Q Y, Hung N Q V, Zhang X L. Self-supervised multi-channel hypergraph convolutional network for social recommendation. In: Proceedings of the Web Conference. Ljubljana, Slovenia: ACM, 2021. 413−424 [32] Cai D R, Song M X, Sun C X, Zhang B F, Hong S D, Li H Y. Hypergraph structure learning for hypergraph neural networks. In: Proceedings of the 31st International Joint Conference on Artificial Intelligence (IJCAI). Vienna, Austria: IJCAI, 2022. 1923−1929 [33] Guo Z C, Zhao J X, Jiao L C, Liu X, Liu F. A universal quaternion hypergraph network for multimodal video question answering. IEEE Transactions on Multimedia, 2023, 25: 38−49 doi: 10.1109/TMM.2021.3120544 [34] 饶子昀, 张毅, 刘俊涛, 曹万华. 应用知识图谱的推荐方法与系统. 自动化学报, 2021, 47(9): 2061−2077 doi: 10.16383/j.aas.c200128Rao Zi-Yun, Zhang Yi, Liu Jun-Tao, Cao Wan-Hua. Recommendation methods and systems using knowledge graph. Acta Automatica Sinica, 2021, 47(9): 2061−2077 doi: 10.16383/j.aas.c200128 [35] He R N, McAuley J. VBPR: Visual Bayesian personalized ranking from implicit feedback. In: Proceedings of the 30th AAAI Conference on Artificial Intelligence. Phoenix, USA: AAAI Press, 2016. 144−150 [36] Chen J Y, Zhang H W, He X N, Nie L Q, Liu W, Chua T S. Attentive collaborative filtering: Multimedia recommendation with item- and component-level attention. In: Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval. Tokyo, Japan: ACM, 2017. 335−344 [37] Lin Z H, Tian C X, Hou Y P, Zhao W X. Improving graph collaborative filtering with neighborhood-enriched contrastive learn-ing. In: Proceedings of the ACM Web Conference. Lyon, France: ACM, 2022. 2320−2329 [38] Xu C, Si J J, Guan Z Y, Zhao W, Wu Y, Gao X Y. Reliable conflictive multi-view learning. In: Proceedings of the 38th AAAI Conference on Artificial Intelligence. Vancouver, Canada: AAAI Press, 2024. 16129−16137 [39] Han Z B, Zhang C Q, Fu H Z, Zhou J T. Trusted multi-view classification with dynamic evidential fusion. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(2): 2551−2566 doi: 10.1109/TPAMI.2022.3171983 [40] Zhang Q Y, Wei Y K, Han Z B, Fu H Z, Peng X, Deng C, et al. Multimodal fusion on low-quality data: A comprehensive survey. arXiv preprint arXiv: 2404.18947, 2024. [41] Wang C, Niepert M, Li H. LRMM: Learning to recommend with missing modalities. In: Proceedings of the Conference on Empirical Methods in Natural Language Processing. Brussels, Belgium: Association for Computational Linguistics, 2018. 3360−3370 [42] Malitesta D, Rossi E, Pomo C, Malliaros F D, di Noia T. Dealing with missing modalities in multimodal recommendation: A feature propagation-based approach. arXiv preprint arXiv: 2403.19841, 2024. [43] Liu C, Li R, Wu S, Che H J, Jiang D Z, Yu Z W, et al. Self-guided partial graph propagation for incomplete multiview clustering. IEEE Transactions on Neural Networks and Learning Systems, 2024, 35(8): 10803−10816 doi: 10.1109/TNNLS.2023.3244021 [44] Frank M, Wolfe P. An algorithm for quadratic programming. Naval Research Logistics Quarterly, 1956, 3(1−2): 95−110 doi: 10.1002/nav.3800030109 [45] Yang Y, Shen H T, Ma Z G, Huang Z, Zhou X F. $ {\ell_{2,\; 1}} $-norm regularized discriminative feature selection for unsupervised learning. In: Proceedings of the 22nd International Joint Conference on Artificial Intelligence (IJCAI). Barcelona, Spain: IJCAI, 2011. 1589−1594 [46] Nie F P, Huang H, Cai X, Ding C. Efficient and robust feature selection via joint $ {\ell_{2,\; 1}} $-norms minimization. In: Proceedings of the 24th International Conference on Neural Information Processing Systems. Vancouver, Canada: Curran Associates Inc., 2010. 1813−1821 [47] Li X C, Chin J Y, Chen Y L, Cong G. Sinkhorn collaborative filtering. In: Proceedings of the Web Conference. Ljubljana, Slovenia: ACM, 2021. 582−592 [48] Courty N, Flamary R, Tuia D, Rakotomamonjy A. Optimal transport for domain adaptation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(9): 1853−1865 doi: 10.1109/TPAMI.2016.2615921 [49] Bahmani S, Raj B, Boufounos P T. Greedy sparsity-constrained optimization. The Journal of Machine Learning Research, 2013, 14(1): 807−841 doi: 10.1109/acssc.2011.6190194 [50] Zhang C, Cai Y J, Lin G S, Shen C H. DeepEMD: Few-shot image classification with differentiable earth mover's distance and structured classifiers. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, USA: IEEE, 2020. 12200−12210 [51] Barratt S. On the differentiability of the solution to convex optimization problems. arXiv preprint arXiv: 1804.05098, 2018. [52] Jaggi M. Revisiting Frank-Wolfe: Projection-free sparse convex optimization. In: Proceedings of the 30th International Conference on Machine Learning (ICML). Atlanta, USA: JMLR.org, 2013. 427−435 [53] He X N, Deng K, Wang X, Li Y, Zhang Y D, Wang M. LightGCN: Simplifying and powering graph convolution network for recommendation. In: Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval. Xi'an, China: ACM, 2020. 639−648 [54] Wu J C, Wang X, Feng F L, He X N, Chen L, Lian J X, et al. Self-supervised graph learning for recommendation. In: Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval. Virtual Event: ACM, 2021. 726−735 [55] Li J, Tan Z C, Wan J, Lei Z, Guo G D. Nested collaborative learning for long-tailed visual recognition. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New Orleans, USA: IEEE, 2022. 6939−6948 [56] Xia L H, Huang C, Xu Y, Zhao J S, Yin D W, Huang J. Hypergraph contrastive collaborative filtering. In: Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval. Madrid, Spain: ACM, 2022. 70−79 [57] Yi Z X, Wang X, Ounis I, Macdonald C. Multi-modal graph contrastive learning for micro-video recommendation. In: Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval. Madrid, Spain: ACM, 2022. 1807−1811 [58] Tao Z L, Liu X H, Xia Y W, Wang X, Yang L F, Huang X L, et al. Self-supervised learning for multimedia recommendation. IEEE Transactions on Multimedia, 2023, 25: 5107−5116 doi: 10.1109/TMM.2022.3187556 [59] Wei W, Huang C, Xia L H, Zhang C X. Multi-modal self-supervised learning for recommendation. In: Proceedings of the ACM Web Conference. Austin, USA: ACM, 2023. 790−800 -

 下载:
下载:

计量
- 文章访问数: 451
- HTML全文浏览量: 399
- PDF下载量: 60
- 被引次数: 0
