

-
摘要: 目前自然语言推理(Natural language inference,NLI)模型存在严重依赖词信息进行推理的现象.虽然词相关的判别信息在推理中占有重要的地位,但是推理模型更应该去关注连续文本的内在含义和语言的表达,通过整体把握句子含义进行推理,而不是仅仅根据个别词之间的对立或相似关系进行浅层推理.另外,传统有监督学习方法使得模型过分依赖于训练集的语言先验,而缺乏对语言逻辑的理解.为了显式地强调句子序列编码学习的重要性,并降低语言偏置的影响,本文提出一种基于对抗正则化的自然语言推理方法.该方法首先引入一个基于词编码的推理模型,该模型以标准推理模型中的词编码作为输入,并且只有利用语言偏置才能推理成功;再通过两个模型间的对抗训练,避免标准推理模型过多依赖语言偏置.在SNLI和Breaking-NLI两个公开的标准数据集上进行实验,该方法在SNLI数据集已有的基于句子嵌入的推理模型中达到最佳性能,在测试集上取得了87.60%的准确率;并且在Breaking-NLI数据集上也取得了目前公开的最佳结果.Abstract: At present, natural language inference (NLI) models rely heavily on word information. Although the discriminant information related to the words plays an important role in inference, the inference models should pay more attention to the internal meaning of continuous text and the expression of language, and carry out inference through an overall grasp of sentence meaning rather than make shallow inference based on the opposition or similarity between individual words. In addition, the traditional supervised learning method makes the model rely too much on the language priori of the training set, and lacks the understanding of the language logic. In order to explicitly emphasize the importance of the learning sequence encoding and reduce the impact of language bias, this paper proposes a natural language inference method based on adversarial regularization. This method firstly introduces an inference model based on word encoding, which takes the word encoding in the standard inference model as input, and it can infer successfully only by using language bias. Then, through the adversarial training between the two models, the standard inference model can avoid relying too much on language bias. Experiments were carried out on two open standard datasets, SNLI and Breaking-NLI. On the SNLI dataset, the method achieves the best performance in existing inference models based on sentence embedding, and achieves 87.60% accuracy in test set. And the inference model has achieved state-of-the-art result on the Breaking-NLI dataset.1) 本文责任编委 张军平
-
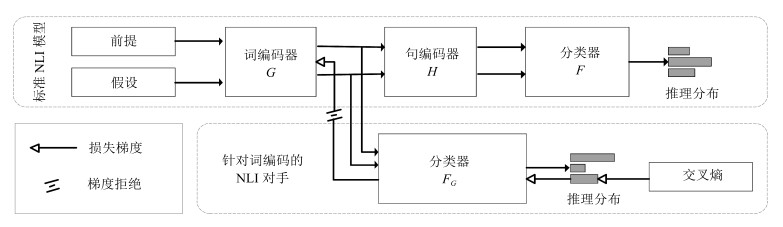
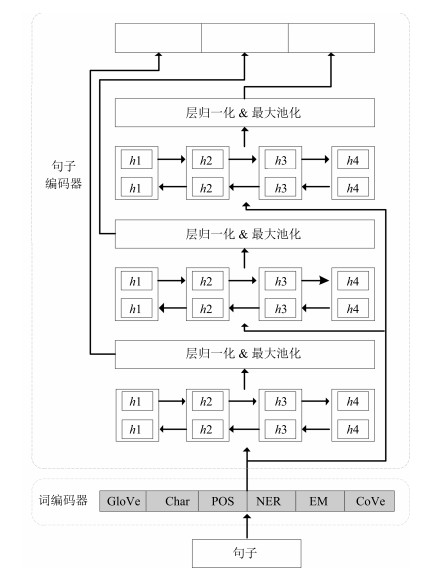
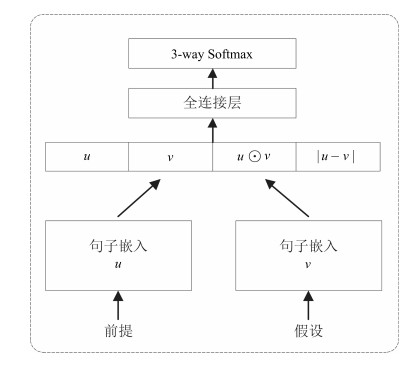
图 2 基于对抗正则化的自然语言推理模型结构框图
Fig. 2 The structure of natural language inference model based on adversarial regularization
表 1 SNLI数据集上的三个例子
Table 1 Three examples from the SNLI dataset
Premise (前提) Hypothesis (假设) Label (标签) A soccer game with multiple males playing. Some men are playing a sport. Entailment (译文) 一场有多名男子参加的足球比赛. 有些男人在做运动. 蕴涵 A person on a horse jumps over a broken down airplane. A person is training his horse for a competition. Neutral (译文) 一个人骑着马跳过了一架坏掉的飞机. 为了参加比赛, 一个人正在训练他的马. 中立 A black race car starts up in front of a crowd of people. A man is driving down a lonely road. Contradiction (译文) 一辆黑色赛车在一群人面前启动. 一个男人开着车行驶在荒凉的路上. 矛盾  下载: 导出CSV
下载: 导出CSV
表 2 不同方法在SNLI上的实验结果(%)
Table 2 Experimental results for different methods on SNLI (%)
对比方法 模型 训练准确率 测试准确率 Mou等[13] (2015) 300D Tree-based CNN encoders 83.3 82.1 Liu等[12] (2016) 600D (300 + 300) BiLSTM encoders 86.4 83.3 Liu等[12] (2016) 600D BiLSTM encoders with intra-attention 84.5 84.2 Conneau等[34] (2017) 4096D BiLSTM with max-pooling 85.6 84.5 Shen等[6] (2017) Directional self-attention network encoders 91.1 85.6 Yi等[7] (2018) 300D CAFE (no cross-sentence attention) 87.3 85.9 Im等[16] (2017) Distance-based Self-Attention Network 89.6 86.3 Kim等[35] (2018) DRCN (-Attn, -Flag) 91.4 86.5 Talman等[36] (2018) 600D HBMP 89.9 86.6 Chen等[37] (2018) 600D BiLSTM with generalized pooling 94.9 86.6 Kiela等[38] (2018) 512D Dynamic Meta-Embeddings 91.6 86.7 Yoon等[17] (2018) 600D Dynamic Self-Attention Model 87.3 86.8 Yoon等[17] (2018) Multiple-Dynamic Self-Attention Model 89.0 87.4 本文方法 BiLSTM_MP 89.46 86.51 本文方法 EMRIM 92.71 87.36 本文方法 BiLSTM_MP + AR 89.02 86.73 本文方法 EMRIM + AR 93.26 $\textbf{87.60}$
下载: 导出CSV
表 3 不同方法在Breaking-NLI上的测试结果
Table 3 Experimental results for different methods on Breaking-NLI
下载: 导出CSV
表 4 权重$\lambda$对NLI准确率的影响
Table 4 Impact of weight $\lambda$ on NLI accuracy
权重值 测试准确率(%) 0.5 86.90 0.25 87.14 0.10 87.60 0.05 87.35 0.01 87.39
下载: 导出CSV
-
[1] 郭茂盛, 张宇, 刘挺.文本蕴含关系识别与知识获取研究进展及展望.计算机学报, 2017, 40(4):889-910 http://d.old.wanfangdata.com.cn/Periodical/jsjxb201704008Guo Mao-Sheng, Zhang Yu, Liu Ting. Research advances and prospect of recognizing textual entailment and knowledge acquisition. Acta Automatica Sinica, 2017, 40(4):889 -910 http://d.old.wanfangdata.com.cn/Periodical/jsjxb201704008 [2] 任函, 冯文贺, 刘茂福, 万菁.基于语言现象的文本蕴涵识别.中文信息学报, 2017, 31(1):184-191 http://d.old.wanfangdata.com.cn/Periodical/zwxxxb201701024Ren Han, Feng Wen-He, Liu Mao-Fu, Wan Jing. Recognizing textual entailment based on inference phenomena. Journal of Chinese Information Processing, 2017, 31(1):184-191 http://d.old.wanfangdata.com.cn/Periodical/zwxxxb201701024 [3] Bowman S R, Angeli G, Potts C, Manning C D. A large annotated corpus for learning natural language inference. In: Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. Lisbon, Portugal: Association for Computational Linguistics, 2015.632-642 [4] Glockner M, Shwartz V, Goldberg Y. Breaking nli systems with sentences that require simple lexical inferences. In: Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Short Papers). Melbourne, Australia: Association for Computational Linguistics, 2018.650-655 https://arxiv.org/abs/1805.02266 [5] Gong Y, Luo H, Zhang J. Natural language inference over interaction space. In: Proceedings of the 6th International Conference on Learning Representations. 2018. [6] Shen T, Zhou T, Long G, Jiang J, Pan S, Zhang C. DiSAN: directional self-attention network for RNN/CNN-free language understanding. In: Proceedings of the 32nd AAAI Conference on Articifical Intelligence. New Orleans, USA: AAAI, 2018.5446-5445 [7] Yi T, Luu A T, Siu C H. Compare, compress and propagate: enhancing neural architectures with alignment factorization for natural language inference. In: Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Brussels, Belgium: Association for Computational Linguistics, 2018.1565-1575 https://arxiv.org/abs/1801.00102 [8] Chen Q, Zhu X, Ling Z H, Wei S, Jiang H, Inkpen D. Enhanced LSTM for natural language inference. In: Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics. Vancouver, Canada: Association for Computational Linguistics, 2017.1657-1668 [9] Zhang K, Lv G, Wu L, Chen E, Liu Q, Wu H, Wu F. Image-enhanced multi-level sentence representation net for natural language inference. In Proceedings of the 2018 IEEE International Conference on Data Mining (ICDM). Singapore, Singapore: IEEE, 2018.747-756 [10] Camburu O M, Rocktäschel T, Lukasiewicz T, Blunsom P. e-SNLI: natural language inference with natural language explanations. In: Proceedings of the 32nd Conference on Neural Information Processing Systems. Montréal, Canada: NeurIPS, 2018.9560-9572 [11] Poliak A, Naradowsky J, Haldar A, Rudinger R, Van Durme B. Hypothesis only baselines in natural language inference. In: Proceedings of the 7th Joint Conference on Lexical and Computational Semantics. Vancouver, Canada, 2018.180-191 https://arxiv.org/abs/1805.01042 [12] Liu Y, Sun C, Lin L, Wang X. Learning natural language inference using bidirectional LSTM model and inner-attention. arXiv preprint arXiv: 1605.09090, 2016. [13] Mou L, Men R, Li G, Xu Y, Zhang L, Yan R, et al. Natural language inference by tree-based convolution and heuristic matching. In: Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics. Berlin, Germany: Association for Computational Linguistics, 2016.130 https://arxiv.org/abs/1512.08422 [14] Munkhdalai T, Yu H. Neural semantic encoders. In: Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics. Valencia, Spain, 2017.397-407 [15] Shen T, Zhou T, Long G, Jiang J, Wang S, Zhang C. Reinforced self-attention network: a hybrid of hard and soft attention for sequence modeling. In: Proceedings of the 27th International Joint Conference on Artificial Intelligence. New Orleans, USA: AAAI, 2018.4345-4352 [16] Im J, Cho S. Distance-based self-attention network for natural language inference. arXiv preprint arXiv: 1712.02047, 2017. [17] Yoon D, Lee D, Lee S K. Dynamic self-attention: computing attention over words dynamically for sentence embedding. arXiv preprint arXiv: 1808.07383, 2018. [18] Goodfellow I, Pouget-Abadie J, Mirza M, Xu B, WardeFarley D, Ozair S, et al. Generative adversarial nets. In: Proceedings of the 2014 Conference on Advances in Neural Information Processing Systems. Montreal, Canada: Curran Associates, Inc., 2014.2672-2680 [19] Mao X, Li Q, Xie H, Lau R Y, Wang Z, Smolley S P. Least squares generative adversarial networks. In: Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV). Venice, Italy: IEEE, 2017.2813-2821 https://arxiv.org/abs/1611.04076 [20] Arjovsky M, Chintala S, Bottou L. Wasserstein GAN. In: Proceedings of the 34th International Conference on Machine Learning. Sydney, Australia: ICML, 2017.214-233 [21] Zhu J Y, Zhang R, Pathak D, Darrell T, Efros A A, Wang O, et al. Toward multimodal image-to-image translation. In: Proceedings of the 31st Conference on Neural Information Processing Systems. Long Beach, USA: NIPS, 2017.465-476 https://arxiv.org/abs/1711.11586 [22] Yi Z, Zhang H, Tan P, Gong M. Dualgan: unsupervised dual learning for image-to-image translation. In: Proceedings of the 2017 IEEE International Conference on Computer Vision. Venice, Italy: IEEE, 2017.2849-2857 [23] Yu L T, Zhang W N, Wang J, Yu Y. Seqgan: sequence generative adversarial nets with policy gradient. In: Proceedings of the 31st AAAI Conference on Artificial Intelligence. San Francisco, USA: AAAI 2017.2852-2858 [24] Lin K, Li D, He X, Zhang Z, Sun M T. Adversarial ranking for language generation. In: Proceedings of the 31st Conference on Neural Information Processing Systems. Long Beach, CA, USA: NIPS, 2017.3155-3165 https://arxiv.org/abs/1705.11001 [25] Tzeng E, Hoffman J, Saenko K, Darrell T. Adversarial discriminative domain adaptation. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, Hawaii, USA: IEEE, 2017.7167-7176 [26] Lample G, Zeghidour N, Usunier N, Bordes A, Denoyer L. Fader networks: manipulating images by sliding attributes. In: Proceedings of the 31st Conference in Neural Information Processing Systems. Long Beach, CA, USA: NIPS, 2017.5967-5976 [27] Pennington J, Socher R, Manning C. Glove: global vectors for word representation. In: Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP). Doha, Qatar: Association for Computational Linguistics, 2014.1532-1543 [28] Yang Z, Dhingra B, Yuan Y, Hu J, Cohen W W, Salakhutdinov R. Words or characters? fine-grained gating for reading comprehension. In: Proceedings of the 5th International Conference on Learning Representations. 2017. [29] McCann B, Bradbury J, Xiong C, Socher R. Learned in translation: contextualized word vectors. In: Proceedings of the 31st Conference in Neural Information Processing Systems. Long Beach, CA, USA: NIPS, 2017.6294-6305 [30] Anastasopoulos A, Chiang D. Tied multitask learning for neural speech translation. In: Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. New Orleans, USA: Association for Computational Linguistics, 2018.82-91 https://arxiv.org/abs/1802.06655 [31] Hinton G E, Srivastava N, Krizhevsky A, Sutskever I, Salakhutdinov R R. Improving neural networks by preventing co-adaptation of feature detectors. arXiv preprint arXiv: 1207.0580, 2012. [32] Ba J L, Kiros J R, Hinton G E. Layer normalization. arXiv preprint arXiv: 1607.06450, 2016. [33] Kingma D P, Ba J. Adam: a method for stochastic optimization. arXiv preprint arXiv: 1412.6980, 2014. [34] Conneau A, Kiela D, Schwenk H, Barrault L, Bordes A. Supervised learning of universal sentence representations from natural language inference data. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. Copenhagen, Denmark: Association for Computational Linguistics, 2017.670-680 [35] Kim S, Hong J H, Kang I, Kwak N. Semantic sentence matching with densely-connected recurrent and co-attentive information. arXiv preprint arXiv: 1805.11360, 2018. [36] Talman A, Yli-Jyrä A, Tiedemann J. Natural language inference with hierarchical bilstm max pooling architecture. arXiv preprint arXiv: 1808.08762, 2018. [37] Chen Q, Ling Z H, Zhu X. Enhancing sentence embedding with generalized pooling. In: Proceedings of the 27th International Conference on Computational Linguistics. Santa Fe, New Mexico, USA: The COLING 2018 Organizing Committee, 2018.1815-1826 https://arxiv.org/abs/1806.09828 [38] Kiela D, Wang C, Cho K. Dynamic meta-embeddings for improved sentence representations. In: Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Brussels, Belgium: Association for Computational Linguistics, 2018.1466-1477 https://arxiv.org/abs/1804.07983 [39] Parikh A, Täckström O, Das D, Uszkoreit J. A decomposable attention model for natural language inference. In: Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. Austin, Texas, USA: Association for Computational Linguistics, 2016.2249-2255 https://arxiv.org/abs/1606.01933 [40] Nie Y, Bansal M. Shortcut-stacked sentence encoders for multi-domain inference. In: Proceedings of the 2nd Workshop on Evaluating Vector Space Representations for NLP. Copenhagen, Denmark: Association for Computational Linguistics, 2017.41-45 https://arxiv.org/abs/1708.02312 [41] Chen Q, Zhu X, Ling Z H, Inkpen D, Wei S. Neural natural language inference models enhanced with external knowledge. In: Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics. Melbourne, Australia: Association for Computational Linguistics, 2018.2406-2417 https://arxiv.org/abs/1711.04289 -

 下载:
下载:

计量
- 文章访问数: 2560
- HTML全文浏览量: 399
- PDF下载量: 144
- 被引次数: 0
