

One-shot Learning Classification and Recognition of Gesture Expression From the Egocentric Viewpoint in Intelligent Human-computer Interaction
-
摘要: 在智能人机交互中, 以交互人的视角为第一视角的手势表达发挥着重要作用, 而面向第一视角的手势识别则成为最重要的技术环节. 本文通过深度卷积神经网络的级联组合, 研究复杂应用场景中第一视角下的一次性学习手势识别(One-shot learning hand gesture recognition, OSLHGR)算法. 考虑到实际应用的便捷性和适用性, 运用改进的轻量级SSD (Single shot multibox detector)目标检测网络实现第一视角下手势目标的快速精确检测; 进而, 以改进的轻量级U-Net网络为主要工具进行复杂背景下手势目标的像素级高效精准分割. 在此基础上, 以组合式3D深度神经网络为工具, 研究提出了一种第一视角下的一次性学习手势动作识别的网络化算法. 在Pascal VOC 2012数据集和SoftKinetic DS325采集的手势数据集上进行的一系列实验测试结果表明, 本文所提出的网络化算法在手势目标检测与分割精度、分类识别准确率和实时性等方面都有显著的优势, 可为在复杂应用环境下实现便捷式高性能智能人机交互提供可靠的技术支持.Abstract: In intelligent human-computer interaction (HCI), the expression of gestures with the perspective of the interactive person as the egocentric viewpoint plays an important role, while gesture recognition from the egocentric viewpoint becomes the most important technical link. In this paper, one-shot learning hand gesture recognition (OSLHGR) algorithm under the egocentric viewpoint in complex application scenarios is studied through the cascade combination of deep convolutional neural networks (CNN). Considering the convenience and applicability of practical applications, the improved lightweight SSD (single shot multibox detector) detection network was utilized to achieve rapid and accurate gesture object detection. Furthermore, the improved lightweight U-Net network is used as the main tool to perform pixel-level efficient and accurate segmentation of gesture targets in complex backgrounds. On the basis of U-Net results, a networked algorithm for OSLHGR from the egocentric viewpoint is proposed by using the combined 3D deep neural network. A series of experimental results on the Pascal VOC 2012 dataset and the gesture dataset collected by SoftKinetic DS325 show that the proposed networked algorithm has significant advantages in gesture target detection and segmentation precision, classification accuracy and real-time performance. It can provide reliable technical support for the realization of convenient and high-performance intelligent HCI in complex application environment.
-

图 1 不同场景下第一视角手势人机交互图示
Fig. 1 HCI demonstration of gestures from the egocentric viewpoint in different scenarios
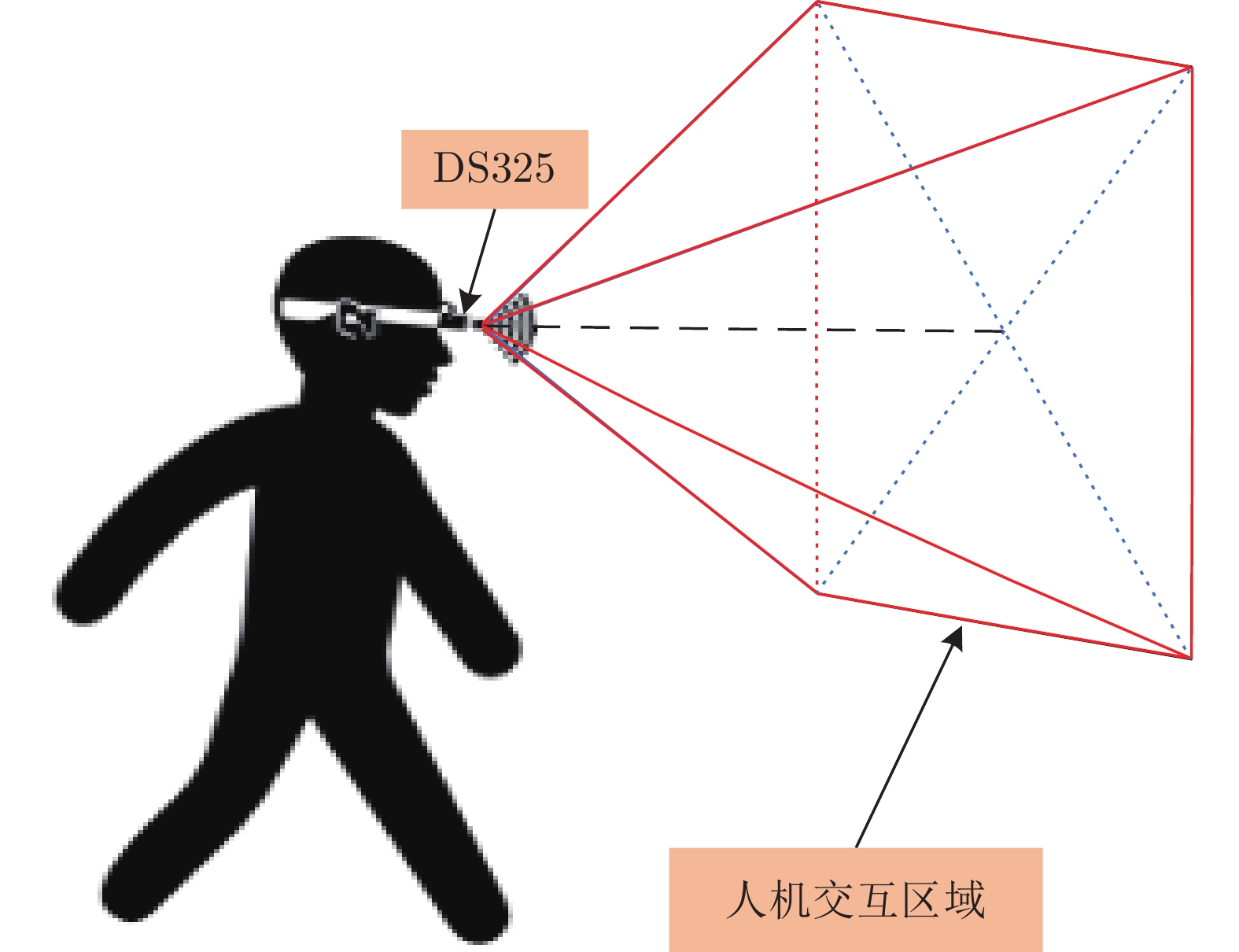
图 2 第一视角下智能人机交互的活动区域图示
Fig. 2 Demonstration of active area of intelligent HCI from the egocentric viewpoint

图 4 第一视角下手势样本数据的标注结果
Fig. 4 Annotation results of gesture samples from the egocentric viewpoint
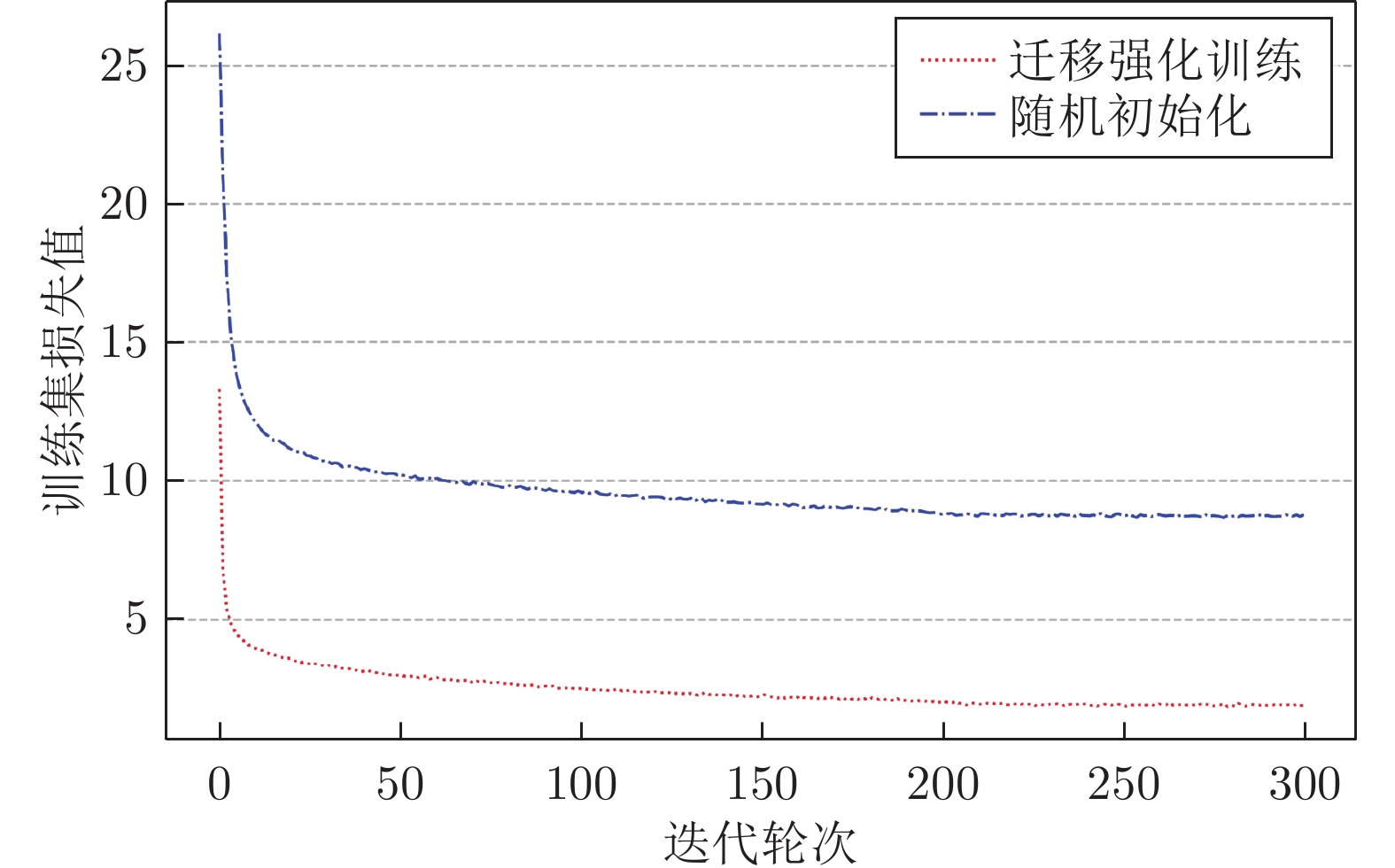
图 5 迁移强化训练和随机初始化两种方式下损失函数变化曲线对比
Fig. 5 Comparison of loss function change curves between transfer reinforcement training and random initialization

图 6 第一视角下改进SSD目标检测网络的检测结果
Fig. 6 The detection results of improved SSD target detection network from the egocentric viewpoint
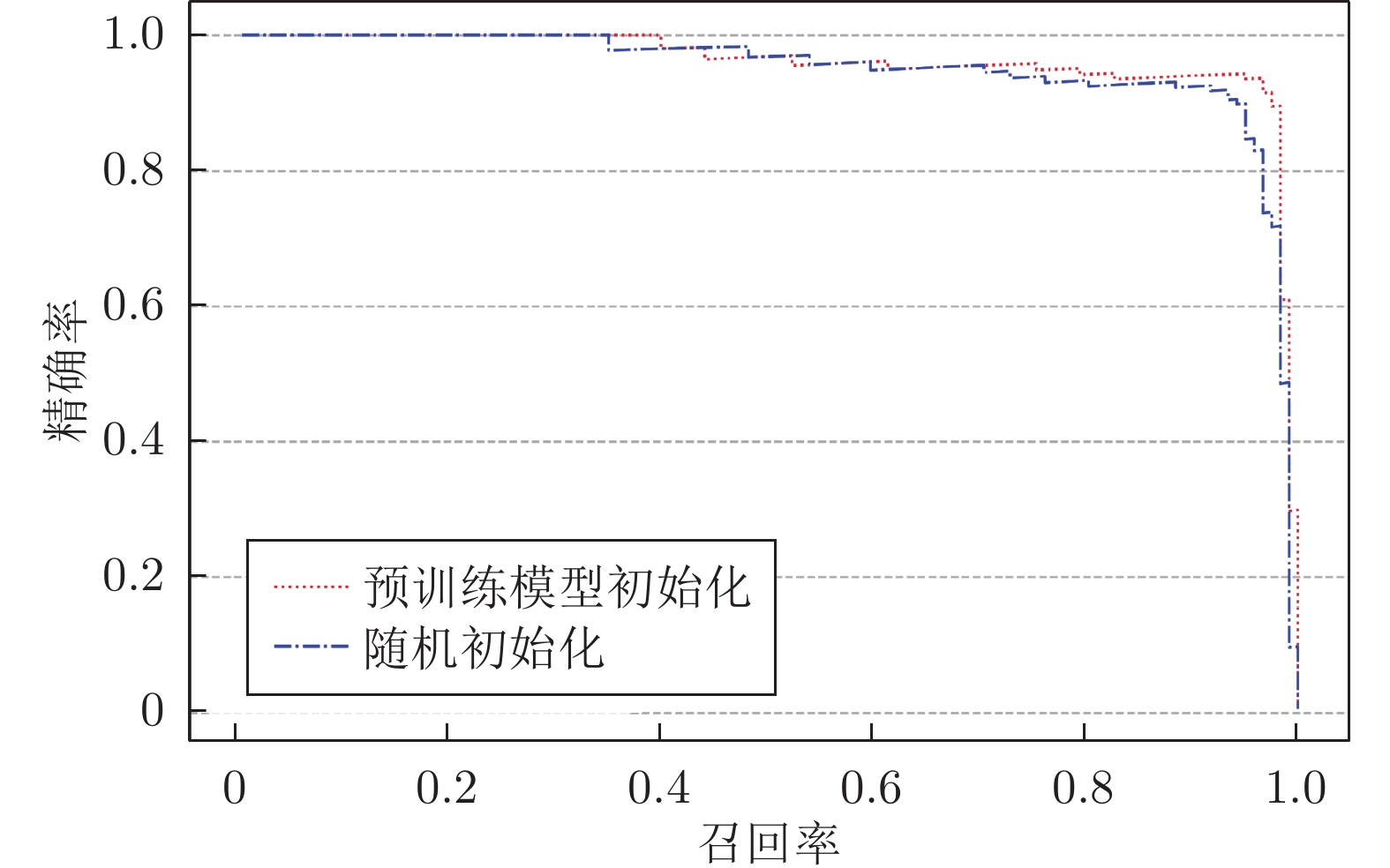
图 7 第一视角下手势目标检测结果的召回率−精确率变化曲线
Fig. 7 Recall and precision curves of gesture target detection results from the egocentric viewpoint

图 9 第一视角下手势目标轮廓的人工标注结果
Fig. 9 Manual annotation results of gesture target contours from the egocentric viewpoint
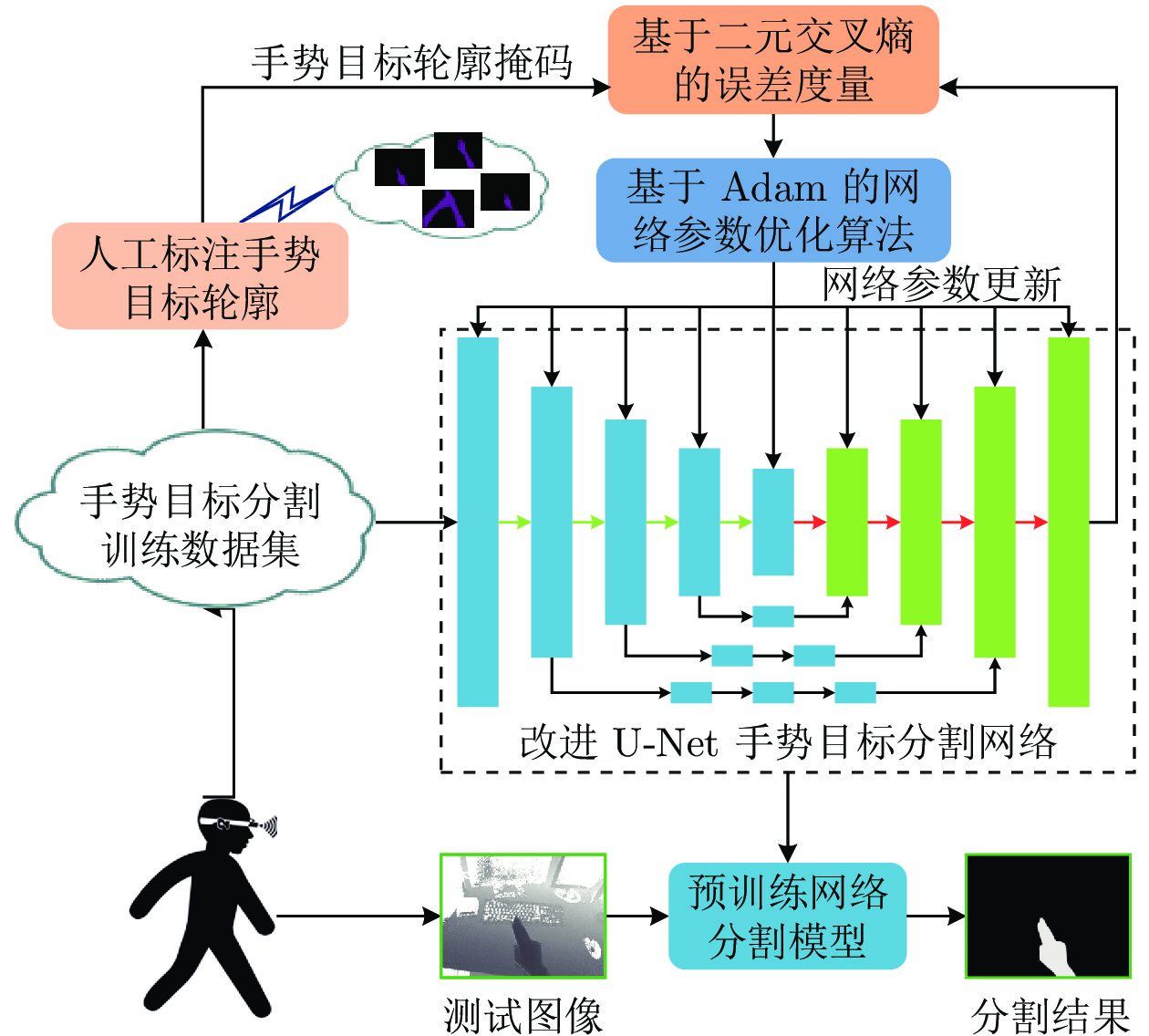
图 10 基于改进U-Net的手势目标快速分割和提取算法系统架构
Fig. 10 Architecture of fast segmentation and extraction algorithm of gesture targets based on improved U-Net
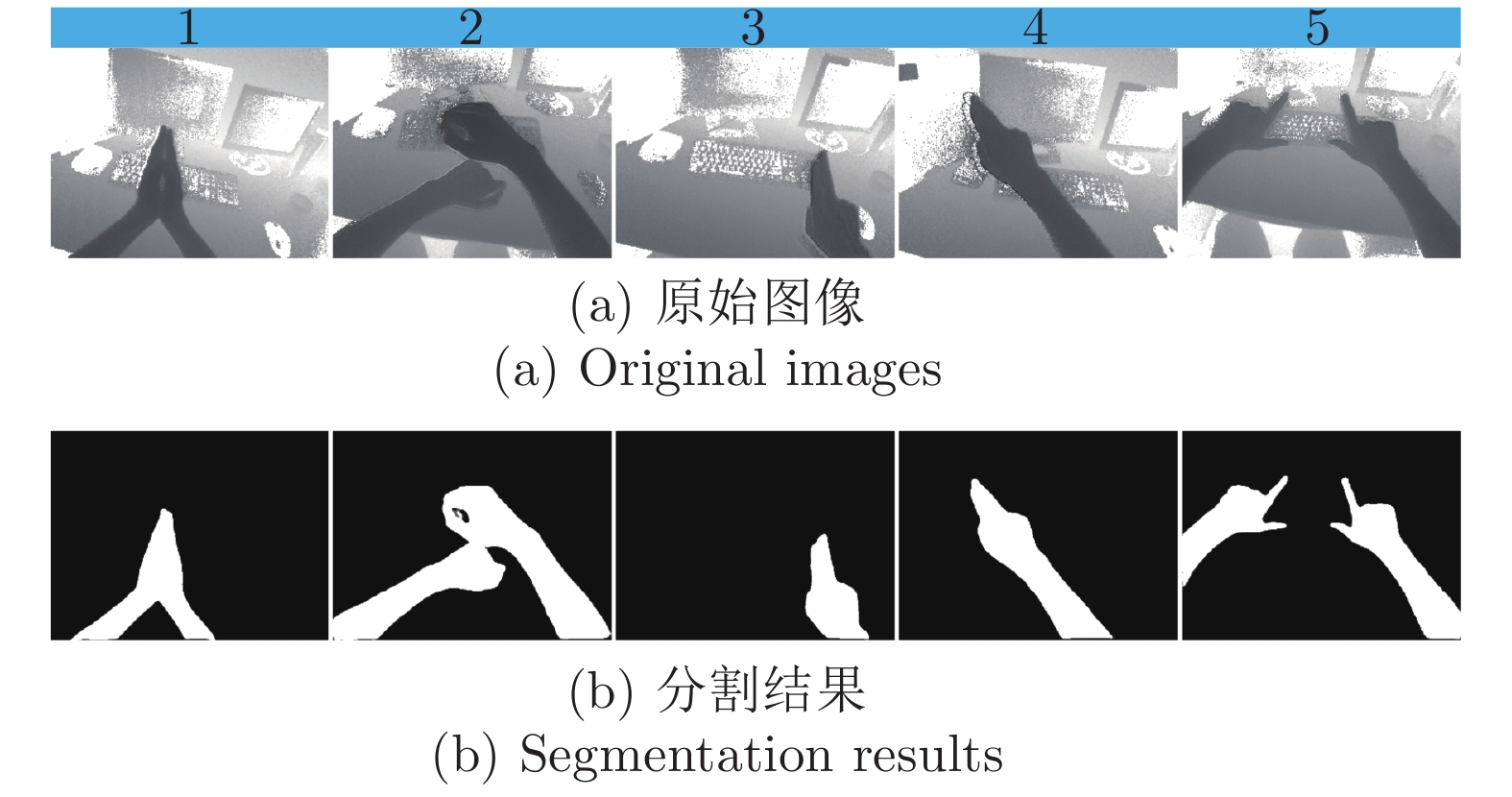
图 11 第一视角下改进U-Net网络模型的分割结果
Fig. 11 The segmentation results of improved U-Net network model from the egocentric viewpoint
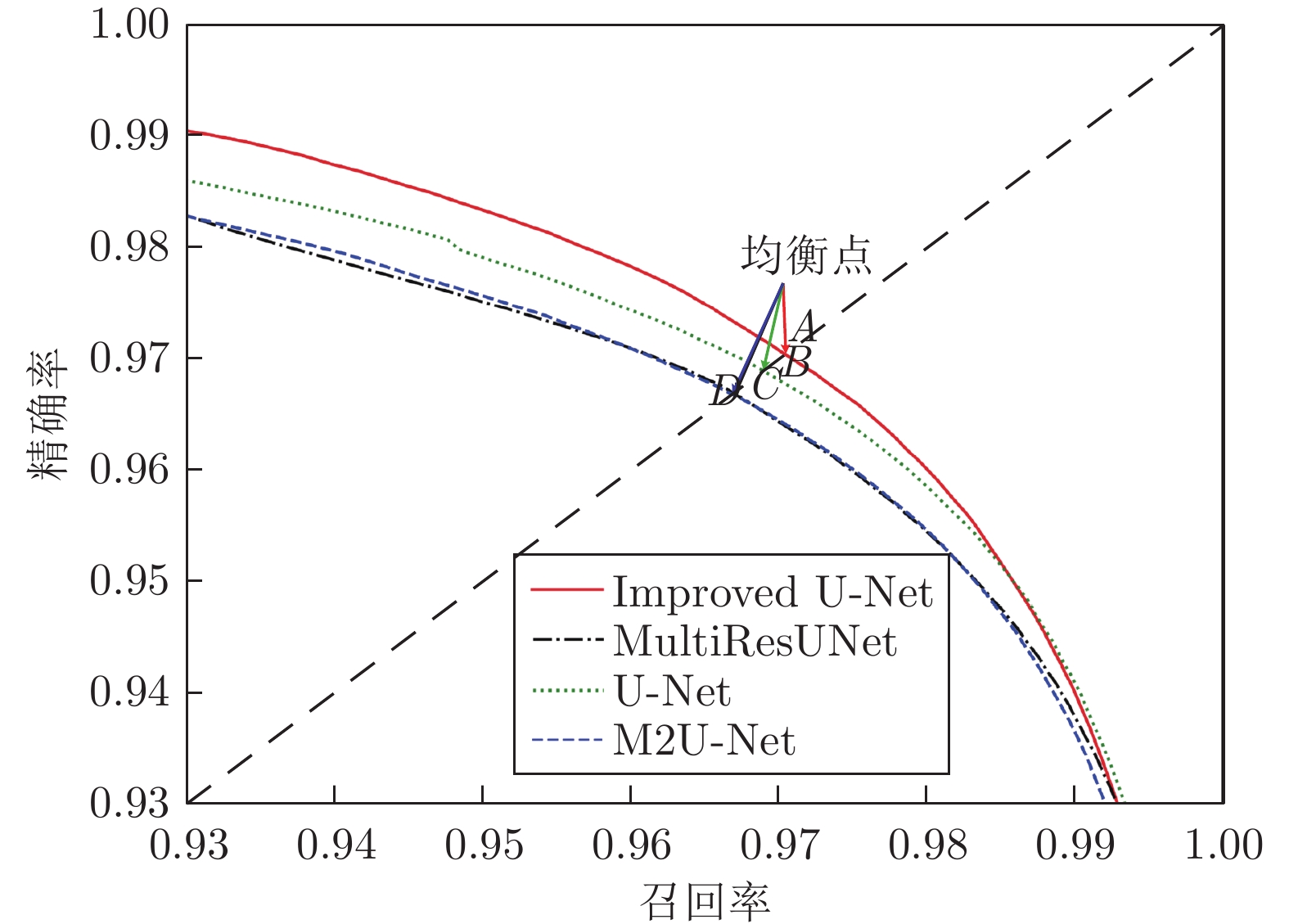
图 12 第一视角下手势目标分割结果的召回率−精确率变化曲线
Fig. 12 Recall and precision curves of gesture target segmentation results from the egocentric viewpoint

图 13 本文提出的SSD + U-Net组合方法与Mask R-CNN v3检测和分割结果对比
Fig. 13 Comparison of detection and segmentation results between SSD + U-Net and Mask R-CNN v3
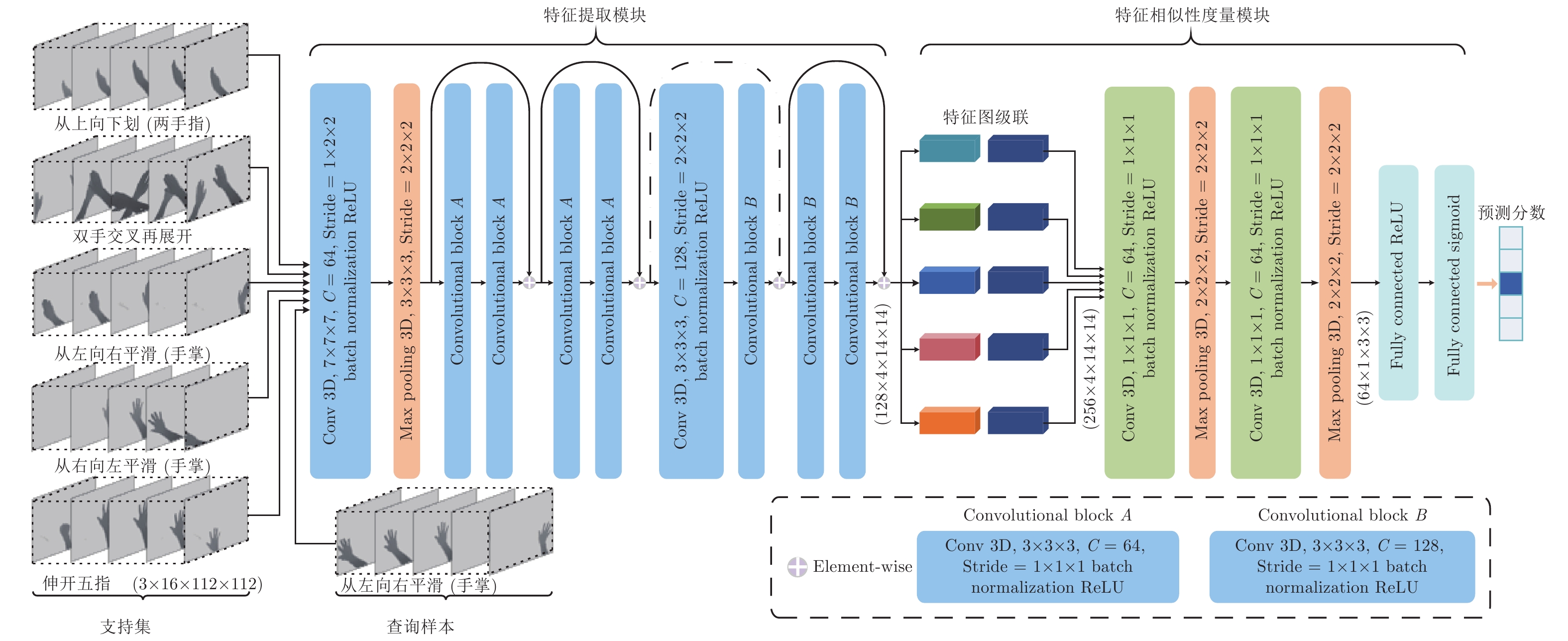
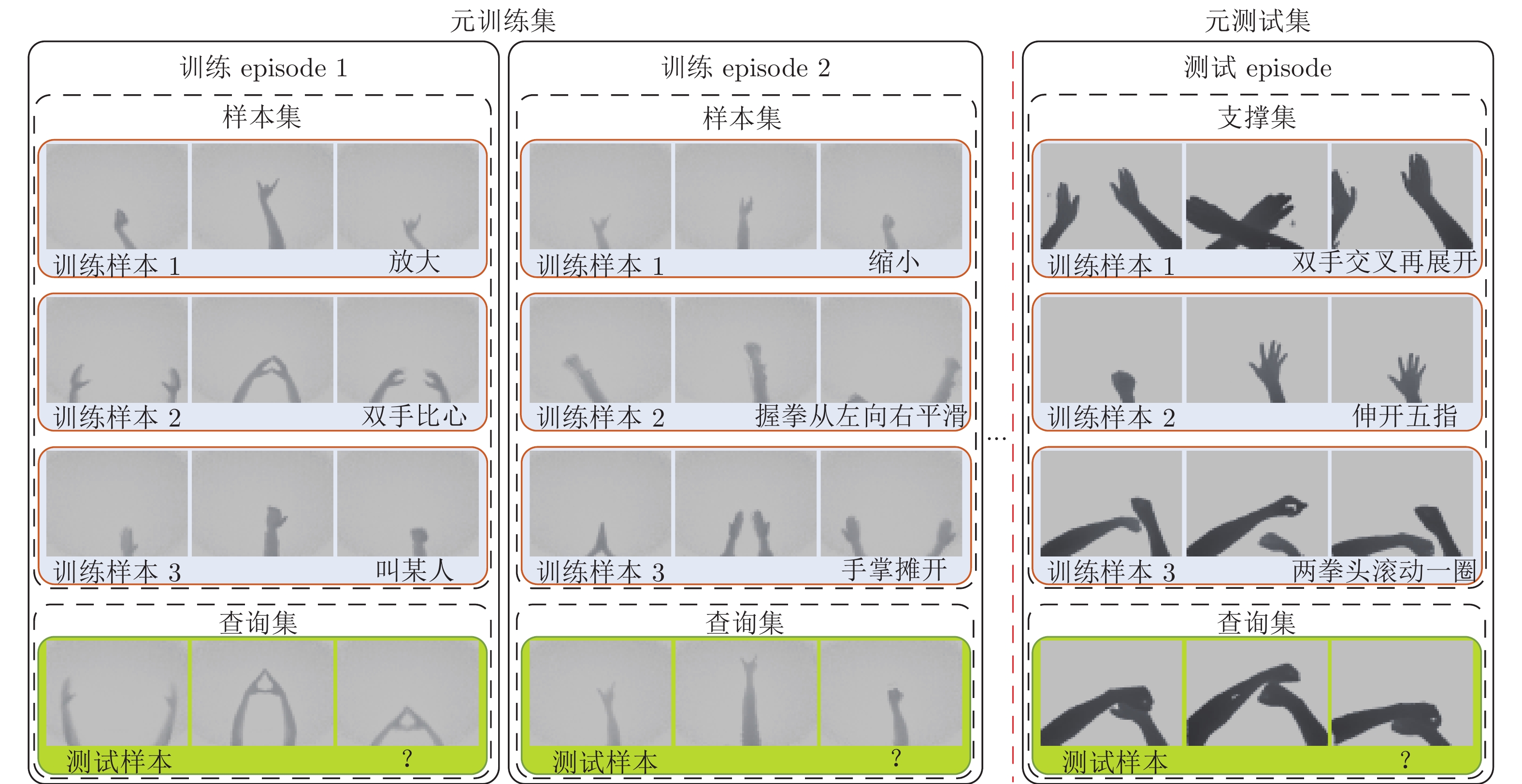
图 14 5-way 1-shot 3D关系神经网络系统架构
Fig. 14 5-way 1-shot 3D relation neural network system architecture

图 17 10种用于验证OSLHGR算法性能的动态手势数据集. 每一列从上向下表示手势核心阶段从起始到结束的变化过程. 图中箭头用于描述动态手势运动的方向
Fig. 17 Ten dynamic gesture datasets to verify the classification performance of OSLHGR algorithm. From top to bottom, each column represents the change process from the beginning to the end of the core phase of gestures. The arrows are used to describe the motion direction of dynamic gestures
表 1 轻量级目标检测模型在VOC 2007测试集上的检测结果对比 (
$ \dagger$ 表示引用文献[34]中的实验结果)Table 1 Comparison of detection results of lightweight target detection model on VOC 2007 test set (
$ \dagger$ represents the experimental results in [34])目标检测算法 输入图像大小 训练数据集 测试数据集 ${\rm{mAP} }$(%) 计算复杂度 (M) 参数量 (M) Tiny YOLO$\dagger$ 416$\times$416 2007 + 2012 2007 57.1 6970 15.12 Tiny SSD[35] 300$\times$300 2007 + 2012 2007 61.3 571 1.13 SqueezeNet-SSD$\dagger$ 300$\times$300 2007 + 2012 2007 64.3 1180 5.50 MobileNet-SSD$\dagger$ 300$\times$300 2007 + 2012 2007 68.0 1140 5.50 Fire SSD[36] 300$\times$300 2007 + 2012 2007 70.5 2670 7.13 Pelee[37] 300$\times$300 2007 + 2012 2007 70.9 1 210 5.98 Tiny DSOD[34] 300$\times$300 2007 + 2012 2007 72.1 1060 0.95 SSD 300$\times$300 2007 + 2012 2007 74.3 34360 34.30 改进的 SSD 300$\times$300 2007 + 2012 2007 73.6 710 1.64  下载: 导出CSV
下载: 导出CSV
表 2 不同网络模型分割结果和模型参数对比
Table 2 Comparison of segmentation results and model parameters of different network models
分割网络
模型输入图像
大小IoU (%) 计算复
杂度 (G)参数量(M) 计算时间(ms/f) U-Net 224$\times$224 94.29 41.84 31.03 67.50 MultiResUNet 224$\times$224 94.01 13.23 6.24 119.50 M2U-Net 224$\times$224 93.94 0.38 0.55 36.25 改进的U-Net 224$\times$224 94.53 0.52 0.61 53.75
下载: 导出CSV
表 3 本文提出的目标检测和分割方法与Mask R-CNN v3的性能对比
Table 3 Performance comparison of the proposed object detection and segmentation method and Mask R-CNN v3
检测与分割算法 输入图像大小 参数量 (M) ${\rm{mAP} }$(%) IoU (%) 目标检测时间 (ms/f) Mask R-CNN v3 (ResNet-101) 300$\times$300 21.20 98.00 83.45 219.73 改进的SSD+U-Net (MobileNetV2) 300$\times$300 2.25 96.30 94.53 31.04
下载: 导出CSV
表 4 OSLHGR算法的分类结果和模型性能对比
Table 4 Comparison of classification results and model performance of OSLHGR algorithms
下载: 导出CSV
-
[1] Betancourt A, López M M, Regazzoni C S, Rauterberg M. A sequential classifier for hand detection in the framework of egocentric vision. In: Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition Workshops. Columbus, Ohio, USA: IEEE, 2014. 600−605 [2] Thalmann D, Liang H, Yuan J. First-person palm pose tracking and gesture recognition in augmented reality. Computer Vision, Imaging and Computer Graphics Theory and Applications, 2015, 598: 3−15 [3] Serra G, Camurri M, Baraldi L, Benedetti M, Cucchiara R. Hand segmentation for gesture recognition in EGO-vision. In: Proceedings of the 3rd ACM International Workshop on Interactive Multimedia on Mobile and Portable Devices. Barcelona, Spain: ACM, 2013. 31−36 [4] Cao C Q, Zhang Y F, Wu Y, Lu H Q, Cheng J. Egocentric gesture recognition using recurrent 3D convolutional neural networks with spatiotemporal transformer modules. In: Proceedings of the 2017 IEEE International Conference on Computer Vision. Venice, Italy: IEEE, 2017. 3763−3771 [5] Liu W, Anguelov D, Erhan D, Szegedy C, Reed S, Fu C Y, Berg A C. SSD: Single shot multiBox detector. In: Proceedings of the 14th European Conference on Computer Vision. Amsterdam, the Netherlands: Springer, 2016. 21−37 [6] Ronneberger O, Fischer P, Brox T. U-net: Convolutional networks for biomedical image segmentation. In: Proceedings of the 2015 International Conference on Medical Image Computing and Computer-Assisted Intervention. Munich, Germany: Springer, 2015. 234−241 [7] Sung F, Yang Y X, Zhang L, Xiang T, Torr P H S, Hospedales T M. Learning to compare relation network for few-shot learning. In: Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, Utah, USA: IEEE, 2018. 1199−1208 [8] Sandler M, Howard A, Zhu M, Zhmoginov A, Chen L C. MobileNetV2: Inverted residuals and linear bottlenecks. In: Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, Utah, USA: IEEE, 2018. 4510−4520 [9] Laibacher T, Weyde T, Jalali S. M2U-Net: Effective and efficient retinal vessel segmentation for resource-constrained environments. arXiv preprint, arXiv: 1811.07738, 2018. [10] Ibtehaz N, Rahman M S. MultiResUNet: Rethinking the U-Net architecture for multimodal biomedical image segmentation. Neural Networks, 2020, 121: 74−87 doi: 10.1016/j.neunet.2019.08.025 [11] 彭玉青, 赵晓松, 陶慧芳, 刘宪姿, 李铁军. 复杂背景下基于深度学习的手势识别. 机器人, 2019, 41(4): 534−542Peng Yu-Qing, Zhao Xiao-Song, Tao Hui-Fang, Liu Xian-Zi, Li Tie-Jun. Hand gesture recognition against complex background based on deep learning. Robot, 2019, 41(4): 534−542 [12] Redmon J, Divvala S, Girshick R, Farhadi A. You only look once: Unified, real-time object detection. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA: IEEE, 2016. 779−788 [13] Yip H M, Navarro-Alarcon D, Liu Y. Development of an eye-gaze controlled interface for surgical manipulators using eye-tracking glasses. In: Proceedings of the 2016 IEEE International Conference on Robotics and Biomimetics. Qingdao, China: IEEE, 2016. 1900−1905 [14] Wanluk N, Visitsattapongse S, Juhong A, Pintavirooj C. Smart wheelchair based on eye tracking. In: Proceedings of the 9th Biomedical Engineering International Conference. Luang Prabang, Laos: IEEE, 2016. 1−4 [15] 杨观赐, 杨静, 苏志东, 陈占杰. 改进的YOLO特征提取算法及其在服务机器人隐私情境检测中的应用. 自动化学报, 2018, 44(12): 2238−2249Yang Guan-Ci, Yang Jing, Su Zhi-Dong, Chen Zhan-Jie. An improved YOLO feature extraction algorithm and its application to privacy situation detection of social robots. Acta Automatica Sinica, 2018, 44(12): 2238−2249 [16] 李昌岭, 李伟华. 面向战场的多通道人机交互模型. 火力与指挥控制, 2014, 39(11): 110−114 doi: 10.3969/j.issn.1002-0640.2014.11.027Li Chang-Ling, Li Wei-Hua. A multimodal interaction model for battlefield. Fire Control and Command Control, 2014, 39(11): 110−114 doi: 10.3969/j.issn.1002-0640.2014.11.027 [17] Zhang Y F, Cao C Q, Cheng J, Lu H Q. EgoGesture: A new dataset and benchmark for egocentric hand gesture recognition. IEEE Transactions on Multimedia, 2018, 20(5): 1038−1050 doi: 10.1109/TMM.2018.2808769 [18] Hegde S, Perla R, Hebbalaguppe R, Hassan E. GestAR: Real time gesture interaction for AR with egocentric view. In: Proceedings of the 2016 IEEE International Symposium on Mixed and Augmented Reality. Merida, Mexico: IEEE, 2016. 262−267 [19] Bambach S, Bambach S, Crandall D J, Yu C. Lending a hand: Detecting hands and recognizing activities in complex egocentric interactions. In: Proceedings of the 2015 IEEE International Conference on Computer Vision. Santiago, Chile: IEEE, 2015. 1949−1957 [20] Pandey R, White M, Pidlypenskyi P, Wang X, Kaeser-Chen C. Real-time egocentric gesture recognition on mobile head mounted displays. In: Proceedings of the 31st Conference on Neural Information Processing Systems. Long Beach, CA, USA: IEEE, 2017. 1−4 [21] Howard A G, Zhu M L, Chen B, Kalenichenko D, Wang W J, Weyamd T, Andreetto M, Adam H. MobileNets: Efficient convolutional neural networks for mobile vision applications. arXiv preprint, arXiv: 1704.04861, 2017. [22] 张慧, 王坤峰, 王飞跃. 深度学习在目标视觉检测中的应用进展与展望. 自动化学报, 2017, 43(8): 1289−1305Zhang Hui, Wang Kun-Feng, Wang Fei-Yue. Advances and perspectives on applications of deep learning in visual object detection. Acta Automatica Sinica, 2017, 43(8): 1289−1305 [23] Girshick R, Donahue J, Darrell T, Malik J. Rich feature hierarchies for accurate object detection and semantic segmentation. In: Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus, Ohio. USA: IEEE, 2014. 580−587 [24] Girshick R. Fast R-CNN. In: Proceedings of the 2015 IEEE International Conference on Computer Vision. Santiago, Chile: IEEE, 2015. 1440−1448 [25] Ren S, He K, Girshick R, Sun J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137−1149 doi: 10.1109/TPAMI.2016.2577031 [26] Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition. In: Proceedings of the 2015 International Conference on Learning Representations. San Diego, USA: ICLR, 2015. 1−14 [27] Fu C Y, Liu W, Tyagi A, Berg A C. DSSD: Deconvolutional single shot detector. arXiv preprint, arXiv: 1701.06659, 2017. [28] Szegedy C, Liu W, Jia Y Q, Sermanet P, Reed S, Anguelov D, et al. Going deeper with convolutions. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA: IEEE, 2015. 1−9 [29] Liu S T, Huang D, Wang Y H. Receptive field block net for accurate and fast object detection. In: Proceedings of the 2018 European Conference on Computer Vision. Munich, Germany: Springer, 2018. 385−400 [30] Shen Z Q, Shi H, Feris R, Cao L L, Yan S C, Liu D, et al. Learning object detectors from scratch with gated recurrent feature pyramids. arXiv preprint, arXiv: 1712.00886, 2017. [31] Hu J, Shen L, Albanie S, Sun G, Wu E H. Squeeze-and-excitation networks. In: Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, Utah, USA: IEEE, 2018. 7132−7141 [32] 张雪松, 庄严, 闫飞, 王伟. 基于迁移学习的类别级物体识别与检测研究与进展. 自动化学报, 2019, 45(7): 1224−1243Zhang Xue-Song, Zhuang Yan, Yan Fei, Wang Wei. Status and development of transfer learning based category-level object recognition and detection. Acta Automatica Sinica, 2019, 45(7): 1224−1243 [33] Wang T, Chen Y, Zhang M Y, Chen J, Snoussi H. Internal transfer learning for improving performance in human action recognition for small datasets. IEEE Access, 2017, 5(1): 17627−17633 [34] Li Y X, Li J W, Lin W Y, Li J G. Tiny-DSOD: Lightweight object detection for resource-restricted usages. In: Proceedings of the 2018 British Machine Vision Conference. Newcastle, UK: BMVC, 2018. 1−12 [35] Wong A, Shafiee M J, Li F, Chwyl B. Tiny SSD: A tiny single-shot detection deep convolutional neural network for real-time embedded object detection. In: Proceedings of 15th Conference on Computer and Robot Vision. Toronto, Canada: IEEE, 2018. 95−101 [36] Liau H, Yamini N, Wong Y L. Fire SSD: Wide fire modules based single shot detector on edge device. arXiv preprint, arXiv: 1806.05363, 2018. [37] Wang R J, Li X, Ling C X. Pelee: A real-time object detection system on mobile devices. In: Proceedings of the 32nd International Conference on Neural Information Processing Systems. Montréal, Canada: IEEE, 2018. 1967−1976 [38] He K M, Zhang X Y, Ren S Q, Sun J. Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification. In: Proceedings of the 2015 IEEE International Conference on Computer Vision. Santiago, Chile: IEEE, 2015. 1026−1034 [39] Long J, Shelhamer E, Darrell T. Fully convolutional networks for semantic segmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2014, 39(4): 640−651 [40] Badrinarayanan V, Kendall A, Cipolla R. SegNet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(12): 2481−2495 doi: 10.1109/TPAMI.2016.2644615 [41] He K M, Gkioxari G, DollárP, Girshick R. Mask R-CNN. In: Proceedings of the 2017 IEEE International Conference on Computer Vision. Venice, Italy: IEEE, 2017. 2961−2969 [42] Lu Z, Qin S Y, Li X J, Li L W, Zhang D H. One-shot learning hand gesture recognition based on modified 3D convolutional neural networks. Machine Vision and Application, 2019, 30(7–8): 1157−1180 doi: 10.1007/s00138-019-01043-7 [43] Lu Z, Qin S Y, Li L W, Zhang D H, Xu K H, Hu Z Y. One-shot learning hand gesture recognition based on lightweight 3D convolutional neural networks for portable applications on mobile systems. IEEE Access, 2019, 7: 131732−131748 doi: 10.1109/ACCESS.2019.2940997 -

 下载:
下载:





计量
- 文章访问数: 2042
- HTML全文浏览量: 2394
- PDF下载量: 308
- 被引次数: 0
